基于改进TextRank的关键句提取方法
2023-01-09陈梦彤谷晓燕刘甜甜
陈梦彤,谷晓燕,刘甜甜
(北京信息科技大学 信息管理学院 北京 100192)
0 引言
如何从大量信息中提取关键信息一直是人们关注的重点,在文本挖掘领域中也至关重要。目前,人们对文本提取关键内容的方法主要是关键词提取和摘要提取。在进行关键词提取时,文献[1-3]在算法中考虑了词性、词语长度、词义和词语边界不同的词特征。文献[4-5]通过学习文本特征并结合语义特征,采取深度学习模型来提取关键信息。文献[6]将图构建与聚类的方法结合提取关键词。然而仅对文本进行关键词提取只能根据词义猜测文本的主要内容,这种方式往往忽略了词语之间的关系,容易误解或者曲解作者要表达的意思,无法准确、直接地获取文本中的主要事件。在进行摘要提取时,文献[7-8]主要根据句子位置、句子之间的关系对算法进行改进。文献[9]提出了LSTM-CNN算法,通过构造新的短语来生成文本摘要。文献[10]使用分层的CNN框架,针对少见或者没见过的单词建立复制机制提取摘要。然而对文本进行摘要提取往往提取的内容较多或者重复,导致无法在第一时间准确高效地理解作者想要表达的信息。针对以上问题,本文提出了一种结合词义、词频及词位置等词特征的改进TextRank算法,目的是用一句话概括文本的主要内容。
目前,有很多学者利用TextRank算法对文本提取关键词和摘要。文献[11]结合文本特征改进了TextRank算法。文献[12-15]将TextRank算法与语义分析相结合进行关键词提取。文献[16]提出了一种基于监督累积TextRank的关键字抽取方法,从边权重、阻尼系数和交互信息三个方面强调词语之间的相关性。文献[17]将主题模型与PageRank算法结合,基于词语的重要性进行关键词提取。由于共现窗口只能关注局部词汇间的关联性,文献[18]对候选关键词做粗糙数据推理,从而提高关键词提取的准确性。文献[19-20]根据句子间相似性、句子位置等特征对文本提取摘要。以上研究在提取关键词或者摘要时,主要是将TextRank算法与词义或文章结构相结合,算法得到的结果比较片面。现有研究中少有将TextRank算法与句意、词义、词频等多种特征相结合的方法,一个句子是由若干词语组成,一个词语就可以影响句意,因此词语和句子对文本内容都十分重要。现有研究中也少有将相似语句进行合并作为关键句候选集的方法,将相同含义的语句进行合并可以降低算法的复杂度。
鉴于此,本文考虑到句子间关系和词语的特征,对TextRank算法进行改进,通过计算句子之间的相似性将相似语句合并得到关键句候选集,并且在考虑词语相似性的基础上统计词频和词位置,对词语设置得分进而选取关键句。改进后的算法能够用一句话准确地概括文本的主要内容,符合文本主题,便于对文本进行分析,从而提高文本分类的准确性。
1 方法与模型
1.1 改进的TextRank算法
TextRank算法是一种图排序算法[7],是由网页重要性算法改进而来。其主要原理是对文本进行分词,将词作为网络上的节点,根据词之间的共现关系建立节点之间的边,计算每个节点的权重并进行排序,选出关键词。但是TextRank算法中并没有考虑到文本自身的特征。每篇文章都是有自身的逻辑,句子之间以及词语之间具有一定关系,将词语以及句子特征与算法结合,得出的结果会更加全面。基于以上内容,本文对TextRank算法进行改进,方法流程如图1所示。
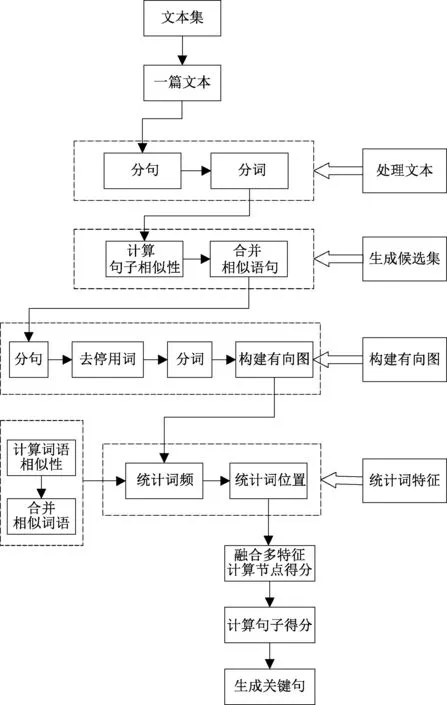
图1 改进后的算法流程图Figure 1 The flow chart of improved algorithm
首先,对文本进行分句、分词的处理,根据句子中的词语计算句子之间的相似度,然后将相似语句进行合并,合并后的语句之间所表达的意义不同,形成关键句候选集。其次,对文本进行分句、去停用词、分词的处理,再将意义相同的词语进行合并,统计每个词的词频以及每个词出现的位置,从而设置每个词语的得分。然后,将关键句候选集中的语句进行分词,按照词语顺序构建有向图,根据词语得分设置节点大小,再计算句子平均分从而选出关键句。
1.1.1合并相似语句 对文本中的语句进行分词后,根据语句中相同词语的个数计算句子之间的相似度。文本表示为C={s1,s2,…,si,sj}(i,j=1,2,…,n),其中:C表示文本;si和sj表示文本中不同的语句。根据语句之间的相似度,对相似语句进行合并,公式为
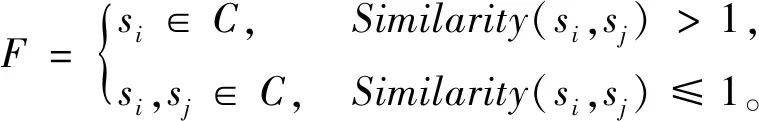
(1)
对语句之间的相似度进行比较。式(1)中:F为合并相似语句后的短文本;Similarity(si,sj)表示句子si和sj的相似度。当Similarity(si,sj)>1时,说明si和sj所表达的句义相近,只留语句si作为代表语句。当Similarity(si,sj)≤1时,说明si和sj所表达的意思不同,不进行操作。将相似语句合并后,剩余的语句相似度较低,所表达意义不同进而形成关键句候选集。其中语句相似度计算公式为
(2)
式中:si和sj为文本中的两个语句;wk(k=1,2,…,n)表示句中的词语。
1.1.2设置词语得分 针对原文本统计词语的特征。先将原文本分句,去除停用词,再对文本进行分词。本文使用Jieba工具包进行分词,根据不同特征综合统计词语得分。
在计算词语得分时,本文主要考虑两个因素:一是词义的词频;二是词语出现的位置。词语得分计算公式为
Twk=Awk+Bwk,
(3)
式中:Twk表示词wk的得分,每个词语的初始得分为0;Awk表示词频对词语得分的影响;Bwk表示词位置对词语得分的影响。
a) 考虑词义的词频
每篇文本都有主题,文本的主体内容是围绕主题展开的,因此文本中的词语与主题息息相关,词语出现的频数可以反映词语的重要性,词语出现的频数越高词语的重要性越高,词语出现的频数越低词语的重要性越低。为了保证文本的用词不重复,作者会使用同义词进行写作,达到同义不同词的效果。针对这种情况,本研究使用Synonyms库来计算词语之间的相似度,将词义相同的词语归为一个词。Synonyms库是中文近义词库,可用于相似度计算、关键字提取、概念提取、自动摘要等多种场景。
基于此,本文将词语出现的频数作为影响词语得分的因素之一。统计每个词语在文本中出现的频数,记为Pwk,词语的得分标准为
(4)
式中:N为去重后词频的中位数。当词语频数大于等于中位数时,词语得分为2;当词语频数小于中位数时,词语得分为1。
b) 词位置
文本一般可分为两部分:标题和正文。有些标题可直接揭示文本的主题,因此标题中的词语具有一定的重要性。然而正文主要是对主题的详细叙述,介绍了事情的背景、起因、经过、结果,读者需要通读全文才能提取文章主题。因此标题中出现的词语重要性高于正文中出现的词语。
本文将词语出现的位置作为影响词语得分的因素之一。统计每个词语在文本中出现的位置,词语的得分标准为

(5)
由式(5)可知,当词语出现在标题或者标题和正文中,词语得分为2;当词语仅出现在正文中,词语得分为1。
综上所述,每个词语得分由两部分组成,且每个词语得分有四种可能性:当词语的词频低于平均值且词语仅出现在正文中,词语得分为2;当词语的词频低于平均值且词语出现在标题或标题和正文中,词语得分为3;当词语的词频高于平均值且词语仅出现在正文中,词语得分为3;当词语的词频高于平均值且词语出现在标题或标题和正文中,词语得分为4。
1.1.3构建有向图 对关键句候选集中的语句进行分词,按照句子中词语先后顺序建立网络图G(V,E),主要步骤为:
a) 对候选集中的语句进行分句;
b) 对句子去除停用词,再使用Jieba工具包进行分词,词语作为网络图的节点V;
c) 根据句子中词语出现的顺序建立有向边E,有向边的方向为V1→V2,V1表示先出现的词,V2表示后出现的词。
一个节点可以有多条边,但是相同的词语只能作为一个节点。根据以上步骤建立有向图,可以直观反映出词语之间的顺序,结果如图2所示。根据词语得分设置节点大小,最终生成的有向图可直观反映词语得分,节点越大表示节点得分越高,如图3所示。
随机选取一篇新闻,使用本文提出的方法构建有向图,新闻原文如图4所示。根据新闻内容生成的有向图如图5所示,生成的带有节点得分的有向图如图6所示。根据图6可以看出,得分较高的词语为“合格”“家用”“灶具”“燃烧”“不”。

图2 有向图示例Figure 2 Example of directed graph

图3 带有节点得分的有向图示例Figure 3 Example of directed graph with node scores

图4 新闻示例Figure 4 Example of news

图5 有向图Figure 5 Directed graph

图6 带有节点得分的有向图Figure 6 Directed graph with node scores
1.1.4选取关键句 文本中每个句子中包含的词语数量不等,为了使每个句子的得分公正,通过计算句子平均分的方法对句子进行评分,句子得分的计算公式为
(6)
式中:Tsi表示句子si得分;m表示句子si中包含的词语数量。
最终从关键句候选集中,根据句子得分选取关键句,关键句选取的公式为
Ksr=Max{Ts1,Ts2,…,Tsi},
(7)
式中:Ksr表示关键句的得分;sr为关键句。以图4中新闻为例,选取的关键句为 “北京家用灶具一半燃烧不合格”。
2 实验
为验证改进后的TextRank算法的准确性,本文设置了对比实验,将提出的算法与传统TextRank算法、TF-IDF算法、基于词频统计的关键句提取算法进行比较。文本是由多个句子组成,有些句子表达的意义相同,只是用词或者表达方式不同,因此,在比较算法准确性时,本文会用两种判定标准进行对比:一是关键句与人工标注结果是否完全一样;二是关键句与人工标注结果是否意义相近。
2.1 实验数据
本文的实验数据来自搜狐新闻、公益中国、人民网的200篇新闻文本,对新闻进行标注,根据新闻内容从新闻中选取一句话作为关键句。
2.2 对比实验
使用本文提出的算法、传统TextRank算法、TF-IDF算法以及基于词频统计的关键句提取算法,分别对不同新闻提取一句关键句,然后比较每种算法结果的准确性。
传统TextRank算法是基于网络图的算法,考虑了句子间相似性,根据句子相似度设置无向有权图,选取关键句。TF-IDF算法是基于词频的算法,通过计算词频以及逆文档频率选取关键句,包含关键词最多的句子就是关键句。基于词频统计的关键句提取算法是根据词频计算词语得分,再计算句子得分,最终选取分数最高的句子为关键句。四种算法的实验结果如表1所示。

表1 不同算法实验结果Table 1 Experimental results of different algorithms
实验结果表明,改进后的TextRank算法在提取一句关键句时准确率明显优于其他算法,改进后的算法提取的关键句与人工标注结果完全一样的数量以及结果意义相近的数量都高于其他三种算法,因此改进后的算法可以更准确地获取文本的主要内容。
3 结论
本文提出的算法考虑了句子间相似度和词语特征,通过对文本中的相似语句进行合并使得文本内容更加精炼,该方法不仅可以提高算法的准确性,还可以降低算法的时间复杂度。此外,在考虑句子间相似性的同时也考虑了词语特征,主要包括词义、词频以及词位置,并且将词义与词频相结合,避免了因词语意义相近,但表达方式不同而影响结果的问题。与传统TextRank算法只考虑句子之间的关系,TF-IDF算法只考虑词频,基于词频统计的关键句提取算法只根据词频对句子进行打分相比,本文提出的方法将词特征和句义全部考虑到算法中,提高了关键句提取的准确性,有助于在较短时间内挖掘文本的主要内容。在进一步的研究中,可以将改进后的算法应用到更多场景中,使其可以针对不同语言种类进行关键句提取。
