基于改进樽海鞘群算法的到达时间差定位
2022-11-15马一鸣石志东贡常磊单联海
马一鸣 石志东 赵 康 贡常磊 单联海
(1. 上海大学特种光纤与光接入网重点实验室, 上海 200444; 2. 上海物联网有限公司, 上海 201899;3. 华东师范大学软件工程学院, 上海 200062)
随着通信和定位技术的迅速发展, 单一的定位导航正在向监控、交通、救助、娱乐等综合位置服务转化, 位置服务作为新兴产业, 在人们的日常生活中起到了重要作用. 在室内环境下,GPS 信号容易被遮挡, 无法实现精确可靠的定位[1], 而室内定位技术可以弥补这一不足. 近年来, 国内外学者对室内定位技术进行了大量研究, 其中到达时间差(time difference of arrival,TDOA)定位方式凭借其定位精度高、系统复杂度低的优势, 成为室内定位的一个重要实现手段.
TDOA 定位方式不要求基站与移动台之间的时间同步, 但需要基站之间保持严格的时间同步. WiFi、蓝牙、Zigbee 等无线通信技术无法实现较高的时间分辨率, 超声波信号穿透能力较弱, 不适合复杂多变的室内环境. 超宽带(ultra wide band, UWB)技术通过发送纳秒或皮秒级的极窄脉冲来传输数据, 具有小于1 ns 的时间分辨率, 可以达到厘米级的理论测距精度, 同时在穿透性和抗多径方面也有良好的表现, 适合用于高精度室内定位[2].
TDOA 定位可以转换为非线性双曲线方程求解问题, 目前已有很多算法可以完成位置解算. 传统算法中泰勒级数展开法[3]需要一个接近真实位置的坐标作为初始值以保证算法收敛.Chan 算法[4]忽略了噪声二次项, 在噪声方差较大时性能会有所下降. 扩展卡尔曼滤波[5]将非线性系统作线性近似处理, 然后进行跟踪滤波, 但定位精度容易受实际环境中的未知信道参数影响. 两步最小二乘法[6]、加权最小二乘法[7]等算法在最小二乘法的基础上进行改进, 适用于测量误差较小的情况, 但当误差大于一定值时定位精度会显著下降.
除了上述解析算法, 元启发式算法也被应用于TDOA 定位. 王生亮等[8]提出改进的自适应遗传算法, 在设计自适应交叉率和变异率时考虑种群随进化代数的整体变化, 并考虑了每代种群个体适应度的作用, 引入最优保存策略来保护优秀个体. Yue 等[9]提出混沌粒子群算法, 利用混沌序列对粒子群优化算法施加扰动, 使算法可以跳出局部最优解, 从而达到全局最优解. 陈涛等[10]将樽海鞘群算法(salp swarm algorithm, SSA)引入TDOA 定位, 取得了比传统粒子群优化算法更高的定位精度. 王梦馨[11]在SSA 中引入领导者数量随迭代次数衰减的动态模型, 增强群体前期全局搜索能力, 同时后期能保持较好的收敛能力. 根据NFL(No-Free-Lunch)理论[12]所述, 不存在适用于所有问题的元启发式算法, 因此针对TDOA 定位对不同元启发式算法进行比较, 有助于找到更适合TDOA 定位问题的算法.
现有的元启发式算法应用研究聚焦于回避局部最优解[13-14]以及搜索和开发能力的平衡[15-16]. 对于TDOA 定位问题, 在适应度函数方面缺少进一步研究[8-11]. 此外, 由于元启发式算法需要较大的种群规模和较多的迭代次数, 造成计算量较大, 不利于实时位置解算. 本工作针对以上不足, 提出用改进的樽海鞘群算法(improved salp swarm algorithm, ISSA)进行TDOA 室内定位, 通过引入主基站选择对适应度函数进行改进, 提高算法寻优精度, 并在此基础上引入近似解和自适应跟随策略, 分别加快了算法前期和后期的收敛速度. 将提出的ISSA与其他元启发式算法[17-20]进行定位性能仿真比较, 结果表明, 采用ISSA 进行室内TDOA 定位可以取得更高的定位精度和更快的收敛速度.
1 TDOA 定位模型
TDOA 定位几何模型如图1 所示, 在2 维平面中部署N个不同位置的基站, 移动台周期性地向基站发送无线定位信号. 基站i的定位信号到达时间为
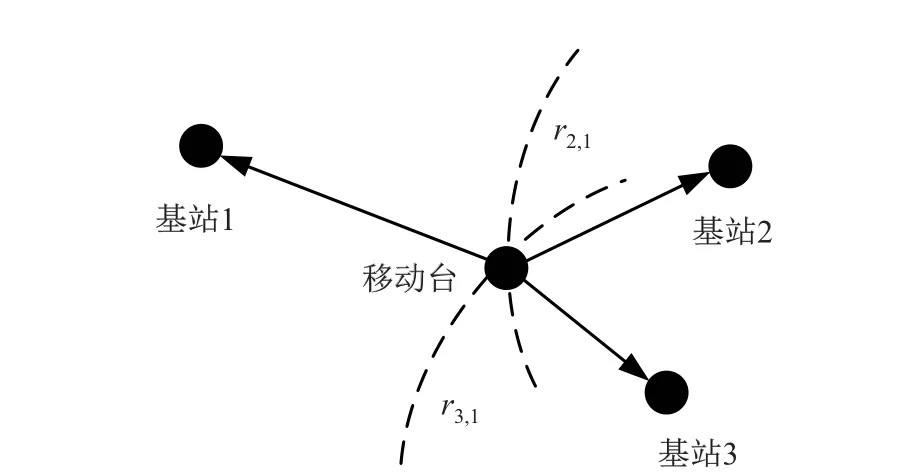
图1 TDOA 定位几何模型Fig.1 Geometric model of TDOA localization

式中:i= 1,2,··· ,N; ˙ti为信号到达时间真实值;eti为到达时间误差, 服从均值为零的高斯分布. 通过测量定位信号从移动台到达两个基站的传播时间差, 再将其乘以电磁波传播速度c,可以得到移动台到两个基站之间的固定距离差. 定义ri为移动台到基站i的距离,ri,j为移动台到基站i和基站j的距离差测量值, 则

式中:i,j= 1,2,··· ,N,i /=j; (x,y) 为未知移动台坐标; (xi,yi) 为基站i的已知坐标;eri=ceti为测距误差, 服从均值为0、标准差为σr的高斯分布. 根据移动台到两个基站的距离差可以确定一条双曲线, 利用多个基站建立双曲线方程组, 再通过数学方法求解即可算出未知移动台的坐标.
定义基站1 为主基站, 其他基站为辅基站. 将信号到达主基站与各个辅基站的时间差乘以电磁波传播速度c, 得到N-1 个距离差测量值为

当非线性函数取最小值时, 得到移动台坐标的估计值, 用解析法求解较为困难, 本工作采用樽海鞘群算法求解. 根据式(6)推导出评价算法中个体优劣程度的适应度函数为

式中:X为樽海鞘个体的位置向量. 适应度取值越小代表估计位置越接近真实位置.
2 樽海鞘群算法
樽海鞘是一种海洋生物, 具有透明的桶形身体, 通过吸入喷出海水进行移动. 樽海鞘群体经常形成被称为樽海鞘链的链状结构, 这种结构可以帮助樽海鞘实现快速协调移动和觅食. 樽海鞘链由领导者和追随者组成, 领导者位于樽海鞘链的最前端, 其他个体则为追随者, 朝着前一个樽海鞘的方向移动.
2017 年, Mirjalili 等[17]受樽海鞘的群体行为特征启发, 建立樽海鞘链的数学模型, 提出SSA 来解决优化问题, 该算法具有计算量小、不易陷入局部最优的优点.
2.1 种群初始化


在求解优化问题时, SSA 首先将樽海鞘种群位置在限定范围内随机初始化,
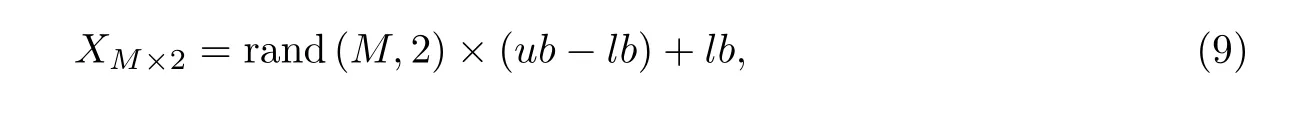

2.2 领导者位置更新
由于优化问题的全局最优是未知的, 只能将当前搜索到的最优位置作为食物位置, 并在搜索过程中不断更新食物位置. 领导者在食物位置附近进行搜索开发, 引导整个种群的移动, 位置更新公式为

式中:Xij为第i个樽海鞘的第j维位置,j= 1,2;Fj是食物的第j维位置;ubj和lbj分别是第j维位置的上、下界;c2和c3都是[0,1]之间的随机数, 保证了领导者移动的随机性;c1为收敛因子, 负责平衡迭代过程中的搜索与开发能力. 当收敛因子大于1 时, 进行全局搜索; 当收敛因子小于1 时, 进行局部开发. 通常c1的取值为一个随迭代次数递减的函数. 根据文献[17],收敛因子为

式中:τ为当前迭代次数;T为最大迭代次数. 为了权衡SSA 的随机性与稳定性, 选取50%樽海鞘作为领导者.
2.3 追随者位置更新
在SSA 中, 追随者依据前一个樽海鞘个体的位置进行移动, 该运动方式符合牛顿运动定律,

3 改进樽海鞘群算法
3.1 改进的适应度函数
适应度函数的选取对最终的寻优精度有直接影响. 观察式(4)可以发现, 将主基站信号到达时间t1作为距离差测量值的公共项, 可以对式(7)中的所有平方项产生影响, 而第i个辅基站信号到达时间ti(i=2,3,··· ,N)只会影响式(7)的第i-1 个平方项, 这会导致适应度函数对主基站的测量值相对敏感, 当主基站的测距误差er1显著大于或小于辅基站的测距误差eri时, 适应度函数的最小值会显著增大. 此时, 可以通过寻找一个最优主基站以减小适应度函数的最小值. 定义基站j为主基站时的适应度函数为

式中:j ∈{1,2,··· ,N},i /=j. 对于不同的主基站, 分别通过最大似然估计计算适应度函数,然后选取其中的最小值作为改进的适应度函数, 代入方程求解,

3.2 近似解引入
初始种群的位置分布会影响算法的收敛速度, 在没有任何先验知识的前提下, 大部分元启发式算法的初始种群都采用随机生成. 为了避免陷入局部最优, 算法在前期需要对整个搜索空间进行充分的全局搜索, 然后逐步缩小搜索范围, 转入局部开发, 在一定程度上浪费了计算资源. 本工作提出通过运算量较小的最小二乘法[21]计算一个近似解,

式中:

其中(xi,yi)为基站i的坐标,i=1,2,··· ,N,N为基站数量,ki=x2i+y2i,rj,1为距离差测量值,j= 2,3,··· ,N. 从初始种群中随机抽取一个个体用近似解XLS替换, 得到改进后的初始种群. 由于近似解位置与目标位置比较接近, 拥有较优的适应度值, 对种群起到很好的引导作用, 使全局搜索的步骤得到简化, 从而加快算法前期收敛速度. 另外, 调整收敛因子c1的衰减规律, 能加快c1的前期下降速度, 使算法更快地从全局搜索转入局部开发,

式中:τ为当前迭代次数.
3.3 自适应跟随策略
追随者的顺次跟随移动使SSA 保有一部分个体不随机运动, 降低了算法陷入局部最优的概率. 但这种盲目跟随的位置更新策略不能保证追随者朝着更优的个体位置移动, 这会限制局部开发效率,导致后期食物的适应度值下降缓慢.因此本工作提出自适应跟随策略,当第i-1 个樽海鞘的适应度值优于第i个樽海鞘时, 按照式(14)进行追随者位置更新, 否则追随者将向食物方向运动, 采用下式实现这个过程:

式中:f(·)为适应度函数. 采用该策略可以保证追随者始终跟随适应度更优的个体移动, 避免盲目跟随, 提高局部开发效率, 加快算法后期收敛速度.
3.4 算法步骤
基于ISSA 的TDOA 定位具体步骤如下.
(1)种群初始化. 确定搜索空间各个维度变化范围的上界和下界, 利用式(9)初始化种群.
(2)引入近似解. 采用最小二乘法计算近似解并随机替换种群中的一个个体.
(3)选定食物、领导者、追随者. 利用式(16)计算每个樽海鞘个体的适应度值, 然后将樽海鞘种群按适应度升序排序, 排在首位的适应度最优的个体位置作为当前食物位置. 排在前50%的个体设为领导者, 其余个体为追随者.
(4)领导者和追随者位置更新. 根据式(10)和(23)分别更新领导者和追随者位置.
(5)食物位置更新. 通过式(16)计算位置更新后个体的适应度, 并与当前食物适应度值进行比较, 若更新后个体的适应度值优于食物适应度值, 则将适应度值更优的樽海鞘个体位置作为新的食物位置.
重复步骤(4)和步骤(5), 当达到最大迭代次数时, 输出当前食物坐标作为目标的估计位置.ISSA 定位流程图如图2 所示.

图2 改进樽海鞘群算法定位流程图Fig.2 Flowchart of localization based on ISSA
4 定位性能仿真
为了验证本工作提出的ISSA 对室内TDOA 定位的有效性, 将ISSA 与传统樽海鞘群算法(SSA)[17]、蚁狮优化(ant lion optimization, ALO)算法[18]、鲸鱼优化算法(whale optimization algorithm, WOA)[19]、哈里斯鹰优化(Harris hawk optimization, HHO)算法[20]进行比较.仿真实验的软件平台为Matlab 2016b. 硬件平台: 处理器为Intel (R) Core(TM) i5-7300HQ,频率2.5 GHz, 内存8 GB.
定位场景和仿真参数设置如下: 在20 m×20 m 的平面内部署8 个基站, 坐标分别为(0, 0)、(0, 20)、(20, 20)、(20, 0)、(0, 10)、(20, 10)、(10, 20)、(10, 0), 定位场景内随机生成1 000 个测试点, 搜索空间的上界ub= [20 20], 下界lb= [0 0], 种群规模M= 30, 最大迭代次数T= 60. 测距误差服从均值为0、标准差为σr的高斯分布. 采用均方根误差(root mean square error, RMSE)作为定位精度的评价指标,
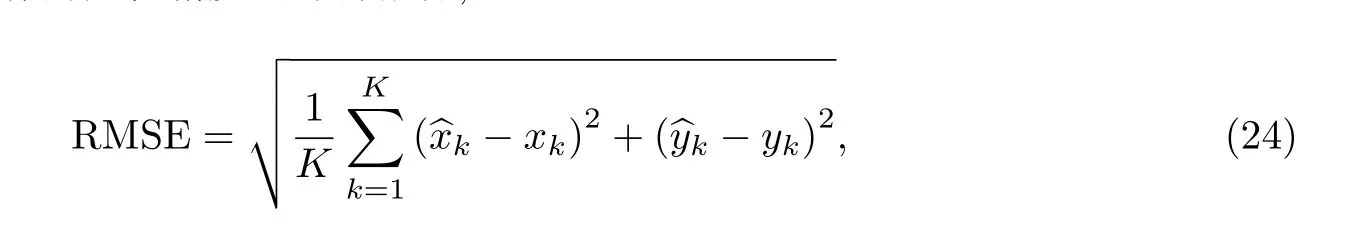

式(25)~(27)中: trace(·)函数的作用为矩阵求迹;Q为协方差矩阵;σr为测距误差的标准差;(x,y)和(xi,yi)分别为移动台和基站i的坐标;ri为移动台到基站i的距离,i= 1,2,··· ,N,N为基站数量.
虽然UWB 技术的理论测距精度为厘米级, 但实际应用中由于发送/接收天线延时、移动台运动等因素, 测距精度无法做到厘米级, 根据文献[22-23]的实测数据, 测距误差的标准差为分米级. 故将仿真参数σr的值设定为0.1~0.8 m, 在定位基站数量N=8 的条件下进行实验,得到不同算法的RMSE 与测距误差标准差的关系, 如表1 所示. 随着测距误差标准差的增大,所有算法的RMSE 逐渐增大, 并逐渐偏离CRLB. ALO 算法、HHO 算法、SSA 的定位误差比较接近, WOA 的定位误差相对较大. 本工作提出的ISSA 在不同σr值下都取得了较高的定位精度, RMSE 比其他元启发式算法更接近CRLB.

表1 RMSE 与测距误差标准差的关系Table 1 Relationship between RMSE and standard deviation of ranging error m
为了测试算法在不同基站数量下的定位精度, 在σr为0.3 m 的条件下, 分别对N取4~8的情况进行仿真实验, 得到不同算法的RMSE 与基站数量的关系, 如表2 所示. 基站数量越多, 各算法的RMSE 越小. ISSA 在不同基站数量下都实现了较低的定位误差, RMSE 相比其他元启发式算法更接近CRLB. 当基站由4 个增加到8 个时, ISSA 的RMSE 相比SSA 分别减小4.89%、8.88%、10.44%、12.08%、16.44%, 在多基站定位场景中优势更明显, 这是因为基站数量越多, 选择最优主基站对适应度函数的改进越显著, 所以ISSA 更适合存在冗余基站的高精度定位场景.
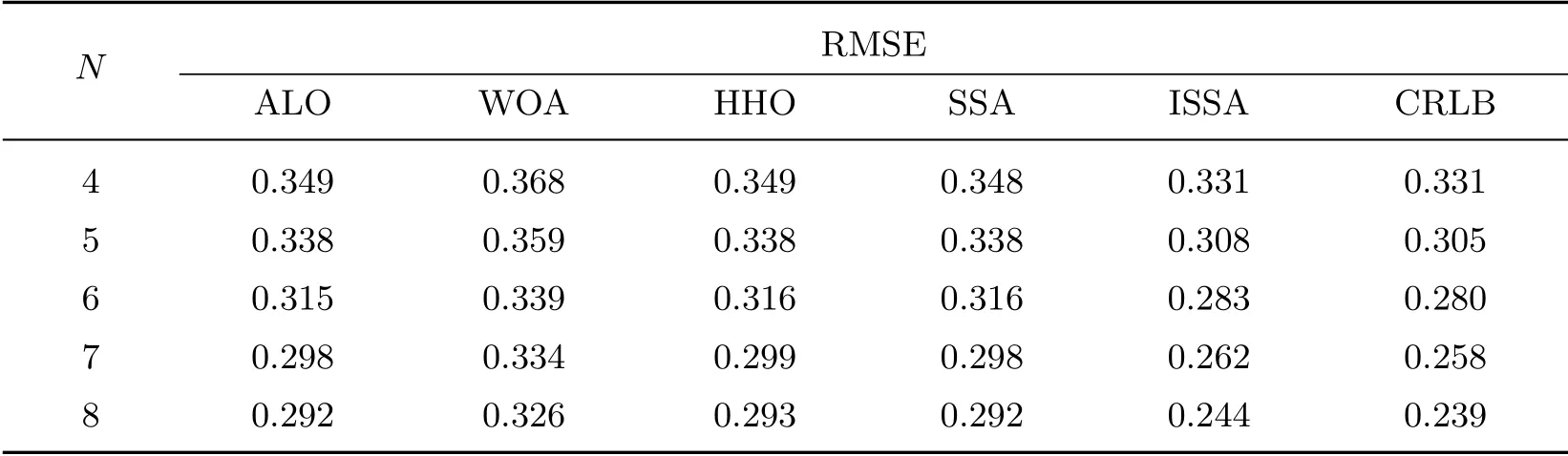
表2 RMSE 与基站数量的关系Table 2 Relationship between RMSE and number of base stations m
在N=8、σr为0.3 m 的条件下进行实验, 为了比较不同算法的收敛能力, 将每次迭代后的估计位置代入式(24), 得到RMSE 随迭代次数增加而逐步减小并趋于收敛的曲线(见图3).图3(a)为不同SSA 的收敛能力比较, 传统SSA 由于只有领导者参与随机运动, 而追随者缺少评价跟随目标优劣的机制, 导致整体收敛速度较慢. SSA2 为引入近似解的SSA, 由于近似解与真实位置比较接近, 使RMSE 有一个较低的初值, 可以更好地引导种群接近目标位置, 但RMSE 在低于一定值后下降速度趋缓. SSA3 在SSA2 的基础上引入自适应跟随策略, 使追随者始终朝适应度较优的个体方向移动, 解决了RMSE 后期下降缓慢的问题. ISSA 在SSA3 的基础上引入主基站选择改进适应度函数, 使算法可以收敛到更低的RMSE, 定位精度更高.
图3(b)为不同元启发式算法的收敛能力比较, ALO 算法、WOA、HHO 算法虽然前期收敛速度快于SSA, 但由于初期需要对整个搜索空间进行充分的全局搜索, 仍需要多次迭代才能完成寻优工作. ISSA 的定位精度和收敛速度均优于其他算法. 定义算法完成收敛的判决条件为经过5 次迭代后RMSE 的改善小于0.001 m,
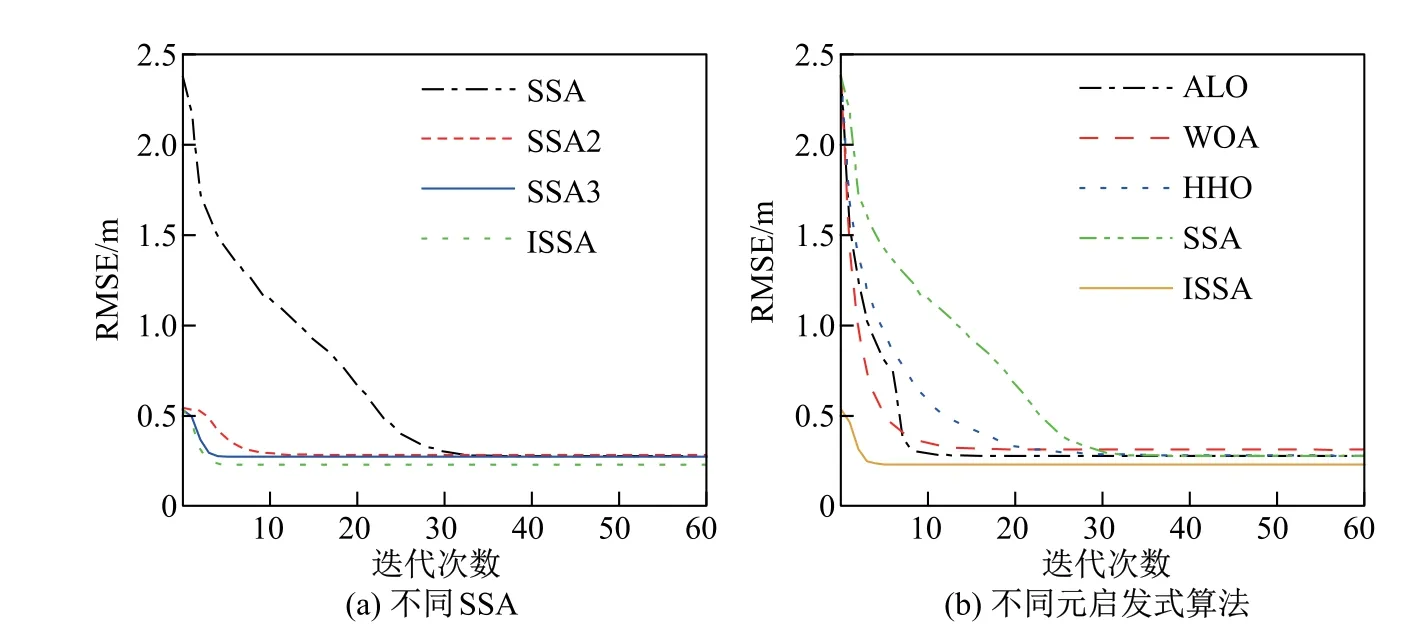
图3 不同算法收敛能力比较Fig.3 Comparison of convergence ability of different algorithms

式中:τ为完成收敛所需的迭代次数, 5<τ≤T. 保持仿真参数不变, 根据式(28)可以得到ALO 算法、WOA、HHO 算法、SSA、ISSA 完成收敛所需的迭代次数分别为20、24、45、42、12.表3 比较了不同最大迭代次数情况下各种算法的RMSE 和平均定位用时. 所有算法在达到收敛后, RMSE 不再随迭代次数的增加而明显下降. 当T= 60 时, ALO 算法、HHO 算法的平均定位用时长于SSA、WOA, 但WOA 定位精度较低. ISSA 在近似解和适应度函数方面相比SSA 增加了一定的计算量, 定位用时有所增加, 但ISSA 在实现高精度的同时, 需要的迭代次数最少, 可以通过设置较小的最大迭代次数实现最少的定位用时, 弥补了元启发式算法经过多次迭代才能收敛的缺点, 对于实现多用户的高频实时位置解算具有实际意义.

表3 RMSE 与平均定位用时比较Table 3 Comparison of RMSE and average localization time
5 结束语
本工作提出一种改进的樽海鞘群算法(ISSA), 并将其用于TDOA 定位问题. 通过选择最优主基站改进适应度函数, 提高了搜索精度, 并引入近似解和自适应跟随策略, 分别加快了算法前期和后期收敛速度. 与其他元启发式算法的定位性能仿真比较结果表明, ISSA 拥有更高的定位精度和更快的收敛速度, 弥补了元启发式算法运算量大的缺点, 对室内高精度实时定位算法的研究有一定参考价值.
