基于值分解的多目标多智能体深度强化学习方法
2023-01-27宋健王子磊
宋健,王子磊
(中国科学技术大学自动化系,合肥 230027)
0 概述
随着深度学习技术的发展,强化学习方法的聚焦问题逐步从单智能体领域转移到多智能体领域。在现实世界中,许多需要多个智能体协作的场景都是多目标多智能体决策问题:每个智能体都需要实现自己的目标,但是只有当智能体协作并允许其他智能体成功时,才能获得所有智能体成功的全局最优解[1]。例如:在自动驾驶中,当多辆车的目标位置和预计轨迹发生冲突时,它们必须执行协同机动;在社交环境中,人们相互合作一般可以获得更高的全局回报,只局限于自身利益而不顾大局的个体往往成为害群之马,适得其反。一个环境即便只涉及合作任务,即所有个体目标是一致的,环境仍可以被表述为多目标场景。例如在星际争霸2 中,一个收集资源的单位也需要小心行动,以免暴露正在执行秘密侦查任务的单位。
多智能体强化学习广泛应用了深度学习方法,且被使用在各种复杂场景中,但多目标多智能体场景中的最优决策仍面临重大挑战。文献[2]提出的IQL(Independent Q-Learning)假设场景中的各智能体是相互独立的,其决策是互不影响的,分别使用Q-Learning 方法训练每个智能体;文献[3]提出的MADDPG(Multi-Agent Deep Deterministic Policy Gradient)和文献[4]提出的M3DDPG(Multi-Agent Minmax Deep Deterministic Policy Gradient)考虑到了具有不同奖励、不同目标的多智能体场景;文献[5]提出的QMIX(Q-Mixer Network)模型将全局动作值函数分解为每个智能体的动作值总和。然而,多目标多智能体场景中往往涉及合作和竞争并存的混合关系,这些模型只考虑了全局奖励或动作值函数由所有智能体共同作用而成,却没有充分探究智能体之间的关系,不能区分合作和竞争动作,也就不能精准地衡量各智能体对全局奖励的贡献高低。
为提高强化学习方法在混合关系场景中的性能,本文针对多目标多智能体场景,提出一种多目标值分解强化学习方法MG-QMIX(Multi-Goal QMixer Network)。将智能体的目标信息引入单调性值分解方法,提出并实现一种二级分解方法,在目标完成度-智能体动作值融合阶段使用注意力机制分析智能体的群体影响力,并选取一些代表性的实验场景,使用MG-QMIX 和其他主流的多智能体强化学习方法分别训练各场景的智能体,以证明MGQMIX 方法在多目标多智能体场景的有效性。
1 相关研究
文献[2-6]主要研究一些具有离散状态和动作空间场景,这些较为简单的场景一般可以建模为单智能体的马尔可夫最优决策过程。其中的智能体可以获得环境的全部状态信息,并且环境的状态转移一般只受到智能体自身决策的影响,也即环境的状态以及状态的变换在智能体的角度看来是相对稳定、可学习的,那么使用马尔可夫过程建模是恰当的。近期的研究[7-8]则逐渐将视角转移到一些更复杂的场景上,这些场景具有更高维的信息和更复杂的智能体交互。
多智能体合作问题是当前领域内的热点课题。在场景中,每个时刻都存在智能体与环境、智能体与智能体之间的交互。文献[9]指出,为了获得全局的成功,可以使用分布式智能体框架学习协作策略。但如果假设所有智能体相互独立,在理论上可以直接对每个智能体应用单智能体算法。这样的假设让每个智能体把其他智能体视作了环境的一部分,环境也就失去了稳定性,不符合之前提到的马尔可夫过程的建模前提,与单智能体强化学习方法相矛盾。但是在实际应用中,这样的方法有时也是可行的,文献[2]提出的IQL 方法使用了Q-Learning 独立地训练了每个智能体,文献[7]在此基础上运用了文献[10]提出的DQN(Deep Q-Network)模型。这种方法有着明显的收敛问题,所以文献[11-12]也针对性地提出了一些加速收敛的方法。
在理论上,集中式地学习各智能体的联合动作策略,既可以保证环境稳定性,也可以从源头实现合作的决策。但是集中式学习意味着联合动作空间会随着智能体数量增长呈指数增长,不易实现。文献[13]提出了集中式学习的经典方法Co-Graph(Coordination Graphs),将全局奖励函数分解为智能体局部项的总和。文献[14]使用了一种拓扑的Q-Learning 合作方法,它仅在需要决策的状态下学习一组合作动作,并将这些依赖项编码在Co-Graph中。但上述方法都需要预先提供或学习智能体之间的依赖关系。
如果可以从环境中获取每个智能体的个体回报值,就可以使用这个回报值作为个体对环境的贡献,那么以上提到的问题就可以使用贡献分配方法来解决[15]。贡献分配是指在复杂的学习系统中如何分配系统内部成员对结果的贡献。然而,文献[16]指出,在完全合作的场景中,智能体只基于个体回报学习的策略不尽如人意,反而是基于其他智能体的回报学习的策略会实现得分更高的全局回报。因此,贡献分配的依据不能只从个体回报值出发,还需考虑到个体与环境、个体与个体之间的利害关系。
最近的研究则使用集中式学习、分布式执行的结构。文献[17]提出的模型COMA(Counterfactual Multi-Agent Policy Gradients)使用集中式的评判网络来评价分布式执行的策略网络,为每个智能体估计了一个基于“反事实基线”的优势函数,以解决多智能体贡献分配问题。类似地,文献[18]提出一种对应于每个智能体的多评判网络的集中式演员评论算法,该算法可以随着智能体数量的增加而扩展,但降低了集中式方法的优势。文献[3]为每个智能体学习了一个集中的评判网络,并将其应用于具有连续动作空间的竞争性游戏。这些方法使用策略梯度学习方法,样本学习效率低,容易陷入次优局部极小。
如果将全局目标视作所有个体目标的总和,那么可以使用值分解方法优化集中式的评判函数,同时保持分布式执行。文献[19]提出一种价值分解网络(Value Decomposition Network,VDN),该网络同样使用了集中价值函数的学习和分散执行的框架,将全局状态动作值函数视为每个智能体的动作值的线性加和。这种方法类似退化的、完全断开的协调图,但该模型在训练期间不使用额外的全局状态信息,没有利用集中式学习的优势,线性加和的分解形式对动作值函数的刻画能力也有限。文献[5]提出的QMIX 方法针对上述问题,在分解中加入非线性度,并在集中式学习过程中使用全局状态信息,提升了模型性能。但使用的单调性值分解方法仍然限制在完全合作的场景中,对具有混合关系的多目标场景性能不佳。
对于智能体目标存在差异的场景,虽然文献[3]提出的MADDPG 和文献[4]提出的M3DDPG 适用于具有不同奖励的智能体,但智能体从根本上无法区分合作和竞争动作,不能解决多目标合作问题。文献[20]提出一种多目标多智能体强化学习方法,并分析了完全分布式训练网络的收敛性。文献[1]设计的CM3(Cooperative Multi-Goal Multi-Stage Multi-Agent Reinforcement Learning)模型类比动作值方程,提出一种目标-动作值方程,根据该方程实现了一种多目标多智能体贡献分配方法,并使用了分散执行、集中训练框架[21]。尽管这些方法或多或少地考虑到了智能体的目标差异,但它们的贡献分配仍然是以智能体个体回报或个体目标为依据的。如何在不稳定的环境状态下评估每个智能体对于环境及其他智能体的影响,是多目标多智能体合作场景的一大难题。
2 数学背景
2.1 多目标马尔可夫决策过程
类比于一般的马尔可夫决策过程以及状态部分可观测的马尔科夫决策过程[22],本文将多目标多智能体强化学习场景建模为多目标马尔可夫决策过程[1]。每个智能体基于有限的观测值和源于一个有限集合的目标独立决策,总体上与其他智能体相互合作获得全局的成功。多目标马尔可夫决策过程可以用式(1)的元组描述:


建模以状态部分可观测为前提,即每个智能体会根据一个观测方程得到个体观测值,再合并该智能体的历史决策动作序列,两者记为τ∈(O×U)。
本文模型采用集中式学习分布式执行的网络结构。该网络结构一般由集中式的评判网络和分布式的策略网络构成。评判网络可以使用完整的全局动作、状态信息以加快训练收敛速度,但是策略网络只能使用智能体的自身局部信息,以还原真实场景的限制因素。
2.2 主要模型
文献[10]提出的深度Q 网络(DQN)方法通过神经网络来学习Q-Learning 中的动作价值函数,并且使用了经验回放池策略和target 网络软更新策略。经验回放池策略可以减弱样本之间的相关性,具体操作是将历史的环境交互<s,u,r,s′>存入缓存池中,其中s′是采取动作u后的转移状态。模型在训练过程中使用从缓存池中采样的若干批次数据样本,通过最小化式(2)的TD(Time Difference)误差函数来学习最优策略。
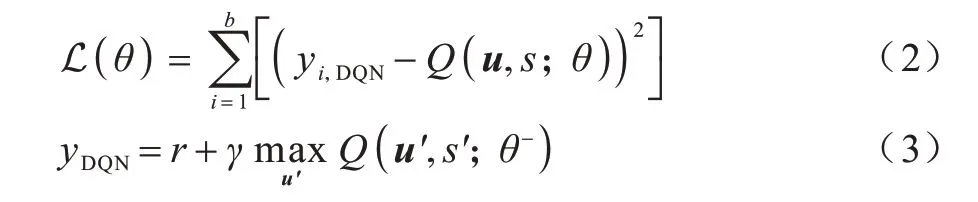
式(3)中的yDQN是基于target 网络生成的动作值,θ-是该网络参数。基于target 网络的更新方式将target 网络拟合的动作值作为“真实”值,相较于一般的更新方式,参数更新更加平滑,提升了收敛性能,可称为软更新。
在部分可观测的前提下,智能体往往能从一些历史动作和观测信息中学习到更多的特征。文献[23]提出的DRQN(Deep Recurrent Q-Learning Network)利用RNN(Recurrent Neural Networks)[24]试图从历史信息中提取特征。在一些时间序列较长的场景中可以使用文献[25]提出的LSTM(Long Short-Term Memory)或文献[26]提出的GRU(Gated Recurrent Units)网络。
文献[19]提出的VDN 通过使用值分解方法优化集中式的动作值函数,同时使用分布式执行的框架。该方法将全局目标视作所有个体目标的总和,学习式(4)的联合动作值函数。
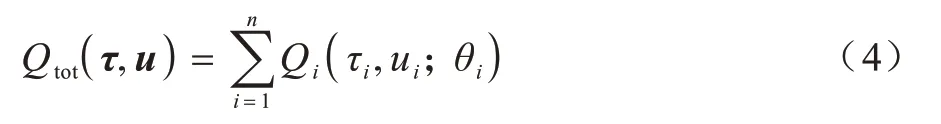
联合动作值是每个智能体的动作值的总和。状态部分可观测和分布式执行框架要求每个智能体的动作值只依赖于其个人的动作与观测值的历史序列。
VDN 的值分解采用了线性加和的方式,这样的分解形式使其使用场景有着极大的限制。文献[5]提出的QMIX 为解决该问题,在分解过程中引入了非线性成分。具体是用一个融合网络将各智能体的动作值融合为全局动作值,将非线性度引入融合过程,联合动作值函数如式(5)所示:

注意力机制经常用来提取输入特征中的关键信息,有很多不同的变种和可选的网络形式。键值对注意力机制用键值对格式来表示输入信息,其中,“键”用来计算注意力分布,“值”用来生成选择的信息。多头注意力是利用多个查询来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分,硬注意力即基于注意力分布的所有输入信息的期望,结构化注意力要从输入信息中选取出和任务相关的信息,主动注意力是在所有输入信息上的多项分布,是一种扁平结构。如果输入信息本身具有层次结构,比如文本分为词、句子、段落、篇章等不同粒度的层次,可以使用层次化的注意力来进行更好的信息选择。此外,还可以假设注意力上下文相关的两项分布,用一种图模型来构建更复杂的结构化注意力分布。
3 MG-QMIX 方法
3.1 融合机制
本文提出一种基于QMIX 和注意力机制的多目标注意力动作值分解与融合的方法MG-QMIX。该方法相比于QMIX,加入了目标信息,扩展了动作值方程的拟合方式,并使用注意力机制分析智能体群体影响力,提升模型对复杂的多智能体交互关系的理解能力与动作值估计的精度。
将环境各智能体的目标信息引入到动作值函数和融合过程中,是本文模型的关键思想之一,也是模型能够应对更为复杂的多智能体场景关系的数据基础。基于值分解方法的多智能体强化学习模型,从VDN 到QMIX,基本是以全局的奖励可以视作所有个体贡献价值的总和为前提的,这样的前提从根本上忽略了各智能体之间的相互影响。所以,QMIX可以在一些完全合作的场景中发挥作用,但在一些涉及多智能体协作与利益冲突并存的混合关系场景中性能受限。
本文的值分解方法可以分为动作值融合和多目标融合两个阶段。在一个时刻下,多目标融合是将所有智能体目标完成程度融合为全局的回报值Qtot,如式(6)所示:
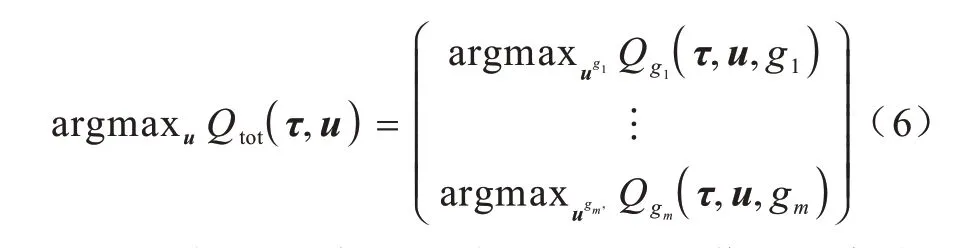
一个目标gi的完成程度可以视作所有智能体对这一目标贡献的融合,也即动作值融合,如式(7)所示:

其中:Q1~Qk代表以gi为目标的智能体(下文称为主体智能体)的动作值;Qk+1~Qn则是其余的智能体(下文称为他体智能体)的动作值;τj、uj分别表示相应智能体的动作-观测值历史纪录和当前时刻决策动作,满足uj∈,∀j=1,2,…,k。
这样的区分主要是因为一个智能体aj只需根据自身目标gi,依据贪心策略选取使Qj(τj,uj,gi)值最大的动作决策,然后再用这个决策动作计算其他目标下的动作值,所以式(7)中的Qk+1~Qn并不涉及最大值选择。这也意味着一个智能体在策略决策阶段只需要自己的历史纪录和观测信息,不需要全局的状态,保证了分布式决策执行的框架实现。但同时,使用到的贪心策略要求模型必须采用离线学习方式。
另外,为了限制分解关系的单调性,需要满足式(8):

文献[27]证明了这样的限制条件允许融合网络拟合某种单调函数。需要注意的是,单调性在融合过程中是局部的,只在多目标融合阶段体现。在动作值融合阶段,不同目标的智能体之间需要考虑到竞争关系的影响,那么对于融合过程中的他体智能体,其影响权重的正负应由该智能体的群体影响力决定。所谓的群体影响力是指他体智能体的决策趋势是否会对主体智能体基于自身目标的最优决策产生正面或负面的影响,以及影响的大小,可以从主体智能体状态smain和所有智能体全局状态s的比较分析中计算得出。目标信息和群体影响力两者的作用是相辅相成的,群体影响力的生成需要借助目标信息,而由目标信息引入的第一阶段的融合需要群体影响力引导生成融合权重。
在多目标融合阶段,各目标完成程度对于全局的回报值Qtot的贡献则可以通过全局状态s分析计算得出。
3.2 神经网络模型的实现
上述的QMIX等分解方法由图1所示的MG-QMIX模型实现,模型由策略网络和融合网络两部分构成。

图1 MG-QMIX 模型结构Fig.1 Structure of MG-QMIX model
一个策略网络学习了一个智能体a的多目标动作值函数{Qa(τa,·,gi)|i=1,2,…,m}。如图1 所示,网络采用DRQN 结构,以智能体当前时刻观测值oa,t和上一时刻历史动作ua,t-1为输入,输出的中间特征za,t与不同的目标向量{gi|i=1,2,…,m}结合后通过后续的全连接层生成对应目标下的动作值{Qa(τa,·,gi)|i=1,2,…,m}。智能体会基于自身目标ga下的动作值Qa(τa,·,ga),以贪心策略选取使动作值最大的动作ua,t,并输出最优动作下的多目标动作值{Qa(τa,ua,t,gi)|i=1,2,…,m}。需要指出的是,在训练过程中,智能体并不会直接选择最优动作ua,t,而是以一个自适应的ϵ概率选择随机动作,目的是增强训练过程中策略的探索能力。
具有注意力的超网络为融合过程提供相应的融合权重和偏置,如图2 所示。因为考虑到无论在动作值融合阶段还是多目标融合阶段,融合方程的非线性度并不强,融合关系是有迹可循的,所以没有直接用融合网络完成两阶段的融合过程。另外,如果直接将全局状态s和策略网络输出的多目标动作值交由一个神经网络处理,无疑会增加学习难度,甚至出现欠拟合的情况,故而选择借助超网络生成融合参数。超网络可以使用神经网络处理状态信息并输出相应的融合参数,可以对融合参数选择性地做一些额外处理,比如通过绝对值激活实现单调性限制,或者在融合中加入线性成分。

图2 融合网络框架Fig.2 Framework of converged network
在动作值融合阶段,融合参数需要衡量主体智能体和他体智能体对融合目标的影响,MG-QMIX模型采用注意力机制。如3.1 节所述,群体影响力是指他体智能体的决策趋势是否会对主体智能体基于自身目标的最优决策产生正面或负面的影响,以及影响的大小。全局状态包含了所有智能体的当前状态(包含目标)和环境状态,状态和目标信息其实也蕴含了智能体在整体环境中所处地位、决策趋势等关键信息,将主体智能体状态与全局状态各部分作比较分析,在理论上可以评估每个他体智能体对于主体智能体决策的影响。注意力机制经常用来提取输入特征中的关键信息。群体影响力可以看作依据主体智能体的状态,提取全局状态中的对主体智能体行动影响较大的部分,以相关性权重输出。在合成过程中,大小不一的权重表示了各智能体对当前目标的贡献程度。与键值对注意力机制相吻合,全局状态和主体智能体状态分别视作“键”和“值”,用键值对格式来表示输入信息,其中“键”用来计算注意力分布,“值”用来生成选择的信息。融合网络对比了主体智能体状态smain和所有智能体全局状态s之间的关联程度,如式(9)所示计算得到aattention向量:

然后利用aattention计算权重和偏置,模型使用了两对参数(W11,b11)、(W12,b12)提高融合刻画能力和精度。如式(10)所示,将aattention分别输入到一个全连接层得到这些参数,b12需要额外经过一层ReLu 激活函数和另一层全连接层。

之后利用这组参数完成各目标下动作值{Qa(τa,ua,t,gi)|i=1,2,…,m,a=1,2,…,n}到目标完成度的融合。为引入一定的非线性度,第1 组参数计算的结果经过一层ELU 激活函数,再利用第2 组参数计算得到最终的目标完成度,如式(11)所示:

在多目标融合阶段,融合参数(W21,b21)、(W22,b22)直接由全局状态s生成,计算方式与第1 阶段相似,但是需要额外满足单调性要求,所以对两个权重取绝对值激活,如式(12)所示:

类似地,模型利用这组参数完成各目标完成度{Qgi(τ,u,gi)|i=1,2,…,m}到全局的回报值Qtot(τ,u)的融合,如式(13)所示:
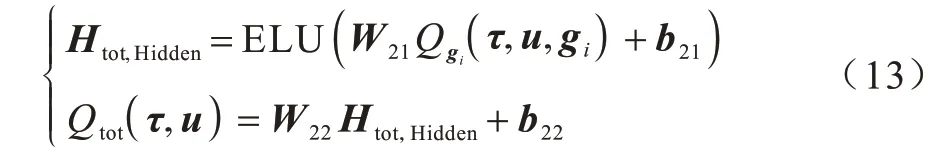
模型整体是端到端训练的,最小化如式(14)所示的损失函数:

算法1MG-QMIX 算法


4 实验设置
4.1 实验环境
为验证本文模型的性能效果和鲁棒性,在一些具有离散动作状态场景上进行数组实验。第1 部分是在单目标、纯粹合作场景星际争霸2 平台选取若干个对抗模式,训练红方多个单位对抗电脑固定策略,主要是验证本文模型是否保留了QMIX 模型对于合作关系的学习能力;第2 部分是一些多目标、混合关系场景,选取了checker、多粒子导航场景,主要是验证本文模型在多目标混合场景中的性能。
4.1.1 星际争霸2
强化学习领域常使用即时策略游戏作为实验平台,星际争霸2 是目前最常使用的即时策略游戏平台之一。通过对地图、部队兵种等的设置,可以满足合作、竞争、多智能等多种环境需求。游戏中的作战单位拥有庞大且复杂的微观动作空间,多个智能体的环境交互也足够复杂。本文选取了由文献[29]提出的星际争霸2 微观操控平台作为本文的实验平台。
具体地,本文使用该平台的一些分布式微观操控场景。场景中有红蓝两方队伍,通过操控红方的各个作战单位与蓝方对抗攻击。按照模型的分布式策略方法,每个智能体操控红方中的一个单位。场景中所有单位无论归属红蓝何方,其兵种决定了它的动作空间和状态属性,即同一个种类的单位具有一样的动作和状态。蓝方的队伍的单位数量和单位种类与红方保持一致,并且由平台的AI 策略操控,共有7 种难度等级,由低到高代表了蓝方AI 的智能等级从低到高,本文选取了等级3 的难度。具体场景包含“3 个枪手(3m)”“8 个枪手(8m)”和“2 个猎人3 个狂热者(2s3z)”,以上均为游戏内的作战单位种类名称。
环境建模方面类似于文献[17]的实验部分。智能体微观动作操控可以概括为移动-攻击模式。每个智能体的动作包含移动、攻击、停止和无动作。其中,移动动作需要给出东南西北四个方向之一的参数,攻击动作需要给出在其攻击范围内的敌方单位编号。需要注意的是,场景并不会让智能体自动攻击范围内的敌方单位,而是强迫智能体学习攻击策略,自行选择攻击的对象和时机。环境的状态空间对于每个智能体是部分可观测的,其状态观测值取决于智能体的视力范围。对于视力范围之外的单位,无论是友方还是敌方,智能体都无法知晓其任何状态。环境的奖励值由我方造成伤害和敌方伤亡情况两部分构成。每个回合,我方造成的伤害值的总和作为奖励的第1 个部分;如果当前回合造成一名敌方阵亡,则有10 得分,如果使得全部敌方阵亡还会额外获得200 得分,这是奖励值的第2 个部分。每个回合的奖励值都会归一化得到一个0~20 范围的分值。
与原平台不同,本文模型需要一个目标信息来表示每个智能体的关注点。在星际争霸2 平台上,由于我方的每个单位的目标都是统一的对抗敌方,不存在内部的资源等的竞争,因此是一个单纯合作的场景。实验中将所有智能体的目标都设置为同一个特征向量,即单目标场景。这组实验的目的也是为了与QMIX 表现较好的实验平台上做直观的对比。
4.1.2 棋盘游戏
棋盘游戏环境来自文献[1],是一种目标信息比较关键的场景。如图3 所示,场景包含两个智能体,要在分布着红蓝点的棋盘上移动,每次只能移动一格,且不能移动到棋盘外或者被其他智能体占领的棋盘格。每当一个智能体移动到一个具有红点或者蓝点的格子上时,便会吃掉该点并获得相应的得分,但是其中一个智能体吃掉红点会获得更多的得分,另一个智能体则是吃掉蓝点会获得更多的得分。场景的总体奖励由两方得分的和构成。所以,若要获得尽可能高的总体得分,两智能体需要相互配合,尽可能只吃自己获益更多的得分点,并且要为另一个智能体向目标点移动清除途中的低分障碍。场景的状态同样是部分可观测的,一个智能体只能获取自身的状态信息和周围指定格数的棋盘信息,以及视野内的另一智能体位置信息。

图3 棋盘游戏样式Fig.3 Board game style
4.1.3 多粒子运动环境
多粒子环境由文献[8]提出,可以在二维空间中模拟操控具有碰撞体积的粒子上下左右移动,并根据不同的任务目标设立了一系列的地图。本文使用了变道(merge)和交叉(cross)两种地图,如图4 所示。较大的粒子代表粒子的初始位置,同花纹的较小粒子代表了操控该粒子移动的期望目标位置。不同的粒子由不同的智能体策略操控,动作空间共有上下左右四个固定速度的移动和停止等指令,环境同样是状态部分可观测的,各智能体的观测状态包括自身的位置、运动和目标信息,以及观测范围的其他粒子的位置信息。场景的总体奖励反馈分为两部分:一部分是根据每个智能体相对于目标位置的距离设定的,为一个负值;另一部分是根据粒子之间的碰撞次数生成的惩罚。因此,整体的奖励值始终是负数,值越大代表策略性能越好。

图4 多粒子运动环境Fig.4 Multi-particle motion environment
4.1.4 目标信息设置
在各个场景中,目标信息的形式可以分为两种:一是与环境状态相关的特征量,比如位置、ID 标识、速度等;二是抽象为独热编码形式。在星际争霸2的各地图中,所有智能体的目标是相同的,所以用“1”指代,这是因为这部分实验设置是为了验证本文模型是否保留了QMIX 模型对合作关系的学习能力。在棋盘场景中,两个智能体分别对红蓝点敏感,所以其目标设置为二维的独热编码“01”和“10”。在多粒子运动场景中,每个智能体要从起始位置移动到终点位置,所以目标信息可以设置为终点位置的二维坐标数据。
4.2 消融实验
为验证本文方法和模型使用的几种关键技术对模型性能的影响,在实验设置中加入了两组消融实验。
首先,在融合网络中,模型使用ReLU、ELU 等激活函数实现非线性的值融合。在理论上,场景中各智能体对于各目标的贡献,以及各目标对全局动作值的贡献分配是较复杂的映射关系,非线性的拟合方式在理论上会提升网络对于各变量之间的关系的刻画能力。因此,基于线性融合方式的模型可以作为一组消融实验,即去掉原模型的融合网络中的非线性激活函数,并在多粒子运动环境中的merge 地图上训练该模型。
其次,在动作值融合阶段,模型使用注意力机制学习智能体的群体影响力,为后续的融合参数的生成提供了更为丰富的特征信息。为证明注意力机制对于动作值融合阶段的关键性作用,不使用注意力机制的模型作为另一组消融实验,即在值融合网络的第一阶段中,全局状态st不经过注意力模块,直接作为超网络的输入。同样地,这组消融实验也在多粒子运动环境中的merge 地图上训练了该模型。
5 实验结果与分析
为了验证MG-QMIX 的各种性能,本文在星际争霸2 微观操控平台、棋盘游戏和多粒子运动环境分别训练、测试了模型,并将结果与文献[5]提出的QMIX 模型和文献[17]提出的COMA 模型进行对比。在每个场景中,每种模型独立训练10 次,图5 所示的训练曲线是10 次独立训练的平均值结果,每种模型训练完成后的100 局测试实验的平均得分如表1 所示(粗体表示结果最优)。从综合结果可以看出:本文模型在星际争霸2 这样的单纯合作场景中与QMIX 的得分持平,比COMA 性能更好;在具有混合关系的场景中,MG-QMIX 得分最高,性能优于QMIX 与COMA。

图5 3 种模型在各场景的训练得分曲线Fig.5 Training score curves of the three models in each scenarios

表1 3 种模型在各场景中的测试平均得分Table 1 Average test scores of the three models in each scenarios
5.1 结果分析
在星际争霸2 微观操控平台中,由于我方每个单位的目标都是统一的对抗敌方,不存在内部资源的竞争,因此是一个单纯合作的场景。实验中将所有智能体的目标都设置为同一个特征向量,也就是单目标场景。QMIX 模型是目前在该平台性能最好的强化学习模型之一。各模型训练超参数设置如表2 所示,在3m、8m、2s3z 地图的胜率对比结果见图5。在智能体构成较为简单的3m、8m 地图中,MG-QMIX 和QMIX 模型都表现出较好的性能,两者胜率基本持平。在智能体数量略多的8m 地图中,各模型的策略稳定性相比3m 地图有所降低。COMA模型在两个地图中胜率略差一些。在智能体种类有较大的差异的2s3z 地图中,COMA 模型无法学习得到一个成功的模型。MG-QMIX 和QMIX 仍有较好的表现,稳定性上QMIX 更好一些,因为MG-QMIX的网络要比QMIX 更为复杂。

表2 各模型在星际争霸2 微观操控平台中的训练超参数Table 2 The training hyper parameters of each models in the StarCraft 2 micro-control platform
星际争霸2 平台的实验结果表明,MG-QMIX 相比QMIX 使用的目标主导的值分解方法对于多智能体合作场景依旧适用,且有优秀表现。
在棋盘游戏中,各模型训练超参数设置如表3所示,3 种模型的得分对比结果见图5。MG-QMIX在训练中学习到了最高24 分的策略,而QMIX 和COMA 模型不能在10 次独立训练中每次都学习到最优策略。实验结果表明了MG-QMIX 在处理混合关系的多目标多智能体合作场景中的优势,可以有效利用各智能体目标信息获得更优的全局成功。
表3 各模型在棋盘游戏中的训练超参数Table 3 Training hyper parameters of each models in board game
在多粒子运动环境中,各模型训练超参数设置如表4 所示,由于cross 地图的环境更为复杂,为得到更直观的结果,延长了训练回合数。各模型在merge和cross 地图上的得分比较结果见图5。在较为简单的merge 地图中,3 种模型都学习到了较高得分的稳定策略,MG-QMIX 的得分最高,并且收敛速度也是最快的。在更为复杂的cross 地图中,COMA 模型的得分表现较差,QMIX 模型得分略好但稳定性较差,MG-QMIX 在得分和稳定性方面都是表现最好的。实验结果体现了MG-QMIX 模型基于目标和注意力机制的值分解方法可以更好地应对多目标多智能体合作场景。

表4 各模型在多粒子运动环境中的训练超参数Table 4 Training hyper parameters of each models in multi-particle motion environment
5.2 消融实验结果
为验证本文方法和模型使用的关键技术的有效性,设置两组消融模型,线性(Linear)模型和无注意力(No Attention)模型。消融模型和本文MG-QMIX在多粒子运动环境merge 地图中的得分对比结果如图6 所示。相较于本文提出的模型,两组消融模型都没有可观的性能表现。

图6 不同模型在多粒子运动环境merge 地图的训练得分曲线Fig.6 Training score curves of different models on merge map in multi-particle motion environment
本文模型的非线性融合方式扩展了对智能体之间的关系模式,提高了值分解的精确程度。然而,线性模型对于智能体关系和值分解的刻画能力有限,只能收敛到一个较低得分的策略,远低于MGQMIX的收敛得分。
本文模型的注意力机制主要用来提取群体影响力特征,该特征在利用目标信息以及完成第一阶段值融合中起到了关键性的引导作用。从无注意力模型的训练曲线中可以看出,智能体策略始终没有收敛,这说明无注意力模型没有群体影响力的引导,无法完成值融合网络中的动作值融合阶段,证明了群体影响力对于值融合的关键作用,也说明了本文选取的键值对于注意力网络可以有效地提取群体影响力这一特征。
上述两组消融实验证明了模型的非线性分解形式和注意力机制对于模型性能的正面作用和必要性。
6 结束语
本文提出一种基于目标信息和注意力机制的多智能体值分解强化学习方法MG-QMIX。为提升强化学习方法在多目标多智能体场景中的性能,采用集中式学习、分布式策略的框架,利用智能体的目标信息实现两阶段的值分解方法,并通过注意力机制提取智能体群体影响力特征,促使网络训练学习。在星际争霸2、棋盘游戏和多粒子运动环境等6 种场景地图上对比了该模型与其他多智能体强化学习方法的表现,结果表明,MG-QMIX不仅保留了QMIX在合作场景中的优势,而且在具有混合关系的多目标场景中仍有优秀性能,消融实验结果也证明了该方法非线性分解和注意力机制的有效性。下一步将考虑增强该方法在更多智能体数量的场景中的拓展性,探索适用于无显式目标或动态目标环境中的强化学习方法。
