事件驱动的微服务调用链路数据动态采集方法
2022-11-30李鹏赵卓峰李寒
李鹏,赵卓峰,李寒
事件驱动的微服务调用链路数据动态采集方法
李鹏1,2*,赵卓峰1,2,李寒1,2
(1.北方工业大学 信息学院,北京 100144; 2.大规模流数据集成与分析技术北京市重点实验室(北方工业大学),北京 100144)(∗通信作者电子邮箱lipeng_2@126.com)
微服务调用链路数据是微服务应用系统日常运行中产生的一类重要数据,它以链路形式记录了微服务应用中一次用户请求对应的一系列服务调用信息。由于系统的分布性,微服务调用链路数据产生在不同的微服务部署节点,当前对这些分布数据的采集一般采用全量采集和采样采集两种方法。全量采集会产生较大数据传输和数据存储等成本,而采样采集则可能会漏掉关键的链路数据。因此,提出一种基于事件驱动和流水线采样的微服务调用链路数据动态采集方法,并基于开源软件Zipkin设计实现了一个微服务调用链路数据动态采集系统。该系统首先对不同节点符合预定义事件特征的链路数据进行流水线采样,即数据采集服务端只在某节点产生事件定义的数据时对所有节点采集同一链路数据;同时,针对不同节点的数据产生速率不一致问题,采用基于时间窗口的多线程流式数据处理和数据同步技术实现不同节点的数据采集和传递;最后,针对各节点链路数据到达服务端先后顺序不一的问题,通过时序对齐方式进行全链路数据的同步和汇总。在公开的微服务调用链路数据集上的实验结果表明,相较于全量采集和采样采集方法,所提方法对于包含异常、慢响应等特定事件的链路数据具有采集准确性高、效率好的效果。
微服务;调用链路数据;动态采样;事件匹配;缓存机制;服务链路追踪
0 引言
微服务架构正逐步成为当前的一种主流软件体系结构,具有易扩展、易维护、高可靠、高可用等特点[1]。相较于传统单体式软件架构,它在软件的开发、部署、维护和运行环境容器化等方面也具有较大优势。微服务架构的主要思想是:将传统单体应用根据业务逻辑和其功能拆分成一系列可以被独立设计、开发、部署、运维的软件服务单元,并且在遵守服务边界的前提下,各个微服务能够彼此相互配合与协作来实现整个系统的价值[2]。但另一方面,随着微服务架构应用系统复杂度越来越高,系统架构变化日益频繁,应用中隐含的服务调用和依赖关系也越来越复杂。当应用涉及的某个服务出现问题,可能导致众多其他服务都出现异常,从而给微服务应用的可靠性保障、性能优化和运维管理等带来诸多新的问题。为此,迫切需要对微服务应用使用过程中涉及的微服务调用链路数据进行有效的收集、记录、管理和分析[3]。
服务链路追踪系统[4]是为应对上述挑战而提出的一类微服务应用支撑系统,它可以用来记录微服务应用的所有请求信息及请求背后涉及的一系列微服务调用信息,包括涉及的服务调用、对应的机器、每个服务调用的耗时和异常情况等,并基于这些信息提供服务调用拓扑分析、调用量统计、异常定位和风险预测等分析功能以支持微服务应用运维[5]。由于这些信息可以根据对应的请求被组织成一系列相关服务调用的数据链,因此被称为服务调用链路。
微服务调用链路数据采集是服务链路追踪系统的基础功能。虽然丰富的链路数据会对后续的应用分析提供有效的支持,然而在分布式环境下进行链路数据采集时,由于原始监控数据分布在一组不同的节点,所需采集的数据越多就需要消耗越多的跨节点数据传输和采集数据存储等成本。因此,随着微服务应用规模及访问数量的增大,对服务调用链路数据进行全量采集变得愈发困难。为此,当前研究者的一种思路是对链路数据通过不同的采样方式进行采集,即只按照一定的采样策略对相应的链路数据进行采集,从而降低链路数据采集的代价。
采样策略一般有定频采样[6]、固定比例采样(Probabilistic Sampling)[7]、蓄水池采样(Rate Limiting Sampling)[8]等不同方式。定频采样按照给定的采样频率对链路数据进行收集,如图1所示的每间隔3 s对链路数据进行一次采集。固定比例采样中的固定比例是指不考虑样品变异性的大小,按统一的比例进行采样,并维持采集到的链路完整性。蓄水池采样是对于一个不知道大小的集合(通常是流式数据),抽取的样本值能够保证随机,每个样本被选中的概率都是相等的,适用于对一个不清楚规模的数据集进行采样。
上述采样方法本质上仍是由链路追踪系统预定义的固定采集方法,系统确定采样采集的静态策略,而采集功能的核心问题就在于保证服务调用链的完整性。这类采样采集方法虽然可以减少一定的数据采集成本,但仍存在两个方面的问题:一是一些具有特定信息(如异常、响应慢或超时等)的链路数据可能由于不在采样策略范围内而被遗漏,而这些链路数据对后续链路分析具有重要意义;二是此方式下采集的大量链路数据都是微服务正常情况下的相似信息,而这些信息在链路分析中意义有限,也就意味着仍然会产生较大的不必要采集成本。
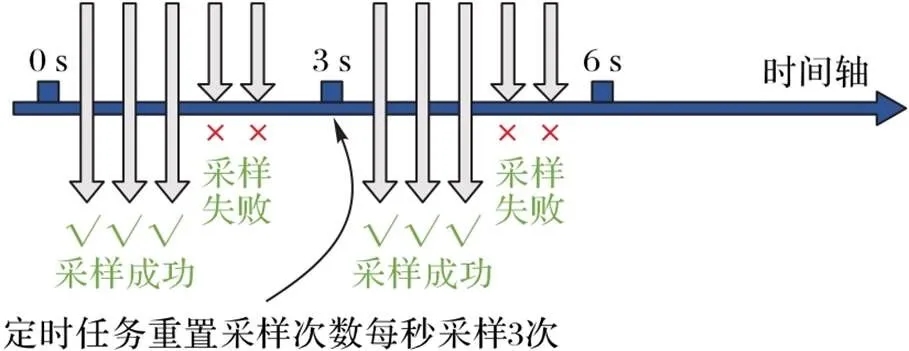
图1 定频采样示意图
针对上述问题,本文提出了一种基于事件驱动的链路数据动态采集方法。在该方法下,需要对所需采集的服务调用链路在任意微服务节点的数据信息由节点客户端根据事件特征进行实时判定,如果发现符合预定义事件的数据特征,则该数据所对应的服务链路在所有微服务节点的数据才会在系统服务端协调下被动态地采集。事件特征是指面向用户关心的服务链路数据包含的数据内容,如特定错误状态码、超时标记或者符合特定规则的数据等。这些用户指定的特定数据内容以预定义的方式储存在特征数据库中并分发给各微服务节点。该方法的难点在于如何在各分布节点上利用有限的资源快速发现符合事件定义的链路数据以及获取与该链路对应的所有相关数据并发送到链路追踪系统服务端。
围绕上述思路,本文开展的主要工作包括:
1)微服务节点链路事件特征定义方法及流式识别机制。给出了基于正则表达式的链路事件定义方法,并采用流计算模型对各节点实时产生的链路数据不间断地进行预定义事件的判定,及时发现包含事件特征的微服务调用链路。
2)基于多线程的多节点链路数据高效获取与缓存机制。对各微服务节点一定时间周期的链路数据采用Hash B树结构进行缓存,并在链路追踪系统服务端发出特定链路数据请求时提供一种相应的查询算法以快速获取相应的链路数据。
3)服务端全链路数据同步和汇总机制。提出一种服务端和节点端的同步机制,以支持数据采集服务端与各微服务节点控制交互和数据收集,并在服务端实现根据链路标识对来自不同节点的时序错乱数据进行对齐和汇总,以得到一个完整的服务调用链路数据。
1 背景知识
1.1 链路追踪
“链路追踪”一词最早出现在谷歌发表的分布式链路追踪系统Dapper[9]论文中。如图2给出了一个微服务调用链路追踪的概念示意,图中展示了一个与用户请求响应过程对应的服务调用链路,其中涉及五个相关的微服务,包括:前端微服务(A),两个中间层微服务(B和C),以及两个后端微服务(D和E)。当用户发起一个请求时,首先到达前端微服务A,然后发送两个远程过程调用(Remote Procedure Call, RPC)调用到微服务B和C。B会立即作出响应,但是C需要与后端的微服务D和E交互之后再响应结果给A,最后再由A来响应最初的用户请求。像图2的服务链路追踪过程,每一次发送和接收动作的跟踪标识符和时间戳都会被收集到。
微服务调用链路的定义主要包括两个核心概念:Trace和Span。Trace对应一次请求涉及的所有服务调用组成的调用链,即一个Trace包含一组Span。Span表示每一次对微服务的调用,它是调用链路的基本单元。每个Span包括对应的traceid、调用起始时间、标注、日志、相关Span等信息。Span之间具有父子和跟随两种关系,分别表示父Span对应微服务对子Span对应微服务之间的直接调用关系(如图2中A到B和C的调用关系)以及没有调用依赖(不依赖被调用微服务的结果,只有先后关系)的特殊父子关系。表1给出了一个服务调用链路数据的示例。
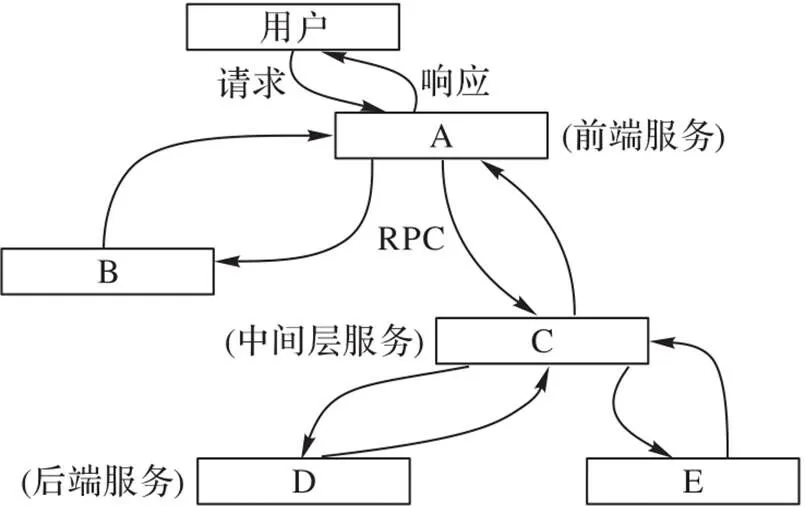
图2 服务链路追踪示意图

表1 服务调用链路数据示例
1.2 链路追踪系统
Dapper系统开始只具有调用链路追踪功能,后来逐渐演化成了监控平台,并且基于监控平台扩展出了很多工具,如实时预警、过载保护、指标数据查询等。除了谷歌的Dapper,还有一些其他知名的链路追踪系统,如阿里的鹰眼、美团的CAT[10]、Twitter的Zipkin[11]、Apache的SkyWalking[12]等。虽然这些系统各有特点,但一般都包括四部分核心内容:链路数据采集、链路数据存储、数据查询分析和数据展示。本文以Zipkin为例具体说明链路追踪系统的体系架构和网络拓扑。
如图3所示,在Zipkin系统架构中,分布式系统由一组节点组成,它一般与微服务部署的节点一一对应,在节点上部署系统客户端,负责处理和缓存该节点上的服务调用数据,并以REST API接口的形式对外提供数据获取支持。图中虚线框内包含负责各节点数据收集和汇总的Collector、负责数据存储的Storage以及数据查询展示的RESTful API和Web UI,可以看作是Zipkin系统的服务端。其中与服务链路数据采集相关的主要是由多个节点构成的分布式系统部分和服务端的Collector[11]。
产生微服务调用数据的各分布式节点客户端和服务端的Collector进行数据交互时有全量采集和抽样采集两种方式。由于目前采样方式的限制,全量采集耗时多、速度慢,而抽样采集会导致一些关键调用数据没有被采集到,或者只是捕捉到具有关键信息的某条调用链路的部分数据(部分Span),不能得到整体的Trace(所有Span)。这些情况在微服务应用异常分析和Debug调试时会带来不利的影响。
综上所述,当前的服务调用链路系统在实际应用中只考虑抽样采集数据,对于符合用户请求特征的调用链路数据可能因为该采样方式而无法捕捉到,导致不能准确分析链路信息。而且完整的服务调用链路数据可能分布在不同节点,不同节点上的微服务调用数据在时间上可能有前有后,同时随着每个节点产生大量不同请求的调用链路,对符合请求特征的调用链路数据采集就变得更加困难。因此,本文设计了一种事件驱动的微服务调用链路数据动态采集方法解决上述问题。
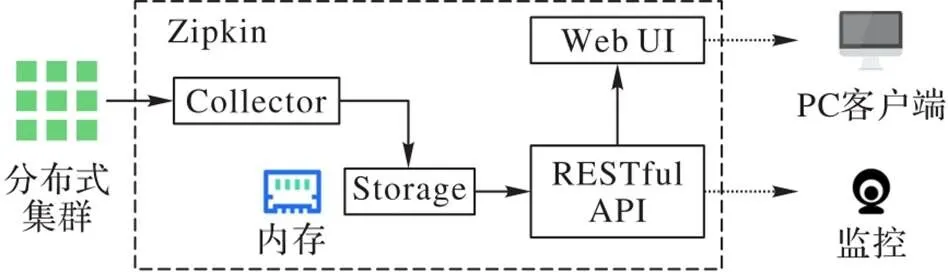
图3 Zipkin系统架构
2 事件驱动的微服务调用链路数据动态采集
2.1 方法思想和核心流程
如图4所示,事件驱动的微服务调用链路数据动态采集方法的核心思想是一种由服务调用数据源节点根据事件识别结果触发进行链路数据采集的方式[13]。
首先,需要在微服务调用数据生成的节点端给出一种事件特征定义方式以及服务调用数据上的实时事件识别机制。考虑到服务调用数据的实时性,采用流计算模型对各节点实时产生的链路数据进行预定义事件的判定,及时发现包含事件特征的微服务调用链路信息。
其次,在某节点发现符合事件特征的调用数据后,会与服务端进行交互并由服务端协调所有节点(广播方式),将一定时间范围内的相关链路数据收集到服务端。为此,各节点需要对一定时间周期内的链路数据进行缓存,并设计与之匹配的查询算法,以获取服务端所需数据。
最后,服务端对来自不同节点的链路数据进行汇总,以形成完整的服务调用全链路数据。汇总过程中,考虑到网络通信影响,需要按照链路标识对各节点数据进行同步和基于时序的对齐。
图4 事件驱动的调用链路数据动态采集方法流程
根据上述思想,事件驱动的微服务调用链路数据动态采集方法如下:
当任何节点出现符合采样条件的链路数据时(重要特征数据),就采集该请求的所有链路数据,由于跨节点的调用链路在全局上是无序的,且同一服务调用链中发生也有前后时间顺序,为此,动态全量采集方法利用有限的资源快速找到符合采样条件的服务调用链路。
数据处理客户端首先从每个节点拉取链路数据,在数据处理层做第一次过滤操作,进行初步的数据清洗,为了尽快高效地进行异常链路追踪,利用客户端的内存进行缓存,但由于内存空间有限,无法在内存中做全量缓存,需要做流式缓存处理,可采用基于时间窗口的方式来处理,找到异常链路的traceid发送到服务器端。
数据汇总服务端接收到客户端的异常链路的traceid后,再去广播发送到每个数据客户端。由于各个节点的数据处理速度不一,且存在并发执行的现象,导致某些节点的数据持续上报,而另外的其他节点数据迟迟未上报,这就需要考虑超时处理,清除缓存,实现数据同步。本文方法计划采用多个线程来处理,可分为数据处理和数据同步线程。
为了实现上述思想和流程,本文方法主要包括三部分内容:
1)微服务节点链路事件特征定义方法及流式识别机制;
2)基于多线程的多节点链路数据缓存和高效获取机制;
3)服务端全链路数据同步和汇总机制。
2.2 微服务节点链路事件特征定义方法及流式识别机制
2.2.1特征事件的定义
特征事件是指含有重要特征的链路数据。预定义事件特征,以便识别特定事件,及时发现包含事件数据特征的微服务调用链路信息。
本文分为以下三类事件:
1)错请求,指链路数据中包含错误信息或链路数据无具体信息。
2)慢响应,指链路请求时间过长导致一次请求超时。
3)异常请求,指调用链路请求信息中有类似http异常状态码。
节点中的链路数据存储于客户端缓存,客户端对其进行处理分析,根据事件预定义的规则匹配到的特征链路数据,将其记录于特定的数据结构为下一步作准备。
事件匹配采用字符串匹配和正则表达式的方法。
字符串匹配较为简单,因大部分请求基于http协议,包含HTTP状态码的信息头,所以在特征数据库中定义与状态码相对应的字符串,如Code=500、Code=503、Code=505、Code=404、Code=403等。该方式匹配简单、快速,但规则固定,匹配范围小。
正则表达式[14]描述了一种字符串匹配的模式,检查链路数据是否包含具有某种语法规则的字符串,是对字符串匹配的加强和完善。
根据正则表达式的基本规则,采集到的链路数据URL正则表达式为:/http[s]{0,1}://([w.]+/?)S*/,最终表达式为:*^[a-z]+://([a-z0-9]{1}[a-z0-9_-]*.)*([a-z0-9]+.)*[a-z0-9]+(/[^f v]*)*$*/。
2.2.2基于流处理的事件识别
采用流计算模型对各节点客户端实时产生的链路数据不间断进行特征事件的判定,及时发现包含数据特征的微服务调用链路信息。
利用缓存机制和预定义的事件匹配规则,快速高效地找到事件数据特征的链路信息。
基于流处理的事件识别如算法1所示,首先将数据与预定义的事件规则进行匹配,若匹配到则符合含有数据特征的链路信息,将其保存到errorSet中,否则保存到traceMap中。
算法1 流处理的事件识别算法。
输入 调用链路数据流;
输出 存放事件匹配特征数据traceid的errorSet;缓存中链路数据traceMap。
1) If 数据流匹配预定义的事件规则
2) 该数据保存到缓存的errorSet中
3) Else
4) 数据保存到缓存中的traceMap中
5) End If
6) If 缓存大小超过设置的缓存大小
7) 客户端停止拉取数据
8) End If
2.3 基于多线程的多节点链路数据缓存和高效获取机制
在某客户端节点发现符合事件特征的调用数据后,会与服务端进行交互并由服务端协调所有节点(广播方式)将一定时间范围内的相关链路数据进行汇总。随着调用链路数据增多,客户端内存有限,数据无法实现全量缓存。为此,本文设计了一种基于客户端节点的流式缓存处理机制,采用时间窗口方式来处理缓存数据,找到异常链路的traceid,将其发送到服务器端,并设计了一种高效查询算法以获取服务端所需数据。
通过进一步分析原始调用链路数据,由于调用链路采用OpenTracing规范[15],每一个trace类似树结构,所以采用Hash B树结构来存储客户端缓存。
Hash B树算法是结合了支持快速查询的Hash算法和支持树结构全值匹配的B Tree索引算法[16-18],可以快速高效地查询缓存中的数据。
客户端节点的微服务调用数据缓存结构如图5所示。traceid由Hash数组存储,当查找某traceid时,利用Hash算法快速查找到所在数组的位置,通过B Tree索引进一步查询具体所需要的span链。
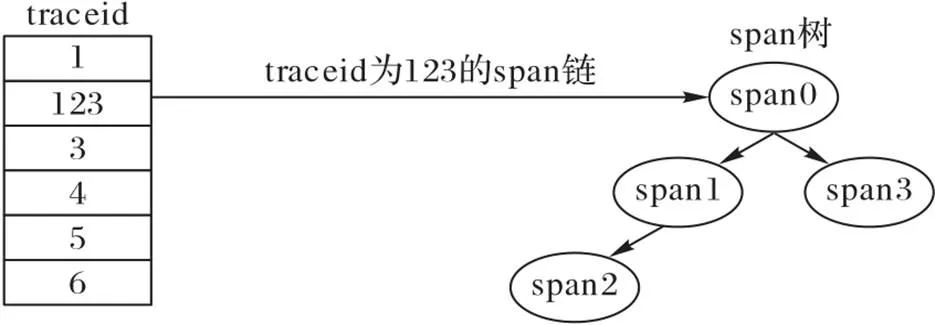
图5 微服务调用数据缓存结构
本文采用的Hash B树结构,客户端缓存大小设计为1 GB,最大容量为200万条(每条数据最大约为500 B)。缓存采用hashMap的K‑V存储结构,方便快速根据traceid读取到整条trace信息。
算法2 多节点流处理算法。
输入 调用链路数据流;
输出 存放事件匹配特征数据traceid的errorSet;缓存中链路数据traceMap。
1) List
2) Set
6) Map
7) IF(map.get(key)!= null)
8) map.get(key).add(value);
9) Else
10) List
11) list.add(value);
12) map.put(key,list);
13) END IF
14) IF value包含特征事件
15) errorSet.add(key);
16) traceMap=map.get(key);
17) END IF
18) END FOR
19) RETURN errorSet,traceMap
如算法2所示,在向缓存中存储数据之前,根据预定义的事件规则,若匹配到含有重要特征的事件,则将该traceid存放到errorSet中,若缓存接近0.8 GB或超过0.8 GB,客户端则减缓拉取数据的速度,避免缓存溢出导致客户端处理崩溃。根据errorSet中的traceid,从Map中找到该traceid的所有调用链span,由于trace是全局无序的,可能另外的客户端含有异常信息的某条trace在该客户端却是正常的,但也要完成采集,所以必须等待所有客户端同一批次的数据流缓存处理完成后再进行缓存清理。客户端处理后发送完成一个信号量给服务端,然后等待服务端响应。
2.4 服务端全链路数据汇总和同步机制
基于事件驱动动态采样方法对CPU和内存要求较低,在有限的物理资源下能充分利用内存资源,快速准确地采集重要特征数据。当节点数量变多时,如果客户端节点之间直接通信会使得整体客户端处理变得复杂,不易维护。故本文采用客户端节点与服务端节点之间通信来实现整体系统的通信。
服务端负责对各个客户端节点发送的traceid进行汇总,并将汇总的信息广播同步到所有客户端,并对客户端发来的调用链路span归并处理。
1)数据汇总。数据汇总分两部分:一是对多个客户端发来的traceid进行汇总,及时更新traceMap(保存的是含有错误信息的链路的traceid);二是对客户端发送的调用链路span进行归并,按调用时间和traceid拼接成一条完整的trace。
2)广播同步。通过广播的方式,发送更新好的traceMap到各个客户端,使各个客户端同步接收到最新的搜索条件。由于可能含有错误信息的相同traceid链路分布在另外的节点上,当前的节点客户端也需要遍历该traceid链路数据并发送给服务端,以此保持监控到的链路完整准确。
3)实现重要特征数据同步机制。图6表示某个客户端与服务器之间的交互,同一批次的数据流缓存处理完成后,客户端向服务端发送信号,等待服务端响应。当接收到服务端响应报文时,响应报文中包含服务端聚合所有的客户端节点的异常调用链路的traceid,数据同步线程会向服务端发送errorSet中traceid的所有调用链,数据处理线程再根据响应报文中traceid搜索当前客户端节点数据流缓存,若找到则发送到服务端。
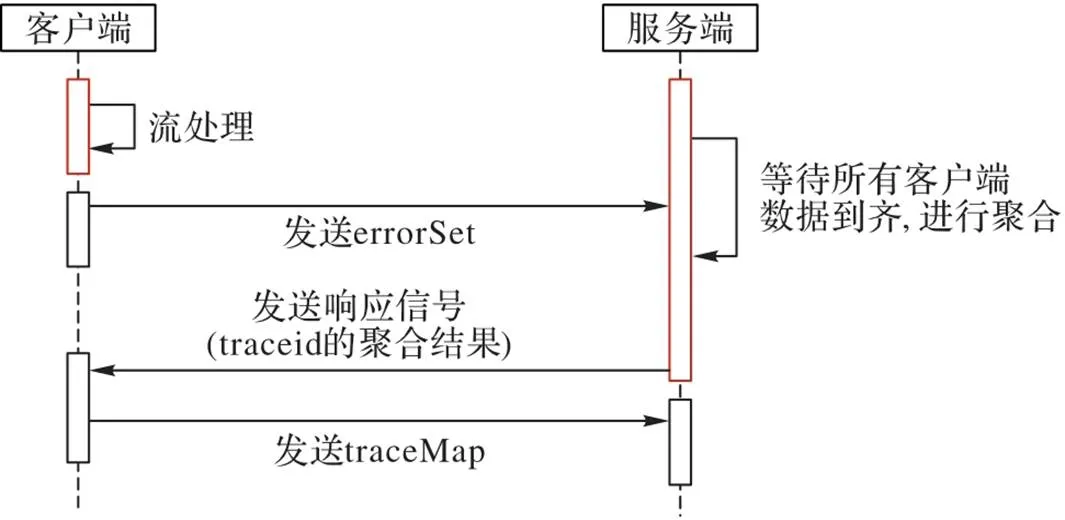
图6 客户端流处理与重要特征数据同步机制
3 系统实现
为了验证本文动态采样方法的准确性和高效性,基于动态采样方式设计实现了一个微服务调用链路数据采集系统[19-21],如图7所示。在该系统中,处理对象是由各个服务模块之间通信产生的调用链路数据,输出为带有异常标记的所有调用链路数据。该框架由三个主要阶段构成,自顶向下包括调用链路生成阶段、收集和处理阶段、存储阶段。各阶段描述如下:
1)调用链路生成阶段。指根据服务模块间的通信和调用生成的请求响应链路,利用Zipkin进行埋点,生成带有时间戳、服务名、ip等信息的调用链路;然后将生成的调用链路写入到分布式的每个节点的日志中。
2)收集和处理阶段。链路收集阶段是从每个节点的日志数据以数据流的形式不断输入到服务处理集群。本文采用动态采样的方法,捕捉所有含有异常信息的traceid链路,更加快捷地处理数据和减少网络输出,充分利用内存资源。
3)储存阶段。将最终捕捉分析到的链路数据存到数据库,并提供查询接口。
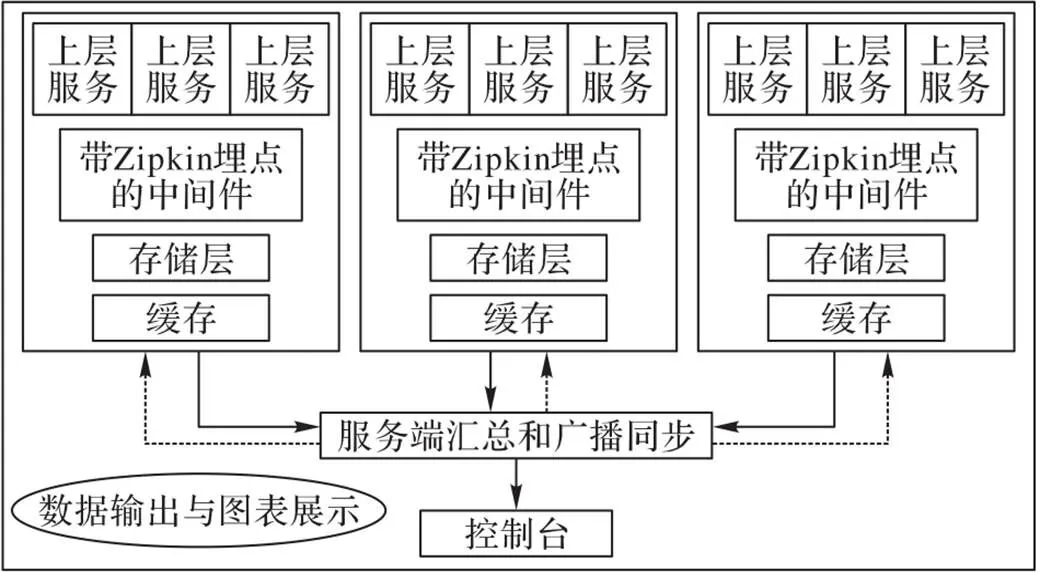
图7 微服务调用链路数据采集系统架构
4 实验与结果分析
4.1 实验环境
为了验证动态采集方法的准确率和性能,本实验准备50个客户端docker容器,1个服务端docker容器。客户端CPU采用英特尔Pentium 双核E5400@2.6 GHz,内存大小为1 GB;服务端CPU采用英特尔Pentium双核E5400@2.6 GHz,内存大小为2 GB。
4.2 数据集
数据集采用阿里开放的服务调用链路数据,共包含两个大小为8 GB的调用链路日志数据。本文对数据格式进行了简化,每行数据(即一个span)包含如下属性:
1)traceid:全局唯一的id,用作整个链路的唯一标识与组装。
2)startTime:调用的开始时间。
3)spanid:调用链中某条数据(span)的id。
4)parentSpanid:调用链中某条数据(span)的父亲id,头节点的span的parantSpanId为0。
5)duration:调用耗时。
6)serviceName:调用的服务名。
7)spanName:调用的埋点名。
8)host:机器标识,比如ip、机器名。
9)tags:链路信息中tag信息,存在多个tag的key和value信息。一般的服务调用链路数据格式为key1=val1&key2=val2&key3=val3,比如含有类似格式的:http.status_code=200&error=1。
4.3 实验评价
本节对异常链路追踪的准确率和采集时间进行验证,并探究了客户端节点数量对本文方法的影响。
1)准确率。指希望采集到的服务链路数据占所有采集到的链路数据的比值,是评估一个采集方法好坏的主要指标。为验证动态采样方法的准确率,与定频采样方法进行对比,如图8所示,定频采样方法每间隔0.2 s采样一次,随着数据量的增大,定频采样找到含有重要特征的异常链路数据准确率逐渐降低,且降低幅度较大,而本文方法依旧保持较高的准确率,准确率接近百分之百(由于时间窗口的限制性可能导致少量数据会丢失)。
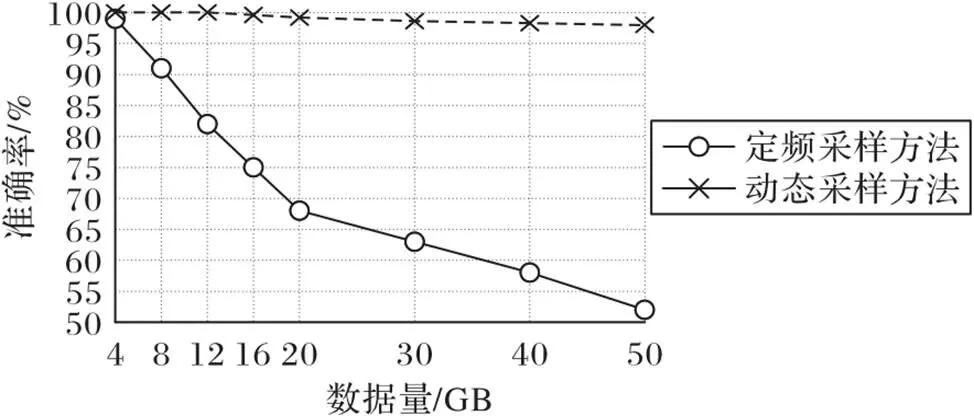
图8 准确率测试结果
2)采集时间。响应速度是评价一个监测方法的主要指标,采集时间越短,表明该方法效率越高。如图9所示,随着数据量的增加,本文的动态采集方法采集异常链路的时间比全量采集方法所用时间更少,且数据量较大时,本文提出的动态采样方法更高效。
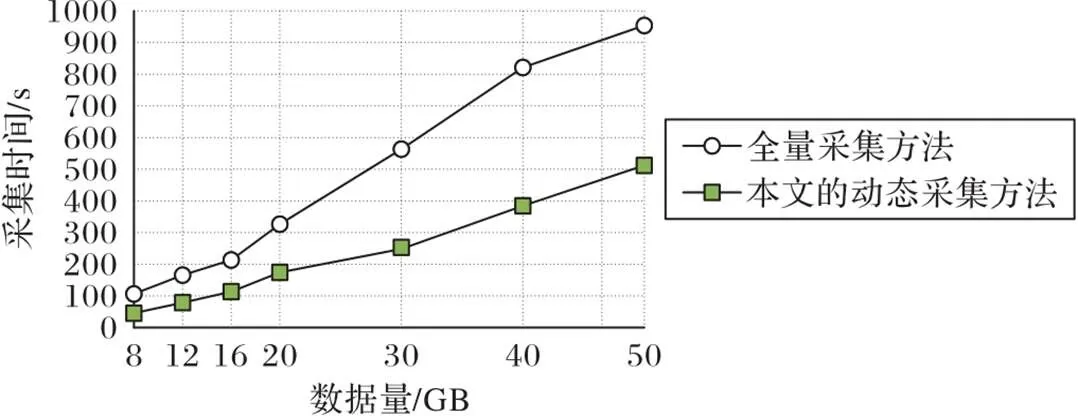
图9 两种方法的采集时间比较
3)客户端节点数量对本文方法影响。如图10所示,当客户端节点越来越多,则处理的线程越多,采集时间耗时少,速度快。数据量越大,客户端节点数对采集时间影响越大,节点数越多,性能越好。
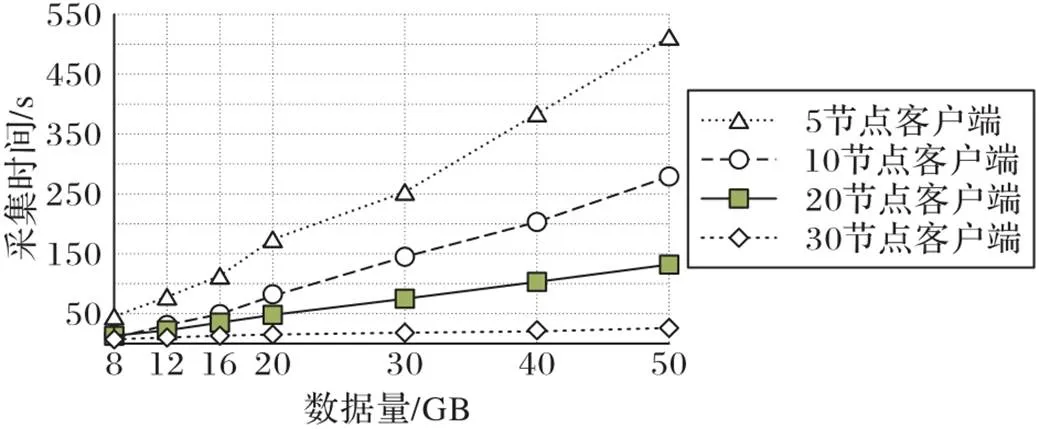
图10 多客户端节点采集时间比较
5 结语
本文提出了一种针对调用链路进行故障排查和异常链路信息监控的高效动态采样方法,并基于动态采样方式设计实现了一个微服务调用链路采集系统,能够在分布式系统快速追踪到含有标记信息的链路,可用于链路故障追踪和错误分析。通过缓存技术和通信机制实现了在有限资源内快速找到含有重要特征的所有链路数据,并保持调用链路的连贯性。该方法弥补了单节点处理数据慢、全量查询耗时较长和无事件匹配机制的抽样采集不准确的缺点。实验结果显示,本文方法对于包含异常信息的链路数据具有采集的精准性和高效性。下一步将进一步增加链路数据集的数量,基于大数据平台搭建微服务调用链路应用,并与当前其他利用大数据框架处理方法进行比较。
[1] NEWMAN S. 微服务设计[M]. 崔力强,张骏,译. 北京:人民邮电出版社, 2016:263-266.(NEWMAN S. Building Microservices[M]. CUI L Q, ZHANG J. Beijing: Posts and Telecom Press, 2016:263-266.)
[2] 辛园园,钮俊,谢志军,等. 微服务体系结构实现框架综述[J]. 计算机工程与应用, 2018, 54(19):10-17.(XIN Y Y, NIU J, XIE Z J, et al. Survey of implementation framework for microservices architecture[J]. Computer Engineering and Applications, 2018, 54(19): 10-17.)
[3] 李春阳,刘迪,崔蔚,等. 基于微服务架构的统一应用开发平台[J]. 计算机系统应用, 2017, 26(4):43-48.(LI C Y, LIU D, CUI W, et al. Unified application development platform based on micro‑service architecture[J]. Computer Systems and Applications, 2017, 26(4): 43-48.)
[4] 杨勇,李影,吴中海. 分布式追踪技术综述[J]. 软件学报, 2020, 31(7):2019-2039.(YANG Y, LI Y, WU Z H. Survey of state‑of‑the‑art distributed tracing technology[J]. Journal of Software, 2020, 31(7):2019-2039.)
[5] 陆龙龙. 分布式链路跟踪系统的设计与实现[D]. 南京:南京大学, 2018:21-30.(LU L L. The design and implementation of distributed tracing system[D]. Nanjing: Nanjing University, 2018: 21-30.)
[6] 刘家严. 定频采样变窗口周期信号幅值计算[J]. 计算机产品与流通, 2020(4):282-282.(LIU J Y. Amplitude calculation of fixed frequency sampling variable window periodic signal[J]. Computer Products and Circulation, 2020(4):282-282.)
[7] CAMALAN M. Simulating probabilistic sampling on particle populations to assess the threshold sample sizes for particle size distributions[J]. Particulate Science and Technology, 2021, 39(4): 511-520.
[8] KONDAPALLI R. Packet sampling using rate‑limiting mechanisms: 20070258370[P]. 2007-11-08.
[9] SIGELMAN B H, BARROSO L A, BURROWS M, et al. Dapper, a large‑scale distributed systems tracing infrastructure: Google Technical Report dapper‑2010‑1[R/OL]. [2021-09-21].http://people.csail.mit.edu/matei/courses/2015/6.S897/readings/dapper.pdf.
[10] 任天. CAT监控系统服务端的设计与实现[D]. 南京:南京大学, 2018: 42-51.(REN T. The design and implementation of CAT monitoring server‑side system[D]. Nanjing: Nanjing University, 2018: 42-51.)
[11] 杨帆. 基于zipkin协议的分布式调用跟踪方案[J]. 福建电脑, 2018, 34(1):124-124, 152.(YANG F. Distributed revocation tracking scheme based on zipkin protocol[J]. Fujian Computer, 2018, 34(1):124-124, 152.)
[12] 吴晟. Apache SkyWalking,开源监控生态[J]. 软件和集成电路, 2021(6):62-62.(WU S. Apache Skywalking, open source monitoring ecology[J]. Software and Integrated Circuit, 2021(6):62-62.)
[13] 李敏,熊灿,肖扬. 基于事件驱动的动态分簇网络的协作传输方法[J]. 电子与信息学报, 2021, 43(8):2232-2239.(LI M, XIONG C, XIAO Y. An event‑driven cooperative transmission scheme for dynamic clustering networks[J]. Journal of Electronics and Information Technology, 2021, 43(8): 2232-2239.)
[14] WANG J, LIU H P, ZHANG Z. Constrained route planning based on the regular expression[C]// Processing of the 2017 International Conference on Collaborative Computing: Networking, Applications and Worksharing, LNICST 252. Cham: Springer, 2018:98-108.
[15] OpenTracing. Specification[EB/OL].[2021-05-11].https://github.com/opentracing/specification/blob/master/specification.md.
[16] 卢晨曦. 面向大数据流的分布式B+树索引构建[D]. 杭州:浙江工业大学, 2019: 34-42.(LU C X. A distributed B+ tree for big data stream[D]. Hangzhou: Zhejiang University of Technology, 2019: 34-42.)
[17] 李双,古良铃,贺媛媛. 从编程和性能看B树和B+树[J]. 电脑编程技巧与维护, 2020(10):47-49.(LI S, GU L L, HE Y Y. Seeing B tree and B+ tree from programming and performance perspectives[J]. Computer Programming Skills and Maintenance, 2020(10): 47-49.)
[18] HU J K, CHEN Y M, LU Y Y, et al. Understanding and analysis of B+ trees on NVM towards consistency and efficiency[J]. CCF Transactions on High Performance Computing, 2020, 2(1):36-49.
[19] 王洪润. 微服务架构中服务监控系统的设计与实现[D]. 北京:北京邮电大学, 2020: 56-67.(WANG H R. Design and implementation of service monitoring system in microservice architecture[D]. Beijing: Beijing University of Posts and Telecommunications, 2020: 56-67.)
[20] 赵来. 面向微服务的运维监控系统的设计与实现[D]. 西安:西安电子科技大学, 2020: 42-53.(ZHAO L. Design and implementation of a microservice‑oriented operation and maintenance monitoring system[D]. Xian: Xidian University, 2020: 42-53.)
[21] 于晓虹. 微服务架构在分布式系统的设计和应用[J].电子技术与软件工程,2021(6):28-29.(YU X H. Design and application of microservice architecture in distributed systems[J]. Electronic Technology and Software Engineering, 2021(6): 28-29.)
Event‑driven dynamic collection method for microservice invocation link data
LI Peng1,2*, ZHAO Zhuofeng1,2, LI Han1,2
(1,,100144,;2(),100144,)
Microservice invocation link data is a type of important data generated in the daily operation of the microservice application system, which records a series of service invocation information corresponding to a user request in the microservice application in the form of link. Microservice invocation link data are generated at different microservice deployment nodes due to the distribution characteristic of the system, and the current collection methods for these distributed data include full collection and sampling collection. Full collection may bring large data transmission and data storage costs, while sampling collection may miss critical invocation data. Therefore, an event‑driven and pipeline sampling based dynamic collection method for microservice invocation link data was proposed, and a microservice invocation link system that supports dynamic collection of invocation link data was designed and implemented based on the open‑source software Zipkin. Firstly, the pipeline sampling was performed on the link data of different nodes that met the predefined event features, that is the same link data of all nodes were collected by the data collection server only when the event defined data was generated by a node; meanwhile, to address the problem of inconsistent data generation rates of different nodes, multi‑threaded streaming data processing technology based on time window and data synchronization technology were used to realize the data collection and transmission of different nodes. Finally, considering the problem that the link data of each node arrives at the server in different sequential order, the synchronization and summary of the full link data were realized through the timing alignment method. Experimental results on the public microservice lrevocation ink dataset prove that compared to the full collection and sampling collection methods, the proposed method has higher accuracy and more efficient collection on link data containing specific events such as anomalies and slow responces.
microservice; invocation link data; dynamic sampling; event matching; caching mechanism; service link tracing
This work is partially supported by National Key Research and Development Program of China (2019YFB1405100), Beijing Natural Science Foundation (4202021).
LI Peng, born in 1996, M. S. His research interests include microservices, big data.
ZHAO Zhuofeng, born in 1977, Ph. D., research fellow. His research interests include cloud computing, massive perceptual data processing, service computing, smart city.
LI Han, born in 1981, Ph. D., associate research fellow. Her research interests include big data analysis, data quality management.
1001-9081(2022)11-3493-07
10.11772/j.issn.1001-9081.2021101735
2021⁃10⁃09;
2021⁃11⁃08;
2021⁃11⁃17。
国家重点研发计划项目(2019YFB1405100);北京市自然科学基金资助项目(4202021)。
TP311.5
A
李鹏(1996—),男,山东济南人,硕士,CCF会员,主要研究方向:微服务、大数据;赵卓峰(1977—),男,山东济南人,研究员,博士,CCF会员,主要研究方向:云计算、海量感知数据处理、服务计算、智慧城市;李寒(1981—),女,辽宁沈阳人,副研究员,博士,CCF会员,主要研究方向:大数据分析、数据质量管理。
