部位级遮挡感知的人体姿态估计
2022-12-15徐士彪张晓鹏
褚 真 米 庆 马 伟 徐士彪 张晓鹏
1(北京工业大学信息学部 北京 100124)2(北京邮电大学人工智能学院 北京 100876)3(模式识别国家重点实验室(中国科学院自动化研究所) 北京 100190)(zhen.chu@foxmail.com)
人体姿态估计即定位图像或视频中的人体关节点,是计算机视觉中一项基本但极具挑战性的任务,在运动康复、人机交互、自动驾驶[1]等方面有着广泛应用.近年来,深度学习的发展使得人体姿态估计技术取得了突飞猛进的进步.然而,现有方法仍难以较好地处理现实环境中普遍存在的遮挡问题.如何有效应对遮挡问题,进而提升人体姿态估计方法的实用价值,是目前研究的重点和难点.
数据增强是处理遮挡问题的常用方法之一.例如,Ke等人[2]通过从关节点周围图像背景中裁剪出正方形区域粘贴到关节点位置来模拟遮挡.Bin等人[3]提出语义数据增强方法,通过生成网络动态地预测增强后的图像,进而利用增强后的数据训练人体姿态估计网络,以提升这些网络在遮挡环境下的鲁棒性.但是,数据增强方法干扰了网络对于关节点表观属性的认知.为此,Zhou等人[4]提出OASNet,利用注意力机制预测遮挡感知的注意力图,删除遮挡区域噪声特征,进而重建出因遮挡而缺失的人体区域特征.相比于数据增强方法,遮挡感知方法能够有效去除噪声干扰.然而,目前此类方法只关注遮挡区域在图像空间中的位置,对所有被遮挡关节点等同对待.由于不同关节点表观和上下文关系差异性大,等同对待难以充分利用关节点之间的关系.
本文提出部位级遮挡感知的人体姿态估计方法,以提高人体姿态估计在遮挡下的鲁棒性.所提出方法在基准人体姿态估计网络框架中引入遮挡部位预测模块,该模块由遮挡部位分类网络和可见性编码器组成.其中,遮挡部位分类网络用于预测每个关节点的遮挡状态,记作关节点可见性向量.关节点可见性向量描述了人体各个部位是否被遮挡这一关键信息,可以作为先验知识指导人体姿态估计任务.基于通道注意力思想,可见性编码器将可见性向量转换为一组权重,与基准姿态估计网络提取的卷积特征进行通道重加权,从而迫使网络学习到被遮挡和可见关节点之间的差异,感知遮挡部位,利用相关关节点的上下文修正错误的预测.所提出遮挡部位预测模块具有通用性,适合任何人体姿态估计基准网络,且参数量低,能够以较低的计算代价有效地减轻遮挡的影响.
本文工作的主要贡献有3个方面:
1) 提出部位级遮挡感知人体姿态估计方法,通过关节点级别的遮挡推测、知识编码和使用,提升遮挡状态下的人体姿态估计准确度;
2) 构建遮挡部位预测模块,由遮挡部位分类网络和可见性编码器组成.前者预测关节点遮挡状态,后者将遮挡状态编码为人体姿态估计所用先验知识.所构建的遮挡部位预测模块能够兼容不同的基准姿态估计网络;
3) 在合成和实际数据集上的实验均表明,所提出方法能够有效地提升遮挡状态下的人体姿态估计性能.
1 相关工作
首先,回顾近年来人体姿态估计相关工作.其次,由于本文重点解决遮挡问题,在此也将对相似任务中如何处理遮挡问题进行介绍.
1.1 人体姿态估计
传统姿态估计方法[5-7]使用手工构建的特征提取器,往往仅仅考虑小范围的局部特征,特征的丰富度也非常有限,因此很难对姿态做出准确的判断.目前先进的人体姿态估计方法都是基于深度卷积神经网络进行的.DeepPose[8]把深度学习引入到人体姿态估计任务中,它基于卷积神经网络直接回归关节点的坐标.由于直接回归法相对困难,基于热图的方法是目前的主流.CPM(convolutional pose machines)[9]能够提取不同尺度的局部区域的关节点概率,再利用多阶段的方式逐步修正提取的结果.Hourglass[10]使用了U型的网络结构,把设计的残差模块作为该网络的基本单元,通过反复的上下采样和同尺度特征的跨层连接来获取更有效的多尺度信息,并且使用多阶段的网络架构实现逐步优化前一阶段的预测热图的“由粗到精”的学习策略.在Hourglass的基础上,PyraNet[11]把残差模块替换为金字塔残差模块,目的是捕捉到细粒度多尺度特征.Tang等人[12]提出一种复合模型,利用神经网络学习人体的层级结构.Hua等人[13]在Hourglass基础上引入精炼模块和残差注意力模块,以提高上采样效果.Lin等人[14]提出基于结构化空间学习和中间估计,以保持视频估计结果的时序一致性.SBN(simple baseline network)[15]把ResNet[16]的全连接层替换为几层反卷积用来增大输出特征图的分辨率,虽然结构简单,但是性能更好.HRNet[17]全程保持高分辨率的表征,并逐渐增加更低分辨率的子网,同时,在并行的子网之间反复交换信息来实现多尺度融合,它超越了以往所有的网络模型,在其他计算机视觉任务中也有着广泛的应用.
尽管取得显著进展,现有人体姿态估计网络仍难以应对遮挡问题.本文提出部位级遮挡感知的人体姿态估计方法,以较低的额外计算代价提升现有网络应对遮挡的鲁棒性,所提出方法能够兼容任何主流人体姿态估计基准网络.
1.2 遮挡处理
CPN[18]采用2阶段的网络结构,利用GlobalNet提取的特征帮助RefineNet优化被遮挡的困难的关节点的检测结果.Chu等人[19]利用基于条件随机场的注意力机制来处理遮挡问题.Ke等人[2]提出的keypoint masking技术,通过从关节点周围图像背景中裁剪出正方形区域粘贴到关节点位置来模拟遮挡.Chen等人[20]利用生成对抗网络预测遮挡部位,通过对抗式学习不断修正预测结果.Bin等人[3]提出语义数据增强方法,利用生成网络粘贴不同语义粒度的身体部位来模拟挑战性更高的图像.OASNet[4]在人体姿态估计网络上添加了额外的分支,通过监督学习的方式预测图像中遮挡区域的空间位置,然后删除被遮挡区域的特征,再利用孪生网络更好地重建特征图上被遮挡区域的特征,从而降低遮挡的干扰,依靠周边信息恢复被遮挡部位的特征.前述工作尝试感知遮挡所在图像空间位置.本文提出遮挡部位感知的人体姿态估计方法.人体姿态结构性强,感知遮挡部位相比感知遮挡位置更加有助于姿态估计时抹除遮挡对相关部位估计的影响和利用相关部位作为上下文线索对遮挡部位进行更有效推断.
处理遮挡也是其他计算机视觉任务中研究的重点之一.在行人检测中,Zhang等人[21]发现对于基于卷积网络的行人检测器,不同的通道对与人体不同部位有不同的响应,为此提出了作用于通道上的注意力机制.OR-CNN[22]设计了AggLoss最小化建议与对象的距离,并且用部件遮挡感知的RoI池化单元替换原有的RoI层.Pang等人[23]提出了Mask引导的注意力网络,在增强人体可见区域权重的同时抑制被遮挡的区域.针对遮挡下的人脸关节点进行检测.Zhu等人[24]提出了遮挡自适应的网络,它可以在高维空间上过滤掉遮挡区域的特征的同时根据上下文恢复出相应的几何信息.与前述工作不同,本文研究结构性更强的人体姿态的估计问题,并提出了部位级遮挡感知的人体姿态估计方法.
2 本文方法
2.1 设计动机
本文以当前性能优秀的HRNet和SBN为例,测试现有方法在被遮挡节点上的预测效果,结果如图1所示,圆圈用于标识预测错误的位置.其中,图1(a)中遮挡影响了未被遮挡的关节点(左手腕、右脚踝)的检测.图1(b)中由于遮挡存在,导致预测姿态不自然.简言之,遮挡不仅影响被遮挡的部位,也对与遮挡部位相邻的未被遮挡关节点的定位有一定程度的影响.

Fig. 1 Failure examples of existing methods to deal with occlusion problems图1 现有方法处理遮挡问题的失败案例
关节点被遮挡也将对其他关节点的预测产生负面影响.为了对比不同部位遮挡对其他关节点估计的影响,首先基于MPII数据集分别在头部、躯干(包含肩膀、髋在内的关节点)、上肢、下肢添加黑色的遮挡;然后排除遮挡部位的关节点,分别计算遮挡下的结果与原始结果的差值,得到其他关节点在遮挡影响下的下降值,再对这些下降值求平均,最终得到遮挡对总体的影响程度PCKh@0.5,在第i个关节点上的PCKh@0.5定义为
(1)

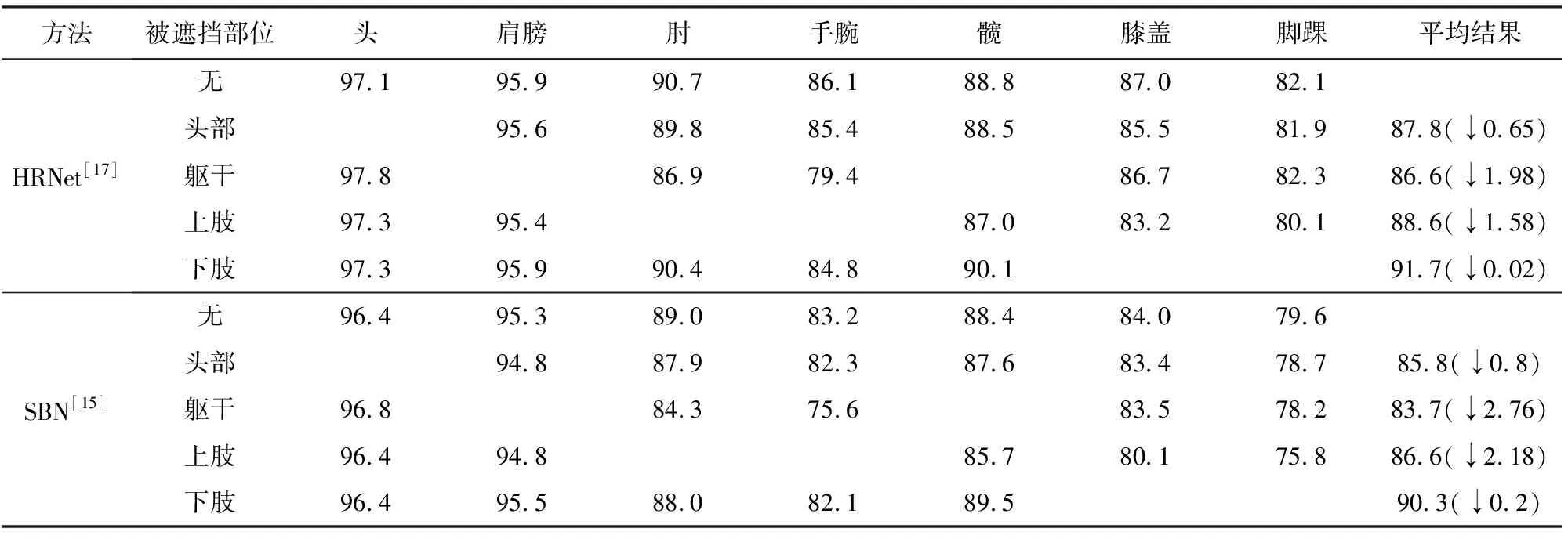
Table 1 Influence of Different Parts of Occlusion on PCKh@0.5 of Other Keypoints表1 不同部位遮挡对其他关节点PCKh@0.5的影响

Fig. 2 The overall architecture of proposed method图2 本文方法整体架构
从表1中可以看出,遮挡躯干对上肢关节点的检测影响较大.在HRNet和SBN上的平均PCKh(head-normalized probability of correct keypoint)@0.5分别下降了1.98和2.76.究其原因,一方面是由于躯干与上肢直接相连,关联度高;另一方面是由于躯干面积较大且人体上肢灵活,上肢经常与躯干重叠,形成人体自遮挡.同理,遮挡上肢对其他关节点的影响也较大,在HRNet和SBN上平均PCKh@0.5分别下降了1.58和2.18.此外,遮挡头部对检测其他关节点有一定影响,在HRNet和SBN上平均PCKh@0.5分别下降了0.65和0.8.而由于MPII数据集中人体姿态多为站立,与其他部位距离较远,因而遮挡下肢对其他关节点的检测影响较小.
综上,人体部位遮挡对自身以及与之相关的其他部位均有一定程度的影响.如果获得关节点级别遮挡线索,则可通过上下文更好地优化被遮挡关节点的定位,同时减少其对其他关节点的影响,提高人体姿态估计模型应对遮挡的能力.
2.2 方法整体架构
本文方法的整体架构如图2所示.首先,将输入图像同时输入基准姿态估计网络和遮挡部位预测模块.然后,使用遮挡部位预测模块的输出对基准姿态估计网络提取的特征施加通道重加权操作,得到优化后的特征.最后,使用1×1卷积获得最终结果.其中,基准姿态估计网络可以是现有任何人体姿态网络.所提出遮挡部位预测模块由遮挡部位分类网络和可见性编码器(visibility encoder, VE)组成.下面分别对其进行介绍.
2.3 遮挡部位分类网络
为了获得关节点级别的遮挡线索,所提出遮挡部位分类网络将根据输入图像预测人体每个关节点的遮挡状态.而关节点仅有被遮挡和可见2种状态,因而相比于人体姿态估计的回归任务,遮挡部位分类任务更简单,模型也更容易收敛.因此,权衡计算量和精度,遮挡部位分类网络将使用轻量级网络MobileNetV2[25]作为主干网络,用于提取适合遮挡部位分类任务的特征,获得每个关节点可见性向量,作为可见性编码器的输入.可见性向量表示为
o=(v0p0,v1p1,…,vkpk),
(2)
其中,pi表示人体每个关节点,vi是一个二值变量,表示第i个关节点是否被遮挡,vi∈{0,1},i∈[0,k],0表示被遮挡,1表示可见.
本文对MobileNetV2做出适当修改以适应关节点的遮挡分类任务.将MobileNetV2末尾用于图像分类的1000维全连接层分类器替换为输出通道数为n的1×1卷积.
在训练阶段,采用二分类交叉熵损失监督遮挡分类网络训练过程,以最小化在每个关节点上的遮挡状态预测误差.遮挡分类预测损失定义为:
(3)
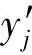
2.4 可见性编码器
为了将可见性向量与带噪声特征融合,首先利用可见性编码器扩展可见性向量的维度,然后利用通道注意力机制对带噪声特征进行重加权.前述过程可表示为
focc=ΩTfch,
(4)
其中,fch为需要被通道重加权的特征,Ω为权重参数向量.
本文选择通道重加权而非其他特征融合方式的原因如下:首先,基于热图的人体姿态估计方法将人体关节点转化为以关节点位置为中心的2维高斯热图,网络末尾使用1×1卷积将高维特征转化为与关节点数量相等的热图,关联了不同部位间的影响关系,说明关节点的信息与通道相关.其次,深层的网络能够学习出人体整体的结构,建模关节点之间的关系.而遮挡部位分类网络预测到的可见性向量仅表达了关节点独自的遮挡状态信息,缺乏关节点之间的关联信息.因此,通道重加权能够更好地利用关节点之间的上下文信息,并在本文所提出的可见性编码器的帮助下,利用注意力机制区分被遮挡与未被遮挡部位直接的差异,利用相关部位的上下文线索克服遮挡的干扰.
为了获得权重参数向量Ω,利用可见性编码器把可见性向量编码到更高维度的特征上.具体而言,利用可见性编码器把可见性向量转换为一组维度与基准姿态估计网络提取的卷积特征通道数相等的权重,其值小于1.然后对卷积特征进行通道重加权.该过程的公式表示为
Ω=F(o),
(5)
F=Sigmoid(F2(F1(o))),
(6)
其中,F表示可见性编码器,其结构如图3所示.输入为遮挡部位分类网络的输出,即可见性向量o.经过2个全连接层F1和F2使得向量的维度和基准姿态估计网络提取的卷积特征通道数相同,再经过Sigmoid函数使该模块输出向量每个元素的值调整为0和1之间,得到权重参数向量Ω.再与基准人体姿态估计网络提取的卷积特征fch进行对应通道上相乘,得到重加权后的特征focc.
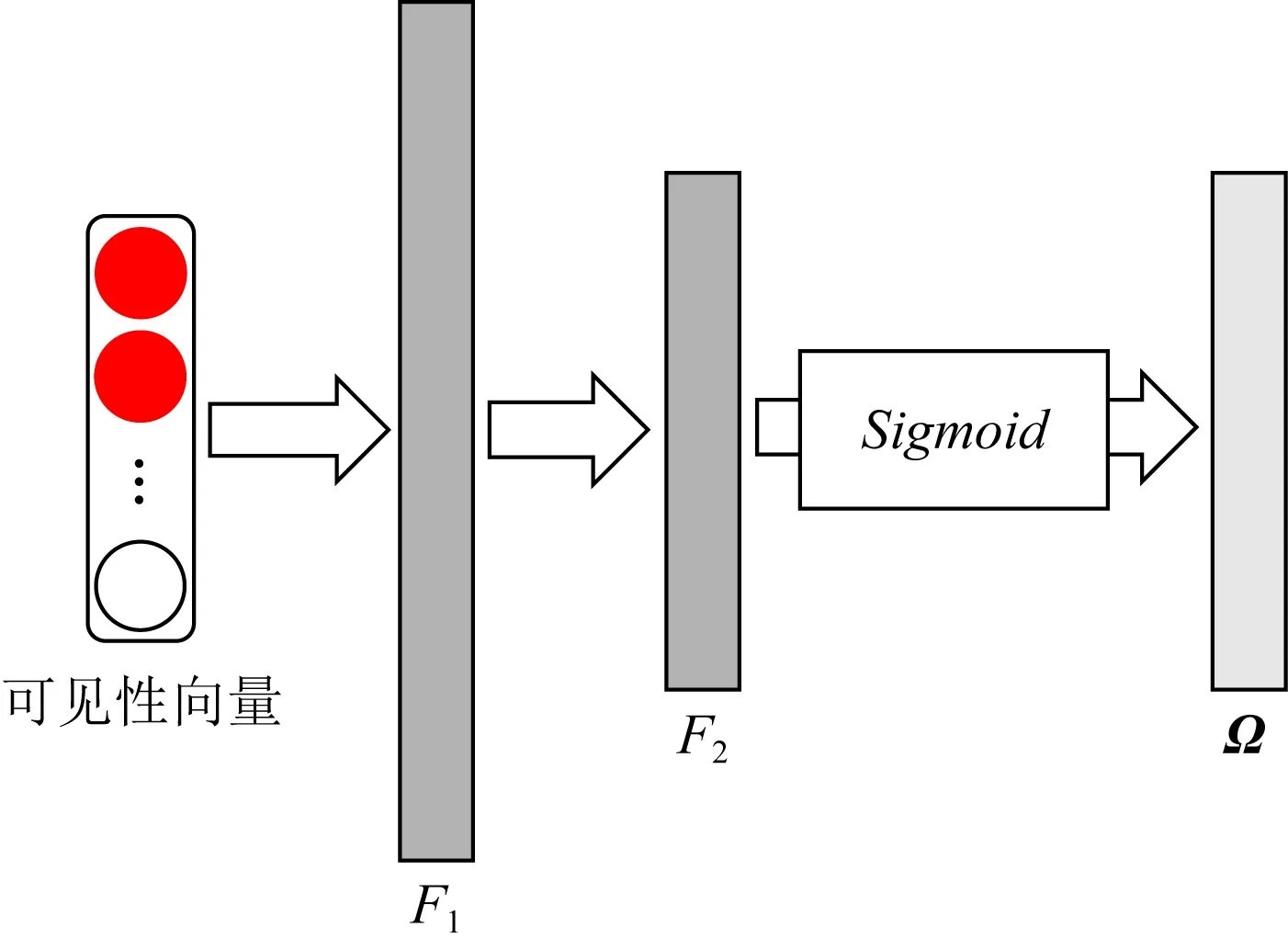
Fig. 3 The network sturcture of the visibility encoder图3 可见性编码器的网络结构
当基准姿态估计网络为HRNet时,2个全连接层输出通道数分别为64和32.此时,将可见性编码器模块添加在HRNet的stage 4之后、1×1卷积之前;当基准姿态估计网络为SBN时,2个全连接层输出通道数分别为64和256.此时,将可见性编码器添加在最后一层反卷积后.
2.5 整体架构训练损失函数
本文对人体姿态估计网络和部位级遮挡分类网络进行联合端到端训练.为此,对人体姿态估计网络预测的关节点热图和遮挡分类模块预测的关节点可见性向量的整体损失进行度量,整体损失函数为
L=Lhm+λLocc,
(7)
其中,Lhm表示人体姿态估计关节点热图检测的L2损失函数,Locc由式(2)给出,表示用于遮挡部位分类的二分类交叉熵损失函数.λ为平衡2个损失函数的超参数.鉴于遮挡分类任务优化较快,本文设λ=0.01.基准姿态估计模块和遮挡分类网络均使用ImageNet预训练模型进行参数初始化.
3 实验结果与分析
3.1 数据集和评价指标
MPII数据集是一个用于2维人体姿态估计任务的数据集,包含约25 000张从真实场景中采集的图像和超过40 000个人体关节点标注,其中每人共有16个关节点被标注,是单人姿态估计任务的主流数据集.
LSP(leeds sports pose)数据集由2 000个样本原始数据集和10 000个样本的扩展数据集组成.其中,原始数据集中的1 000个样本用于测试,其余11 000个样本用于训练.每人有14个标注的关节点.
PCKh是MPII和LSP数据集的评价指标,用于计算检测的关节点与其真值的归一化距离小于预设阈值(头部长度)的比例.
本文分别基于MPII和LSP数据集,构建合成随机矩形遮挡的图像数据集,包括训练集和验证集.随机矩形遮挡的高是人体目标框高度的[1/4,1/2]之间的随机值,宽是人体目标框宽度的[1/2,1]倍之间的随机值.遮挡区域的位置在人体的包围框内,颜色是图像的平均值.
3.2 实验设置
训练阶段实验设置.实验基于PyTorch框架在GTX 1080Ti GPU上训练,并使用了ImageNet的预训练参数.参考Xiao等人[15]、Sun等人[17]的实验设置,输入图像大小调整为256×256,批大小为32,优化器为Adam,初始学习率为0.001.基于HRNet基准网络,迭代训练到170和200轮时,学习率分别下降至0.000 1和0.000 01,总共训练210轮;基于SBN基准网络,迭代训练到90和120轮时,学习率分别下降至0.000 1和0.000 01,总共训练150轮.数据增强的策略包括-45°~45°随机旋转,0.65~1.35随机尺度变换和左右随机翻转.
测试阶段实验设置.输入图像经过网络推理得到热图后,对该热图和翻转后的热图对应位置求平均,得到最终的热图.在后处理时,参考Hourglass[10],将热图上值最高的一点向次高点的1/4像素的偏移作为最终的关节点预测位置.
3.3 消融实验
本文首先设计消融实验确定方法的最终结构.所有消融实验均基于HRNet和所构建合成MPII数据集训练和测试.以下分别介绍通道重加权位置、可见性编码器结构、遮挡部位分类网络和遮挡部位预测模块通用性的消融实验.
3.3.1 通道重加权位置
本文基于HRNet设计消融实验,对比在3个位置(A,B,C)施加通道重加权(如图4所示)对结果的影响.其中:A表示在HRNet前执行重加权;B表示在主干网络提取到特征之后执行重加权;C表示经过最后一个1×1卷积,得到的16个关节点热图后再执行重加权;1,2,3,4表示HRNet四个阶段网络结构组成.实验结果如表2所示,在位置B施加通道重加权操作的效果最好.
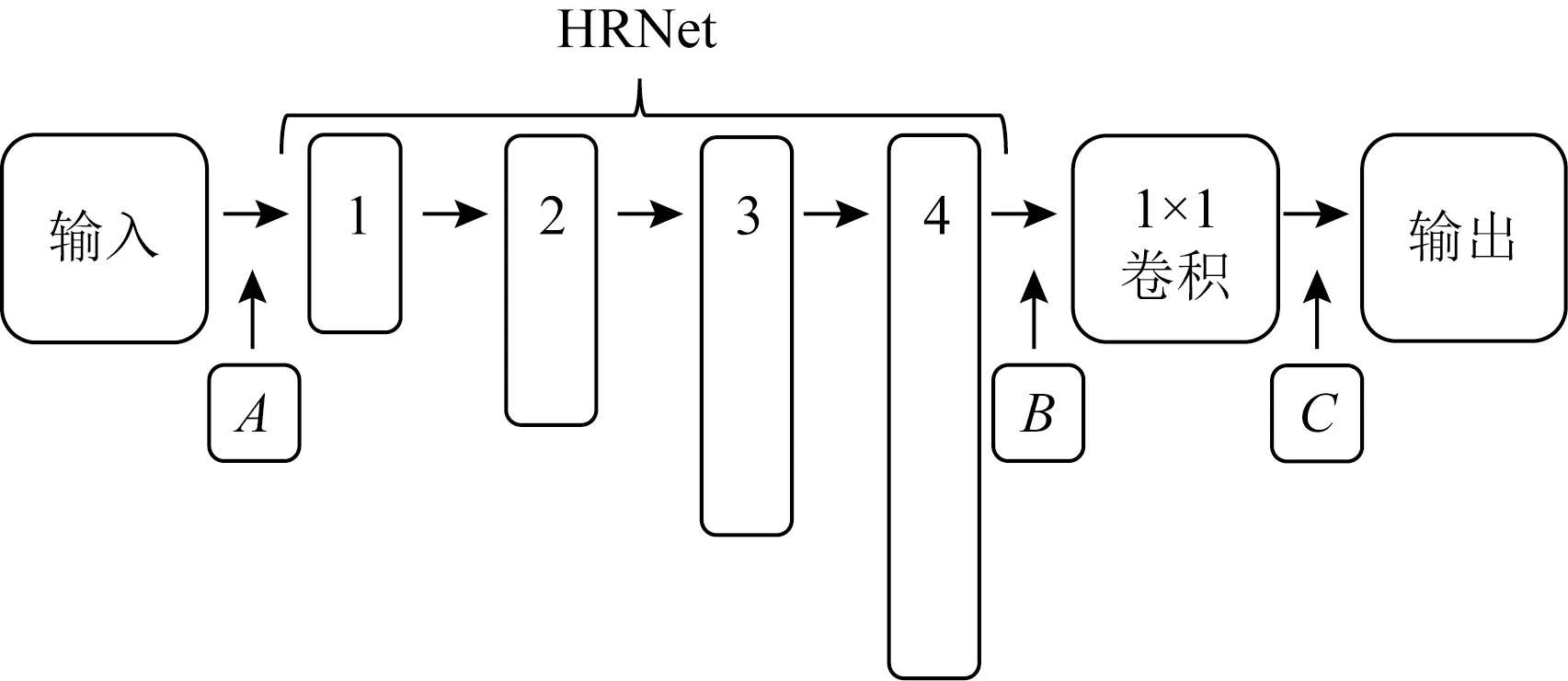
Fig. 4 Indication of the positions where channel weighting is applied on HRNet图4 在HRNet上施加通道重加权位置示意图

Table 2 Ablation Study of HRNet with Channel Re-weighting at Different Positions
3.3.2 可见性编码器结构
在基于HRNet验证可见性编码器结构的消融实验中,比较该模块不同数量的全连接层之间的差异.实验结果如表3所示,当全连接层数量为2时,可见性编码器的结果最好,因此本文方法最终选择2层全连接的可见性编码器.

Table 3 Ablation Study on the Number of Fully Connection Layers in the Visibility Encoder
3.3.3 遮挡部位分类网络
遮挡部位预测模块所使用的遮挡分类网络可以是现有的任何轻量级分类网络.本文选择有代表性的轻量级网络MobileNetV2[25],ShuffleNetV2[26],GhostNet[27]进行对比实验,结果如表4所示.从表4中可看出,选择不同的分类网络对最终姿态估计结果的影响极小,因此本文选择经典的MobileNetV2作为遮挡部位分类网络.
Table 4 Ablation Study of the Occlusion Classification Network
3.3.4 遮挡部位预测模块通用性
鉴于本文方法兼容所有基准人体姿态估计网络,为了使其性能最优,设计验证遮挡部位预测模块通用性的消融实验,结果如表5所示.在HRNet和SBN中引入遮挡部位预测模块后,平均指标分别提升了0.3和0.5.实验结果说明所提出的遮挡部位预测模块能广泛提升现有方法在合成遮挡下的性能.综上,最终选择HRNet作为本文方法的基准姿态估计网络,用于和现有方法横向比较.

Table 5 Ablation Study for Verifying the Universality of the Visibility Encoder表5 验证可见性编码器通用性的消融实验
3.4 横向对比实验——效率分析
表6给出了各方法的参数量、计算量和在RTX 3090显卡上的推理速度(输入图片的尺寸为256×256)的横向对比.从表6中可看出,本文方法设计的遮挡预测模块的参数量和计算量分别为30.8 MB和9.85 GFLOPS,相比基准网络HRNet分别仅增加8.0%和3.8%,且推理速度仅慢5.9%,达到143 fps.
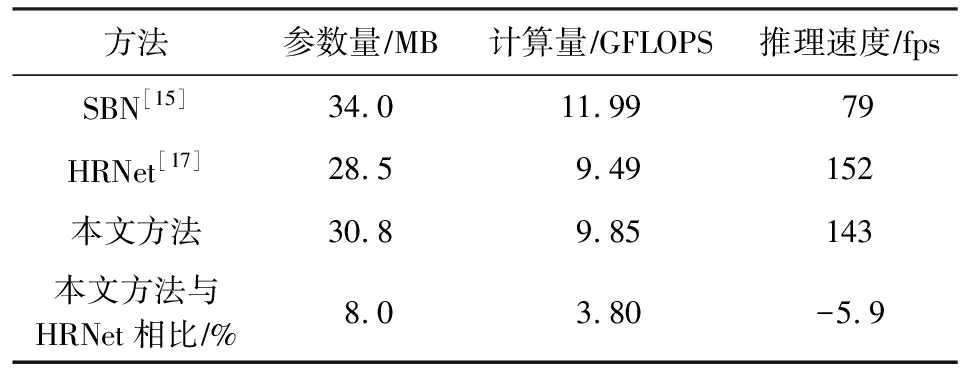
Table 6 Efficiency Comparison Between the Proposed Method and Existing Methods
进一步说明本文方法在维持较低计算代价的同时,有效降低遮挡对人体姿态估计的影响.
3.5 横向对比实验——量化对比与分析
通过3.3节的消融实验确定了本文方法的最终结构,即基准姿态估计网络为HRNet,通道重加权施加在HRNet尾部和1×1卷积之间,可见性编码器使用2层全连接层.以下分别在MPII与LSP数据集上进行横向对比实验与分析.
在MPII数据集上,利用在合成遮挡MPII训练集上训练得到本文模型.在实际MPII验证集上测试该模型,并将其与多种先进的方法做横向对比,结果如表7所示.所有对比方法的结果数值取自原文献.其中SBN,PyraNet,DLCM,Hourglass,HRNet为在MPII数据集上的原始结果,而OASNet和本文方法都使用了构建遮挡的数据增强策略,显式地利用遮挡信息.
从表7中可看出,本文方法平均准确度优于其他方法,尤其在人体四肢等灵活度大、挑战性高的关节点上优势更明显.相比对比方法中表现最好的OASNet,本文方法在头部、肘部、手腕、髋和膝盖关节点上,PCKh@0.5得分值分别领先0.1,0.2,0.2,0.9,0.4,平均PCKh@0.5得分值为91.0,领先OASNet方法0.3.
综上可看出,本文所提出的部位级遮挡感知的人体姿态估计方法推测关节点级别的遮挡线索,在此基础上利用上下文优化被遮挡关节点的定位,同时减小了被遮挡关节点对未被遮挡关节点的影响,能够显著提升人体姿态估计模型在应对遮挡问题上的性能.
表8给出了在LSP数据集上的测试结果.从表8中可看出,本文方法在多数关节点上,尤其是灵活度高的四肢上,准确度高于现有方法.

Table 7 Comparison Between the Proposed Method and Existing Methods on the MPII Valid Set表7 本文方法与现有方法在MPII验证集上的横向对比

Table 8 Comparison Between the Proposed Method and Existing Methods on the LSP Test Set表8 本文方法与现有方法在LSP测试集上的横向对比
3.6 横向对比实验——可视化对比与分析
图5展示了本文方法与HRNet在原始MPII验证集上的可视化结果.图5中3列分别为真值、HRNet和本文方法在相同图像上的可视化结果.实线圆圈和虚线圆圈分别标识了HRNet和本文方法预测正确和预测失败的例子.

Fig. 5 Visual comparison of proposed method and HRNet on the MPII valid set图5 本文方法与HRNet在MPII验证集上的可视化 对比
从图5可看出,第1行图像中人的双脚距离近且互相遮挡,导致HRNet错误地预测了2只脚的位置,所估计的双腿的姿态与真值相比出现明显偏差.而本文方法通过对遮挡部位的预测,避免了脚关节点遮挡对于腿部其他关节点的影响,同时借助其他可见关节点成功预测了脚关节点位置;第2行图像中双脚表观较为模糊,且与之相邻的膝盖关节点被遮挡,干扰了HRNet对双脚关节点的准确定位.本文方法能够在提升被遮挡关节点检测精度的同时,减少其对双脚关节点预测的干扰,令网络对姿态的估计更加合理;第3行中HRNet完全错误地预测图像中男士被遮挡的右脚位置,使得估计到的姿态为右脚翘起的错误状态,而本文方法结果合理、更加接近真值.
综上可看出,本文方法够有效克服遮挡对自身部位和相关部位的影响.
本文方法仍有不足之处,尚难以处理如复杂背景导致的挑战性高的情形.如图5第3行例子中所示,本文方法对右臂关节点的预测相比HRNet来说没有改进,结果仍然错误.第4行例子中,本文方法错将旁人相近关节点当作主体对象关节点,且右脚位置有一定偏移.
4 结论与展望
本文提出部位级遮挡感知的人体姿态估计方法,通过在基准人体姿态估计网络中引入所提出遮挡部位预测网络,有效降低遮挡对人体姿态估计任务的影响.实验表明,本文方法在较小的计算代价下能够增强多种基准方法应对遮挡的能力,尤其对于四肢等灵活度高的部位较为明显.
本文方法对复杂背景下的人体关节点预测能力仍然有限.原因在于本文方法依赖所学习的遮挡线索处理遮挡问题,未进一步考虑关节点之间更全局的关系.现有方法大多根据人类经验设计关节点之间的关系模型,仅关注局部信息,而忽视了潜在的全局关联.为了从全局视角下建模关节点之间的关系,在未来的工作中,将考虑设计遮挡状态下基于数据驱动的关节点影响关系建模.同时,探索基于图神经网络融合全局关节点关系的人体姿态优化算法,以提升本任务在遮挡状态下的准确性.
作者贡献声明:褚真提出研究思路、设计方案,进行实验、起草论文;米庆、马伟负责对文章内容进行指导及修订;徐世彪、张晓鹏负责论文的指导.
