融合LSTM的自然语言转结构化查询语句算法的研究与设计
2023-01-31黄瓯严
孙 红,黄瓯严
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
在大数据时代,数据库和SQL语言已经渗透到各行各业,如何使非技术人员使用自然语言从数据库中找到相应的信息就成为了一个非常重要的课题.因此,自然语言转结构化查询语句(Natural Language to SQL,NL2SQL)任务应运而生.
早期的流水线方法就是将用户提出的自然语言问题通过模型转化为一种中间表达,再将中间表达映射为相应的结构化查询语句.孟小峰等人[1]提出的NChiql使用语义依存树实现从自然语言到SQL语言的转化;Unger等人[2]在2012年提出一种基于SPARQL查询范本和WordNet填充的方案;Li等人[3]在 2016 年提出一种基于“解析树”的中间表达,需要用户交互选择最终结果,系统自动化程度低;Baik等人[4]在2019年提出了TEMPLAR系统,只使用SQL语句的历史查询日志,没有使用查询自然语言的描述,减少人工标注工作;Yin等人[5]针对复杂场景提出使用语法生成树来提高模型的泛化能力.
基于流水线的方法有一定的局限性,如严重依赖于模板和手动设计的特征、对用户语言的解析不够灵活等.而基于深度学习的方法不再需要将用户提出的自然语言问题通过模型转化为中间表达,可以减少转化时所产生的信息的丢失,并且不需要手工提取特征,能有效弥补流水线方法的局限性.Wang等人[6]使用Seq2Seq+Copying模型,通过复制机制定位到输入自然语言问题的其中一部分,将其直接作为结构化查询语句的部分输出,但这种方法可能会存在语法错误;对此,Xu等人[7]在2017年提出了一个名为SQLNet的模型,通过填充预先定义好SQL查询的模板能大幅度减少输出SQL查询的语法错误,提高准确度.
深度学习模型需要大量的自然语言查询与SQL查询的配对标注工作,预训练模型可以很好地解决这个问题.随着ELMO[8](Embedding from Language Models)、GPT[9]、BERT[10](Bidirectional Encoder Representations from Transformers)等预训练语言模型在NLP任务上取得更好的结果,并在这些模型的基础上催生出了一些新方法,如RoBERTa[11]、XLNet[12]、ERNIE[13]、FastBERT[14]、MobileBERT[15]、MTL-BERT[16]等.
He等人[17]提出了X-SQL模型,该模型利用MT-DNN预训练模型对自然语言查询和数据库模式进行特征提取来提升准确度.Yu等人[18]提出的TypeSQL模型将Seq2Seq模型的方式转换成为了插槽的方式,最大限度地融合了文本信息.Yu等人[19]提出了SyntaxSQLNet模型,该模型针对Spider数据集,引入结构性信息,通过数据增强的方式提升准确率.Ben等人[20]提出了Global-GNN模型,该模型利用关系数据库的结构信息,使用全局信息重新调整序列的方式对模型进行优化.Wang等人[21]提出了RAT-SQL模型,该模型将自然语言问句、表格信息以及表格列名同时建模,利用字符串匹配的方法提升模型效果.Yin等人[22]提出了TaBERT模型,联合自然语言问句和结构化的表格数据进行建模,采用弱监督的方式提升模型效果.
本文提出了一种融合LSTM的自然语言转结构化查询语句模型,解决了现有模型存在的无法捕捉各类别间依赖和自然语言问句与数据表格中的数据不一致的问题.实验结果表明本文提出的算法在分类模型和条件值模型两个子任务上都要远优于其他对比算法模型,完整模型的平均准确率达到82.8%.
2 相关工作
2.1 SQLNet模型结构
SQLNet模型将一个自然语言问句所对应的SQL语句分解为SELECT子句和WHERE子句两部分,使用序列到集合(Sequence-to-set)的方法解决WHERE子句中的条件顺序无关的问题.SQL语句的解耦方式如图1所示.
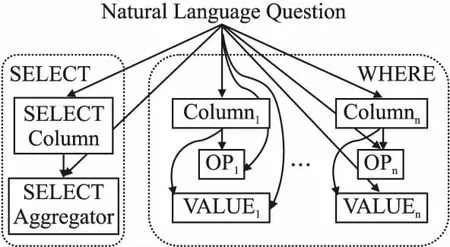
图1 SQLNet中的SQL语句解耦图Fig.1 SQL decoupling diagram in SQLNet
SQLNet模型对每一个子部分的模型构建相似,以对WHERE子句中的列WHERE-Column进行预测为例,模型结构如图2所示.其中LSTM_q表示自然语言问句经过的LSTM网络,LSTM_c表示表格列名经过的LSTM网络,这两个LSTM网络不共享参数.LSTM_qc表示两个网络最后一个隐层输出的拼接.
2.2 改进的SQLNet模型结构
SQLNet模型中的各个分类子模型在编码阶段采用了自然语言问句和数据表格中的列两部分分开编码的方式,分别经过BiLSTM网络编码,再将各自的隐层状态拼接用于后续分类任务.这种使用两个神经网络编码的方式,切断了自然语言问句和数据表格列的内在联系.针对上述问题,本文采用预训练语言模型对输入数据进行编码,使用单个编码模型替代两个编码模型的方式.
预训练语言模型使用大量通用领域数据对模型进行预训练,使模型具备通用领域的知识,能够区分不同的特征.预训练语言模型使用SEP分隔符来分隔句子输入,本文将列名作为单个句子,对输入进行改造后的SQLNet模型如图3所示.
此外,本文对损失函数进行了改进,在对SELECT子句和WHERE子句的列名进行训练时,由于只有少数的列会被选中作为正例,大多数的列都是负例,数据中存在非常严重的类别不平衡问题.本文针对上述问题对相应分类问题的交叉熵损失函数做出修正,修正结果如公式(1)所示.
(1)
其中Loss为对SELECT子句和WHERE子句的列名分类的损失函数.y′表示模型的输出结果,y表示真实标签结果,表示第i个模型,α为正样本所附带的权重,用来平衡正负样本不均衡的问题,本文根据经验值取α=2.
3 系统框架
与改进SQLNet模型将NL2SQL单任务解耦成多任务的设计思路类似,本文提出了一种融合LSTM的自然语言转结构化查询语句模型,将自然语言转结构化查询语句问题分解成两个子问题,分别提出分类模型和条件值模型.
3.1 融合LSTM的自然语言转结构化查询语句
本节将NL2SQL单任务解耦成分类模型和条件值模型两部分任务,其中分类模型对WHERE子句的条件值VAL之外的其他部分进行预测.以条件间的关系cond_conn_op为例,条件间的取值只存在{0:"",1:"and",2:"or"}3种,因此将其作为分类问题来进行处理.条件值模型则是对WHERE子句的条件值VAL进行预测,由于条件值VAL存在数值和文本两种类型数据,与其他部分不同,需要单独处理.模型结构如图4所示.
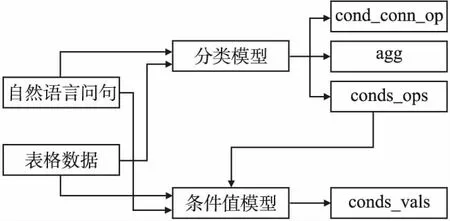
图4 融合LSTM的NL2SQL模型结构图Fig.4 Diagram of NL2SQL model fused with LSTM
3.2 分类模型
在自然语言转结构化查询语句的任务中,模型输出对应一个完整的SQL语句,本文将模型输出的SQL语句分解成SELECT子句与WHERE子句两部分,与SQLNet模型相似,定义了SQL语句输出的模版,通过填槽的方式实现对应槽位的填充,模版如图5所示.
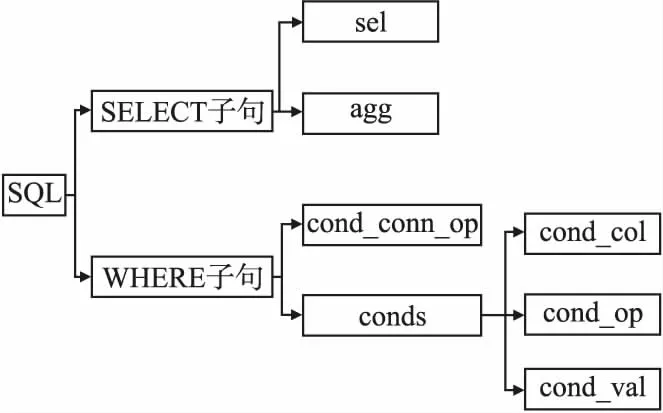
图5 SQL语句输出模版图Fig.5 SQL statement output template map
除了条件值cond_val之外,其它槽位的填充的取值都是有限的,因此可以将其余部分都作为分类任务来进行处理.在处理过程中,模型首先将输出映射为一个n维向量,其中n为每个分类任务所对应的类别数量,再使用softmax函数计算每个类别所对应的概率大小,最大概率所对应的类别即为模型预测的结果.
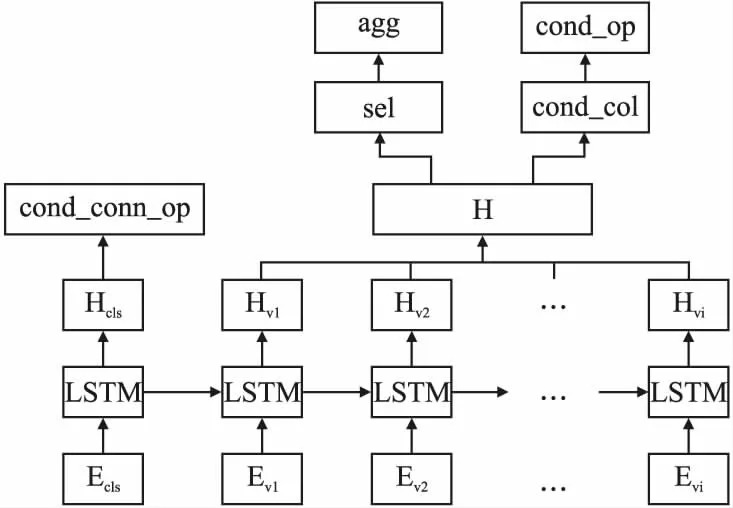
图6 分类模型结构图Fig.6 Classification model structure diagram
输入向量首先使用预训练模型处理,然后通过LSTM长短时记忆网络可以得到输入隐层状态HCLS和每一列的对应编码向量隐层状态HVi,之后再对各个槽位填充进行分类,如图6所示.在SELECT子句中,数据表中选择的列sel和列之间的聚合操作agg存在着对应关系,模型只会对被选中的列进行聚合操作,因此在模型预测时sel和agg的结果将会同时得到.在WHERE子句中,同理条件列cond_col和条件比较符cond_op也存在一一对应的关系,处理方法和sel与agg相同.HCLS隐层状态向量是对完整输入编码的表达,包含Question和每一列COL的语义信息,用于预测WHERE子句中各个条件列之间的关系cond_conn_op.
3.3 条件值模型
在完成分类任务之后,为了得到完整SQL的预测语句,还需要对WHERE子句的条件值cond_val进行预测.但自然语言灵活性较高,简单的指针网络无法实现判别同义词.针对自然语言描述与表格数据描述不一致的问题,本文采取不同的方式分别对文本类型数据和数值类型数据进行处理.
3.3.1 文本类型数据的处理
对于文本数据的相似表达,本文选择条件比较符“=”将相近词构造为一个候选条件Candidate,如:“腾讯=鹅厂”等.
3.3.2 数值类型数据的处理
对自然语言中数值表达不规范问题,本文使用正则表达式对所有语句进行标准化处理,如17年标准化后为2017年.
之后,将预处理过的输入文本送入预训练语言模型进行编码.由于每一列都会作为候选值送入模型,不需要捕捉上下文之间的关系,在条件值模型中不用经过LSTM网络处理,使用编码得到的输入编码向量ECLS分类即可.分类目标为该候选条件Candidate是否为WHERE子句中的条件,模型结构如图7所示.
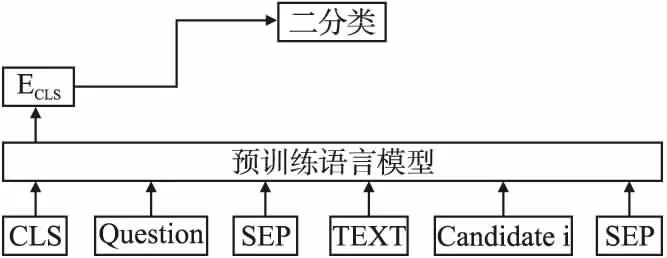
图7 条件值模型图Fig.7 Conditional value model diagram
3.4 目标函数
由于分类模型和条件值模型的最终目的是分类,本文使用分类任务常用的交叉熵损失函数作为每个分类任务的目标函数,而模型的目标函数即所有分类任务目标函数之和,本文的模型优化方向是最小化该目标函数,如公式(2)所示:
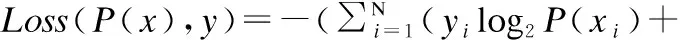
(2)
其中xi表示第i个类别的输入,yi表示第i个类别的真实标签,P(xi)表示第i个类别的模型预测输出结果,N表示类别总数.
4 实验结果与分析
4.1 数据集
NL2SQL数据集是一个公开的数据集,由追一科技在2019年和天池共同举办的首届NL2SQL挑战赛中提出,主要使用金融以及通用领域的表格数据作为数据源,并以这些表格为基础标注自然语言与SQL语句的匹配对,该数据集的诞生主要是为了中文的自然语言转结构化查询语句研究.数据集收集了4万条有标签数据作为训练集,1万条无标签数据作为测试集.
4.2 实验结果分析
实验1.分类模型实验结果
在分类模型实验中,各个模型的分类结果见表1.其中,sel表示SELECT子句中的条件列,agg表示sel选中的条件列之间的聚合操作,cond_col表示WHERE子句中的条件列,cond_op表示WHERE子句中对应条件列cond_col的条件比较符,cond_conn_op表示WHERE子句中各个条件之间的关系.
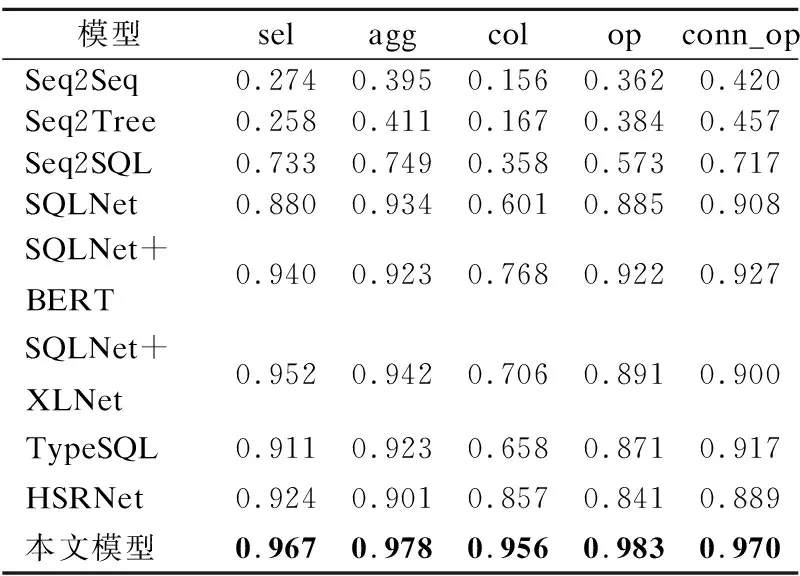
表1 各个子分类模型准确率Table 1 Accuracy of each sub-classification model
从实验结果来看相较于SQLNet等模型使用BiLSTM进行编码,本文使用了近年来被验证效果最佳的BERT预训练语言模型进行编码,对于文本特征的提取能力有大幅提升.同时这也充分说明在预训练语言模型编码之后加入LSTM捕捉特征的有效性,加入LSTM优化后的模型性能得到大幅提升.
实验2.条件值模型实验结果
在条件值模型中,对于文本类型条件值,本文将数据中出现的25个表达不一致的高频词进行统一替换;对于数值类型条件值,本文将自然语言问句中所用的中文数字表达替换为阿拉伯数字,并对不同的年月份表达进行标准化处理.
本实验中对比了不同模型中条件值的准确率,依次来分析对文本数据和数值数据单独处理的有效性.表2中第2列数值类型+文本类型表示对应的某条SQL语句中既包含数值类型条件值,也包含文本类型条件值.条件值模型结果如表2所示.

表2 各个算法条件值模型准确率Table 2 Accuracy of each algorithm condition value model
从结果可以看出自然语言问句经过本文的模型能够得到最好的效果,这是因为首先在第一阶段的分类任务上,本文提出的分类模型能够达到非常高的准确率,其次与其他对比模型使用的指针网络不同,本文将文本类型条件值和数值类型条件值采取不同的方式处理,解决了自然语言问句与表格数据中的条件值经常存在的无法对齐的问题.
实验3.完整模型实验结果
在完成分类模型与条件值模型之后,本文将得到的结果进行融合,通过填槽得到转化之后完整的SQL语句,使用逻辑准确率(Logic Form Accuracy)和执行准确率(Execution Accuracy)作为评价指标用来验证最终的模型效果,实验结果如表3所示.表3中第4列平均准确率表示逻辑准确率和执行准确率的平均值.
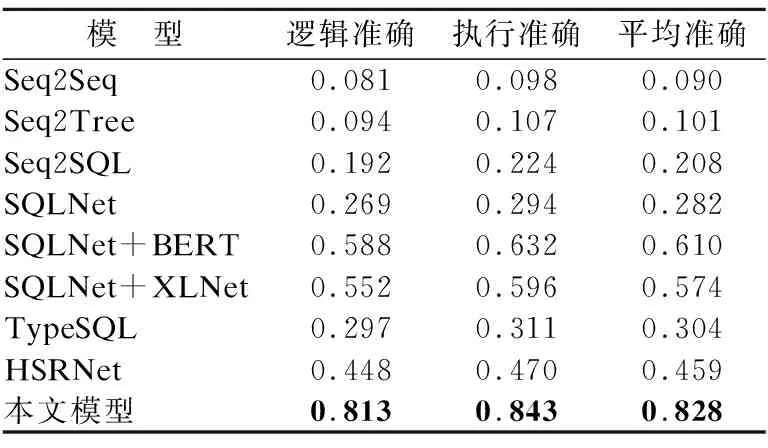
表3 自然语言转结构化查询语句实验结果表Table 3 NL2SQL experimental result table
从结果来看,本文所提出的模型在上述的指标上都要优于其他对比模型,比对比模型中效果最好的SQLNet+BERT模型平均准确率高出21.8%.这是因为本文使用了预训练语言模型并做了微调,使模型在编码阶段能得到更好的特征.此外,本文在分类模型和条件值模型的各个类别的准确率上效果也有很大提升,这主要得益于文中提出的正则匹配等文字对齐优化处理.
实验4.消融实验结果
其中基线BERT模型使用BERT-wwm-ext,微调数据量表示对基线模型微调所使用的数据量,其中BERT+TAPT使用了任务中所使用的全部自然语言问句.

表4 预训练语言模型微调结果表Table 4 Pre-trained language model fine-tuning result table
由表4知,本文对预训练语言模型进行微调能够大幅提高完整模型的效果,BERT模型在领域自适应模型微调(DAPT)中可以看出,随着微调数据量的增加,完整模型的平均准确率也相应的得到提高,在使用461M领域数据微调模型时平均准确率达到最大值82.8%,当微调数据量继续增加到847M时,平均准确率趋于饱和,微调数据量与平均准确率之间的关系如图8所示.
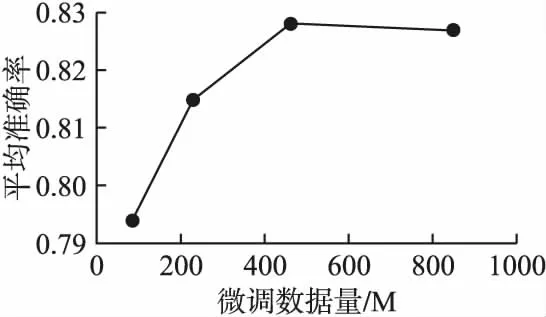
图8 微调数据量与平均准确率关系图Fig.8 Relationship between the fine-tuned data and the average accuracy
BERT模型在任务自适应模型微调(TAPT)中可以看出,预训练语言模型在少量(23M)的任务数据上进行微调即可达到在领域自适应模型微调(DAPT)中使用228M数据的效果,然而由于任务能够使用的数据量有限,只有23M数据能够使用,限制了模型效果的进一步提升.
5 结 论
本文主要是对NL2SQL中文公开数据集自然语言转结构化查询语句的研究,主要创新点在于提出了一种基于改进的SQLNet模型以及一种基于LSTM的自然语言转结构化查询语句.本文所做的主要工作如下:
1)提出了基于SQLNet的自然语言转结构化查询语句改进模型.本文首先对SQLNet所用的编码方式进行了改进,采用最新的预训练语言模型替换SQLNet所使用的双向长短时记忆网络,充分利用了预训练语言模型对特征的表征能力.然后对模型所使用的损失函数进行了修正,解决了在对列名预测时所产生的严重的类别不平衡问题.并通过实验证明了上述改进能够提升SQL语句的预测准确率.
2)提出了融合LSTM的自然语言转结构化查询语句模型.本文首先通过对预训练语言模型进行微调的方式提高特征在目标任务上的表达能力.然后提出了将模型解耦为分类模型和条件值模型来生成SQL语句,其中分类模型部分经过预训练语言模型编码之后,再经过LSTM对各类别之间的依赖关系进行捕捉,提升了SQL语句的预测准确率;本文在对条件值模型处理的过程中,对文本类型和数值类型分别进行处理,文本类型条件值从数据表格中取值并进行判断,数值类型条件值从自然语言问句中获取,由此解决了自然语言问句与数据表格中的数据不一致的问题.
3)通过对比实验验证本文提出的模型的有效性,并通过消融实验分析模型中各个对模型的贡献.实验结果表明,本文提出的方法在分类模型和条件值模型两个子任务上都要远优于对比算法模型,完整模型的平均准确率最高,说明了本文提出的模型能够产生更准确的预测.
