重油加氢处理分子层次模型构建与原料适应性考察
2022-11-16关月明袁胜华张霖宙徐春明
关 冬, 张 莹, 张 成, 关月明, 袁胜华, 张霖宙, 徐春明
(1.中国石油大学(北京) 重质油国家重点实验室,北京 102249;2.中国石化 大连石油化工研究院,辽宁 大连 116045)
“双碳”背景下石油化工企业提质增效迫在眉睫,精准的石油加工过程模型将为石化行业转型提供强大助力。石油加工过程建模伴随着石化工业的发展,现如今,过程模型为实现石油资源最大化利用,在石化过程工艺设计、操作优化等诸多方面已经起到无可替代的作用[1]。自20世纪40年代起,石油炼制二次加工工艺蓬勃发展,50年代末期出现了最早的石油加工过程集总动力学模型,实现了石油加工过程产品收率的预测[2-3]。早期过程建模集中于集总动力学模型开发,采用集总形式可以极大简化石油体系的复杂程度,其中具有代表性的模型如1968年Weekman[4]建立的催化裂化过程集总动力学模型,该模型对产物含量进行了预测。1969年,Qader和Hill[5]建立了减压馏分油加氢裂化集总动力学模型,对主要产品产量和杂质脱除率进行了预测。随后,诸多其他过程集总动力学模型相继问世[6-8]。针对加氢过程,自Qader和Hill建立二集总减压瓦斯油加氢裂化模型开始,加氢过程多集总以至于连续集总模型相继被开发出来[6-7,9-12]。集总模型正向着精细化、复杂化方向发展,这是因为实际模型应用过程不再仅仅满足加氢产品收率的预测,产品性质的预测显得更为关键。由此,研究者在建模过程中纳入越来越多分子层面信息,以期提高模型的精度,石油加工过程分子层次建模逐渐成为业内热门的研究领域。
分子层次模型的研究始于20世纪90年代,许多分子层次建模的关键性技术相继被开发[1,13-15]。Quann和Jaffe[13, 16]第一次在集总模型中引入了分子结构信息,提出了结构导向集总法(Structure-oriented lumping, SOL),合并简化石油分子中大量分子结构,采用有限分子结构片段拼接表达石油分子,结合基团贡献法,成功预测了油品性质,使模型的预测能力大为提升。Jaffe等[17]将该方法用于渣油分子组成与反应动力学建模。利用SOL法,Tian等[18-26]开发了延迟焦化、蒸汽裂解工艺等分子层次模型。SOL法在分子层次石油加工建模上拥有广泛的应用[27-32]。与此同时,Klein课题组[14,33-37]采用更为细致的键电矩阵法描述和表达石油分子。Broadbelt等[34-35]将该方法应用于复杂反应体系建模,建立了从分子组成到反应过程的全流程分子层次建模方法。Klein课题组[38]也开发了KME (Kinetic model editor)和KMT (Kinetic modelers toolbox)分子管理软件包。除此之外,Peng等[15]建立了同系物矩阵(Molecular-type homologous series, MTHS)法,Aye等[39]将该法用于石油馏分组成模型构建。笔者所在课题组[40-43]也提出了结构单元耦合键电矩阵(Structural unit and bond-electron matrix,SU-BEM)法,在保留分子结构细节的同时提高了可操作性,同时搭建了CUP分子管理软件平台,基于该平台开发了加氢处理和催化裂化分子层次反应动力学模型。文献报道的分子层次模型实现了不同石油加工过程的原料组成、产品组成及性质预测。对于轻质石油馏分加工过程,采用气相色谱数据准确把握原料分子组成,为分子层次模型的准确性提供了基础保证。对于重油馏分原料组成预测目前还停留在宏观性质反演分子组成层面,重油原料分子分布的准确预测对重油分子层次加工模型的准确性尤为关键。
分子层次模型建立的关键在于准确把握石油体系的分子组成,对于重油体系,需要准确把握其特征分子结构。早期由于缺乏重油详细的分子组成表征手段,分子层次模型的分子分布准确性没有办法得到有效验证。近年来,重油分子层次表征技术突飞猛进,来自埃克森美孚公司的Qian等[44-45]通过高分辨质谱第一次实现了重油分子层次表征,在石油体系分子水平表征领域具有里程碑意义。为了能够直接得到重油中的分子结构,Zhang等[46-48]将原子力显微镜技术引入重油分子结构解析领域,第一次观察到重油中的分子结构,为基于质谱数据推断重油分子结构提供了有力支撑。随着高分辨质谱的发展,结合不同电离技术与预处理技术的重油分子表征方法不断被开发出来,如采用甲基化+电喷雾电离源检测石油中含硫化合物等[49-51]。因此,笔者所在课题组前期开发重油加氢处理分子层次模型时,采用高分辨质谱数据作为验证原料与产物组成模型杂原子分子分布的手段,使模型更加细致,且准确地描述杂原子化合物在重油加氢处理过程的转化规律,使模型在不同反应条件下产物性质预测能力大为提升[52-55]。然而,分子层次模型相比于集总模型的一大优势在于原料适应性强,理论上将分子层次模型迁移到其他重油原料时,模型依然可以准确预测产物的分子组成与性质。
相较于以往分子层次重油加工模型,在重油原料分子组成模型构建过程中参照了高分辨质谱数据,以保证重油组成模型分子分布的准确性,反应模型构建过程中参照了高分辨质谱提示的杂原子反应规律,以保证反应模型的准确性。与此同时,在前期开发的重油加氢处理过程模型的基础上,提出了分子层次模型的迁移方法,将模型应用于全新的重油原料,以考察分子层次模型的预测能力与原料适应性。
1 分子层次模型构建
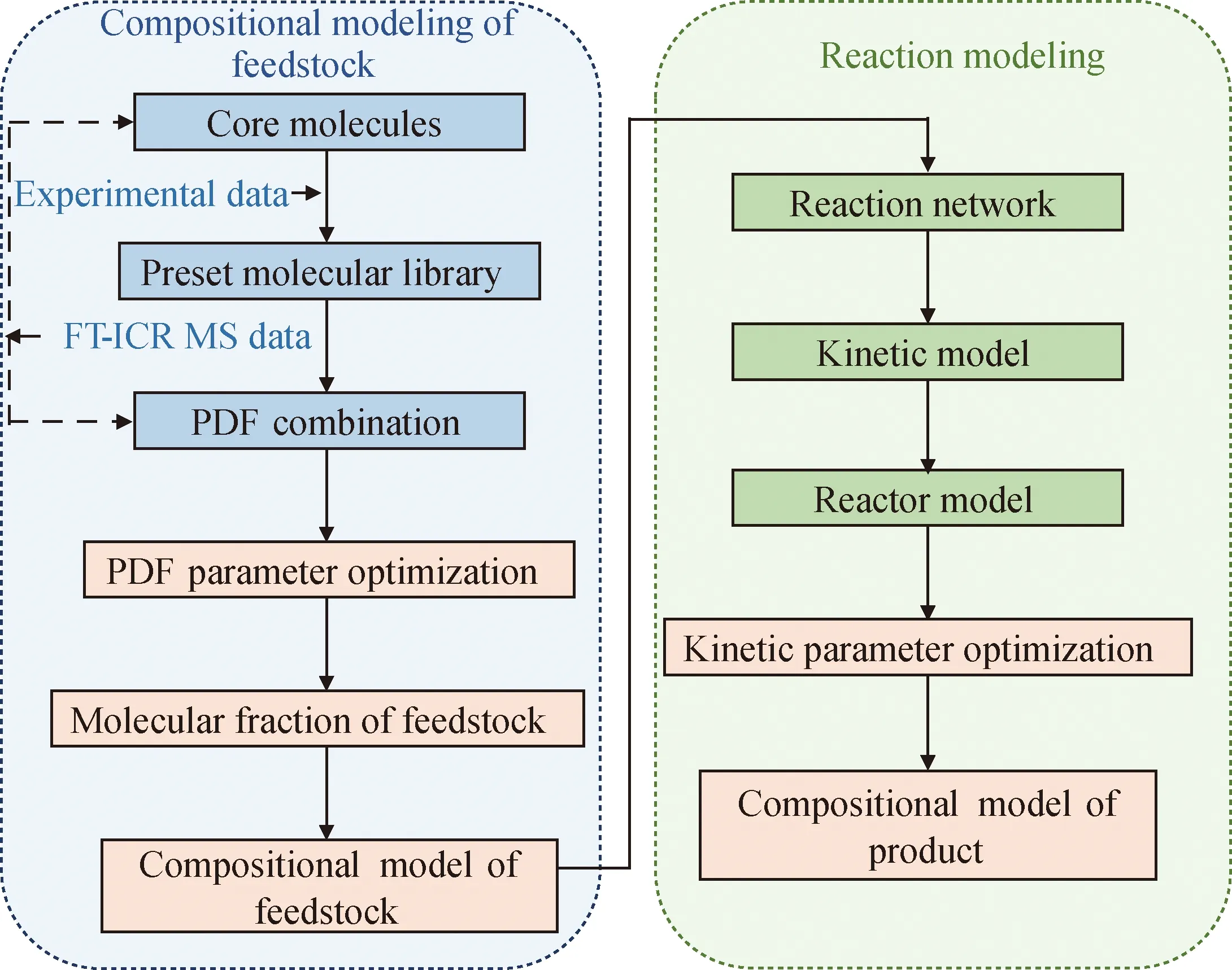
分子层次模型以分子作为最小构筑单元,相比于集总模型具有更强外推/预测能力。石油加工过程分子层次模型中往往不止包含单一反应器,更为常见的是多反应器串联或反应器-分馏塔串联模型,如催化加氢、催化裂化等单元过程。与集总模型相比,分子层次模型在衔接前后反应装置/分馏装置模型时避免了原料集总的再次划分,适用于多装置联合建模,更具发展前景。一般来说,分子层次模型开发包括7个步骤: (1)原料分子组成表征;(2)原料分子数字化;(3)原料组成模型构建;(4)分子反应网络构建;(5)反应动力学模型构建;(6)反应器模型构建;(7)模型组合与优化,如图1所示。由图1可知,步骤(1)~(3)是原料分子组成模型构建部分,步骤(4)~(7)是反应过程模型构建部分。基于笔者所在课题组开发的石油加工分子管理平台可高效完成上述模型搭建工作,该平台的基础架构采用SU-BEM框架,SU-BEM框架提供分子的数字化转化方法,反应的数字化表达及分子物理化学性质计算方法,为油品组成模型构建及反应模型开发提供基础[4,41]。

C—Carbon; H—Hydrogen; S—Sulfur; N—Nitrogen; O—Oxygen; CCR—Conradson carbon residue; SU—Structural unit;A6, N3, IH, NS, A4, AN—Chemical structures of structural units; R1—Reactor 1; R2—Reactor 2; R3—Reactor 3; R4—Reactor 4;k1—k9—Reaction rate constants图1 分子层次模型开发流程示意图Fig.1 Schematic diagram for the development process of molecular-level model
1.1 原料组成模型构建
原料组成模型构建对于开发重油加工过程分子层次模型尤为关键。对于重油,分子组成重构技术是获取其定量分子组成的唯一方法。分子重构技术是指由油品的宏观性质出发,寻找符合油品性质的代表性分子集的方法,由分子重构技术得到的油品分子组成被称为分子组成模型。石油馏分分子组成模型主要包含2部分关键信息,足够代表性的分子集和对应分子含量。分子含量是在分子集的基础上优化得到的,优化目标往往是使组成模型的宏观物性与实验数据一致。组成模型优化过程往往不能直接优化每个分子的含量,这会造成优化参数过多而导致优化效率下降,值得庆幸的是石油体系中分子的含量分布往往符合一定的分布规律,这样的分布规律又可以通过概率密度函数(Probability density function, PDF)描述。因此,通过优化概率密度函数参数的方式间接得到分子含量在提高优化效率的同时能够很好地约束体系中分子分布,前期研究结果也证明了该方法的有效性[41,55]。
基于SU-BEM框架,通过优化PDF参数可以准确且高效地获取原料组成模型。图2给出了原料组成模型构建的具体流程,首先需要给定原料组成模型的分子集和PDF组合方式,分子集的获取采用定义核心分子并延长其侧链碳数完成,分子管理软件平台也具备了基于核心分子的分子集自动构建技术,PDF组合形式则可根据实验数据灵活设置。拿到分子集后可对应获得分子物性库,通过给定分子含量初始值即可获得油品宏观物性,计算宏观物性与实验数据间的误差,当误差过大时,通过调整PDF参数间接调整分子含量,重新计算宏观物性,直至原料组成模型中宏观物性与实验数据间的误差达到允许值后输出,原料组成模型构建完成。原料组成模型为分子层次模型构建提供了基础数据。

PDF—Probability density function; Tb—Boiling temperature图2 原料组成模型构建流程示意图Fig.2 Schematic diagram for the construction process of feedstock compositional model
1.2 反应过程模型构建
复杂体系的反应过程模型构建需要耦合体系的反应动力学模型,基于反应器内物料流动与相态的传质模型及传热模型,构建难度较大。分子层次的复杂体系反应过程建模更是极具挑战。对于轻质石油馏分尚可构建其机理层面分子层次反应动力学模型,如蒸汽裂解过程,而重油加工过程由于原料组成的复杂性,只能从反应路径层面完成分子层次反应动力学建模。
SU-BEM框架提供了基础的反应规则制定与反应网络构建方法,反应动力学模型构建则需要在反应网络的基础上确定各反应的速率,同时需要根据反应器内物料的流动状态确定传质速率,进而由原料组成模型得到产物组成模型。图3给出了反应模型的构建过程,输入端为原料组成模型,原料分子遍历反应规则后形成反应网络,反应网络中包含的分子包括原料分子及新生成的产物分子。与原料组成模型构建法类似,反应过程模型的优化目标也是获得产物分子含量并优化各反应速率。值得注意的是,若反应过程模型中包含反应器信息,则需要根据反应物在反应器内的流动状态确定传质方程,将传质系数等模型参数纳入优化变量中。优化目标是使产物分子含量和性质与实验数据达到允许误差,当误差较大时,需要重新优化反应过程模型参数。理论上,分子层次反应过程模型参数在后续模型应用过程中无需重新训练。

图3 反应模型构建流程示意图Fig.3 Schematic diagram for the construction process of reaction model
2 重油加氢处理分子层次模型构建与验证
2.1 模型构建
为了考察分子层次模型的预测能力,基于前期工作[55]完成的重油加氢处理分子层次模型,采用全新目标重油原料,优化其分子组成模型并预测其加氢处理产物组成,以考察模型的预测能力与原料适应性。理论上,模型预测能力与模型的精细程度正相关,原料组成模型对分子分布规律及反应模型对分子转化规律的描述越准确,模型预测能力越强。因此,前期工作在模型搭建过程中引入了傅里叶变换离子回旋共振质谱(FT-ICR MS)数据,简称高分辨质谱,用于原料组成模型分子分布和反应转化规律准确性的验证,重油加氢处理过程分子层次组成模型构建过程如图4所示,构建过程与前期工作一致[55]。基于高分辨质谱检测数据与目前已鉴定出的石油中的分子结构,定义了重油核心分子156个,包括正构烷烃、异构烷烃、环烷烃、芳香烃、芳香-环烷混合烃及含S、N、O的杂原子化合物,忽略含量极少的金属卟啉类化合物,包含常见的杂原子化合物,如硫醚、噻吩、吡啶、吡咯、环烷酸及酚类化合物,经侧链拓展后预置分子集共包含不同结构分子数为12734个。基于SU-BEM框架,采用上文所述优化方法,最终得到原料组成模型。
PDF—Probability density function; FI-ICR MS—Fourier transform ion cyclotron resonance mass spectrometry图4 重油加氢处理过程分子层次模型构建流程图Fig.4 Flow chart for molecular-level model construction during heavy oil hydrotreating
原料组成模型构建完成后,将其用于反应过程模型构建。反应过程模型需与实验过程保持一致,并尽可能描述反应器内所发生的物料流动、相变及反应。图5给出了模型所用重油加氢处理装置示意图,该过程采用固定床加氢处理反应器串联模式,不同反应器内装填不同种类催化剂,用以实现不同杂原子化合物的脱除[56-57]。以图5所示反应流程为基础,构建反应过程模型如图4所示,首先以组成模型作为输入,依据重油加氢处理过程反应机理,通过制定反应规则并遍历反应物分子完成反应网络构建。重油加氢处理过程采用双功能催化剂,重油分子在酸性中心主要发生裂化反应,包括烷烃裂化、环烷烃开环、芳烃脱烷基反应等,在金属中心主要发生加氢反应,包括加氢脱硫、加氢脱氮、加氢脱氧、芳香环饱和等。由于重油体系过于庞大,笔者在制定反应规则时,忽略了部分次要反应,在反应路径层面合并部分反应路径以减少不必要的中间分子生成,采用的反应规则与前期工作一致,形成的反应网络中共包含分子 17351个,反应25591个[57]。反应网络构建完成后,还需将反应网络转化为反应速率表达式并与反应器传质方程耦合。滴流床反应器内的物料呈气-液-固三相共存状态,加上复杂的物料组成部分,反应模型构建难度极大,因此,在保证模型精度的前提下,采用平推流模型降低模型求解难度,所用质量平衡方程如式(1)~式(5)所示。
气相质量平衡方程如公式(1)所示。
(1)
液相质量平衡方程如公式(2)所示。
(2)
固相质量平衡方程如公式(3)所示。
(3)
将公式(3)代入公式(2)得到液相质量平衡如公式(4)所示。
(4)
基于课题组前期工作[57],加氢处理过程反应速率表达式可以采用LHHW方程表示。如方程(5)所示:
(5)
将原料组成模型与反应网络带入上述式(1)~式(5)中,构成常微分方程组,通过数值计算求得最终解,值得注意的是模型中包含上万个分子,说明该常微分方程组由数万个常微分方程组成,可见求解难度之大。最后,采用实验分析得到的产物数据训练并最终得到合适的反应动力学模型参数完成反应模型构建,参数训练过程见前期工作[57]。

图5 重油固定床加氢处理装置示意图Fig.5 Schematic diagram of heavy oil fixed bed hydrotreating
2.2 模型验证
分子层次重油加氢处理过程模型构建完成后,以硫化物的分布为例,证明分子层次模型的精度,如图6所示。由于不同组高分辨质谱数据间无法定量比较,以原料、中间产物和最终产物组成模型中各自硫化物总体质量含量为基准,统计了不同类型硫化物的质量比例变化,并与高分辨质谱数据进行比较。图6模型计算结果显示:原料中硫化物质量分数从大到小依次为苯并噻吩类、二苯并噻吩类、噻吩类;从重油原料到加氢后的重油产物中噻吩类和苯并噻吩类化合物质量分数逐渐下降,而二苯并噻吩类化合物质量分数略有提升,说明噻吩和苯并噻吩类化合物较为容易脱硫,而二苯并噻吩类化合物难以脱除,这与实验规律一致,如4,6-二甲基二苯并噻吩的空间位阻作用导致其脱硫十分困难[2]。综上表明硫化物的脱除难度与其环数正相关。分子层次重油加氢处理模型计算结果也与高分辨质谱得到的分子转化规律一致。除此之外,由图6可知,模型计算结果在原料与产物宏观性质、氮化物和氧化物分子分布与转化规律上均与实验数据一致,证明了分子层次重油加氢处理模型的准确性。
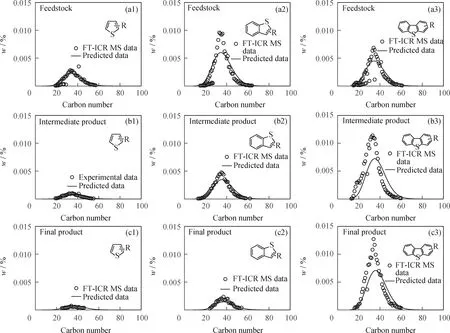
R—Side-chain carbon number; FI-ICR MS—Fourier transform ion cyclotron resonance mass spectrometry图6 模型计算结果的硫化物分子分布与FT-ICR MS数据对比Fig.6 Comparison between model calculation results for the molecular distribution of sulfides and FT-ICR MS data(a1)—(a3) Sulfur-containing species in the feedstock; (b1)—(b3) Sulfur-containing species in the intermediate products;(c1)—(c3) Sulfur-containing species in the final products
3 重油加氢处理分子层次模型原料适应性考察
分子层次模型相比于传统集总模型的优势在于原料适应性强,因此,将模型应用于不同重油原料(模型迁移),以考察模型的原料适应性。集总模型在进行模型迁移时,需要针对全新原料重新划分集总,其后续反应动力学模型参数同样需要重新训练,原料适用性差。分子层次模型在模型迁移过程中,仅需优化组成模型中的分子含量,使其与新原料匹配即可,后续反应动力学参数无需重新训练。重油加氢处理分子层次模型的模型迁移流程如图7所示。首先需要表征重油原料1的分子组成与宏观物性,用于重油原料1的组成模型构建,重油原料2的组成模型只需在重油原料1的组成模型基础上优化模型参数,进而得到重油原料2的组成模型分子含量即可。组成模型构建完成后,将其输入反应模型中,预测产物组成与性质,反应模型参数采用优化完成的重油加氢处理分子层次模型参数[57]。
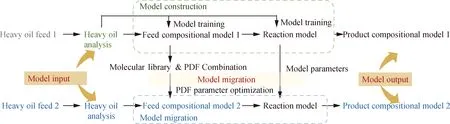
PDF—Probability density function图7 重油加氢处理分子层次模型构建与迁移流程Fig.7 Construction and migration process of molecular-level model for heavy oil hydrotreating
3.1 原料组成模型优化结果
为了证明重油分子组成模型具有较强的原料适应性,采用图7模型迁移方案,得到重油原料2的组成模型。对比重油加氢处理分子层次模型构建时的原料重油(重油原料1)与采用的目标重油(重油原料2)的模型构建结果,如表1所示。重油原料1与重油原料2 为来源于国内不同炼油厂的重油加氢处理原料油,2种重油原料在杂原子含量上差异较大,适用于模型的原料适应性考察。由表1可知,原料组成模型的预测值均与实验数据保持一致,尤其是重油加氢处理过程中最为关键的杂原子含量与残炭值,相比于重油原料1,重油原料2的硫含量较高,氮含量和氧含量较低,残炭值略高,原料组成模型很好地再现了目标重油原料的特点。

表1 重油组成模型构建结果与实验值对比Table 1 Comparison between the results of heavy oil compositional model construction and experimental data
进一步将重油原料2组成模型中杂原子分子分布结果与高分辨质谱数据对比,如图8所示,以不同类型杂原子化合物的高分辨质谱数据为准,将杂原子化合物含量归一化,统计了典型化合物在同种杂原子化合物中所占比例及分子分布情况。由图8可知,重油原料2中硫化物与氮化物分子分布规律与高分辨质谱数据十分接近,如硫化物中噻吩类化合物分子分布中心位于C35左右,与高分辨数据相差无几,分子分布峰形宽度十分接近。重油原料2组成模型计算结果显示,其硫化物含量由大到小依次为苯并噻吩类>二苯并噻吩类>噻吩类,与图6中重油原料1中的硫化物分布规律相同。重油原料2氮化物含量排序由大到小依次为苯并喹啉类≈喹啉类>吡啶类。重油原料2的组成模型在保证重油原料宏观性质与实验数据一致的前提下,很好地保证了其杂原子分子分布与高分辨质谱的一致性,证明重油原料2的组成模型具有较高准确性。
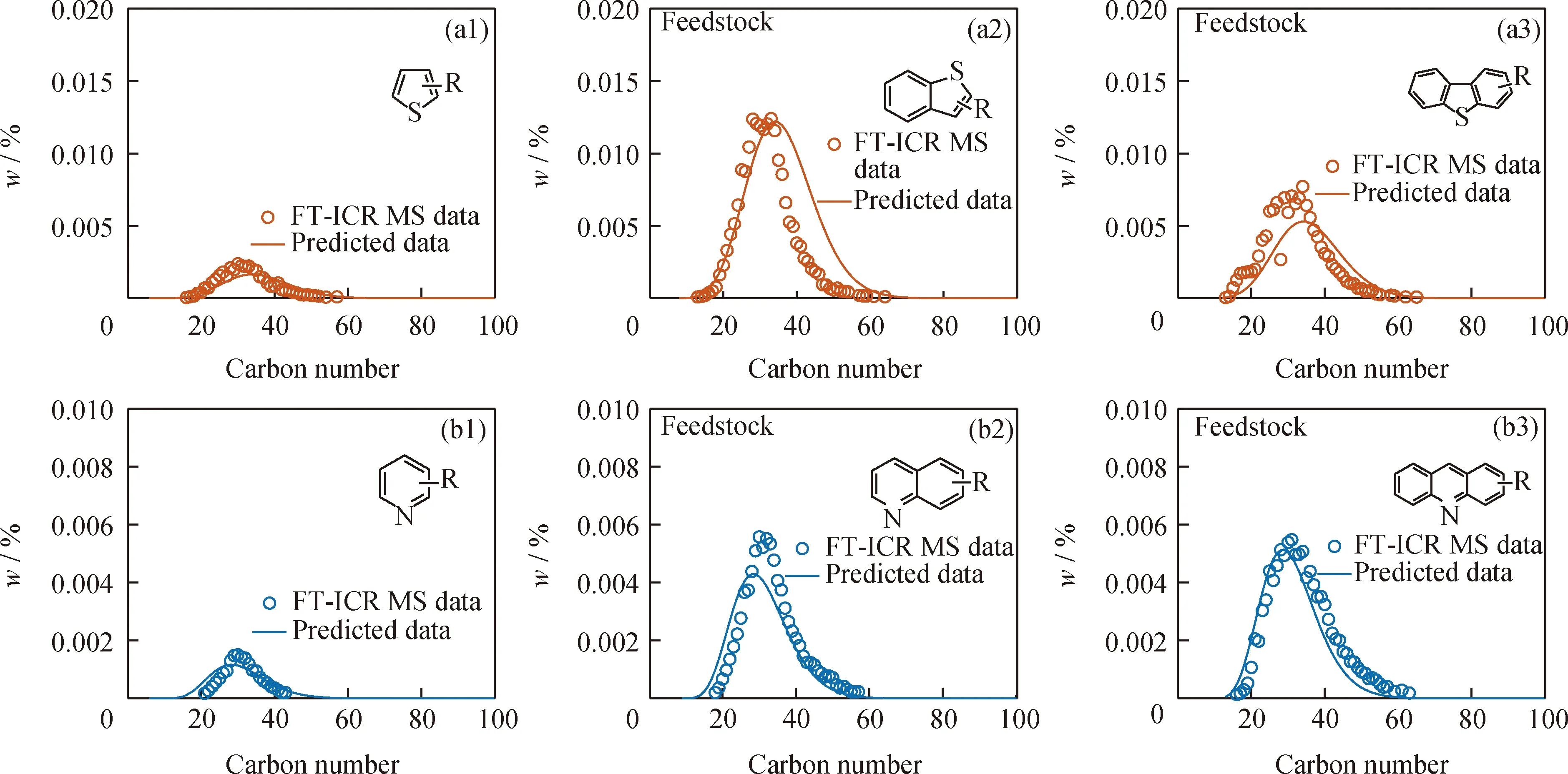
R—Side-chain carbon number; FI-ICR MS—Fourier transform ion cyclotron resonance mass spectrometry图8 重油原料2组成模型分子分布与FT-ICR MS数据对比Fig.8 Comparison between the molecular distribution of compositional model for heavy oil feed 2 and FT-ICR MS data(a1)—(a3) Sulfur-containing species; (b1)—(b3) Nitrogen-containing species
3.2 反应模型预测结果
将重油原料2的组成模型输入反应模型中,求解产物组成与性质。重油加氢处理实验条件为:反应器入口温度386 ℃,反应压力17 MPa,氢/油体积比680 m3/m3,液时空速为0.2 h-1。设置完成重油加氢处理分子层次模型的实验条件后,运行模型并得到产物性质,结果如图9所示。由图9可知,不同反应器出口产物模型中的关键参数如硫含量、氮含量与残炭值(Conradson carbon residue, CCR)的预测结果与实验值较为吻合,说明重油加氢处理分子层次模型很好地描述了重油加氢过程中硫、氮元素及CCR值的脱除效果。
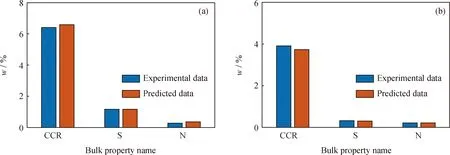
S—Sulfur; N—Nitrogen; CCR—Conradson carbon residue图9 各反应器出口产物S、N元素含量和CCR预测值与实验值对比Fig.9 Comparison between S and N element content and CCR predicted value of the productat the outlet of each reactor and the experimental data(a) Intermediate product; (b) Final product
为了证明重油加氢处理分子层次模型很好地描述了重油原料2加氢处理过程分子转化规律,进一步比较各反应器出口反应产物的杂原子化合物的分布与高分辨质谱数据,如图10所示。图10中分别统计了重油原料2加氢处理后典型硫化物及氮化物在中间产物和最终产物中分子分布情况。由图10可知:与原料相比,产物的硫化物中噻吩类及苯并噻吩类化合物比例随反应的进行逐步下降,二苯并噻吩类化合物含量略有提升,说明二苯并噻吩类化合物难以脱除;产物中的典型氮化物,如吡啶类、喹啉类和苯并喹啉类化合物比例与原料保持一致,说明氮化物的反应规律与硫化物不同,其脱除难度与环数无关;重油加氢处理分子层次模型的计算结果与高分辨质谱数据吻合,与重油原料1的加氢处理产物组成模型结果一致(见图6),重油原料2的加氢处理产物组成模型结果同样展现了与实验数据的一致性。以上结果表明,构建的重油加氢分子层次模型具有一定的原料适应性,可以直接用于不同原料的组成及产物性质与分子分布预测。

R—Side-chain carbon number; FI-ICR MS—Fourier transform ion cyclotron resonance mass spectrometry图10 重油原料2加氢处理后产物组成模型分子分布与FT-ICR MS数据对比Fig.10 Comparison between the molecular distribution of product compositional model after hydrotreating ofheavy oil feed 2 and FT-ICR MS data(a1)—(a3) Sulfur-containing species in the intermediate products; (b1)—(b3) Nitrogen-containing species in the intermediate products;(c1)—(c3) Sulfur-containing species in the final products; (d1)—(d3) Nitrogen-containing species in the final products
4 结 论
介绍了分子层次模型的构建方法,并将其用于重油加氢处理分子层次模型的构建。提出了分子层次模型的模型迁移策略,考察了重油加氢处理分子层次模型的产物性质预测能力与原料适应性。结果表明,构建的重油加氢处理分子层次模型具有一定的油品性质预测能力及原料适应性。相比于集总模型,分子层次模型更加适用于炼油过程多装置联合优化甚至全厂优化,分子层次模型更具工业应用前景。原料分子组成模型的准确性是保证分子层次模型产物性质预测精度及原料适应性的关键,利用先进表征技术提升原料分子组成模型精度是分子层次模型的发展趋势。在反应模型中有效结合反应机理、催化剂性能、物料流动状态及物料相态变化,准确回归动力学参数是急需解决的关键问题。
符号说明:
aL——气-液传质面积,cm-1;
aS——液-固传质面积,cm-1;
Badsi——物质i的吸附常数;

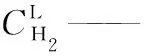
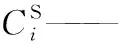
hi——物质i的亨利系数, MPa cm3/mol;
ksrij——反应j的表面反应速率常数,h-1;


m——反应物的反应级数;
p——反应器压力,MPa;


R——理想气体常数, J/(mol·K);
rH/O——氢/油体积比,m3/m3;
ri——物质i所参与的总反应速率,mol/(cm3·h);
rij——反应j的反应速率,mol/(cm3·h);
T——反应器温度,K;
ug——气相平均流速,cm/s;
uL——液相平均流速,cm/s;
z——反应器长度,cm;
ηi——物质i的内扩散有效因子;
ρb——催化剂堆密度,g/cm3。
