多属性推荐算法在企业研发服务系统中的应用
2023-01-31田俊鹏李晓戈马鲜艳
田俊鹏,李晓戈,2,马鲜艳
1(西安邮电大学 计算机学院,西安 710000) 2(西安邮电大学 陕西省网络数据分析与智能处理重点实验室,西安 710000)
1 引 言
现如今各行各业对于科技研发的需求日益上升,科技信息化开始进入大规模应用阶段,但企业却很难寻找到专业的研发团队去满足相应的研发需求.相反,高校重点实验室作为国内科研领域的重要组成部分,前沿科研应用于行业相对迟缓.因此,加大产学研密切合作,既是检验高校技术成果的有效途经,也是解决企业科技研发需求的有效方案.
从实践中发现,部分在线技术转移平台虽然登记了大量专利信息、技术成果以及研发需求信息,但并未有一套成熟的系统针对需求给出与其匹配的技术供给,导致技术转移成交量较少.以“陕西省中小企业服务平台”为例,2020-2021年成交195例,仅占平台全部需求的28%.关于在线平台的科技研发推荐的难点关键在于:1)技术供给文本通常包含大量信息,相似度计算决定供需匹配的准确性;2)单一属性无法全面表征技术供给方的科研领域及能力,技术供给方通常会从多个方面介绍自己的科研领域,例如:论文、专利、项目、成果、仪器等.各种指标属性对于供需方成交的影响力不同,因此需要对各属性数据计算结果赋予合适的权值,才能使供需匹配结果更加合理.因此,本文将基于文本语义匹配的方法[1],针对“陕西省中小企业服务平台”的技术需求文本,以及平台上公布的陕西省各高校重点实验室科研成果信息,探索技术需求匹配中的多维关键特征,为科技研发转移提供可行方案.
2 相关工作
近年来在线技术转移平台发展迅速,为企业科技研发服务提供了基础平台.但存在数据不对称、技术供应方成果多导致的人工检索难等问题.目前,线上供需推荐研究成果较少.2017年清华大学杨德林教授利用TF-IDF的方法计算余弦相似度[2],从网络平台的特点出发,运用文本表示及相似度计算模型,计算并评价了技术供需匹配效率.Mikolov等[3]开发的Word2vec能够利用大规模未经标注的语料高效地生成词的向量表示,且利用依存关系和上下文关系来训练词向量,可以包含更多的语义信息.2019年何喜军[4]等人提出计算供需文本词频特征、相关性特征和语义特征的匹配模型,通过采集在线技术转移平台数据,使用熵值法将多特征计算结果进行融合.目前国内外在语义层面上计算句子相似度的先进研究方法大多是基于词向量和深度模型的[5],这类方法在表征上下文语义信息方面还有许多不足之处.基于句向量的表示方法可以更好的表征句子的语义特征,表征更加丰富的上下文信息,可以通过均值模型或加权模型将词向量转化为句向量,也可以通过字向量拼接得到句向量的表示.2018年谷歌提出的Bert预训练模型通过取高层的隐向量求得对应的句向量[6],可以更好的捕捉上下文语义关系.TextCNN[7]用于文本等序列化数据的特征提取有不错的效果,但在文本特征提取任务中滑动窗口的大小较难确定.传统的RNN也可用于序列化特征提取,但对于局部特征的捕捉能力有限.TextRCNN[8]网络结合双向RNN与TextCNN的特点,对于解决“长距离依赖”和捕捉局部特征问题有明显的改善.本文基于句向量的嵌入表示计算文本的相似度[9],以TextRCNN作为特征提取器,将不同属性的相似性评分结合熵值法动态构建权重矩阵.最终实现融合多属性的推荐方式,尝试探索科研推荐的有效方案.
3 多属性融合企业研发推荐模型设计
本文基于 “陕西省中小企业服务平台”数据进行企业研发供需推荐,其中包括各高校重点实验室数据172组,每组数据包含专利、论文、成果、项目以及专著等多个属性.每个属性包含若干条概要信息描述该属性信息.数据结构示例如图1所示.
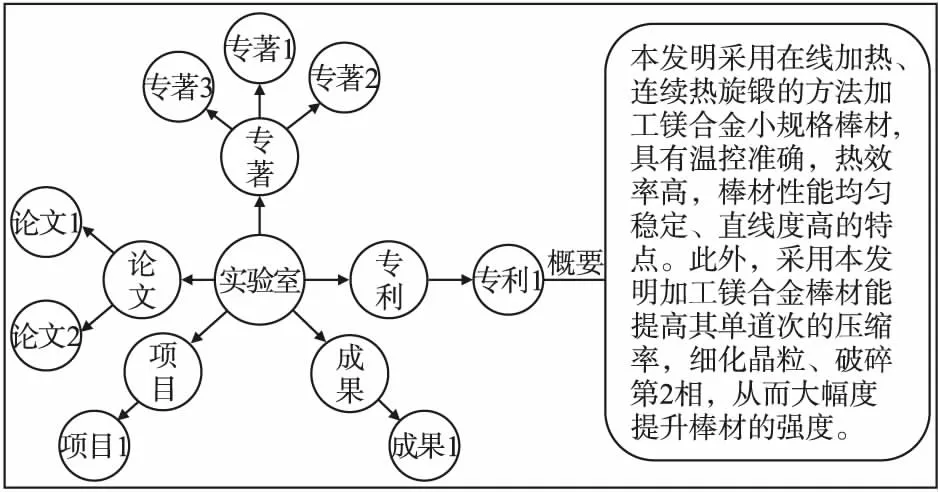
图1 多属性数据结构示例Fig.1 Example of multi-attribute data structure
针对该供需数据特征,图2展示了该推荐模型的系统流程.使用Bert预训练模型[10]作为供需文本的嵌入层,用于表征文本的上下文信息.结合TextRCNN模型用于学习文本相似性特征,输出层使用Softmax函数作为相似性评分[11],对各属性评分计算结果结合熵值法赋予权值,计算出每个实验室的推荐评分并排序.
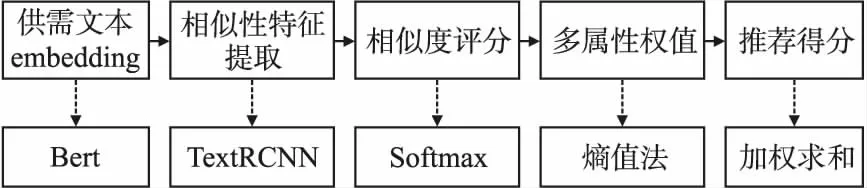
图2 系统流程图Fig.2 System flow chart
3.1 供需文本嵌入表示
句子表示阶段采用基于Bert预训练模型表示上下文特征,可以获得多层输出,每一层输出包括输入的每个字对应的隐向量,通过取高层的隐向量求得对应的句向量,Bert使用了Transformer[12]作为算法的主要框架,如图3所示.
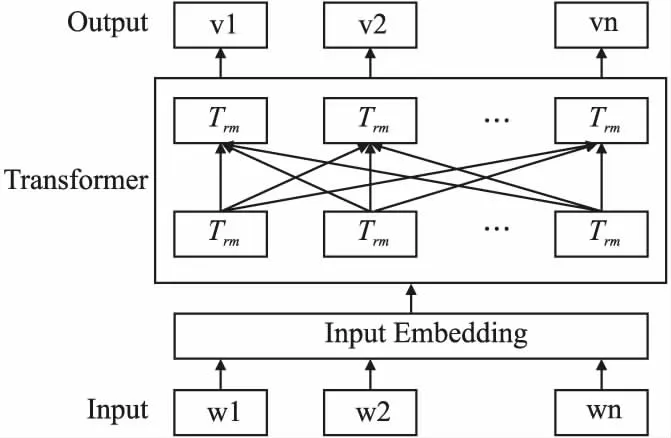
图3 Bert模型结构图Fig.3 Bert model structure diagram
由于Bert模型在设计的时候使用了完全基于注意力机制的双向Transformer编码结构.能够计算出每个词对句子中所有词的关系,进而能够反映出词与词之间的相互关系以及重要程度.因此能够蕴含更多上下文信息,从而可以更好地服务于下游任务.对于Bert的输入表示是将Token Embeddings、Segment Embeddings以及Position Embeddings这3个向量进行拼接[13],如图4所示.
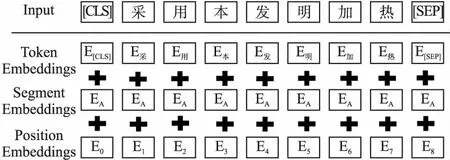
图4 Bert输入表示Fig.4 Bert input representation
3.2 神经网络特征提取
通过嵌入层得到文本的向量表示后,该向量作为TextRCNN层的输入,用以提取文本的相似性特征.TextRCNN结合了卷积网络与循环网络的优点,既可以获取局部特征也可以获取上下文特征.TextRCNN将经过嵌入层得到的向量使用循环网络RNN进行上下文特征提取.LSTM[14]网络可以学习长期依赖信息,由记忆细胞、输入门、遗忘门和输出门组成,其中记忆细胞用来存储和更新历史信息,3个门结构通过Sigmoid函数来决定信息的保留程度.记忆单元的结构如图5所示.
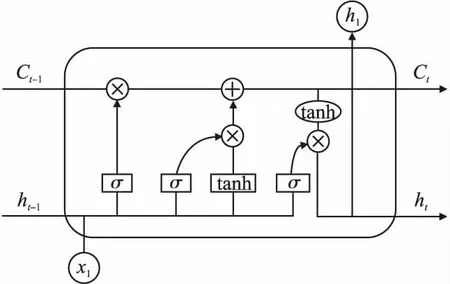
图5 LSTM网络记忆单元结构Fig.5 LSTM network memory cell structure
由于LSTM网络对于“长距离依赖”具有更好的处理能力,本文使用LSTM网络代替RNN网络用于特征提取.首先使用LSTM处理输入的向量,然后在每个时间步,把LSTM的输出与对应的句向量拼接,作为当前时间步的“语义向量”,可以更好的表示文本的上下文特征.之后使用池化层进行特征选择,选取 K个重要的语义向量作为输出的特征,把文本所有的语义向量取纵向最大池化操作得到特征表示输出,Text-RCNN网络结构如图6所示.
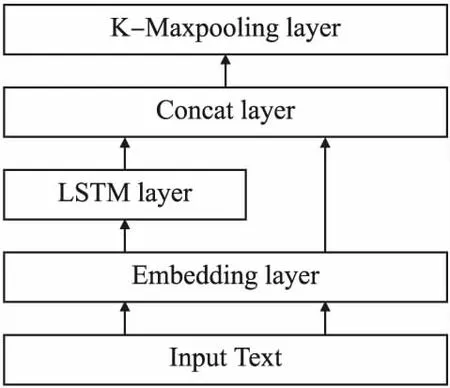
图6 TextRCNN网络结构Fig.6 TextRCNN network structure
3.3 多属性指标评价体系构建
各重点实验室信息包括论文、专利、项目、专著以及成果等多属性指标,各属性指标对于需求的重要性程度不同,需强化数据中的重要属性,削弱次要属性,引入多特征权值矩阵是一种可行的方法.本文采用熵值法确定多属性权值矩阵.
使用熵值法计算首先要进行非负处理,由于相似评分均为正数,故文本采用极差标准法对各项指标进行标准化处理[15].标准化计算公式如公式(1)所示.
(1)
Bij为原始数据,其中i=1,2,3,…,m;j=1,2,3,…,n;i和j分别表示第i个科技研发团队及该科技研发团队第j个科研成果属性;(Bj)max和(Bj)min分别代表第j个成果属性相似性得分的最大值和最小值.由于指标中涉及百分比变量,为避免权重为0的情况,统一将归一化后数值为0的指标按0.01计算.
首先,计算第i个实验室下第j个推荐指标所占的比重Pij,计算公式如公式(2)所示.
(2)
计算第j个指标的熵值ej,计算公式如公式(3)所示.
(3)
其中,ej为第j项指标的熵值,n为评价指标的数量,ln为自然对数.计算第j个指标的熵值Sj,计算公式如公式(4)所示.
(4)
设候选推荐实验室集合为Q={q1,q2,q3,…,qj},j为该数据集中科研团队的总数,qi为第i个实验室.qi={p1,p2,…,qn}为该科研团队科研成果属性集合.pm={c1,c2,c3,…,ck}表示第i个科研团队属性m下的所有成果集合.定义相似度评分函数score来衡量候选实验室Qi下的每一项科研成果与需求r的相关程度,计算公式如公式(5)所示.最后根据评分结果进行排序,给出推荐的科技研发团队.
(5)
4 模型评价数据集及评价方法
4.1 模型评价数据集准备
为验证Bert-TextRCNN网络在短文本相似性匹配任务上的有效性验证,本文使用两种数据集进行验证,分别是ATEC蚂蚁花呗数据集和LCQMC相似度匹配数据集.其中ATEC蚂蚁花呗数据集由阿里巴巴蚂蚁金服提供,采集于金融行业,来自客服与顾客的直接对话,基本都是短句子;LCQMC相似度匹配数据集是哈尔滨工业大学为解决在中文领域大规模问题匹配数据集的缺失,人工标注的相似度任务数据集.两种数据集的样本构造如表1及表2所示.由于这两个数据集为非平衡数据集[16],故对数据集进行欠采样处理,既可以平衡模型对正负样例的学习能力,还可以考察模型在小数据集上的表现.数据集处理后结果如表3所示.

表1 ATEC数据集样例Table 1 Sample ATEC data set

表2 LCQMC数据集样例Table 2 Sample LCQMC data set
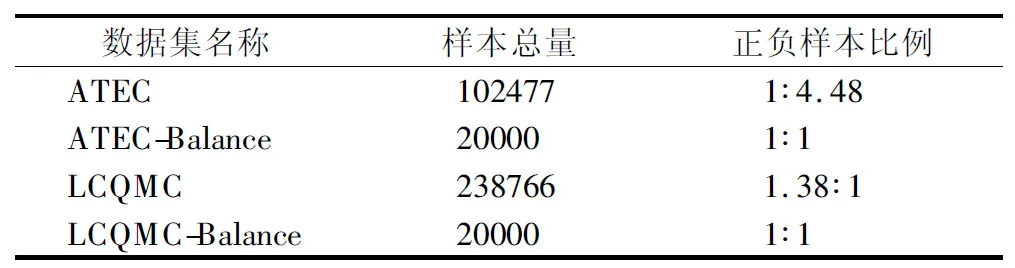
表3 数据集欠采样处理结果Table 3 Data set under-sampling processing result
4.2 评价方法
选择ROC-AUC作为评价标准,指标越接近1,代表模型性能越好.根据ROC的横纵坐标,可以构建混淆矩阵,利用混淆矩阵可计算ROC曲线的两个指标TPR和FPR,即召回率和查准率.根据TPR和FPR,可以计算出准确率的综合评分F1值,具体计算公式如公式(6)所示:
(6)
其中召回率表示模型正确预测出测试集正例数据数量与测试集数据总数的比率(其中TP表示正例数据预测正确的个数,FN表示负例数据预测正确的个数);准确率用来评估测试集预测正确的正例数量与测试集数据预测成正例的比率(FP表示测试集负例数据预测错误的个数);F1值即为两者的调和平均数.
5 实验与分析
本章主要验证Bert-TextRCNN网络模型各部分在短文本相似度匹配任务上的实验对比,验证本文所采用模型在该任务上的有效性,同时对实验结果进行分析,探究模型各部分组成对实验结果的影响,为将来进一步优化改进或应用于其他领域提供参考依据.
5.1 相似度对照实验
相似度对照实验模型采用Word2vecTextCNN、Word2vecTextRCNN、Bert-TextCNN以及Bert-TextRCNN这4种模型设置对照组,分别验证引入预训练模型Bert对于实验结果的影响以及TextCNN和TextRCNN对于短文本相似度匹配任务的不同表现.实验结果如表4、表5所示.
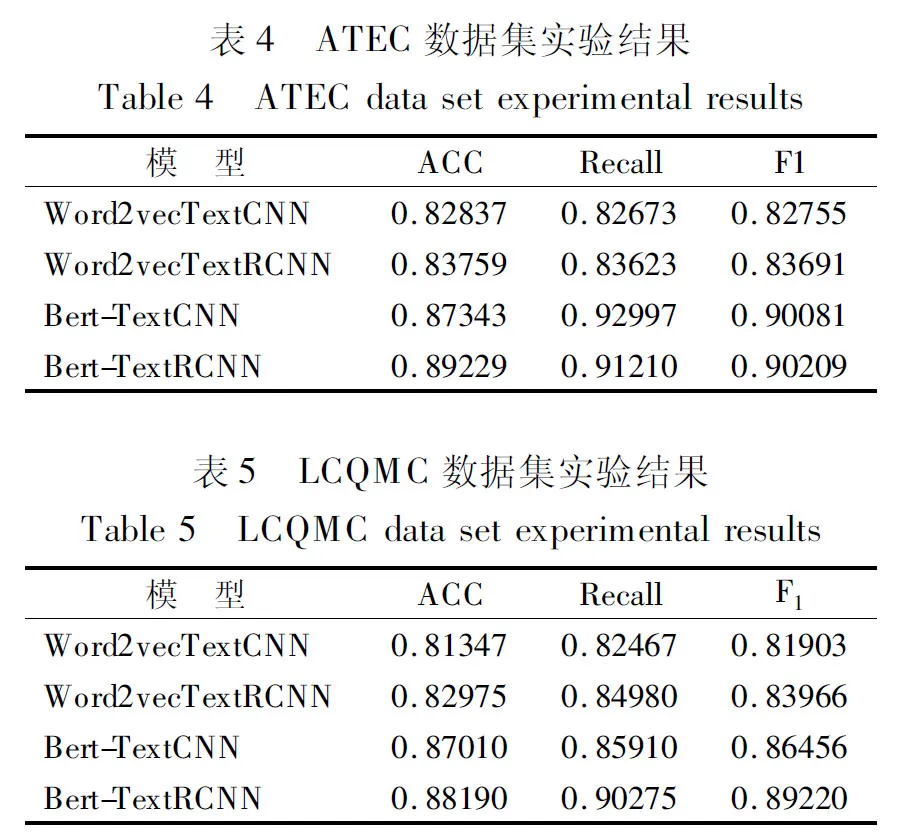
由实验结果可见Bert-TextRCNN在ATEC数据集和LCQMC数据集上的表现要优于其他3种网络结构,这得益于Bert预训练模型的遮蔽语言模型和多层Transfomer结构作为特征提取器,可直接作为一种抽象特征来服务于下游任务.对比实验表明,采用Bert预训练模型构建句向量的效果要优于Word2vec的词向量表示方法.在文本相似度计算领域,TextRCNN的效果比TextCNN的表现更好,这是由于Text-CNN只能捕捉局部特征,而TextRCNN使用LSTM网络代替卷积层,更好的捕捉序列化特征,从而捕捉到文本上下文语义信息.
5.2 多特征权值矩阵对照实验
在文本相似度实验的基础上,采用在ATEC数据集和LCQMC数据集表现最好的Bert-TextRCNN模型作为相似度计算模型,在“陕西省中小企业研发服务平台”成交信息数据集上测试引入多属性权值矩阵对于推荐结果准确性的影响.对于多属性权重矩阵的构建分为两种思路,一种是根据各属性数据分布情况使用熵值法[17]动态确定各组数据不同属性的权重,一种是根据业内专家对于属性的重要性评估,采用层次分析法确定固定权值矩阵.层次分析法确定权值过程如下:
5.2.1 构建判断矩阵
判断矩阵是建立各层次之间关系的结构化形式,根据各层次之间的重要性程度两两之间相互比较构建判断矩阵.首先根据相关专家对指标的相关重要性进行评估赋分,赋分标准按表6所示.

表6 标度取值及含义Table 6 Scale value and meaning
根据10名相关领域的专家评价结果作为层次分析法分析的对象.随机选取其中一位专家评价结果将其结果转换为判断矩阵B′如公式(7)所示,该矩阵具有正互反的特点,即Bii=Bjj=1,Bij×Bji=1.
(7)
5.2.2 计算多特征指标权重系数
利用几何平均法计算权重系数分为以下步骤:首先将判断矩阵B′的元素按照行相乘得到一个新的列向量Mi,接着计算Mi的n次方根Vi,最后对Vi进行归一化处理得到wi,具体计算如公式(8)所示,特征权重映射如表7所示.
(8)

表7 属性权重映射关系Table 7 Attribute weight mapping
共设置3组对照实验.分别验证引入熵值法、层次分析法与不引入多特征权重矩阵分别对于多属性推荐中权值矩阵对推荐结果的影响.测试数据使用“陕西省中小企业研发服务平台”所发布188条成交记录作为测试数据集进行测试,从中随机抽取若干条成交记录中的需求文本进行结果分析,平台成交记录示例如表8所示.通过对推荐得分的前5名实验室的科研成果内容根据成交结果判别推荐的准确性.为了消除某一属性内实体数量过多而导致的得分堆叠致使推荐分数过高,从而影响推荐结果的问题,故对相似度计算模型的得分进行剪枝操作,相似度得分低于0.3认为与目标需求不相关,故置为0.对比实验结果示例如表9、表10及表11所示.

表8 成交结果示例Table 8 Sample auction results

表9 相似度计算模型结合熵值法推荐结果Table 9 Similarity calculation model combined with entropy method recommendation results

表10 相似度计算模型结合层次分析法推荐结果Table 10 Similarity calculation model combined with analytic hierarchy process recommended results
针对需求“泾河大桥上部结构钢结构…”,通过在数据集中人工筛选,其中“陕西省结构与抗震重点实验室”与“陕西省公路桥梁与隧道重点实验室”是与其最为匹配的目标科技研发团队.需求“关于高温碳化金属有机框架材料…”,通过人工筛选,其中“陕西省纳米材料与技术重点实验室”与“陕西省轻化工助剂重点实验室”是与其最为匹配的目标科技研发团队.对比实际成交结果,实际成交方均被包含于上述人工筛选的科研团队中,可知该实例交易记录不存在太多客观扰动因素.分析实验结果,在引入熵值法的推荐结果中对应需求的实际成交方排名分别为第2名和第1名,表明权值矩阵可以调整推荐结果,且引入熵值法的推荐结果要明显优于层次分析法.这是由于熵值法会根据推荐得分的数据分布情况动态确定各指标权值,充分强化高分数据,削弱低分数据.而层次分析法权值矩阵固定,对于每组得分都赋予相同权值,且判断矩阵由人为填写,致使推荐结果附带一定的主观性.
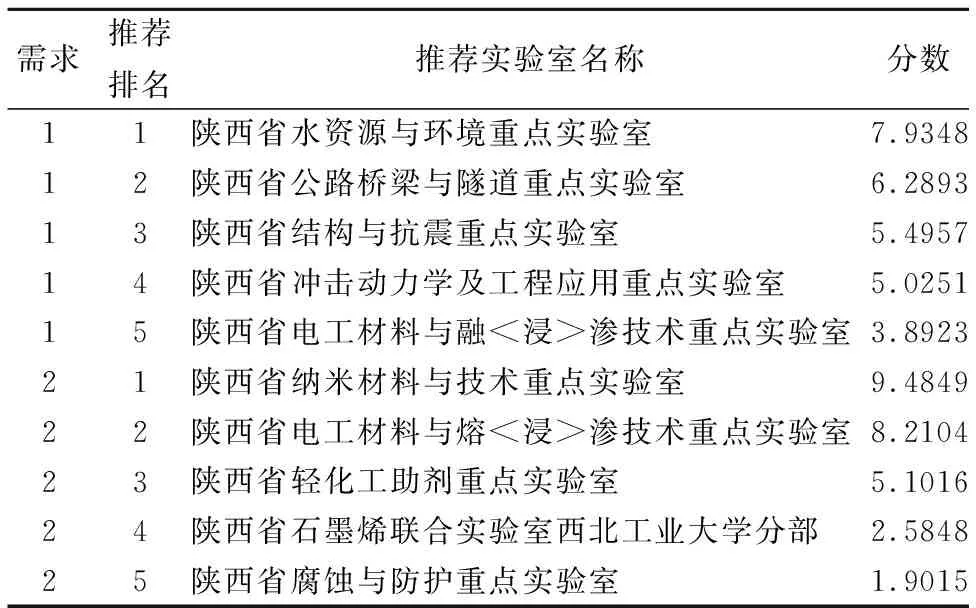
表11 相似度计算模型(不引入权值矩阵)推荐结果示例Table 11 Similarity calculation model(without introducing weight matrix)recommendation results
熵值法对各指标的权值计算与数据的分布有关,数据量的离散程度不同,最终确定的权重也不同,为验证在小样本上权值矩阵对推荐结果带来的影响,在上述实验的基础上抽取172个待推荐的科研团队其中的50个,但这50个目标团队中要包含与实际需求最相关的2个科研团队,使用表8所示成交实际样例进行验证,实验结果如表12所示.
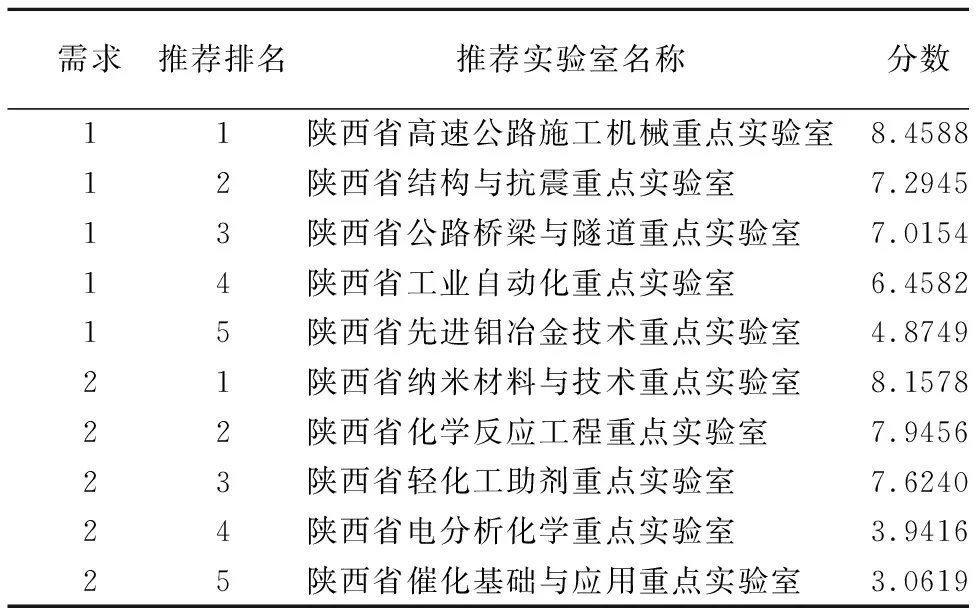
表12 小数据样例推荐结果示例Table 12 Small data sample recommended example results
由实验结果可以看出,本文提出的推荐算法在小数据集上的推荐结果并未受到明显的影响,表明采用熵值法确定指标权重的方法在小量数据上实现科研团队推荐具有一定的抗扰动性,这是熵值法的计算方式与该推荐任务的特殊性结合导致的结果.由公式(2)和公式(3)可知,对于成果项中的第j项指标,对应的指标值Bij的差异越大,熵值就越小,其所包含的信息量越多.由公式(5)可知,熵值越小,对应成果指标的权值越大.在科技研发团队推荐任务中,第j项指标下指标值Bij离散程度较大,说明j指标下有n(0 本文为实现技术供需双方信息共享和加速供需有效对接,充分利用互联网平台以实现技术交易的有效途径,提出一种融合多属性表示的相似度计算模型,利用句向量与序列化结合最大池化的特征提取方式,使文本的相似度度量结果更加准确.实验采集“陕西省中小企业服务平台”的供需数据用于验证模型在供需匹配领域的有效性,并验证权值矩阵可以有效的提高供需推荐的准确性.但由于只在“陕西省中小企业研发平台”进行供需推荐测试,数据量相对较小,且由于在实际研发中存在价格、事件、效率等客观因素,未进行人工标注测试集,仅采用随机抽取部分交易成交信息验证分析模型的准确性.为增强实验结果的说服力,该部分内容还有待优化,是今后继续改善提升的方向.由于该领域标注数据集的缺乏,本文使用了通用领域LCQMC数据集训练好的模型作为相似度得分计算模型,用其对提出的推荐算法进行验证,如果使用相关领域的数据集应该会取得更好的效果.基于图结构的推荐方式目前在许多领域有不错的表现,未来工作中将考虑采用基于知识图谱以及图神经网络的方式进行改进.6 结 语
