结合ALBERT和BiFASRU-AT的情感分析模型
2023-01-31梅侠峰吴晓鸰吴杰文
梅侠峰,吴晓鸰,吴杰文,凌 捷
1(广东工业大学 计算机学院,广州 510006) 2(华为技术有限公司,北京 100085)
1 引 言
随着网络平台兴起,人们更多地在网上发表评论,产生了大量带有情感倾向的文本信息.文本情感分析是自然语言处理中一个重要研究领域,是解决如何有效获取和管理海量文本数据的关键技术[1].
预训练词向量技术是深度学习技术应用于文本情感分析任务的前提条件[2].传统静态词向量模型Word2vec[3]、Glove[4],通过预训练技术将文本映射到数字向量,但存在缺乏文本位置信息和一词多义问题.随着预训练技术的发展,ELMO[5]和基于Transformer的双向编码器表征技术[6](BERT)等众多动态预训练模型被提出.Lan等[7]提出了基于BERT的轻量级模型ALBERT,利用跨层参数共享和嵌入层因式分解策略降低参数量,并提出了SOP任务,在多个NLP任务上取得最佳效果.使用表征能力强的词向量工具对深度模型的应用效果有着巨大影响.
文本情感特征分析方式一般包括3种,有基于情感字典和规则[8]的方法、基于传统机器学习[9,10]的方法和目前流行的基于深度学习模型的方法.卷积神经网络[11](Convolutional neural network,CNN)、循环神经网络(Recurrent neural network,RNN)以及长短期记忆网络[12](Long Short-Term Memory,LSTM),作为基础深度模型被广泛使用到情感分析任务,但RNN、CNN、LSTM模型无法聚焦于对情感分类的关键特征上.Vaswani等[13]在机器翻译领域首次提出了Transformer模块,此后,自注意力机制被大量应用于与传统深度模型的结合上.Gan等[14]提出了具有注意力机制的CNN-BiLSTM模型,采用多通道扩展联合结构,既能提取原始上下文特征,也能提取高层多尺度上下文特征,在多个数据集上准确率都有明显提升,但其模型架构复杂,需要多通道CNN-BiLSTM进行特征提取.Wu等[15]提出了基于字向量表示方法,同时引入了BiLSTM和注意力机制,有效地解决了分词不精确以及注意力参数依赖问题.Huang等[16]针对隐式情感分析任务,提出了ERNIE2.0-BiLSTM-Attention模型,能较好地捕捉隐式情感文本的上下文语义.以上模型无法很好地对完整上下文进行语义建模,导致获取的情感特征不够丰富;注意力机制仅用于特征提取完成后对重要特征分配更高权重,且由于BiLSTM的循环依赖机制,模型整体训练速度也会降低.
综上所述,本文提出了结合ALBERT和BiFASRU-AT的情感分析模型,主要贡献和创新点概括如下:
1)本文使用ALBERT模型获取动态词向量,解决静态词向量无法表示多义词问题;同时由于其轻量化的特点,适合于大规模部署,具有工程上的应用优势.
2)针对CNN、BiLSTM获取上下文语义不充分的问题,提出了双向内置快速注意力简单循环单元,在对完整上下文进行建模的同时,内置注意力可以更好地关注到词与词之间的依赖关系.双向内置快速注意力简单循环单元摆脱了对上一个时间步输出的依赖,实现了高速并行化计算.利用注意力机制重点聚焦于对情感分类更为关键的特征.
3)为了降低注意力计算的时间和空间复杂度,将原来的标准注意力替换成快速注意力,有效地解决了BiLSTM训练速度慢的问题.
2 相关技术
2.1 ALBERT模型
ALBERT为降低参数量和增强语义理解能力,引入了词嵌入矩阵分解和跨层参数共享策略,并使用SOP(Sentence Order Prediction)任务替换原先的NSP(Next Sentence Prediction)任务.模型结构如图1所示.E1,E2,…,En表示文本序列中的词.T1,T2,…,Tn为得到的文本特征向量表示.
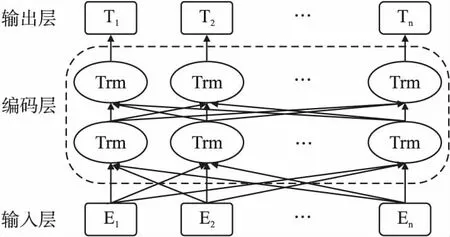
图1 ALBERT模型结构图Fig.1 Structure of ALBERT model
2.2 简单循环单元
LSTM和GRU的出现有效地解决了传统RNN存在的梯度消失和长期依赖问题,但无法并行计算,导致模型训练效率低.简单循环单元[17](Simple Recurrent Unit,SRU)在保持LSTM高效建模能力的同时,摆脱了对上一个时间状态的依赖,实现了高速并行化,有效降低了建模时间.单层SRU计算如式(1)至式(4).
ft=σ(Wtxt+vf⊙ct-1+bf)
(1)
ct=ft⊙ct-1+(1-ft)⊙(Wxt)
(2)
rt=σ(Wrxt+vr⊙ct-1+br)
(3)
ht=rt⊙ct+(1-rt)⊙xt
(4)
其中,⊙表示矩阵对应元素的乘法运算,Wt、Wr和W是参数矩阵,bf、br、vf和vr是训练过程中需要学习的参数向量.SRU将Wt、Wr和W合并进行矩阵乘法,并将其放置在串行循环外,降低了内循环的计算量.为提高建模能力,式(1)、式(3)中分别引入vf⊙ct-1和vr⊙ct-1,使状态向量的每个维度独立化,便于并行化处理.ht计算不再依赖前一个时间状态ht-1,可通过高速网络实现层之间的跳过连接来得到最终输出状态ht,实现并行加速.
3 结合ALBERT和BiFASRU-AT的情感分析模型
3.1 模型网络结构
结合ALBERT和BiFASRU-AT的情感分析模型结构如图2所示,由数据预处理、词嵌入层、双向内置快速注意力简单循环单元层、注意力层、线性层和Softmax层组成.
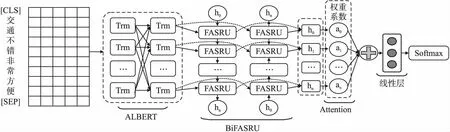
图2 完整模型结构图Fig.2 Overall structure of the model
3.1.1 数据预处理
由于数据集文本可能存在较多无用的特殊字符,例如标点符号、表情等,使用正则表达式进行数据清洗,得到具有语义的字.然后使用分词器对文本进行字符级别的分词,并去除停用词,再通过词汇表对字符进行序列化,对不存在的字符使用[UNK]替代;同时在文本前后加入句向量[CLS]和分句标志[SEP];最后字符向量作为ALBERT模型的输入之一,训练完成会得到融合上下文语境的动态词向量表示.
3.1.2 词嵌入层
ALBERT预训练模型作为词嵌入层,通过自注意力机制关注到当前词对其他词的重要程度,能够得到表征能力更强的动态词向量.输入向量E1,E2,…,En由字符向量、位置向量和分句向量构成,其形成过程如图3所示.
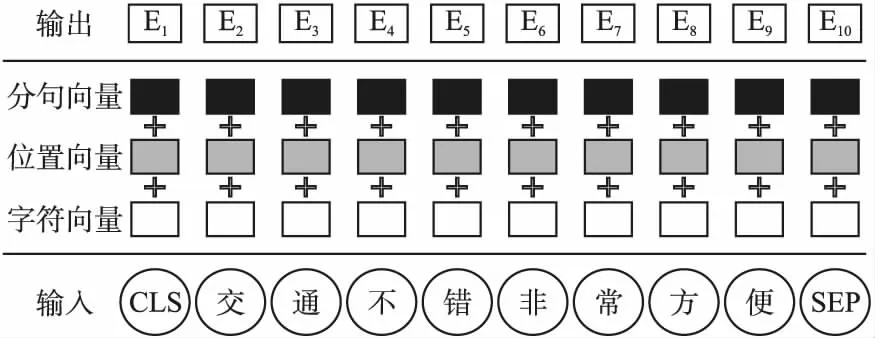
图3 输入向量结构图Fig.3 Structure of the input vector
其中,第一个向量为[CLS],可用于下游分类任务.分句向量[SEP]是标记不同句子的分隔符,由于本文是句子级别文本情感分析,因此使用一个分句向量.字符向量是字的静态编码.位置向量为字加入位置信息,为Transformer提供时序信息.
3.1.3 BiFASRU上下文语义提取层和注意力层
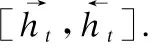
然后将输出Ht送入注意力机制层,计算当前词对其他词的重要程度,捕获词之间的语法和语义特征,使模型聚焦于对情感分类贡献大的关键特征,有助于提升模型分类性能.注意力计算如式(5)-式(7).其中,Wg为可学习参数矩阵,tanh(·)函数为对ut加入非线性因素;再进行权重因子的计算得到αt,最后将t时刻的输出Ht与相应权重αt相乘求和后得到注意力表示V,exp(·)为指数运算.
ut=tanh(WgHt+bj)
(5)
(6)
(7)
通过注意力层得到特征向量V,对V进行降维操作,利用Softmax(·)函数对线性层输出做归一化操作,得到句子级别情感极性概率分布Ps,由top()函数取最大值对应的标签值为情感分类结果Prediction,如式(8)和式(9)所示.
Ps=Softmax(WsV+bs)
(8)
Prediction=top(Ps)
(9)
3.2 快速注意力机制
Transformer的核心模块是自注意力层和前馈神经网络,自注意力机制可将序列中任意两个位置之间的距离缩小为一个常量,解决了长期依赖问题.但随着输入序列长度的增加,算力和内存消耗是输入序列长度的平方,存在复杂度二次增长问题,为此Choromanski等[18]提出了快速注意力机制.通过正随机特征实现快速注意力算法分解注意力矩阵,然后重新排列矩阵乘法顺序,以对标准注意力机制的结果进行近似,避免了显示构建注意力矩阵.过程如图4所示.时间和空间复杂度变化如公式(10)和式(11).
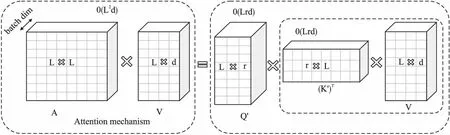
图4 快速注意力机制图Fig.4 Fast attention mechanism
其中,左边是标准注意力机制计算,由注意力矩阵A与值矩阵V计算得到结果.右边是快速注意力机制计算过程,对A进行分解得到解耦矩阵Q′和K′,按照虚线框表示的顺序进行矩阵乘法,得到可线性扩展的快速注意力.当r≪L和L≫d时,可降低时间和空间复杂度.
O(L2d)→O(Lrd)
(10)
O(L2+Ld)→O(Lr+rd+Ld)
(11)
3.3 双向内置快速注意力简单循环单元模型
内置注意力简单循环单元[19](SRU++)注意力层使用缩放点积注意力,计算过程如式(12)至式(16).输入序列长度增加时,计算和存储注意力矩阵导致时间和空间复杂度二次增长.
Q=WqXT
(12)
K=WkQ
(13)
V=WvQ
(14)
(15)
UT=Wo(Q+α·A)
(16)
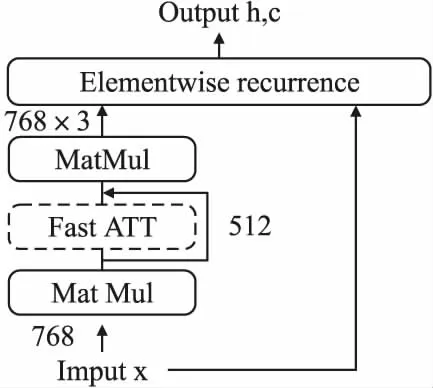
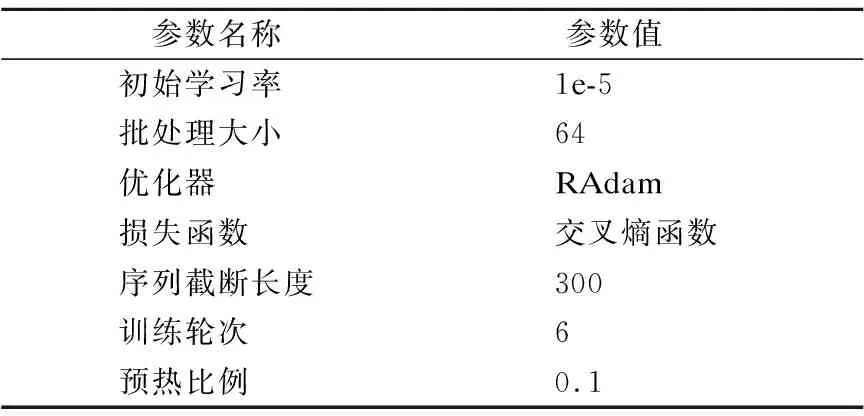
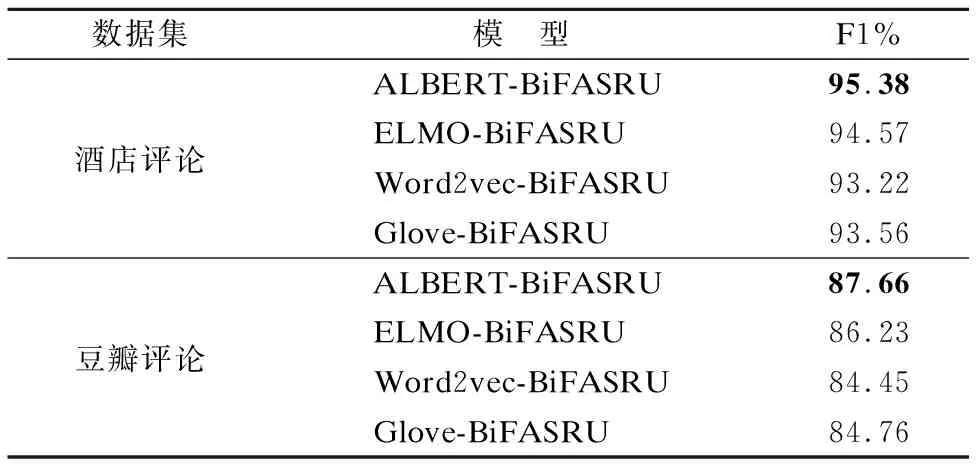
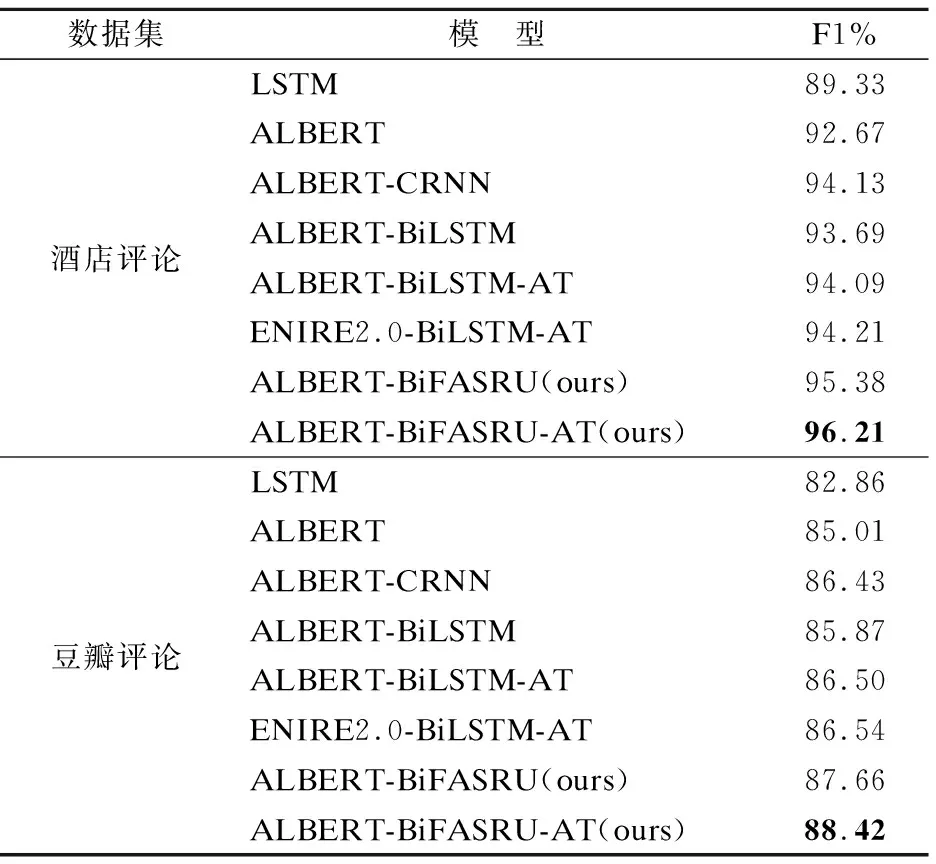
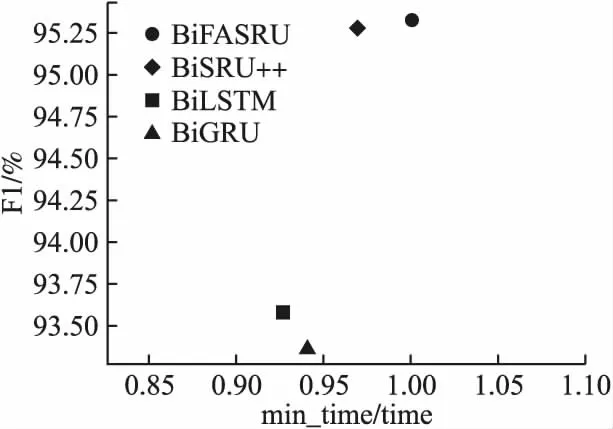
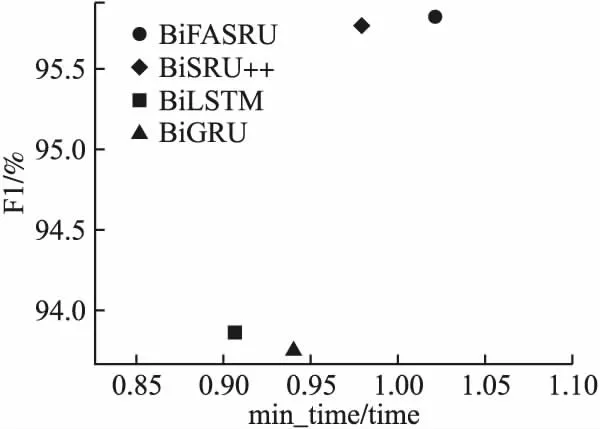
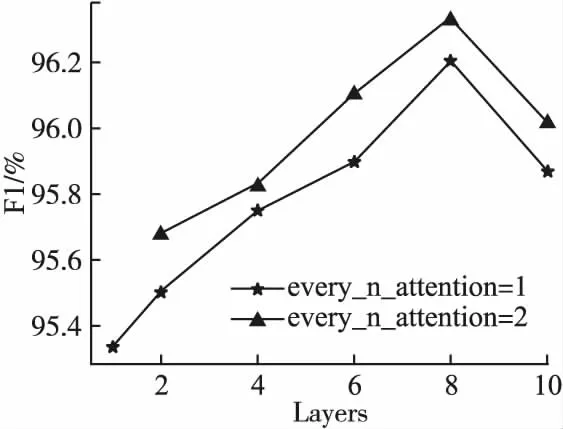
其中,X∈RL×d为输入文本表示向量,L为句子长度,d是词向量维度;Wq∈Rd′×d,Wk∈Rd′×d′,Wv∈Rd′×d′均为参数矩阵,d′是注意力维度,且d′ 针对缩放点积注意力计算复杂度高的问题,引入快速注意力,提出了内置快速注意力简单循环单元.模型结构如图5所示. 其中,768为输入维度,512为注意力维度.针对公式(15)中显式计算和储存注意力矩阵,导致时间和空间复杂度二次增长问题,使用随机特征函数Ø(u)方法对矩阵QTK进行分解,得到Q′和K′,再调整Q′、K′和VT的矩阵乘法运算顺序,调整后顺序为Q′((K′)TVT),避免显式计算和存储注意力矩阵,降低了时间和空间复杂度.计算过程如式(17)至式(20). (17) Kernel(x,y)=E[Ø(x)TØ(y)] (18) A=D-1Q′((K′)TVT) (19) D=diag(Q′((K′)T1L)) (20) 图5 FASRU模型结构图Fig.5 Structure of the FASRU model O(L2d′)→O(Lrd′) (21) O(L2+Ld′)→O(Lr+rd′+Ld′) (22) (23) 为评价模型的有效性,采用中文酒店评论和豆瓣评论数据集[20]进行验证.酒店评论数据集被划分为训练集9600条、测试集1200条和验证集1200条.训练集消极样本共4801条,积极样本共4799条.豆瓣评论数据集被划分为训练集20000条、测试集10000条和验证集10000条,训练集消极样本共10219条,积极样本共9781条.由于训练集各类情感样本数量不平衡会导致分类器偏向样本多的类别,降低了分类器综合性能,因此训练集中各类情感样本数量基本相等. 为验证模型的有效性,评价标准为准确率(Precision)、召回率(Recall)和F1得分,计算过程如式(24)至式(26). (24) (25) (26) 本文实验环境参数如表1所示. 表1 实验环境参数表Table 1 Experimental environment parameters table 经过多次实验对比后,模型选取参数如下:为防止模型过拟合,训练阶段dropout为0.3;BiFASRU隐藏层维度为256,投影层维度为512,注意力维度512. 表2 综合模型训练参数表Table 2 Training parameters of integrated model table 模型训练参数如表2所示.其中,序列截断长度为样本平均长度加上两倍样本长度的标准差,涵盖了大部分的样本长度,降低样本语义损失.为避免学习率大小的复杂调整过程,使用RAdam[21]优化器,能够自适应调整学习率的大小. 为了验证本文提出模型ALBERT-BiFASRU-AT的有效性,本小节将此模型与经典模型、近期基于ALBERT的深度学习模型和表现较好的模型,分别在酒店评论和豆瓣评论数据集进行对比.ALBERT模型均采用Google发布的中文Base版本ALBERT.与本文提出模型进行对比的模型如下: 1)LSTM:LSTM[15]模型,隐藏层维度为256,使用300维度的Word2vec[1]工具进行文本向量表示. 2)ALBERT:ALBERT[6]预训练模型,利用最后一层输出的句向量[CLS]进行分类,隐藏层维度为768. 3)ALBERT-CRNN:基于ALBERT的多尺度卷积叠加双向门控循环单元模型[2],可同时关注上下文和局部情感信息.卷积核为(2,3,4),通道数量均为128,BiGRU隐藏层维度为256. 4)ALBERT-BiSLTM:通过ALBERT得到文本动态向量表示;将实验1中LSTM叠加正反向层,形成双向长短期记忆网络模型,可捕获词在正反方向的情感语义. 5)ALBERT-BiSLTM-AT:在实验4的基础上,加入注意力机制,赋予模型聚焦关键特征的能力. 6)ENIRE2.0-BiLSTM-AT:ENIRE2.0-BiLSTM-AT隐式情感分析模型[16],ENIRE2.0为词嵌入层,BiLSTM隐藏维度为256. 为确保实验的可对比性,降低随机误差,设定随机数种子,取10次冷启动实验的平均结果作为最终实验结果. 4.4.1 文本向量表示分析 本小节采用ALBERT、Glove、ELMO和Word2vec这4种不同词向量模型,在酒店评论和豆瓣评论数据集合上做情感分类对比实验,目的是验证ALBERT作为词嵌入层的合理性.结果如表3所示. 表3 基于不同词向量模型对比表Table 3 Comparison of F1 values using different word vectors 由表3可知,在两组数据集上使用ALBERT作为词嵌入层的模型,均取得了最高的F1分数.ALBERT和ELMO均能动态表示词向量,根据下游任务对词向量语义进行微调,融合特定领域知识,解决一词多义问题,并得到特征更加丰富的词向量.相对于静态词向量Word2vec和Glove,F1得分均提升明显.Glove是基于全局词频统计的词表征工具,而Word2vec没有充分利用全部语料,因此Glove应用效果优于Word2vec.虽然ELMO和ALBERT都是动态词向量模型,但ELMO使用双向LSTM动态计算一个词在上下文的语义向量,而ALBERT使用特征提取能力更强的Transformer模块,因此ALBERT应用效果优于ELMO. 4.4.2 分类模型对比分析 本文分类模型与其他模型对比结果如表4所示.由表4可知,本文提出模型F1值在两个数据集中均是最高,高于近期表现较好的ALBERT-CRNN和ENIRE2.0-BiLSTM-AT模型,证明了模型架构的有效性.实验模型ALBERT-CRNN、ALBERT-BiLSTM和ALBERT-BiFASRU,二次情感特征抽取模型分别是CRNN、BiLSTM和BiFASRU,本文模型ALBERT-BiFASRU的F1值最高,说明了BiFASRU能全面提取句子上下文语义,内置注意力机制捕捉句子内部词依赖关系,有助于提升分类性能.BiLSTM仅能够提取上下文语义,而CRNN在进行多尺度卷积后再进行循环训练,其卷积过程存在一定的语义损失.实验模型ALBERT-BiLSTM-AT和ALBERT-BiFASRU-AT对比也再次证明了BiFASRU的特征提取能力优于BiLSTM.为验证AT模块的作用,设置实验ALBERT-BiFASRU和ALBERT-BiFASRU-AT对比,可看出AT模块能够聚焦关键特征的特点,提升了模型性能.相对于ALBERT利用句向量进行分类,加入二次特征提取模块如BiFASRU,可明显提升分类性能. 表4 分类模型对比结果表Table 4 Ablation study of classification models 4.4.3 BiFASRU与其他循环模型对比分析 验证其相对其他传统循环模型在深度学习中的优势,故采用了BiSRU++、BiGRU和BiLSTM作为对比,均使用ALBERT作为词嵌入层,且确保其他超参数一致.实验采用酒店评论数据集,结果如图6和图7所示.其中,横坐标为最小平均轮次训练时间(min_time)/平均轮次训练时间(time),因此平均轮次时间小的模型横坐标值更大,最大为1.0.纵坐标为F1值,用于评价模型性能,F1值越高代表模型越好.因此位于右上方的模型综合评价高. 图6 1层时模型综合评价图Fig.6 Comprehensive evaluation of 1 layer 图7 4层时模型综合评价图Fig.7 Comprehensive evaluation of 4 layers 由图6和图7可知,BiFASRU综合模型评价高于其他3种循环模型,证明BiFASRU在深度学习中有着更好的实用性.BiFASRU与BiSRU++F1值相差不大,受限于输入序列长度,训练速度加速不十分明显,但均位于BiSRU++模型的右上方,说明了快速注意力可有效提升标准注意力机制的计算速度.而相对于BiLSTM,由于BiGRU门结构简化和总参数量降低,因此训练速度更快,但F1值略有降低.相比BiLSTM和BiGRU,由于并行化处理和内置快速注意力机制,BiFASRU的训练速度和模型性能都有较大提升. 4.4.4 BiFASRU层数影响实验分析 为了验证BiFASRU层数对模型效果的影响,基于酒店评论数据集进行了实验.在不同层数下进行对比,分别为1、2、4、6、8和10层,以及为验证内置注意力机制的有效性,每1或2层内置注意力机制,every_n_attention表示每n层内置快速注意力.其结果如图8所示. 图8 不同层数下内置注意力机制的有效性Fig.8 Effectiveness of built-in attention in different layers 由图8可知,模型层数小于8时,随着层数叠加,F1值持续增加,最高为96.33%;当层数达到10层时,效果反而变差,出现了模型退化现象,说明了模型层数不宜过多,需要根据任务情况适当选择模型深度,也可使用残差连接来防止模型退化.同时,every_n_attention为1时,即每层都内置注意力机制,其F1值比every_n_attention=2时低,说明了注意力机制并不是越多效果越好,较少的注意力反而能提升模型的泛化能力,从而提高F1值. 本文提出了结合ALBERT和BiFASRU-AT的情感分析模型(ALBERT-BiFASRU-AT),在两个评论数据集上验证了模型的有效性.相对于静态词向量工具,ALBERT赋予词符合上下文语境的动态语义,解决了评论数据集中一词多义问题,使用ALBERT进行文本向量表示,效果优于ELMO和静态词向量工具.相对于CNN、BiLSTM,本文提出的BiFASRU-AT模型可抽取上下文完整语义和关注句子内部词依赖关系,对关键特征分配更多权重,提升情感分类准确性,在训练速度上也优于其他循环模型.内置注意力机制的循环模型在应用效果上优于一般的循环模型,层数则需要根据任务特点适当选择.本文仅在句子级别情感分类任务进行实验,在接下来的工作中,将尝试将模型应用到方面级别的情感任务中.受序列长度限制,模型训练加速有限,未来也会将模型应用到长序列任务.并考虑采用ENIRE2.0、GPT等预训练模型,得到特征更丰富的文本向量表示.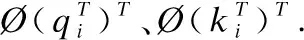
4 实验分析
4.1 数据集与评价标准
4.2 实验环境与参数选取

4.3 模型对比实验设计
4.4 实验结果分析
5 结束语
