联合立场的过程跟踪式多任务谣言验证模型
2022-11-30张斌王莉杨延杰
张斌,王莉,杨延杰
联合立场的过程跟踪式多任务谣言验证模型
张斌,王莉*,杨延杰
(太原理工大学 大数据学院,山西 晋中 030600)(∗通信作者电子邮箱wangli@tyut.edu.cn)
当前,社交媒体平台成为人们发布和获取信息的主要途径,但简便的信息发布也导致了谣言更容易迅速传播,因此验证信息是否为谣言并阻止谣言传播,已经成为一个亟待解决的问题。以往的研究表明,人们对信息的立场可以协助判断信息是否为谣言。在此基础上,针对谣言泛滥的问题,提出了一个联合立场的过程跟踪式多任务谣言验证模型(JSP‑MRVM)。首先,分别使用拓扑图、特征图和公共图卷积网络(GCN)对信息的三种传播过程进行表征;然后,利用注意机制获取信息的立场特征,并融合立场特征与推文特征;最后,设计多任务目标函数使立场分类任务更好地协助验证谣言。实验结果表明,所提模型在RumorEval数据集上的准确度和Macro‑F1较基线模型RV‑ML分别提升了10.7个百分点和11.2个百分点,可以更有效地检验谣言,减少谣言的泛滥。
谣言验证;立场;多任务;图卷积网络;传播过程;目标函数
0 引言
随着在线社交媒体的迅速发展,Twitter、Facebook、微博等社交平台已成为信息传播、交流的主要平台。由Dixon[1]和Thomala[2]的统计数据可以看出,绝大部分用户主要通过这些平台获取信息。用户通过在社交媒体上阅读推文来获取新闻,同时还可以分享自己对各种事件的立场。由于用户在社交媒体上发布信息的门槛较低,所以可以很自由地发布信息,这就为谣言的发布和传播创造了有利条件。根据Zubiaga等[3]对谣言的定义,“谣言是一个在发布时尚未确定真实性的且需要验证的流通信息”。例如,有人在用手机拍摄闪电时看到闪电劈向自己,之后将视频在社交账号上发布,有网友以此发布“雷雨天手机会引雷”的话题一度登上热搜。随着话题热度的上升,为防止人们误信此话题,有关专家对打雷和避雷的原理进行了解释,这个话题信息最终被认定为谣言。又比如“不吃药,吃大蒜就能治幽门螺旋杆菌”这种“土方法”在人们生活中被传播,误导人们在得病的第一时间选择吃大蒜,导致病情恶化、感染人数骤增等情况。但是随着多位医学专家在主流社交平台进行医学常识讲解,这个信息最终被人们当作谣言。
这些未经验证的信息的扩散,不仅阻碍了社交平台的健康发展,而且如果不及时发现,这些耸人听闻的谣言可能会在紧急事件中引发社会恐慌;所以信息在社交平台上的可信度变得至关重要,Twitter、Facebook、微博等社交平台都急切寻找有效的解决方案来识别谣言。
谣言的识别过程可以分为四个步骤[3]。1)谣言初期筛查阶段:这个过程将那些可以直接确定客观存在或真实的信息过滤出来,初步将信息分类为真实信息和不确定信息;2)信息跟踪阶段:这一过程将收集上一步被判断为不确定信息的相关推文信息;3)立场分类阶段:基于所收集的相关推文信息,这一过程将得出网络用户对事件所持有的态度(即立场);4)谣言验证阶段:这一过程是为了确定在跟踪不确定信息一段时间后(即收集了一段时间的相关推文和评论信息),此信息是否可以被证实为真实(T)、虚假(F)或未验证(U)[4]。其中,对立场的分类[5]如下:
1)支持(S):用户所发表的推文和评论信息中所持有的态度是支持其相关事件的立场,对其内容表示支持;
2)反对(D):对其内容表示不认同;
3)查询(Q):对其内容表示不确定,想要获取更多相关信息;
4)评论(C):对其内容不做评价,仅仅进行了无立场的信息表达。
图1展示了一个谣言的树状会话中源推文及其评论的立场。

图1 谣言的树状会话
已有的研究[6-8]表明,对于已发布的未经验证的信息,其源推文和相应的评论中的立场可以帮助识别谣言。比如,对于一个发布了不确定信息的推文,会有越来越多的评论对源推文进行否认、质疑等[9],并且直接给出相应的评论内容。因为人们在接收过各种各样的虚假信息后,对于信息的真实度有了比较高的判断力。Ma等[10]曾对100件谣言进行分析后得出,用户更倾向于对谣言推文信息进行否认或质疑的评论;而对于非谣言推文信息,则更多的是支持与肯定的评论。由此说明推文信息和其评论的立场可以为谣言验证提供指示性线索[11]。
相较于单独的立场分类和谣言验证任务,通过多任务学习(Multi‑Task Learning, MTL)模型将两个任务联合会更有效地降低拟合,通过增加训练集标签数,从而提高训练集模型精度。MTL通常用于相似或相关任务的并行学习,利用每个任务各自特征的独立参数和共同特征的共享参数来帮助其他任务更好地训练。近年来,MTL在自然语言处理(Natural Language Processing, NLP)任务中频频出现,基于MTL的模型在谣言验证任务[12]中也有相关应用和发展。受此启发,本文将谣言识别过程表示为多任务问题,其中谣言验证任务是主要任务,立场分类任务是辅助任务,利用辅助任务来提高谣言验证分类器的性能。
本文提出了一个联合立场的过程跟踪式多任务谣言验证模型(Joint Stance Process tracking Multi‑task Rumor Verification Model, JSP‑MRVM)。其中,利用立场分类任务协助谣言验证任务确定一个信息为真实(T)、虚假(F)或未经验证(U),试图在这个统一的体系结构中,通过相互反馈的特征和参数来加强谣言检测和立场分类准确度。其中使用了一个共享层、两个任务特定层和两个特征融合层来容纳不同目标的任务表示及其相应的参数。由于两个任务共同训练,数据特征得以增加,并且MTL可以降低每个单独任务的过拟合风险。得益于此,本文提出的JSP‑MRVM在谣言验证方面的准确度有了明显提高。
1 相关工作
1.1 立场分类
现阶段关于单独的立场分类任务方面的研究比较少,大多数研究都是将立场分类任务作为一个子任务进行研究。最初,关于信息的立场研究都是人工分析提取特征为主。Mendoza等[13]发表了一项开拓性的研究,在人工分析不同类型的谣言立场时,他们发现大多数与真实信息相关的推文都保持着支持的立场,而且在谣言信息相关推文中,有大约一半的推文保持着质疑或反对的立场。随着立场分类在不同的研究领域得到了越来越广泛的应用,研究者们探索了在包含评论的数据集中每个用户角度下的观点[14-15]。
而后,机器学习方法应用到了立场分类任务中,Zeng等[16]研究提取了多种特征,将立场分类由支持和反对变为多分类任务,形成细粒度的划分,包括支持、反对、查询和评论。考虑到信息传播过程的时序性,Zubiaga等[5]利用树结构会话构建了树状条件随机场(Conditional Random Field, CRF),其中每一个分支都是根据时序性构建的线性链CRF,以此学习树结构会话(如Twitter推文及其评论)中的立场,而不仅仅对推文进行分类。
随着深度神经网络在立场分类中的应用,Kochkina等[17]使用长短期记忆(Long Short‑Term Memory, LSTM)网络对推文立场分类。之后Chen等[18]使用卷积神经网络(Convolutional Neural Network, CNN)获取每条推文的表示,根据推文表示进行分类。但是,以往的研究都将源推文和评论拼成序列进行立场分类,虽然有研究者利用树状会话,但还是提取了树分支的序列特征,并没有充分利用树状会话传播的过程和图结构信息。
1.2 融合过程信息的谣言验证
在谣言验证的相关研究中,Zubiaga等[9]将不确定信息归类为真实(T)、虚假(F)和未经验证的(U)。刚开始,Zhao等[19]关注于推文传播过程中的质疑词分布(比如,“not”“true”“unconfirmed”或“really?”等),利用质疑和否认词在传播过程的分布来检测谣言。随着深度学习在各个领域的广泛应用,Ma等[20]提出了利用循环神经网络(Recurrent Neural Network, RNN)提取信息传播过程中不同时间点的推文表示,进而验证谣言。之后Ma等[21]又提出了利用传播结构和核函数来识别谣言,这是对传播的过程信息的进一步应用。随着研究的深入,立场作为特征也有了相关研究,Li等[22]利用立场特征和用户特征进行了多任务学习,同时进行立场分类任务和谣言验证任务。MTL在识别未验证信息的任务中也有了越来越多的研究与应用。
1.3 多任务学习
多任务学习(MTL)的概念由Caruana[23]提出,是为了通过使用其他相关任务来提高原任务的性能。大多数MTL或联合学习模型都可以看作是参数共享的模型,即在多个任务中共同训练模型,共享参数或特征。在NLP任务中,已经有大量关于MTL的研究与应用。最近,关于立场分类和谣言验证的MTL也受到了广泛关注,主要可以分为两类。
其一是将推文与评论进行拼接,以长文本为输入。Ma等[10]提出了联合模型MT‑ES(MultiTask‑learning‑ Enhanced Shared‑layer architecture),设计构造了基于RNN的深度神经网络模型进行立场分类和谣言验证任务。随后,Kochkina等[12]提出了利用RNN的变形体即LSTM网络作为共享层,提取原推文与评论的共享特征,再分别设计子任务层。而后Lv等[24]在Kochkina等[12]研究的基础上提出了多任务谣言验证模型RV‑ML(Rumor Verification scheme based on Multitask Learning model),谣言验证子任务用CNN对特征进行细化提取,从而提高谣言验证任务的准确度。Li等[22]借鉴了Kochkina等[12]和Ma等[20]的思想,在利用LSTM提取特征的同时加入了用户特征,从而利用用户和推文特征构造共享层。随着Transformer在各个领域的广泛应用,Fajcik等[25]用预训练的基于Transformer的双向编码表征提取文本表征,然后用softmax函数进行立场分类和谣言验证。Khandelwal[26]在此基础上,增加了统计特征、情感特征等特征后,再加入Transformer提取特征表征,以实现动态立场分类和谣言验证。以上提及的多任务模型中,只有共享层同时受到了多任务的反馈影响。本文则研究了如何使多任务模型间可以更多地互相影响反馈从而提升主任务性能,最终提出并设计了融合层。
其二是将推文与评论构造成树状会话作为输入。Kochkina等[17]从源推文的树状会话中提取构造了分支LSTM(Branch‑LSTM)模型,在Branch‑LSTM模型的每一个时间步中进行立场分类,最终进行谣言验证。其后,Kumar等[27]借鉴了Branch‑LSTM思想,以树状会话为基础构造LSTM模型,在每个分支进行立场分类,在树根进行谣言验证。
已有的研究关注到了传播结构对信息真假判断的作用,但主要基于其分支序列结构,并没有考虑信息传播过程中的图结构信息。由于评论只能回复一个推文,但是其立场可能同时受多个评论的影响,所以中心评论与周围评论的相互影响也有助于发现其立场,但很少有人研究这方面。另外,MTL模型在损失函数的设计上,都是将多个任务的损失进行加和,超参数对模型影响较大,不能使模型参数达到最优化。
2 本文模型JSP‑MRVM
本文提出了一个联合立场的过程跟踪式多任务谣言验证模型——JSP‑MRVM,模型框架如图2。主要包括:
输入层将语句转化为向量表征,s为源推文表征,c为评论表征。
共享层利用LSTM网络获取上下文源推文表征s和评论表征c。
子任务表征层中,经过立场分类任务表征层得到源推文表征gs和评论表征gc;经过谣言验证任务表征层得到会话表征cs。
融合层以子任务表征层和共享层为输入,得到源推文融合表征fs和评论融合表征fc。
最后立场分类为S(支持)、D(反对)、Q(查询)、C(评论);谣言验证为T(真)、F(假)和U(未验证)。
本文工作包括:
1)利用拓扑图、特征图和公共图的图卷积网络(Graph Convolutional Network, GCN)从三个角度的传播过程和图结构信息来丰富立场特征;
2)设计融合门(Fusion‑GATE, F‑GATE)融合共享层和子任务表征层输出,提升多任务模型间的相互作用,联合立场特征进行谣言验证;
3)设计可优化目标函数全面优化模型参数,并且本文模型在两个数据集上的准确度分别达到了70%和39.5%。
2.1 问题定义
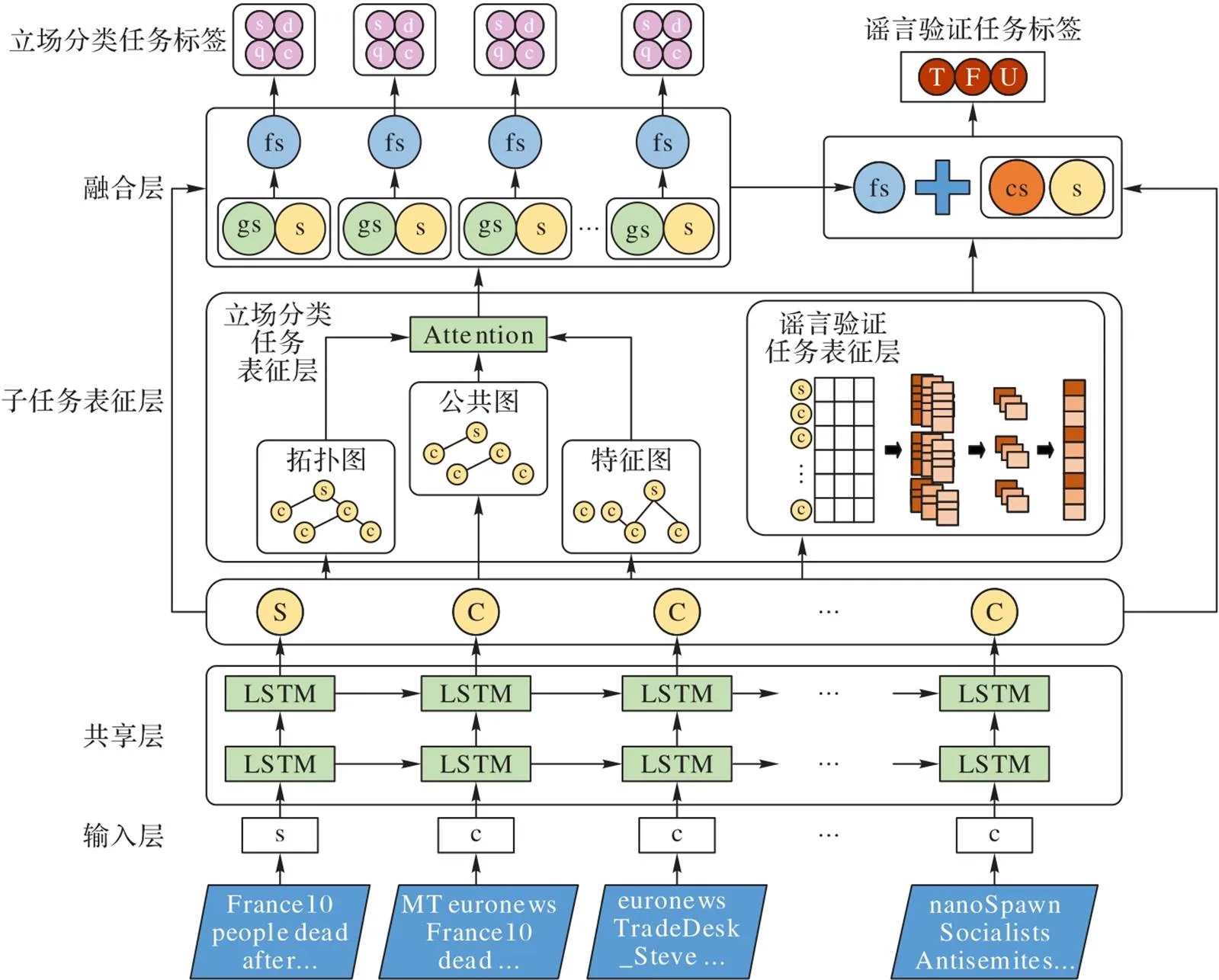
图2 JSP‑MRVM的模型框架
2.2 共享特征层
相较于单任务学习模型,MTL模型可以利用相关任务来学习更易于识别虚假信息的复杂特征。因为多个任务在共享特征层的基础上进行不同子任务,所以反向梯度传播时,两个不同的子任务表征层的反向传播可以让共享层更好地学习利于立场分类和谣言验证的特征。
受Lv等[24]的启发,本文选择带有LSTM单元的双向长短期记忆网络作为共享层。LSTM不仅可以对上下文信息进行整体建模,提取会话表征,还可以获取每个单元的表征。
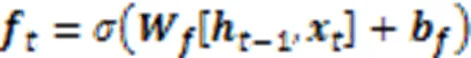


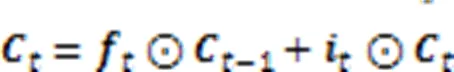



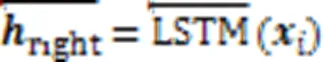
2.3 子任务表征层
在MTL模型中,每个任务都有其重视的推文特征,所以应对不同任务,用相应适合的模型才能更好地捕获相应任务的重要的特征。为了能充分提取传播结构的结构信息并跟踪其传播过程,本文提出在立场分类任务中用GCN模型,并且分别从拓扑图、特征图和公共图三种图结构提取立场特征。在谣言验证任务中,为了获取细粒度的局部语义特征,利用文本卷积神经网络TextCNN模型。
2.3.1立场分类任务表征层

特征图是由节点间相似性为边构成的,所以利用如下公式构造特征图:

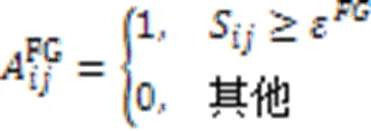
公共图是为了提取两个图的公共图结构,如式(11):


由于每种图都有其结构信息,为了融合三个图的结构信息,本文利用了注意力机制,使同一节点在不同结构中的重要信息得以融合。注意机制公式如下:


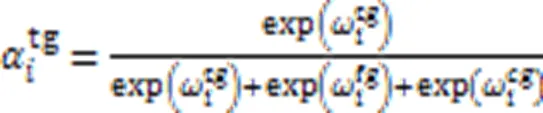
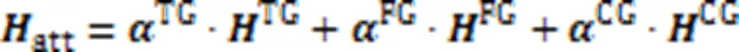
2.3.2谣言验证任务表征层
在模型中,谣言验证子任务表征层采用TextCNN。因为无论是源推文还是评论,其本质是字符构成的文本内容,而利用TextCNN可以有效捕捉到推文的局部特征,并提取推文的细粒度特征。
在卷积层中,使用不同窗口大小的滤波器来捕捉特征。与单窗口大小的滤波器相比,三种不同窗口大小的滤波器可以获得多个特征。单个滤波器的公式如下:
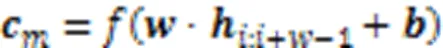


2.4 融合层
为了克服以往研究中只有共享层受多任务的影响反馈的不足,本文在子任务表征层后增加了融合层,使立场任务和谣言检测任务可以互相反馈,提升主任务性能。
经过子任务表征层的特征抽取,模型会丢失一些共享层的重要特征,同时也会丢失立场特征,所以本文设计F‑GATE来融合共享层和子任务表征层特征,获取任务相关的重要特征。对于立场分类表征层的融合如下所示:

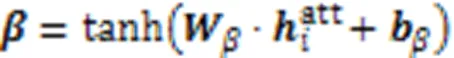


对于谣言验证任务表征层的融合与立场分类任务表征层的融合相似,但是输入不同。如下所示:

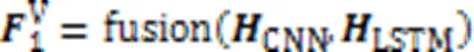

2.5 目标函数

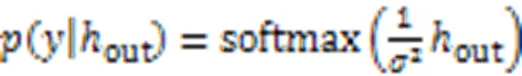

最终联合多任务的损失函数为:

3 实验与结果分析
3.1 数据集
在两个公开的数据集RumourEval[12]和PHEME[3]上测试本文模型,它们的详细统计和类分布如表1和表2。
RumourEval数据集中包含与谣言事件对应的twitter会话。在RumourEval数据集中,每个会话都被标记为真、假或未验证的,会话中的每个源推文和评论都被标记为支持、否认、查询或评论。该数据集分为训练集、验证集和测试集:训练集和验证集包括与8个谣言事件相关的297个会话;测试数据包括从8个谣言事件中提取的20个会话和从另外2个谣言事件中提取的8个会话。
PHEME数据集包含了9个事件的2 402个会话,同样包括了立场标签和谣言标签。为了与基线模型对比,本文每次将其中一个事件作为测试集,剩下的事件作为8∶2的训练集和验证集,进行多次交叉验证实验。

表 1 RumorEval数据集分布

表 2 PHEME数据集分布
3.2 实验设置
对数据集中的推文进行以下预处理:1)去除非字母字符;2)删除文本内容的网站链接;3)将所有单词转换为小写并标记文本。对推文文本进行预处理后,使用word2vec预训练的的谷歌新闻数据集获取推文中每个词的嵌入表征,并取其平均值,得到每条推文表示。

3.3 实验结果
为了验证本文模型JSP‑MRVM的性能,分别在上述两个数据集中进行对比实验。在对比实验中选择了同样基于立场分类和谣言验证任务的MTL的模型,包括:
BranchLSTM[3]:该模型是将树状会话分成会话分支,利用LSTM进行分类,然后将同一源推文分支结果进行投票。
MTL‑2[12]:该模型是基于MTL的谣言分类模型,模型中的共享层和谣言准确度验证都使用了LSTM单元。
MT‑ES[10]:该模型提出了增强型共享架构,共享层和任务层都利用GRU提取特征。
RV‑ML[24]:该模型在LSTM共享层的基础上利用CNN对准确度验证进行进一步特征的局部提取。
从表1和表2可以看出,两个数据集中的立场标签类别不平衡且不同事件的数量落差大,所以本文使用准确度和Macro‑F1来评估模型。本文模型有两种,UO和O后缀分别代表非优化和优化的目标函数的模型。
表3为在RumourEval和PHEME数据集上本文的模型和Baseline模型的结果对比。可以看出,在RumourEval数据集上,模型JSP‑MRVM(O)在准确度和Macro‑F1上分别比RV‑ML模型高了10.7个百分点和11.2个百分点;在PHEME数据集,JSP‑MRVM(O)模型在准确度和Macro‑F1都超过了基线模型。在两个数据集上,本文模型都超过了基线模型,在RumourEval数据集上尤为明显,说明了本文模型的优越性。同时如图3所示,本文模型在非优化模型上仍然大幅超越了基线模型的准确度(Accuracy, Acc)和Macro‑F1。
为了分析本文模型各个组成部分的重要性,在RumourEval数据集作消融实验,结果如表5。表5中模型JSP‑MRVM‑G、JSP‑MRVM‑C和JSP‑MRVM‑F分别表示去掉了GCN、CNN和F‑Gate。
首先,O和UO模型在同基础上的性能,前者都优于后者,说明优化的目标函数可以获取模型的最优参数。其次,模型中的GCN部分对整个模型的性能影响最大,说明从三个图结构中提取的立场特征和谣言的过程表征对谣言验证的辅助作用还是很大的。
从表3中可以明显看出,本文模型在PHEME数据集上提升效果不如RumorEval明显,本文做了如下分析:
在表2和图3中可以看到,PHEME数据集中各事件的真、假和未验证的比例严重失衡,在Ferguson和Putinmissing事件中真假标签数量远远低于未验证标签数量,而Ottawashooting事件中则是真标签数量远高于假和未验证标签数量。在Putinmissing、Prince‑toronto、Gurlitt和Ebola‑essien事件中甚至出现了没有某一类标签的情况,严重影响了用其中一个事件为测试集的交叉测试。从表4中五个主要事件的真、假和未验证的准确度结果来看,其中Ferguson事件中,分类为假出现了0%准确度,Ottawashooting、Charliehebdo和Sydneysiege事件中都出现了分类为真的准确度远高于其他两类准确度,这些结果印证了上述由数据集比例失衡而影响到预测某一类偏低的猜测。
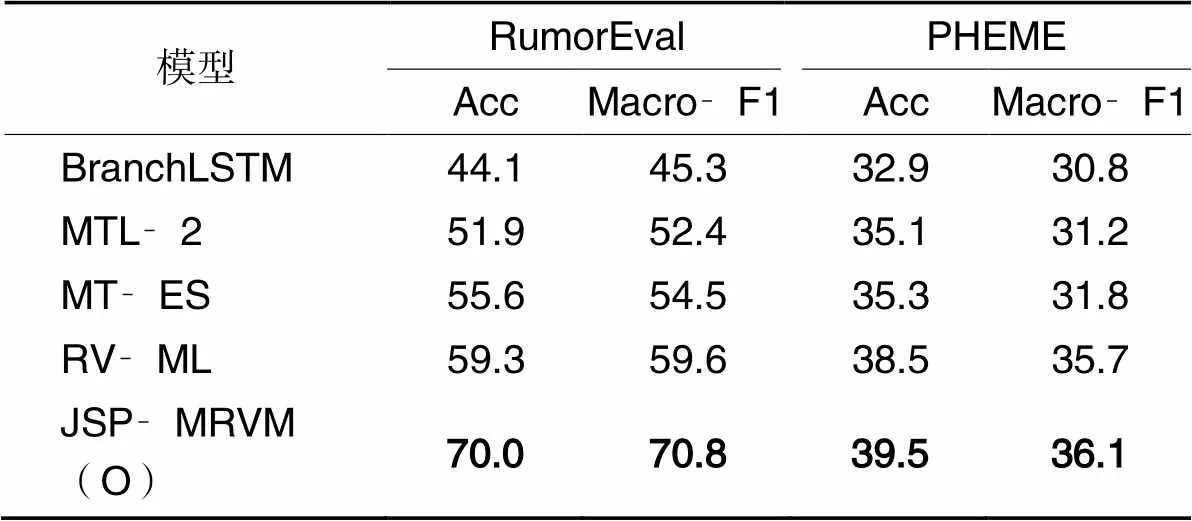
表 3 RumorEval和PHEME数据集上本文模型与基线模型的对比 单位: %

表 4 本文模型在RumorEval和PHEME数据集上的子类准确度 单位:%

表 5 RumorEval数据集上的消融实验结果 单位: %

图3 PHEME数据集中各事件真、假和未验证的事件数
本文模型在立场分类任务中提取了会话中的三种图结构信息,并在融合层中利用辅助任务丰富了准确度验证任务的特征表征,所以性能表现更优。而且,本文设计的优化的损失函数使得模型的参数可以尽可能地达到最优值。
4 结语
本文基于MTL框架提出了一个联合立场的过程跟踪式多任务谣言验证模型,该模型采用立场分类作为辅助任务,提高了谣言验证任务的性能。在RumourEval和PHEME数据集上的实验表明,本文所提出的JSP‑MRVM(O)获得了最好的谣言验证性能,从消融实验看出优化目标函数的模型总体性能优于非优化模型。在未来的工作中,将探索加入推文和用户的其他特征,从更多角度获取识别谣言的特征进行谣言检测。
[1] DIXON S. Twitter: number of monthly active users 2010 — 2019[EB/OL]. (2022-07-27)[2022-08-10].https://www.statista.com/statistics/282087/number‑of‑monthly‑active‑twitter‑users/.
[2] THOMALA L L. Number of Sina Weibo users in China 2017‑2021[EB/OL]. (2019-11-08)[2021-08-13].https://www.statista.com/statistics/941456/china‑number‑of‑sina‑weibo‑users/.
[3] ZUBIAGA A, AKER A, BONTCHEVA K, et al. Detection and resolution of rumours in social media: a survey[J]. ACM Computing Surveys, 2019, 51(2): No.32.
[4] CAPLOW T. Rumors in war[J]. Social Forces, 1947, 25(3): 298‑302.
[5] ZUBIAGA A, KOCHKINA E, LIAKATA M, et al. Stance classification in rumours as a sequential task exploiting the tree structure of social media conversations[C]// Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers. [S.l.]: The COLING 2016 Organizing Committee, 2016: 2438-2448.
[6] ENAYET O, EL‑BELTAGY S R. NileTMRG at SemEval‑2017 task 8: determining rumour and veracity support for rumours on Twitter[C]// Proceedings of the 11th International Workshop on Semantic Evaluation. Stroudsburg, PA: Association for Computational Linguistics, 2017: 470-474.
[7] LUKASIK M, SRIJITH P K, VU D, et al. Hawkes processes for continuous time sequence classification: an application to rumour stance classification in Twitter[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2016: 393-398.
[8] 魏武挥. 谣言的传播与辟谣[J]. 新闻记者, 2012(5): 28-31.(WEI W H. The spread and refutation of rumors[J]. Journalist Review, 2012(5): 28-31.)
[9] ZUBIAGA A, LIAKATA M, PROCTER R, et al. Analysing how people orient to and spread rumours in social media by looking at conversational threads[J]. PLoS ONE, 2016, 11(3): No.e0150989.
[10] MA J, GAO W, WONG K F. Detect rumor and stance jointly by neural multi‑task learning[C]// Proceedings of the 2018 Web Conference. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2018: 585-593.
[11] 李峤,刘宇. 基于机器学习的推特谣言立场分析研究[J]. 电子设计工程, 2019, 27(21): 36-39, 44.(LI Q, LIU Y. Research on Twitter rumor standpoint analysis based on machine learning[J]. Electronic Design Engineering, 2019, 27(21): 36-39, 44.)
[12] KOCHKINA E, LIAKATA M, ZUBIAGA A. All‑in‑one: multi‑ task learning for rumour verification[C]// Proceedings of the 27th International Conference on Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2018: 3402-3413.
[13] MENDOZA M, POBLETE B, CASTILLO C. Twitter under crisis: Can we trust what we RT?[C]// Proceedings of the 1st Workshop on Social Media Analytics. New York: ACM: 2010: 71-79.
[14] CHUANG J H, HSIEH S. Stance classification on PTT comments[C/OL]// Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation: Posters. [2021-08-11].https://aclanthology.org/Y15‑2004.pdf.
[15] RANADE S, SANGAL R, MAMIDI R. Stance classification in online debates by recognizing users’ intentions[C]// Proceedings of the 4th Annual Meeting of the Special Interest Group on Discourse and Dialogue. Stroudsburg, PA: Association for Computational Linguistics, 2013: 61-69.
[16] ZENG L, STARBIRD K, SPIRO E S. #Unconfirmed: classifying rumor stance in crisis‑related social media messages[C]// Proceedings of the 10th International AAAI Conference on Web and Social Media. Palo Alto, CA: AAAI Press, 2016: 747-750.
[17] KOCHKINA E, LIAKATA M, AUGENSTEIN I. Turing at SemEval‑2017 Task 8: sequential approach to rumour stance classification with branch‑LSTM[C]// Proceedings of the 11th International Workshop on Semantic Evaluation. Stroudsburg, PA: Association for Computational Linguistics, 2017: 475-480.
[18] CHEN Y C, LIU Z Y, KAO H Y. IKM at SemEval‑2017 Task 8: convolutional neural networks for stance detection and rumor verification[C]// Proceedings of the 11th International Workshop on Semantic Evaluation. Stroudsburg, PA: Association for Computational Linguistics, 2017: 465-469.
[19] ZHAO Z, RESNICK P, MEI Q Z. Enquiring minds: early detection of rumors in social media from enquiry posts[C]// Proceedings of the 24th International Conference on World Wide Web. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2015: 1395-1405.
[20] MA J, GAO W, MITRA P, et al. Detecting rumors from microblogs with recurrent neural networks[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2016: 3818-3824.
[21] MA J, GAO W, WONG K F. Detect rumors in microblog posts using propagation structure via kernel learning[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 708-717.
[22] LI Q Z, ZHANG Q, SI L. Rumor detection by exploiting user credibility information, attention and multi‑task learning[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019: 1173-1179.
[23] CARUANA R. Multitask learning[J]. Machine Learning, 1997, 28(1): 41-75.
[24] LV Q, WANG Y F, ZHANG B, et al. RV‑ML: an effective rumor verification scheme based on multi‑task learning model[J]. IEEE Communications Letters, 2020, 24(11): 2527-2531.
[25] FAJCIK M, SMRZ P, BURGET L. BUT‑FIT at SemEval‑2019 Task 7: determining the rumour stance with pre‑trained deep bidirectional transformers[C]// Proceedings of the 13th International Workshop on Semantic Evaluation. Stroudsburg, PA: Association for Computational Linguistics, 2019: 1097-1104.
[26] KHANDELWAL A. Fine‑tune Longformer for jointly predicting rumor stance and veracity[C] // Proceedings of the 8th ACM IKDD CODS and 26th COMAD. New York: ACM, 2021: 10-19.
[27] KUMAR S, CARLEY K M. Tree LSTMs with convolution units to predict stance and rumor veracity in social media conversations[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019: 5047-5058.
[28] CIPOLLA R, GAL Y, KENDALL A. Multi‑task learning using uncertainty to weigh losses for scene geometry and semantics[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7482-7491.
[29] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013-09-07)[2021-08-13].https://arxiv.org/pdf/1301.3781.pdf.
Process tracking multi‑task rumor verification model combined with stance
ZHANG Bin, WANG Li*, YANG Yanjie
(,,030600,)
At present, social media platforms have become the main ways for people to publish and obtain information, but the convenience of information publish may lead to the rapid spread of rumors, so verifying whether information is a rumor and stoping the spread of rumors has become an urgent problem to be solved. Previous studies have shown that peoples stance on information can help determining whether the information is a rumor or not. Aiming at the problem of rumor spread, a Joint Stance Process Multi‑Task Rumor Verification Model (JSP‑MRVM) was proposed on the basis of the above result. Firstly, three propagation processes of information were represented by using topology map, feature map and common Graph Convolutional Network (GCN) respectively. Then, the attention mechanism was used to obtain the stance features of the information and fuse the stance features with the tweet features. Finally, a multi‑task objective function was designed to make the stance classification task better assist in verifying rumors. Experimental results prove that the accuracy and Macro‑F1 of the proposed model on RumorEval dataset are improved by 10.7 percentage points and 11.2 percentage points respectively compared to those of the baseline model RV‑ML (Rumor Verification scheme based on Multitask Learning model), verifying that the proposed model is effective and can reduce the spread of rumors.
rumor verification; stance; multi‑task; Graph Convolutional Network (GCN); propagation process; objective function
This work is partially supported by National Natural Science Foundation of China (61872260).
ZHANG Bin, born in 1995, M. S. candidate. His research interests include natural language processing, rumor detection.
WANG Li, born in 1971, Ph. D., professor. Her research interests include data mining, artificial intelligence, machine learning..
YANG Yanjie, born in 1995, M. S. candidate. His research interests include natural language processing, data mining.
1001-9081(2022)11-3371-08
10.11772/j.issn.1001-9081.2021122148
2021⁃12⁃21;
2022⁃02⁃28;
2022⁃03⁃04。
国家自然科学基金资助项目(61872260)。
TP391.1
A
张斌(1995—),男,山西永济人,硕士研究生,CCF会员,主要研究方向:自然语言处理、谣言检测;王莉(1971—),女,山西太原人,教授,博士,CCF高级会员,主要研究方向:数据挖掘、人工智能、机器学习;杨延杰(1995—),男,山西原平人,硕士研究生,主要研究方向:自然语言处理、数据挖掘。
