神经正切核K‑Means聚类
2022-11-30王梅宋晓晖刘勇许传海
王梅,宋晓晖,刘勇,许传海
神经正切核K‑Means聚类
王梅1,2,宋晓晖1,刘勇3,4*,许传海1
(1.东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318; 2.黑龙江省石油大数据与智能分析重点实验室(东北石油大学),黑龙江 大庆 163318; 3.中国人民大学 高瓴人工智能学院,北京 100872; 4.大数据管理与分析方法研究北京市重点实验室(中国人民大学),北京 100872)(∗通信作者电子邮箱liuyonggsai@ruc.edu.cn)
针对K‑Means聚类算法利用均值更新聚类中心,导致聚类结果受样本分布影响的问题,提出了神经正切核K‑Means聚类算法(NTKKM)。首先通过神经正切核(NTK)将输入空间的数据映射到高维特征空间,然后在高维特征空间中进行K‑Means聚类,并采用兼顾簇间与簇内距离的方法更新聚类中心,最后得到聚类结果。在car和breast‑tissue数据集上,对NTKKM聚类算法的准确率、调整兰德系数(ARI)及FM指数这3个评价指标进行统计。实验结果表明,NTKKM聚类算法的聚类效果以及稳定性均优于K‑Means聚类算法和高斯核K‑Means聚类算法。NTKKM聚类算法与传统的K‑Means聚类算法相比,准确率分别提升了14.9%和9.4%,ARI分别提升了9.7%和18.0%,FM指数分别提升了12.0%和12.0%,验证了NTKKM聚类算法良好的聚类性能。
神经正切核;K‑Means;核聚类;特征空间;核函数
0 引言
聚类算法是一种典型的无监督的机器学习方法,是利用样本的特征比较样本的相似性,并将具有相似属性的样本划分到同一类或簇中的算法[1-3]。聚类算法的目的是使每个类中的数据之间的相似度最大,不同类中的数据之间的相似度最小。聚类算法的应用十分广泛,主要在数据挖掘、信息检索和图像分割等方面发挥重要作用[4-6]。
为了在复杂多样的数据中提取人们所需的有价值的信息,研究人员不断改进聚类算法。学者们将核方法引入聚类中,提出了核聚类算法,并对核聚类算法展开了广泛而深入的研究。Girolami[7]和张莉等[8]的研究对核特征空间中的聚类问题有指导性意义;Ben‑Hur等[9]在基于高斯核的支持向量数据域描述(Support Vector Domain Description, SVDD)算法基础上拓展出无监督非参数型的聚类算法。核聚类在图像处理方面也有出色表现:徐小来等[10]采用基于核改进的模糊C‑均值(Fuzzy C‑Means,FCM)聚类算法,通过高斯核函数和欧氏距离分别对像素8‑邻域的灰度和空间信息进行建模,实现了图像的分割;杨飞等[11]提出了使用内核诱导距离取代欧氏距离的核函数FCM算法,提高了传统FCM算法处理噪声图像的能力。在多核聚类的研究方面:Xiang等[12]针对多核聚类方法在数据具有高缺值率时,易落入局部最优状态的问题提出了一种针对不完整数据的多核聚类(Absent Multiple Kernel Clustering , AMKC)方法;Liu等[13]提出了简单的多核K‑均值(Simple Multiple Kernel K‑Means, SimpleMKKM),它将广泛使用的监督核对齐准则推广到多核聚类中。在核聚类的其他研究方面:Liu等[14]研究了核K‑Means的统计特性并获得近乎最优的过度聚类风险界限,大幅提高了现有聚类风险分析中的最新界限。核聚类通过非线性映射增加了数据点线性可分的概率,即能较好地分辨、提取并放大有用的特征,从而实现更准确的聚类,算法收敛速度也较快。在经典聚类算法失效时,核聚类算法常常能得到较好的聚类结果[15];但学者们大多数使用浅层的核函数为基础进行研究,而浅层的核函数挖掘深层次信息时存在局限性。
Neal等[16]在1994年就提出了在无限宽度的神经网络下,具有参数为独立同分布的单层全连接神经网络等价于高斯过程(Gaussian Process, GP),揭示了无限宽的神经网络与核方法之间的联系。Lee等[17]和Matthews等[18]研究发现这些内核对应于无限宽的深度网络,参数都是随机选择的,只有顶层是通过梯度下降进行训练。近几年,Jacot等[19]研究表明参数化深层神经网络的训练与神经正切核(Neural Tangent Kernel, NTK)有关,一个正确地随机初始化的、足够宽的、由具有无穷小步长大小的梯度下降训练的深度神经网络和一个带有NTK的确定性核回归预测器是等效的。NTK在无限宽极限下趋于一个确定的核,而且在梯度下降的训练过程中保持不变。NTK不仅可用于全连接网络,还可用于其他各种神经网络结构。例如,在文献[20]中,研究人员将NTK拓展到卷积神经网络中,称为卷积神经正切核(Convolutional Neural Tangent Kernel, CNTK);王梅等[21]将神经正切核拓展到多核学习中,提出了一种基于神经正切核的多核学习方法,能增强多核学习方法的表示能力;Arora等[22]通过对比实验证明NTK比高斯核和低次多项式核在低数据任务中表现更佳。
NTK可以看作是一种复杂的多层次结构的神经网络,它相比浅层的核函数能更好地表示数据之间的关系,捕捉深层信息,进一步增加了数据点的线性可分的概率。因此本文提出了神经正切核K‑Means(Neural Tangent Kernel K‑Means, NTKKM)算法,经过NTK核处理后的数据集中的数据特征能够更好地突显出来,从而能够更好地聚类复杂数据。
1 核K‑Means聚类
核聚类的基本思想是利用Mercer核[23]把输入空间中的样本映射到高维特征空间中,在高维特征空间中得到更加理想的聚类效果,该方法是普适的。核K‑Means聚类算法在聚类的准确性、稳定性及健壮性等方面相比K‑Means聚类算法有一定程度的改进[24-25]。
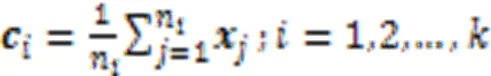
K‑Means目标函数为:
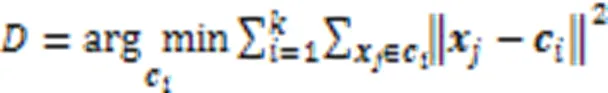
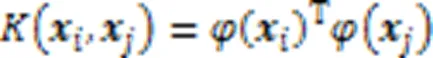
首先利用核函数计算出输入数据集的一个核矩阵,在高维空间中核K‑Means更新聚类中心为:
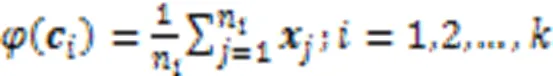
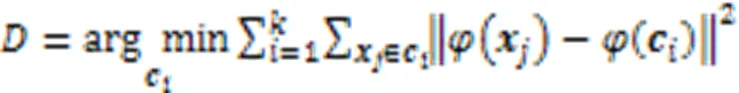
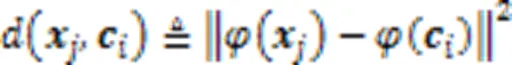
2 神经正切核K‑Means
2.1 神经正切核
采用无穷小学习率的梯度下降算法作为损失函数,即:
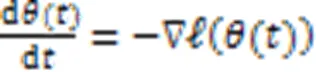
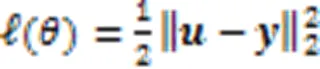
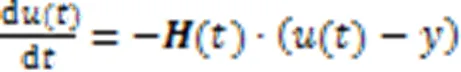
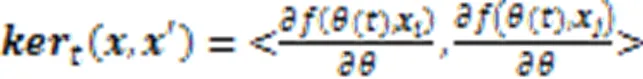
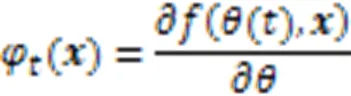
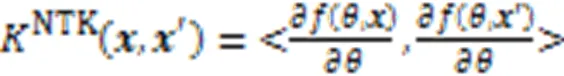
由上述可得,NTK相当于一个多层结构的神经网络,它与其他浅层核函数相比可以更好地表示复杂数据的特征。这为后面的聚类工作奠定了良好的基础。
2.2 NTKKM聚类算法
2.2.1算法的目标函数
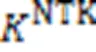
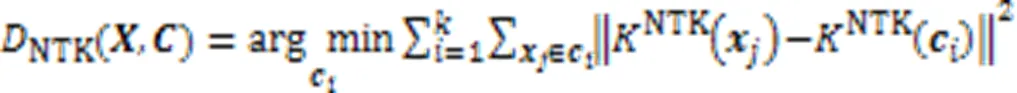
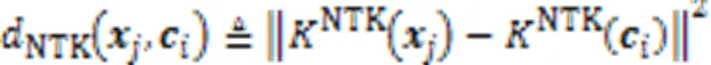
2.2.2聚类中心的初始
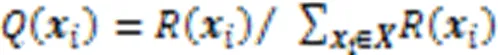
2.2.3聚类中心的更新
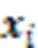
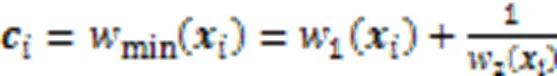
2.2.4本文算法
综上所述,NTKKM聚类算法如下所示:
end for
end for
end for
end while
2.2.5本文算法时间复杂度
3 实验与结果分析
3.1 实验数据
为验证本文算法能够在维度较高、数量较大以及聚类数目较多的数据集上有较好的表现,选取UCI数据集中4个在维度、数量及聚类数目等方面具有代表性的数据集进行实验,分别为红酒质量数据集(winequality‑red)、鸢尾花数据集(iris)、乳腺组织(breast‑tissue)以及汽车评估数据集(car),它们的详细信息如表1所示。
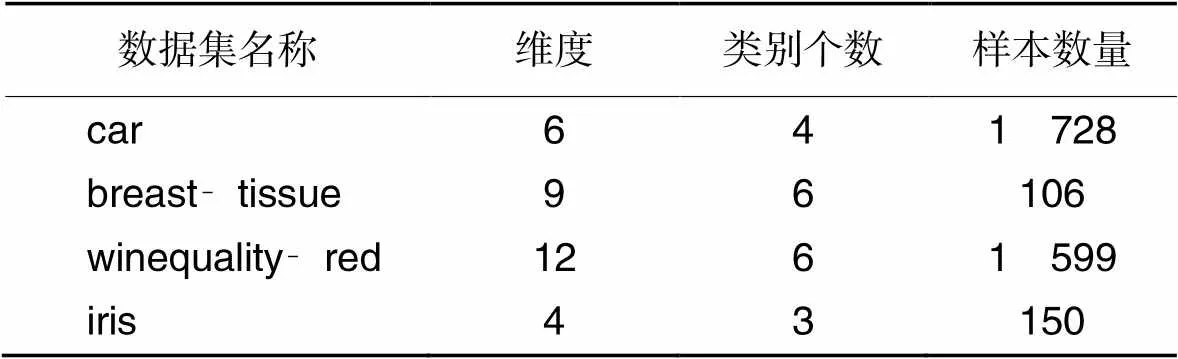
表1 实验数据集信息
3.2 实验方法及实验结果分析
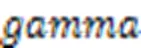
本文选用准确率(Accuracy, ACC)、调整兰德系数(Adjusted Rand Index, ARI)及FM指数(Fowlkes and Mallows Index, FMI)三个评价指标进行评价。三种算法在每个数据集分别运行20次,然后统计各评价指标平均结果。上述三个评价指标都是值越大、聚类效果越好[33]。
3.2.1根据评价指标分析实验结果
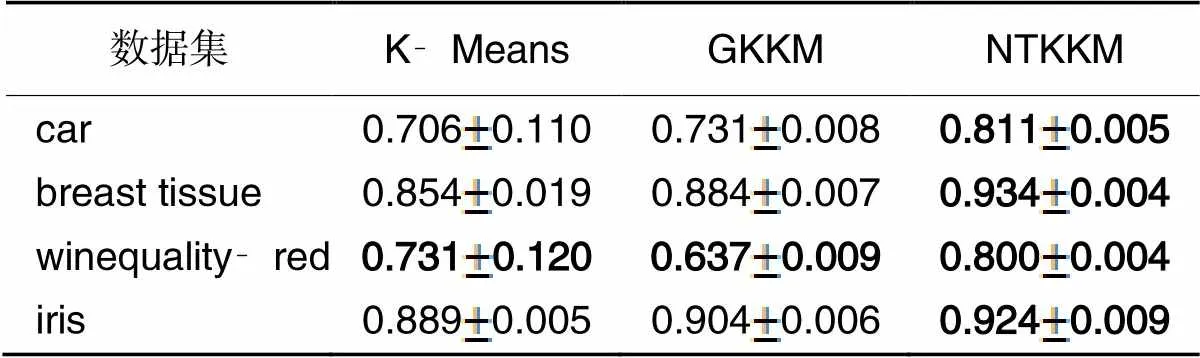
表2 三种算法的准确率
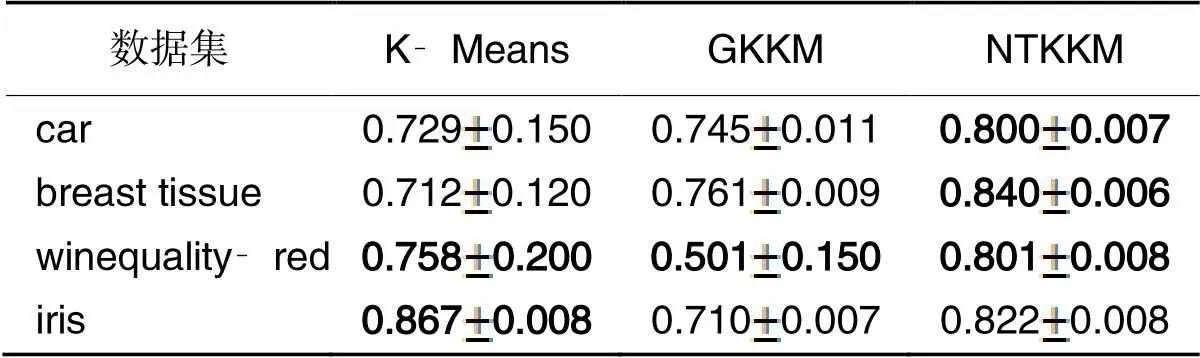
表3 三种算法的ARI
FMI作为衡量分类效果的标准,是精确率(Precision)和召回率(Recall)的几何平均值,取值范围为[0,1]。精确率指模型判为正的所有样本中有多少是真正的正样本;召回率指所有正样本有多少被模型判为正样本。精确率和召回率分别从局部和全局考虑分类效果。三种算法在每个数据集上FMI的统计结果如表4所示。由表4可知,NTKKM聚类算法精确率和召回率的几何平均数的值高于对比算法,说明NTKKM聚类算法分类效果更优。特别是在breast‑tissue、car以及winequality‑red数据集上,NTKKM聚类算法的FMI有显著提升,比K‑Means分别提升了12.0%、12.0%及20.0%。
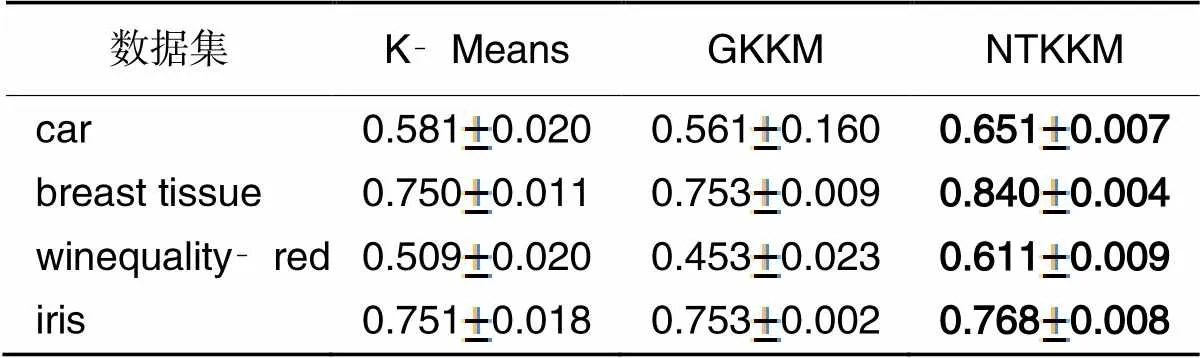
表4 三种算法精确率和召回率的几何平均数
3.2.2根据数据集特征分析实验结果
本节根据数据集的特征对NTKKM聚类算法的聚类性能进行分析。实验选用的数据集特征包括样本维度、类别个数以及样本数量,评价指标为准确率。
随着样本维度的增加,三种聚类算法准确率的变化情况如图1所示,在NTKKM聚类算法聚类的准确率都优于对比的两种算法的前提下,NTKKM聚类算法相较于K‑Means聚类算法在car、breast‑tissue以及winequality‑red数据集上准确率分别提升了14.9%、9.4%、9.4%及3.9%,在维度较低的iris数据集上准确率仅提升3.9%,说明了NTKKM聚类聚类算法在维度较高的数据集合上的聚类效果更佳。
随着聚类个数的增加,三种聚类算法准确率的变化情况如图2所示,可以明显看到在聚类个数相对较少的iris数据集上,NTKKM聚类算法的准确率较其余两个对比算法提升不明显,但在聚类个数较多的数据集car、breast‑tissue以及winequality‑red上,NTKKM聚类算法的聚类性能相较于经典的K‑Means聚类算法和GKKM聚类算法有显著提高。
随着样本数量的增加,三种聚类算法准确率的变化情况如图3所示,NTKKM在处理样本数量较多数据集winequality‑red和car上,聚类准确性明显优于对比算法。

图1 不同维度下三种算法的准确率
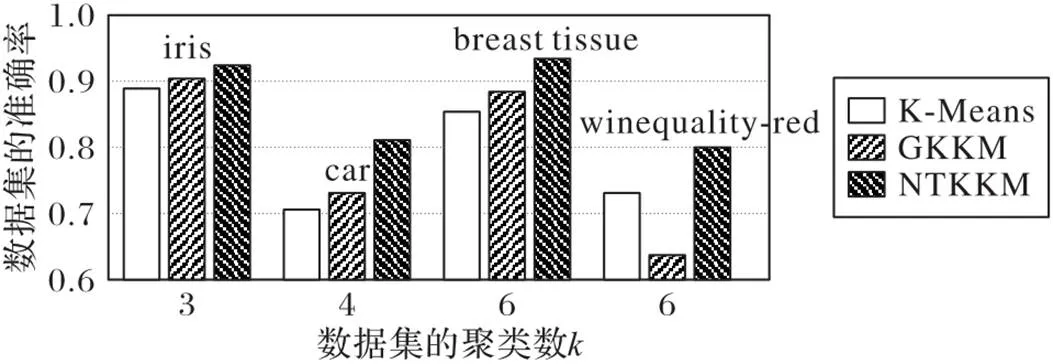
图2 不同聚类个数下三种算法的准确率

图3 不同样本数量下三种算法的准确率
3.2.3聚类结果图
使用K‑Means聚类算法、GKKM聚类算法以及NTKKM聚类算法分别对iris和breast‑tissue数据集进行聚类,结果图如图4、5所示。
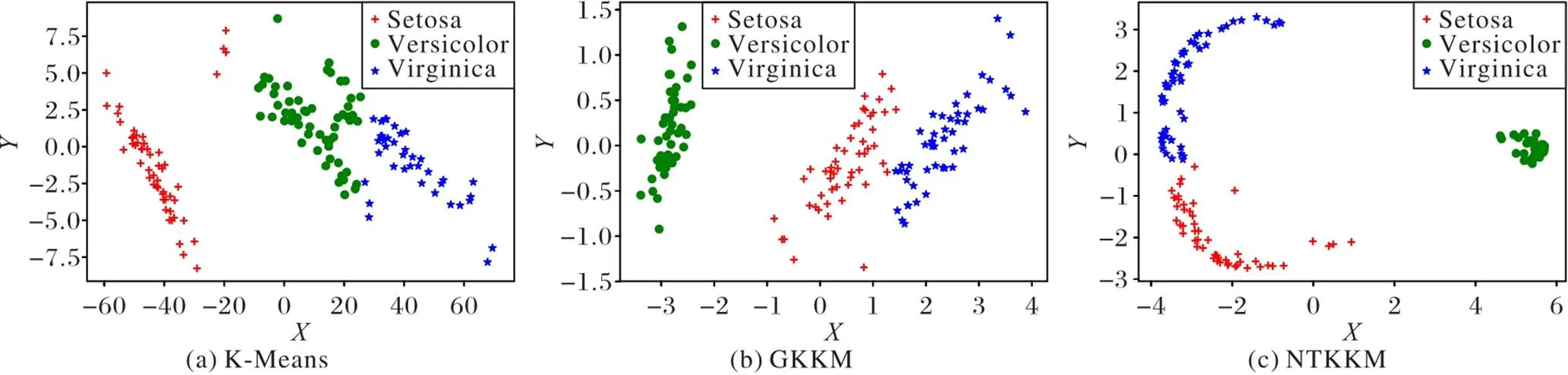
图4 在iris数据集上三种算法的聚类效果图
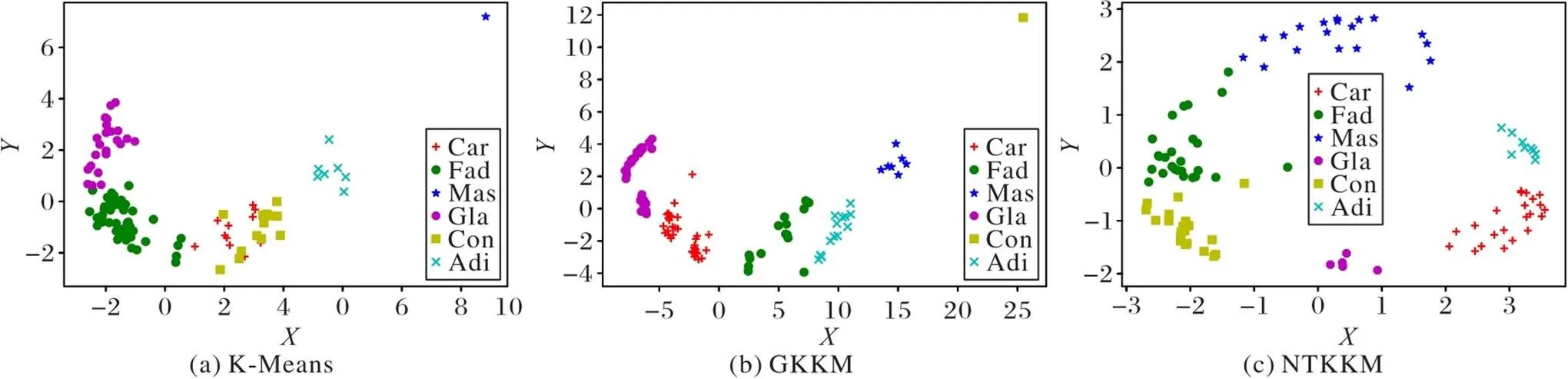
图5 在breast‑tissue数据集上三种算法的聚类效果图
由图4、5分析可知,传统的K‑Means聚类算法没有对数据进行处里,数据点的分布十分密集不易聚类;GKKM聚类算法通过高斯核将数据进行映射后进行聚类,通过图4(b)和图5(b)可以看出,浅层的高斯核对数据的表达能力较弱,未能充分表达出数据之间的相关性,因此,GKKM聚类效果并不理想;而NTKKM聚类算法通过神经正切核将数据集进行高维映射后,充分挖掘数据之间的联系,从图4(c)和图5(c)可以看出,原始空间中分布紧密的数据被映射到高维特征空间后数据之间的分布发生了改变,增加了数据之间的可分性,因此,能够得到较好的聚类效果。
综上所述,NTKKM聚类算法与传统的K‑Means聚类算法和GKKM聚类算法相比有更好的聚类效果和更强的稳定性,并且在维度较高、分类数目较多以及样本数量较多的数据集上表现更好。
4 结语
本文基于核聚类的基本思想提出了一种神经正切核K‑Means的聚类算法。首先使用NTK对数据集进行映射,挖掘数据之间在低维空间未显示出的特征,同时对K‑Means聚类算法进行改进,最后在高维空间中对数据点聚类。相较于传统的K‑Means聚类算法和浅层核K‑Means,NTKKM聚类算法有更好的表示能力和更强的聚类效果。实验结果表明,本文提出的NTKKM聚类算法在维度较高、分类数目较多以及聚类数量较多的数据集上的聚类结果较好,稳定性也更强,能够更好地表达数据的特征。
基于以上分析,NTKKM聚类算法也适用于图像聚类。图像聚类是将图像划分成各具特征或者是某种特性的区域,实现对图像的精准分割,从而达到对特定实物识别和检测的目的。由于NTK核具有多层次的网络结构,因此NTK在对数据集进行高维映射时所需要时间较长。因此,下一步需要解决的问题是减少其计算时间,以及将NTKKM聚类算法拓展到图像聚类应用中。
[1] FAHIM A M, SALEM A M, TORKEY F A, et al. An efficient enhanced‑means clustering algorithm[J]. Journal of Zhejiang University — SCIENCE A (Applied Physics and Engineering), 2006, 7(10): 1626-1633.
[2] 汪敏,武禹伯,闵帆. 基于多种聚类算法和多元线性回归的多分类主动学习算法[J]. 计算机应用, 2020, 40(12):3437-3444.(WANG M, WU Y B, MIN F. Multi‑category active learning algorithm based on multiple clustering algorithms and multiple linear regression[J]. Journal of Computer applications, 2020, 40(12):3437-3444.)
[3] LAWRENCE L O. A Primer on Cluster Analysis by James C. Bezdck[J]. IEEE Systems, Man, and Cybernetics Magazine, 2018, 4(1):48-50.
[4] 于佐军,秦欢. 基于改进蜂群算法的K‑means算法[J]. 控制与决策, 2018, 33(1):181-185.(YU Z J, QIN H. K‑means algorithm based on improved artificial bee swarm algorithm[J]. Control and Decision, 2018, 33(1):181-185.)
[5] 覃华,詹娟娟,苏一丹. 基于概率无向图模型的近邻传播聚类算法[J]. 控制与决策, 2017, 32(10):1796-1802.(QIN H, ZHAN J J, SU Y D. Affinity propagation clustering algorithm based on probabilistic undirected graphical model[J]. Control and Decision, 2017, 32(10): 1796-1802.)
[6] 周涛,陆惠玲. 数据挖掘中聚类算法研究进展[J]. 计算机工程与应用, 2012, 48(12):100-111.(ZHOU T, LU H L. Clustering algorithm research advances on data mining[J]. Computer Engineering and Applications, 2012, 48(12):100-111.)
[7] GIROLAMI M. Mercer kernel‑based clustering in feature space[J]. IEEE Transactions on Neural Networks, 2002, 13(3):780-784.
[8] 张莉,周伟达,焦李成. 核聚类算法[J]. 计算机学报, 2002, 25(6): 587-590.(ZHANG L, ZHOU W D, JIAO L C. Kernel clustering algorithm[J]. Chinese Journal of Computers, 2002, 25(6): 587-590.)
[9] BEN‑HUR A, HORN D, SIEGELMANN H T, et al. Support vector clustering[J]. Journal of Machine Learning Research, 2001, 2:125-137.
[10] 徐小来,房晓丽. 基于改进的直觉模糊核聚类的图像分割方法[J]. 计算机工程与应用, 2019, 55(17):227-231.(XU X L, FANG X L. Image segmentation method based on improved intuitive fuzzy kernel c‑means clustering algorithms[J]. Computer Engineering and Applications, 2019, 55(17):227-231.)
[11] 杨飞,朱志祥. 基于特征和空间信息的核模糊C-均值聚类算法[J]. 电子科技, 2016, 29(2):16-19.(YANG F, ZHU Z X. Kernelized fuzzy C‑means clustering algorithm based on feature and spatial information[J]. Electronic Science and Technology, 2016, 29(2):16-19.)
[12] XIANG L Y, ZHAO G H, LI Q, et al. A fast and effective multiple kernel clustering method on incomplete data[J]. Computers, Materials & Continua, 2021, 67(1):267-284.
[13] LIU X W, ZHU E, LIU J Y, et al. SimpleMKKM: simple multiple kernel‑means[EB/OL]. (2020-05-12)[2021-07-20]. https://arxiv.org/pdf/2005.04975.pdf.
[14] LIU Y, DING L. Nearly optimal risk bounds for kernel K‑means[EB/OL]. (2020-03-09)[2021-07-01].https://arxiv.org/pdf/2003.03888v1.pdf.
[15] 孔锐,张国宣,施泽生,等. 基于核的K-均值聚类[J]. 计算机工程, 2004, 30(11):12-13, 80.(KONG R, ZHANG G X, SHI Z S, et al. Kernel‑based K‑means clustering[J]. Computer Engineering, 2004, 30(11):12-13, 80.)
[16] NEAL R M. Bayesian Learning for Neural Networks[M]. New York: Springer, 1996: 29-53.
[17] LEE J, BAHRI Y, NOVAK R, et al. Deep neural networks as Gaussian processes[EB/OL]. (2018-03-03)[2020-05-19].https://arxiv.org/pdf/1711.00165.pdf.
[18] MATTHEWS A G D G, ROWLAND M, HRON J, et al. Gaussian process behaviour in wide deep neural networks[EB/OL]. (2018-08-16)[2020-05-19].https://arxiv.org/pdf/1804.11271.pdf.
[19] JACOT A, GABRIEL F, HONGLER C. Neural tangent kernel: convergence and generalization in neural networks[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018:8580-8589.
[20] ARORA S, DU S S, HU W, et al. On exact computation with an infinitely wide neural net[C/OL]// Proceedings of the 33rd Conference on Neural Information Processing Systems. [2020-12-24].https://proceedings.neurips.cc/paper/2019/file/dbc4d84bfcfe2284ba11beffb853a8c4-Paper.pdf.
[21] 王梅,许传海,刘勇. 基于神经正切核的多核学习方法[J]. 计算机应用, 2021,41(12):3462-3467.(WANG M, XU C H, LIU Y. Multi‑kernel learning methods based on neural positive tangent kernel[J]. Journal of Computer Applications, 2021, 41(12):3462-3467.)
[22] ARORA S, DU S S, LI Z Y, et al. Harnessing the power of infinitely wide deep nets on small‑data tasks[EB/OL]. (2019-10-27)[2021-01-08].https://arxiv.org/pdf/1910.01663.pdf.
[23] SCHÖLKOPF B, SEBASTIAN MIKA S, BURGES C J C, et al. Input space versus feature space in kernel‑based methods[J]. IEEE Transactions on Neural Networks, 1999, 10(5): 1000-1017.
[24] 王守志,何东健,李文,等. 基于核K-均值聚类算法的植物叶部病害识别[J]. 农业机械学报, 2009, 40(3):152-155.(WANG S Z, HE D J, LI W, et al. Plant leaf disease identification based on the nuclear K‑means clustering algorithm[J]. Transactions of the Chinese Society for Agricultural Machinery, 2009, 40(3): 152-155.)
[25] 王宇,李晓利. 核-凝聚聚类算法[J]. 大连理工大学学报, 2007, 47(5):763-766.(WANG Y, LI X L. Kernel‑aggregate clustering algorithm[J]. Journal of Dalian University of Technology, 2007, 47(5): 763-766.)
[26] HUO J, BI Y H, LÜ D R, et al. Cloud classification and distribution of cloud types in Beijing using Ka‑band radar data[J]. Advances in Atmospheric Sciences, 2019, 36(8):793-803.
[27] TZORTZIS G, LIKAS A. The MinMax‑Means clustering algorithm[J]. Pattern Recognition, 2014, 47(7):2505-2516.
[28] 翟东海,鱼江,高飞,等. 最大距离法选取初始簇中心的K‑means文本聚类算法的研究[J]. 计算机应用研究, 2014, 31(3):713-715, 719.(ZHAI D H, YU J, GAO F, et al. K‑means text clustering algorithm based on initial cluster centers selection according to maximum distance[J]. Application Research of Computers, 2014, 31(3):713-715, 719.)
[29] DENG Z H, CHOI K S, CHUNG F L, et al. Enhanced soft subspace clustering integrating within‑cluster and between‑cluster information[J]. Pattern Recognition, 2010, 43(3):767-781.
[30] HUANG X H, YE Y M, ZHANG H J. Extensions of kmeans‑type algorithms: a new clustering framework by integrating intra‑cluster compactness and inter‑cluster separation[J]. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(8): 1433-1446.
[31] PANG N, ZHAO X, WANG W, et al. Few‑shot text classification by leveraging bi‑directional attention and cross‑class knowledge[J]. Science China Information Sciences, 2021, 64(3): No.130103.
[32] 黄学雨,程世超. KNN优化的密度峰值聚类算法[J]. 通信技术, 2021, 54(7):1608-1618.(HUANG X Y,CHENG S C. KNN optimized density peak clustering algorithm[J]. Communication Technology, 2021, 54(7): 1608-1618.)
[33] 王芙银,张德生,张晓. 结合鲸鱼优化算法的自适应密度峰值聚类算法[J]. 计算机工程与应用, 2021, 57(3):94-102.(WANG F Y, ZHANG D S, ZHANG X. Adaptive density peak clustering algorithm combining with whale optimization algorithm[J]. Computer Engineering and Applications, 2021, 57(3): 94-102.)
Neural tangent kernel K‑Means clustering
WANG Mei1,2, SONG Xiaohui1, LIU Yong3,4*, XU Chuanhai1
(1,,163318,;2(),163318,;3,,100872,;4(),100872,)
Aiming at the problem that the clustering results of K‑Means clustering algorithm are affected by the sample distribution because of using the mean to update the cluster centers, a Neural Tangent Kernel K‑Means (NTKKM) clustering algorithm was proposed. Firstly, the data of the input space were mapped to the high‑dimensional feature space through the Neural Tangent Kernel (NTK), then the K‑Means clustering was performed in the high‑dimensional feature space, and the cluster centers were updated by taking into account the distance between clusters and within clusters at the same time. Finally, the clustering results were obtained. On the car and breast‑tissue datasets, three evaluation indexes including accuracy, Adjusted Rand Index (ARI) and FM index of NTKKM clustering algorithm and comparison algorithms were counted. Experimental results show that the effect of clustering and the stability of NTKKM clustering algorithm are better than those of K‑Means clustering algorithm and Gaussian kernel K‑Means clustering algorithm. Compared with the traditional K‑Means clustering algorithm, NTKKM clustering algorithm has the accuracy increased by 14.9% and 9.4% respectively, the ARI increased by 9.7% and 18.0% respectively, and the FM index increased by 12.0% and 12.0% respectively, indicating the excellent clustering performance of NTKKM clustering algorithm.
Neural Tangent Kernel (NTK); K‑Means; kernel clustering; feature space; kernel function
This work is partially supported by National Natural Science Foundation of China (51774090, 62076234), Postdoctoral Research Startup Fund of Heilongjiang Province (LBH‑Q20080), Natural Science Foundation of Heilongjiang Province (LH2020F003), Higher Education Teaching Reform Key Entrusted Project of Heilongjiang Province (SJGZ20190011).
WANG Mei, born in 1976, Ph. D., professor. Her research interests include machine learning, kernel methods, model selection.
SONG Xiaohui, born in 1998, M. S. candidate. Her research interests include deep kernel learning.
LIU Yong, born in 1986, Ph. D., research associate. His research interests include large‑scale machine learning, automatic machine learning, statistical machine learning theory.
XU Chuanhai, born in 1998, M. S. candidate. His research interests include deep kernel learning.
TP181
A
1001-9081(2022)11-3330-07
10.11772/j.issn.1001-9081.2021111961
2021⁃11⁃17;
2021⁃12⁃13;
2021⁃12⁃23。
国家自然科学基金资助项目(51774090, 62076234);黑龙江省博士后科研启动金资助项目(LBH‑Q20080);黑龙江省自然科学基金资助项目(LH2020F003);黑龙江省高等教育教学改革重点委托项目(SJGZ20190011)。
王梅(1976—),女,河北保定人,教授,博士,CCF会员,主要研究方向:机器学习、核方法、模型选择;宋晓晖(1998—),女,山东济南人,硕士研究生,CCF会员,主要研究方向:深度核学习;刘勇(1986—),男,湖南益阳人,副研究员,博士,CCF会员,主要研究方向:大规模机器学习、自动机器学习、统计机器学习理论;许传海(1998—),男,黑龙江鸡西人,硕士研究生,CCF会员,主要研究方向:深度核学习。
