基于多语BERT的无监督攻击性言论检测
2022-11-30师夏阳张风远袁嘉琪黄敏
师夏阳,张风远,袁嘉琪,黄敏*
基于多语BERT的无监督攻击性言论检测
师夏阳1,张风远1,袁嘉琪2,黄敏1*
(1.郑州轻工业大学 软件学院,郑州 450001; 2.郑州轻工业大学 数学与信息科学学院,郑州 450001)(∗通信作者电子邮箱huangmin@zzuli.edu.cn)
攻击性言论会对社会安定造成严重不良影响,但目前攻击性言论自动检测主要集中在少数几种高资源语言,对低资源语言缺少足够的攻击性言论标注语料导致检测困难,为此,提出一种跨语言无监督攻击性迁移检测方法。首先,使用多语BERT(mBERT)模型在高资源英语数据集上进行对攻击性特征的学习,得到一个原模型;然后,通过分析英语与丹麦语、阿拉伯语、土耳其语、希腊语的语言相似程度,将原模型迁移到这四种低资源语言上,实现对低资源语言的攻击性言论自动检测。实验结果显示,与BERT、线性回归(LR)、支持向量机(SVM)、多层感知机(MLP)这四种方法相比,所提方法在丹麦语、阿拉伯语、土耳其语、希腊语这四种语言上的攻击性言论检测的准确率和F1值均提高了近2个百分点,接近目前的有监督检测,可见采用跨语言模型迁移学习和迁移检测相结合的方法能够实现对低资源语言的无监督攻击性检测。
跨语言模型;攻击性言论检测;BERT;无监督方法;迁移学习
0 引言
网络社交媒体中时常存在着大量的攻击性言论,如网络欺凌、网络攻击和仇恨言论等[1-2]。社交媒体中的攻击性言论会严重影响人们的正常交流,更有甚者可能煽动群众情绪,对社会稳定造成不良的影响。因此,检测和过滤网络中的攻击性言论显得格外重要,成为自然语言处理领域的一个研究热点[3]。
目前攻击性言论检测的研究主要集中在高资源语言(如英语)中,这是因为高资源的数据集资源、单语词典和预训练语言模型成果丰富[4]。然而,在社交媒体平台上,往往存在着多种语言的攻击性言论(例如:不同国家的语言、不同民族的语言和不同地区的方言),而对语言进行攻击性言论检测研究大多基于有限的数据集上,因此低资源语言攻击性言论检测的研究面临巨大的挑战[5-6]。
攻击性言论检测是分类任务中的一项具体应用,往往将分类任务分为上游的语言建模和下游的分类特征学习两阶段。神经网络语言模型(Neural Network Language Model, NNLM)通过构建神经网络的方式来探索和建模自然语言内在的依赖关系,能够用向量表征一个单词或者句子,优良表征能够提高下游模型泛化能力。检测方法泛化能力往往建立在庞大的数据资源基础上,因此,当建模语言对象为低资源语言时,由于可用资源很少,无法学习到语言对象中内在的依赖关系,也就无法对低资源语言中的文本语义特征进行有效的语义编码学习。研究表明可以通过跨语言词向量结合迁移学习(Transfer Learning, TL)实现对低资源语言上的文本语义编码[7]。此外,下游阶段模型的泛化能力决定分类性能的优劣,而可用数据资源的多少又决定了下游阶段的泛化能力;同时,也造成了下游分类模型无法依靠这些低资源数据得到一个有效的攻击性言论检测模型。
低资源的攻击性言论检测面临两大挑战:一是由于可用资源少,无法单独对低资源语言中的文本语义进行有效编码;二是无法对低资源语言中的攻击性特征进行有效训练。基于上述分析,本文采用迁移学习架构,在BERT(Bidirectional Encoder Representation from Transformers)模型的基础上,多语言预训练语言模型——多语BERT(multilingual BERT, mBERT)进行在低资源语言中的迁移学习,使模型具备对低资源语言的文本语义编码能力[8]。此外,通过探索不同语言之间的语言相似程度,再次对低资源语言进行迁移,实现对低资源语言的攻击性言论的跨语言检测,使模型具有一定的对低资源语言的攻击性言论检测的泛化能力。
本文的主要工作包括:
1)提出了一种融合mBERT的跨语言攻击性言论迁移检测方法,通过探索不同语言之间的语言相似度,将在高资源语言上训练的模型迁移到其他低资源语言中来检测该低资源语言中的攻击性;
2)使用BERT模型作为语言模型,通过对BERT微调,保证了对自然语言的语义编码能力;
3)利用mBERT进行不同语言的迁移学习,保留了mBERT模型对不同语言的语义编码特征,以便于探索不同语言之间的语言相似程度。
1 相关工作
进行攻击性言论识别的早期工作依赖于手动提取不同类型的特征和基于知识的功能以及多模式信息[9-10],如:Saroj等[11]使用四种机器学习分类器:多项式朴素贝叶斯(Multinomial Naive‑Bayes, MNB)、随机梯度下降(Stochastic Gradient Descent,SGD)、线性支持向量机(Linear Support Vector Machine, LSVM)和线性回归(Linear Regression,LR)来识别社交媒体中印地语中的攻击性言论;Pathak等[12]通过提取文本语言中的‑gram特征,使用机器学习中的分类和回归方法来学习这些攻击性言论的特征。但是这种基于特征的方法在文本表示中的能力相对较弱,往往需要构建高维的特征对复杂文本进行特征学习,在进行相关计算时耗费大量资源,且特征的冗余会影响分类的实际效果[13]。受Zampieri 等[14]的启发,Howard等[15]借助BERT,利用ULMFiT(Universal Language Model Fine‑tuning for Text classification, ULMFiT)方法经过预训练的语言模型成功实现了迁移学习在攻击性言论检测的应用,由于性能较好,该类方法成为用于解决攻击性言论识别任务的主流。在2019年OffensEval竞赛[16]中,参加任务A的前10个团队中,有7个使用了BERT,仅在参数设置和预处理步骤有所不同[17-18]。目前利用跨语言预训练模型进行攻击性言论检测大多数都以预训练跨语言模型基础[19-21]。这类方法最大的优点是:通过这种无监督的跨语言预训练模型,能够实现低资源语言的攻击性言论检测。Ayo等[22]提出基于支持向量机(Support Vector Machine, SVM)和BERT的方法构建跨语言攻击性言论和厌女性(Misogynist)言论检测模型。Kapil等[23]在跨语言预训练模型的基础上加入了迁移学习,将丰富资源的攻击性言论检测任务知识迁移到低资源语言上,可以有效提高低资源语言的攻击性言论检测准确率,但上述方法的检测性能并不令人满意。
2 融合mBERT与TL的攻击性言论检测方法
本文提出的方法包括两个方面:第一是单语攻击性言论检测学习;第二是跨语言迁移检测。对于给定的单语攻击性言论样本集,首先,使用mBERT模型在单语攻击性言论样本集中进行迁移学习,得到单语攻击性言论检测器。对于给定的低资源语种文本,将单语攻击性言论检测器迁移到低资源语言,检测低资源语言文本中的攻击性言论。融合mBERT与TL的攻击性言论检测方法结构如图1所示。
2.1 单语攻击性言论检测学习
由于给定的单语攻击性言论样本集较小,不足以支撑构建一个相对完整的模型表达这些言论中的文本语义信息,但跨语言迁移学习方法能够利用其他语言提供的更大的可用数据集。通过迁移学习将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型,从而提高模型的学习效率,避免了多数网络从零学习的缺点。
mBERT为Google发布的基于BERT模型训练的多语言预训练模型,由12个堆叠的Transformer组成,其中一个隐藏层大小为768,还包括12个自注意力头。mBERT模型经过预先训练,将104种不同语言的单语维基百科数据(包括英语、印地语、土耳其语、马拉雅拉姆语等)与一个共享的词汇表(该词汇表包括12万个单词)进行连接,使得所有字符编码共享一个嵌入空间和编码器,方便应用于不同的语言任务中[24]。Kudugunta等[25]和Kondratyuk等[26]验证了在下游任务上(如词性标注、命名实体识别等)可以实现从跨语言预训练模型中提取相关特征,获取在特定任务上的基于语言知识的信息。Kumar等[27]在德语和印地语任务中,使用了预训练模型mBERT,通过对BERT模型微调在德语和印地语的识别仇恨和冒犯性任务上取得了显著的效果。Libovický等[28]证明了基于上下文的mBERT可以捕捉语言之间的相似性,并将语言按语种进行聚类,且跨语言微调后不会破坏这个属性。换句话说,mBERT可以将语言信息的一部分按照嵌入空间中的位置进行编码,将每种语言的编码集中起来,可以实现一定程度的跨语言性。
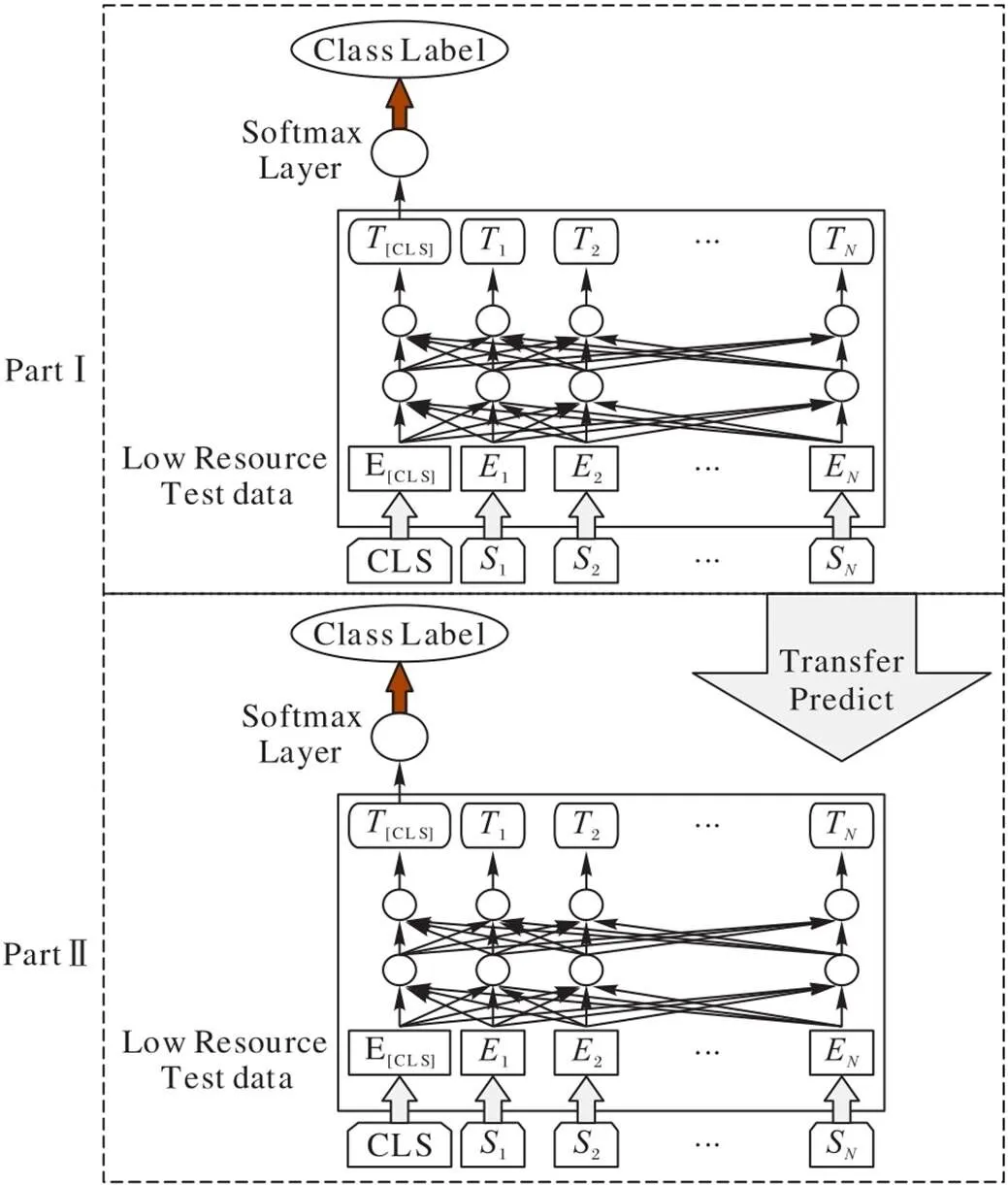
图 1 本文方法的结构
受到前面工作的启发,本文利用mBERT模型的跨语言性使得检测器可以捕获不同语言的文本特征,通过迁移学习将mBERT学到的有关各种语言的知识信息分享给新模型,在mBERT模型参数的基础上进行检测器模型的训练,从而提高模型的学习效率。本文方法使用BERT模型作为构建攻击性言论检测模型的基础结构,将mBERT的模型参数作为上述攻击性言论检测模型的初始参数,在此基础上,通过对BERT模型进行微调,完成攻击性言论检测器的训练。
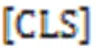
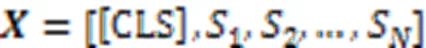
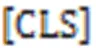

最后,使用交叉熵函数作为该任务的损失函数。该损失函数如式(3)所示:
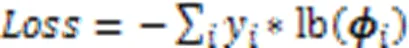
通过使用迁移学习,将mBERT跨语言预训练模型的权重参数迁移到单语攻击性言论检测模型中作为单语攻击性言论检测模型的初始参数,在这基础上进行攻击性言论中的攻击性特征的学习,最后得到一个单语攻击性言论检测模型。
2.2 跨语言检测
2.1节中得到的单语攻击性言论检测模型不仅可以解释高资源攻击性言论中的攻击性特征,还继承了迁移到mBERT预训练模型对多种语言的语义编码能力。这种能力使单语攻击性言论检测模型可以对未参与攻击性特征学习的语言直接进行检测。本文将使用训练好的单语攻击性言论检测模型对未参与攻击性特征学习的语言进行检测的方法称为跨语言检测。
为观察语言之间的关系,从每种语言中随机抽取了1 000个样本,并使用tSNE(t‑distributed Stochastic Neighbor Embedding)可视化了它们的句子嵌入(见图2)[29]。从可视化中观察到,这些例子基于它们的语言形成了一个粗略的聚类,但是英语和丹麦语的集群彼此靠近。这进一步说明了利用嵌入空间的这种接近性来提高对低资源语言攻击性文本检测的可能性。
需要特别指出的是,本文方法并未使用上述单语攻击性言论检测模型在低资源数据上进行再迁移学习,因此该方法可以称无监督的跨语言检测。
对于某些语种(如丹麦语、阿拉伯语和印地语等),由于这些语种的攻击性言论样本资源极少,在对现有资源进行跨语言迁移学习时,这些样本量不足以训练一个完整的针对该语言的攻击性言论检测器。通过观察表1,发现这些语言之间或多或少都有些相似之处,如:丹麦语和英语之间,在实际生活中,丹麦语中也包含大部分的英语;又发现如英语、土耳其语这些语言,构成文本的字符较为相似;而印地语、阿拉伯语和希腊语这些语言的字符之间差异较大,这些差异也决定了这些语言间的相似性不高。因此,提出一种通过探索不同语言之间的语言相似度,选取合适的单语攻击性言论检测器,用来检测低资源语种文本中的攻击性言论。
为了定量估计两种语言的语义相似性,本文使用了Patra等[30]提出的GH(Gromov‑Hausdroff)距离度量两个单词之间嵌入空间距离的方法。与文献[30]中不同语言的单词所映射到的嵌入空间不同的情况相反,通过跨语言预训练模型mBERT编码的嵌入编码都映射在同一空间内,且通过编码可视化(编码可视化如图2所示)可以看出不同语言的编码聚集在不同区域。因此,本文只需计算两种语言嵌入编码在不同区域的等距距离,以此来定量两种语言的语义相似程度。
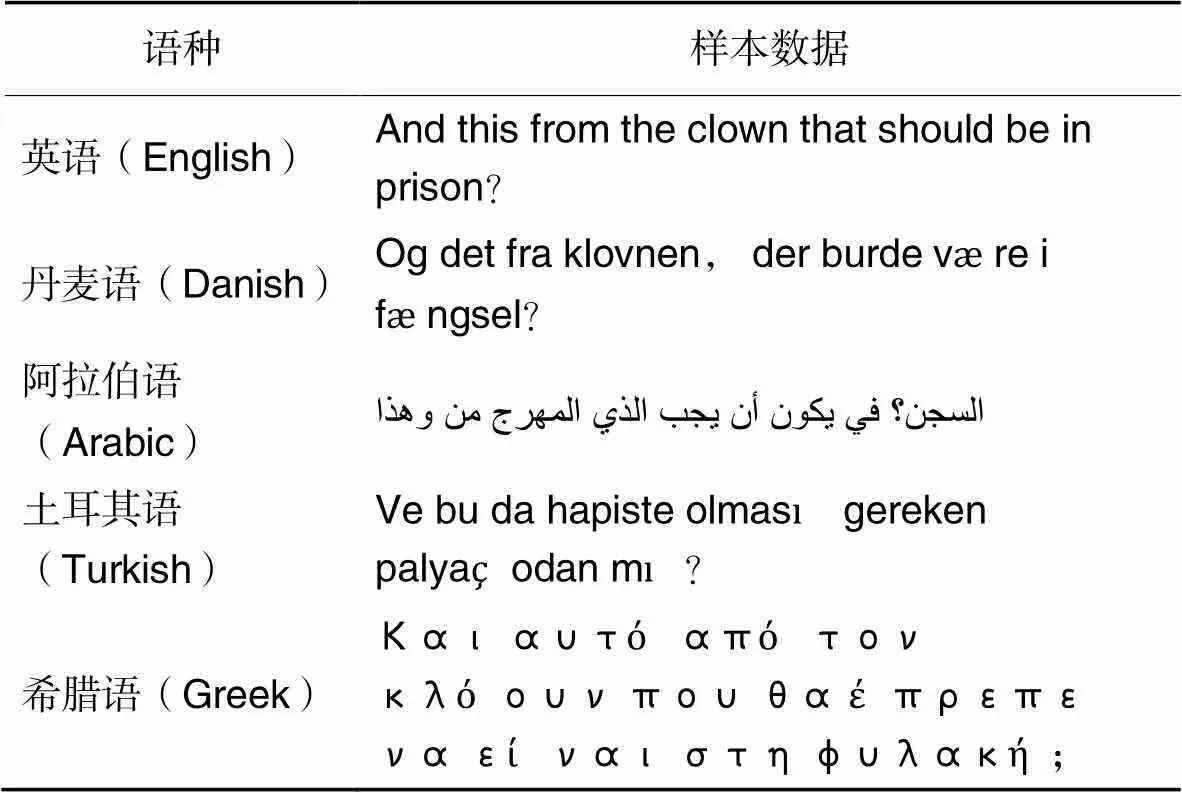
表1 各语种的样本数据
具体来说,GH距离定义如式(4)所示:
3 实验设置
3.1 数据设置
为了验证本文方法的性能,使用了如表2所示的公开可用的攻击性言论检测数据集。对于丰富的资源语言,本文使用2019年OffensEval共享任务6中发布的英文标记数据集(EN‑OLID)[31],OLID(EN‑OLID)是最流行的英语语言数据集之一。对于其他资源匮乏的语言,选择使用在2020年OffensEval共享任务12中发布的丹麦语(Danish)、阿拉伯语(Arabic)、土耳其语(Turkish)和希腊语(Greek)数据集。其中,OLID数据集包括三个子任务。子任务A:检测语言文本具有攻击性或不具有攻击性,以及两者样本总和;子任B:将攻击语言文本的攻击类型分类为有针对性的侮辱(TIN)、有针对性的威胁(TTH)或无针对性的(UNT);子任务C:将攻击目标确定为个人(IND)、人群(GRP)、组织或实体(ORG)及其他(OTH)。而阿拉伯语、丹麦语、希腊语和土耳其语只包含子任务A。本文实验只针对上述所有任务A数据进行探讨。此外,实验中设置训练集样本量和测试集样本量的比例为9∶1。
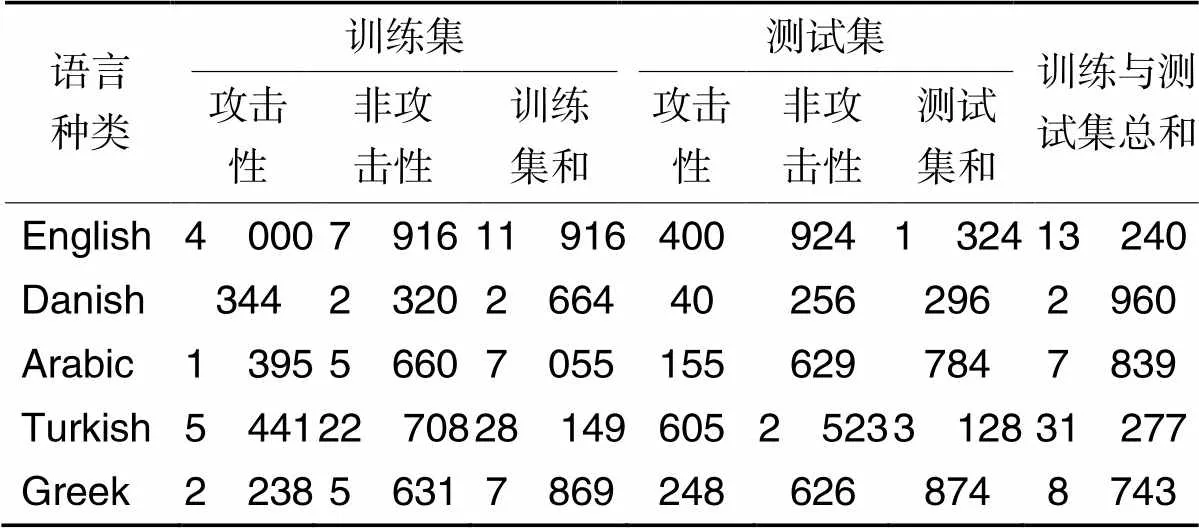
表2 样本数据分布
3.2 参数设置
词向量维度:设置本方法中的模型词向量维度为768维。
词表:设置mBERT预训练模型对应的词表作为文本实验中的共享词表,其中,该词表包括104种语言,共有12万词汇。
跨语言迁移学习:经过对样本的数据分析,发现大部分数据长度在120个词以内,因此设置句子最大长度为120。设置Softmax层的隐藏层单元为标签类别个数2。
模型训练:设置训练batch为64,epoch为10。
优化器设置:设置优化器为Adam。
优化参数设置:设置隐藏层dropout参数为0.01,固定学习率为0.000 02。
4 实验及结果分析
4.1 度量标准
度量标准主要包括模型预测的准确率(Accuracy)、精确率(Precision)、召回率(Recall)、宏平均macro F1值(后文统称F1值)。
4.2 对比实验分析
首先实验验证所提方法对于低资源语言攻击性言论检测的有效性。先抽取英语样本集做跨语言迁移学习,接着将训练好的攻击性言论检测器迁移到其他语言样本中,用来检测文本中的攻击性。同时设置几个单语模型作为对比,单语模型设置如下:
BERT:直接迁移mBERT预训练模型权重参数到低资源语言上进行攻击性特征的学习。
LR:使用词频‒逆向文档频率(Term Frequency‑Inverse Document Frequency,TF‑IDF)提取语言文本特征信息,接着使用Logistic Regression算法构建攻击性言论分类器。
SVM:使用TF‑IDF提取语言文本中的特征信息,使用SVM来学习特征信息中的文本特征。
MLP:使用多层感知机(Multi‑Layer Perceptron, MLP)来构建攻击性文本分类器。
实验结果如表3所示。表3显示,与所设置的4种方法相比,本文方法不论是准确率还是F1值都有所提升,进一步验证了本文提出的跨语言迁移检测方法要优于基于单语模型的检测方法。从以下两方面分析原因:
1)理论上,可以通过对BERT模型进行微调来自动检测攻击性言论,但要达到上述目标需要大量的语料,而由于语料不足,模型无法很好地对文本中的攻击性特征进行表示学习;类似地,在使用TF‑IDF表示文本特征时,数据集极少的情况下并不能将文本中的多元信息很好地表示出来,所以这些单语模型尽管可以学习到一些攻击性特征,但在测试过程中的检测性能表现一般。
2)在数据资源极少的情况下,由于组成不同语言的单词不同,可能差异很大。这导致将其他语言的文本作为单语检测器的输入时,该检测器对上述所能表示的信息量与对训练语言相同的文本表示的信息量相差悬殊,不利于迁移检测。而对mBERT的迁移学习使该检测器对不同的语言都有一定的表示能力,可以缩小文本表示阶段的信息量差距,这有利于将单语检测器学习到的特征迁移到其他语言做检测。
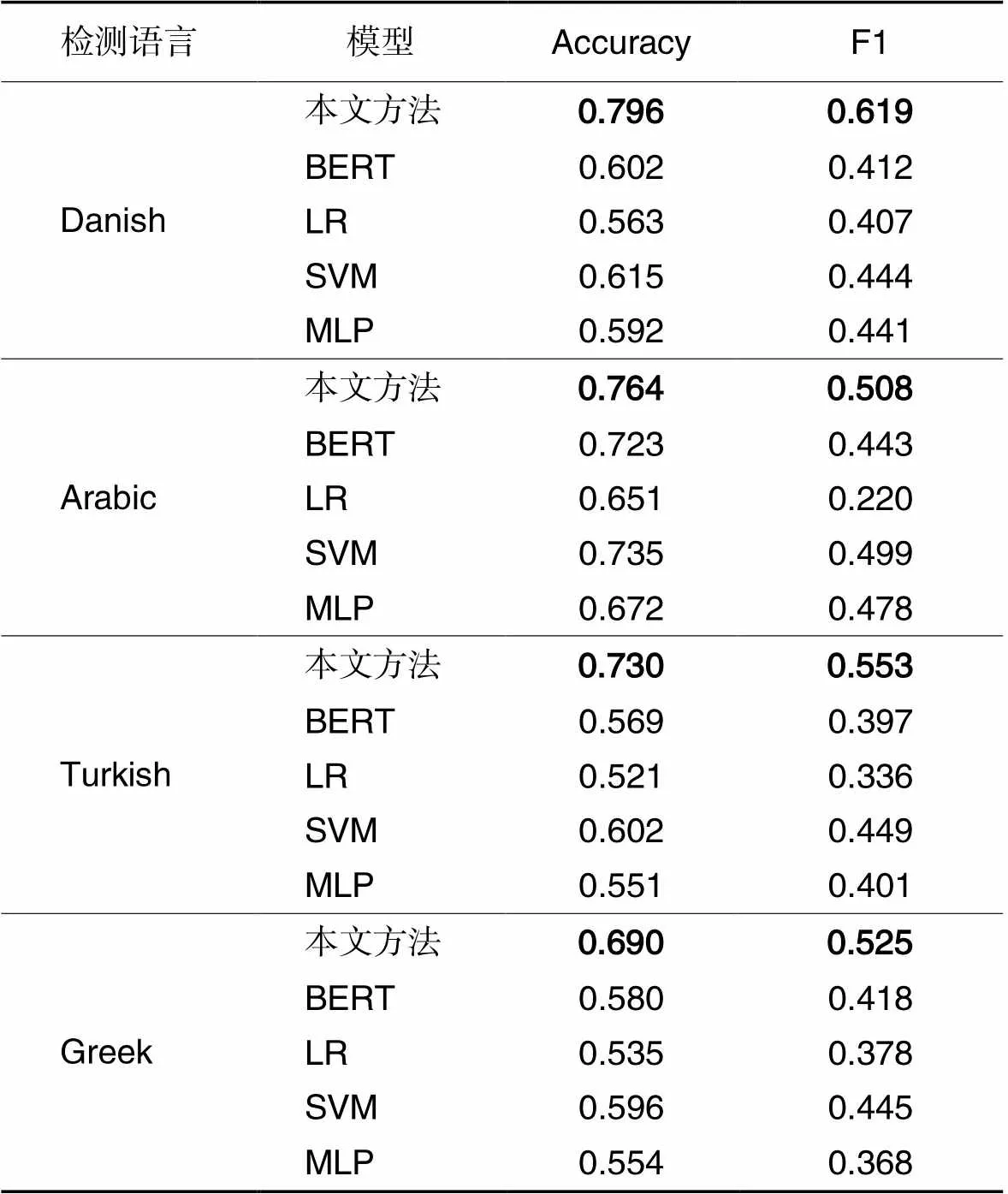
表3 不同模型的实验结果对比
经验上,对可用数据资源极少的语言收集工作和标记工作都是极耗费人力物力的,从而导致这些语言的可用资源很少;而使用跨语言迁移检测方法能够将从别的语言上学习到的攻击性特征迁移到低资源语言上检测包含攻击性的言论,扩大了该方法的使用范围。
实验也验证了跨语言迁移检测方法可以检测低资源语言中的攻击性言论。观察表3,可以看到基于英语数据集的攻击性言论检测器在不同语言上的迁移检测实验结果并不一致。相比其他语言,在丹麦语上的迁移检测结果最好。通过观察表3中的原数据,发现不同的单语检测模型在不同语言的迁移检测效果是不同的。可以得出结论,在两种语义相近的语言上做迁移检测可以解决低资源的攻击性言论检测问题。为进一步验证本文方法的有效性,通过式(4)计算两个语言的GH距离作为判断最佳迁移检测模型的效果,结果如表4所示。表4计算了样本量最高的三种语言(英语、土耳其语和希腊语)和其他语言之间的单词向量的GH距离来衡量不同语种之间的语言相似度。其中,两种不同语言对应的值越小,表明这两种语言越相似。从表4中可以看出英语与丹麦语相似度更高,而希腊语与丹麦语、土耳其语与阿拉伯语相似度高,这也符合人们对语言的观测。
4.3 语义相似度对迁移效果的影响分析
为了分析语义相似度对迁移效果的影响,设置样本量最高的三种语言训练单语检测模型,并迁移到其他语言中做迁移检测实验,检测不同单语检测模型对不同语言的迁移检测效果。
首先,分别在英语、土耳其语和希腊语三个语言的数据集上进行攻击性言论检测模型的训练,得到英语检测模型、土耳其语检测模型和希腊语检测模型;接着,将这三个检测模型分别在其他语言上进行检测实验,实验结果图3所示,其中en、da、ar、tr、和el表示英语、丹麦语、阿拉伯语、土耳其语和希腊语。
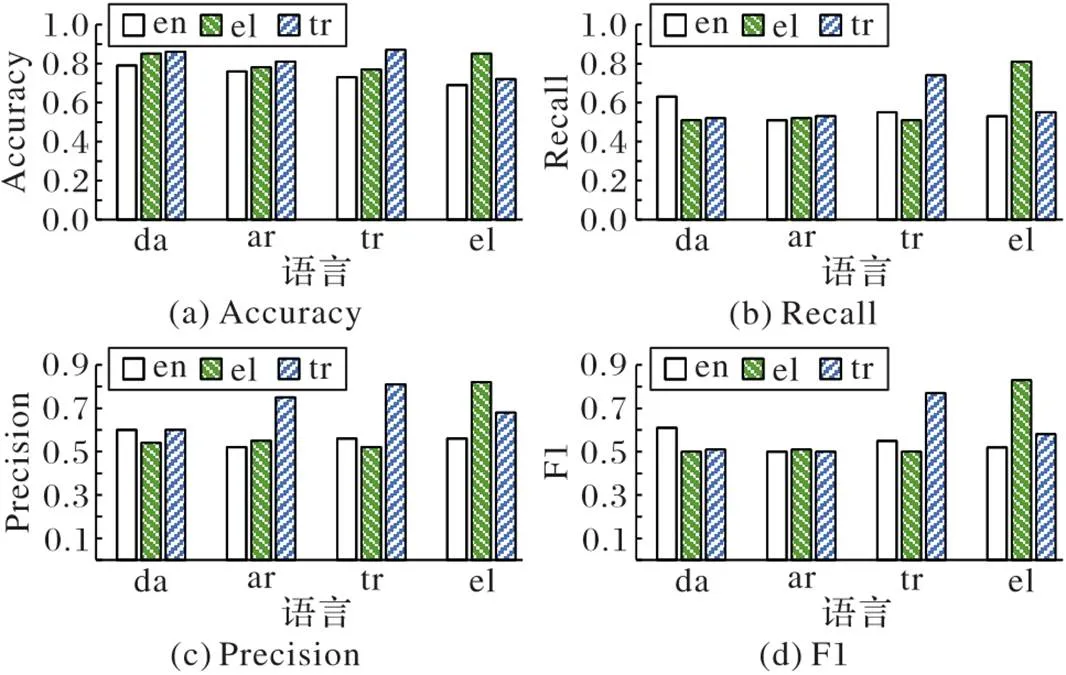
图3 五种语言模型的准确度、召回率、精确度和F1性能比较
从图3可以看出,对于丹麦语、阿拉伯语和土耳其语的F1以及Recall,使用英语检测器的检测结果对应的四个评价指标基本优于另外两个分类器(在本次分析中,使用土耳其语检测器检测土耳其语和使用希腊语检测器检测希腊语的结果不参与分析),且这三种语言与英语之间的GH距离也远小于其他两种语言之间的GH距离。对于Accuracy和Precision,土耳其语对应的柱状图要高于英语对应的柱状图,表明这种方法在一定程度上利用了语言上的相似性,使在语义相似的语言间迁移时达到信息损失最小化,进一步说明了判断语义相似度在跨语言检测中的重要性。可以利用这种特性,选择与低资源语言语义相似度最高的高资源数据进行单语攻击性言论检测模型的训练,进而可以更好地实现对低资源语言中的攻击性判断。
4.4 训练资源的多少对迁移效果的影响分析
设置不同的训练样本量以分析样本量变化过程中迁移检测效果的变化,结果如图4。可以看出,随着训练样本量的增多,迁移检测效果的性能也不断提升。观察图4发现,当训练样本量小于3 000时,对各个语言的迁移检测性能指标均低于0.35,此时模型处于不够理想的状态;随着训练样本量的增加,模型的迁移检测性能指标也随之上升,当训练样本量增加到12 000时,图中各指标处于缓慢增长甚至稳定状态。而且相较于其他语言,与英语语义相似度最高的丹麦语的检测性能指标增长最快。所以训练样本越多,用这些训练样本训练得到的模型迁移到其他语言中的效果越好,但当样本量超过一定值时,训练资源的多少带来的影响就会很小;而且与高资源语言相似度最高的低资源语言的检测性能的变化最明显。由此,本文认为语言之间的相似性是使迁移效果更优的主要原因,两种语言越相似,迁移检测效果越好。
4.5 与有监督方法的对比实验分析
本文方法主要是基于mBERT的无监督检测方法,为了进一步探究语言相似性对低资源语言任务中的影响,将无监督方法与一组有监督方法作对比实验。具体实现为在得到英语这种高资源语言对应的检测模型后,在有限的低资源语言中做进一步的迁移学习,实验结果如表5。由表5可以看出,本文的无监督方法效果接近有监督的方法,并且不同语言之间的接近程度有一定的差异。值得注意的是,丹麦语中的有监督方法比无监督方法在Accuracy和F1两种评价指标中分别高0.029和0.090。同时发现,与英语相似度更高的丹麦语无论是各指标值还是接近程度都要优于其他语言,这也进一步验证了语言相似性对低资源语言任务中的影响一致性。
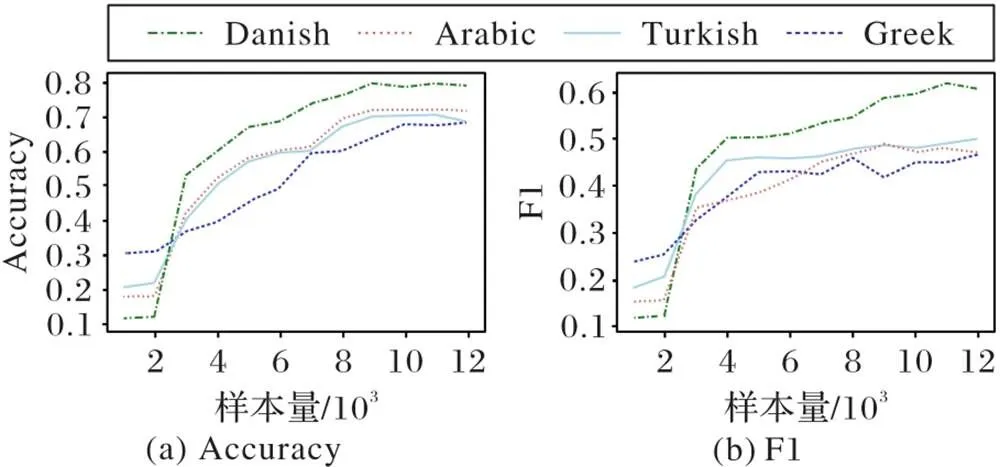
图 4 训练样本量不同时的模型迁移检测对比

表5 本文方法与有监督方法的对比
5 结语
本文采用跨语言模型迁移学习和迁移检测相结合方式构建了攻击性言论监测器,实现了对低资源语言的攻击性检测。通过在BERT模型中迁移跨语言预训练语言模型mBERT,保证模型对多种语言的语义编码能力,且减少多语语言模型训练过程中资源的耗费。对BERT模型微调,实现在该语言中的攻击性言论检测。通过探索不同语言之间的语言相似度,提高在低资源语种中的攻击性言论迁移检测有效性。实验结果表明,本文方法确实能有效提高对低资源语种的迁移检测效果。在今后的研究中,会尝试将这种方法应用在多种任务上,如其他自然语言处理领域的机器翻译、文本生成等。
[1] MALMASI S, ZAMPIERI M. Challenges in discriminating profanity from hate speech[J]. Journal of Experimental and Theoretical Artificial Intelligence, 2018. 30(2): 187-202.
[2] KUMAR R, OJHA A K, MALMASI S, et al. Benchmarking aggression identification in social media[C]// Proceedings of the 1st Workshop on Trolling, Aggression, and Cyberbullying. Stroudsburg, PA: Association for Computational Linguistics, 2018: 1-11.
[3] NOBATA C, TETREAULT J, THOMAS A, et al. Abusive language detection in online user content[C]// Proceedings of the 25th International Conference on World Wide Web. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2016: 145-153.
[4] ROSENTHAL S, ATANASOVA P, KARADZHOV G, et al. SOLID: a large‑scale semi‑supervised dataset for offensive language identification[C]// Findings of the Association for Computational Linguistics: ACL‑IJCNLP 2021. Stroudsburg, PA: Association for Computational Linguistics, 2021: 915-928.
[5] MUBARAK H, RASHED A, DARWISH K, et al. Arabic offensive language on Twitter: analysis and experiments[C]// Proceedings of the 6th Arabic Natural Language Processing Workshop. Stroudsburg, PA: Association for Computational Linguistics, 2021: 126-135.
[6] ÇÖLTEKIN Ç. A corpus of Turkish offensive language on social media[C]// Proceedings of the 12th Language Resources and Evaluation Conference. Paris: European Language Resources Association, 2020: 6174-6184.
[7] CASULA C, PALMERO APROSIO A, MENINI S, et al. FBK‑DH at SemEval-2020 Task 12: using multi‑channel BERT for multilingual offensive language detection[C]// Proceedings of the 14th Workshop on Semantic Evaluation. [S.l.]: International Committee for Computational Linguistics, 2020: 1539-1545.
[8] FENG F X Y,YANG Y F, CER D, et al. Language‑agnostic BERT sentence embedding[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2022: 878-891.
[9] PAMUNGKAS E W, PATTI V. Cross‑domain and cross‑lingual abusive language detection: a hybrid approach with deep learning and a multilingual lexicon[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop. Stroudsburg, PA: Association for Computational Linguistics,2019: 363-370.
[10] WARNER W, HIRSCHBERG J. Detecting hate speech on the world wide web[C]// Proceedings of the 2nd Workshop on Language in Social Media. Stroudsburg, PA: Association for Computational Linguistics, 2012: 19-26.
[11] SAROJ A, PAL S. An Indian language social media collection for hate and offensive speech[C]// Proceedings of the 1st Workshop on Resources and Techniques for User and Author Profiling in Abusive Language. Paris: European Language Resources Association, 2020: 2-8.
[12] PATHAK V, JOSHI M, JOSHI P A, et al. KBCNMUJAL@ HASOC‑Dravidian‑CodeMix‑FIRE2020: using machine learning for detection of hate speech and offensive code‑mixed social media text[EB/OL]. (2021-02-19)[2021-08-10].https://arxiv.org/ftp/arxiv/papers/2102/2102.09866.pdf.
[13] 苏金树,张博锋,徐昕. 基于机器学习的文本分类技术研究进展[J]. 软件学报, 2006, 17(9): 1848-1859.(SU J S, ZHANG B F, XU X. Advances in machine learning based text categorization[J]. Journal of Software, 2006, 17(9):1848-1859.)
[14] ZAMPIERI M, NAKOV P, ROSENTHAL S, et al. SemEval-2020 Task 12: multilingual offensive language identification in social media (OffensEval 2020)[C]// Proceedings of the 14th Workshop on Semantic Evaluation. [S.l.]: International Committee for Computational Linguistics, 2020: 1425-1447.
[15] HOWARD J, RUDER S. Universal language model fine‑tuning for text classification[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 328-339.
[16] LIU P, LI W, ZOU L. NULI at SemEval-2019 Task 6: transfer learning for offensive language detection using bidirectional transformers[C]// Proceedings of the 13th International Workshop on Semantic Evaluation. Stroudsburg, PA: Association for Computational Linguistics, 2019: 87-91.
[17] PITENIS Z, ZAMPIERI M, RANASINGHE T. Offensive language identification in Greek[C]// Proceedings of the 12th Language Resources and Evaluation Conference. Paris: European Language Resources Association, 2020: 5113-5119.
[18] NIKOLOV A, RADIVCHEV V. Nikolov‑Radivchev at SemEval-2019 Task 6: offensive tweet classification with BERT and ensembles[C]// Proceedings of the 13th International Workshop on Semantic Evaluation. Stroudsburg, PA: Association for Computational Linguistics, 2019: 691-695.
[19] MAHESHAPPA P, MATHEW B, SAHA P. Using knowledge graphs to improve hate speech detection[C]// Proceedings of the 3rd ACM India Joint International Conference on Data Science and Management of Data. New York: ACM, 2021: 430-430.
[20] PHAM Q H, NGUYEN V A, DOAN L B, et al. From universal language model to downstream task: improving RoBERTa‑based Vietnamese hate speech detection[C]// Proceedings of the 12th International Conference on Knowledge and Systems Engineering. Piscataway: IEEE, 2020: 37-42.
[21] AL‑MAKHADMEH Z, TOLBA A . Automatic hate speech detection using killer natural language processing optimizing ensemble deep learning approach[J]. Computing, 2020, 102(2):501-522.
[22] AYO F E, FOLORUNSO O, IBHARALU F T, et al. Hate speech detection in Twitter using hybrid embeddings and improved cuckoo search‑based neural networks[J]. International Journal of Intelligent Computing and Cybernetics,2020, 13(4):485-525.
[23] KAPIL P, EKBAL A. A deep neural network based multi‑task learning approach to hate speech detection[J]. Knowledge‑Based Systems, 2020, 210: No.106458.
[24] COLLA D, CASELLI T, BASILE V, et al. GruPaTo at SemEval-2020 Task 12: retraining mBERT on social media and fine‑tuned offensive language models[C]// Proceedings of the 14th Workshop on Semantic Evaluation. [S.l.]: International Committee for Computational Linguistics, 2020: 1546-1554.
[25] KUDUGUNTA S, BAPNA A, CASWELL I, et al. Investigating multilingual NMT representations at scale[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2019: 1565-1575.
[26] KONDRATYUK D, STRAKA M. 75 languages, 1 model: parsing universal dependencies universally[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2019: 2779-2795.
[27] KUMAR A, SAUMYA S, SINGH J P . NITP‑AI‑NLP@HASOC‑ FIRE2020: fine tuned BERT for the hate speech and offensive content identification from social media[C]// Proceedings of the 12th Meeting of Forum for Information Retrieval Evaluation. Aachen: CEUR‑WS.org, 2020: 266-273.
[28] LIBOVICKÝ J, ROSA R, FRASER A. How language‑neutral is multilingual BERT?[EB/OL]. (2019-11-08)[2021-08-10].https://arxiv.org/pdf/1911.03310.pdf.
[29] ABE M, MIYAO J, KURITA T. q‑SNE: visualizing data using q‑Gaussian distributed stochastic neighbor embedding[C]// Proceedings of the 25th International Conference on Pattern Recognition. Piscataway: IEEE, 2021: 1051-1058.
[30] PATRA B, MONIZ J R A, GARG S, et al. Bilingual lexicon induction with semi‑supervision in non‑isometric embedding spaces[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA: Association for Computational Linguistics, 2019: 184-193.
[31] ZAMPIERI M, MALMASI S, NAKOV P, et al. SemEval-2019 Task 6: identifying and categorizing offensive language in social media (OffensEval)[C]// Proceedings of the 13th International Workshop on Semantic Evaluation. Stroudsburg, PA: Association for Computational Linguistics, 2019: 75-86.
Detection of unsupervised offensive speech based on multilingual BERT
SHI Xiayang1, ZHANG Fengyuan1, YUAN Jiaqi2, HUANG Min1*
(1,,450001,;2,,450001,)
Offensive speech has a serious negative impact on social stability. Currently, automatic detection of offensive speech focuses on a few high‑resource languages, and the lack of sufficient offensive speech tagged corpus for low‑resource languages makes it difficult to detect offensive speech in low‑resource languages. In order to solve the above problem, a cross‑language unsupervised offensiveness transfer detection method was proposed. Firstly, an original model was obtained by using the multilingual BERT (multilingual Bidirectional Encoder Representation from Transformers, mBERT)model to learn the offensive features on the high‑resource English dataset. Then, by analyzing the language similarity between English and Danish, Arabic, Turkish, Greek, the obtained original model was transferred to the above four low‑resource languages to achieve automatic detection of offensive speech on low‑resource languages. Experimental results show that compared with the four methods of BERT, Linear Regression (LR), Support Vector Machine (SVM) and Multi‑Layer Perceptron (MLP), the proposed method increases both the accuracy and F1 score of detecting offensive speech of languages such as Danish, Arabic, Turkish, and Greek by nearly 2 percentage points, which are close to those of the current supervised detection, showing that the combination of cross‑language model transfer learning and transfer detection can achieve unsupervised offensiveness detection of low‑resource languages.
cross‑language model; offensive speech detection; BERT (Bidirectional Encoder Representation from Transformers); unsupervised method; Transfer Learning (TL)
This work is partially supported by Key Research and Development and Promotion Project of Henan Province (212102210547).
SHI Xiayang, born in 1978,Ph. D., lecturer. His research interests include natural language processing, machine translation.
ZHANG Fengyuan, born in 1998. Her research interests include natural language processing, machine translation.
YUAN Jiaqi, born in 1996, M. S. candidate. Her research interests include natural language processing, multimodal machine translation.
HUANG Min, born in 1972, Ph. D., professor. His research interests include data mining, information processing.
TP391.1
A
1001-9081(2022)11-3379-07
10.11772/j.issn.1001-9081.2021112005
2021⁃11⁃25;
2021⁃12⁃31;
2022⁃01⁃14。
河南省重点研发与推广专项(212102210547)。
师夏阳(1978—),男,河南鲁山人,讲师,博士,CCF会员,主要研究方向:自然语言处理、机器翻译;张风远(1998—),女,河南许昌人,主要研究方向:自然语言处理、机器翻译;袁嘉琪(1996—),女,河南许昌人,硕士研究生,主要研究方向:自然语言处理、多模态机器翻译;黄敏(1972—),男,河南南阳人,教授,博士,主要研究方向:数据挖掘、信息处理。
