考虑准备时间的两阶段装配流水线订单接受与调度决策
2022-12-11宋李俊鲁若愚李孝斌龚小容
宋李俊,鲁若愚,李孝斌,龚小容,*
(1.重庆理工大学 机械工程学院,重庆 400054;2.重庆大学 机械与运载工程学院,重庆 400044)
0 引言
经济全球化的大背景下,制造自动化、柔性化、智能化和高度集成化推动全球产业竞争格局发生着重大调整,制造企业间的竞争愈趋激烈。在过去,按订单生产型(Make To Order,MTO)企业在订单接受和订单生产上分别由销售部门和生产部决策,销售部门往往只关心订单接受的数量而不考虑订单的生产,而生产部门更多考虑生产订单交期的满足,对订单总体效益较少关注。这样的分开决策往往会导致接受的订单大大超过生产能力而产生订单的延迟惩罚成本,从而导致企业效益受损和名誉受损,更严重的会导致客户的流失。为了企业效益提升,MTO企业开始对订单接受与调度(Order Acceptance and Scheduling,OAS)问题进行集成决策,在订单接受同时根据订单特点和要求进行优化调度排产,在满足订单交期的前提下尽可能接受更多订单。
目前,已有一些学者对OAS问题进行了一定的研究。Slotnick和Morton是OAS问题较早的研究者,他们将企业生产环境抽象为一台机器,加工不允许抢占和中断,客户接受一定的交货期延迟,延期惩罚是与延期天数线性相关的递增函数,对比结果表明在产能有限的约束下,订单接受和调度联合决策比分开决策利润率更高,证实了OAS问题的研究意义与实用价值[1]。Oguz等进一步扩展了Slotnick和Morton研究的优化决策模型,考虑订单发布时间和序列生产准备时间带来的复杂性,提出了一种混合整数线性规划模型[2]。Back等进一步考虑了有限产能约束,并假设准备时间对释放时间存在部分依赖关系,提出了一个新的混合整数线性规划模型[3]。王柏琳等针对多品种混合制造商的不相关并行机订单拒绝问题,以总成本最小为目标,基于列表拒绝方法和订单拒绝准则设计了采用单亲-传统双遗传算子的协同进化遗传算法[4]。Wang等人研究了一种不相关并行机OAS决策问题,以总收益与总加权延误的差额为目标函数,建立了两个混合整数规划模型,并提出了一种分枝定界算法[5]。Naderi等针对订单选择和相同并行机调度问题,建立了预处理技术、有效不等式和优势规则等增强策略改进一个混合整数规划数学模型,并利用分支松弛和检查(BRC)方法将模型进行了分解[6]。宋李俊等人针对JIT模式下多节点流水线具有订单交货延迟惩罚与产品库存平衡约束的OAS决策问题,建立了总利润最大化决策模型,并设计了改进型双层编码遗传算法进行求解[7]。
从现有的相关文献来看,对OAS问题的研究主要集中在单机(单节点)环境[8~10]或并行机环境[11,12],对于更复杂的多阶段加工环境的研究较少。本文以两阶段装配流水线为研究对象,基于有限产能考虑订单序列相关准备时间约束,建立以订单利润最大为目标的订单接受与调度模型,并设计一种变邻域半置换遗传算法(Semi-permutation-based Genetic Algorithm-Variable Neighborhood Search,SPGA-VNS)进行求解。
1 问题描述与建模
1.1 问题描述
本文提及的两阶段装配流水线生产流程可以描述为:产品生产分为配套零件加工、装配两个阶段,第一个阶段有M个并行的流水加工单元,不同的加工单元完成不同的零部件加工,本文将M个加工单元简化为M台特定的异速并行加工机器;第二个阶段有1个装配单元,当各配套零件加工完成后,装配单元支持将零件装配成完整产品,其生产流程模型如图1所示。
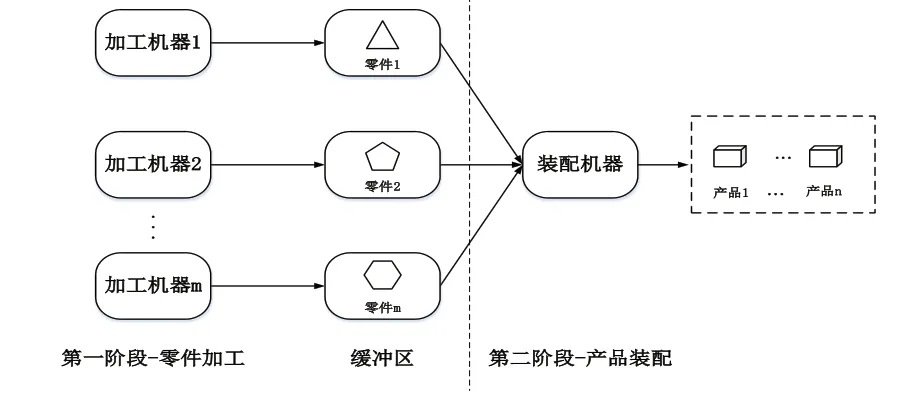
图1 两阶段装配流水线生产流程模型
两阶段装配流水线OAS问题可以描述为:企业初始时刻收到n个生产订单可供选择,在满足两阶段装配流程生产模式情况下,确定接受哪些订单以及制定被接受订单的调度方案,以实现订单收益最大化。其中,订单采用柔性交货期形式进行交付,即若订单在约定交货期之后、最迟交货期之前完成生产,则视为延期交付,将产生延期惩罚;若在约定交货期前完成生产,则视为按期交货,无惩罚;若在最迟交货期之后完成生产,则视为延期惩罚大于订单收益,订单将被拒绝。该问题模型需要满足以下假设:
1)所有参数均为已知和确定的。
2)所有订单都在初始时刻(设为t=1时刻)可在任何机器上进行加工。
3)机器加工或装配过程为非抢占式。
4)每个订单的工艺路线为确定的。
5)每个订单之间均不存在先后约束。
6)机器持续可用。
7)加工存在订单序列相关的加工准备时间。
8)任何一个订单完成第一阶段所零件加工后才可开始装配。
9)两个生产阶段间存在足够大的缓冲区域。
为了方便建模,本文符号定义如表1所示。
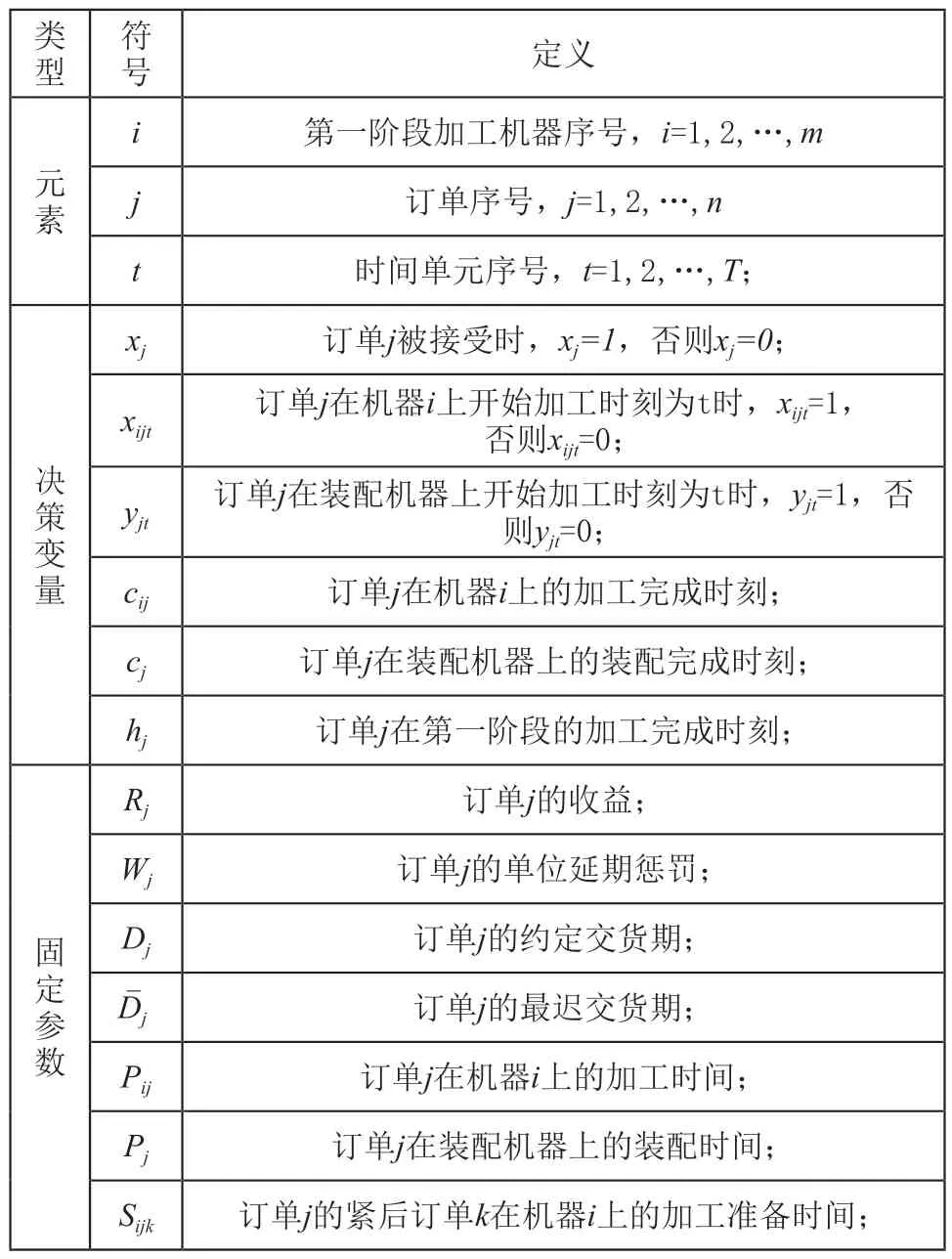
表1 符号定义
1.2 模型建立
根据以上描述建立采用时间索引(Time-indexed formulation,TIF)方法的混合整数线性规划模型。目标为订单利润最大化。数学模型如下:


式(1)表示目标函数为订单收益与延期惩罚之差;式(2)表示每个订单只在某个确定时刻在第一阶段的机器上开始加工;式(3)表示订单j在第一阶段加工机器i上的加工完成时刻;式(4)表示订单j在第一阶段的加工完成时刻大于或等于其在任意机器i上的加工完成时刻;式(5)表示任何一个时刻机器i上最多只有一个订单在加工;式(6)表示每个订单只在第二阶段的某个确定时刻在装配机器上开始装配;式(7)表示订单j在第二阶段的装配完工时刻;式(8)表示订单j必须在完成其第一阶段所有加工后才能开始装配;式(9)表示订单j在第一阶段的加工完成时刻必须小于或等于其装配开始时刻;式(10)表示任何一个时刻装配机器上最多只有一个订单在装配;式(11)表示订单j的装配完工时刻必须小于或等于订单j的最迟交货期;式(12)表示订单j必须在其第一阶段加工时间范围内开始加工;式(13)表示订单j必须在其第二阶段加工时间范围内开始装配;式(14)表示订单j的装配开始时刻大于其在第一阶段机器上的最大加工时间;式(15)表示决策变量的取值范围。
2 算法设计
同粒子群、蚁群、模拟退火等算法相比,遗传算法具有操作简单、迭代时间短、全局寻优能力强、鲁棒性好等特点,更适用于求解复杂生产环境下的OAS问题。但遗传算法存在搜索效率较低和容易过早收敛等不足,因此对遗传算法进行一定程度的改进或与其他算法混合,是增强其局部搜索能力、加快收敛速度以及提高解质量的有效手段。本文针对两阶段装配流水线订单接受与调度问题求解,提出一种变邻域半置换改进遗传算法,利用整数矩阵编码和启发式规则提升初始种群的质量,设计随机半置换单点交叉、互换变异等改进遗传策略提高解的质量,并提出原基因重插入法确保新种群个体均为可行解,结合变邻域搜索提高算法的局部搜索能力。
2.1 染色体编码
考虑到加工装配流水线由m台异速并行机器和1台装配机器组成,本文采用基于订单顺序的整数矩阵对染色体进行编码。一个完整的个体为一个m+1行、n列的整数编码矩阵,编码矩阵中每一行代表一条染色体,如图2所示。编码矩阵的前m行表示第一阶段的加工机器i上的订单加工顺序,数字表示对应的订单序号;编码矩阵的第m+1行表示第二阶段的装配机器上订单的装配顺序。
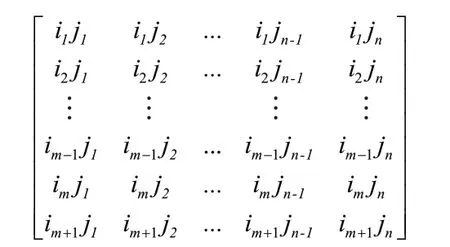
图2 整数矩阵编码
2.2 种群初始化
初始种群由三个种类,共N个种群个体组成。
1)第一类种群个体采用随机策略,共生成0.6N个。首先,随机排序生成第一阶段加工机器1的订单加工顺序,然后采用随机相邻半置换策略生成其他机器订单加工顺序,即在保持最先开始加工的订单序号不变的情况下,其余n-1个订单的加工顺序均采用两个随机选择的相邻订单的成对交换2n次生成,最后第二阶段装配机器上的订单装配顺序采用FIFO规则生成。
2)第二类种群个体采用单位加工时间收益越大优先策略,共生成0.2N个。首先基于订单Rj/Pj的非升序排列生成第一阶段加工机器1上的订单加工顺序,然后采用随机相邻半置换策略生成剩余机器上的订单加工顺序,最后第二阶段装配机器上的订单装配顺序采用FIFO规则生成。
3)第三类种群个体采用单位加工时间延期惩罚越低优先策略,共生成0.2N个。首先基于订单Wj/Pj的非降序排列生成第一阶段加工机器1上的订单加工顺序,然后采用随机相邻半置换策略生成剩余机器上的订单加工顺序,最后第二阶段装配机器上的订单装配顺序采用FIFO规则生成。
2.3 适应度函数
种群中个体的适应度值代表其对环境的适应程度,同时也反映了现有种群每一个体的质量好坏,本文将模型的目标函数作为算法的适应度函数:
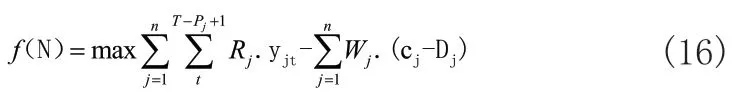
2.4 选择操作
采用锦标赛法作为选择操作策略,并利用精英保留策略保证种群中的最优个体一定被选中。带精英保留策略的锦标赛法步骤为:
步骤1:确定每次从父代种群中随机抽取个体的数量,本文设定数量为0.05N。
步骤2:父代种群个体按照适应度值非增序排列,选择最优的1%父代个体直接复制进入新种群。
步骤3:从经过精英保留后的种群中随机抽取0.05N个父代个体,比较每个被抽取个体的适应度值,复制适应度值相对较大的个体作为新的父代保留。
步骤4:重复步骤3的操作,直到新的父代种群规模达到N。
2.5 交叉操作
本文采用整数矩阵编码,选择单点交叉作为交叉操作方法,然而并非每个经单点交叉后的个体都是可行解,若新个体的染色体中存在基因重复,将导致新个体成为一个不可行解。因此本文设计了原基因重插入法,以此保证交叉生成的新个体是可行解,其操作步骤为:
步骤1:随机选择交叉点,假设交叉点确定为位置4和位置5基因之间处,随后对两个父代染色体进行单点交叉操作,互换交叉点后的基因片段后父代Ⅰ产生的子代染色体为6→5→1→4→1→2。从左往右检查子代染色体,可以发现基因1为重复基因,将较早出现的基因1从染色体中剔除,剔除后的子代染色体变为6→5→4→1→2。
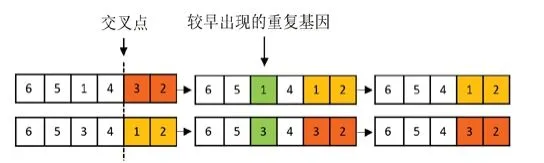
图3 步骤1
步骤2:将父代Ⅰ的互换基因片段添加到子代染色体的末尾。

图4 步骤2
步骤3:再次检查子代染色体,确认基因2为重复基因,将较后出现的重复基因剔除,得到可行解子代染色体为6→5→4→1→2→3。
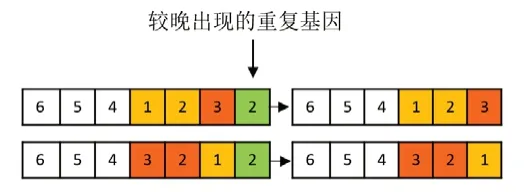
图5 步骤3
步骤4:当父代Ⅱ经相同步骤得到子代染色体6→5→4→3→2→1后,交叉操作结束。
2.5 变异操作
采用互换变异对染色体进行变异操作,如图6所示,随机选定染色体上的两个基因(染色体上的第一个基因除外)互换位置产生新的染色体。

图6 互换变异
2.6 变邻域搜索
邻域结构是变邻域搜索算法的核心部分,将会直接影响算法的搜索质量。根据染色体的编码机制,设计以下两种邻域结构:
1)邻域结构NS1采用部分逆序反转策略。该策略对原始染色体进行较大幅度变动,以扩大邻域搜索空间,能够更好的跳出局部最优。例如一条染色体的原本基因编码为6→5→4→1→2→3,随机选择两个基因位置4和6(基因位置1不可选),将两个之间的基因逆转,得到新的染色体6→5→4→3→2→1。
2)邻域结构NS2采用插入策略。该策略随机选择两个基因位置(基因位置1不可选),将靠后位置上的基因插入至靠前位置的基因前,位置2之后的基因则依次后移,得到新的染色体。
本文对构造邻域进行动态构建,交替使用两种邻域结构,避免单一邻域结构导致搜索效率降低。
2.7 订单拒绝操作
当初始种群经过迭代,满足遗传算法终止条件时,计算新种群中每一个体适应度值,定义适应度值最大的个体为最优个体,其适应度值f(N)即为当前种群的最大目标函数值。若该个体中存在延期订单,则进入订单拒绝操作:新种群中每一个体随机去掉一个订单。
假如某种群个体的第一条染色体为5→4→1→2→3,随机去除一个订单(假设为1号订单)后,表示1号订单被拒绝,2、3、4、5号订单被接受。
被接受的订单将根据种群初始化策略,产生新的初始种群。
2.8 SPGA-VNS算法流程
变邻域半置换遗传算法(SPGA-VNS)求解流程如图7所示:
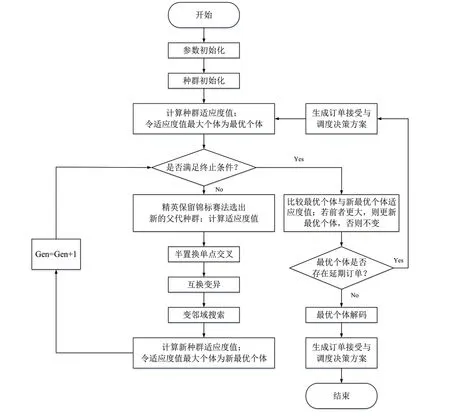
图7 SPGA-VNS算法流程图
3 案例分析
3.1 环境设置
由于目前针对两阶段装配流水线的订单接受与调度问题研究方面尚未有标准算例提出,为了测试所提出的SPGA-VNS性能,本文参考已有的文献生成测试算例,具体生成方案如下:
第一阶段加工机器数量有m=2、4、6三种不同数量,订单数量规模分为小规模、中规模和大规模三种不同数量规模,分别对应n=10、20、30,n=50、75、100以及n=150、200。针对不同规模的算例,每一种机器数量与订单数量的组合都采用随机的方式,生成10个算例。
每台机器上的加工或装配时间由[1,10]之间的离散均匀分布随机产生,即U[1,10]。订单的单位延期惩罚同样由U[1,10]随机生成。第一阶段加工机器上的准备时间由U[1,5]随机产生。由于本文所研究问题的交货期为柔性交货期,所以定义订单的松弛时间DTj由U[1,β.PTi]随机生成,其中PTi=Σpij,松弛程度β可从集合{0.25,0.50,0.75}中选择。每个订单的交货期Dj=maxi{DTj+Sijk+Pij+Pj},订单的收益Rj服从U[1,20]。
算法参数具体设定为:种群规模N=100、迭代次数Gen=1、最大迭代次数maxGen=100、交叉概率CP=0.8、变异概率MP=0.2。
对比算法如下:
1)遗传算法(GA):与SPGA-VNS相比,该遗传算法在种群初始化、交叉操作方面与SPGA-VNS不同,且未对变异产生的新种群进行邻域搜索,其他操作都与所提出的SPGA-VNS方法类似。
2)半置换遗传算法(SPGA):与SPGA-VNS相比,SPGA在种群初始化、交叉、变异、订单拒绝等方面均无区别,唯一不同是未采用邻域搜索算法对种群进行邻域搜索。
SPGA-VNS、SPGA、GA以及CPLEX均在Intel Core i7 CPU、16GB RAM、Windows10操作系统和Python3.7环境下进行编译。
3.2 结果分析
本文通过不同规模算例优化解数量B-number、对偶间隙Gap以及CPU计算时间Time(s)来衡量SPGA-VNS算法的性能。备注:CPLEX在3600秒内能找到优化解,则记可行解为数量1;在3600秒以外才能找到可行解,则记可行解数量为0,CPLEX在运行时长7200秒以内无法找到可行解,则记录该算例CPLEX的可行解数量为NA。SPGA-VNS算法在3600秒内可以找到目标值大于或等于CPLEX的可行解,则记非劣解数量为1,否则为0。
从表2可以看出,CPLEX虽在小规模算例中解得127个可行解,但随着机器数量的增加,可行解数量也在减少。由于订单数量更多的中规模算例中,CPLEX已难以在规定时间内求得可行解,因此不再给出大规模算例下CPLEX可行解和算法非劣解数量。SPGA-VNS算法在小规模算例中求得了96个非劣解,多于SPGA算法的75个和GA算法的42个。虽然订单和机器数量的不断增加,使得三种算法的非劣解数量虽然都逐渐变少,但SPGA-VNS和SPGA算法的求解性能优势逐渐明显,找到的非劣解数量均远多于GA算法。与此同时,β的增大使得算例的求解难度在不断上升,CPLEX和三种算法的求解表现均与β呈现出了负相关的变化趋势。

表2 小规模和中规模算例可行解和非劣解结果表
以上结果说明,利用SPGA-VNS算求解小规模和中规模算例是可行的,且随机半置换策略在规模越大的算例中,对求解效果的提升作用越明显。
对偶间隙能够反映出解在目标值层面的相对优劣,对表3中的对偶间隙Gap定义如下:
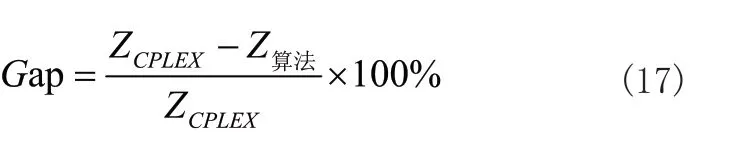
从表3可以看出,小规模算例中,在只有2个加工机器时,CPLEX能找到目标值不低于其他算法的可行解,当加工机器数量增至4个时,SPGA-VNS等三种算法均能找到目标值不小于CPLEX的非劣解,且对偶间隙随着订单数量的增大和β值的上升开始出现负数,这表明算法在机器数量较多时,求解质量优于CPLEX。在所有中等规模算例中,采用了随机半置换策略的SPGA-VNS和SPGA算法都能找到比CPLEX可行解的平均目标值更大的优化解,并且算例规模越大,SPGA-VNS和SPGA算法的求解优势越明显。
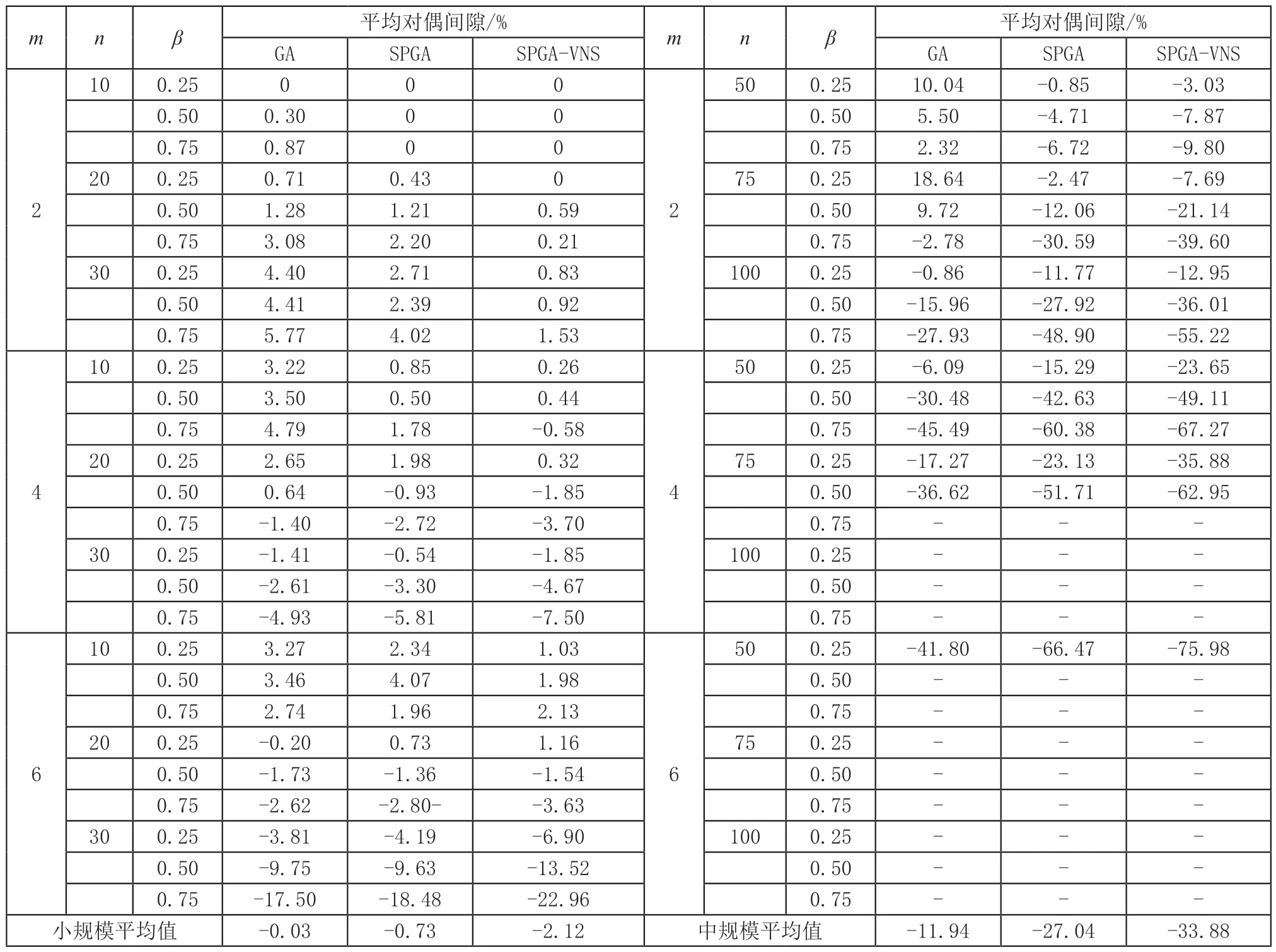
表3 小规模和中规模算例平均对偶间隙结果表
此外,横向对比三种算法,在小规模算例中,SPGA-VNS算法的平均对偶间隙为-2.12%,略优于SPGA和GA算法,但在中规模算例中,SPGA-VNS算法的求解质量表现出了更明显的优势,平均对偶间隙较之SPGA和GA算法分别提升了19.60%和5.38%。
在表4中,重新定义对偶间隙为SPGA-VNS和SPGA算法的优化解与GA算法的优化解在目标值方面的差距,具体计算公式如式(18)所示:

表4 大规模算例平均对偶间隙结果表
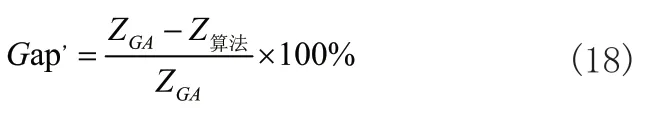
从表4可以看出,相对于GA算法,SPGA-VNS和SPGA算法在大规模算例中,优化解的平均目标值都有较大幅度的提升。
CPU计算时间结果如表5所示,SPGA-VNS和SPGA算法的求解速度较之GA算法均有着一定幅度的领先,且随着算例规模逐渐增大,优势更加明显。在大规模算例中,采用随机半置换策略的SPGA算法求解速度提升了17.52%,同样采用随机半置换策略并结合变邻域搜索的SPGA-VNS则是进一步将求解速度提升了25.39%。
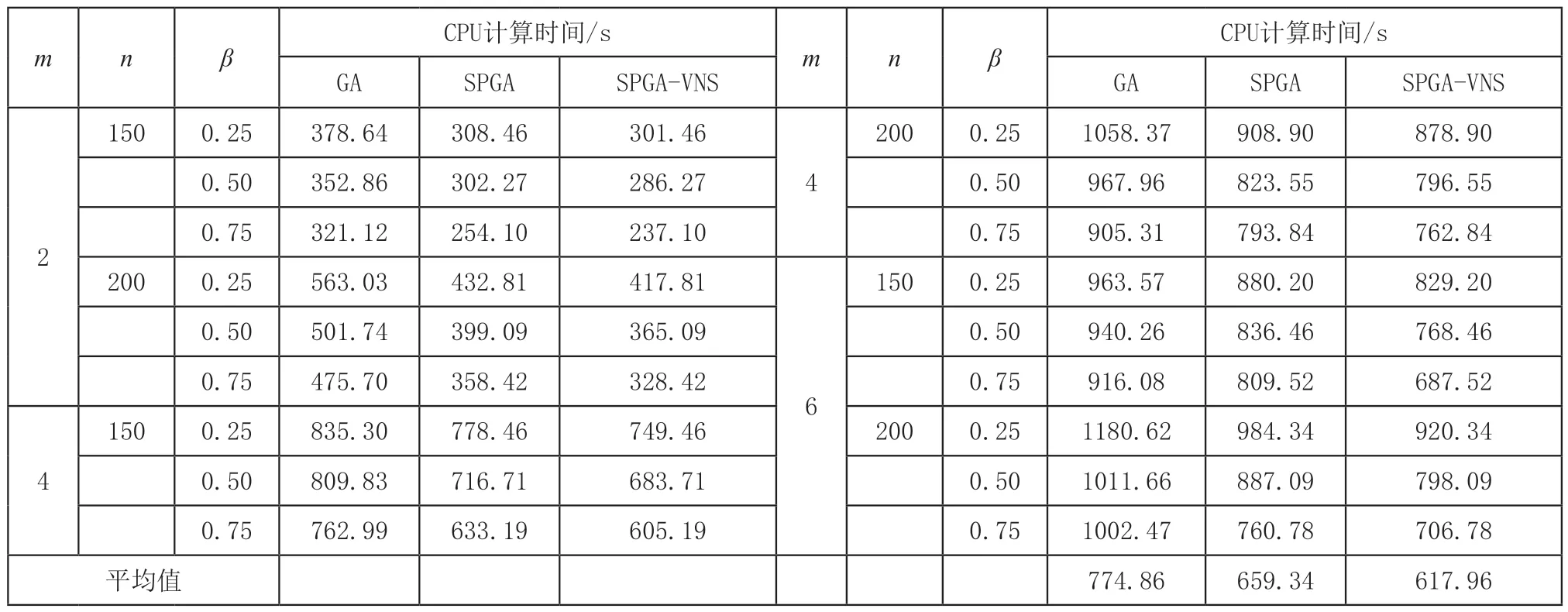
表5 大规模算例CPU计算时间结果表
表6给出了4×10规模算例下,采用分开决策、联合决策的计算结果。通过订单利润、延期惩罚、以及订单延期三个方面的对比,可以看出,对订单接受和生产调度进行联合决策可以在订单利润目标方面比分开决策取得更好的效果,且SPGA-VNS算法可以有效地求解复杂环境下的OAS问题。

表6 4×10规模算例分开决策与联合决策结果表
图8给出了规模为4×10的小规模算例在迭代100次时的算法收敛曲线。可以看出,SPGA-VNS和SPGA算法能够得到较大的适应度值,这说明随机半置换策略能够有效提高算法求解质量;另外,SPGA-VNS算法能在迭代30次左右找到最优解,先于SPGA和GA算法,说明变邻域搜索策略有效的加快了算法收敛速度。以上结果表明,本文提出的SPGA-VNS算法就具有良好的求解质量和收敛性。
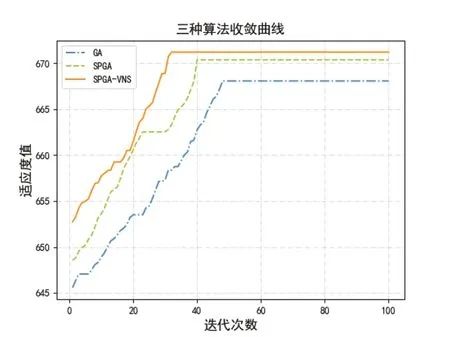
图8 小规模算例算法收敛曲线
4 结语
本文针对两阶段装配流水线的订单接受与调度问题,在考虑具有订单序列相关准备时间约束基础上,建立了以订单利润最大化为目标的TIF-MILP模型,提出了一种采用整数矩阵编码、启发式规则改进初始种群生成策略、随机半置换单点交叉、互换变异等改进策略的改进遗传算法SPGA-VNS,并采用原基因重插入法保证新种群个体均为可行解,结合变邻域搜索提高算法的局部搜索能力。最后,通过不同规模的随机算例测试结果表明,SPGA-VNS算法相较于SPGA、GA算法,可以在合理的时间内更快找到目标值更大的优化解,具有良好的求解质量和收敛性。
