融合工件几何特征的变工况切削力预测方法
2022-12-01常建涛孔宪光李欣伟
常建涛,刘 尧,孔宪光,李欣伟,陈 强,苏 欣
(1.西安电子科技大学 机电工程学院,陕西 西安 710071;2.西安邮电大学 通信与信息工程学院,陕西 西安 710121;3.西安邮电大学 工业互联网研究院,陕西 西安 710121;4.西南电子技术研究所,四川 成都 610036)
切削力是机械加工过程中最重要的状态特征之一[1]。过大的切削力将直接加快刀具磨损,加速机床性能退化,并引发切削系统塑性变形。为了避免切削力过大造成的负面效应,工艺人员通常会选用较保守的切削参数,降低切削速度、进给速率、切削深度和宽度,导致机床的性能无法充分发挥,使得加工效率大幅损失。为了最优化加工质量和加工效率,工艺人员需要在最初检验切削条件,设定最合适的切削参数进行加工。因此,切削力的精确建模预测成为工业界和学术界的重要研究课题。
当前,对切削力预测方法的研究主要分为4类:经验法、切削力系数辨识法、有限元仿真法以及数据驱动法。经验法具有代表性的是ABOU-EL-HOSSEIN等[2]通过对铣削深度、进给量、轴向与切向铣削深度的分析与拟合,对铣削力进行了预测。经验法依赖大量实验数据,忽略了切削加工过程的机理,且无法依据工件几何特征来修正切削力。切削力系数辨识法可以根据实验数据辨识线性模型或者简单的指数模型系数[3],并用该模型对刀片微元的切削力进行描述,再根据各个微元的运动方程求解各个微元切削力,最终叠加求解整体机械加工切削力。SINGH等[4]采用两步最小二乘拟合的方法提取切削力系数,且假定切削力系数为切削速度和切削厚度的函数。但是由于这种方法基于实验数据,因此经常会受外界因素的影响,导致切削力计算精度下降。JIA等[5]将金属切削过程视为一系列微分斜切削过程的线性叠加,提出一种考虑工件材料特性的铣削力预测方法,实验结果证明了该方法具有适用性,但预测精度相对较低。有限元仿真法主要是利用Deform-3D[6]、AdvantageEdge[7]、ABAQUS[8]等软件对机械加工过程进行有限元仿真,计算仿真过程中的切削力。然而机械加工有限元仿真操作复杂,加工几何特征易改变,需要二次构建仿真模型,而且创建的刀具网格量大,计算量大,仿真时间长。
随着大数据技术与智能算法的发展,数据驱动法逐渐应用于切削力预测。KILICKAP等[9]采用硬质合金刀具对钛合金材料进行切削实验,以实验测得的切削力参数数据训练神经网络模型。李鑫等[10]利用神经网络构建切削力预测模型,相对于多元线性回归方法,该模型的准确性得到了很大的提高。JURKOVIC等[11]比较了神经网络、支持向量机和多项式回归这3种数据驱动方法在高速车削加工切削力预测方面的性能,研究表明这3种方法在不同参数组合范围内各有优缺点。目前数据驱动的切削力预测方法多聚焦于刀具本身参数以及切削参数,很少考虑零件几何特征对切削力的影响。然而研究表明,几何特征对加工过程中的切削力变化有显著影响[12],即使在保持刀具、切削参数等不变的情况下,切削力信号幅值仍随着所加工几何特征发生显著变化。另一方面,数据驱动方法依赖于训练数据集与测试数据集的独立同分布假设,而实际生产中加工工况多变,数据分布特性不一,导致模型的泛化性能较差,限制了数据驱动的切削力预测方法在实际生产中的应用。近年来,迁移学习理论和算法[13]打破了传统数据驱动方法严苛的数据独立同分布要求,提高了在不同源域和目标域数据中模型的泛化能力且应用范围广泛,如目标检测[14]、故障诊断[15]等。王俊成等[16]基于迁移学习理论方法,在构建基于神经网络的切削力预测模型时在优化目标中加入数据集之间的最大均值差异距离,可降低对训练样本的数量要求,同时保证了模型的预测精度。
综上所述,当前大多数数据驱动的切削力预测模型只能在规定工况、相似尺寸的情况下使用,一旦工况和尺寸发生变化,预测精度会受到严重影响。而在实际机械加工过程中,加工几何特征种类繁多,加工工况复杂多变,需要考虑几何特征和加工工况的变化构建模型来解决此类问题。因此,笔者提出了一种基于迁移学习的融合工件几何特征的变工况切削力预测方法。该方法可在一定范围内改变所加工工件的几何特征信息,同时可以在源域数据基础上增加少量目标域数据来构建模型,使得模型预测精度显著提高,泛化性能更强。
1 机械加工切削力预测建模
笔者提出的基于迁移学习的融合工件几何特征的变工况切削力预测方法,通过对工件几何特征的形状尺寸信息进行编码,从而将工件几何特征融入切削力预测模型中。联合切削参数、工件材料等作为输入,预测最终切削力大小。总体技术路线如图1所示,具体步骤如下:

图1 技术路线图
(1) 数据汇集。采集机械加工过程数据,包括切削参数(主轴转速、切深、进给速度等)、加工工件的材料数据、工件几何特征数据及切削力信号。
(2) 建模数据集构建。主要包括工件几何特征信息编码、工况信息处理、切削力信号预处理及异常值处理,并根据实验条件划分源域和目标域数据,合并源域数据和部分目标域数据构成训练数据集,剩余目标域数据构成测试数据集。
(3) 构建切削力预测模型。以工件几何特征信息、切削参数、刀具和工件材料特征作为模型输入,利用迁移学习算法Two-Stage TrAdaBoostR2构建切削力预测模型。
(4) 模型验证。用测试数据集对模型进行验证,完成机械加工切削力的预测。
1.1 数据集构建
传统经验知识表明,机床主轴转速、刀具进给量、刀具背吃刀量和加工材料都对机械加工切削力变化具有显著影响。同时实验表明,加工工件不同的几何特征产生的切削力存在明显差异。因此,将上述反应切削力变化的主要参数作为特征向量,并将特征向量按照数据格式不同划分为离散数据和连续数据,根据两者的实际情况,分别进行预处理。
1.1.1 工件几何特征信息编码
工件几何特征信息包括形状和尺寸两部分。对于离散的工件几何形状,采用独热编码进行处理。根据离散数据特征的不同状态,创建一个N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。使用独热编码[17],将离散特征的取值扩展到欧氏空间,离散特征的某个取值就对应欧氏空间的某个点,使非偏序关系的变量取值不具有偏序性,并且到原点是等距的,让特征之间的距离计算更加合理。
实际工业生产中所加工的几何特征以矩形、圆形为主,对于规则连续的工件尺寸信息,可选择两个典型几何尺寸进行描述,如对于矩形槽、缝等,选择长和宽进行量化;对于圆孔,选择两个几何尺寸都等于其直径大小。
1.1.2 工况信息处理
工况信息包含两部分:一部分为切削参数,包括主轴转速、刀具进给量、刀具背吃刀量等;另一部分为刀具几何特征和材料、工件材料特征等。切削参数为连续变量,因而使用其实际值作为模型输入。刀具几何特征以刀具直径值作为模型输入,由于刀具材料、工件材料特征在实际加工中变化次数有限,因而将其作为离散特征,分别进行独热编码后加入模型输入。
1.1.3 切削力信号预处理
在实际工业现场中采集到的切削力往往存在电磁噪声干扰和测力仪的误差干扰,因而对采集到的切削力需要进行滤波降噪,去除趋势项和噪声。
对于正弦波趋势项,通过频谱分析可观察到正弦波趋势项的频率通常低于正常切削力频率,因而可设计一个高通滤波器,将滤波器截止频率设置为略大于正弦波的频率,从而滤除低频的正弦趋势项。对于线性趋势项,可采用最小二乘法进行拟合,并从原始数据中减除,使去除趋势项后的数据均值为零即可。
1.1.4 切削力异常值处理
为了后续建立切削力预测模型,按照所加工几何特征类型对原始切削力信号进行分段,对每一段切削力信号求统计特征值将其转换为单一数值。考虑到切削力信号存在正负值,因而使用均方根值作为切削力信号的统计特征值。由于电磁噪声和外界干扰,切削力信号会出现异常值,倘若不去除将对模型精度造成严重干扰。笔者首先采用多元线性回归拟合切削力经验公式,然后剔除残差过大的值,从而实现异常切削力剔除。根据金属切削理论,切削力经验数学模型可通过三元线性回归方程来拟合:
(1)
其中,Vc为切削速度,f为进给速度,ap为切深,CF为切削力系数。
对式(1)两边取自然对数,得
lnFx=lnCF+b1lnVc+b2lnf+b3lnap。
(2)
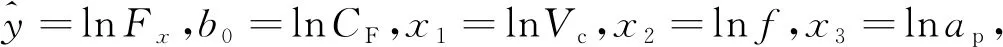
(3)
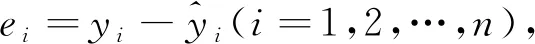
1.2 变工况多尺寸切削力预测模型
切削力预测属于典型回归问题。为了解决不同工况下切削力的预测问题,采用迁移学习来提高模型泛化性能。迁移学习是给定源域Ds和学习任务τs,目标域Dt和学习任务τt,在Ds≠Dt或τs≠τt的情况下,降低预测模型的泛化误差。采用两阶段的TrAdaBoost.R2[18-19]迁移学习算法,最终构建变工况、变几何尺寸下动态切削力预测模型,简称McVs-TrAdaBoost.R2。
TrAdaBoost.R2算法在第1阶段根据每步迭代调整源域样本的权重。当迭代到最后一步时,源域的权重减少量接近0。通过二叉搜索来确定学习器权重是否满足上述条件,然后根据错误率更新源域样本的权重分布。在第2阶段根据AdaBoostR2拟合方式更新目标域的权重分布,同时源域样本的权重保持不变。
输入:源域数据Ts=(D1,D2…,Dk),目标域数据为Tt,其中Ts各数据长度为ni,Tt数据长度为m,弱学习器Learner,迭代次数S,交叉验证次数S。
Fort=1,2,…,S:
(1) 合并源域数据与目标域数据形成训练数据集Ti=(Di,Tt),初始化训练数据的权重分布:
(4)


(5)
(6)
(5) 更新所有样本的权重:
(7)
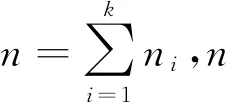
输出:F(x)=FS(x),其中S为误差最小。
2 实验验证
2.1 数据采集
测试实验在一台米克朗HSM600U LP高速铣削加工中心上进行,工件为铝合金样件。
实验1 所用刀具直径为1 mm;工件材料为进口和国产两种铝合金,编号分别为3A21和6061。所加工工件如图2所示。工件上分布着3组几何特征,分别为8.6 mm×8.6 mm 矩形、5.2 mm×5.2 mm矩形以及3.0 mm×8.0 mm槽、1.0 mm×8.0 mm裂缝、13.0 mm×13.0 mm矩形、Φ6.0 mm圆孔。

图2 实验1中的工件几何信息
实验2 刀具直径为1.5 mm和1 mm交替使用,工件材料为国产铝合金6061,所加工工件如图3所示。几何特征分别为Φ8 mm的圆、4.7 mm×1.5 mm细缝、8.4 mm×5.5 mm矩形、7.1 mm×3.6 mm矩形、5 mm×2.1 mm矩形、11.4 mm×4.1 mm矩形。

图3 实验2中的工件几何信息
在实验中使用一台Kistler测力仪测量切削力(型号为9257B),使用一台电荷放大器(型号为5070A)对信号进行放大。测力仪安装布置和电荷放大器如图4所示。

图4 数据采集装置
在实验过程中对切削参数、工件材料和刀具进行调整,每组实验均使用相同参数加工完所有特征,实验1共进行84组试验,实验2共进行50组试验。具体实验条件如表1所示。
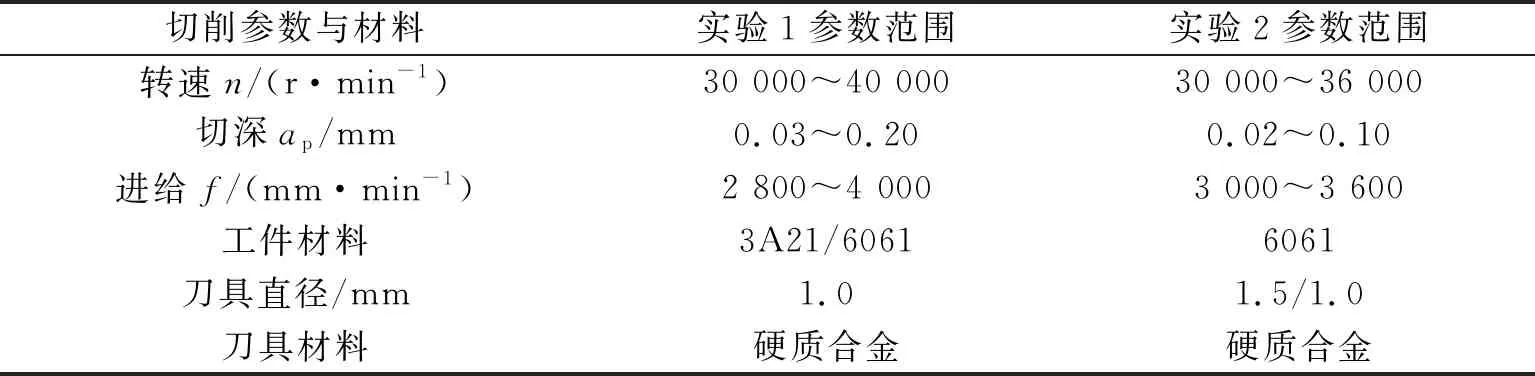
表1 实验条件
2.2 建模数据集构建
2.2.1 工件几何特征信息编码
两次实验工件几何特征按形状分为圆孔、矩形、细缝 3种,对上述离散特征进行独热编码。对于连续的工件尺寸信息,选择两个典型几何尺寸进行描述,编码后的工件几何特征信息如表2所示。

表2 几何特征信息编码
2.2.2 工况信息处理
两次实验的刀具均使用整体立铣刀,材质均为硬质合金。实验1中工件材料为铝合金3A21和6061,实验2中工件材料为铝合金6061。对刀具、工件材料进行编码,如表3所示。

表3 材料编码
刀具几何以直径值作为模型输入,切削参数以实际值作为模型输入。
2.2.3 切削力信号处理
以实验1测试的切削力信号为例,图5是转速为36 000 r/min、轴向切深为0.1 mm、进给速度为3 000 mm/min的切削力信号变化图。从图5中可以明显观察到整个切削力信号可划分为6段,与所加工的6个几何特征相对应。由于铣削加工中影响工件加工变形的主要是X和Y方向的切削力,因而仅对X和Y方向的切削力进行分析建模。

图5 X、Y两向切削力(n=36 000 r/min,ap=0.1 mm,f=3 000 mm/min)
由于测力仪的漂移和传输干扰,部分切削力信号存在趋势项,主要为正弦波趋势和线性趋势。通过滤波处理,原始信号和去除趋势项后的效果如图6和图7所示。
图6 去除线性趋势项
图7 去除正弦波趋势项
2.2.4 切削力异常值处理
对滤波处理后的切削力信号进行分段,计算每段信号的均方根值并作为模型的输出。根据式(1)~(3),利用多元线性回归方法对切削力进行回归拟合,并计算残差。以实验1中加工5.2 mm×5.2 mm矩形几何特征为例,X向切削力预测结果残差图如图8所示。
图8 实验1中加工5.2 mm×5.2 mm矩形X向切削力残差图
由图8可见,大部分残差都分布在零线附近,且有正有负,分布较好。残差图中第28个样本点的残差偏离原点较远,可以认为是由测量或者其他原因造成的异常点,应当予以剔除。
通过以上步骤,最终形成建模数据集。输入参数包括转速、切深、进给速度、刀具直径,以及对刀具、工件材料独热编码,工件几何特征信息编码后的特征;模型输出为加工每个几何特征X和Y方向切削力的均方根值。
2.3 变工况多尺寸的切削力预测建模与结果分析
将数据集分为源域数据和目标域数据。其中实验1数据为源域数据,实验2数据为目标域数据。以源域数据加部分目标域数据构建训练集,剩余目标域数据为测试集,并分析评估不同目标域样本数量下迁移学习模型的性能。将目标域数据采用分层抽样的方式进行划分,保证目标域数据分布的完整性,共分为7组,如表4所示。

表4 数据划分
用以上数据分组分别训练McVs-TrAdaBoost.R2动态模型,采用平均绝对百分比误差(MAPE)评估模型的预测精度。平均绝对百分比误差比较真实值与预测值的误差,相当于把每个点的误差进行了归一化,降低了个别离群点带来的绝对误差的影响,其定义如下:
(8)
X与Y向的切削力预测平均绝对百分比误差如图9和图10 及表5所示。

图9 X向切削力预测
图10 Y向切削力预测

表5 切削力预测平均绝对百分比误差 %
从上述图表分析可以看出,在开始时模型预测误差快速下降,随着训练数据中加入目标域数据样本量增加,模型预测的精度显著提高。当加入的目标域数据样本量达到一定程度后,模型预测的精度趋于稳定。
3 模型验证与对比分析
模型的验证与对比分析主要包括3部分:
(1) 融入几何特征的多尺寸模型与不考虑几何特征的模型验证与对比分析
分别对各尺寸不同特征利用数据驱动算法,如线性回归、SVM[20]、RF、Adaboost、XGBoost[21],构建切削力模型。将上述模型与融入几何特征并利用数据驱动算法构建的切削力模型进行对比分析,采用评价指标——平均绝对百分比误差,说明笔者提出的多尺寸切削力模型具有可行性与实用性。
(2) 变工况模型验证与对比分析
在实际机械加工中,因加工工况变化导致数据分布存在差异,传统的切削力预测方法的精度难以适应变工况切削力预测。实验1、实验2所加工工件的几何特征、工件材料以及刀具直径都发生了变化,因此将两次实验视为变工况。设置实验1的数据作为源域数据,实验2的数据作为目标域数据,针对加工工况变化使用McVs-TrAdaBoost.R2构建变工况切削力模型,同时与不考虑工况的数据驱动方法构建的切削力模型进行对比分析,进一步说明笔者提出的变工况模型具有可行性与泛化性能。
(3) 变工况多尺寸模型的验证分析
为了进一步说明笔者提出的融合工件几何特征的变工况切削力预测方法具有良好的泛化性能与适用性,设置实验1的数据作为源域数据,实验2的数据作为目标域数据,利用笔者提出的变工况多尺寸切削力建模方法以实验1数据加实验2少量数据预测切削力,同时增加对照实验,在机器学习算法基础上基于样本迁移的KMM+Adaboost、基于特征迁移的CORAL[22]+Adaboost算法构建模型。这说明笔者提出的方法具有实用性与泛化性。
3.1 融入几何特征多尺寸模型验证与对比
为说明融合几何特征多尺寸模型方法的可行性,设计两种场景:场景1为尺寸不变化的情况,对两次实验根据不同加工几何特征和不同向切削力和材料进行划分,共形成36组数据,对每组数据按照7∶3分层抽样划分为训练集和测试集,采用数据驱动方法根据加工几何特征依次构建切削力预测模型。场景2为多尺寸的情况,根据笔者提出的融合工件几何特征的变工况切削力预测方法,针对几何特征编码,分别对实验1、实验2的数据按照7∶3分层抽样,划分为训练集和测试集,构建融入几何特征的多尺寸模型,分别观察两者的预测精度。
根据图11和图12分析X向、Y向模型的平均预测准确率可知:X向线性回归切削力模型的平均准确率为31.10%,SVM切削力模型的平均准确率为43.38%,XGBoost切削力模型的平均准确率为36.15%,Adaboost切削力模型的平均准确率为33.67%,RF切削力模型的平均准确率为33.90%。场景1训练后的模型精确度波动范围大,且X向误差较大;Y向线性回归切削力模型的平均准确率为8.46%,SVM切削力模型的平均准确率为7.28%,XGBoost切削力模型的平均准确率为7.81%,Adaboost切削力模型的平均准确率为5.14%,RF切削力模型的平均准确率为5.79%。场景2训练后X向最优模型为XGBoost,其平均准确率为27.47%;Y向最优模型为XGBoost,其平均准确率为4.76%。相比于其他单一尺寸模型,笔者提出的模型X向精度提升6.2%,Y向精度提升0.38%。

图11 单一尺寸场景X向模型MAPE(%)
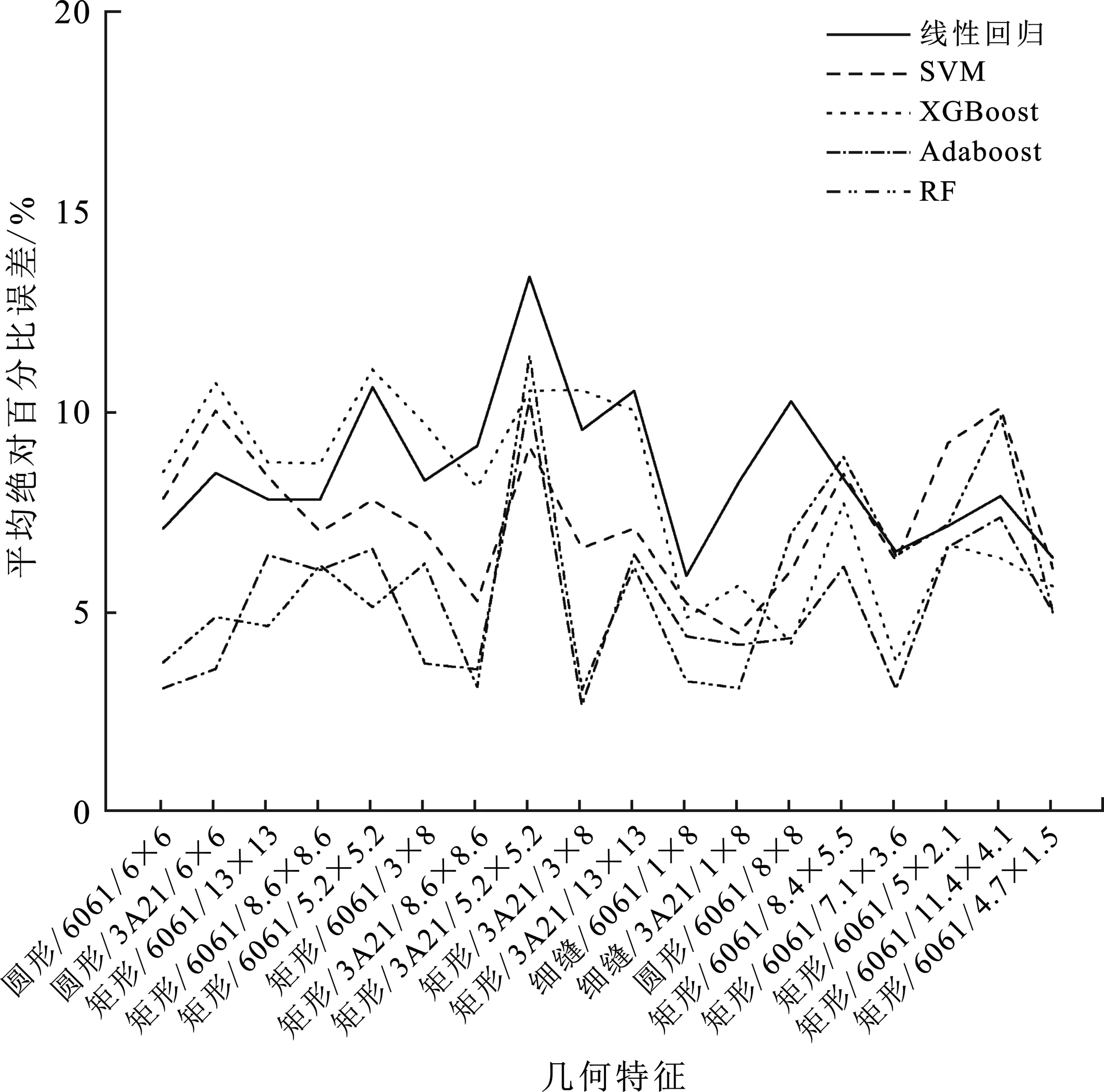
图12 单一尺寸场景Y向模型MAPE(%)
将实验取得的数据列在表6中。分析结果表明,当加工几何特征变化时,需要修正模型,即需要进行新的切削实验采集数据来更新模型的参数,所以不具有通用性。相比于不考虑加工几何特征的模型,融合几何特征的多尺寸切削力预测模型不会出现因几何特征不同而导致的预测精度波动,说明笔者提出的融合几何特征的多尺寸切削力模型具有可行性。
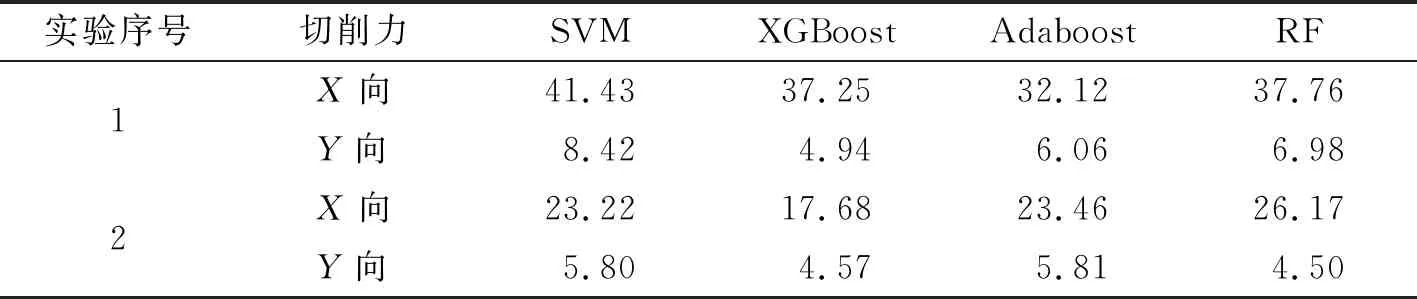
表6 多尺寸场景模型平均绝对百分比误差 %
3.2 变工况模型验证与对比
为说明变工况模型的泛化性能与可行性,采用两个场景构建切削力模型。首先对数据按照加工特征分为矩形数据、圆孔数据、细缝数据。场景3为工况变化场景,以实验1为训练集,实验2为测试集;场景4为工况迁移场景,采用实验1的数据加10%实验2的数据为训练数据,剩余90%实验2的数据为测试数据,构建以矩形、圆孔、细缝几何特征为基础的变工况切削力预测模型,同时与数据驱动切削力预测方法对比,观察笔者提出的方法的泛化性能以及适用性。实验数据如表7和表8所示。
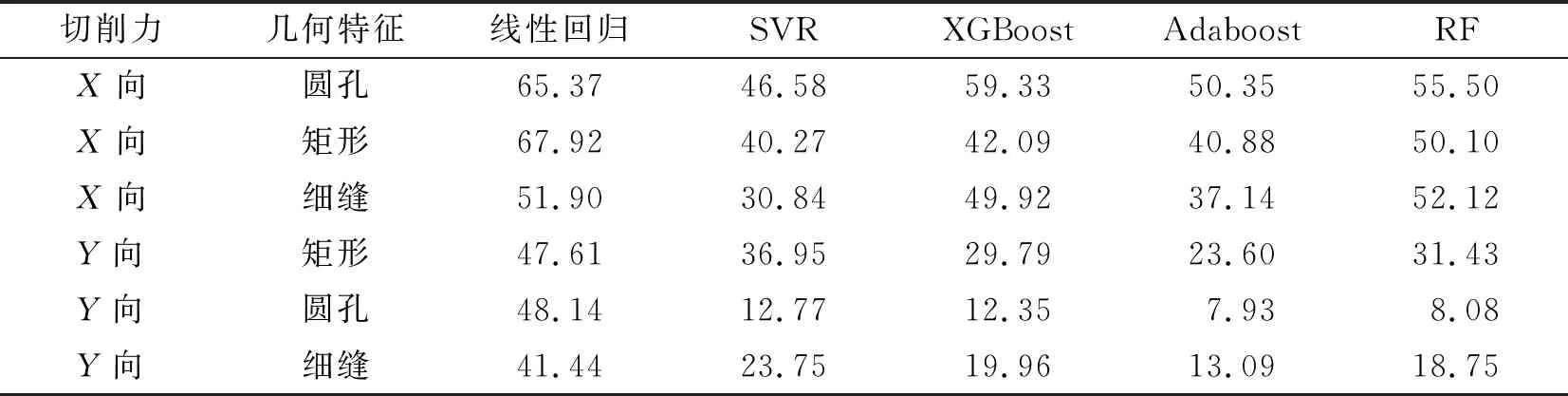
表7 工况变化场景模型平均绝对百分比误差 %
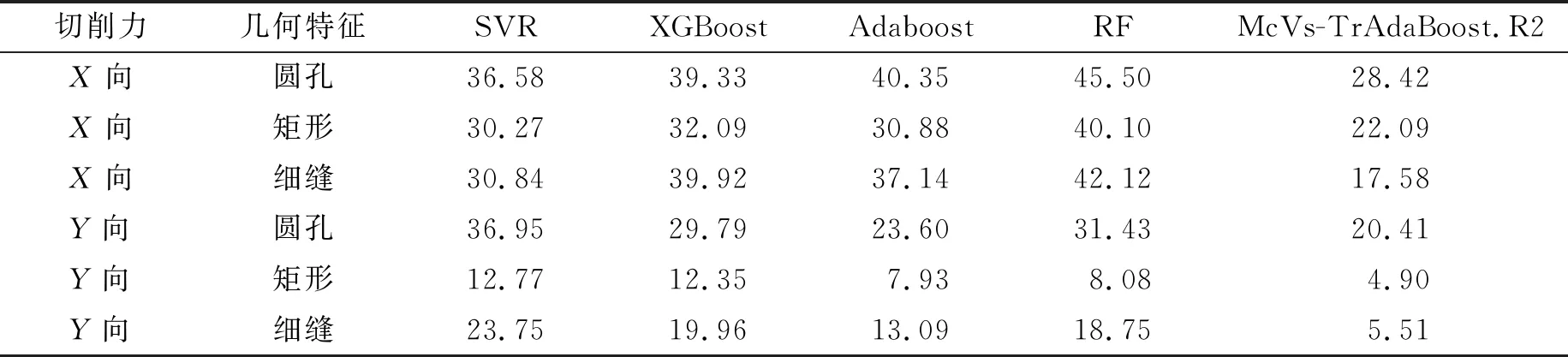
表8 工况迁移场景模型平均绝对百分比误差 %
从表7和表8中可知,场景3线性回归模型的精度降低严重,对机械加工工况变化情况不再适用;而传统数据驱动模型因工况不同引起数据分布不同,导致模型的泛化能力较低。X向的切削力预测精度明显差异较大,说明X向切削力受工况影响严重,数据分布差异明显。为了提高模型的泛化能力,场景4在原训练集基础上增加10%实验2的数据,保证在增加少量新数据情况下提高模型的泛化性能。从表中可明显看出,相比于场景3,场景4模型的预测精度有了提高,同时使用的McVs-TrAdaBoost.R2算法使融合工件几何特征的变工况切削力预测模型的精度提升更为明显。X向矩形切削力预测模型的精度相比于最优数据驱动切削力预测模型的精度提高8.16%,X向圆孔切削力预测模型的精度提高8.18%,X向细缝切削力预测模型的精度提高13.26%;Y向矩形切削力预测模型的精度提高2.19%,Y向圆孔切削力预测模型的精度提高3.03%,Y向细缝切削力预测模型的精度提高7.58%。
根据对场景3和场景4模型预测的精度分析得知,采用数据驱动方法构建的切削力模型受数据分布影响较大,预测精度低;笔者提出的变工况动态切削力预测模型,在X向圆孔、矩形、细缝预测精度分别为28.42%,22.09%,17.58%,Y向圆孔、矩形、细缝预测精度分别为20.41%,4.90%,5.51%。从上文对比中可知预测精度较数据驱动模型有较好的提升,说明笔者提出的融合工件几何特征的变工况切削力预测模型具有更好的泛化性能。
3.3 变工况多尺寸的模型验证与对比
为了进一步说明笔者提出的McVs-TrAdaBoost.R2模型的性能优势,采用3种测试场景:测试场景5为多尺寸工况变化的情况,训练数据为实验1的数据,测试数据为实验2的数据;测试场景6为多尺寸工况迁移的情况,训练数据包括实验1的数据加10%实验2的数据,测试数据为剩余90%实验2的数据;测试场景7为多尺寸单一工况的情况,训练数据为10%实验2的数据,测试集为剩余90%实验2的数据。实验数据如表9和表10所示。
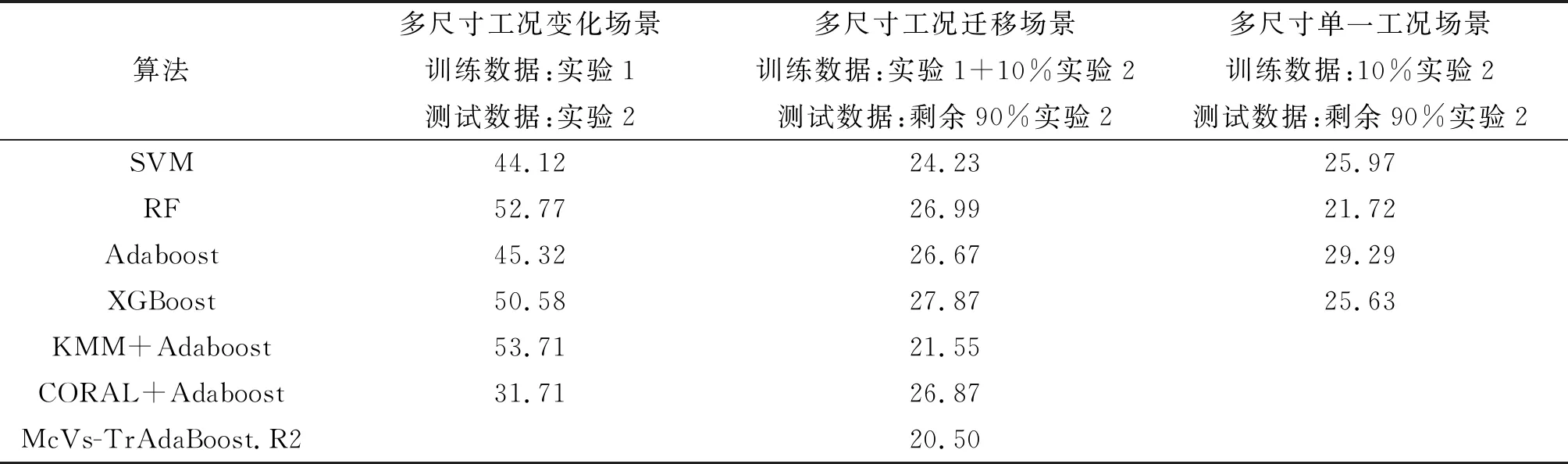
表9 X向各模型学习效果平均绝对百分比误差 %

表10 Y向各模型学习效果平均绝对百分比误差 %
从X向学习效果分析,测试场景5最优切削力模型CORAL+Adaboost的精度为31.71%,模型效果不佳,说明实验1和实验2两次实验的X向数据分布差异较大。测试场景7采用少量训练数据,最优切削力模型RF 的精度为21.72%。场景5、场景3均采用传统数据驱动方式构建切削力模型,测试场景6采用笔者提出的方法进行训练,模型的精度为20.50%。在同测试场景中,笔者提出的方法相比最优传统数据驱动方式构建的模型精度提升3.73%,相比于基于特征的迁移方法的精度提升1.05%;相比测试场景7提升1.22%,相比测试场景5提升11.21%。从Y向学习效果分析,测试场景5最优切削力模型XGBoost的精度为12.6%,相比于X向切削力,Y向切削分布差异较小。测试场景6最优切削力模型XGBoost的精度为10.6%;采用笔者提出的方法进行训练,模型的精度为8.78%。在同测试场景中,笔者提出的模型相比最优传统数据驱动方式构建的模型精度提升0.48%,相比于基于样本的迁移方法精度提升4.34%;相比测试场景7提升1.82%,相比测试场景5提升3.82%。
综上所述,笔者所提方法在结合历史数据和不同分布的小样本数据时提高了模型的预测精度。在数据分布差异较大的变工况机械加工中,预测精度提升1.05%;在数据分布差异较小的变工况机械加工中,预测精度提升0.48%。说明笔者提出的方法进一步降低了数据驱动方法对数据分布一致的要求,提高了模型的泛化性能。
4 总结与展望
笔者提出了一种融合工件几何特征的变工况切削力预测方法,并进行了实验验证和对比分析,结论如下:
(1) 提取加工工件不同几何特征的形状和尺寸信息,加入到切削力预测模型的输入中,使得本模型具备了对不同工件几何特征的辨识能力,可在一定精度范围内改变所加工工件几何特征的尺寸信息,而无须预先对不同几何特征分类训练切削力模型。
(2) 基于迁移学习采用原工况数据结合少量变工况数据构建切削力模型,降低了机器学习方法严苛的数据独立同分布要求,并提升了模型的预测精度。在几何特征相同的情况下,X向模型的精度分别提升8.16%、8.18%、12.26%,Y向模型的精度分别提升2.19%、3.03%、7.58%。
(3) 相较作为对比的其他模型,笔者构建的切削力模型无须大量新工况下的实验数据即可显著地提升泛化性能,X向和Y向都取得了最高的预测精度。
笔者主要对形状规则的几何特征机械加工切削力预测问题进行了研究,然而在实际机械制造中还存在一类自由曲面,其形状并不规则。在未来工作中,将进一步探索对自由曲面类零件几何特征的编码方式,进一步完善所提出的方法。
