不平衡多分类算法综述
2022-11-30李蒙蒙刘艺李庚松郑奇斌秦伟任小广
李蒙蒙,刘艺*,李庚松,郑奇斌,秦伟,任小广
不平衡多分类算法综述
李蒙蒙1,刘艺1*,李庚松1,郑奇斌2,秦伟1,任小广1
(1.军事科学院 国防科技创新研究院,北京 100071; 2.军事科学院,北京 100091)(∗通信作者电子邮箱albertliu20th@163.com)
不平衡数据分类是机器学习领域的重要研究内容,但现有的不平衡分类算法通常针对不平衡二分类问题,关于不平衡多分类的研究相对较少。然而实际应用中的数据集通常具有多类别且数据分布具有不平衡性,而类别的多样性进一步加剧了不平衡数据的分类难度,因此不平衡多分类问题已经成为亟待解决的研究课题。针对近年来提出的不平衡多分类算法展开综述,根据是否采用分解策略把不平衡多分类算法分为分解方法和即席方法,并进一步将分解方法按照分解策略的不同划分为“一对一(OVO)”架构和“一对多(OVA)”架构,将即席方法按照处理技术的不同分为数据级方法、算法级方法、代价敏感方法、集成方法和基于深度网络的方法。系统阐述各类方法的优缺点及其代表性算法,总结概括不平衡多分类方法的评价指标,并通过实验深入分析代表性方法的性能,讨论了不平衡多分类的未来发展方向。
不平衡分类;多类别分类;不平衡多分类;分类算法;机器学习
0 引言
近年来,大数据的发展使数据规模显著增长,不平衡性成为当前数据的明显特点,不平衡多分类数据的应用已经成为亟待解决的重点课题。例如,医药系统检测[1]、情感分类[2-3]、邮件分类[4]、风力发电斜坡事件预测[5]、网络入侵检测[6]、信用卡欺诈检测[7]等实际工程应用都与不平衡多分类问题密切相关。数据不平衡也称为“数据倾斜”,主要指不同类别的样本分布具有显著差异。以不平衡数据集为训练样本,构建学习模型,并用来预测新样本类别的问题称为不平衡数据分类问题[8]。在该类问题中通常利用不平衡率描述数据集的不平衡性。不平衡率指数据集中多数类样本数量与少数类样本数量的比值,当不平衡率大于1时,认为该数据集具有不平衡性。传统的分类算法通常假设类别间样本数量均衡,且样本的误分代价一致。然而,这些前提条件在现实应用中很难满足,数据的不平衡可能导致学习算法性能下降,使传统方法在处理不平衡数据分类时具有一定的局限性。为了解决不平衡数据分类问题,近些年出现了一系列优异的不平衡数据分类方法。以“不平衡多分类”和“imbalanced multi‑class data classification”为关键词分别在中国知网(CNKI)数据库和Elsevier、IEEE、Springer数据库中搜索,得到的相关文献数目如图1所示,可以发现,近些年国内外关于不平衡多分类的文献正逐年增加,在短短十五年的时间里,相关文献数目增长了数十倍,这表明关于不平衡多分类的研究正逐渐得到重视,相关研究成果也正逐渐丰富。为方便相关学者了解该领域的进展,对近些年提出的研究成果展开综述变得十分必要。近些年,一些相关的综述也相继发表:Sahare等[9]从数据级和算法级两个角度进行分类,并对近些年经典的算法进行总结阐述;Tanha等[10]对基于Boosting的不平衡多分类集成方法进行了详细综述,并利用典型算法进行了大量实验。与现有综述阐述的角度不同,本文主要以多分类为切入点,从“分解方法”和“即席方法”两个角度展开综述,在多分类的基础上进一步考虑数据的不平衡性。
与二分类数据集中仅包含正类和负类不同,多分类数据集中通常包含更多类别的样本,这使得各类别间关系更加多样,而随着类别数目的增加,整个问题的难度也随之增加,因此直接将二分类算法应用到多分类问题中通常难以有效解决问题。尤其面对不平衡数据,样本规模不一致使得各类别间的分布关系更加复杂,导致分类模型对少数类的识别更加困难。
不平衡多分类问题的特性主要体现在类别间样本数目不均衡和多类别两个层面。类别间样本数目不均衡导致训练出的分类模型偏向多数类,而多类别问题不仅要考虑分类器本身性能,还要深入探究分类器的组合问题[11]。根据解决问题的角度不同可以把现有不平衡多分类算法分为两类:基于分解的方法和即席方法。基于分解的方法将不平衡多分类问题分解为多个不平衡二分类问题进行求解;即席方法是将不平衡多分类问题作为一个整体进行求解[12]。更进一步地,按照采用架构的不同,分解方法可以分为基于“一对一(One Vs. One, OVO)”的方法和基于“一对多(One Vs. All, OVA)”的方法;根据采用技术的不同,即席方法可以分为数据级方法、算法级方法、代价敏感方法、集成方法和基于深度网络的方法[13-14],如图2所示。

图1 不平衡多分类文献数量的趋势
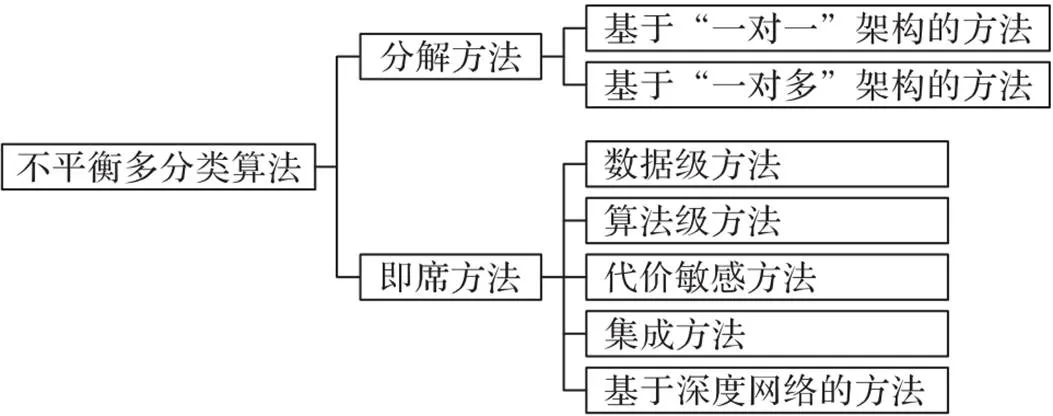
图2 不平衡多分类算法分类
根据图2中的分类方法,本文详细总结了各大数据库中近三年提出的比较有代表性的不平衡多分类算法,为从事不平衡多分类研究的学者了解该领域的近几年的进展提供参考。首先将不平衡多分类算法分为分解方法和即席方法,详细介绍两种方法的研究进展和特点,并进行比较;其次,本文还总结概括了不平衡多分类领域的评估指标,主要包括经典的评估指标和近些年提出的改进的评估指标;接着通过实验对几种典型的不平衡多分类算法展开了对比并进行深入分析;最后总结并阐述了不平衡多分类领域存在的几个难点问题,为该领域未来的研究提供方向。
1 分解方法
由于目前对二分类问题的研究较为深入,因此很多学者采用“分解法”的思想把多分类问题转换成多个二分类问题,并通过利用或修改现有的二分类算法求解转换后的二分类问题。典型的分解架构主要有“一对一(OVO)”和“一对多(OVA)”。
1.1 “一对一”架构

Lango[2]认为对于不平衡多分类问题而言,OVO要优于OVA,因为通过OVA方法构造出来的二分类问题可能会比原始问题更加不平衡,从而增加了分类难度。Żak等[15]则通过大量实验对不平衡多分类问题中几种分解策略的性能进行了分析,并得出结论:在相同的条件下,以G‑mean为评价指标,OVO比OVA方法性能更好。Zhang等[16]结合数据采样法和OVO分解方法共同解决不平衡多分类问题,提出基于距离的相对权重自适应采样方法来平衡数据,通过该方法提高OVO中每个二分类器的性能。Liang等[17]利用随机欠采样(Randomly Under‑Sampling, RUS)和SMOTE(Synthetic Minority Oversampling TEchnique)方法[18]平衡数据集,然后采用弹性网络来选择特征,最后用支持向量机(Support Vector Machine, SVM)为二分类器进行分类,并将提出的模型成功运用于心律失常疾病检测。Zhang等[13]提出结合集成思想的OVO方法来提升每个类别对的分类效果,最后通过实验表明OVO与SMOTE+AdaBoost(Adaptive Boosting)或EasyEnsemble结合得到的算法比与UnderBagging、SMOTEBagging、RUSBoost(Randomly Under‑Sampling Boosting)、SMOTEBoost等集成方法结合得到的算法在平均精度上表现更好[19-23]。
OVO架构虽然在不平衡多分类问题中表现出比较好的性能,但是也存在一定的局限性。例如,OVO架构在训练每个二分类器时仅利用两类数据,这将造成一定的信息丢失[12,16];此外,该架构需要训练多个二分类器,因此当类别数目较大时,算法的时间开销也较大[12,24]。
1.2 “一对多”架构

Sen等[25]基于OVA模式提出一种新的多分类模型,称为基于Boosting集成和过采样技术的二值化方法(Binarization with Boosting and Oversampling, BBO)。该模型利用SMOTE过采样技术解决OVA带来的不平衡问题,并使用5种不同的二分类器在带标签的数据集和部分数据带标签的数据集上进行测试比较,此外该模型还利用Boosting集成技术进一步提升了分类器的性能。Jiang等[26]结合特征选择和OVA架构对产品评论进行分类,设计了3个独立的子分类器分别对应不同类别,并利用二叉树将这3个子分类器组合在一起进行多分类。
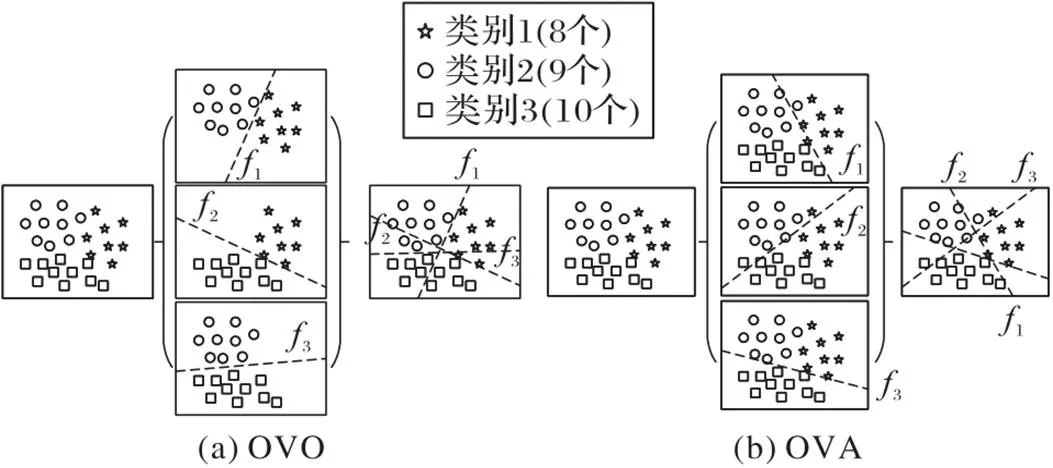
图3 OVO和OVA架构流程示意图
2 即席方法
即席方法是将多分类问题看作一个整体,直接利用多类别之间的关系进行分类的一种方法。按照处理不平衡问题的角度不同可以分为数据级方法、算法级方法、代价敏感方法、集成方法和基于深度网络的方法,如图4所示。
数据级方法从数据分布的角度进行分析,通过重采样技术平衡数据集,避免数据不平衡带来的影响;算法级方法则通过提出新的算法或者对已有的算法进行改进来提升算法在不平衡多分类问题中的性能,该类方法不会增加或删除数据样本,因此不会影响数据的分布;代价敏感方法从实际应用的角度出发,给少数类样本分配较大的误分代价,并以最小化整体误分代价为优化目标;单独使用集成方法难以有效解决不平衡问题,因此通常将集成方法与其他方法相结合,共同解决不平衡问题;基于深度网络的方法是近些年比较受关注的方法,该类方法主要是构建新的网络架构来对不平衡多类别数据进行分类,通过不断调整模型参数来优化分类结果,提升分类性能。
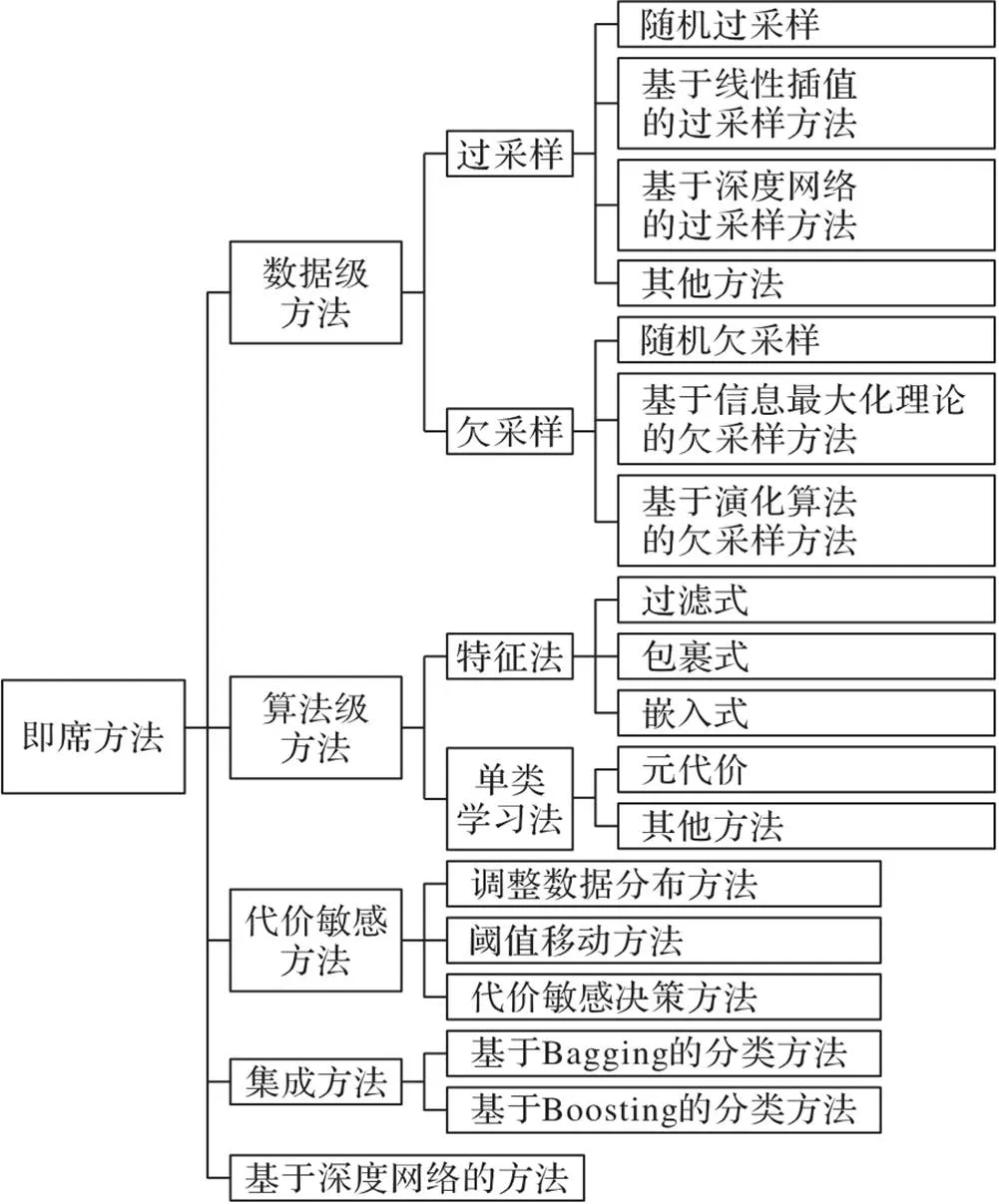
图4 即席方法的分类
2.1 数据级方法
数据级方法旨在从数据层面出发利用重采样技术降低数据集的不平衡率,通过构建相对平衡的数据集来降低数据不平衡给分类模型带来的影响,从而可以利用传统分类模型解决不平衡多类别数据分类问题。数据级方法先对数据集进行重采样,然后再利用平衡后的数据集训练分类器,重采样过程与分类器训练过程无关,因此可以根据数据集特性选择合适的重采样技术和分类器。按照采样方式的不同,数据重采样技术可以分为:过采样和欠采样。
2.1.1过采样方法
过采样方法通常是对少数类样本进行处理,通过重复采样或者合成新的少数类样本,增加少数类样本数量,提高分类器对少数类的识别度,提升算法分类性能。常用的过采样方法是随机过采样,即随机重复复制少数类样本,该方法简单易操作,但是随机重复采样会带来严重的过拟合问题。针对此问题,研究学者相继提出了一系列新的过采样方法,主要包括基于线性插值的过采样方法、基于深度网络的过采样方法以及一些其他过采样方法。基于线性插值的过采样方法通过考虑少数类样本及其近邻样本之间的位置关系,采用插值的方式合成新样本,并将新生成的样本与原始样本结合构成新的数据集;基于深度网络的过采样方法主要利用对抗神经网络进行样本生成与分类,该类算法通过生成器生成新样本,再利用判别器进行判别和分类;基于聚类的过采样方法考虑了数据样本的位置分布,首先将样本分组为多个簇,再从每个簇中过采样样本;基于距离的过采样方法通过计算各样本之间的距离选择合适的少数类样本,并结合其他策略生成新样本。
1)基于线性插值的过采样方法。SMOTE方法[18]是最早提出利用随机线性插值在少数类样本和其近邻同类样本之间合成新样本的方法,它在一定程度上缓解了随机过采样带来的过拟合问题。受到SMOTE的启发,Han等[29]和He等[30]分别提出了Borderline‑SMOTE和ADASYN(ADAptive SYNthetic sampling approach)过采样方法。与SMOTE方法平等对待所有少数类样本的策略不同,Borderline‑SMOTE首先利用近邻机制选择出少数类边界样本,然后再利用随机线性插值生成新样本;ADASYN则根据少数类样本的困难程度为其分配权重,然后按照不同的权重合成对应数量的新样本。SMOTE、Borderline‑SMOTE和ADASYN使用较为简单且效果显著,在不平衡数据分类中得到了广泛的应用。
Zhang等[16]把Galar等[31]提出的基于距离的相对能力加权OVO方法(Distance‑based Relative Competence Weighting for OVO strategy, DRCW‑OVO)应用到了不平衡多分类问题中。他们认为DRCW‑OVO是一种很好的多分类方法,但是并不适用于不平衡多分类问题,因为DRCW‑OVO方法在测试新样本时依据的是新样本到不同类别的近邻平均距离,在类别不平衡的情况下,少数类样本通常比多数类样本更加稀疏,导致预测结果更偏向多数类。针对此问题,他们又提出了一种基于距离的相对能力加权与自适应样本合成(Distance‑based Relative Competence Weighting with Adaptive Synthetic Example Generation, DRCW‑ASEG)方法。DRCW‑ ASEG方法首先为每个少数类线性插值合成新样本以消除样本不平衡带来的偏差,再计算测试样本到不同类别的近邻平均距离,最后依据计算出的平均距离给不同类别设置权重值,提高把测试样本分类为少数类的可能性。Zhang等[32]首先利用欧氏距离选择边界多数类样本和边界少数类样本,然后计算边界少数类样本的权重值,再由不平衡率决定少数类的合成率,采用聚类方法对少数类样本分组,并在每个簇中以随机线性插值的方式合成新样本。Patil等[33]在SMOTE的基础上提出了三种过采样技术并用于解决大数据时代庞大的数据集分类问题,分别是:MEMMOT(MEre Mean Minority Over_sampling Technique)、MMMmOT(Minority Majority Mix mean Over_sampling Technique)和CMEOT(Clustering Minority Examples Over_sampling Technique)。这三种过采样技术都是基于样本安全等级[34]提出的,其中MEMMOT仅对少数类样本进行合成,首先根据其近邻中少数类样本的数目确定所有少数类样本的安全等级,然后利用该安全等级合成新样本,该方法避免了SMOTE方法随机采样导致大量重复样本的问题;MMMmOT则同时对多数类样本和少数类样本进行处理,避免边界样本合成错误类别的新样本;CMEOT则利用聚类的思想对所有少数类样本进行分组,并在各簇内部合成新样本。Mathew等[35]提出了一种基于加权核的SMOTE(Weighted Kernel‑based SMOTE, WK‑SMOTE)。WK‑SMOTE方法通过在SVM分类器的特征空间中对少数类样本进行过采样来克服SMOTE对于非线性问题的局限性。
2)基于深度网络的过采样方法。在故障诊断问题中,正常的样本数要多于故障样本数,Zareapoor等[36]提出了能够同时分类和故障检测的少数类样本过采样生成对抗网络(Minority oversampling Generative Adversarial Network, MoGAN)。MoGAN由两个相互依赖的网络组成,其中生成网络根据多数类样本的分布合成少数类样本,而判别网络则与其他判别方法[37-38]同时具有判别器和分类器不同,MoGAN提出的判别网络可以同时充当分类器和故障检测器。为了解决多类不平衡数据线上分类过程中模型自适应更新的问题,Yu等[39]利用两阶段博弈策略设计了一个动态的多分类方法,在数据生成阶段,利用两个结合博弈策略的动态极限学习机生成少数类样本以平衡数据分布,在模型更新阶段设置了新的目标函数,该目标函数同时考虑了模型的预测性能和成本开销。Lee等[40]提出了一种基于生成对抗网络的入侵检测系统。该系统首先将数据集分成训练数据集和测试数据集,然后利用对抗网络对训练集中的少数类样本进行过采样,再结合所有多数类样本构成新的训练数据集,最后利用机器学习的方法构建分类模型。Shamsolmoali等[41]针对图像数据集不平衡给深度学习技术带来了严峻的挑战等问题,提出了一种结合生成对抗网络和胶囊网络的方法来平衡图像数据集。该模型中生成器根据多元概率分布生成新的样本,结合了多数类样本的分布结构,判别器则与Zareapoor等[36]提出的鉴别器类似,在对样本进行鉴别的同时进行样本分类。此外为了提高模型的收敛速度,Shamsolmoali等[41]使用了特征匹配损失函数对生成器进行训练。此外,Pouyanfar等[42]针对视频不平衡分类问题提出了一种深度学习框架,该框架首先利用时间和空间综合过采样技术在两个维度上分别处理数据不平衡问题,然后利用预训练的卷积神经网络(Convolutional Neural Network, CNN)提取空间特征,利用残差双向长短期记忆网络捕获视频数据集中的时间信息,最后利用全连接网络生成预测结果。Liu等[43]提出了一种基于对抗神经网络和多传感器数据融合技术的机械故障诊断框架。根据数据融合的位置不同,Liu等[43]提出两种不同的模式:融合前对抗神经网络模式和融合后对抗神经网络模式;最后利用两个不平衡机械数据集验证该框架,实验结果表明,两种模式在机械故障诊断中均具有良好的性能。
3)其他过采样方法。Yang等[44]在MDO(Mahalanobis Distance‑ based Over‑sampling)[45]方法的基础上进行改进,提出基于马氏距离的自适应过采样方法(Adaptive MDO, AMDO),并将其推广到了混合类型不平衡数据集分类问题中。AMDO方法利用马氏距离选择合适的少数类样本,并将其映射到主成分空间,再利用广义奇异值分解策略生成新的少数类样本。Li等[46]结合OVO分解方法和谱聚类技术提出了一种新的不平衡多分类数据预处理方法。该方法使用OVO架构给所有类别两两配对,使用谱聚类技术把各类别对中的少数类样本划分为多个子空间,再根据数据的特征对其进行过采样。基于谱聚类技术的过采样方法考虑了数据的分布,有效避免了对异常值的过度采样。针对多分类问题中类别不平衡和类别重叠等问题,Chen等[47]提出了基于聚类的自适应分解和基于编辑的多样化过采样(Clustering‑based Adaptive Decomposition and Editing‑based Diversified Oversamping procedure, CluAD‑EdiDO)方法。CluAD‑EdiDO由两个关键部分组成:基于聚类的自适应分解和基于编辑的多样化过采样技术。前者对数据集中的相似数据样本进行分组,通过聚类的方式生成多个簇;后者则应用于不同的簇中,通过在近邻过采样方法(‑Neighbor Over‑Sampling, KNOS)[48]的基础上提出的动态近邻过采样(Dynamic‑Neighbor Over‑Sampling, DKNOS)方法对少数类样本进行过采样,解决类别不平衡和类重叠问题。Koziarski等[49]针对不平衡多分类问题中类重叠和离群点等挑战提出了多类别组合清洗和重新采样(Multi‑Class Combined Cleaning and Resampling, MC‑CCR)方法。MC‑CCR方法利用基于能量的方法对适合于过采样的区域进行建模,与SMOTE相比,该区域受离群值的影响较小。此外,该方法与提出的清理操作相结合,其目的是减少类重叠对学习算法性能的影响。最后,通过合并处理多分类问题的专用策略[12],与传统的多类别分解策略相比,MC‑CCR受类间信息丢失的影响较小。
2.1.2欠采样方法
欠采样通常是对多数类样本进行处理,通过在多数类样本中选择与少数类样本数目大概一致的样本,再与所有少数类样本结合,组成平衡数据集。随机欠采样是最简单的一种欠采样方法,其通过随机选择部分多数类样本实现欠采样目的,但是其随机性也可能导致大量有用信息丢失。针对此问题,研究学者提出了一些新的欠采样方法,主要包括基于信息最大化理论的欠采样方法和基于演化算法的欠采样方法。基于信息最大化理论的欠采样方法与随机选择多数类样本不同,它通过一定的方法选择出有代表性且有助于分类的多数类样本,将选择出的多数类样本与所有少数类样本进行结合构成新的数据集。基于演化算法的欠采样方法将欠采样过程看成是所有样本的组合优化问题,通过不断迭代选择出较优的样本组合以形成新的数据集。
2.2 算法级方法
算法级方法旨在通过修改分类模型的学习过程来提升分类器对少数类的识别度,提升算法性能。该类方法不会增加或删除原始样本,因此不会影响数据分布的变化,更适合数据分布较复杂的不平衡分类问题。常见的算法级方法主要有特征法和单类学习法。
2.2.1特征法
特征法是指通过特征选择方法从原始特征空间中选取具有区分能力的特征子集,以提高模型对少数类识别度的一类方法。数据是由特征组成的,数据分布不均衡将直接导致特征分布不均衡,因此选择具有强区分性的特征至关重要。
按照特征选择过程与分类器是否相关可以把特征选择方法分为过滤式(Filter)、包裹式(Wrapper)和嵌入式(Embedded)三类:过滤式方法依据一定的评价准则进行特征选择,该过程与分类器无关,即先对数据集进行特征选择,再训练分类器;包裹式方法直接将分类器的性能作为特征选择的评价准则,即为给定的分类器选择最合适的特征子集;嵌入式方法则将特征选择过程与分类器训练过程融为一体,即在训练分类器的过程中自动地进行特征选择,例如基于决策树和随机森林的分类方法。特征选择方法不仅可以提高模型的分类性能,还可以降低算法开销,因此得到了众多学者的青睐。
Liu等[59]提出了一种基于极限学习机的混合方法来解决癌症微阵列多类不平衡数据分类问题,该方法同时在特征层面和算法层面进行分析,首先采用过滤式方法选择特征,再利用极限学习机进行多分类,在分类过程中通过计算特征的重要性为每个输入节点生成权重,最后通过构建集成分类器来提升算法的泛化性能。Sarıkaya等[60]认为相对于某个特定的分类器,包裹式方法比过滤式方法选择的特征子集更加高效,因此提出了利用包裹式方法进行特征选择,利用随机森林进行多分类的方法。Li等[61]提出了一种典型的嵌入式方法,称为结合LASSO(Least Absolute Shrinkage and Selection Operator)惩罚的自适应多项式回归方法,该方法被应用在评估肺癌数据基因的重要性中,其中原始特征中仅对应着稀疏解非零分量的特征才是最终选择的特征。
2.2.2单类学习法

使用单类学习法会丢弃其他类别信息,因此Bellinger等[63]和Hempstalk等[64]建议应尽量避免使用单类学习法。但是Krawczyk等[65]则指出单类学习法可以捕获目标类别中足以区分其他未知类别的独特属性,因此适用于分布较复杂的数据,尤其在类不平衡、类噪声、类重叠等情况下可以表现出比其他多分类方法更加优异的性能。Pérez‑Sánchez等[66]也指出单类学习法不考虑类之间的不均衡性,因此可以训练出无偏的模型,对于解决类不平衡问题具有较好的鲁棒性。Krawczyk等[67]则详细比较了单类学习法与基于分解策略的OVO和OVA多分类方法之间的不同,并详细阐述了单类学习法的特点。Gao等[68]将单类学习法应用到医疗图像数据分类问题中,提出使用深度学习模型来学习目标类别图像特征,并使用图像复杂度进行扰动。Krawczyk等[67]则针对单类学习法中分类器覆盖重叠和由远程训练样本引起的分类器涵盖大量空白区域等问题,提出了动态选择分类器的方法,该过程根据每个样本的近邻样本决定分类器是否有效,并通过设置阈值动态删除无效分类器,最终通过集成所有选择的分类器提高模型鲁棒性。
2.3 代价敏感方法
经典的分类方法通常以最小化误分率为目标,并假设各类别误分代价相等,但在现实生活中,不同类别的误分代价通常是不一样的,因此很多学者认为训练分类算法时应符合实际需求,重点关注误分代价较高的样本,以最小化整体误分代价为目标,针对此观点,提出了基于代价敏感理论的分类方法[8]。在类别不平衡问题中,人们往往更关注少数类样本的分类结果,因此在训练分类模型时可通过提高少数类样本的误分代价来提升模型对少数类样本的重视度,进而提升模型整体分类性能。
万建武等[69]根据解决问题的阶段不同将代价敏感方法分为数据前处理方法、结果后处理方法以及直接的代价敏感学习方法,并对代价敏感理论、应用和经典模型进行了详细阐述。与之相对应的是,Zhang等[70]把代价敏感方法分为了调整数据分布、阈值移动和代价敏感决策三类。调整数据分布方法类似数据前处理方法,即以代价矩阵为依据,对误分代价较高的样本进行过采样,对误分代价较低的样本进行欠采样,使类别之间代价敏感[71]。万建武等[69]得出,在实验条件下,使用代价敏感欠采样方法比使用代价敏感过采样方法的分类结果更准确。阈值移动则通过调整决策阈值让分类器偏向误分代价较高的类别,比较典型的方法是元代价[72]。元代价方法的基本思想是利用贝叶斯风险理论最小化准则对训练样本重新标记,然后再利用重新标记的样本训练最终的分类模型。代价敏感决策方法是近年来研究的重点,它通过修改模型的训练过程来构建代价敏感分类器,即把不同类别的代价信息嵌入到模型训练的目标函数中,通过最小化期望损失来获得最优分类模型[73-75]。
虽然代价敏感方法的理论基础比较完备,但将其广泛应用在一些实际问题中仍存在一些困难。例如,在多分类问题中难以权衡各类别之间的代价权重,生成合理的代价矩阵比较困难;此外,代价矩阵的生成通常由该领域的专家完成,开销高昂且很多时候难以实现。
2.4 集成方法
在机器学习领域,集成方法由于表现出了优异的性能而得到了众多研究学者的关注。与传统方法仅训练单个学习器不同,集成方法通过训练多个学习器来解决问题。已有理论证明,当基学习器性能优于随机学习器时,集成学习器的性能将得到显著提升。集成方法通常以提高整体准确度为目标,难以适用于类别不平衡问题[50],只有与其他平衡策略相结合才能更好地解决不平衡分类问题。
2.4.1基于Bagging的集成方法
Bagging方法的原理是首先自助采样得到多个数据集,再利用这些数据集独立地训练多个基分类器,最后利用一定的结合策略将训练出的基分类器组合成一个集成分类器。比较经典的方法是随机森林,它以决策树为基分类器,通过集成多个决策树的分类结果,并利用投票机制得到最终的结果。Lango等[76]认为粗糙平衡Bagging(Roughly Balanced Bagging, RBBag)[77]是解决不平衡二分类问题算法中较为成功的一种集成方法,并从基分类器个数、基分类器多样性等方面深入研究了促使其性能较优的本质原因,最后通过分析得出基分类器个数在10~15时RBBag算法性能均值最好;此外RBBag算法的精度高低可能与基分类器的多样性并无直接关系。Lango等[76]进一步将RBBag扩展到了不平衡多分类问题中,还提出了两个多类别粗糙平衡Bagging方法(Multi‑class Roughly Balanced Bagging, MRBBag),即基于粗糙平衡Bagging的多类过采样方法(oversampling Multi‑class Roughly Balanced Bagging, oMRBBag)和基于粗糙平衡Bagging的多类欠采样方法(undersampling Multi‑class Roughly Balanced Bagging, uMRBBag)。
2.4.2基于Boosting的集成方法
与Bagging独立地训练基分类器不同,Boosting采用序列式方法依次训练基分类器。Boosting在每次训练完一个基分类器之后都会重新调整样本权重,增大被分错样本的权重,使其在下一个基分类器中得到重视并尽可能被分对,最后采用线性加权的方式结合所有基分类器,形成最终的集成分类器。在不平衡多分类问题中,Wu等[50]提出了一种基于枢纽度感知的Boosting集成方法以解决高维不平衡数据分类问题,它通过聚类欠采样解决类不平衡问题,并引入折扣因子减缓由样本权重过度增长带来的负面影响。Taherkhani等[78]将AdaBoost与CNN结合提出了AdaBoost‑CNN算法,该算法利用迁移学习的思想把训练好的CNN分类器迁移到下一个CNN分类器中,以此降低传统AdaBoost算法在大规模数据集上训练时产生的巨大的时间开销。Rodríguez等[14]考虑随机平衡策略与Boosting方法的结合在不平衡二分类中的良好表现[79],将其扩展到了不平衡多分类问题中,提出了多分类随机平衡算法。Fernández‑Baldera等[80]结合了Boosting方法和代价敏感方法提出了一个多类别代价敏感分类算法(Boosting Adapted for Cost matrix, BAdaCost),该算法利用一系列的代价敏感基分类器构造成一个集成分类器,并通过实验验证了所提算法的有效性。
直观地,训练集成分类器通常比训练单个分类器更加耗时,但是,Schwenker等[81]指出构建集成分类器的代价未必会显著高于构建单个分类器的代价,这是因为训练单个分类器时,对模型的选择和不断调参也会产生多个版本的模型,这与训练集成分类器中多个基分类器的代价基本相当;此外集成分类器中的结合策略通常比较简单,并不会带来巨大的时间开销,因此,当同时考虑模型时间开销和分类效果时,集成方法是个较好的选择。
2.5 基于深度网络的方法
由于深度网络的快速发展,近些年提出了大量基于深度网络的不平衡多分类方法[82]。Rendón等[83]深入分析了基于深度神经网络的启发式采样方法在不平衡多分类问题中的性能,它首先利用SMOTE和欠采样方法平衡数据集,然后利用处理好的数据集训练人工神经网络,再利用Editing Nearest Neighbor[84]或者Tomek’s Links[85]消除神经网络输出噪声对应的训练数据集中的样本,最终利用新生成的数据集再次训练人工神经网络。Raghuwanshi等[86]将极限学习机分类模型[87]从二分类问题扩展到多分类问题中,采用高斯核函数将输入数据转换到核空间,避免非优隐藏节点问题,此外,该算法为每个类别分配权重,这与传统算法为每个样本分配权重不同,有效降低了算法时间开销。
2.6 分解方法和即席方法的比较
相较于分解方法,即席方法可以更加客观且充分地利用所有样本信息,这更加接近多分类问题的本质,因此通常具有较好的分类性能。但是由于即席方法不能直接使用现有的二分类方法,因此通常需要开发新的分类算法,这伴随着复杂的算法设计和巨大的时间开销[12],给即席方法的发展带来了一定的挑战。
从大量关于分解方法和即席方法的研究成果中可以发现,两类算法都具有一定的优势和局限性,总结分解方法和即席方法的优缺点,如表1所示。由于分解方法通常把多分类问题转化为较为简单的二分类问题,因此其单个二分类器的训练过程通常比即席方法训练多分类器的过程更加简单;但是即席方法的训练过程可以充分利用数据集中所有样本的分布信息,因此训练出的多分类器更加具有针对性,可以适用于数据分布较为复杂的情况,而分解方法中,OVO架构在训练二分类器时仅考虑两个类别的样本,造成信息丢失,OVA架构则将除正类以外的其他类别都作为负类,人为引入不平衡,加大了训练难度。此外,分解方法可以利用现有的比较成熟的二分类算法,这不仅可以节约开发成本,还可以节省开发算法的时间开销;而即席方法则只能针对多分类问题研究新型算法。

表1 分解方法和即席方法的比较
3 评价指标
传统的分类算法通常以提高准确度为目标,但是在面对不平衡分类问题时,准确度则难以客观反映算法性能。例如,某数据集包含90个负类样本和10个正类样本,在训练学习器的过程中,如果算法把所有样本都标记为负类仍可以获得0.9的准确度,但是很明显该算法是无效的。因此,为了准确地评估不平衡算法的性能,研究学者们提出了一系列具有针对性的评价指标。下面主要从两个方面进行阐述:经典的评价指标和改进的评价指标。
3.1 经典的评价指标
在不平衡多分类问题中常用的评价指标有:准确率(Accuracy)、F、几何平均值(Geometric‑mean, G‑mean)、受试者工作特征(Receiver Operating Characteristic, ROC)、ROC曲线下面积(Area Under ROC Curve, AUC)、类平衡准确度(Class Balanced Accuracy, CBA)[88]、宏观F1(Macro‑F1)[89]和微观F1(Micro‑F1)[89]等。为了详细说明各种指标的计算方式和意义,给出混淆矩阵如表2所示。

表2 二分类混淆矩阵
3.1.1F和G‑mean

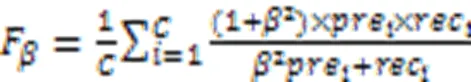
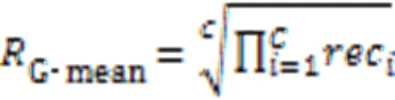
3.1.2ROC和AUC
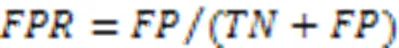
3.1.3类平衡准确度
类平衡准确度是专门针对不平衡数据提出的评价指标,主要用来衡量分类器把新样本分类正确的能力[88],如式(3)所示:
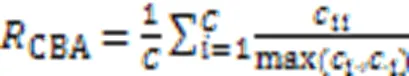
3.1.4Macro‑F1和Micro‑F1
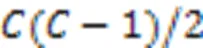
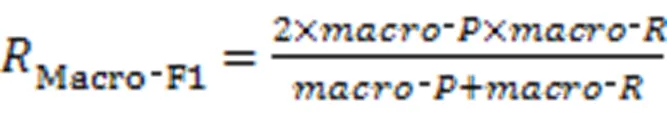
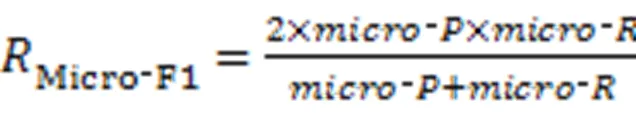
3.2 改进的评价指标
Mortaz等[90]指出在三种特殊情况下使用经典评价指标并不能客观反映分类器性能,因此提出了基于混淆矩阵的不平衡准确度指标(Imbalance Accuracy Metric, IAM)。该指标是基于CBA的一个改进版本,在CBA的基础上进一步考虑了混淆矩阵的非对角线元素,使用简单且具有较好的可解释性。计算公式如式(6):
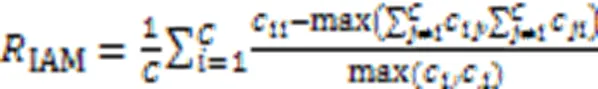

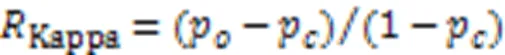

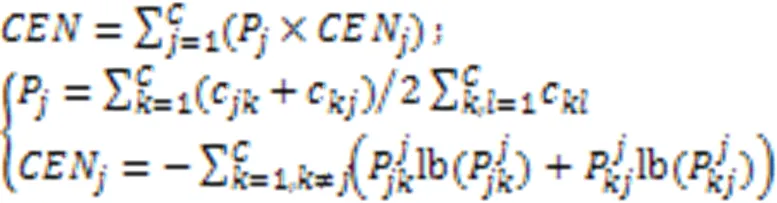
Branco等[93]根据用户偏好给每个类别设置了一个相关性,并用于分类器的评估。以召回率、精确度、F和CBA为例,分别如式(9)~(13)所示。
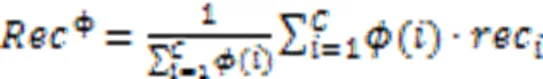
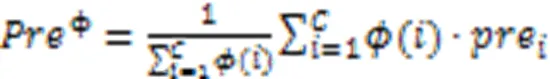
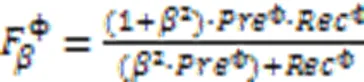
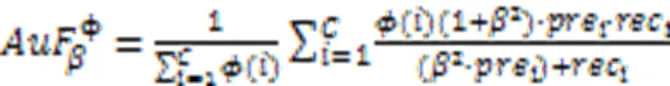
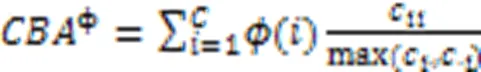
Gorodkin等[94]针对马修斯相关系数(Matthews Correlation Coefficient, MCC)[95]只能应用于二分类问题这一局限性,提出了一个可以用来评估多分类的相关系数指标。计算方式如式(14)所示。
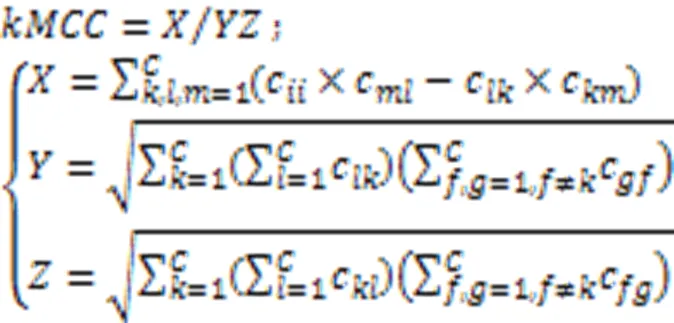
虽然针对不平衡多分类问题的指标较多,但指标的选取要结合具体应用场景和关注重点进行合理选择,有时甚至需要同时结合多种指标的结果来综合评估分类器的性能。
4 实验与结果分析
4.1 实验设置
实验数据包括10个来自KEEL、UCI的不平衡多分类数据集,其基本信息如表3所示。其中不平衡率涵盖范围从1.48至175.46,类别数目从3类到6类不等。选择了10种不同类型的不平衡多分类方法展开实验,即OVO方法,OVA方法,OVO和OVA的组合(All‑and‑One, A&O)方法[96],OVO_SMOTE方法[97],OVA_SMOTE方法[97],不平衡模糊粗糙有序加权平均最近邻分类(Imbalanced Fuzzy‑rough ordered weighted average nearest neighbor classification, FuzzyImb)方法[98],一对后序(One‑Against‑Higher‑Order, OAHO)方法[28],用于不平衡多分类的基于集成和过采样策略的二值化(Binarization with Boosting and Oversampling for multiclass classification, BBO)方法[25],多元化纠错输出编码(Diversified Error Correcting Output Codes, DECOC)方法[99],多元化一对一(Diversified One‑Vs.‑One, DOVO)方法[100]。其中:OVO、OVA、A&O、DOVO、DECOC方法是基于不同思想的分解方法;OVO_SMOTE和OVA_SMOTE是基于数据级的方法;FuzzyImb是基于代价敏感的方法;OAHO是通过缓解数据的不平衡性来提高分类器对少数类识别度的方法,可以认为是一种算法级方法;BBO是结合数据级方法的集成方法。
实验过程中采用的分类指标为:准确度、F、AUC、G‑mean、Kappa。其中,准确度以整体分类正确率为目标,是分类问题中最常用的指标;F指标更重视较小值,可以反映算法整体分类情况,实验过程中=1;AUC和G‑mean则是不平衡分类问题中常用的指标;Kappa则体现了分类模型的可信度。实验基于单机环境,以Windows 10为操作系统,Matlab 2018a为实验平台,采用5重交叉检验,独立运行20次,对运行结果取均值。
4.2 实验结果及分析
实验结果如表4~8所示,其中:最后一行代表方法在所有数据集上的平均值;加粗表示最优值;NaN表示空值,指该方法在分类过程中出现了将某一类完全分错的情况。
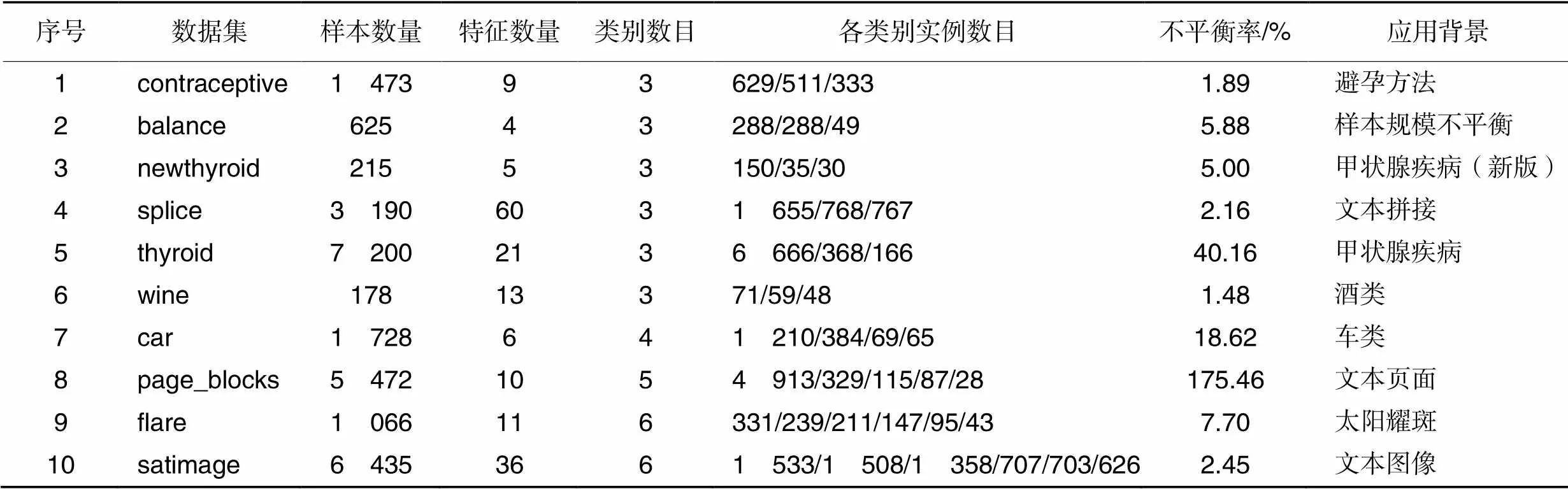
表3 实验数据集属性
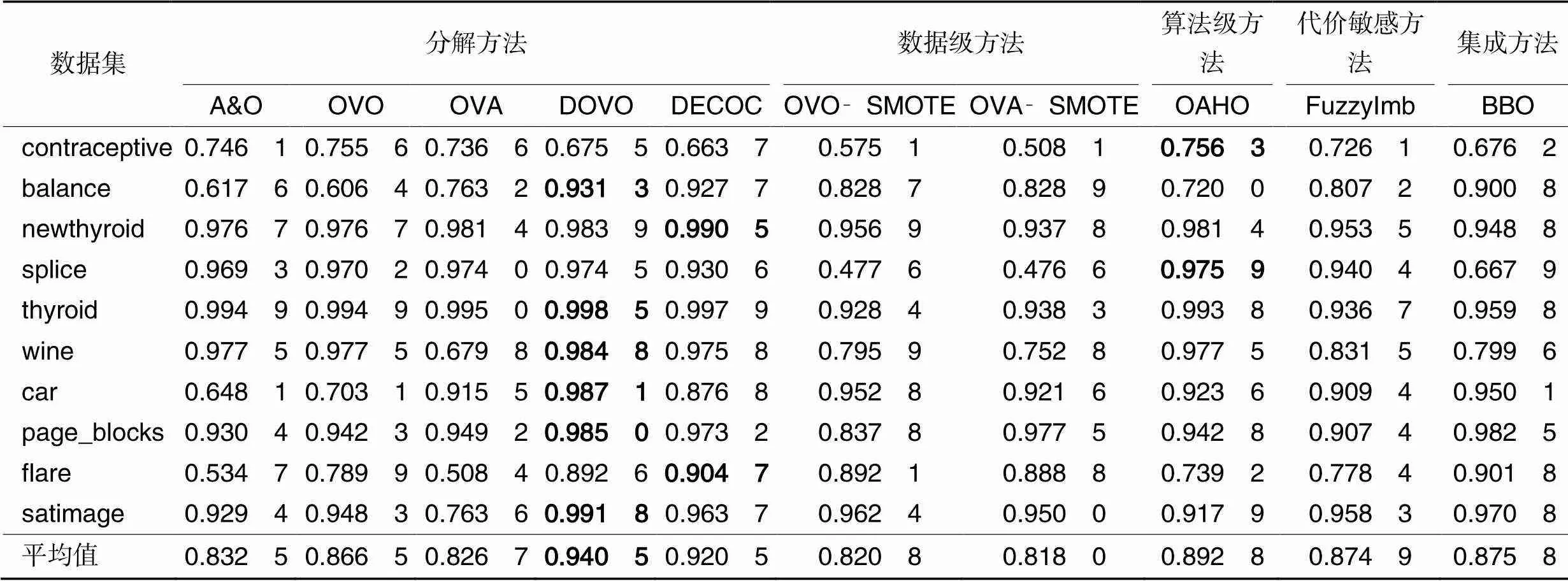
表4 典型方法在实验数据集上的准确度值
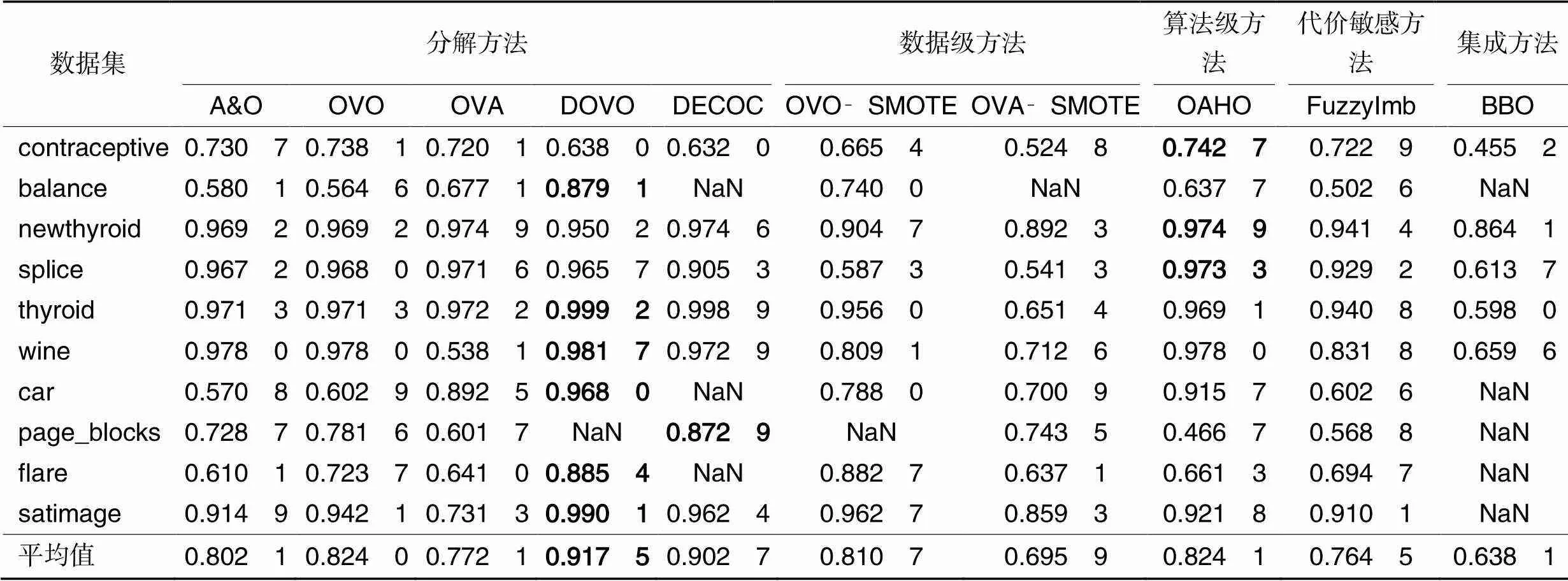
表5 典型方法在实验数据集上的F1值
分析表4可知:首先,DECOC和DOVO的平均值在0.9以上,其他8种方法的平均值在0.8~0.9,从统计学的角度分析可以认为DECOC和DOVO方法较其他8种方法性能更好,且在不平衡多分类数据集上可以获得优异的分类结果;其次,OVO和OVA方法的分类准确度比结合SMOTE方法的OVO‑SMOTE和OVA‑SMOTE的分类准确度更高,表明在多分类问题中简单采用SMOTE方法不一定会提升方法分类准确度,甚至会由于引入大量新合成的样本而影响方法分类性能;最后,从实验结果中可以看出,在contraceptive和splice两个数据集上,OAHO取得了最好的分类准确度,在newthyroid和flare两个数据集上,DECOC取得了最好的分类准确度,而在其他数据集上,即balance、thyroid、wine、car、page_blocks和satimage,DOVO方法取得了最好的分类准确度。由于DOVO方法与传统多分类方法采用固定的二分类器不同,它为每个类别对分别选择最合适的二分类器,说明选择良好的基分类器可以显著提升方法的分类性能。
从表5可以看出,在contraceptive、newthyroid和splice三个数据集上,OAHO的F1值最好;在page_blocks数据集上DECOC的F1值最好;在其他数据集上DOVO的F1值最好。从平均值看,DOVO和DECOC的结果最好,均在0.9以上,而其他8种方法的均值在0.6~0.9。
从表6、7可以看出,虽然AUC和G‑mean的最优值在各个方法上比较分散,但从AUC和G‑mean的平均值上可以看出,DOVO方法取得了最好的均值结果,与次优值OVO方法和DECOC方法的结果分别相差0.01和0.06。结合表4~7可以看出,基于OVO改进的DOVO方法在处理不平衡数据集上较其他几种对比方法性能更好。
从表8可以看出,DOVO和OAHO的Kappa均值比其他8种方法的Kappa均值更高,能达到0.8以上,表明DOVO和OAHO训练出的模型更加可靠;此外,所有方法的Kappa均值都在0.4以上,表明这些方法训练出的模型基本都可以达到可信程度。结合表4~7的分类结果,可以得出结论:DOVO方法不仅分类效果明显,而且分类模型可信度较高,因此可以认为DOVO方法是一种优异的不平衡多分类方法。
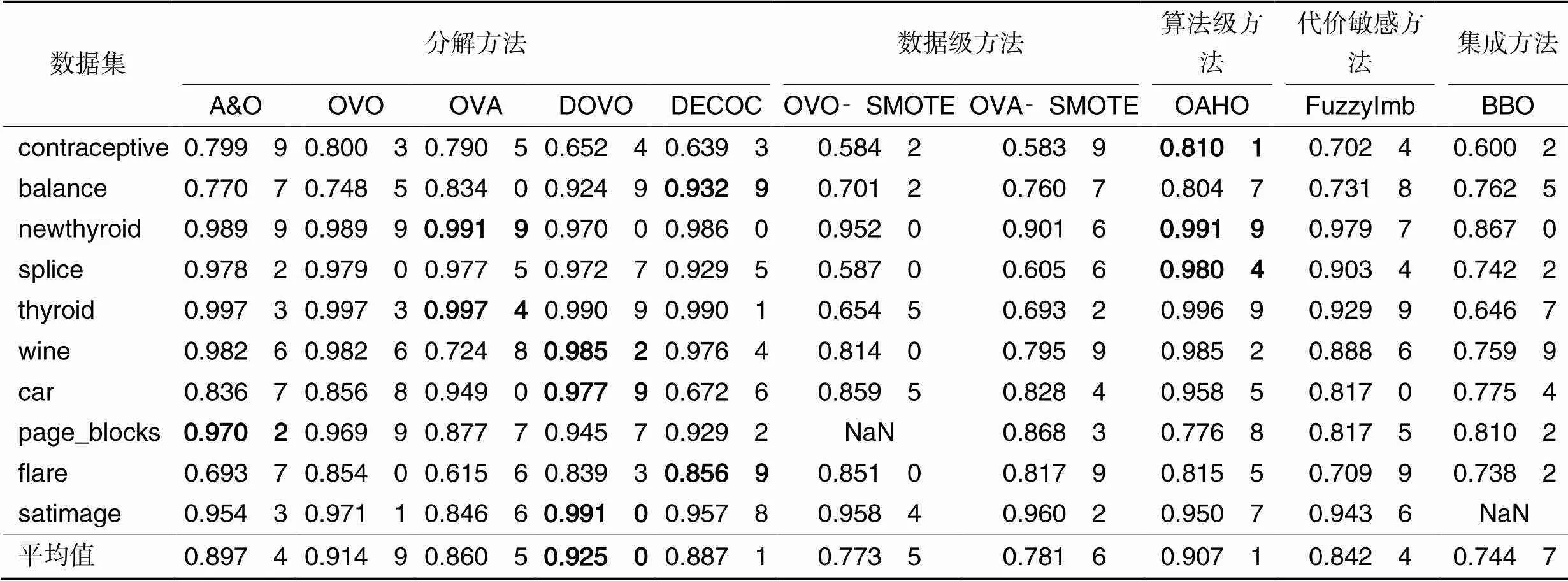
表6 典型方法在实验数据集上的AUC值
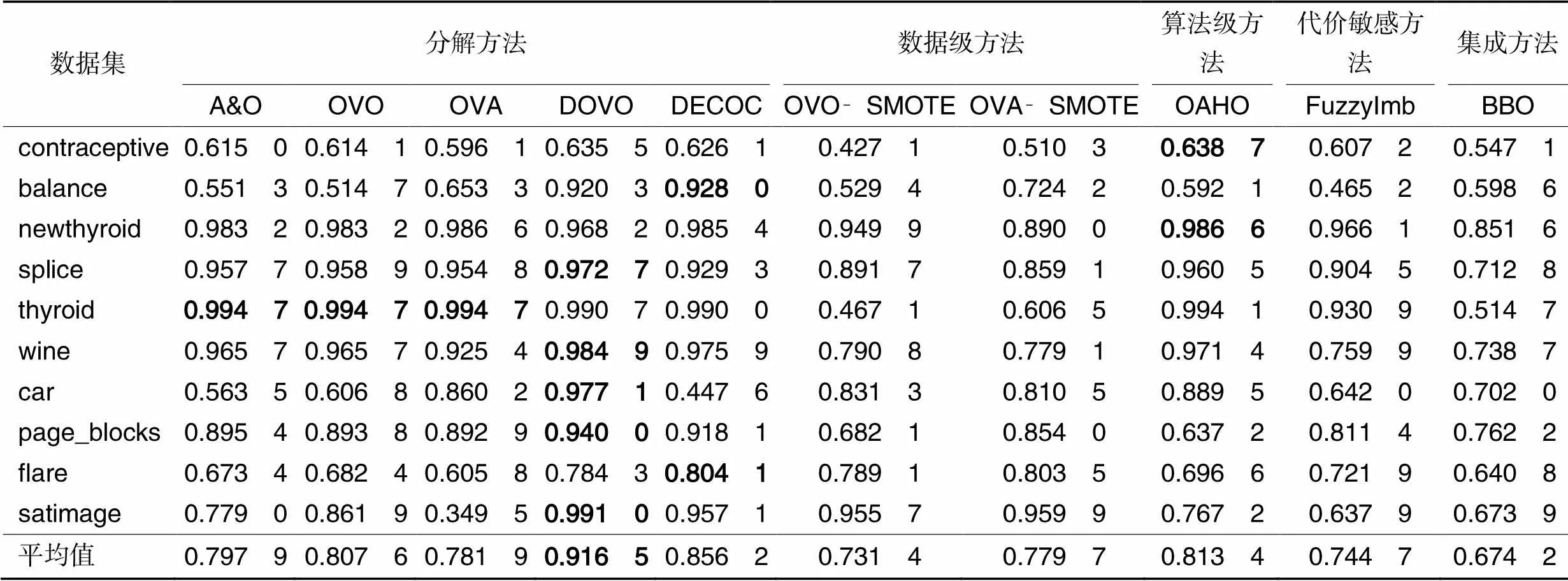
表7 典型方法在实验数据集上的G‑mean值
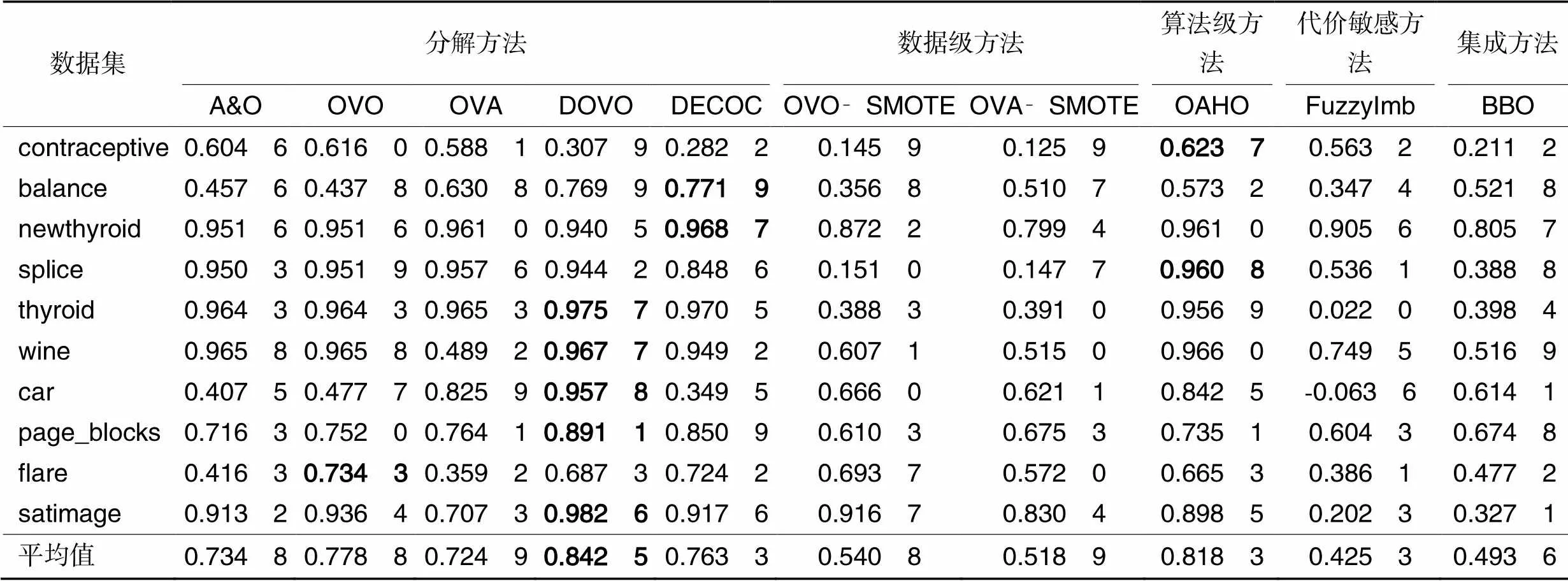
表8 典型方法在实验数据集上的Kappa值
下面从四个方面对实验结果进行总结:
1)分解方法DOVO的性能总体上要优于其他几种对比方法,除了Kappa均值为0.842 5,其他四种指标的结果均值均在0.9以上,在5个指标上分别高于次优值0.02、0.015、0.01、0.06、0.025,表明在不平衡多分类问题中,提升每个二分类器的性能可显著提高最终的分类结果。
2)通过比较对比方法的结果,可以发现在实验条件下,OVO在5个评价指标上均要优于OVA,这可能是由于OVA模型人为引入不平衡造成的,因此,可以认为在处理不平衡多分类问题时采用OVO方法比OVA方法更合适。
3)分解方法A&O在5个指标上均要优于OVA,但不如OVO,表明基于OVO和OVA两者结合的改进方法的性能并不一定能同时优于两种基模型。算法级方法OAHO在5个指标上的结果均优于基模型OVA,表明OAHO采用一对后序的策略相较OVA一对所有的策略可以更好地缓解类别之间的不平衡,通过利用较平衡的数据集训练分类模型,进而提升方法对不平衡数据集的分类性能。
4)数据级方法OVO‑SMOTE和OVA‑SMOTE的性能要低于分解方法OVO和OVA,表明在不平衡多分类问题中简单采用分解策略和SMOTE过采样方法的结合并不能显著提高方法的分类性能,甚至还会因为引入了大量合成样本影响了原始数据分布,造成方法分类性能的下降。
5 结语
不平衡多分类问题具有广泛的研究意义和应用价值,是机器学习领域重要的研究内容。本文从分解方法、即席方法以及不平衡多分类评价指标三个层面进行了总结。首先介绍了基于“一对一”架构的分解方法和基于“一对多”架构的分解方法,并从数据级方法、算法级方法、代价敏感方法、集成方法和基于深度网络的方法五个角度系统地阐述了即席方法;然后描述了不平衡多分类领域的评价指标;最后通过实验对比了几种典型的不平衡多分类方法。
近些年关于不平衡多分类的研究虽然得到了重视和发展,但仍存在一些具有挑战性的问题亟待解决:目前关于如何进行过采样和欠采样的方法很多,但是关于样本采样率的研究相对较少,在利用数据重采样技术平衡数据集的过程中,具体采样多少,如何获得最优采样率至关重要,但目前采取的方法主要是依靠人为经验或者优化算法,缺少一定的理论支持;数据不平衡分类问题的根本难点在于数据的分布,不同类别间数据分布越复杂,分类器的训练越困难,尤其是在多分类问题中,类别数目的增加直接导致类别关系的多样化,增加了整个问题的难度,但是目前的研究主要集中在如何在数量上平衡数据样本,而关于数据分布的研究则相对较少;近些年由于集成方法表现优异,相关学者提出了大量基于集成方法的分类算法,但是在集成分类器中如何合理地设置基分类器的权重系数仍是一个开放性问题;此外,如何将数据级方法、算法级方法和代价敏感方法与集成方法更好地结合起来,共同解决不平衡多分类问题也是今后需要进一步研究的问题。
[1] SHILASKAR S, GHATOL A. Diagnosis system for imbalanced multi‑minority medical dataset[J]. Soft Computing, 2019, 23(13): 4789-4799.
[2] LANGO M. Tackling the problem of class imbalance in multi‑class sentiment classification: an experimental study[J]. Foundations of Computing and Decision Sciences, 2019, 44(2): 151-178.
[3] KRAWCZYK B, McINNES B T, CANO A. Sentiment classification from multi‑class imbalanced twitter data using binarization[C]// Proceedings of the 2017 International Conference on Hybrid Artificial Intelligence Systems, LNCS 10334. Cham: Springer, 2017: 26-37.
[4] KULKARNI R, VINTRÓ M, KAPETANAKIS S, et al. Performance comparison of popular text vectorising models on multi‑class email classification[C]// Proceedings of the 2018 SAI Intelligent Systems Conference, AISC 868. Cham: Springer, 2019: 567-578.
[5] DORADO‑MORENO M, GUTIÉRREZ P A, CORNEJO‑BUENO L, et al. Ordinal multi‑class architecture for predicting wind power ramp events based on reservoir computing[J]. Neural Processing Letters, 2020, 52(1): 57-74.
[6] YUAN Y L, HUO L W, HOGREFE D. Two layers multi‑class detection method for network intrusion detection system[C]// Proceedings of the 2017 IEEE Symposium on Computers and Communications. Piscataway: IEEE, 2017: 767-772.
[7] BENCHAJI I, DOUZI S, EL OUAHIDI B. Using genetic algorithm to improve classification of imbalanced datasets for credit card fraud detection[C]// Proceedings of the 2019 International Conference on Advanced Information Technology, Services and Systems, LNNS 66. Cham: Springer, 2019: 220-229.
[8] 李艳霞,柴毅,胡友强,等. 不平衡数据分类方法综述[J]. 控制与决策, 2019, 34(4): 673-688.(LI Y X, CHAI Y, HU Y Q, et al. Review of imbalanced data classification methods[J]. Control and Decision, 2019, 34(4): 673-688.)
[9] SAHARE M, GUPTA H. A review of multi‑class classification for imbalanced data[J]. International Journal of Advanced Computer Research, 2012, 2(5): 160-164.
[10] TANHA J, ABDI Y, SAMADI N, et al. Boosting methods for multi‑class imbalanced data classification: an experimental review[J]. Journal of Big Data, 2020, 7: No.70.
[11] KAUR H, PANNU H S, MALHI A K. A systematic review on imbalanced data challenges in machine learning[J]. ACM Computing Surveys, 2019, 52(4): No.79.
[12] KRAWCZYK B, KOZIARSKI M, WOŹNIAK M. Radial‑based oversampling for multiclass imbalanced data classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(8): 2818-2831.
[13] ZHANG Z L, KRAWCZYK B, GARCÌA S, et al. Empowering one‑vs‑one decomposition with ensemble learning for multi‑class imbalanced data[J]. Knowledge‑Based Systems, 2016, 106: 251-263.
[14] RODRÍGUEZ J J, DÍEZ‑PASTOR J F, ARNAIZ‑GONZÁLEZ Á, et al. Random balance ensembles for multiclass imbalance learning[J]. Knowledge‑Based Systems, 2020, 193: No.105434.
[15] ŻAK M, WOŹNIAK M. Performance analysis of binarization strategies for multi‑class imbalanced data classification[C]// Proceedings of the 2020 International Conference on Computational Science, LNCS 12140. Cham: Springer, 2020: 141-155.
[16] ZHANG Z L, LUO X G, GONZÁLEZ S, et al. DRCW‑ASEG: One‑versus‑one distance‑based relative competence weighting with adaptive synthetic example generation for multi‑class imbalanced datasets[J]. Neurocomputing, 2018, 285: 176-187.
[17] LIANG L J, JIN T T, HUO M Y. Feature identification from imbalanced data sets for diagnosis of cardiac arrhythmia[C]// Proceedings of the 11th International Symposium on Computational Intelligence and Design. Piscataway: IEEE, 2018: 52-55.
[18] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over‑sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16: 321-357.
[19] LIU X Y, WU J X, ZHOU Z H. Exploratory undersampling for class‑imbalance learning[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2009, 39(2): 539-550.
[20] BARANDELA R, VALDOVINOS R M, SÁNCHEZ J S. New applications of ensembles of classifiers[J]. Pattern Analysis and Applications, 2003, 6(3): 245-256.
[21] WANG S, YAO X. Diversity analysis on imbalanced data sets by using ensemble models[C]// Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Data Mining. Piscataway: IEEE, 2009: 324-331.
[22] SEIFFERT C, KHOSHGOFTAAR T M, HULSE J van, et al. RUSBoost: a hybrid approach to alleviating class imbalance[J]. IEEE Transactions on Systems, Man, and Cybernetics — Part A: Systems and Humans, 2010, 40(1): 185-197.
[23] CHAWLA N V, LAZAREVIC A, HALL L O, et al. SMOTEBoost: improving prediction of the minority class in boosting[C]// Proceedings of the 2003 European Conference on Principles of Data Mining and Knowledge Discovery, LNCS 2838. Berlin: Springer, 2003: 107-119.
[24] JEGIERSKI H, SAGANOWSKI S. An “outside the box” solution for imbalanced data classification[J]. IEEE Access, 2020, 8: 125191-125209.
[25] SEN A, ISLAM M M, MURASE K, et al. Binarization with boosting and oversampling for multiclass classification[J]. IEEE Transactions on Cybernetics, 2016, 46(5): 1078-1091.
[26] JIANG C Q, LIU Y, DING Y, et al. Capturing helpful reviews from social media for product quality improvement: a multi‑class classification approach[J]. International Journal of Production Research, 2017, 55(12): 3528-3541.
[27] SÁEZ J A, GALAR M, LUENGO J, et al. Analyzing the presence of noise in multi‑class problems: alleviating its influence with the One‑vs‑One decomposition[J]. Knowledge and Information Systems, 2014, 38(1): 179-206.
[28] MURPHEY Y L, WANG H X, OU G B, et al. OAHO: an effective algorithm for multi‑class learning from imbalanced data[C]// Proceedings of the 2007 International Joint Conference on Neural Networks. Piscataway: IEEE, 2007: 406-411.
[29] HAN H, WANG W Y,MAO B H. Borderline‑SMOTE: a new over‑sampling method in imbalanced data sets learning[C]// Proceedings of the 2005 International Conference on Intelligent Computing, LNCS 3644. Berlin: Springer, 2005: 878-887.
[30] HE H B, BAI Y, GARCIA E A, et al. ADASYN: adaptive synthetic sampling approach for imbalanced learning[C]// Proceedings of the 2008 IEEE International Joint Conference on Neural Network (IEEE World Congress on Computational Intelligence). Piscataway: IEEE, 2008: 1322-1328.
[31] GALAR M, FERNÁNDEZ A, BARRENECHEA E, et al. DRCW‑OVO: distance‑based relative competence weighting combination for One‑vs‑One strategy in multi‑class problems[J]. Pattern Recognition, 2015, 48(1): 28-42.
[32] ZHANG J H, CUI X Q, LI J R, et al. Imbalanced classification of mental workload using a cost‑sensitive majority weighted minority oversampling strategy[J]. Cognition, Technology and Work, 2017, 19(4): 633-653.
[33] PATIL S S, SONAVANE S P. Enriched over_sampling techniques for improving classification of imbalanced big data[C]// Proceedings of the IEEE 3rd International Conference on Big Data Computing Service and Applications. Piscataway: IEEE, 2017: 1-10.
[34] RIVERA W, ASPAROUHOV O. Safe level OUPS for improving target concept learning in imbalanced data sets[C]// Proceedings of the 2015 IEEE SoutheastCon. Piscataway: IEEE, 2015: 1-8.
[35] MATHEW J, PANG C K, LUO M, et al. Classification of imbalanced data by oversampling in kernel space of support vector machines[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(9): 4065-4076.
[36] ZAREAPOOR M, SHAMSOLMOALI P, YANG J. Oversampling adversarial network for class‑imbalanced fault diagnosis[J]. Mechanical Systems and Signal Processing, 2021, 149: No.107175.
[37] XIA M, LI T, XU L, et al. Fault diagnosis for rotating machinery using multiple sensors and convolutional neural networks[J]. IEEE‑ASME Transactions on Mechatronics, 2018, 23(1): 101-110.
[38] LIU H, ZHOU J Z, XU Y H, et al. Unsupervised fault diagnosis of rolling bearings using a deep neural network based on generative adversarial networks[J]. Neurocomputing, 2018, 315: 412-424.
[39] YU H Y, CHEN C Y, YANG H M. Two‑stage game strategy for multiclass imbalanced data online prediction[J]. Neural Processing Letters, 2020, 52(3): 2493-2512.
[40] LEE J, PARK K. GAN‑based imbalanced data intrusion detection system[J]. Personal and Ubiquitous Computing, 2021, 25(1): 121-128.
[41] SHAMSOLMOALI P, ZAREAPOOR M, SHEN L L, et al. Imbalanced data learning by minority class augmentation using capsule adversarial networks[J]. Neurocomputing, 2020, 459: 481-493.
[42] POUYANFAR S, CHEN S C, SHYU M L. Deep spatio‑temporal representation learning for multi‑class imbalanced data classification[C]// Proceedings of the 2018 IEEE International Conference on Information Reuse and Integration. Piscataway: IEEE, 2018: 386-393.
[43] LIU Q J, MA G J, CHENG C. Data fusion generative adversarial network for multi‑class imbalanced fault diagnosis of rotating machinery[J]. IEEE Access, 2020, 8: 70111-70124.
[44] YANG X B, KUANG Q M, ZHANG W S, et al. AMDO: an over‑sampling technique for multi‑class imbalanced problems[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(9): 1672-1685.
[45] ABDI L, HASHEMI S. To combat multi‑class imbalanced problems by means of over‑sampling techniques[J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(1): 238-251.
[46] LI Q M, SONG Y J, ZHANG J, et al. Multiclass imbalanced learning with one‑versus‑one decomposition and spectral clustering[J]. Expert Systems with Applications, 2020, 147: No.113152.
[47] CHEN X T, ZHANG L, WEI X H, et al. An effective method using clustering‑based adaptive decomposition and editing‑based diversified oversamping for multi‑class imbalanced datasets[J]. Applied Intelligence, 2021, 51(4): 1918-1933.
[48] SANTOSO B, WIJAYANTO H, NOTODIPUTRO K A, et al. K‑Neighbor over‑sampling with cleaning data: a new approach to improve classification performance in data sets with class imbalance[J]. Applied Mathematical Sciences, 2018, 12(10): 449-460.
[49] KOZIARSKI M, WOŹNIAK M, KRAWCZYK B. Combined cleaning and resampling algorithm for multi‑class imbalanced data with label noise[J]. Knowledge‑Based Systems, 2020, 204: No.106223.
[50] WU Q, LIN Y P, ZHU T F, et al. HUSBoost: a hubness‑aware boosting for high‑dimensional imbalanced data classification[C]// Proceedings of the 2019 International Conference on Machine Learning and Data Engineering. Piscataway: IEEE, 2019: 36-41.
[51] RAYHAN F, AHMED S, MAHBUB A, et al. CUSBoost: cluster‑ based under‑sampling with boosting for imbalanced classification[C]// Proceedings of the 2nd International Conference on Computational Systems and Information Technology for Sustainable Solution. Piscataway: IEEE, 2017: 1-5.
[52] LI Y, WANG J, WANG S G,et al. Local dense mixed region cutting + global rebalancing: a method for imbalanced text sentiment classification[J]. International Journal of Machine Learning and Cybernetics, 2019, 10(7): 1805-1820.
[53] LI L S, HE H B, LI J. Entropy‑based sampling approaches for multi‑class imbalanced problems[J]. IEEE Transactions on Knowledge and Data Engineering, 2020, 32(11): 2159-2170.
[54] GALAR M, FERNÁNDEZ A, BARRENECHEA E, et al. EUSBoost: enhancing ensembles for highly imbalanced data‑sets by evolutionary undersampling[J]. Pattern Recognition, 2013, 46(12): 3460-3471.
[55] GARCÍA S, HERRERA F. Evolutionary undersampling for classification with imbalanced datasets: proposals and taxonomy[J]. Evolutionary Computation, 2009, 17(3): 275-306.
[56] FERNANDES E R Q, DE CARVALHO A C P L F. Evolutionary inversion of class distribution in overlapping areas for multi‑class imbalanced learning[J]. Information Sciences, 2019, 494: 141-154.
[57] DEB K, PRATAP A, AGARWAL S, et al. A fast and elitist multiobjective genetic algorithm: NSGA‑Ⅱ[J]. IEEE Transactions on Evolutionary Computation, 2002, 6(2): 182-197.
[58] GOLDBERG D E. Genetic Algorithms in Search, Optimization, and Machine Learning[M]. Boston: Addison‑Wesley Professional, 1989: 95-99.
[59] LIU Z, TANG D Y, CAI Y M, et al. A hybrid method based on ensemble WELM for handling multi class imbalance in cancer microarray data[J]. Neurocomputing, 2017, 266: 641-650.
[60] SARIKAYA A, KILIÇ B G. A class‑specific intrusion detection model: hierarchical multi‑class IDS model[J]. SN Computer Science, 2020, 1(4): No.202.
[61] LI J T, WANG Y Y, SONG X K, et al. Adaptive multinomial regression with overlapping groups for multi‑class classification of lung cancer[J]. Computers in Biology and Medicine, 2018, 100: 1-9.
[62] DUFRENOIS F. A one‑class kernel fisher criterion for outlier detection[J]. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(5): 982-994.
[63] BELLINGER C, SHARMA S, JAPKOWICZ N. One‑class versus binary classification: which and when?[C]// Proceedings of the 11th International Conference on Machine Learning and Applications. Piscataway: IEEE, 2012: 102-106.
[64] HEMPSTALK K, FRANK E. Discriminating against new classes: one‑class versus multi‑class classification[C]// Proceedings of the 2008 Australasian Joint Conference on Artificial Intelligence, LNCS 5360. Berlin: Springer, 2008: 325-336.
[65] KRAWCZYK B, WOŹNIAK M, HERRERA F. On the usefulness of one‑class classifier ensembles for decomposition of multi‑class problems[J]. Pattern Recognition, 2015, 48(12): 3969-3982.
[66] PÉREZ‑SÁNCHEZ B, FONTENLA‑ROMERO O, SÁNCHEZ‑ MAROÑO N. Selecting target concept in one‑class classification for handling class imbalance problem[C]// Proceedings of the 2015 International Joint Conference on Neural Networks. Piscataway: IEEE, 2015: 1-8.
[67] KRAWCZYK B, GALAR M, WOŹNIAK M, et al. Dynamic ensemble selection for multi‑class classification with one‑class classifiers[J]. Pattern Recognition, 2018, 83: 34-51.
[68] GAO L, ZHANG L, LIU C, et al. Handling imbalanced medical image data: a deep‑learning‑based one‑class classification approach[J]. Artificial Intelligence in Medicine, 2020, 108: No.101935.
[69] 万建武,杨明. 代价敏感学习方法综述[J]. 软件学报, 2020, 31(1): 113-136.(WAN J W, YANG M. Survey on cost‑sensitive learning method[J]. Journal of Software, 2020, 31(1): 113-136.)
[70] ZHANG Z L, LUO X G, GARCÍA S, et al. Cost‑sensitive back‑ propagation neural networks with binarization techniques in addressing multi‑class problems and non‑competent classifiers[J]. Applied Soft Computing, 2017, 56: 357-367.
[71] LING C X, SHENG V S. Cost‑sensitive learning and the class imbalance problem[M]// Encyclopedia of Machine Learning. Boston: Springer, 2010: 171, 231-235.
[72] DOMINGOS P. MetaCost: a general method for making classifiers cost‑sensitive[C]// Proceedings of the 5th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 1999: 155-164.
[73] IRANMEHR A, MASNADI‑SHIRAZI H, VASCONCELOS N. Cost‑sensitive support vector machines[J]. Neurocomputing, 2019, 343: 50-64.
[74] GU B, SHENG V S, TAY K Y, et al. Cross validation through two‑dimensional solution surface for cost‑sensitive SVM[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1103-1121.
[75] ZHANG C, TAN K C, LI H Z, et al. A cost‑sensitive deep belief network for imbalanced classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(1): 109-122.
[76] LANGO M, STEFANOWSKI J. Multi‑class and feature selection extensions of roughly balanced bagging for imbalanced data[J]. Journal of Intelligent Information Systems, 2018, 50(1): 97-127.
[77] HIDO S, KASHIMA H, TAKAHASHI Y. Roughly balanced bagging for imbalanced data[J]. Statistical Analysis and Data Mining, 2009, 2(5/6): 412-426.
[78] TAHERKHANI A, COSMA G, McGINNITY T M. AdaBoost‑ CNN: an adaptive boosting algorithm for convolutional neural networks to classify multi‑class imbalanced datasets using transfer learning[J]. Neurocomputing, 2020, 404: 351-366.
[79] DÍEZ‑PASTOR J F, RODRÍGUEZ J J, GARCÍA‑OSORIO C, et al. Random Balance: ensembles of variable priors classifiers for imbalanced data[J]. Knowledge‑Based Systems, 2015, 85: 96-111.
[80] FERNÁNDEZ‑BALDERA A, BUENAPOSADA J M, BAUMELA L. BAdaCost: multi‑class Boosting with costs[J]. Pattern Recognition, 2018, 79: 467-479.
[81] SCHWENKER F. Ensemble methods: foundations and algorithms [Book Review][J]. IEEE Computational Intelligence Magazine, 2013, 8(1): 77-79.
[82] JOHNSON J M, KHOSHGOFTAAR T M. Survey on deep learning with class imbalance[J]. Journal of Big Data, 2019, 6: No.27.
[83] RENDÓN E, ALEJO R, CASTORENA C, et al. Data sampling methods to deal with the big data multi‑class imbalance problem[J]. Applied Sciences, 2020, 10(4): No.1276.
[84] WILSON D L. Asymptotic properties of nearest neighbor rules using edited data[J]. IEEE Transactions on Systems, Man and Cybernetics, 1972, SMC‑2(3): 408-421.
[85] TOMEK I. Two modifications of CNN[J]. IEEE Transactions on Systems, Man and Cybernetics, 1976, SMC‑6(11): 769-772.
[86] RAGHUWANSHI B S, SHUKLA S. Generalized class‑specific kernelized extreme learning machine for multiclass imbalanced learning[J]. Expert Systems with Applications, 2019, 121: 244-255.
[87] RAGHUWANSHI B S, SHUKLA S. Class‑specific kernelized extreme learning machine for binary class imbalance learning[J]. Applied Soft Computing, 2018, 73: 1026-1038.
[88] MOSLEY L S D. A balanced approach to the multi‑class imbalance problem[D]. Ames, IA: Iowa State University, 2013: 15-25.
[89] SOKOLOVA M, LAPALME G. A systematic analysis of performance measures for classification tasks[J]. Information Processing and Management, 2009, 45(4): 427-437.
[90] MORTAZ E. Imbalance accuracy metric for model selection in multi‑class imbalance classification problems[J]. Knowledge‑ Based Systems, 2020, 210: No.106490.
[91] VIERA A J, GARRETT J M. Understanding interobserver agreement: the kappa statistic[J]. Family Medicine, 2005, 37(5): 360-363.
[92] WEI J M, YUAN X J, HU Q H, et al. A novel measure for evaluating classifiers[J]. Expert Systems with Applications, 2010, 37(5): 3799-3809.
[93] BRANCO P, TORGO L, RIBEIRO R P. Relevance‑based evaluation metrics for multi‑class imbalanced domains[C]// Proceedings of the 2017 Pacific‑Asia Conference on Knowledge Discovery and Data Mining, LNCS 10234. Cham: Springer, 2017: 698-710.
[94] GORODKIN J. Comparing two‑category assignments by a‑category correlation coefficient[J]. Computational Biology and Chemistry, 2004, 28(5/6): 367-374.
[95] MATTHEWS B W. Comparison of the predicted and observed secondary structure of T4 phage lysozyme[J]. Biochimica et Biophysica Acta (BBA) — Protein Structure, 1975, 405(2): 442-451.
[96] GARCÍA‑PEDRAJAS N, ORTIZ‑BOYER D. Improving multiclass pattern recognition by the combination of two strategies[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(6): 1001-1006.
[97] FERNÁNDEZ A, LÓPEZ V, GALAR M, et al. Analysing the classification of imbalanced data‑sets with multiple classes: Binarization techniques and ad‑hoc approaches[J]. Knowledge‑ Based Systems, 2013, 42: 97-110.
[98] RAMENTOL E, VLUYMANS S, VERBIEST N, et al. IFROWANN: imbalanced fuzzy‑rough ordered weighted average nearest neighbor classification[J]. IEEE Transactions on Fuzzy Systems, 2015, 23(5): 1622-1637.
[99] BI J J, ZHANG C S. An empirical comparison on state‑of‑the‑art multi‑class imbalance learning algorithms and a new diversified ensemble learning scheme[J]. Knowledge‑Based Systems, 2018, 158: 81-93.
[100] KANG S, CHO S, KANG P. Constructing a multi‑class classifier using one‑against‑one approach with different binary classifiers[J]. Neurocomputing, 2015, 149(Pt B): 677-682.
Survey on imbalanced multi‑class classification algorithms
LI Mengmeng1, LIU Yi1*, LI Gengsong1, ZHENG Qibin2, QIN Wei1, REN Xiaoguang1
(1,,100071,;2,100091,)
Imbalanced data classification is an important research content in machine learning, but most of the existing imbalanced data classification algorithms foucus on binary classification, and there are relatively few studies on imbalanced multi‑class classification. However, datasets in practical applications usually have multiple classes and imbalanced data distribution, and the diversity of classes further increases the difficulty of imbalanced data classification, so the multi‑class classification problem has become a research topic to be solved urgently. The imbalanced multi‑class classification algorithms proposed in recent years were reviewed. According to whether the decomposition strategy was adopted, imbalanced multi‑class classification algorithms were divided into decomposition methods and ad‑hoc methods. Furthermore, according to the different adopted decomposition strategies, the decomposition methods were divided into two frameworks: One Vs. One (OVO) and One Vs. All (OVA). And according to different used technologies, the ad‑hoc methods were divided into data‑level methods, algorithm‑level methods, cost‑sensitive methods, ensemble methods and deep network‑based methods. The advantages and disadvantages of these methods and their representative algorithms were systematically described, the evaluation indicators of imbalanced multi‑class classification methods were summarized, the performance of the representative methods were deeply analyzed through experiments, and the future development directions of imbalanced multi‑class classification were discussed.
imbalanced classification; multi‑class classification; imbalanced multi‑class classification; classification algorithm; machine learning
This work is partially supported by National Natural Science Foundation of China (61802426).
LI Mengmeng, born in 1992, M. S. candidate. Her research interests include data quality, evolutionary algorithms.
LIU Yi, born in 1990, Ph. D., research assistant. His research interests include robot operating system, data quality, evolutionary algorithms.
LI Gengsong, born in 1999, M. S. candidate. His research interests include big data, algorithm selection.
ZHENG Qibin, born in 1990, Ph. D., research assistant. His research interests include data engineering, data mining, machine learning.
QIN Wei, born in 1983, M. S., research assistant. His research interests include intelligent information system management.
REN Xiaoguang, born in 1986, Ph. D., associate research fellow. His research interests include robot operation system, high‑performance computing, numerical computation and simulation.
TP391
A
1001-9081(2022)11-3307-15
10.11772/j.issn.1001-9081.2021122060
2021⁃12⁃06;
2021⁃12⁃30;
2022⁃01⁃18。
国家自然科学基金资助项目(61802426)。
李蒙蒙(1992—),女,河北邯郸人,硕士研究生,主要研究方向:数据质量、演化算法;刘艺(1990—),男(回族),安徽蚌埠人,助理研究员,博士,主要研究方向:机器人操作系统、数据质量、演化算法;李庚松(1999—),男,湖南长沙人,硕士研究生,主要研究方向:大数据、算法选择;郑奇斌(1990—),男,甘肃兰州人,助理研究员,博士,主要研究方向:数据工程、数据挖掘、机器学习;秦伟(1983—),男,安徽阜阳人,助理研究员,硕士,主要研究方向:智能信息系统管理;任小广(1986—),男,湖北随州人,副研究员,博士,主要研究方向:机器人操作系统、高性能计算、数值计算和模拟。
