面向故障间格兰杰因果发现的霍克斯过程研究
2023-01-27蔡瑞初吴思宇乔杰
蔡瑞初,吴思宇,乔杰
(广东工业大学 计算机学院,广州 510006)
0 概述
故障事件序列由连续时间下的离散事件组成,常以服务器状态日志、设备运行记录、系统异常告警的形式出现在大型应用程序[1-3]、自动化系统[4-6]、通信网络[7-8]等现实应用场景中。基于故障事件序列数据发现故障之间的格兰杰因果关系,对研究故障机制、预测预防潜在故障[9-10]以及定位故障根因[11-12]等工作有重要的推动作用。以大型的通信网络场景为例,由于具有网络规模巨大、设备类型多样等特点,单点故障极易引发大规模相关故障事件,通过人工难以对大量故障事件进行及时响应和定位根因。因此,基于历史故障事件序列发现网络故障类型之间的因果关系,有助于高效准确地定位告警根因,提高运维效率,降低运维成本。
然而故障事件序列所具有的数据稀疏、信息量少、时间精度低的特点,对现有的格兰杰因果发现算法带来许多挑战。另外,在现实场景的应用中,为了保证算法结果的可靠性,降低线上应用风险,常要求模型算法能够引入一些由专家标注、业务反馈得到的直接、非直接因果结构先验(无环先验、依赖性先验、故障根因标注等),并在此基础上进行格兰杰因果关系发现。因此,如何有效引入结构先验,是实现事件序列因果关系建模落地应用亟需解决的问题。
现有的许多工作被提出用于发现事件序列背后的因果关系,其中包括基于约束的时序快速因果推断算法(time series Fast Causal Inference,tsFCI)[13]、瞬时条件独立彼得-克拉克算法(Peter&Clark algorithm with Momentary Conditional Independence test,PCMCI)[14]、
基于转移熵的方法[15-16]。将这类方法运用到故障事件序列因果发现场景,需要将故障事件序列数据转化为等时间间隔中事件发生次数所组成的时间序列,这导致部分时间数据丢失。另一种更多应用于事件序列的因果发现场景的方法是多变量霍克斯过程[17-19]。这类方法利用点过程建模故障事件序列,利用由基础强度和激发强度构成的强度函数刻画格兰杰因果机制,并利用稀疏正则项对事件间的影响强度参数进行稀疏约束,如乘法交替方向法[10](Alternating Direction Method of Multipliers and Majorization Minimization,ADM4)和基于稀疏群套索正则的最大似然估计算法[8](Maximum Likelihood Estimator with Sparse-Group-Lasso,MLE-SGL)。然而这类方法在优化过程中存在无法有效引入因果先验、剔除间接因果影响、保证稀疏性的问题,使得结果可靠性不足,效果十分依赖于强度阈值的选择。
针对现有模型存在的问题,本文提出一种面向故障序列的格兰杰因果发现的霍克斯过程模型。在霍克斯过程模型基础上,设计基于贝叶斯信息准则(Bayesian Information Criterion,BIC)的两步结构优化算法,用于发掘故障事件序列背后的格兰杰因果关系。基于贝叶斯信息准则构造的目标函数,以ℓ0范数作为稀疏惩罚项,有效隔离间接因果效应,保证结构的稀疏性。为优化这一目标函数,将基于期望最大化(Expectation-Maximization,EM)算法的参数优化模块与基于爬山法的结构搜索模块相结合,提出两步结构优化算法,通过迭代优化格兰杰因果网络参数和结构,在保证优化效率的同时,有效引入因果结构先验,提高模型可靠性。而对于故障运维场景中时间记录精度低的问题,将霍克斯过程模型扩展到离散时间域上,从强度函数和目标函数两个角度,讨论霍克斯模型在离散时间域和连续时间域上的关联。
1 面向故障事件格兰杰因果发现的霍克斯过程
本节将形式化定义本文重点解决的问题,进而从多变量点过程定义出发,介绍霍克斯过程,并给出霍克斯过程下格兰杰因果的定义。
1.1 问题定义
在自动化系统的运维场景中,故障可以抽象为由类型和发生时间表示的事件,因此,系统在一段时间内发生采集到的故障告警记录可以用事件序列形式化地表示。其中:V表示事件类型的集合;T表示事件序列的记录时间范围;(vn,tn)表示第n个事件,其发生在tn时刻,类型为vn。为了方便建模,事件序列可以等价地转化为函数形式,用一个计数函数族C={Cv(t)|t∈T,v∈V}表示。其中:Cv(t)记录了发生在时刻t之前的v类事件的数量;dCv=Cv(t+dt)-Cv(t)。事件类型之间的格兰杰因果结构则能用有向图G=(N,E)表示。其中:E表示因果边的集合。因此,对于这个事件序列的格兰杰因果发现问题,给出如下定义:
定义1利用给定事件序列的观测数据E=发现不同事件类型V背后的因果结构G=(N,E)。
1.2 多变量霍克斯过程
多变量点过程作为一个随机过程模型,常被用于建模刻画多种类型的事件序列之间的影响机制。多变量点过程的建模核心是构造各个事件类型发生的强度函数λv(t):

本文所采用的霍克斯过程[20]是点过程的一种特殊形式,常被用于建模事件之间的相互激发的机制。霍克斯过程考虑了一种特定类型的强度函数,该函数测量过去事件对于当前时刻强度的激发程度,这种激发影响随时间变化而变化,具体形式如下:


在本文中,使用不同衰减系数δk的指数函数作为基函数,即κk(t)=δkexp(-δkt)。
在现实场景中,故障序列数据往往以一定的时间间隔进行采集,如每秒更新一次数据,存在记录精度不够的情况。因此,本文工作还关注离散时域下事件序列的建模。在离散时间域下,T变为一个离散时间域T={0,Δt,2Δt,…,T},其中Tt-={t′|t′∈T,t′≤t-Δt}。因此,事件序列Xv,t=Cv(t+Δt)-Cv(t)可以用时间序列X={Xv,t|v∈V,t∈T}表示,表示时间间隔[t,t+Δt)中事件的发生次数。在这种情况下,给出离散时间域下霍克斯过程模型的扩展,其强度函数的表示形式如下:
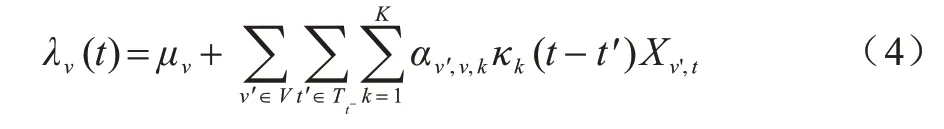
在离散时间域的事件序列建模中,λv(t)表示的是每个时间间隔[t,t+Δt)中的平均强度,Xv,t取值服从期望为λv(t)Δt的泊松分布。而在理想状态下,记录时间精度提高,时间间隔趋近于0,则有Δt→dt,Xv,t→dCv(t),那么离散时间域强度函数(式(4))则会转化为连续时间下的强度函数(式(3))。
1.3 霍克斯过程中的格兰杰因果关系
在文献[21]中,作者对点过程格兰杰因果关系的定义[22],揭示了霍克斯过程的强度函数和格兰杰因果结构之间的关系,具体如下:
定理1假设一个霍克斯过程其条件强度函数如式(2)所示,且满足格兰杰因果结构G=(N,E),则格兰杰因果边v'→v∉E,当且仅当所有t∈T满足ϕv',v(t)=0。
根据定理1 可以进一步得出,在模型(式(3))中,v' 不是v的格兰杰原因当且仅当对于所有k∈{1,2,…,K}满足αv',v,k=0。那么在给定因果结构G=(N,E)下,能够对霍克斯过程的强度函数(式(3))做进一步简化:
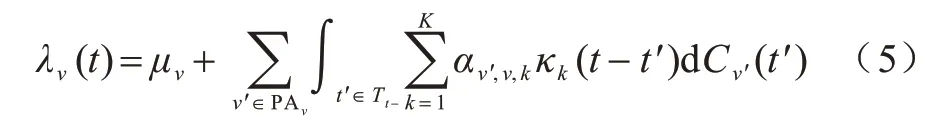
在离散时间域下,强度函数的形式为:
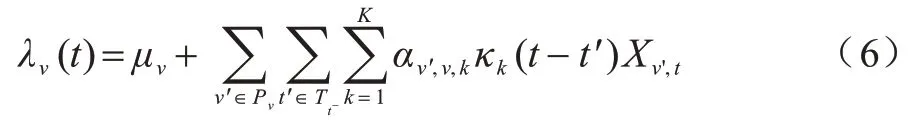
其中:Pv表示给定格兰杰因果结构G=(N,E)下,事件类型v的格兰杰原因事件类型的集合,即v在G中的父节点。
2 霍克斯过程下的贝叶斯评分准则
基于定理1 可知,为了获得合理的因果结构,稀疏性约束是至关重要的。因此,本文在似然度的框架下,基于贝叶斯信息准则构造目标函数,将ℓ0范数作为稀疏惩罚项,以保证结构的稀疏性。
由于在连续时间域下,霍克斯过程的似然函数已经在许多工作中被很好地定义,为了将离散时间域的事件序列建模也引入到本文的模型框架中,本节针对离散时间域,从泊松分布的角度构造似然度函数。在本文模型中,似然度是关于G和Θ的函数,给定事件序列观测数据,对数似然函数如式(7)所示:

进一步地,通过对Δt取极限,令Δt→dt,能够将离散时间域下的似然函数扩展到连续时间域上,从而得到连续时间域下霍克斯过程的似然函数:
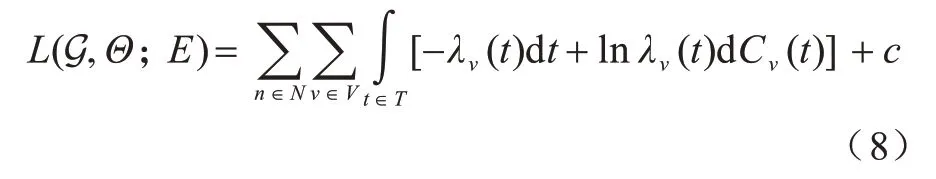
然而只将对数似然函数作为目标函数容易产生过多的冗余因果边。为了保证结构的稀疏性,将贝叶斯信息准则的惩罚项引入本文的目标函数中,从而得到如下目标函数:
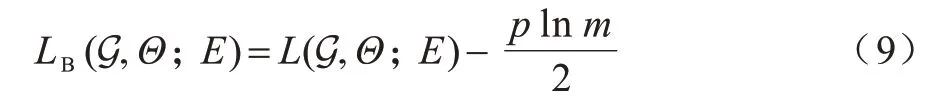
其中:p=|V|+K|E|表示模型的参数数目[23];m表示在T中发生的所有的事件数目。BIC 惩罚项等价于关于模型参数的ℓ0范数正则项。p为参数的ℓ0范数,而正则项的权重能够随样本数目变化而调整,具有更强的适应性。
3 基于EM 和爬山法的两步稀疏优化算法
本节将介绍如何优化上述带ℓ0稀疏约束的目标函数。虽然现有工作针对这一问题已经提出了多种方法,如ADM4 方法采用低秩约束对邻接矩阵进行约束,MLE-SGL 方法进一步引入了对因果强度的稀疏性正则化,但它们的性能很大程度上取决于稀疏性正则化权重的选择或结构剪枝的阈值,并且现有方法存在无法引入直接、间接因果性先验的不足。
针对上述问题,本文提出基于EM 和爬山法的两步稀疏优化算法(Two Step Sparse Optimization,TSSO),迭代进行参数估计和结构搜索的步骤,以保证学到一个稀疏的因果结构,并提供了在结构搜索过程中引入先验信息的方法。算法求解部分可以分为结构评分模块和结构搜索模块。结构评分模块通过给定因果结构,利用EM 优化参数计算结构的BIC评分,即(G,Θ;E);结构搜索模块利用爬山法搜索BIC评分最高的因果结构,即
3.1 格兰杰因果结构评分模块——EM 算法
在格兰杰因果结构评分模块中,对于给定的因果结构G,本文利用EM 算法估计参数Θ,计算结构G的BIC 评分基于EM 算法的思想,通过引入隐变量z∈N×T×{1,2,…,K},用于告警事件发生的具体原因,推导出参数Θ的迭代优化公式。
参数μv的迭代公式为:

而参数αv',v,k的迭代公式为:

在格兰杰因果结构评分模块中,利用上述公式迭代更新给定结构G的模型参数,直至收敛,具体的算法流程如算法1 所示。
算法1因果结构评分模块

需要注意的是,由于目标函数的非凸性质,EM算法存在收敛到局部最优解的风险,因此在实践中,通常会尝试不同的参数初始起点进行优化,并取评分最高的参数作为结果。
3.2 格兰杰因果结构搜索模块——爬山法
为搜索最优的格兰杰因果结构,本文参照文献[24],使用爬山法,以通过EM 的优化得到的BIC评分为基础,选出BIC 评分——最高的结构G,具体的算法流程如算法2 所示。
算法2因果结构搜索模块

在算法2 中,V(G′)表示G′的邻居结构,即通过对结构G′进行一次增边、删边或转边的操作,得到的结构的集合。在结构搜索模块中,通过初始化搜索结构(步骤1)、加入对搜索空间的约束(步骤7)等形式,灵活地引入直接、非直接的因果先验。具体地,在步骤7 中,通过将不满足无环条件的格兰杰因果结构剔除的方式,引入因果无环先验性先验。
现有一些关于BIC 一致性以及爬山法的相关工作,也为本文算法的可靠性提供了理论支撑。根据文献[23]中的证明可知,在给定足够大的样本量的情况下,霍克斯过程BIC 评分的一致性是渐进成立的。而文献[25]中给出证明指出,由于BIC 得分所具有的一致性属性,这种基于爬山法的结构优化算法能够找到真实的因果图。
3.3 复杂度分析
对本文算法的时间复杂度进行分析。在结构评分模块中,计算复杂度主要取决于EM 算法。EM 算法的迭代次数为常数,因此,给定一个因果结构G,EM 算法的时间复杂度为O(Km3e)。其中:K代表核函数中的基函数κk的数目;m是指发生事件的总数;e表示因果结构G中因果边的数目。需要注意的是,如果使用基函数κk满足κk(t1+t2)=κk(t1)κk(t2),那么EM 的计算复杂度就能降低为O(Km2e),因为每个发生的事件的强度都可以只用前一个发生事件的强度来计算。因此,在实践中,常使用指数形式函数作为基函数,降低计算复杂度O(Km2e)。为了使结果更具普适性,下面的分析将不考虑选择特殊基函数的情况。
在结构搜索模块中,时间复杂度主要取决于每个事件类型对应的原因类型的数目。根据BIC 评分的一致性假设,因果结构搜索会从边数为0 的空图开始,在找到所有的E条因果边后结束。那么,最坏的情况下,即当所有的因果边都指向同一个事件类型时,算法的时间复杂度最高,具体为:
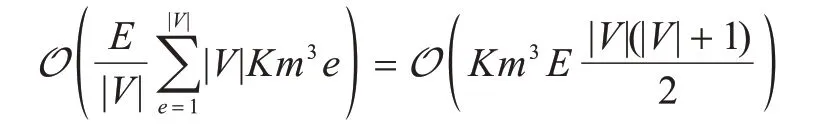
在这种情况下,由于本文每次加边只需要更新原因事件类型集合发生变化的事件类型对应的评分即可,因此每加一条边的时间复杂度为O(Km3|V|e)。而最好的情况是因果边都均匀地分布在每一种事件类型上,因此每一种类型的原因事件类型数目为在这种情况下,本文算法的时间复杂度将降低为:
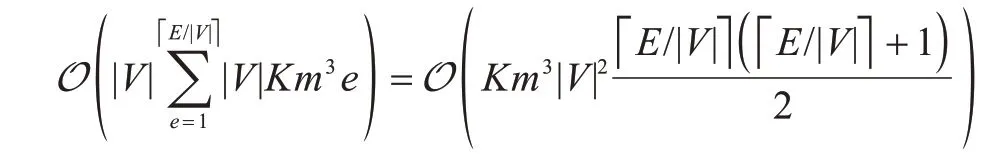
在具体的工程实现过程中,得益于似然度函数能够按事件类型进行分解的特性,结构搜索模块能够通过并行化计算进一步提高计算效率。
4 实验
本节使用模拟数据以及两个真实场景的数据对模型进行评估。将TSSO 与主流的事件序列格兰杰因果发现方法进行对比,其中包括基于独立性检验的PCMCI 算法、基于低秩约束的霍克斯过程模型的ADM4 算法,以及在此基础上使用更加复杂强度函数的MLE-SGL 算法。本文采用F1 评分(F)作为评价指标,计算公式如下:
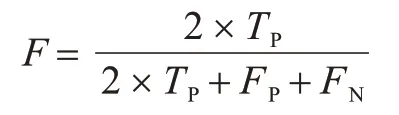
其中:TP表示算法预测正确的因果边的数目;FP为算法预测错误的因果边的数目;FN为真实因果结构中没有被算法发现的因果边的数目。
4.1 模拟数据实验
在模拟数据实验中设计5 个控制变量实验,通过指数形式的霍克斯过程生成数据,强度函数为其中αv',v表示v'对v的激发强度。每次实验都会随机生成格兰杰因果结构以及霍克斯过程参数。5 个实验变量包括:不同的基础强度采样范围{(0.000 05,0.000 1),(0.000 1,0.000 5),(0.000 5,0.001),(0.001,0.005),(0.005,0.01)},激发强度系数取值范围{(0.01,0.03),(0.03,0.05),(0.05,0.07),(0.07,0.09),(0.1,0.3),(0.3,0.5),(0.5,0.7),(0.7,0.9)},平均入度{0.5,1,1.5,2,3,4},样本数量{4 000,6 000,8 000,10 000,15 000,20 000,25 000,30 000},以及事件类型数目{10,20,30,40,50}。其中:加粗的部分为控制变量实验中的默认设置;β默认为0.1。此外,为使数据更加接近真实场景情况,在模拟生成的事件发生时间的基础上加上一个采样出的高斯噪声,并将事件发生事件的精度设置为1 s,模拟现实中故障记录过程中存在时间偏差、精度不足的情况。
图1 展示了不同基础强度取值范围下的实验结果,可以看出,基础强度对本文方法的影响不大,而对于其他方法,尤其是ADM4 和MLE-SGL,随着基础强度增大,其效果下降明显。这是因为随着基础强度增大,自发发生事件的占比变多,容易与不同事件类型之间的相互影响相混淆,引入冗余的因果边。这说明TSSO 中,基于贝叶斯信息准则的ℓ0范数惩罚项能够更有效剔除冗余的因果关系。

图1 针对基础强度的控制实验结果Fig.1 Results of control experiments on base intensity
图2 显示了不同激发强度取值下的实验,可以看出,由于激发强度取值跨度大,各种方法对于激发强度的取值大小都比较敏感。这是因为:直观上,当激发强度取值过小,一些由于事件类型相互影响产生的事件容易与自发发生的事件混淆,导致因果边的漏检测、误检测;而由于模拟数据时间精度低,且存在记录噪声的情况,当激发强度过大时,原因和结果事件容易落在同一个时间间隔中(模拟数据为1 s),增大判断格兰杰因果方向的难度。在这种情况下,本文方法仍优于其他对比方法,表明本文方法具有较好的稳定性。

图2 针对激发强度的控制实验结果Fig.2 Results of control experiments on excitation intensity
如图3 所示,本文方法在小样本量的情况下仍然保持较好的性能表现,这主要是因为结构评分函数中的BIC 罚项能够适应不同的数据样本量,保证不同样本量下BIC 评分的一致性。

图3 针对样本数量的控制实验结果Fig.3 Results of control experiments on sample size
由图4 和图5 可以看出,事件类型数目和平均出度对于本文模型的影响不大,验证了本文方法在格兰杰因果结构规模及密度下的鲁棒性。

图4 针对事件类型数目的控制实验结果Fig.4 Results of control experiments on number of event type
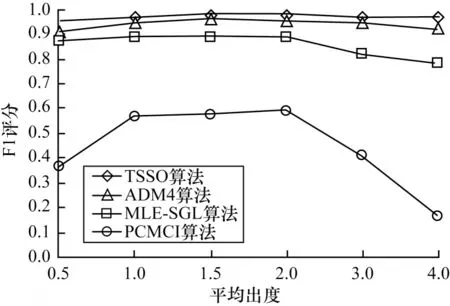
图5 针对平均出度的控制实验结果Fig.5 Results of control experiments on average out-degree
4.2 真实数据实验
真实数据实验分别在无线基站网络告警场景和城际蜂窝网络告警场景数据上进行测试。对比方法包括PCMCI 和MLE-SGL、ADM4。在实验中,除了F1 评分之外,进一步引入精确率(P)和召回率(R)作为模型性能的评价指标,计算公式如下:

其中,真实结构标签通过专家标注得到。
4.2.1 无线基站网络告警场景
在无线基站网络场景中,实验所使用的数据采集于一个包含2 476 个基站设备的无线网络,时间跨度为37 d,包含605 217 条故障告警记录,涉及18 种告警类型。
需要注意的是,基于专家知识,在这个场景,故障之间的格兰杰因果是满足无环的先验的。因此,在TSSO 的结构搜索模块中(步骤7)加入结构无环的约束,将不满足无环约束的因果结构从搜索空间中剔除。加入有向无环约束后的算法用TSSO-DAG表示。由表1 可以看出,本文方法在准确率和召回率上,相比对比方法都有明显优势(加粗数据表示最优值)。F1 评分比对比方法中表现最优的ADM4 高出了16.45%。这说明基于BIC 评分能够在更有效地剔除冗余因果边的同时,发现难以被其他方法检测到格兰杰因果关系。

表1 无线网络故障数据上的实验结果Table 1 Experimental results on wireless network alarm data
4.2.2 城际蜂窝网络告警场景
为进一步测试算法的性能,在一个更具挑战性的城际蜂窝网络告警场景数据集上进行实验。在这个场景中,数据是从配置了3 087 个网元设备的蜂窝网中采集的,包含228 030 条告警记录,涉及18 种告警类型,时间跨度为7 d。在此数据集中,存在时间跨度小、样本分布不平衡的情况。实验结果如表2所示。其中:加粗数据表示最优值;TSSO 为不加无环先验的算法;TSSO-DAG 表示加入无环约数的算法。
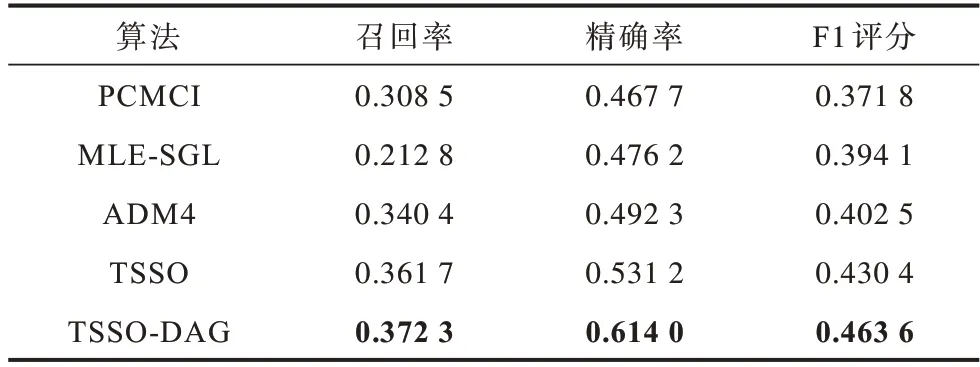
表2 蜂窝网络告警数据集实验结果Table 2 Experimental results on cellular network alarm dataset
由表2 可以看出,在召回率的指标上,各种方法的表现都不够好,这可能是因为数据分布不均匀、采集时间跨度短,导致一些强度较弱的格兰杰因果关系所对应的数据没有被采集到。通过与其他方法对比可以得出,即使没有引入无环先验,TSSO 的结果仍明显优于其他对比方法,尤其是在精确率指标上提升明显。这说明本文方法能够更有效地保证结构的稀疏性,剔除冗余、间接的格兰杰因果关系。而从TSSO-DAG 的结果可以看出,在加入了无环性约束后,模型的表现有了进一步的提升,在F1 评分上,较对比方法中ADM4 高出15.18%,在精确率指标上,较没有无环约束的TSSO 提升了13.49%。可以看出,在这个场景中,无环先验的引入对于提升模型的可靠性有很大的帮助。
同时由表2 也可以看出,对于这种更具挑战性的场景,先验知识与反馈的引入就显得尤为重要。因此,为进一步讨论先验知识引入的有效性和必要性,在此真实数据的基础上设计两个实验,模拟两种故障运维场景中常见的先验、反馈形式,对本文方法进行测试。
1)引入根因标注案例反馈的实验
在运维场景中,对于一段时间内出现的一系列告警,业务专家会标记出告警对应的根因并反馈给运维人员做进行处理。在本文方法中,能够通过记录所有案例中根因及其后继节点,并将存在不满足该条件的因果图从搜索空间中剔除掉的方式,对模型进行矫正,从而引入根因标注案例反馈信息。本文通过对已知的因果图中的告警类型进行随机采样(每次采样选取5~10 个告警类型)模拟一段时间内出现的告警类型,并通过因果图定位其中的根因,以此作为模拟根因标注案例反馈数据。如图6 所示,相比于原始结果,少量的根因标注案例反馈的引入就能让TSSO 的性能有显著的提升,最终能使模型的F1 评分提高22.43%,其中精确率达到0.78,提升了20.98%。

图6 引入根因标注案例反馈的实验结果Fig.6 Results of experiment of introducing root cause feedback
2)引入因果依赖性先验的实验
依赖性先验是指对于两个故障类型,已知其存在因果依赖关系但是无法判断其因果方向。在TSSO 中,通过修改结构搜索终止条件的方式,引入依赖性先验,保证输出的因果图的骨架包含先验告警对。在模拟依赖性先验数据方面,本文对已知因果结构的骨架的边集合进行采样,模拟依赖性先验数据,进行实验。如图7 所示,横坐标表示格兰杰因果骨架的采样的比例,即先验的故障对数目占真实因果边的比例。可以看出,依赖性先验引入则更侧重于提高模型召回率,能够在保证精确率稳定的情况下,使召回率得到显著提升,且F1 评分提升29.93%。
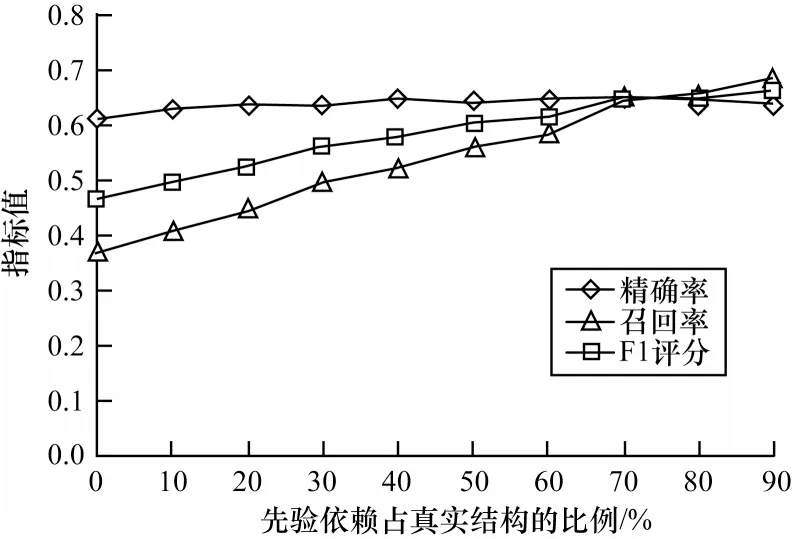
图7 引入因果依赖性先验的实验结果Fig.7 Results of experiment of introducing dependence priors
5 结束语
现有基于事件序列的格兰杰因果发现算法难以有效引入因果先验,保证所学因果结构的稀疏性,在稀疏、时间精度低故障事件数据上,存在结果不稳定、可靠性差的问题。本文提出一种面向故障序列的因果发现的霍克斯过程模型。将霍克斯过程拓展到离散时间域,并依据贝叶斯信息准则构造以ℓ0范数为稀疏惩罚项的目标函数,保证因果结构稀疏性。同时通过结合EM 算法与爬山法,提出两步迭代优化算法,发掘故障事件背后的格兰杰因果关系,在保证优化效率的情况下,有效引入因果结构先验,进一步提高模型的可靠性。实验结果表明,与ADM4、MLE-SGL、TSSO 和PCMCI 算法相比,本文方法在模拟数据和真实数据下具有更高的准确率。后续将通过引入深度点过程模型的框架,使用表达能力更强的模型捕捉机制更复杂的因果关系。
