基于深度学习的图像抠图技术
2022-11-15王榕榕徐树公黄剑波
王榕榕 徐树公 黄剑波
(1. 上海大学上海电影学院, 上海 200072; 2. 上海大学上海先进通信与数据科学研究院, 上海 200444;3. 上海大学上海电影特效工程技术研究中心, 上海 200072)
图像抠图是将图像中的目标前景物体从背景图像中分割出来的技术, 是图像融合、图像增强复原等图像编辑技术的基础. 随着数字图像领域的不断发展与成熟, 图像抠图技术已经广泛应用于日常生活、影视制作、广告宣传等领域[1]. 手机、平板等移动端设备也推出了一些集成抠图功能的APP 应用[2], 以满足人们的日常需求.
传统的抠图算法通常根据颜色、纹理等低级特征从已知确定像素部分推测出不确定像素部分, 而没有利用高级语义信息, 这些方法并不适用于前背景颜色相似或者纹理复杂的图像,逐像素的处理方式也需较长时间, 而在日常应用场景中, 往往对抠取前景有高质量要求和快速处理大量图像的要求, 传统图像抠图方法难以满足实际应用需求.
近年来, 随着深度学习理论不断完善和网络大数据爆发时代的到来, Russakovsky 等[3]建立了ImageNet大型数据集, 该数据集依赖于大数据集的卷积神经网络, 在计算机视觉、自然语言处理等领域显示了强大生命力. 图像抠图与深度学习的结合也受到了广泛关注, 深度卷积神经网络的强大拟合能力, 能有效提取前景与背景之间的结构信息、语义信息, 因而不完全依赖于简单的颜色信息, 从而获得更好的抠图效果.
基于深度学习的抠图算法相比于传统算法在生成α图的质量上有了很大的提升, 本工作在原有深度学习抠图算法基础上, 根据抠图任务的特点做了相应的改进, 使得最终网络输出的α图在细节上有更好的预测结果.
1 相关工作
图像抠图的核心在于将图像中的前景物体和背景部分分离, 一张图像可以看作是前景图像和背景图像中的颜色按照一定权重(α透明度)结合[4]:

式中:Ii为像素块i的RGB 色彩值;Fi和Bi为前景图像和背景图像.
于是, 抠图任务就可以转换为求解上述方程中的α值, 即由Porter 等[4]首次提出的α通道, 表示前景与背景的混合比例. 但从像素层面来说, 前景图像和背景图像都包含R、G、B这3 个未知量, 则式(1)中有3 个已知量(原图的R、G、B值)和7 个未知量(前景图像和背景图像的R、G、B值以及α值), 由于一个约束方程显然是无法解出α值的, 故需要添加额外的辅助信息, 如三元图(trimap)和草图(scribble)(见图1). 其中使用最为广泛的是三元图, 包含有确定的前景像素值部分(如图1(b)中白色部分)、确定的背景部分(如图1(b)中黑色部分)和前背景结合的不确定部分(如图1(b)中灰色部分).

图1 辅助信息Fig.1 Auxiliary information
目前, 图像抠图方法主要有3 类: 基于采样、基于传播和基于深度学习.
(1) 基于采样. 在三元图标记的前景背景区域中为每个未标记像素选取候选样本集合, 再在其中选择合适的前景背景样本点对. 例如, Robust matting 法[5]会构建一个较大的候选样本集合, 在计算未知像素点的α值时, 从样本集合中选出相似度较高的几对样本点对, 计算其α值来作为该未知像素的α值.
(2) 基于传播. 在未知像素点周围局部小范围像素内, 通过具有相似性的已知像素点的α值的加权来估计该未知像素点的α值. 例如, KNN matting 法[6]选取未知像素高维特征空间中的前K个近邻来计算α值, 相似性的确定依赖于颜色、距离和纹理特性; Closed-form matting法[7]假设局部颜色分布遵循线性模型, 在此基础上构建了抠图拉普拉斯矩阵, 证明了前景图像的α值可以以封闭的形式进行求解.
(3) 基于深度学习. Learning based matting 法[8]中将抠图问题看作一个半监督学习问题,用更通用的学习方法拟合颜色模型来求解α值. 不同于Closed-form matting 法中的局部颜色满足线性模型的假设, 该方法引入核函数, 使预测α值更具有线性表达能力. 通过卷积神经网络拟合能力来估计α值, 如DCNN matting 法[9]是第一个将抠图任务和深度卷积神经网络相结合的方法, 该方法将KNN matting 法[6]和Closed-form matting 法[7]计算输出的α预测图和RGB 图像一起作为神经网络的输入, 以此融合局部与非局部的特征, 但整个网络只包含6个卷积层, 无法获得较好的拟合效果; 而Deep image matting (DIM)法[10]首次构建了可用于训练神经网络的抠图数据集, 在VGG16 网络基础上搭建了2 阶段深度卷积神经网络, 学习图像中的结构、颜色信息和语义信息等, 对α图从粗到细进行估计以达到最优值.
2 抠图网络设计
2.1 整体网络模型
本工作在DIM 法的网络结构基础上根据抠图任务的特点进行了如下2 个部分的改进.
(1) 由于抠图训练集个体图像之间差异较大, 易导致训练网络时的损失值产生较大振荡, 并且存在收敛速度慢的问题, 因此在DIM 原网络结构中的每层卷积层后面加上标准批量化(batch normalization, BN)层[11], 将网络中的批训练数据归一化可有效防止过拟合, 加快模型收敛速度; 设置训练时批量大小(batch size)为16, 代替DIM 训练时的1, 此时反向传播更新参数更符合数据集特性, 减少训练时损失振荡, 有更加稳定的回传梯度.
(2) 由于预测的未知区域一般集中于前景物体边缘部分, 故根据抠图任务的特点, 将原网络结构中的部分普通卷积层替换为可变形卷积(deformable convolution)层[12], 这样可有效扩大感受野范围, 卷积采样点更集中于物体边缘, 以获得更好的细节处理效果.
整个抠图网络的具体结构如图2 所示, 由原图和与其对应的三元图组成四通道输入, 经过下、上采样, 输出为一通道α图. 下采样的特征提取网络与VGG16 网络类似, 可按特征图大小变换分为5 个阶段, 将VGG16 网络中的最后一层全连接层替换为卷积层, 每个卷积结构都由卷积层、BN 层和Relu 激活函数组成. 针对抠图任务的特点, 将第3~5 阶段的2 个普通卷积层替换为可变形卷积层. 在下采样的卷积层和可变形卷积层中, 卷积核大小均为3×3, 卷积时步长为2, padding 为1, 即在卷积前后不改变特征图大小. 另外, 下采样时使用最大值池化操作来丢弃冗余信息, 并保留最大值池化映射; 在上采样时根据该映射进行反池化, 从而一步步扩大特征图, 以此更好地保留和恢复边缘信息; 在反池化层后接5×5 卷积核的卷积层, 将反池化后的稀疏特征图通过卷积计算得到更为稠密的特征图.

图2 抠图网络结构Fig.2 Matting network structure
2.1.1 BN 层
神经网0络的训练主要是学习数据的分布. 在基于深度学习完成图像抠图任务时, 由于抠图训练集中各图像差异较大, 又常设置batch size 为1 来进行训练, 因此每次输入网络训练数据的分布千差万别, 网络在每次迭代时需要进行大范围的参数更新以适应不同分布的数据, 整个网络在训练时不稳定, 且收敛慢. 如果在卷积层之间加入BN 层, 对输入卷积层的数据进行归一化处理, 则可有效改善训练过程中出现的不稳定、收敛慢等问题. 加入BN 层的具体公式为[11]

式中:m为批量输入网络的数据个数, 即batch size;xi为输入数据;μB和σ2B分别为输入数据的均值和方差; ^xi为归一化后数据;γ和β为2 个可学习参数;yi为经过BN 层后的输出数据.
由上述公式可以看出, BN 层的加入不仅使输入数据进行了归一化操作, 并且还引入了2 个可学习参数, 不影响网络的非线性表达能力. 因此, 在抠图网络的每层卷积后都加入了BN层, 并且设置batch size 为16 进行训练, 网络是在小批量数据的基础上进行参数更新, 更有利于网络进行有效的学习数据分布, 同时也加快了网络训练速度和收敛速度, 稳定网络训练过程, 防止过拟合.
2.1.2 可变形卷积
普通卷积层一般采用1×1、3×3 或5×5 等大小不一的正方形卷积核, 对于不同的输入数据都采用相同几何结构和尺寸的卷积核进行卷积计算, 因为有固定大小的感受野, 网络就无法根据输入数据的不同, 自适应地迎合物体尺寸、形状变换. 在原始卷积核的基础上, 添加学习的2 维偏移量, 根据物体形状进行调整, 偏移后的卷积核不再是固定形状, 更符合实际输入.以3×3 普通卷积核ω为例, 对于输入图像x在p0处的像素点, 卷积后得到y(p0)的具体公式[12]:

式中:R={(-1,-1),(-1,0),··· ,(0,1),(1,1)}, 即pn为p0处周围3×3 范围内的像素点位置. 而可变形卷积层在此基础上加入网络单独分支学习到的卷积核偏移量, 则上述p0处卷积操作可变为
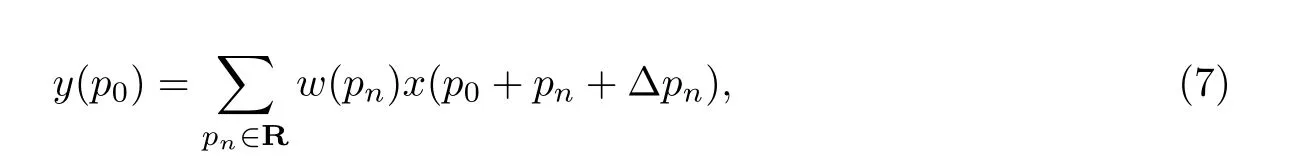
式中: Δpn为偏移值.
抠图任务主要是预测三元图中未知区域的α值, 而未知区域部分往往位于物体的边缘部分, 因此卷积核形状多变的可变形卷积层比普通卷积层更适合于进行抠图任务. 通过迭代学习, 可变性卷积层使网络能根据图像前背景特性来自适应学习卷积核, 卷积区域也会始终覆盖在物体形状的相关区域, 从而有效地扩大感受野范围, 更好地结合语义信息进行α图的估计.
2.2 模型训练
2.2.1 数据集合成
训练使用的是DIM[10]构建的数据集, 其中包含训练集的431 幅前景图像、测试集的50 幅前景图像.训练集中的每幅前景图像与100 幅不同的背景图像通过α图合成, 组成一个共43 100 幅图像的合成训练数据集, 测试集中的每幅前景图像与20 幅不同的背景图像进行合成,组成一个共1 000 幅图像的合成测试数据集Composition-1k, 其中背景图像来自目标检测数据集COCO 2014 和VOC 2007, 具体合成流程如图3 所示.

图3 数据集的合成Fig.3 Process of compositing dataset
2.2.2 三元图的生成
在抠图算法中, 三元图的辅助信息必不可少, 三元图的辅助信息越精确则最后的抠图结果越好. 训练网络所需的三元图是通过α图的腐蚀膨胀获得, 三元图生成过程如图4 所示. 图中,对α图白色区域进行腐蚀操作得到腐蚀图; 再对α图白色区域进行膨胀操作得到膨胀图; 将膨胀图与腐蚀图相减, 得到灰色未知区域; 将灰色未知区域与腐蚀后的白色区域相结合得到最终的三元图. 通过设置不同腐蚀膨胀率, 可以获得大小不同未知区域的三元图. 本工作中腐蚀膨胀核为1~5 之间的随机值, 迭代次数为1~20 之间的随机值, 可有效提高抠图网络的鲁棒性.

图4 三元图的生成过程Fig.4 Generation of trimap
2.2.3 模型训练
训练时使用如式(8)所示的损失函数, 计算预测的α图和Groundtruth 图(公开数据集提供的标准图, 即α真实值)之间的差异:

式中:αp为预测的α图;αg为Groundtruth;ε=1.0×10-6.
数据增广是深度学习模型训练时常用的技巧之一, 能在数据集数量有限的情况下增加训练数据的多样性, 提高模型的泛化性能. 在训练抠图网络时采用的数据增广方式有水平翻转、平移、裁剪、色彩变换, 其中裁剪是以三元图中的未知区域为中心, 进行一定大小的裁剪, 裁剪出像素为320×320、640×640 大小的图像, 送入网络进行训练.
训练时, 下采样网络采用经ImageNet 预训练的VGG16 网络参数进行初始化, 其中输入卷积层的第4 通道采用全0 初始化, 可变形卷积层和上采样网络卷积层中的参数使用Xavier初始化, 设置batch size 为16, 迭代30 次, 学习率设置为0.000 01, 在第20 次迭代时减小学习率为0.000 001, 采用Adam 优化器进行梯度下降优化参数.
3 实验分析
为了比较各方法优劣性, 本工作将几种传统方法和基于深度学习的抠图方法在Compsition-1k 上进行了测试. 评测是基于Rhemann 等[13]提出的4 个常用指标, 即绝对误差之和(sum of absolute difference, SAD)、均方误差(mean squared error, MSE)、Gradient 和Connectivity, 其中SAD 是计算预测α图和Groundtruth 各像素值之间的绝对误差和; MSE计算预测的α图和Groundtruth 各像素值之间的平均平方误差. 单纯比较二者之间的数值差异并不能全面衡量最终估计的α图质量, 因此本工作另外加入了2 个评价指标Gradient 和Connectivity 来评估整体误差, Gradient 指标主要计算二者的归一化梯度差异, 预测的α图和Groundtruth 越相似, 则该指标值越小; Connectivity 主要计算二者像素的连通性差异, 该指标值越小连通性越好,α图上的断点越少图像质量越好. 具体数值结果如表1 所示.
从表1 数据可以看出: DCNN matting 是基于深度学习的方法, 但由于缺少大型的训练数据集, 没有发挥出卷积神经网络的作用, 没有在KNN matting、Learning based matting 和Closed-form matting 传统方法的基础上有较大提升; DIM 构建了抠图数据集, 在抠图评测结果上有了大幅度的提升; 在DIM 网络基础上加入BN 结构, 虽然在SAD 指标上略微有性能下降, 但在MSE 和Gradient 2 个指标上均有提升, 并且在实验中网络的收敛速度明显加快; 用可变形卷积层替换普通卷积层在细节方面也获得了更好的效果, 在4 个评测指标上均有提升,其中Gradient 指标从36.7 提升至29.6.

表1 几种方法在Compsition-1k 测试集上的结果比较Table 1 Comparison results of several methods on Compsition-1k test set
几种方法在Compsition-1k 测试集上的结果图如图5 所示. 从图中可以看出,传统方法几乎不能在大片未知区域部分预测出图像前景的α值, 如灯泡的球体部分以及蒲公英的触须部分; DCNN matting 是基于深度学习的方法, 但从可视化结果图中也可以看出, 预测结果仍不理想, 在图像透明灯泡中的背景部分仍清稀可见; DIM 算法相比于传统算法有较好的预测结果, 但细节部分仍有缺失, 如灯泡的灯芯部分. 从实验结果可以看出, 在DIM 结构基础上加入了BN 层和可变形卷积层, 细节部分有了更精确的预测, 生成的α图也有更高的质量.

图5 几种方法Composition-1k 测试集上的部分结果Fig.5 Partial results of several methods on Composition-1k test set
表2 为几种方法在相同图像上的平均行计算时间, 其中DIM 和本方法是在GPU 2080 Ti 上计算所得. 由表2 可见, 基于深度学习的方法对于相同图像的计算远快于如KNN matting 等传统算法. 由于DCNN matting 输入包含KNN matting 和Closed-form matting 的结果, 故此处未进行运行时间的比较, 因为本方法用可变形卷积层替换普通卷积层引入了更多参数, 从而在运行时间上略慢于DIM, 但本方法在抠图结果上有更高的质量.

表2 几种方法运行时间比较Table 2 Comparison of running time of several methods
4 结束语
本工作提出了一种基于深度学习的抠图方法, 根据抠图任务的特点, 在原有下、上采样结构中的每层卷积层后加入了BN 层, 并且用可变形卷积层替换普通卷积层, 网络能根据不同的输入数据自适应学习卷积核的偏移量, 有效扩大图像的感受野. 实验表明, 这种改进使得抠图网络在Composition-1k 数据集上的4 个性能指标都有一定提升, 在生成的α图的细节部分也有更好的效果.
虽然本方法在测试数据集上获得了较好的结果, 但在实际应用过程中仍存在依赖GPU 硬件加速以及计算量大、速度慢的问题, 在以后的研究中仍要着重于减少网络参数, 用更轻量的结构来获得更优的效果. 另外在实际应用过程中, 对全新的任务来说三元图的获取也需要人工标注, 故在之后的研究中高质量三元图的自动生成也是一个重要的课题.
