融合多特征和注意力机制的肺结节分割算法
2023-01-31汤铁群张荣福林凯临
卢 娟,汤铁群,张荣福,李 峰,林凯临
1(上海理工大学 光电信息与计算机工程学院,上海 200093) 2(上海理工大学 医用光学技术与仪器教育部重点实验室,上海 200093) 3(复旦大学 附属肿瘤医院,上海 200093)
1 引 言
肺癌是全世界范围内发病率和致死率最高的癌症之一.据全球统计数据显示[1],截至2020年男性肺癌发病率及死亡率均占恶性肿瘤的第一位;在女性人群中肺癌的死亡率仅次于乳腺癌,位列第二.患者的早期诊断及治疗是提高其存活率的关键.根据相关报道,晚期肺癌患者的五年存活率小于15%,而早期肺癌患者的五年存活率可以达到40%-70%[2].然而,基于肺部CT影像的人工分析费时、费力,而且严重依赖医生的主观判断.同时,随着CT影像数据指数级的增长,也给医生带来了沉重的工作负担,大大增加了误诊和漏诊率.因此,基于肺部CT影像的计算机辅助肺癌诊断和筛查技术的研究可以辅助医生的诊断,加速诊断过程,减轻医生负担,具有非常重要的意义.
肺结节是肺癌的早期症状,从肺部CT中准确地分割出肺结节对后续转诊、治疗具有重要临床意义.近年来,虽然很多针对肺结节分割的方法已被提出[3-5],但由于肺结节在CT图像上的异质性,仍难以获得准确的分割结果.如图1所示,孤立性结节、胸膜旁结节、空洞结节和磨玻璃不透明结节都从形状、质地和强度上反映了肺结节的异质性.此外,由于肺结节与其周围组织之间高度相似,开发一个稳健的分割模型也是一个技术挑战.例如,胸膜旁结节(图1(b)),由于肺结节的强度与肺壁几乎相同,很难自动确定其确切位置.
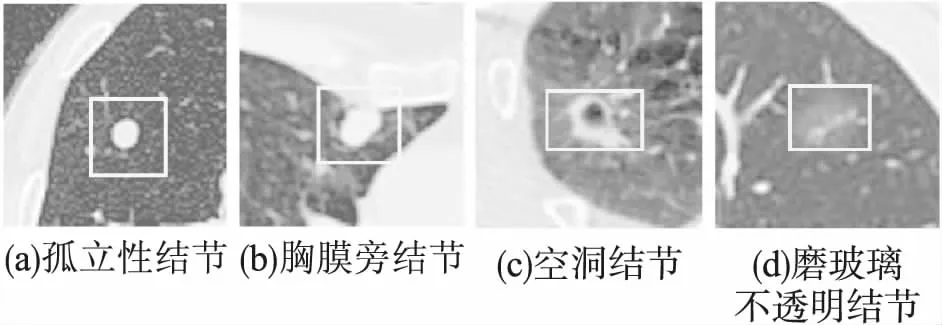
图1 肺结节CT表现Fig.1 Examples of lung nodules in CT images
本研究试图探索融合多特征和注意力机制的VGGNet16来自动分割肺结节.主要有以下贡献:
1)采用改进的VGGNet16作为特征提取的主干网络.为了防止高层特征中的小目标分辨率过低甚至丢失,以至于在浅层特征中其位置信息也随之消失,故排除其最后的池化层和全连接层.其次,在主干网络的每一个block中引入卷积块注意力机制(CBAM:Convolutional Block Attention Module)引导网络更加关注重点目标区域,抑制无效区域,提高网络的分割性能.
2)主干网络的5个block用于提取不同层不同尺度大小的多个特征.其中,前两个block(低层block)用以提取具有高分辨率、弱语义性的边缘特征.为了能够使提取到的边缘特征更加精确和清晰,在低层block之后还额外添加一个1×1的卷积层,通过该卷积层得到边缘映射图.在主干网络末端引入部分解码器(PD:Partial Decoder)融合后3个block(高层block)中所有高层特征,生成一个粗略的全局映射图,用于指导后续基于反向注意力的渐进式学习.低层特征与高层特征相融合获得较精确的肺结节分割图.
3)分别在主干网络的高层block尾部添加反向注意力模块(RA:Reverse Attention),作为一种渐进式的精细标注,使得整个网络能够学习到更多目标分割区域中的细节信息.即通过从侧向输出特征中删除当前预测的待分割肺结节区域,从而引导整个网络依次发现丢失的细节特征.
本文的组织结构如下:第2节中,简要阐述了本文的相关工作.第3节中,详细描述所提出的肺结节分割算法.在第4节中,将本文的肺结节分割算法与现有的几种基于深度学习的肺结节分割方法进行实验对比及分析讨论.第5节中,总结全文和展望.
2 相关工作
CT成像技术在肺部疾病的诊断中发挥重要作用.研究人员一直在努力开发一种具有更高精度和鲁棒性的基于CT影像的自动分割系统,以辅助放射科医生进行病变的诊断.基于CT影像的自动分割技术主要分为基于传统图像的分割技术和基于深度学习的分割技术.
传统图像分割技术主要包括阈值法[6]、区域生长[7]和形态学法[8]等.传统的分割方法通常是基于一定的先验假设人工提取目标特征,不能客观地对目标区域进行分割.例如,Awad[9]等人使Otus多阈值法和形状约束法获得肺实质轮廓,然后利用基于稀疏场的活动轮廓模型在肺实质中对肺结节进行分割.Dehmeshki[10]等人提出了一种利用模糊连通性和基于对比度的区域生长技术来进行结节分割的算法.该算法对分离结节的分割效果较好,但在分割附着的结节方面表现较差.考虑到肺部 CT 图像中结节的边缘模糊、灰度不均匀、受到噪声和伪影的影响大,这些传统的肺结节分割算法比较局限,很难正确有效地检测出形状各异的结节.然而,与手工提取特征的方法相比,深度神经网络能从训练数据中自动地学习并提取特征,最终实现分割,效果更好.
近年来,深度学习广泛应用于医学图像的分割、分类等领域[11-16].在肺结节分割领域,由于肺结节的异质性以及结节与其周围组织之间具有相似的视觉特征,肺结节区域的提取变得相对困难.为此,各种基于深度学习的肺结节分割模型[17-19]被提出.例如,Wang[17]等人提出了一个中心聚焦式卷积神经网络,用于从异质的二维CT图像中分割出肺结节区域,然而该算法要求较高的计算复杂度.Jin[18]等人利用GAN合成的数据来训练一个更具判别性的病理性肺分割模型.闫欢兰[19]等人结合Sobel算子和Mask R-CNN网络在CT图像上来分割肺结节区域,其算法的总体精度偏低,泛化性较差.
为了解决肺结节的异质性及其与周围组织具有相似的视觉特征,本文基于深度学习提出了一种融合多特征和注意力机制的肺结节分割模型(FMA-Net),采用了由粗到细的分割策略.FMA-Net模型利用主干网络的低层block提取富含边缘信息的低层特征;主干网络末端的部分解码器聚合高层block中的所有高层特征,生成一个粗略全局映射图,其次,将生成的全局映射图结合高层block中提取的多个不同尺度的特征图作为输入,传输到引入的反向注意力模块开始逐层依次挖掘目标区域的细节特征;最终,融合多特征,即将低层具有高分辨率的边界特征作为分割约束与高层特征进行融合生成最终的肺结节分割图.
3 肺结节分割算法
3.1 网络总体结构设计
本文所提出的FMA-Net的总体框架如图2所示.二维 肺部CT图像首先被送入低层block中,用以提取具有高分辨率、弱语义性(即低层)的特征.为了使目标区域的边界特征表现更加清晰,我们让C2特征通过具有一个卷积核的卷积层,获得更加精确的边缘映射图.然后,所获得的低层C2被送入到主干网络的后续block中.为了提取部分特征,我们在主干网络末端引入一个部分解码器(PD)模块,聚合高层block中的所有高层特征,生成一个全局映射图Pd用于粗略的定位待分割肺结节区域.此外,分别在高层block之后添加反向注意力模块(RA),每个高层block均产生一个不同尺度大小的特征,从粗略全局映射图开始依次与每个block获得的不同尺度大小的特征相结合,作为输入被送入到反向注意力模块,以提取目标区域的更多细节特征.最后,将多个特征进行融合,即低层的边界特征Pe作为分割约束与高层中最末尾的RA模块的输出R3相融合,经过Sigmoid激活函数生成最终的肺结节分割图.
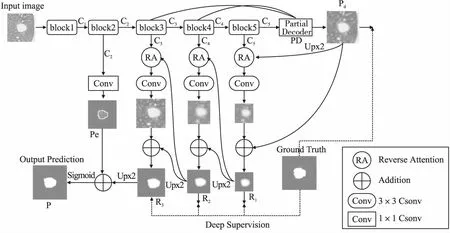
图2 肺结节分割网络(FMA-Net)结构图Fig.2 Structure of Lung nodule segmentation network(FMA-Net)
3.1.1 主干网络
在FMA-Net中,我们选择VGGNet16作为特征提取的主干网络,并对其进行了改进,如图3所示.为了降低参数数量、防止高层特征中小目标的丢失,我们排除了VGGNet16中最后的池化层和全连接层.同时,为了使网络重点关注更多目标区域,提高模型的性能,主干网络的每一个block中均引入卷积块注意力机制[20](CBAM).为了使网络具备学习多尺度特征的能力,我们在主干网络的后4个block之后都加入侧向输出部分用于提供不同尺度的特征信息,其中,低层block2的侧向输出分支用于提取高分辨率、弱语义性的低层特征,高层block3、4、5侧向输出分支用于提取具有较高语义置信度的高层特征.将高低层特征相融合即可获得最终的肺结节分割结果图.
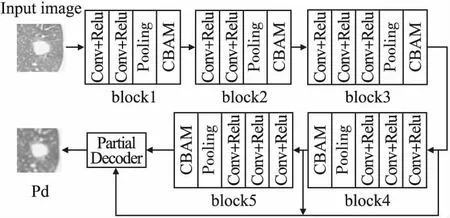
图3 主干网络结构图Fig.3 Structure of backbone network
3.1.2 部分解码器
许多现有的医学图像分割网络[21,22]都使用编码器的高低层特征进行分割病灶区域,融合多层特征可以进一步提高分割性能.在CNN中,高层特征提供语义信息,低层特征包含有助于细化对象边界的空间细节.然而,Wu等人[23]指出,与高层特征相比,低层特征对性能的贡献较小,且由于其较大的空间分辨率,其计算量较大.因此,我们在FMA-Net的主干网络末端引入部分解码器(PD)[23]模块,如图4所示.PD模块仅集成高层特征,丢弃了浅层的较大分辨率特征,实现快速准确的分割目标区域.具体过程如下:首先,在主干网络的高层block中提取3组具有高语义置信度的特征(即高层特征){Ci,i=3,4,5}.然后,利用部分解码器pd(·)聚合该3组高层特征,融合不同层级的特征可以使不同层的特征信息进行相互补充,从而产生一个粗略的全局映射图Pd=pd(C3,C4,C5),用于指导后续基于反向注意力的渐进式学习.
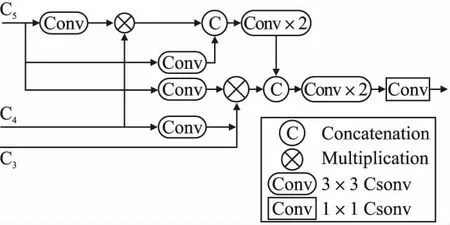
图4 部分解码器结构图Fig.4 Structure of partial decoder module
3.1.3 反向注意力模块
在本文中,为了能够将待分割肺结节区域的细节信息学习的更加精准.我们在FMA-Net的高层block中增加反向注意力模块(RA),用于渐进式扩展目标区域.具体来说,从将PD模块生成的粗略全局映射图开始,依次结合block5、4、3提取的不同尺寸大小的多个特征,作为输入,传输到RA中,通过从高层侧向输出特征中擦除当前预测的分割区域,由上到下依次发现需要补充的待分割肺结节区域的丢失信息和细节特征.其中,当前的预测结果则由更深的网络层的信息上采样得到的.这种渐进的擦除方式[24]可以将粗略的、低分辨率的预测结果细化为一个完整的高分辨率预测图,如图5所示.
对于输出的反向注意力特征,我们可以利用高层输出特征){Ci,i=3,4,5}和反向注意力权重Ai逐元素相乘得到,其可以表示为:
Ri=D(Ci·Ai)
(1)
其中,D(·)表示点乘操作.而RA权重Ai只需要简单的用1减去侧向输出第i+1阶段的上采样预测即可得到,其计算如下:
Ai=1-Sigmoid(U(Ci+1))
(2)
其中,U(·)表示上采样操作.
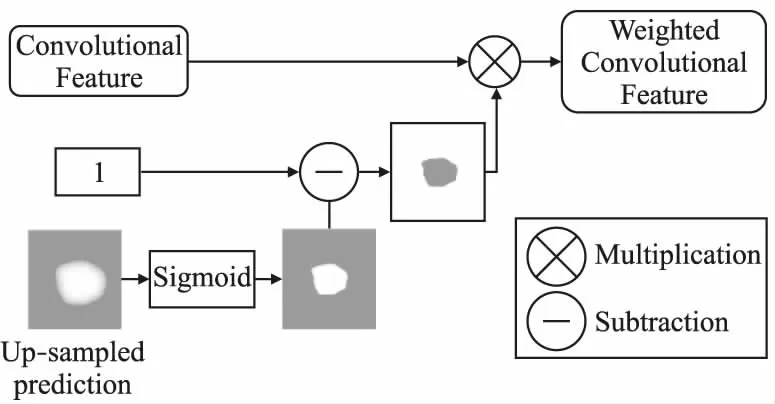
图5 反向注意力模块示意图Fig.5 Illustration of reverse attention module
3.2 损失函数设计
损失函数主要用于衡量预测值和目标值之间的误差,网络训练的目的旨在最小化损失函数.本文FMA-Net的损失函数主要由低层损失函数和高层损失函数构成.
在低层block中,我们使用标准的二值交叉熵损失函数(BCE)来度量由低层特征生成的边缘映射图Pe与由真值图(GT)获得的边缘真值图Ge之间的差异:
(3)
其中,(x,y)是所预测的边缘图Pe和边缘真值图Ge中每一个像素点的坐标值.Ge由真值图Gs求导获得.此外,w和h分别是特征映射图的宽和高.
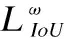
(4)
其中,λ表示权值,实验中设置为1.与标准损失函数不同,加权损失函数增加了困难像素样本点处的权值,为各个像素分配不同的权重,以突出它们不同的重要性.
在考虑损失函数时,我们需要同时考虑全局特征级别的损失函数和部分特征级别的损失函数,以获得更加准确的分割效果.全局特征级别的损失函数为PD模块生成的粗略全局映射图Pd与待分割肺结节区域的真值图Gs之间的损失函数,而部分特征级别的损失函数则是由高层block中每一个高层侧向输出的映射图(C3,C4,C5)与待分割肺结节区域的真值图Gs之间的损失函数.因此,我们的总体损失函数定义如式(5)所示:
(5)
4 实验分析与讨论
本实验的硬件平台:GPU为NVIDIA GTX 1080Ti 内存为16GB.软件平台:操作系统为Ubuntu 18.04.3,64位;MATLAB版本为2019a;训练环境为pytorch-gpu 1.4.0;python版本为3.6.2.
4.1 实验数据集
为了验证FMA-Net的有效性,我们采用两个不同的数据集来进行训练测试.数据集A是LUNA16第1期提供的包含1186张肺结节图片的公开数据集,其中包含结节直径和位置信息的标注.该数据集是含有2610张肺结节图片的公开LIDC-IDRI数据集的一个子集.从LIDC-IDRI数据集中筛选了888名患者的CT数据,每个数据都由经验丰富的放射科医生标记.此外,每位放射科医生将已识别的病变分为3类:非结节(其他组织或背景)、直径大于3毫米的结节和直径小于3毫米的结节.以直径大于3毫米并由3至4名放射科医生标记的结节作为金标准,而直径小于3毫米且仅由1至2名放射科医生标记的结节被忽略.
数据集B来自于合作的上海复旦大学附属肿瘤医院的病例数据,该数据集包含了89名患者的631张肺结节二维CT图像.在初始阶段,这些病例样本被随机分配给3名放射科医生进行筛查和标记,并在间隔至少1周的时间中重复筛查和标记一次;在最终阶段,再由3名工作时间至少5年的经验丰富的放射科专家来验证和纠正标注结果.
4.2 数据集扩充
本文对两个数据集中的图像进行了数据增强以避免网络过拟合.我们所使用的数据增强方法主要包括水平镜像、垂直翻转、旋转和高斯噪声.此外,利用高斯金字塔下采样方法将数据集上的所有CT图像下采样到96×96像素,并将像素值缩放至0~1的范围内,以满足网络的计算要求.
4.3 评价指标
我们采用Dice相似系数、灵敏度(Sensitivity)以及特异性(Specificity)指标来评估模型的性能.为了测量我们最终预测的分割结果图P与真值图G之间的像素级别误差,我们还采用了平均绝对误差(MAE).Dice相似系数计算分割结果与真值图之间的重叠度,定义为:
(6)
其中,TP为真阳性数,FP为假阳性数,FN为假阴性数.
灵敏度(Sensitivity)以及特异性(Specificity)分别计算为:
(7)
(8)
其中,TN为真阴性数.
平均绝对误差(MAE):该指标度量了最终预测的分割结果图P和真值图G之间像素级别的误差,定义为:
(9)
4.4 实验结果及分析
4.4.1 实验过程
为了验证本文提出的FMA-Net模型的有效性,我们分别在公开的数据集LUNA16和来自合作医院的数据集B上进行实验.
在实验时,对于公开数据集LUNA16,我们随机抽取119张样本图片作为独立测试集,其余1067张样本图片作为训练集.对于数据集B,我们随机选取64张样本图片作为独立测试集,其余567张样本图片作为训练集.为了避免过拟合,我们还分别对两个数据集进行数据增强.训练过程中,我们统一把输入样本图像的尺寸大小缩放为96×96.同时,采用不同的缩放比例{0.75,1,1.25}对输入图像进行多尺度采样.此外,使用重新采样的图像对FMA-Net模型进行训练,从而提高了模型的泛化性能.我们在训练时使用Adam优化器,初始学习率为1e-4,batchsize的大小设置成4,迭代次数为350次.
4.4.2 实验定性结果及分析
肺结节分割结果如图6所示,表明本文提出的FMA-Net模型优于经典的U-Net[25]及Attention U-Net[26].具体而言,所分割出的肺结节边界更清晰,错误分割的组织区域较少.相反,U-Net会错误分割出与肺结节相似的周围组织,Attention U-Net模型虽然改善了结果,但分割出的肺结节边界较模糊,性能仍然不理想.FMA-Net的性能提升归因于3点.1)主干网络每一个block中引入了卷积块注意力机制(CBAM),使得整体网络学习到更多目标区域的特征.2)本文的从粗到细的渐进式分割策略,即部分解码器(PD)首先粗略定位肺结节分割区域,然后使用反向注意力模块(RA)进行细化分割,这种从粗到细的策略模仿了临床医生从二维 CT 图像中分割出肺结节区域的过程,获得较好的表现.3)融合多特征,即将低层block中获得的边缘特征作为分割约束与高层block获得的高层语义特征相融合经过Sigmoid激活函数产生最后的分割结果图.
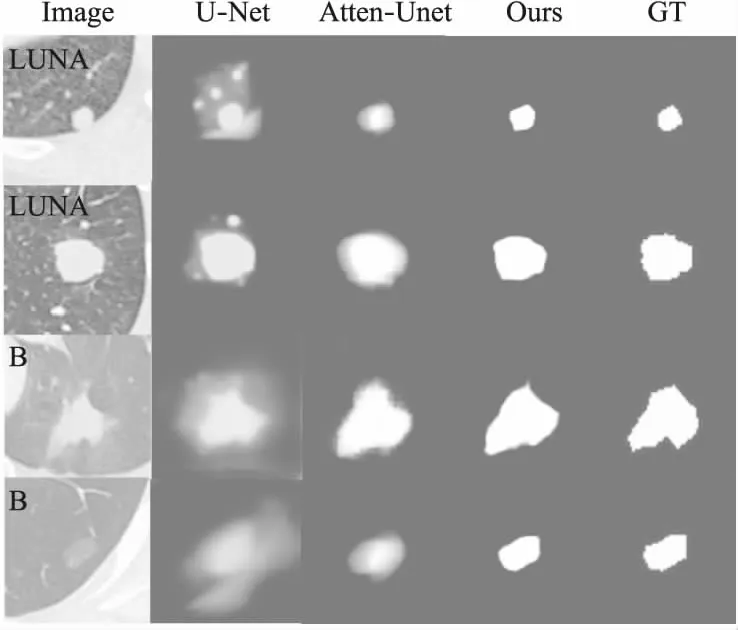
图6 不同数据集上肺结节分割结果对比图Fig.6 Comparison of lung nodules segmentation results on different datasets
4.4.3 不同模型的分割结果对比分析
为比较肺结节分割效果的性能,在公开数据集LUNA16上与经典U-Net、Residual U-Net[27]、Attention U-net、Issa Ali.et al[28]以及DFCNet[29]进行了比较.如表1所示,本文模型的Dice相似系数达到了86.4%,与U-Net、Residual U-Net以及Attention U-net相比,分别增加了29%、19%、10%.此外,本文模型获得的灵敏度达到了89.5%,与U-Net、Issa Ali.et al及DFCNet相比,分别提高了27%、52%、22%.同时,本方法获得的特异性达到了99.4%,与U-Net、Issa Ali.et al 及DFCNet相比,分别提高了2%、79%、21%.从表1中还可以看出,FMA-Net获得的MAE值降低到0.005,显著低于U-Net和Attention U-net的MAE值.
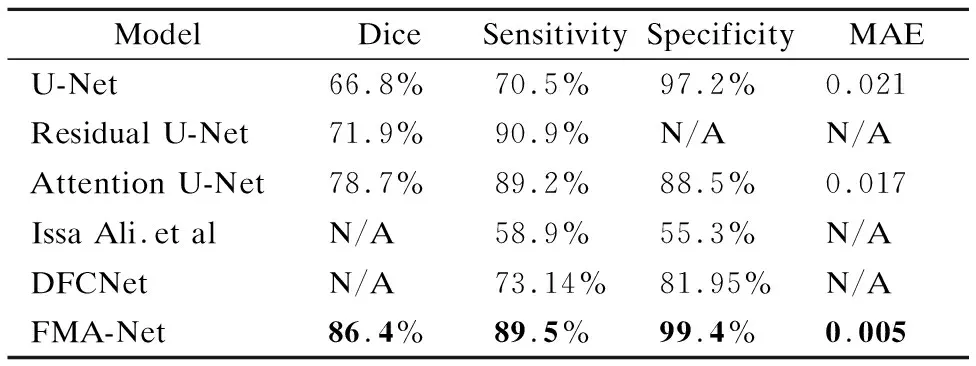
表1 LUNA16数据集上不同模型的肺结节分割定量结果Table 1 Quantitative results of lung nodules segmentation based on different models on LUNA16 dataset
4.4.4 注意力机制对性能的影响
分别在公开的数据LUNA16和数据集B上验证了卷积块注意力机制(CBAM)对FMA-Net模型分割性能的影响.分割定性结果如表2、表3所示,主干网络中引入注意力机制(CBAM)在主要指标(例如Dice、Sensitivity和 MAE 等指标)方面可以有效地改善分割性能.

表2 LUNA16数据集上肺结节分割定量结果Table 2 Quantitative results of lung nodules segmentation on dataset LUNA16

表3 数据集B上肺结节分割定量结果Table 3 Quantitative results of lung nodules segmentation on dataset B
5 总结与展望
本文提出了一个融合多特征和注意力机制的肺结节分割算法(FMA-Net),用于从肺部CT图像中自动可靠地分割出肺结节区域.FMA-Net以改进的VGGNet16网络作为主干网络,引入CBAM机制学习网络中更深层的重点信息.此外,融合多个特征,在主干网络的低层block中提取浅层特征,使用部分解码器(PD)聚合高层block中的深层内部细节特征.利用反向注意力模块(RA)从高层侧向输出特征中擦除当前预测分割区域,引导整个网络从上到下依次挖掘需要补充的细节信息,提高了分割的精度.
与其它类型结节相比,FMA-Net对磨玻璃类结节分割精度较低,这主要是由于该类型结节与周围组织对比度低.在后续工作中,将进一步研究低对比度目标分割算法,实现一个更优的肺结节分割模型.
