基于Soft-NMS的候选框去冗余加速器设计*
2021-05-11李景琳姜晶菲许金伟
李景琳,姜晶菲,窦 勇,许金伟,温 冬
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
21世纪,目标检测算法[1 - 5]作为计算机视觉领域的经典应用获得飞速发展,走向成熟。然而,大规模的存储和浮点运算限制了目标检测算法的广泛应用,如何将目标检测算法部署到功率、资源受限的实时边缘化检测系统中成为新的研究热点。通常,目标检测算法分为前处理、特征提取和后处理3个部分,其中后处理主要使用非极大值抑制算法NMS(Non-Maximum Suppression)去除卷积神经网络输出的冗余候选框,找到最佳的目标位置,提高检测的准确率。文献[6]的研究表明NMS在基于RPN+Fast-R-CNN网络的目标检测应用计算任务中占22%左右计算延迟,因此对NMS的量化与加速也很值得研究。
文献[7]中给出了最常用的Hard-NMS方法,将所有的候选框按得分值从高到低排序,选取得分值最高的候选框(本文称为靶候选框),删除所有与靶候选框的重叠率超出阈值(本文设为Nt)的候选框,对未删除的候选框选取得分值最高的继续此操作。Hard-NMS是一种高复杂度的贪心算法,反复迭代计算候选框的重叠率给算法带来了巨大的延时。不仅如此,Hard-NMS是一种基于唯一固定阈值的方法,当图像中2个目标物体的重叠率大于Nt时,Hard-NMS会直接删除得分值较低的目标物体的候选框,导致检测精度受损。
针对这个问题,文献[8,9]提出了一些改进方法,其中文献[9]提出的Soft-NMS最为简单,与Hard-NMS中直接删除大于预定义阈值候选框的方法不同,Soft-NMS使用一个衰减函数逐步减小候选框得分值。文献[9]认为Soft-NMS是非极大值抑制算法的广义版本,Hard-NMS是使用不连续的二值加权函数作为衰减函数的特例,其衰减函数如式(1)所示,当然使用线性函数和连续的高斯函数效果更佳,其衰减函数分别如式(2)和式(3)所示:
(1)
(2)
(3)
其中,M表示靶候选框;bi表示第i个候选框,得分值为si;iou(M,bi)为bi与靶候选框的面积交集与面积并集的比例,表示bi与靶候选框之间的重叠率;线性函数使用(1-iou(M,bi))作为惩罚系数;高斯函数为连续函数没有预定义阈值Nt,但存在预定义参数σ;D为靶候选框的集合,表示后处理阶段的输出候选框结果。
实验表明,在标准数据集PASCAL VOC2007(较R-FCN和Faster-RCNN提升1.7%)和MS-COCO(较R-FCN提升1.3%,较Faster-RCNN提升1.1%)上使用Soft-NMS检测精度均有提升。但是,Soft-NMS仍然是一种复杂度较高的贪心算法,逐步减小候选框得分值不仅增加了大量的浮点计算,而且还使得Soft-NMS无法像Hard-NMS一样用提前排序的方法代替迭代选取最大值的方法。Soft-NMS每轮遍历之后必须重新调整得分值的排列顺序,使得算法的并行难度大大增加。
仅在CPU平台上实现Soft-NMS计算延迟过高,不能满足目标检测任务对性能的要求,因此本文尝试使用异构计算来加速算法,提高吞吐率。Soft-NMS频繁修改得分值的特点使得GPU平台的异构加速方法在付出大量功耗的代价下却无法发挥其高度并行的优势。为了实现性能、功耗和成本之间的平衡,本文使用高性能、低成本、低功耗的FPGA平台实现一种低延时、高效率的Soft-NMS专用加速器。
本文提出一种基于Soft-NMS的加速器体系结构,设计了一种基于细粒度流水线的重叠率计算单元PE(Processing Element),并利用对数函数将计算单元中所有的浮点乘除运算转换为定点加减运算;在加速器中加入一个最值模块,设计了一种基于粗粒度并行的2级并行结构:包括计算单元组的循环级并行和最值模块与计算单元组之间的模块级并行。根据最值模块与计算单元组之间计算速度不匹配的特性,设计了一种预取最值的方法,将可能作为下一轮遍历靶候选框的候选框预先取入缓冲队列,节约排序时间。Soft-NMS加速器充分利用细粒度流水和粗粒度并行组成2级优化结构提升算法的吞吐率,在KU-115 FPGA开发板上对COCO_2017数据集进行评估,与CPU实现的Soft-NMS相比,该体系结构实现了36倍的性能加速比。
2 相关工作


Figure 1 Two Hard-NMS acceleration methods图1 2种Hard-NMS加速方法
3 基于Soft-NMS的加速方法
在目标检测任务中,卷积网络输出的候选框得分值是乱序的,上述2种方案都是用提前排序候选框的方法代替每轮迭代选取最大得分值候选框的方法,而排序操作的计算复杂度为O(N2),计算延时是不可省略的。本文分析Soft-NMS具有频繁修改得分值的特点无法提前排序,于是加入一个最值模块在每轮遍历后选取得分值最大的靶候选框;为了节约排序时间,提出最值模块与计算单元组并行计算的策略。但是,最值模块比计算单元组的计算速度快,并且最值模块与计算单元组之间存在数据相关,即最值模块选出的靶候选框可能被计算单元组视为冗余候选框删除,于是本文设计一种预取最值的方法:每轮遍历中,最值模块将前k大候选框预先取入缓冲队列中,每轮遍历结束后,从缓冲队列中直接获得下一轮遍历的靶候选框,节约选取靶候选框的时间。如果下一轮的靶候选框存在缓冲队列中则称为命中靶候选框,命中靶候选框的概率称为命中率。当命中率较高时,排序时间几乎可以完全省略。
为了节约中间数据的存储空间,与文献[11]中的方法类似,本文也使用基于位置的位表J来存储候选框的状态信息。不同的是位表J需要使用2位状态位表示“0”“1”“2”3种状态。候选框与位表之间是一对一映射,该位置写入“2”表示该候选框得分值低于阈值被删除或者该候选框被选为靶候选框被输出。对于被标记为“2”的候选框后续将不再进行任何操作。该位置写入“1”表示在当前轮遍历中该候选框与靶候选框的重叠率大于Nt,该候选框的得分值经衰减函数修改,但修改后的得分值大于阈值θ。对于被标记为“1”的候选框下一轮遍历开始之前需要将状态位的值从“1”修改为“0”。该位置写入“0”表示该候选框与靶候选框的重叠率小于Nt,不属于冗余候选框,不进行任何处理或者表示位表为初始化状态候选框,还未被处理。
如图2所示本文方法的步骤为:第1步,位表J所有的元素都初始为“0”,使用最值模块比较出得分值最大的靶候选框。第2步,计算靶候选框与其它候选框的重叠率(本文将此过程称为一轮遍历),同时最值模块继续比较出得分值前k大的候选框序列作为下一轮遍历可能的靶候选框预先存入缓冲队列中。以候选框dy为例,计算重叠率的方法为:首先判断,如果靶候选框与dy的重叠率高于阈值Nt,则候选框dy的得分值将被衰减函数修改,并且在位表中的状态位从“0”修改为“1”,如第1轮遍历中b3的得分值被修改;如果重叠率低于阈值Nt,则dy的得分值和在位表中的状态都保持不变。
接着判断,修改后dy的得分值是否小于阈值θ,如果是则候选框dy的得分值修改为零,并且在位表中的状态位修改为“2”,如第2轮遍历中b6所示,否则dy的得分值和状态位都保持不变,如第1轮遍历中b6所示。靶候选框与自身的重叠率为1,衰减函数必定将其得分值修改为0,小于阈值θ,因此它在位表中的状态位修改为“2”,如第1轮遍历中b1所示。第3步,当一轮遍历结束后,如果从前k大的候选框缓冲队列中命中靶候选框,即找到位表J的状态位为“0”的得分值最大的候选框则可以直接开始下一轮遍历,否则需要重新调用最值模块比较出靶候选框。第4步,将位表J中所有状态位为“1”的值修改为“0”,继续执行第2步。重复这些步骤,直到位表J中所有的状态位全为“2”时停止。

Figure 2 Soft-NMS acceleration method图2 Soft-NMS加速方法
4 硬件设计
基于Soft-NMS的候选框去冗余加速器由DDR4、控制器、最值模块MAX、位表J、计算单元组(Computation Unit)、片上存储BRAM(Block RAM)和靶向模块Target组成,加速器整体结构如图3所示。控制器负责接收来自主机的指令,控制加速器的状态;最值模块MAX负责选择出N个候选框中得分值最大的候选框;位表J用于记录N个候选框状态信息;计算单元组由S个PE组成,负责计算靶候选框与N个候选框的重叠率并修改候选框的得分值和位表J的状态信息;片上存储BRAM由RAMA、RAMB和RAMC组成,用于存储输入数据和中间结果;靶向模块Target负责计算每轮遍历的靶候选框。

Figure 3 Architecture of hardware accelerator based on Soft-NMS图3 基于Soft-NMS算法的硬件加速器整体架构
加速器启动时,片上存储BRAM、位表J被初始化。其中位表J被初始化为全“0”,RAMA接收来自DDR4的N个候选框的坐标数据并将其发送到计算单元组,RAMB接收来自DDR4的N个候选框得分值数据并将其发送到计算单元组和RAMC。接着在每一轮遍历中,最值模块、计算单元组和靶向模块3个模块同时并行工作,去除冗余候选框。RAMC接收RAMB的N个候选框的得分值数据并将其发送到最值模块,最值模块接收RAMC的N个候选框的得分值数据,计算出前k大得分值,并将其发送到Target;Target计算出得分值最大的靶候选框后,从RAMA中获取靶候选框的坐标数据,将靶候选框得分值数据和坐标数据发送到计算单元组和主机;计算单元组分批(每批S个候选框)接收RAMA中S个候选框的坐标数据、RAMB的S个候选框的得分值数据、位表J中S个候选框的状态信息和来自Target的靶候选框坐标数据,将计算得到的候选框得分值发送到RAMB、状态信息值发送到位表J中。当N个候选框的重叠率计算完成时,一轮遍历结束。每轮遍历结束后位表J中所有状态位为“1”的值修改为“0”。位表J中所有的状态位全为“2”时加速器停止,Soft-NMS就完成了。主机使用PCIe传输通道发送N个候选框的坐标数据和得分值数据到DDR4,接收Target的靶候选框的坐标数据和得分值数据并将其发送到主存。
本文针对Soft-NMS的计算特性提出一种细粒度流水和粗粒度并行结合的2级优化结构。为了提高资源利用率,减小实现面积和降低功耗,本文设计一种基于细粒度流水的重叠率计算单元PE;为了充分开发Soft-NMS的并行性,本文设计了一种基于粗粒度并行的2级并行结构;为了解决2级并行结构存在的计算速度不匹配和数据相关等问题,本文设计一种预取最值方案。
无乘除法的PE:PE是整个加速器的核心,PE的计算结构对加速器的功耗和资源量起决定性作用。Soft-NMS计算候选框之间的重叠率时,反复进行浮点乘法和浮点除法会消耗大量的存储空间和运算资源,因此本文使用对数函数优化计算,设计了一个基于全流水结构无乘除法的计算单元PE。PE由“对数映射”“计算重叠率”“指数映射”“写回”4段流水栈组成,其结构如图4所示,其计算方法如算法1步骤4所示。
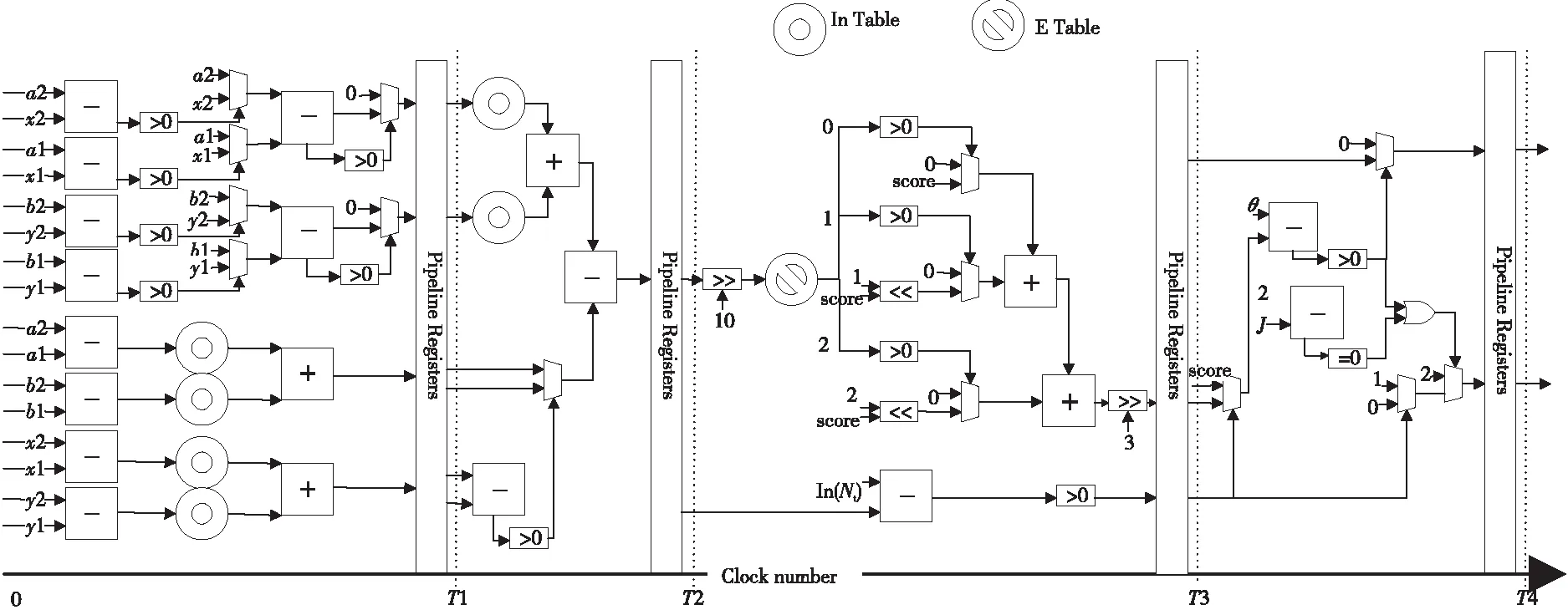
Figure 4 PE based on four-level flow structure图4 基于4级流水结构的PE
本文以候选框b1和候选框b2为例介绍PE计算重叠率的对数优化方法。候选框b1的坐标表示为(x1,y1)和(x2,y2),得分值为s1,候选框b2的坐标表示为(p1,q1)和(p2,q2),得分值为s2,且s1>s2。运算符A(·)定义为区域面积,A(b1∩b2)表示候选框b1与候选框b2重叠部分面积。PE更新候选框得分值时,其衰减函数如式(2)所示。由iou(b1,b2)的定义可知,当候选框b1、b2满足式(4)时,可认为b1、b2的重叠率过高,需要更新候选框b2的得分值。式(4)中有3个计算矩阵面积的乘法运算和1个除法运算,为了减少乘除法运算量,本文利用式(5)对式(4)的左边进行缩放,结果如式(6)所示,继续对式(6)不等式两边同时进行对数运算,结果如式(7)所示。为了方便表示,我们用lnOR(Overlap Rate)表示式(7)左边ln (A(b1∩b2))-ln(max(A(b1),A(b2)))的运算结果,在lnOR中代入候选框b1、b2的长和宽h1=x2-x1,w1=y2-y1,h2=p2-p1,w2=q2-q1和b1、b2的重叠部分A(b1∩b2)的长和宽H=min(x2,p2)-max(x1,p1)和W=min(y2,q2)-max(y1,q1)后,如式(8)所示,lnOR中所有乘除运算将全部转换为对数加减运算。
A(b1∩b2)/(A(b1)+A(b2)-A(b1∩b2))≥Nt
(4)
max(A(b1),A(b2))≤
(A(b1)+A(b2)-A(b1∩b2))
(5)
A(b1∩b2)/max(A(b1),A(b2))≥Nt
(6)
ln(A(b1∩b2))-
ln(max(A(b1),A(b2)))≥ln(Nt)
(7)
lnOR=(lnH+lnW)-
max(lnh1+lnw1,lnh2+lnw2)
(8)
文献[9]提出了Soft-NMS的基本原理,与靶候选框重叠率越高的候选框衰减率越高,因为它们有更高的可能性是假阳性,即候选框的衰减率与重叠率之间应该满足正相关关系。为了简化计算,节约资源,减少计算延迟,本文提出用查找表来实现重叠率与衰减率之间的正相关对数映射。
查找表实现正相关对数映射的方法为:首先,如描述第1级流水栈“对数映射”方法的步骤4.1所示,用查找表将候选框的长、宽等数据映射到对数空间(本文称此查找表为ln表);然后如描述第2级流水栈“计算重叠率”方法的步骤4.2所示,使用加减运算得到用对数表示的候选框重叠率lnOR;接着,如描述第3级流水栈“指数映射”方法的步骤4.3所示,用另一个查找表将lnOR映射到衰减率f(OR)上(本文称此查找表为E表),将衰减率与得分值相乘得到新的得分值;最后,如描述的第4级流水栈“写回”方法的步骤4.4所示,PE将计算得到的新得分值发送到RAMB、新状态信息值发送到位表J。
可以发现,算法1步骤4.3中得分值与衰减率相乘仍然是一个乘法运算,于是本文将这个乘法运算转化为移位加法。本文实验部分将证明使用3位无符号定点小数表示衰减率不会影响算法的检测精度,其数据表示范围为0~(1-2-3),因此可以将得分值与衰减率相乘转化为得分值的3次移位加法。
为了减小冗余存储,本文将使用64×3 bit的E表,因此需要将16位的lnOR右移10位作为E表的索引键,E表中的元素为3位无符号定点小数表示的衰减率;在图像像素不超过1024×1024的情况下本文选择使用1024×16 bit的ln表。由此可知,本文所使用的查找表方法占用的资源很少,适合在FPGA等硬件平台上实现。
算法1基于Soft-NMS的加速算法
输入:B={b1,…,bN},Score={s1,…,sN},J={j1,…,jN},Nt,θ。
输出:D={b1,…,bK}。
步骤1初始化集合D为空,初始化表J全为“0”。
步骤2表J不全为2时执行步骤3,否则执行步骤5。
步骤3选取集合B中得分值最大的候选框为靶候选框,并将该候选框加入集合D中并从集合B中删除,将表J中所有状态位的值“1”修改为“0”。
步骤4计算靶候选框与集合B中每一个候选框的重叠率:
步骤4.1(对数映射) 计算出候选框b1与候选框b2的长和宽h1=x2-x1,w1=y2-y1,h2=p2-p1,w2=q2-q1;计算重叠部分的长和宽H=min(x2,p2)-max(x1,p2)和W=min(y2,q2)-max(y1,q1);查找ln表得到lnh1、lnw1、lnh2、lnw2;计算出较大的候选框面积的对数lnArea_max= max(lnh1+lnw1,lnh2+lnw2)。
步骤4.2(计算重叠率) 查找ln表得到lnH、lnW;计算候选框b1与候选框b2的重叠部分面积的对数lnA(b1∩b2)=lnH+lnW;计算用对数表示的候选框重叠率lnOR=lnA(b1∩b2)-lnArea_max。
步骤4.3(指数映射) 判断当lnOR>lnNt时,以lnOR≫10为索引键查E表得到3 bit的f(OR),通过3次移位加法更新b2的得分值s2_new,并将J2从“0”修改为“1”;否则s2_new=s2,J2不变。
步骤4.4(写回) 判断s_2_new<θ时,更新集合Score中b2的得分值为0,修改J2为“2”,否则集合Score中b2的得分值不变,J2不变;当靶候选框与集合B中每一个候选框的重叠率都计算完成后返回步骤2。
步骤5算法结束。
2级并行结构:为了提高加速器的吞吐率,本文根据Soft-NMS的双循环结构,设计了一种2级并行硬件结构。此结构包括:计算单元组的循环级并行和最值模块与计算单元组之间模块级并行。计算单元组由S个PE组成,为了开发计算单元组的循环级并行性,在每轮遍历中,分批(每批S个)计算靶候选框与其他候选框的重叠率,修改候选框的得分值和位表J的状态信息,减少重叠率的计算延迟。
根据Soft-NMS频繁修改得分值的特点,本文在加速器中加入一个最值模块,用于选取每轮遍历后得分值最大的靶候选框。为了提高并行度,节约排序时间,在模块级别上,本文设计计算单元组与最值模块并行工作。在每轮遍历中,计算单元分批求取候选框重叠率的同时最值模块反复比较出N个候选框的前k大得分值候选框,为下一轮遍历提供靶候选框,优化比较最值的时间。
预取最值方法的硬件实现:最值模块与计算单元组并行工作时,存在计算速度不匹配和数据相关等问题,于是本文设计了一种预取最值方案,在加速器中加入一个靶向模块。在每轮遍历结束后,靶向模块从前k大得分值候选框中选取靶候选框,直接开始下一轮遍历,节约了选取最值的时间。
本文分析最值模块选取一个最大值的时间较短,一轮遍历的时间可以重复进行k次最值选择的操作,得到N个候选框的前k大得分值序列。其方法为:最值模块每次找到最大值候选框后都将其在RAMC中的得分值数据修改为 0,然后重新选取最大值,重复进行k次最值选择操作后,将得到N个候选框的前k大得分值序列,并存入Target的缓冲队列中。一轮遍历结束后,如果Target能从前k大得分值序列中找到在位表J的状态位为“0”的得分值最大候选框作为靶候选框,则视为命中靶候选框,否则视为不命中。可以发现,当命中率较高时,排序时间几乎可以完全省略。
假设最值模块选取一次最大值的时间为tm,计算单元组计算1次候选框重叠率的时间为ts。在一轮遍历中,最值模块与计算单元组并行工作,最值模块选取N个候选框的前k大得分值的时间为k×tm,并行度为S的计算单元组完成N个候选框重叠率计算的时间为N×ts/S,则最值模块预选候选框数量k与计算单元组的并行度S满足公式k×tm=N×ts/S。由此可知在tm、N、ts保持不变的条件下,计算单元组的并行度S与k呈反比,并行度S越小,k越大,预取最值方法的命中率越高;但是并行度S较小时,加速器吞吐率也较小,因此合适的S值才能充分发挥Soft-NMS加速器的计算优势。
5 实验与结果
本文在XILINX KU-115 FPGA开发板及 XILINX ISE 18.3 设计环境下实现了该加速器。所有模块均用 Verilog 编码实现,并在 XILINX ISE 18.3 环境下进行综合、布线和实现。为了探索最合适的计算单元组个数S的值,本文从COCO_2017 val数据集中选取了50幅图像,包含992个候选框进行实验,观察加速器吞吐率在不同PE数目下的变化情况(每个候选框的坐标信息用8 B数据表示)。如图5所示,实验结果表明,成倍增加PE的数量并不能成倍地提高加速器的吞吐率。这是因为PE数目过高导致计算单元组分批的数量减少,不能充分发挥PE的流水线计算优势。为了充分发挥PE流水线的计算优势,提高预取最值算法的命中率,实现性能与资源量的平衡,本文使用128个PE组成计算单元组实现候选框去冗余加速器,此时加速的工作频率是100 MHz。

Figure 5 Relationship between throuthput and number of PE in the accelerator图5 加速器中吞吐率与PE数目的关系
基于Soft-NMS的候选框去冗余加速器的综合数据细节如表1所示,加速器没有占用DSP资源,但由于FPGA片上逻辑的并行度在提高的过程中会消耗大量的BRAM,128个PE并行工作使得候选框去冗余加速器占用较多的BRAM资源。总体上,加速器资源占用较少。

Table 1 Resource occupancy of redundancy-reduced candidate box accelerator
为了评估加速器的性能,本文用R-FCN模型在COCO_2017 val数据集上分别测试了CPU实现的Hard-NMS、CPU实现的线性衰减函数Soft-NMS和候选框去冗余加速器的性能。如表2所示,实验结果表明,候选框去冗余加速器与基于线性衰减函数的Soft-NMS相比几乎不会有精度损失,表明了本文提出的体系结构的正确性。
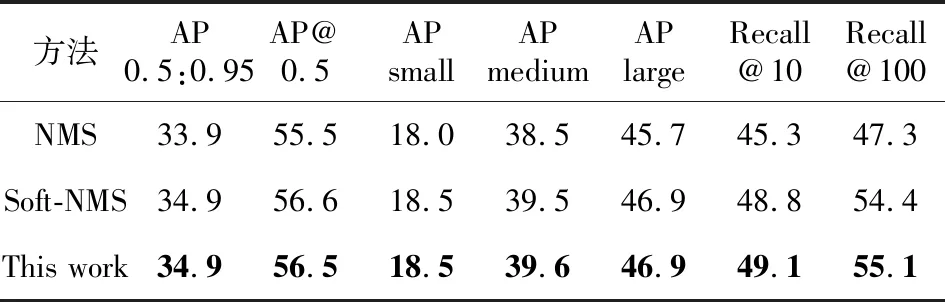
Table 2 Accuracy of R-FCN model on coco dataset under different methods
为了评估候选框去冗余加速器的加速性能,本文选用Intel(R) Core(TM) i7-4790k CPU @4.00 GHz、NVIDIA GeForce GTX 1080 Ti、TSMC 28 nm作为对比平台,实验结果如表3所示,候选框去冗余加速器处理992个候选框的延时为168.95 μs,吞吐率为47.0 MB/s,比CPU平台实现的Hard-NMS提高了32倍、比CPU平台实现的Soft-NMS提高了36倍、比GPU平台实现的Hard-NMS提高了3.9倍,但本文的硬件功耗仅为6.107 W,性能功耗比为CPU实现Hard-NMS的234倍、为CPU实现Soft-NMS的264倍、为GPU实现Hard-NMS的39倍。文献[11]根据Hard-NMS在TSMC 28 nm平台上使用1 024个计算单元CALU时,在100 MHz的频率下的计算延时为51.13 μs,吞吐率为149.21 MB/s,本文基于Soft-NMS在FPGA平台上实现1 024个PE,在100 MHz频率下的吞吐率为108.83 MB/s。虽然本文方法的吞吐率稍稍低于文献[11]的,但准确率较文献[11]的提升了4%左右,并且文献[11]没有考虑对乱序候选框排序的时间。因此,本文提出的加速器体系结构是解决候选框去冗余问题的有效方法。

Table 3 Performance comparison of NMS implemented on different platforms
6 结束语
本文提出了一种高效加速Soft-NMS的体系结构,利用对数函数优化复杂的浮点计算,采用细粒度流水和粗粒度模块级并行组成2级优化结构进一步提升算法的吞吐率。实验结果表明,与以前的方法相比,本文方法准确率更高、效率更高、资源消耗更少。
