基于AMI数据驱动的窃电用户识别研究
2022-12-11刘文浩冯玥姜东良
刘文浩,冯玥,姜东良
(1.辽宁工程技术大学 电气与控制工程学院,葫芦岛 125105;2.国网冀北电力有限公司迁西县供电分公司,唐山 064300;3.辽宁工程技术大学 软件学院,葫芦岛 125105)
0 引言
电已经成为我们生活中的必需品。电能损失可分为技术损失和非技术损失[1],通常发生在发电、输电和配电过程中。主要的非技术损失之一是窃电。这种不当行为通常包括绕过电表、篡改电表读数或破坏电表等[2]。在发达国家,如美国每年因窃电损失约60亿美元[3]。对于发展中经济体来说,损失的后果要糟糕得多。印度每年因窃电损失170亿美元[4]。其他发展中国家损失了近50%的电力收入[5]。除了会给电力公司造成巨额收入损失外,窃电也会导致电力需求激增、电力系统负荷过重、以及对公共安全的危害(如火灾和电击)。
目前,有大量关于检测窃电的研究。传统的窃电检测方法包括[6]:人工检查有问题的电表安装或错误配置,将异常电表读数与正常电表读数进行比较,以及检查旁路输电线路等。然而,这些方法极其耗时、昂贵且效率低下。智能电网的出现为解决窃电带来了机遇。随着高级计量设施(AMI)的大量安装,用户的用电大数据的收集变成了可能。相比于传统的窃电检测方法,数据驱动方法是更具吸引力的,因为智能电表提供了丰富的能耗数据,成本低并且能提供良好的检测率。
文献[5~10]使用开源的爱尔兰能源数据集[11]对用户窃电检测问题进行了大量研究。但爱尔兰数据集中所有的用户都被认为是诚实用户,需自定义生成窃电用户的数据。自定义窃电用户数据与真实窃电用户数据之间相似性不能保证完全。文献[12]公布出带真实窃电标签的用户用电数据集,针对窃电用户和诚实用户每周和每月用电规律的差异性,从周用电消费趋势和月用电消费趋势两个维度提取特征,搭建卷积神经网络模型进行窃电检测,给出了80%的AUC值。但此方法中数据预处理不够充分,对连续缺失值的插补过多,并且仅考虑不同类型用户自身的用电规律,缺乏不同用户用电数据的直接对比。
考虑到诚实用户与窃电用户用电数据的差异是多样的。我们对数据集中的数据进行严格预处理。通过分析不同类型用户用电数据数值和消费趋势方面的差异性,寻找其它可用于有效分类的特征,并搭配监督学习方法进行试验。
由于时频域参数在故障分类方面有非常多成功的经验[13,14]。为此,我们对用户时频域参数在窃电分类中的研究也做了初步探索,并给出分类结果。试验流程图如图1所示。
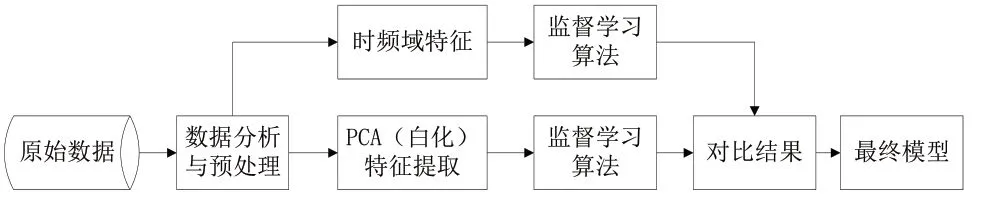
图1 窃电检测流程图
1 数据处理与分析
1.1 数据预处理
源数据集[15]由中国国家电网公司提供,包括42372个用户2014年1月1日至2016年10月31日连续1034天的日用电负荷。其中,有3615个用户被标记为窃电用户,其余则为诚实用户,且数据中包含大量的缺失值。为此,使用Python语言软件的msno模块绘制数据分布矩阵,发现2016年1月1日之前的数据情况存在严重缺失。为保证数据可靠性,我们截取2016年1月1日至2016年10月31日连续304天的的数据,并将其中连续缺失数据超过6天的用户删除,少量缺失值我们对其进行前向插补,最后预处理后的数据情况如表1所示。

表1 预处理后数据信息表
1.2 用户用电行为分析
为证明所提模型的合理性,在建立模型之前,我们对表1中用户进行用电行为分析,绘制负荷图如下。为保证分析数据的有效性,我们对诚实用户和异常用户进行随机抽取。
如图2所示,我们随机抽取诚实用户与窃电用户各三名,绘制出它们连续304天的用电数据曲线,从中我们可以看出总体上,大部分窃电用户的日用电量是低于诚实用户的,并且诚实用户相比窃电用户用电规律具有更强的波动性。此外,我们随机挑选部分用户绘制节假日和休息日的用电数据曲线,如图3、图4所示。从中我们可以观测到节假日和休息日不同类型用户的电量差是变化的,诚实用户的用电波动性更强。除此之外,随机抽取窃电用户与诚实用户各500名,绘制出时频域参数中的无量纲值峭度与偏斜度对比图,如图5所示。

图2 窃电用户与诚实用户用电负荷对比图

图3 节假日用电负荷对比图
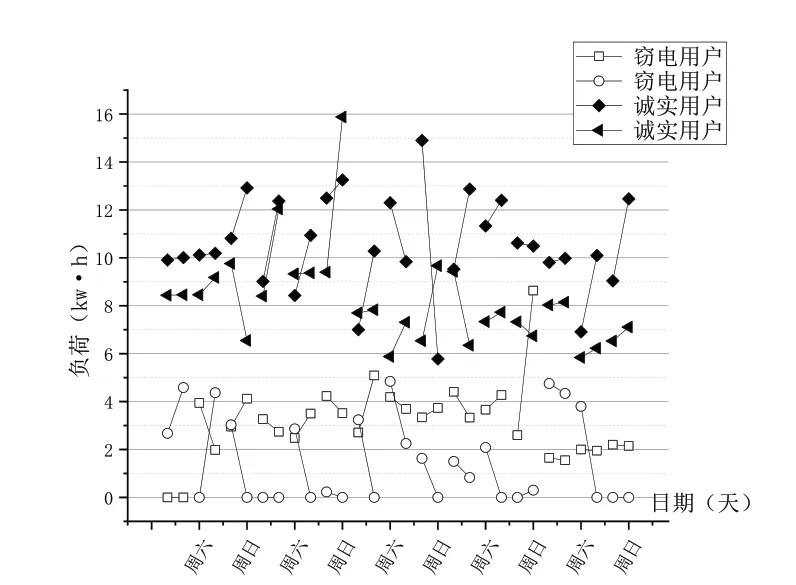
图4 休息日用电负荷对比图

图5 部分时频域特征对比图
基于对比图,利用经验和直观负荷图从数据中提取特征是困难的。在对窃电用户和诚实用户的数据分析中,我们无法看出窃电用户与诚实用户之间用电规律明显的不同。但考虑用电规律的波动性,我们将用户每天的日用电总量作为特征,利用主成分分析(PCA)保留特征中绝大部分信息,进行特征重构继而分类。此外,针对峭度等时频域参数对比图,我们也挑选了部分时频域参数作为特征进行分类。
1.3 数据集的平衡
如表1中窃电用户与诚实用户的数量分布情况。为解决数据类别严重不平衡的问题,在本文中,我们引入合成少数类过采样技术(SMOTE)。SMOTE根据少数类样本人工合成新样本添加到数据集中[16]。原理如下,SMOTE对少数类中每一个样本(x1,x2),以欧式距离为标准计算它与少数类样本集中所有样本的距离,得其k近邻。根据不平衡比例设置采样倍率N,由N从其k近邻中随机选择若干样本,假设选择的近邻为(x'1,x'2)。样本点合成公式如式(1)所示:
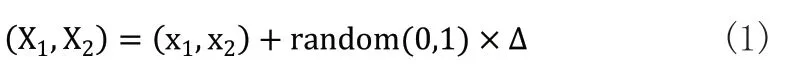
其中Δ={(x'1-x1),(x'2-x2)},random(0,1)为0,1之间的随机数。使用SMOTE后,正常用户和盗窃用户的数量几乎相等。
2 特征提取与用户分类
对窃电识别效果最好的PCA-RandomForest模型给出搭建原理和详细过程,其他则在第3节中简要介绍。
2.1 利用PCA进行特征提取
在探索提议的检测方法之前,简要介绍主成分分析的基本原理[17]。主成分分析是一种统计分析方法,在空间上可以理解为保持源数据集中各样本空间位置不变的情况下,构建新坐标系,使得各样本在这个新的坐标系上的投影具有最大的方差。这样可以在尽可能保留源数据集信息的同时,降低给定高维数据的维数。
在我们的模型中,我们定义每个用户为一个独立的样本,用户每天的用电数据量为其用电特征。我们提取处理后的用户用电数据(细节如表1所示)构建特征矩阵。矩阵的每一行是一个样本的特征向量,即矩阵中有m个样本,每个样本有n个特征值。降维之前我们对数据X进行白化处理,保证数据各维度的方差为1,之后对数据集X应用主成分分析进行降维。
第一主成分如下所示:
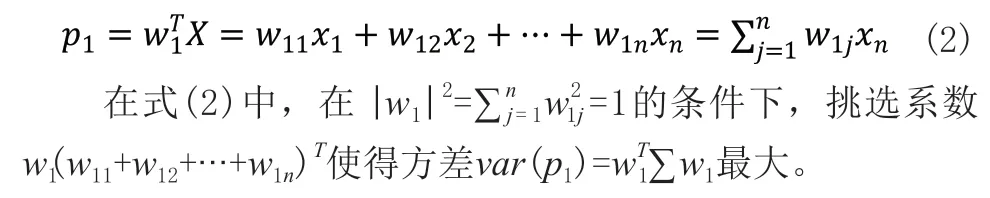
同理,第二主成分被给出为:

同样,我们计算出其他主成分,各主成分所保留信息占比如图6所示,我们选择前7个主成分,重新构建特征矩阵p=[p1,p2,...,p7],这保存了源数据集99%的信息。
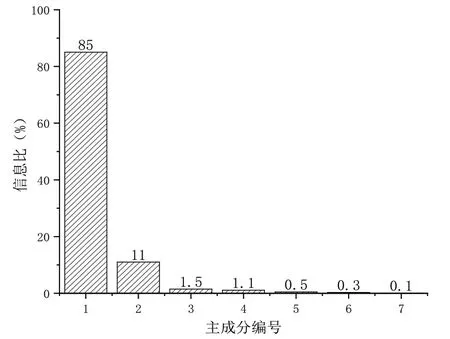
图6 各主成分信息占比图
2.2 利用随机森林进行分类
根据PCA重建数据的特点,随机森林算法用于分类。随机森林算法由多个CART决策树组成。构建每棵决策树前,首先对全部m个样本进行有放回的自助采样,获得与源数据集大小相同,但部分数据点会缺失(大约三分之一)的数据集。接下来,基于新创建的数据集建立决策树。与普通决策树构建不同,随机森林中决策树的构建选择在每个节点处,随机选择特征的一个子集,并对其中一个特征寻找最佳测试。特征子集中特征个数由最大特征数(max_features)参数来控制。由于使用了自助采样,随机森林中构建每颗决策树的数据集都略有不同。由于每个节点的特征选择,每棵树的划分都是基于特征的不同子集。这共同保证随机森林中所有树都不相同。在分类过程中,采取软投票(soft voting)策略。即每个算法做出“软”预测,给出每个可能的输出标签的概率。对所有树的预测概率取平均值,然后将概率最大的类别作为预测结果。
随机森林算法通过Python语言软件平台实现,在实现过程中的一个关键参数是max_features,较小的max_features可以降低过拟合。我们对不同max_features进行试验,默认的max_features=sqrt(n_features)给出了比较好的结果。
3 实验结果与讨论
以(均值,方差,最小值,最大值,峭度,偏斜度,标准差)等七个时频域参数为特征进行分类的结果如表2所示。除此之外,PCA搭配监督学习方法的分类结果也在表2中显示作为对比。

表2 各方法准确率对比表
为证明所提模型的稳定性,随机抽取源数据集不同比例样本进行分类。PCA-RandomForest(R%)指随机抽取源数据集中R%的样本,利用PCA-RandomForest模型进行分类。结果如表3所示。
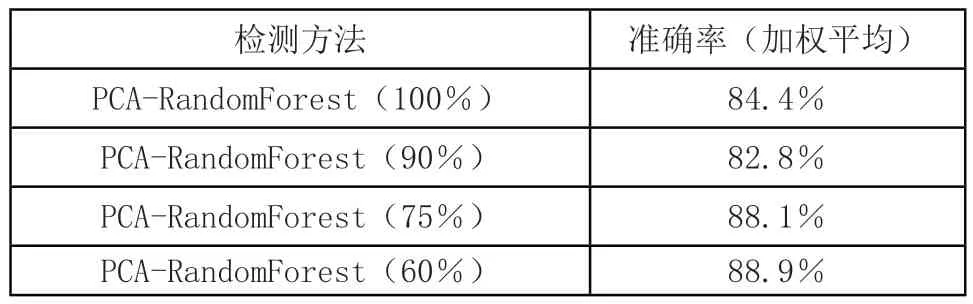
表3 不同比例源数据集准确率对比表
PCA-RandomForest(100%)窃电检测模型的混淆矩阵如图7所示。从中可以看出该模型非常均衡,对窃电用户的识别率达到84%左右,同时对诚实用户的误诊率小于15%。由此证明不同类型用户每天的日用电量也为窃电用户和和诚实用户的不同特征之一,对此特征进行降维后进行窃电用户的识别是有效的。

图7 混淆矩阵图
4 结语
本文基于由中国国家电网公司(SGCC)提供的带窃电用户标签的真实数据集,对不同类型用户用电数据进行分析,建立以用户所有日负荷总量为特征的PCARandomForest窃电检测模型。该模型非常均衡。利用该模型超过84%的窃电用户被识别,而诚实用户的误检率小于15%,这表明日负荷值的差异性同样是识别不同类型用户的有效手段之一。占比源数据集60%~90%的对比实验证明了该模型的稳定性。事实上,由PCA-RandomForest的原理,该模型可适用于很多场景,尤其是工业应用。同时也可与其它模型共同作用,进行异常对象的识别。除此之外,我们对峭度等时频域参数在窃电检测领域中的效果进行了初步探索,给出对比结果,这也是我们正在尝试的方向之一。
