基于改进Faster R-CNN的航空发动机制件表面缺陷检测算法
2022-12-29唐嘉鸿黄颀田春岐
唐嘉鸿,黄颀,田春岐
(1.中国航发上海商用航空发动机制造有限责任公司,上海 201306;2.同济大学电子与信息工程学院,上海 201804)
0 前言
航空发动机是航空器的核心,是航空器安全飞行的重要保证。而发动机零部件在制造中难免会产生一些缺陷,轻则影响发动机的使用性能和使用寿命,重则危害到航空器的飞行安全,因此在零部件制造中对其进行缺陷检测以保证零部件的高质量具有重要意义。
传统的缺陷检测方法分为人工检测和传统机器检测,人工检测效果易受检测人员的经验、疲劳程度等因素影响,且检测效率低;传统机器检测需要根据检测目标的特性设计相应的检测方案,研发周期长,且方案难以迁移,泛化能力较差。
LUO等[1]运用选择性显性局部二值模式(Selectively Dominant Local Binary Patterns,SDLBPs)算法对热轧带钢的表面缺陷进行分类,以获得更高的分类精度和时间效率,但未能实现目标缺陷检测。ZHANG等[2]提出了一种正弦相位光栅投影方法来检测连铸坯中裂纹的深度和表面轮廓,该方法适用于检测连铸坯表面的缺陷。卷积神经网络和深度学习算法在目标检测领域取得了飞速的发展,为实现高准确性、高效率的零件表面缺陷提供了新的解决方案,许多学者提出了“深度学习+缺陷检测”方法。ZHANG等[3]使用YOLOv3对钢带表面缺陷进行检测,但由于未考虑单阶段检测模型训练过程中样本不平衡问题,故最终检测精度较低。DONG等[4]提出金字塔特征融合和全局上下文关注网络(Pyramid Feature Fusion and Global Context Attention Network,PGA-Net),但由于未考虑单一尺度特征图不利于多尺度缺陷检测,因此最终检测精度依旧较低。王海云等[5]使用融合特征提取网络将低层特征图的位置信息融合进高层特征图,但其同样未考虑单一尺度特征图不利于多尺度检测问题,并且由于融合特征提取网络引入较多的计算量,因此模型的检测精度和检测速度难以满足实际应用需求。LI等[6]在Faster R-CNN加入特征金字塔模型对不同层级特征图进行融合以提高检测精度,并根据候选框尺度截取对应层级的特征图,该模型在传统目标检测中检测精度有较大提升,但在航空部件的缺陷检测中效果并不好,仍有较大改进空间。
在此次研究中,由于实际生产数据未脱敏,同时也为了更好地和其他模型进行比较,本文作者选取和实际制件数据较为接近的东北大学钢带表面缺陷公共数据集NEU-DET[7]作为研究对象,提出一个基于Faster R-CNN的改进模型(如图1所示)。该模型使用深度残差网络ResNet-50[8]作为卷积部分提取缺陷特征,使用含有内容感知重组算子(Content-Aware Reassembly of Features,CARAFE)[9]的特征金字塔结构以对不同层次特征进行更好的融合,并使用RoIAlign结构[10]根据检测框尺度选取对应层次的特征图以提高模型对小尺度缺陷的检测效果,在RCNN部分使用基于交并比(Intersection over Union, IoU)的分层采样挖掘难例样本,增强模型对难例样本的学习。在实验过程中,文中仅对原数据集进行旋转、翻转操作扩充数据集并与在此数据集上表现最好的模型[6]进行对比实验。

图1 基于Faster R-CNN的改进模型
1 Faster R-CNN原理及改进方向
GRISHICK等[11-13]提出的R-CNN、Fast R-CNN、Faster R-CNN构建了双阶段检测模型的基本检测流程,即通过卷积结构提取原图对应的特征图,使用区域建议网络(Region Proposal Network, RPN)生成一系列候选框并对候选框内容所对应的特征图进行初步前景背景预测,选取含有前景概率较高的部分候选框进行检测,筛选去重后输出检测结果并对候选框位置尺度进行微调。因此,双阶段模型可以分为3个模块:(1)卷积结构,用于提取特征;(2)RPN网络,用于生成候选框;(3)RCNN结构,用于对候选框内容分类并对候选框位置尺度进行微调。
Faster R-CNN作为双阶段检测模型的代表作,后续对它改进也基本围绕以上3点进行。比如由于Faster R-CNN使用最后一层特征图进行检测,对小目标检测效果不好,故LIN等[14]提出特征金字塔模型(Feature Pyramid Network,FPN),在卷积部分增加特征金字塔结构,通过融合高低层特征丰富低层特征图语义信息并根据候选框尺度从对应层级选取特征图,解决了多尺度目标检测问题;常规RPN网络根据预设的尺度和长宽生成候选框,候选框的质量对后续检测精度有较大影响,REDMON和FARHADI[15]提出的Yolov2使用聚类方法挖掘数据集中检测框尺度和形状的先验知识用于候选框的生成,为RPN网络如何更好地利用数据集先验知识提供了新的思路;RCNN结构较好的检测效果依赖于高质量的训练,其训练过程所使用的候选框通过从RPN网络生成的候选框中采样获得,相关研究发现对候选框中难例样本的学习可以显著提高RCNN检测能力,因此SHRIVASTAVA等[16]提出在线难例挖掘算法(Online Hard Example Mining,OHEM),通过增强模型对难例样本的学习从而提高模型整体的检测能力。
2 基于Faster R-CNN的改进模型
文中针对上述3个改进方向进行实验研究,发现卷积结构的特征提取效果和难例挖掘的策略选择直接影响到模型的检测效果。因此,文中在现有Faster R-CNN改进基础上做了进一步改进,在卷积部分引入含有内容感知重组算子的FPN网络代替常规的FPN网络,使用学习的方式实现特征图上采样过程,在难例挖掘部分使用分层采样的挖掘策略代替OHEM优化RCNN结构的训练,将模型的召回率提高到99%以上,基本满足实际应用的要求。
2.1 含有内容感知重组的FPN网络
FPN网络的结构如图2所示,它包含两部分:第一部分是自底向上的过程,通过下采样操作实现,如卷积操作;第二部分是自顶向下和侧向连接的过程,其中自顶向下通过上采样操作实现。最常规的上采样操作为插值和转置卷积操作,插值使用距离衡量特征点之间的关系,但插值法只适用小邻域的上下文信息,不能很好地融合不同层特征图信息;转置卷积使用学习方式自适应计算特征值,但需要进行大量计算,增加了模型训练难度。

图2 特征金字塔结构
WANG等[9]提出一种轻量级上采样算子——内容感知重组算子用于融合较大范围局部信息并进行重组。假设给定一个尺度为C×H×W的特征图X且上采样比率为σ,使用CARAFE算子将获得一个尺度为C×σH×σW的目标特征图X′。对于目标特征图X′上每个目标位置l′=(i′,j′),在源特征图X上都有一个对应的源位置l=(i,j),其中i=[i′/σ],j=[j′/σ]。N(Xl,k)表示在特征图X上以源位置l为中心、大小为k×k的局部特征图,即Xl的邻域。

Wl′=ψ[N(Xl,kencoder)]
(1)
(2)

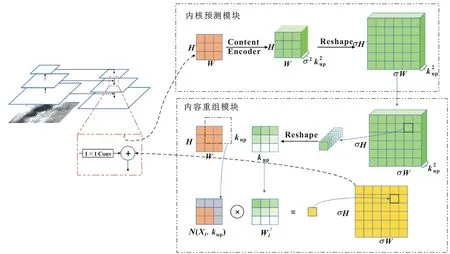
图3 内容特征重组整体框架(灰色部分为填充0操作)
内容感知重组模块φ使用重组内核Wl′对源特征图X上的局部信息通过卷积操作进行融合。对于目标位置l′和对应的以l=(i,j)为中心的局部特征图N(Xl,k)的融合操作如公式(3)所示,其中r=⎣kup/2」。
(3)
重组内核使得N(Xl,kup)区域中每个特征点都根据其特征内容而非距离为目标特征点l′提供信息,因此重组后的目标特征图的语义信息比仅采用插值所得到的特征图更加丰富;相比转置卷积的方式,CARAFE算子大大减少了计算量,降低了训练难度,有效提高了后续检测效果。
2.2 分层采样
Faster R-CNN在梯度反传时通过对候选框随机采样以减少计算量,而相关研究发现对候选框中难例样本的学习可以有效提高模型的检测能力。检测领域最常用的难例挖掘方法为OHEM采样,OHEM采样算法通过loss值来挖掘难例,选取loss值最高的k个候选框用于模型训练,其理论依据为难例样本容易漏检误检,对应的loss值较高。然而loss值很高的样本除了可能是难例样本外,还有可能是漏标、误标带来的噪声样本,使用噪声样本进行训练会导致模型负优化。
在实验中,文中发现NEU-DET数据集可能存在漏标情况,如图4所示。为了挖掘难例样本并减少噪声标签带来的负优化影响,文中使用IoU比值作为难例样本的衡量条件,即对于前景候选框,它与真实检测框IoU越小则越难检测,对于背景候选框,它与真实检测框IoU越大越难以检测,并使用分层采样以获取用于训练的样本。具体流程为:(1)计算每个候选框和它对应真实检测框的IoU并进行排序,和所有真实检测框的IoU小于0.5的视作背景候选框;(2)根据IoU值将候选框分为3组,并分别对每组进行随机采样;(3)将随机采样的结果汇总用于模型训练。由于NEU-DET数据集没有误标,所以使用IoU作为难例衡量标准可以有效地减少噪声标签带来的负优化影响,使用分层采样可以确保训练样本中含有固定比例难例样本。实验结果如表1所示,结果表明使用分层采样算法的模型较使用OHEM算法在召回率和平均精度均值δmAP上有较大提升。

图4 漏标样本(蓝框为原标注,红框为漏标缺陷区域)

表1 使用OHEM算法和分层采样算法的结果对比 单位:%
3 实验及分析
为了验证此模型的可行性和优势,文中使用NEU-DET数据集进行实验。
3.1 NEU-DET数据集
NEU-DET是钢带表面缺陷数据集,包含6种缺陷类别,分别为裂纹(Crazing)、夹杂(Inclusion)、斑块(Patch)、点蚀表面(Pitted Surface)、轧制氧化皮(Rolled-in Scale)、划痕(Scratch),每种缺陷含有300张分辨率为200像素×200像素的灰度图片,总样本数为1 800。数据集同时提供每张图片所对应的缺陷标注信息的XML文件,标注信息包括缺陷所属类别与边界框的信息(矩形框左上角和右下角的坐标信息),共计4 189个边界框。图5所示为NEU-DET数据集中6种表面缺陷图像的示例样本。

图5 NEU-DET数据集缺陷样本示例
为了保证模型对每类缺陷都经过充分训练和测试结果客观性,文中选择对每类缺陷随机抽取70%作为训练集,20%作为验证集,10%作为测试集,并且分别对训练集、验证集、测试集进行旋转和翻转扩充,数据增强结果如图6所示。通过先抽取再扩充的方法既可以保证模型训练充分,又可以在确保训练集、验证集、测试集互相独立,且在不改变样本分布的情况下增加测试样本数以更好地评估模型表现,实验结果如表2所示。

图6 数据增强效果(翻转、旋转)

表2 有无数据增强的实验对比结果 单位:%
3.2 评价指标
文中选择召回率rRecall和平均精度均值δmAP作为模型的评价指标,其公式分别如下:
(4)
(5)
(6)
式中:aTP表示一个实例为正例且被预测为正例;aFP表示一个实例为负例且被预测为正例;aFN表示一个实例为正例且被预测为负例。
3.3 实验结果
实验采用的硬件配置为GTX1080Ti显卡,软件环境为CUDA10.1、Cudnn7.6.4,每个批次使用8张图片进行训练,使用含动量的随机梯度下降优化参数,学习率为0.2,动量为0.9,权重衰减速率为0.000 1,每个模型共训练36轮。实验结果如图7及表3所示。

图7 各类别检测结果示例(蓝框为原标注,绿框为模型检测结果)

表3 不同算法实验结果对比 单位:%
从表2、表3中可以看出:文中的模型在NEU-DET数据集上的δmAP和召回率均高于先前表现最好的Faster R-CNN+FPN[6]模型。在引入含有内容感知重组的FPN结构和基于分层采样的难例挖掘后使得检测的召回率均达到99%,模型检测速度为33帧/s,满足了航空制件对缺陷检测召回率和速度的要求。
文中对模型进行消融实验以具体分析每个模块对模型检测效果的提升,实验结果如表4所示。

表4 消融实验结果 单位:%
通过表4可以看出在FPN结构中引入CARAFE模块使得模型检测的δmAP提升了2.6%,模型对各缺陷的检测召回率均提升至98%以上。引入CARAFE模块改善了FPN上采样过程,有效丰富了各层级特征图的语义信息,这表明特征图语义、图像信息丰富程度直接影响模型最终的检测效果。
通过表4可以看出使用基于IoU的分层采样使得模型在使用CARAFE模块的情况下,其δmAP提升了1.5%,召回率提升至99%以上,而使用OHEM却导致模型负优化,说明仅根据loss值大小来挖掘难例会导致将负类误判为难例,而通过计算IoU值挖掘难例则可以有效地规避根据loss大小判断难例的缺陷,并且根据IoU值判断是否为难例也更符合候选框回归的思想,即让候选框向与之最接近的检测框回归。而根据IoU值进行分层采样的思想更类似于对随机采样和难例挖掘的折中,可以规避随机采样导致的难例样本过少和OHEM导致的将负类误判为难例的问题,通过分层采样的方法能够确保难例样本在训练样本中的比例,确保模型训练可靠。
4 结束语
文中从双阶段目标检测流程出发,根据航空制件表面缺陷检测问题,提出一种改进Faster R-CNN算法,使用含有内容感知重组模块的FPN更好地融合高低层特征,丰富各层级特征图的信息,并且使用基于IoU的分层采样以挖掘难例样本,提升模型的训练质量,检测准确率达到93.9%,各类缺陷召回率均高于99%,检测速度达到33帧/s,文中所提算法有效提升了航空制件缺陷检测的准确性和效率。在消融实验中发现特征图的质量对检测效果有直接影响,未来将尝试借鉴神经架构搜索(Neural Architecture Search,NAS)的思想[17],探索新的卷积结构和FPN结构以增强特征提取质量。
