A small-spot deformation camouflage design algorithm based on background texture matching
2023-01-18XinYangWeidongXuJunLiuQiJiaHengLiuJianguoRanLiangZhouYueZhangYoubinHaoChaochangLiu
Xin Yang,Wei-dong Xu,Jun Liu,Qi Jia,Heng Liu,Jian-guo Ran,Liang Zhou,Yue Zhang,You-bin Hao,Chao-chang Liu
National Key Laboratory on Electromagnetic Environmental Effects and Electro-optical Engineering,Army Engineering University,Nanjing,Jiangsu,210007,China
Keywords:Camouflage design Small-spot camouflage Adversarial network Texture feature
ABSTRACT In order to solve the problem of poor fusion between the spots of deformation camouflage and the background,a small-spot deformation camouflage design algorithm based on background texture matching is proposed in this research.The combination of spots and textures improved the fusion of the spot pattern and the background.An adversarial autoencoder convolutional network was designed to extract background texture features.The image adversarial loss was added and the reconstruction loss was improved to improve the clarity of the generated texture pattern and the generalization ability of the model.The digital camouflage was formed by obtaining the mean value of the square area and replacing the main color.At the same time,the spots in the square area with a side length of 2 s were subjected to simple linear iterative clustering to form irregular small-spot camouflage.A dataset with a scale of 1050 was established in the experiment.The training results of three different loss functions were investigated.The results showed that the proposed loss function could enhance the generalization of the model and improve the quality of the generated texture image.A variety of digital camouflages with main colors and irregular small-spot camouflage were generated,and their efficiency was tested.On the one hand,intuitive evaluation was given by personnel observing the camouflage pattern embedded in the background and its contour map calculated by the canny operator.On the other hand,objective comparison result was formed by calculating the 4 evaluation indexes between the camouflage pattern and the background.Both results showed that the generated pattern had a high degree of fusion with the background.This model could balance the relationship between the spot size,the number of main colors and the actual effect according to actual needs.
1.Introduction
Pattern painting camouflage is one of the cheapest and most convenient measures among various camouflage measures.At present,various countries and armies generally apply camouflage patterns on the surface of clothing and various equipment.According to different design principles and application ranges,pattern painting camouflage can be divided into protective camouflage,imitation camouflage and deformation camouflage [1].Deformation camouflage is mainly applied to moving targets in the target area,and is widely used in military clothing and movable weapons and equipment.Therefore,it is of great significance to improve design patterns and colors to adapt to larger-scale backgrounds.
The traditional deformation camouflage design is mainly based on large-spot camouflage with 3-5 colors,but the design steps are mostly based on empirical experience.In recent years,many efforts have been devoted to the design convenience of deformation camouflage,but the research on performance improvement is rare.From the perspective of spot size and shape,Cao et al.[2]analyzed the quantitative laws of area,perimeter,elongation,dispersion and overall concavity,etc.,to provide theoretical support for spot shape design.From the perspective of digital image processing,Zhu et al.[3] proposed a calculation method for the brightness and proportion of spot colors,so that the main color extraction process avoided subjective factors and was more scientific.Xin et al.[4]used the Bezier curve to simulate the camouflage spots,and designed an interpolation method to make the generated patterns meet the requirements of randomness and curvature ratio.After 2010,attention has been shifted to the form of digital camouflage.Jia et al.[5] used the mean clustering method to extract the main color and area ratio of the background image,used the Markov random field model to simulate the texture distribution of natural objects,and constructed a digital camouflage pattern design system with pyramid model decomposition.Wu et al.[6] studied the establishment of a spot template library,and used the heuristic nesting algorithm combination to obtain the digital camouflage contour texture map based on the background outline.This algorithm could realize the fast and effective design of digital camouflage.Cai et al.[7] studied the digital camouflage design method based on the 3D model of the equipment,and designed the fivesided expansion of the camouflage pattern based on the fractal Brown model,and formed the 3D effect of the equipment.
Restricted by military confidentiality,the public materials on deformation camouflage mainly focuses on the effectiveness analysis of animal body spots [8,9],and there are very few references related to military applications.However,these studies provide guidance for the design of deformation camouflage.Most of the existing research believes that although high-contrast spots on the bodies of animals such as zebras and tigers match the background in nature,this destructive coloring can impair the detection of predators [10,11],reduce their significance or make it difficult to accurately determine their movements.Trend[12].The Tiger Stripe camouflage of the US military and the DPM camouflage of the United Kingdom can demonstrate this principle [13].In terms of theoretical research,Hughes et al.[14] reviewed the effectiveness of imperfect camouflage applied to different backgrounds,and proposed general setting principles for interference,fraud,and other different backgrounds.
Judging from the current applications of deformation camouflage,there are mainly the following problems.One is the limited effect of large-spot camouflage.In theory,when a large spot appears as less than 3-5 pixels on the imaging film,it can make people unable to detect the difference and thus play the role of deformation and segmentation,while the small-spot camouflage can show the same effect when the imaging distance is closer.The second is that the digital camouflage has a regular outline,which is conducive to spraying operations and not conducive to camouflage at close range.Third,most algorithms separate the main color extraction from the shape design,making it difficult for the generated texture pattern to match the background well.This paper designs a background texture feature extraction algorithm based on deep adversarial autoencoder convolutional neural network.Through the combination of spot contours and detail texture,this algorithm can achieve a highly integrated original camouflage pattern.Finally,according to the difficulty of spraying and application requirements,the following parameters are determined,such as the number of camouflage main colors and the average size of the spots.The overall diagram of the algorithm is shown in Fig.1.The proposed design method has high practicability.Section 1 outlines the necessary design methods of traditional deformation camouflage,and introduces the extraction method of spot contours.In Section 2,the background texture feature extraction algorithm is proposed.Section 3 introduces the idea of clustering and generating small spots.In Section 4,the performance results of the algorithm are discussed.Section 5 makes the summary.
2.An overview of deformation camouflage theory
The mechanism of deformation camouflage is to use the splicing of various color patches to achieve partial region fusion and partial region segmentation of the target and the background,so that irregular contours are visually presented and cannot be effectively recognized.Limited by spraying efficiency and paint color mixing technology,3-5 main colors are usually used.Taking the 3-color camouflage as an example,it is divided into bright spots,dark spots and intermediate spots.Generally,the color difference should be greater than L*a*b*units,and the brightness contrast should be at least greater than 0.2.The brightness coefficientof the intermediate color adopts the principle of protection color,and the calculation method is shown in Eq.(1).

where riis the brightness coefficient of the ith type of spots in the background,and Piis the ratio of the color of the ith type of spots to the total area.In addition,the proportions of the 3-color spots should be consistent with the proportions of the corresponding dominant colors in the background.
If the influence of the target surface is not considered,the spot shape of the deformation camouflage should be characteristically consistent with the background's spot shape.Previous research[15]has determined a GAN-based deformation camouflage spot feature extraction algorithm,which could quickly extract the background spot contour shape with rotation invariance.The spot shape of the generated model was evaluated by characteristic parameters such as rectangularity and aspect ratio [16,17],and the result showed that the spot shape of the background and the pattern were consistent.The generated spot shape had the characteristics of a bad pattern,which damaged the target contour.Based on this,this paper determines the edge contour characteristics of the texture map.
3.Background texture modeling based on adversarial network
The existing texture modeling algorithms can be divided into four methods,i.e.statistics-based[18],modeling-based[19],signal processing-based [20],and texture primitive structure-based [21].Although each method has achieved many achievements,in essence,texture features include multiple mutually coupled features such as color,fineness,arrangement,and periodicity.Through certain assumptions and analytic modeling,the locality of application is obvious.The generative network model was proposed by Goodfellow [22],and is especially good at solving generative models with complex distributions.Background data can provide a large number of samples for this deep learning,so this paper builds a background texture model based on deep adversarial network.
3.1.Overall architecture
The network model consists of 3 parts,as shown in Fig.2.The autoencoder network is responsible for extracting and reproducing texture features.The autoencoder network can be divided into an encoder E1 and a decoder E2.The background image X is input into the encoder E1.The texture feature code L is obtained through calculation.The feature code is then input into the decoder E2 to generate a texture image X~that conforms to the type of background.This process is the main training process.In order to enhance the ability of the autoencoder to learn appropriate texture expression,two auxiliary discriminators are added for adversarial learning training.The discriminator D1 conducts adversarial training on the input latent variable feature L and the random multivariate normal distribution N (0,1) of the same dimension,with the purpose of making the generated features meet the normal distribution as much as possible to facilitate understanding and application.The discriminator D2 conducts adversarial training on the original background image and the generated texture image respectively to supplement the fuzzy shortcomings of the reconstruction loss.
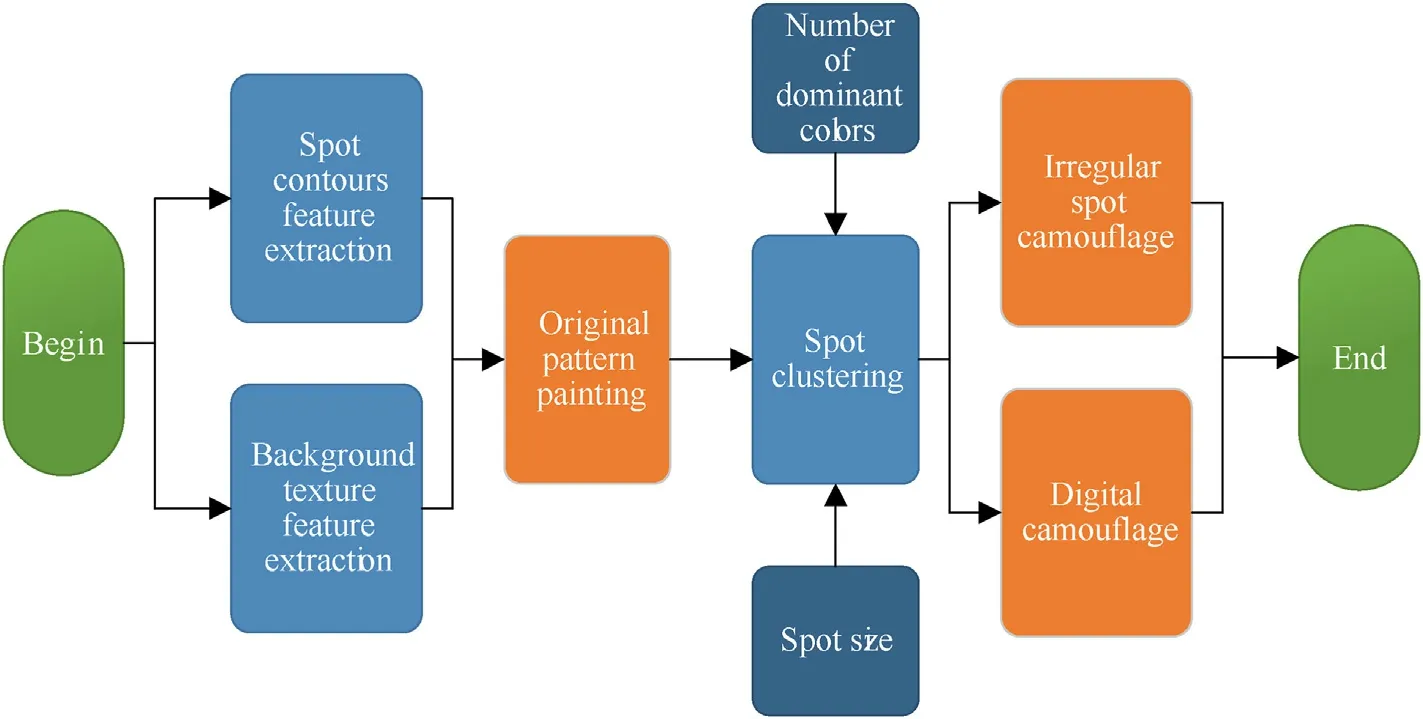
Fig.1.Overall diagram of the proposed algorithm.

Fig.2.The overall architecture of the network model.
3.2.Specific design of network structure
In order to simplify the model,the designed convolutional block structure combination is introduced into the network as the basic unit of the model.Each convolutional block structure includes a convolutional layer,a nonlinear activation layer,a convolutional layer,a nonlinear activation layer,a batch normalization layer,and a pooling layer.Specifically,the kernel size of the convolutional layer is 3*3,and the receptive field can be expanded through multiple feature extraction of the deep network convolution kernel.This setting simplifies the network structure and reduces the amount of network parameters [23].Leaky ReLU function [24] is used in the non-linear activation layer.The traditional ReLU function produces a gradient of 0 for neurons whose output is negative,which will retard the convergence of the model to a certain extent.The Leaky ReLU function introduces a small gradient for negative input to overcome this problem.In this model,the gradient value of the negative region is set to 0.2.After two convolution and nonlinear activation layers,the introduction of batch normalization layers[25,26] can reduce the probability of gradient dispersion and gradient explosion,and accelerate model convergence.In order to prevent the model from generating a big difference in the parameters of the training set and the test set,the attenuation rate of this layer is set to 0.8.
Without the participation of any auxiliary discriminator,the structure of the autoencoder network is optimized only by training the reconstruction loss of the autoencoder network,and the detailed structure of the network is determined,as shown in Fig.3.The background image data size of the input network is 112*112*3,and the output is a texture image of the same size.Through experimental tests,it can be concluded that when the model performs best,the number of neurons in the latent variable layer is 128.The encoder E1 first extracts the basic features of the background image through three groups of convolutional block structures.The numbers of the three groups of convolution kernels are 32,64,and 64,respectively.Through three pooling operations,the output characteristic parameters can be greatly reduced,and the training difficulty can be reduced.Finally,the final feature code is obtained through the dense link layer with the number of neurons of 256 and 128.The structure of the decoder E2 and the encoder E1 are completely inversely symmetrical.The difference is that the deconvolution layer is used in the decoder E2.When the number of neurons needs to be expanded,it can be achieved by setting the step size of the deconvolution kernel to 2.Table 1 shows the parameter quantity and input and output size structure of each block.Through calculation,the autoencoder network needs to train 6,820,161 parameters in total.
Fig.4 shows the structural model diagram of the two sets of discriminator networks.The goal of the discriminator network D1 is to enable the encoder E1 to generate coding features conforming to the normal distribution through adversarial training.After the model training is completed,the texture map can be generated through the decoder network E2 by sampling from the normal distribution.Since the task of judging whether the code belongs to the normal distribution is relatively simple,the model capacity of D1 is small,and it is realized by using a 2-layer densely connected network.The number of neurons in each layer is 512 and 256,respectively,and the activation function also uses LeakyReLU.The goal of the discriminator D2 is to overcome the fuzzy problem of the texture map generated by the reconstruction loss through adversarial training.Consistent with the encoder,the basic features of the background image are extracted through two groups ofconvolutional block structures,and the number of convolution kernels is set to 32 and 16,respectively.Finally,the discriminant results are output through two dense link layers,and the number of neurons is 256 and 1,respectively.The activation function of the last layer of the two discriminators uses sigmoid to make the output range(0,1).Table 2 shows the structure of the discriminator network and the size of its output.
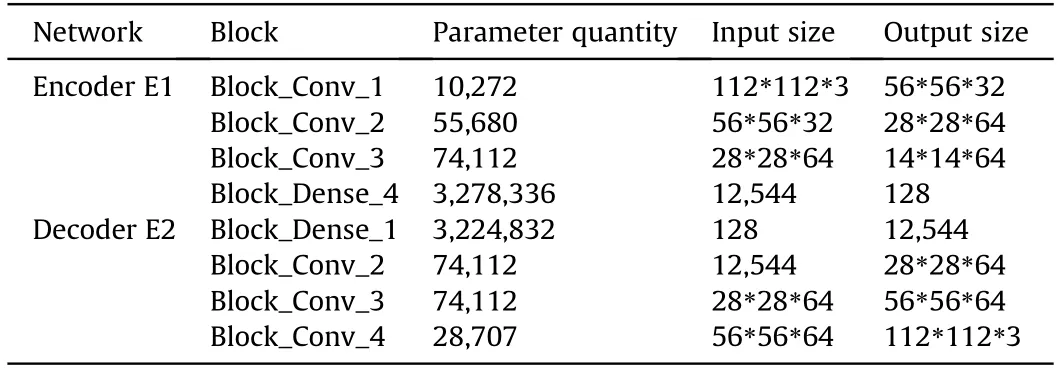
Table 1 Input and output size and parameter quantity of autoencoder network.
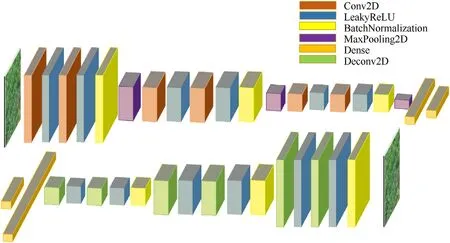
Fig.3.Autoencoder network structure: encoder E1 (top) and decoder E2 (bottom).

Fig.4.The network structure diagram of the discriminator:discriminator D1(top)and discriminator D2 (bottom).
3.3.Loss function and training

Table 2 Discriminator network input and output size and parameter quantity.
The reconstruction loss is used to train the autoencoder.The same type of background image may have a large difference in texture mode.In order to overcome this problem,when constructing the reconstruction loss,not only the original input image is used as the label data,but the surrounding background area of the randomly-sampled original image and the original image are commonly used as tag data.The advantage of this loss function design is that it can add random data,enhance the generalization ability of the model,and make the output texture map consistent.But its disadvantage is that it may cause serious blurring of the generated image.Suppose the input background image is X,the randomly-sampled background image around is X',and the output background image is,then the reconstruction loss lossrcan be calculated by:
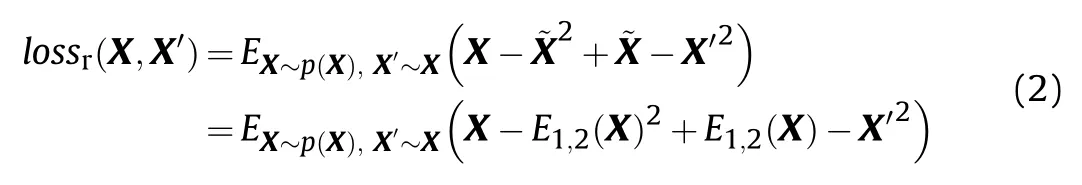
Cross entropy loss is used in the discriminator [27].Let z be a random normal distribution sampling with the same dimension as the feature code,and complete the training process of the entire network through the method of adversarial training.That is,the minimization and maximization of the autoencoder network and the discriminator network are alternately completed.Eq.(3) and Eq.(4) are the loss functions of the discriminators D1and D2,respectively.
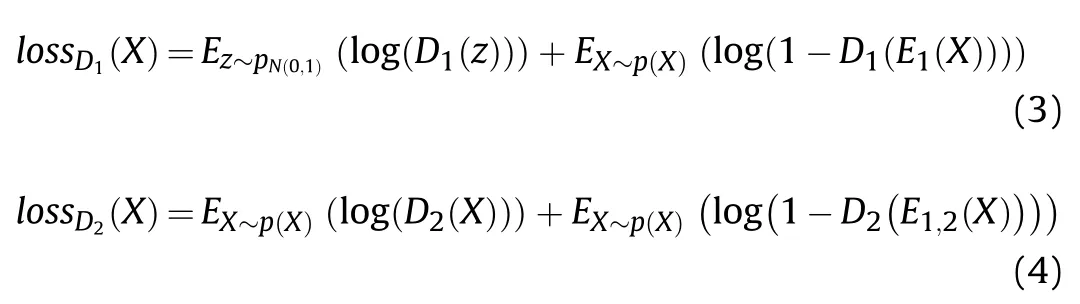
Eq.(5)is the total loss function of the model.In order to facilitate the training of the model,the method of alternate training through the autoencoder and the discriminator is adopted in practice.First,and the discriminator D1is trained by randomly-sampled z and the output of the autoencoder.Then the discriminator D2is trained by randomly sampling the background image X and the corresponding autoencoder output~X.Finally,the parameters of the two sets of discriminators are fixed,and all the loss functions are combined to train the autoencoder network.It is finally determined that when the ratio between reconstruction loss and the damage of the discriminators D1and D2is 85%,10% and 5%,the generated image quality is the best.
When optimizing,Adam[28]is used to implement the gradient descent process.Adam algorithm adds momentum to the RMSprop algorithm,so that the parameters are maintained inertially during gradient descent.The advantage of this algorithm is the understandability of hyperparameters.In this paper,the learning rate parameter is set to 0.002.This is because the model of the adversarial training process is complicated,and too high learning rate may cause the model to collapse.The rest of the parameters all use the default values.
4.Small-spot pattern generation
Small-spot camouflage generally includes digital camouflage patterns with regular shapes and general small-spot camouflage with irregular shapes.After generating the original camouflage map with spot contours and texture patterns,a small-spot camouflage pattern is generated through a spot clustering algorithm.This paper designs an irregular spot generation model and a square digital camouflage spot generation model respectively.
4.1.Square digital camouflage generation
Let the side length of the small square spots be s,the number of all small spots be nsp,and the total number of pixels be ntp.Then the unknown parameter nspcan be determined according to Eq.(6).

Let mi=[ri,gi,bi]T,i=1,2,…,nspbe the color of the ith small spot,and Cibe the scope of the ith small spot with size of s×s.Then the true color of the digital camouflage spots is obtained by obtaining the average color in the Cidomain of the original camouflage pattern.Let z=[r,g,b]represent the color value of a pixel,then the color miof each small square spot can be obtained:

Finally,a camouflage pattern containing only K-type colors is realized by replacing the small spot color with the closest camouflage main color.Suppose the extracted dominant color is Dk,k=1,2,…,K,then mican be updated as:

4.2.Irregular small-spot camouflage generation
Simple linear iterative clustering(SLIC)[29]algorithm is used to generate irregular digital camouflage based on small square spots.Let mi'=[ri,gi,bi,xi,yi]T,i=1,2,…,nspbe the initial cluster center of each small spot.The initial value of mi'selects the center position of the aforementioned small square spot area.In order to prevent the selection of mi'at the edge of the image from being unfavorable for clustering of small spots,mi' is moved to the smallest gradient position in the 3*3 area of each center.The measure between the pixel p in the original pattern and all cluster centers can be recorded as d(p)=where d(p,mi')can be calculated by Eq.(9).
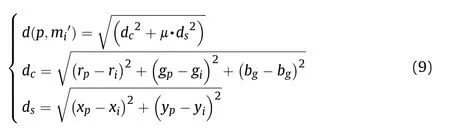
where rp,gp,bp,xp,yprepresent the three primary color components and coordinate position components of the pixel p,respectively;μ is the weight coefficient for determining the position and chromaticity difference.The larger the value of μ,the larger the proportion of the position coordinates in the measurement,and the closer the generated pattern is to the small square spot camouflage.The smaller the μ value,the greater the proportion of color difference in the measurement,and the more irregular shapes are generated.
Iterative calculation is used to generate clustered images.In the first step,in order to simplify the calculation,we calculate the measurement d(p) in the 2 s × 2 s field for all pixels p,which is labeled as L(p)=i.In the second step,let Ci'be the sum of the pixel points marked by the ith type,and Eq.(10) is used to update mi'.The first step and the second step are calculated alternately until the change before and after W is less than the set threshold T.W can be calculated by Eq.(11).

5.Experiment and results analysis
5.1.Dataset establishment
A dataset with a woodland type background as the main and loess background as a supplement was constructed.A DJI Wizard 4RTK optical imaging drone was used to collect the background image of a certain place in Nanjing from the air.The indicators such as visibility and ground illumination at the time of collection were in line with the requirements of relevant Chinese national and military standards.The collection time was about mid-June 2020,and the background area of the collection range covered approximately 9 km2.The flying height of the aircraft was about 120 m,and the ground imaging resolution was about 0.03 m.The number of sampled original images was about 1050.In order to make the data meet the input requirements of the deep neural network,an image area with a size of 112*112 was randomly selected to construct a dataset.The dataset was divided into training set,test set and validation set,with a proportion of 4:1:1.Fig.5 shows some of the images in the dataset,in which the top row is a woodland background,and the bottom row is a desert background.
In order to enhance the capacity of the dataset,the training set was randomly transformed by operations such as rotation,mirror flip and small angle beveling.Through these operations,the scale of the dataset could be expanded 3-5 times.Data enhancement could improve the generalization ability of the model and reduce the risk of overfitting.
5.2.Texture feature generation
In order to explore the impact of adversarial loss on the model,three types of loss functions were used to train the model,and the results after 20,000 batches are shown in Fig.6.Fig.6(a)shows that only the reconstruction loss was backpropagated,and the generated image was not much different from the training set image,but it was blurrier.In Fig.6(b),the random sampling of the surrounding area of the background image was used to simultaneously backpropagate the reconstruction loss.The result showed that the uniformity of the generated texture image was greatly improved,but the degree of blur was also more obvious.Fig.6(c) shows the result of adding a generative adversarial network structure,and the clarity of the image and the uniformity of the texture had been improved to a certain extent.
5.3.Camouflage pattern generation and performance analysis
In order to conduct the comparison of effects,traditional largespot camouflage,digital camouflage and irregular small-spot camouflage were generated respectively,and the results are shown in Fig.7.The traditional large-spot camouflage pattern in Fig.7(a)was generated by extracting the spot shape feature and the main color clustering of the background.According to the combination of background image and on-site sampling,three main color modes of earthy yellow,dark green and light green were determined.The generated texture feature map close to the main color was used to replace the large spot main color,thereby forming the original camouflage pattern as shown in Fig.7(b).Subsequently,the digital camouflage and irregular small-spot camouflage patterns shown in Fig.7(c) and (d) were generated by clustering respectively.Fig.7(e) and (f) and (g) are the camouflage patterns after clustering the multi-color camouflage of Fig.7(c) into 3,5,and 7 main colors,respectively.Similarly,Fig.7(h),(i) and (j) are the camouflage patterns after the multi-color small-spot camouflage of Fig.7(d) was determined with 3,5,and 7 main colors.
According to the generated camouflage patterns,it could be concluded that the model had the following typical characteristics.First,the more the main colors of the generated pattern,the more subjectively obvious the depth of the pattern was,and the closer it was to the real background;both digital camouflage and irregular spot camouflage had this feature.Second,the larger the number of spots,the smaller the average size of connected spots,and the more obvious the color mixing effect of small spots.Third,the small-spot camouflage had a clearer outline feature than the digital camouflage.Fourth,the camouflage patterns of the 5 main colors and the 7 main colors were not obviously different,so the best effect could be obtained by using 5 colors.Fifth,this generation algorithm could quickly determine the final camouflage pattern with the spot size and the number of main colors,which could explain the essential reason for the effectiveness of the camouflage.
Now,the operating efficiency of the model is examined.Based on the 5-color camouflage,the running time of the test algorithm was affected by different spot sizes.The result is shown in Fig.8,where the horizontal axis is the spot size s,and the vertical axis is the time consumed by the algorithm to execute,the red histogram represents the time consumed to calculate the irregular small-spot camouflage pattern,and the blue represents the time consumed to generate the digital camouflage.The pixel size of the generated image was 1100×1100.The computer hardware environment used a 4-core 3.7 GHz CPU and 16 GB memory.In order to dilute the impact of the operating system's task scheduling randomness,the test was performed 10 times and the average value and standard deviation were calculated.Due to the iterative calculation,the irregular spot camouflage had about 25-45 times of calculation more than the digital camouflage.In addition,as the spot size increased proportionally,the time consumed exhibited a negative exponential decrease.Based on the collected background's ground resolution,it could be known that the time for calculating the camouflage pattern with size of 33 m × 33 m was acceptable for general-purpose computers and for most military targets.

Fig.5.Part of the images in the dataset: woodland background (top row),and desert background (bottom row).

Fig.6.Comparison of texture images generated by three different training structures.

Fig.7.Camouflage pattern generation process.
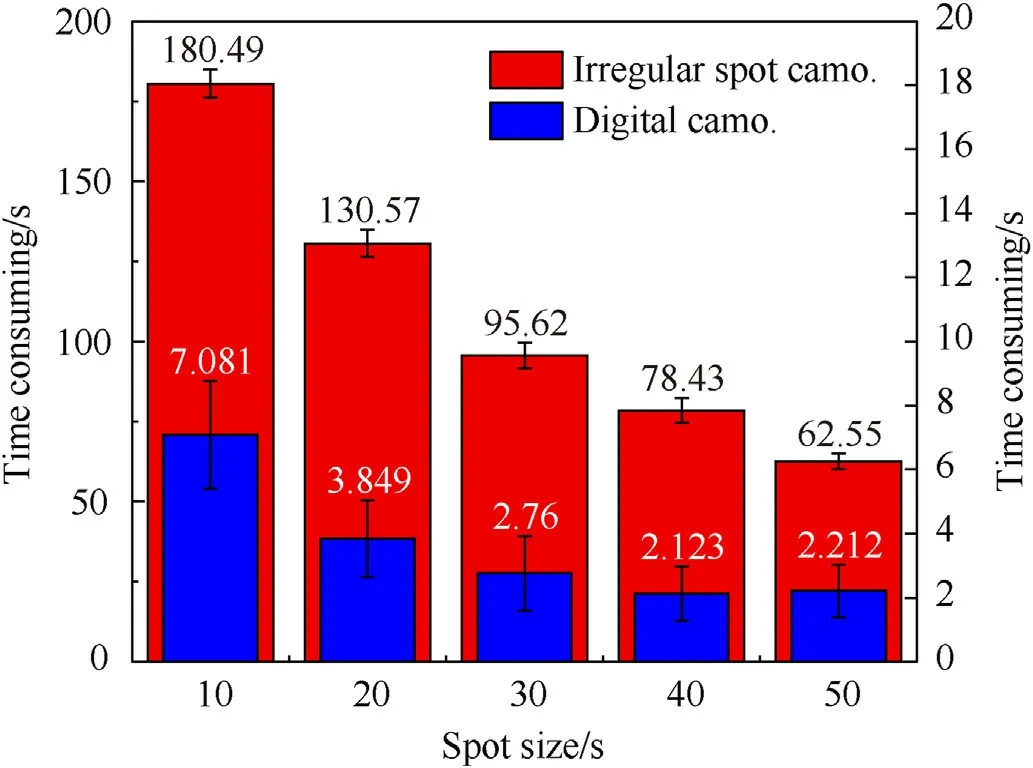
Fig.8.Influence of spot size on the model's operating efficiency.
5.4.Comparison of the effectiveness of different design algorithms
Tests were performed to compare the effects of large-spot camouflage,original deformation camouflage,5-color digital camouflage and 5-color irregular small-spot camouflage in the background,which were numbered as 1-4 sequentially.The research was carried out from two aspects:subjective analysis and objective analysis.The goal of the subjective test is to make 5 military-related professionals observe two materials and give the tagets salience ranking and comments.As shown in Fig.9,The four types of camouflage patterns were randomly placed in the background,and each type of background image was randomly placed in two positions.One of the patterns was as close to the woodland background and the other was close to the desert background.In Fig.9(a),the camouflage design is below the red label.In addition,as shown in Fig.9(b),the contour of the figure was extracted using the canny operator[30]to obtain preliminary features.The result of the statistical majority showed that pattern 1 had the most obvious significance,and the other camouflage patterns 2-4 had lower significance.In contrast,the camouflage effect of pattern 2 was relatively more prominent.Judging from the segmented image,pattern 4 had the best effect,pattern 3 had better long-distance effects and had obvious good graphic characteristics at short distances.Pattern 2 was more obvious,which showed that the average gradient of the generated texture map was relatively large,and there was still room for improvement.On the whole,the generated digital camouflage and irregular small-spot camouflage patterns could form an effective camouflage effect.

Fig.9.The effects of the four types of camouflage embedded in the background.
In addition,from the point of view of the fusion of spots and background,the original camouflage pattern could achieve a high degree of fusion with similar backgrounds and break the regular outline.Under the same visual conditions,the outline of the traditional large-spot camouflage was more obvious,and the effect of the small-spot camouflage was slightly worse than the original camouflage pattern.
The objective evaluation of camouflage effect was mainly completed by quantifying the characteristic difference between the camouflage pattern and the adjacent background to obtain the calculation index.Four indicators of SSIM [31],UIQI [32],CSI [33]and MF-CFI [34]were used for evaluation.Among them,SSIM mainly investigates the structural differences between two grayscale images.UIQI was proposed by Lin et al.Eye movement experiments show that there is a good correlation between this indicator and eye movement data.CSI is used to calculate the color difference between two images.MF-CFI integrates the characteristic differences between the two images such as color,texture and structure.The closer these four indicators are to 1,the better the camouflage pattern effect.
The calculation results are shown in Table 3.SSIM shows that the 5-color digital camouflage had the best fusion with the background,while the original deformation camouflage had the lowest background similarity.Since SSIM does not contain chromaticity information,this result has some reference.Both UIQI and CSI results showed that the original deformation camouflage had the best effect.MF-CFI showed that the original deformation camouflage,5-color digital camouflage and 5-color irregular spot camouflage were less different,and the 5-color irregular spot camouflage was slightly better than the other two.These three indicators all showed that the effect of the large-spot camouflage pattern was significantly different from the other three patterns.In summary,it could be considered that the effect of large-spot camouflage was the worst,and the original deformation camouflage,5-color digital camouflage and 5-color irregular small-spot camouflage all had better effects.
6.Conclusion
This paper proposes a deformation camouflage pattern design algorithm based on background texture matching.An adversarial autoencoder convolutional network model was designed to extract background texture features.Through the combination of spot contours and detail texture,a highly integrated original camouflage pattern was realized.Then according to the proposed simple linear iterative algorithm and the square area average color algorithm,the final irregular spot camouflage and digital camouflage were obtained.A background dataset was constructed.The effects of three loss functions on the effect of texture generation were tested,and the best texture generation model was determined.The traditional large-spot camouflage,the original deformation camouflage,the 5-color irregular small-spot camouflage and the 5-color digital camouflage were generated respectively.The time complexity of these camouflages under different conditions was discussed.The effects of 4 patterns were examined by subjective and objective analysis methods.Subjectively,five military personnel were asked to observe the camouflage images embedded in the background and provide intuitive results.In the objective aspect,four camouflage performance evaluation indicators were used to score the feature similarity between the camouflage pattern and the background.The results showed that the original camouflage pattern had the best effect,the digital camouflage and the small-spot camouflage effect were slightly weaker,and the large-spot camouflage pattern had the poorest effect.

Table 3 Calculation results of camouflage pattern effects based on quantitative indicators.
The advantage of the proposed algorithm is that it can achieve a high degree of fusion of the deformation camouflage spots and the background image in the texture level,and adjust the number of main colors and spot size through the actual spraying difficulty and application requirements.This leads to the controllable performance of the generated small-spot camouflage.The next step is to expand the dataset and optimize the texture generation theory,while focusing on the adaptability and adjustment methods of the algorithm in the context of large differences.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgments
This research was funded by Natural Science Foundation of Jiangsu Province,China,grant number is BK20180579.
杂志排行

Defence Technology的其它文章
- Experimental and numerical analysis on suitability of S-Glass-Carbon fiber reinforced polymer composites for submarine hull
- Damage response of conventionally reinforced two-way spanning concrete slab under eccentric impacting drop weight loading
- Analysis and design for the comprehensive ballistic and blast resistance of polyurea-coated steel plate
- Positive effects of PVP in MIC: Preparation and characterization of Al-Core heterojunction fibers
- Flight parameter calculation method of multi-projectiles using temporal and spatial information constraint
- Numerical simulation of drop weight impact sensitivity evaluation criteria for pressed PBXs