基于YOLOv5的工厂化养殖虾目标检测方法研究
2022-11-11陈子文李卓璐杨志鹏何佳琦曹立杰蔡克卫王其华
陈子文,李卓璐,杨志鹏,何佳琦,曹立杰,3,蔡克卫,3,王其华
(1.大连海洋大学机械与动力工程学院,辽宁大连 116023;2.大连海洋大学信息工程学院,辽宁大连 116023;3.辽宁省海洋信息技术重点实验室,辽宁大连 116023;4.济宁医学院医学信息工程学院,山东日照 276800)
虾的工厂化养殖系统开发起源于20世纪90年代,国外主流工厂化养殖系统有美国德克萨斯海洋科学研究所研发的跑道式养虾系统[1]。我国工厂化养殖发展尚处于初级阶段,自动化程度低,亟需开发相关智能化系统[2]。目前,虾的工厂化养殖仍采用人工投喂方式,饵料投喂量需根据池内虾群密度确定[3]。传统养殖虾计数一般采用人工随机采样方式进行,劳动强度大,效率低,且易对虾的生长和循环水系统的净化负荷造成影响。
基于计算机视觉的养殖虾计数方法具有全程无接触、计数速度快等优势,可有效解决人工计数耗时耗力且对虾有一定损伤等问题。目前,计算机视觉技术在水产养殖中已经得到了较为广泛的应用。郭显久等[4]根据海洋微藻显微图像的特点,提出使用小波去噪、最大类间方差法等图像处理技术自动统计海洋微藻数量的方法;王文静等[5]对鱼苗图像进行阈值分割和目标提取后计算出每帧图像中的鱼苗数量。杨眉等[6]用canny算子提取扇贝边界像素,并使用BP算法对扇贝图像进行识别分类。王硕等[7]提出一种基于曲线演化的图像处理方法,实现对大菱鲆(Scophthalmusmaximus)鱼苗准确计数。
上述传统计算机视觉方法均在水产领域取得很好的应用,但仍存在计数误差较大、对重叠个体和差异较大个体计数不准确等缺点。随着深度卷积神经网络的迅速发展,基于深度学习的目标检测已经超越传统方法,成为当前目标检测的主流方法,并已被广泛应用于不同领域。基于深度学习的目标检测算法框架主要有R-CNN(region-convolutional neural networks)系列[8-10]、SSD(single shotmulti box detector)[11-12]和YOLO系列(you only look once)[13-16]等。目前,已有学者将其引入到农业工程领域,并取得较好效果。薛月菊等[17]使用改进的Fast R-CNN(fast regionconvolutional neural networks)针对深度图像设计了全天候的哺乳母猪姿态的自动识别。王羽徵等[18]利用改进式VGG16网络对水体中的单细胞藻类进行有效识别。一段式(one-stage)检测的代表算法YOLO在目标检测速度和算法效率上都有着不错的表现,该算法已在农业设施智能化研究中得到广泛应用;CAI等[19]使用改进版的YOLOv3深度神经网络模型实现了工厂化养殖环境下的红鳍东方鲀(Takifugu rubripes)的识别和计数。刘芳等[20]使用改进的多尺度YOLO实现了复杂环境下的番茄果实的快速识别。本文基于YOLOv5框架,采用少量高清图像样本,试图实现养殖虾的精准目标检测与计数。
工厂化养殖环境下,虾的游动速度较快,游动过程中的虾体形状和姿态存在较大的差异,需要利用高分辨率工业相机对养殖池进行抓拍,保证图像样本质量。然而,由于养殖环境差、样本采集成本高、所采集图像样本数量有限,且高分辨率图像直接压缩进行训练会导致图像细节缺失,直接影响检测精度。因此,针对上述问题,本文提出自适应裁片算法进行数据预处理,增强高分辨率下对虾的细节特征的学习效果,并基于YOLOv5框架进行数据集训练,实现养殖池内虾精准识别与计数,以期为实现科学喂养、定量投饵提供数据基础。
1 材料与方法
1.1 数据集
虾的工厂化养殖图像采用海康威视DS-2CD3T86FWDV2-15S摄像头,2.8 mm焦距镜头,114.5度视角进行拍摄采集。摄像头垂直固定于虾养殖盘正上方进行俯视拍摄,所采集图像为PNG格式,图像高度为3 000 Pixl,宽度为4 000 Pixl,2 min间隔拍摄,共采集图像181张。采集图像样本及其标注结果如图1所示。

图1 采集图像样例Fig.1 Example of captured images
本文数据集采用“LabelImg”标注工具进行人工标注,标注信息存储至txt标签文件,每个标签文件与图像文件一一对应,其中每行存放一个目标信息,信息依次为:目标类别、检测框中心点X、Y轴坐标以及目标宽度、高度。
1.2 YOLOv5
本文基于YOLOv5目标检测框架(图2)进行养殖虾图像分析并计数研究,该检测框架首先将图像划分成S×S个网格,然后判断目标检测框中心点是否处于某一网格内,再预测目标的坐标位置和目标置信度,最终实现多目标检测,在检测速度及准确率上相对前代算法有很大提升。
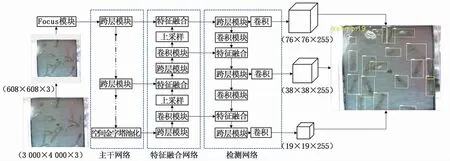
图2 YOLOv5网络结构Fig.2 Structure of YOLOv5
1.3 评价指标
本文采用平均精度均值(mean average precision,mAP)、准 确 率(precision)、召 回 率(recall)作为训练模型性能的评价指标。对于分类问题,可以根据真实的类别情况与模型预测的类别情况的组合将样例划分为真正例(true positive,TP)、假正例(false positive,FP)、真反例(true negative,TN)、假反例(false negative,FN)4种情况,分类结果混淆矩阵如表1所示。
准确率和召回率是一对矛盾的度量标准,准确率越高,召回率一般会偏低,反之亦然,由表1可得准确率P与召回率R计算公式为:

表1 分类结果混淆矩阵Tab.1 Classification results of confusion matrix

平均精度(AP)是衡量模型检测效果的常用标准,AP是召回率取值0到1时准确率的平均值,综合考虑了准确率和召回率,能够很好的衡量目标检测效果。mAP为所有类别的检测精度的平均值,是衡量模型预测目标的位置以及类别的度量标准,mAP的计算公式为:
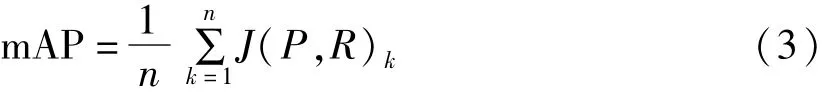
式(3)中,J(P,R)k为平均精度函数,计算方式为类别为编号k时的准确率P与召回率R构成的P-R曲线下方面积。
2 算法框架
2.1 算法整体框架
本文检测算法框图如图3所示。原始高清图像经过自适应裁切与标签映射后生成裁切图像数据集,并与原始图像混合作为总数据集,按照训练集70%与验证集30%的比例划分并输入检测网络进行训练,获得模型后,对养殖虾图像进行分析,实现目标检测与计数。
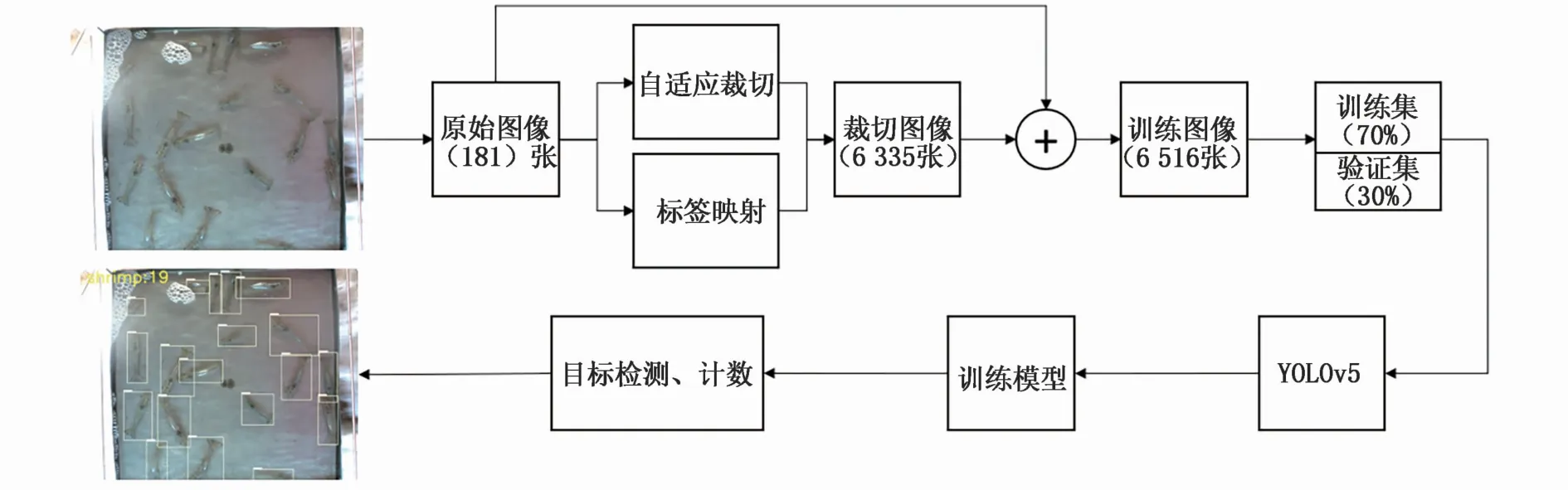
图3 养殖虾目标检测算法框图Fig.3 Block diagram of shrim p object detection algorithm
2.2 自适应图片裁切算法
2.2.1 图像裁切
为解决直接压缩高清图像导致细节丢失以及只有少量图像样本问题,本文设计提出一种根据网络输入图像尺寸自适应调节的高分辨率图像裁切算法,算法流程如图4所示。该算法根据原图尺寸与网络预处理输入图尺寸计算出裁切数量与裁切窗口滑动步长,计算公式为:
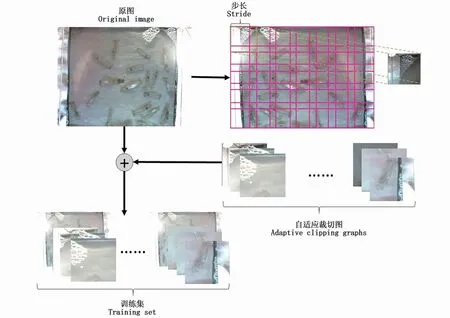
图4 自适应图片裁切算法流程Fig.4 Adaptive image clipping algorithm flow

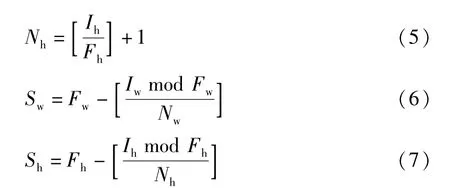
式(4)~式(7)中,Nw代表水平方向最终生成的裁切框的数量,Nh代表竖直方向最终生成的裁切框的数量,Iw代表原图的宽度,Ih代表原图的高度,Fw代表网络预处理后输入图的宽度,Fh代表网络预处理后输入图的高度,Sw为裁切框沿横向滑动的步长,Sh为裁切框沿纵向滑动的步长。
裁切所得图像与原图共同组成了检测模型数据集。本研究中原始图像分辨率为3 000×4 000,网络预处理输入图像尺寸为640×640,因此水平方向裁切框的数量为7,竖直方向裁切框数量为5,裁切框沿横向滑动的步长为602,裁切框沿纵向滑动的步长为552。原始图像数量为181,经过算法处理后,最终得到的图像样本量为6 516张。
2.2.2 标签映射
由于算法需要对图像进行裁切生成单独的图像,所以需要对标签文件内的坐标信息进行重新计算,在裁切图像的同时计算裁切后新图像的坐标信息,将原图的坐标映射到新生成的裁切图中。标签映射算法流程见算法1:

算法1标签映射Labelmapping输入:原图目标框(x1,y1,x2,y2),滑动窗口坐标(x3,y3,x4,y4)输出:裁切图目标框(xtop,ytop,xbot,ybot)1:function Labelmapping(x1,y1,x2,y2,x3,y3,x4,y4)2: if IoU([x1,y1,x2,y2],[x3,y3,x4,y4])>0 then 3: xtop=max(x1,x3)4: xbot=min(x2,x4)5: ytop=max(y1,y3)6: ybot=min(y2,y4)7: return xtop,ytop,xbot,ybot
其中,原图目标框为其左上角坐标(x1,y1)及右下角坐标(x2,y2),当前滑动裁切窗口坐标为其左上角坐标(x3,y3)与右下角坐标(x4,y4)。IoU函数用于计算两个矩形框的交集与并集的比值,计算公式为为原图目标框面积,B为滑动裁切窗口面积。max(x,y)为最大值函数,返回x、y中的最大值,min(x,y)为最小值函数,返回x,y中的最小值。经过计算获得裁切图目标检测框的标注映射坐标分别为左上角坐标(xtop,ytop)及右下角坐标(xbot,ybot)。
3 结果与分析
3.1 模型训练
为获得更快的收敛速度,减少训练时间成本,本文基于YOLOv5框架下YOLOv5s预训练权重进行迁移学习。其中,硬件平台参数中央处理器为Intel i7 7700k,图形计算卡为Nvidia GeForce GTX 1070 Ti,批量数为16,训练100轮,共迭代28 507次。
经过训练之后,得到目标检测模型,模型识别效果如图5所示。训练过程误差函数以及mAP曲线如图6曲线所示。

图5 检测效果展示Fig.5 Detection effect display
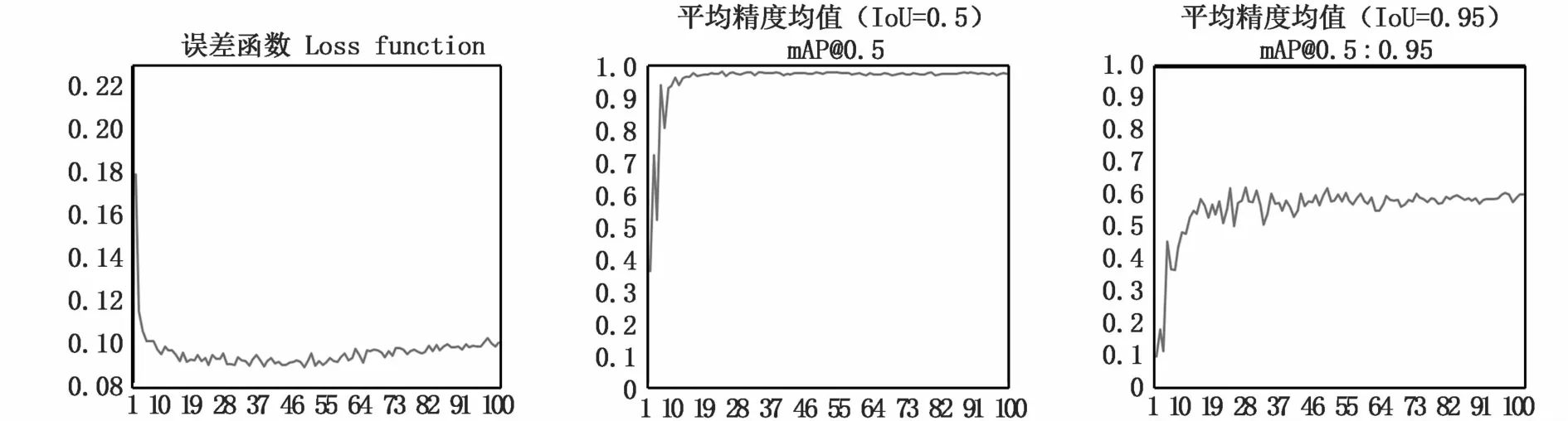
图6 模型训练参数Fig.6 Model training parameters
3.2 对比实验
本文将原始图像与自适应裁切算法生成的图像混合作为模型训练数据集,训练所得模型记为模型1。为证明本文提出自适应裁切算法的有效性,本文设计了另两组对比实验,分别使用原始图像作为训练集,训练所得模型2。以及仅使用自适应裁切算法生成的图像作为训练集,训练所得模型3。
3.2.1 模型参数分析
本文采用均值平均精度mAP、召回率、准确率作为评价指标,对3个模型训练效果进行评价,最终训练参数如表2所示。

表2 模型预测参数对比Tab.2 Comparison of prediction parameters of 3 models
经过100轮的训练之后,最终分别得到对应训练集1、训练集2、训练集3的3个模型——模型1、模型2、模型3。训练过程损失函数变化曲线如图7所示。结果显示,模型1可以很快收敛,并在第10轮训练的时候基本趋于稳定,模型2在训练开始阶段有较大的波动,并且在第28轮训练之后基本趋于稳定,模型3则波动范围较大,不易收敛。
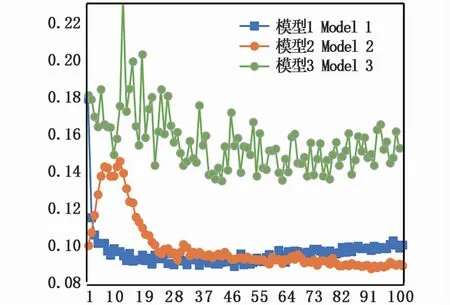
图7 误差函数对比Fig.7 Loss function comparison
图8为3个模型的平均精度均值(IoU=0.5)与平均精度均值(IoU=0.95)的折线图。由图8中可以看到,模型1的平均精度均值(IoU=0.5)在第10轮训练时已经基本达到稳定,最大值为97.5%,而模型2的平均精度均值(IoU=0.5)在第80轮训练才基本到达稳定,最大值为96.4%。模型3仅为85.2%。
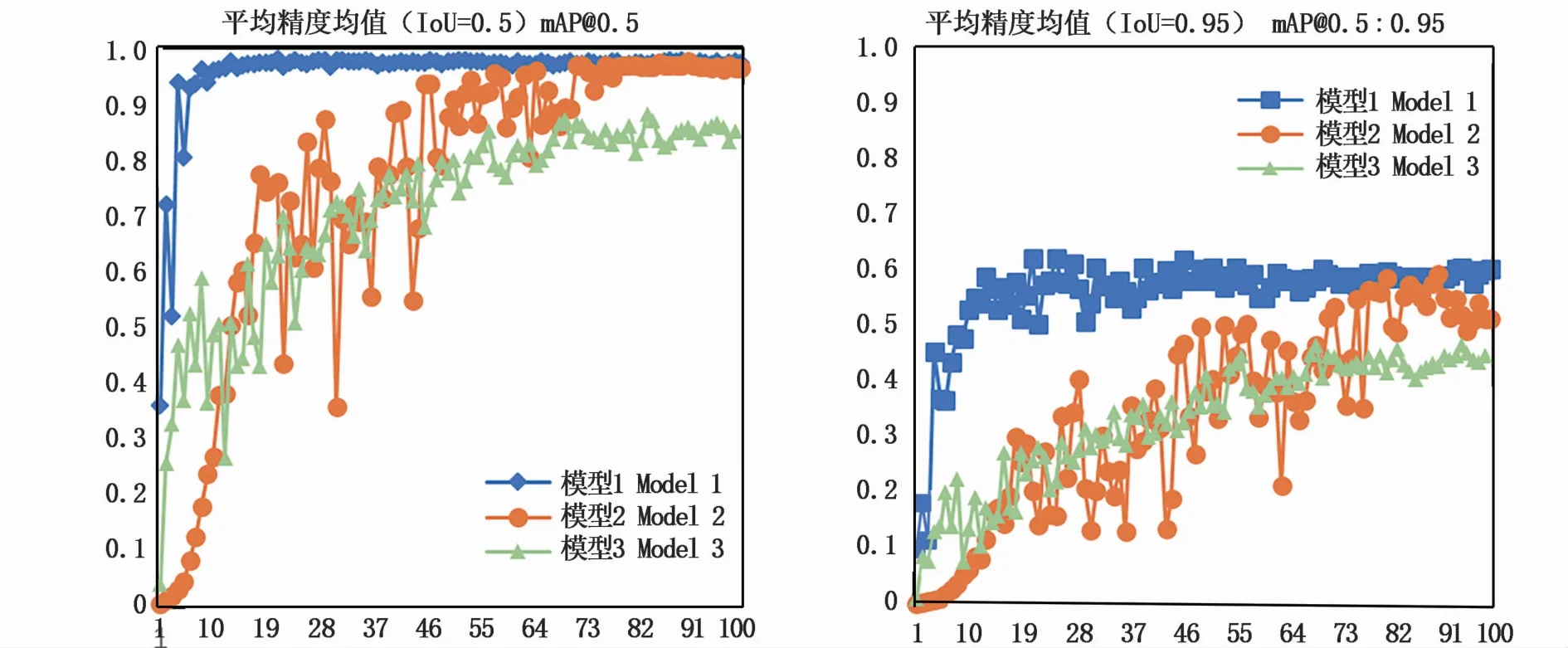
图8 平均精度均值对比Fig.8 m AP comparison
平均精度均值(IoU=0.95)能更好的衡量一个模型的实际检测性能,模型1的平均精度均值(IoU=0.95)的最大值为62.36%,模型2最大值为59.5%,而模型3只有46.7%。表明模型1在输出的预测框与真实的目标框有着很高的交并比,预测效果与真实值很接近。
准确率为对目标预测值与真实值的比值,是1个目标检测网络对目标识别准确性的评价标准。3个模型的准确率如图9-a所示,由曲线可见,得益于训练集图片自适应裁切算法,模型1仅仅训练了20轮就达到92.55%。模型3仅使用自适应裁切算法裁切后的图片进行训练,缺乏对整体特征的学习,最高准确率为89.02%。模型2仅使用高分辨率原图进行训练,压缩后无法学习到细节特征,最高准确率为85.43%。
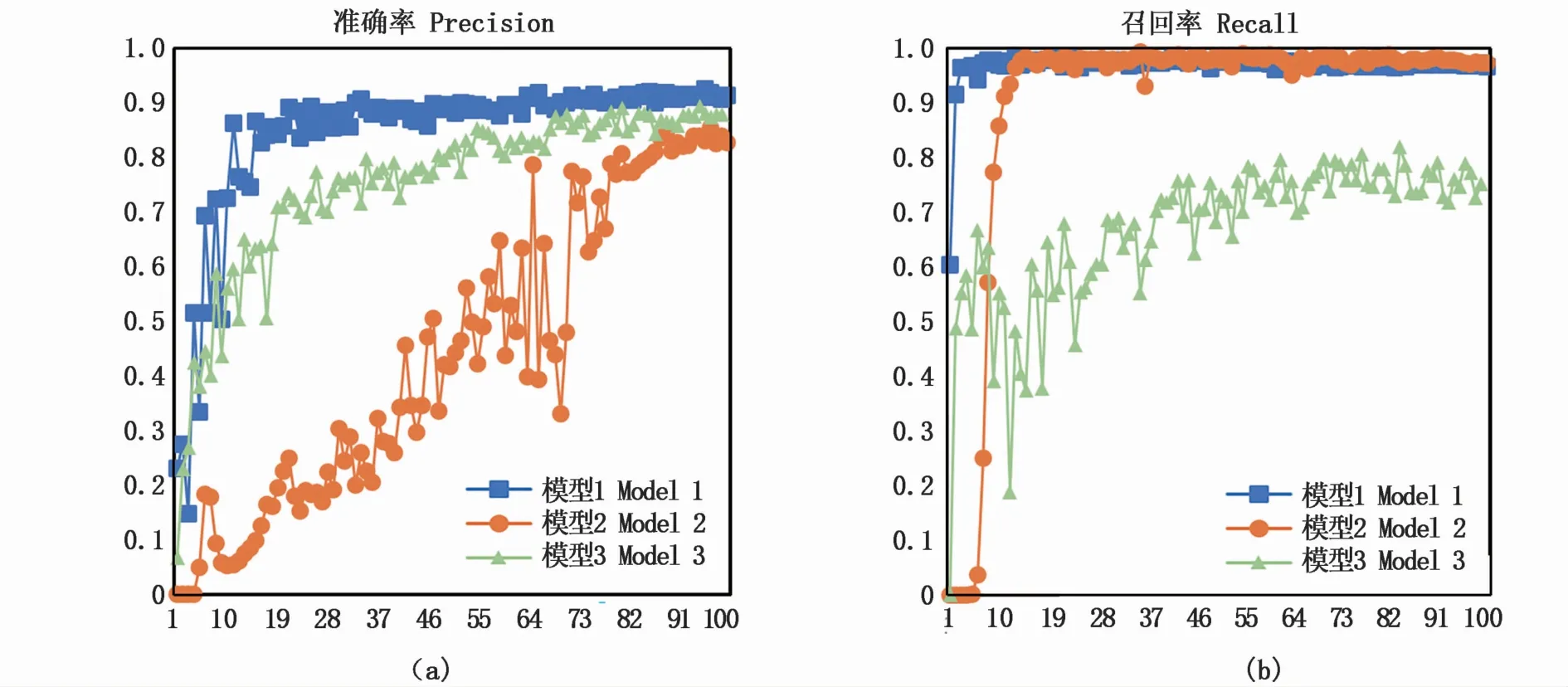
图9 准确率与召回率对比Fig.9 Com parison of precision and recall
召回率为检测的目标数量与所有目标数量的比值,是评价一个模型能否检测出所有目标的衡量标准。3个模型的召回率如图9-b所示,模型1的最大召回率为98.78%,模型2的最大召回率为98.42%,模型3的最大召回率为81.85%。由此可得,模型1在检测目标的查全度方面优于模型2与模型3。
3.2.2 检测效果分析
通过使用3个模型对高清图像进行预测,挑选出6组不同干扰环境下的预测图像进行对比。如图10所示,(a)组中模型1的检测与人工计数结果相同,相对于模型2,模型1成功检测到了图像下方有水面反光干扰的目标,而模型2与模型3均未检测到所有的虾;(b)组中模型1可以准确检测到被泡沫遮挡的虾。模型3出现了对重叠目标无法分辨的情况;(c)组中模型1检测到了图中被遮挡仅露出虾尾的目标,模型2与模型3均未检出全部目标;(d)组中模型1准确分开了1组高密度目标,并正确标记数量,而模型2与模型3出现了漏检;(e)组中模型1同样准确检出了被泡沫遮挡和水面反光干扰的目标;(f)组中模型1对非正常体位的虾进行了精确识别,而模型2与模型3因缺少此部分细节所以未能实现全部检出。

图10 检测计数效果对比Fig.10 Com parison of detection and counting effect
由此可见,使用自适应裁切算法训练的模型1无论是在虾被遮挡,或者是被水面反光干扰、扭曲变形的情况下,均能准确的检测出所有目标,并且能精确计数。
4 展望
本文算法仅仅在数据预处理部分进行了部分创新实验,证明了数据预处理算法对目标检测算法的影响。因此,如果将本文算法进行迁移到网络检测部分是否可行?以及如何有效减少高分辨率检测过程中的网络结构引起的特征损失,如何平衡分块检测的精度与检测时间的关系?将是下一步的主要方向。
