基于GitHub的高校图书馆开源项目开发制约因素分析
2022-11-10程逸凡
陈 萍,程逸凡
(1.南京医科大学 图书馆,江苏 南京 211166;2.南京邮电大学,江苏 南京 210046)
0 引言
大数据、区块链、人工智能、5G等新技术的迅猛发展,为高校图书馆的现代化转型发展带来了契机。针对科技浪潮对高校师生信息与服务需求在先进性、知识化、便捷化和智能化等方面带来的巨大变革,高校图书馆应主动积极融合各项新技术,以用户需求和偏好为导向[1],运用开源资源研发图书馆应用系统。2020年在美国得克萨斯农工大学举办了世界开放图书馆基金会会议[2](World Open Library Foundation Conference,WOLFcon),会上众多倡导开源运动的图书馆、开发人员、相关学者和开发商聚集在一起,共同对开源软件在图书馆的运用开展了深入的探讨,提出发展前景。高校图书馆可以此为契机,运用开源软件以适应新技术的发展趋势满足高校师生对图书馆的智慧服务需求。
本文针对高校图书馆运用基于GitHub开源软件进行应用系统开发存在的制约因素(Pull Request被拒绝),通过数据挖掘的关联规则,对GitHub上影响Pull Request被拒绝的影响因素进行了深入分析,并提出解决办法,为高校图书馆开源项目深入研发和应用提供技术支撑,提升高校图书馆数字服务能力。
1 相关技术的提出
版本控制系统(Version Control System)是配置管理的主要策略之一,允许开发人员通过开发和维护来控制对软件工件的更改[3]。分布式版本控制系统(Distributed Version Control System)的出现,则增强了支持协作软件开发的模式[4],分布式版本控制系统使开发人员可以控制多个远程存储库,从而使不同小组可以同时在同一项目上进行联合工作。这种系统的一个例子是Git,它记录了软件发展的整个历史。这样,项目托管工具被视为丰富的信息源,以支持配置管理过程。分布式版本控制系统的一个重要功能是系统化外部团队成员如何与核心团队成员进行协作[5]。外部成员可以克隆存储库,更改代码,然后请求将更改合并回主存储库。请求将更改合并回存储库的过程是通过Pull Request完成的,Pull Request中包含的贡献将由负责其分析的核心团队的任何成员选择接受或拒绝。
当前,GitHub被广泛用于软件开发行业[6],它是一种流行的分布式版本控制系统,用于开源项目中的源代码管理和控制。在GitHub中,Pull Request是代码贡献的首选方法[7],当开发人员希望将其代码更改合并到项目的主存储库中时,将提交Pull Request[8]。Pull Request状态有两种:接受和拒绝。Pull Request状态指示将源代码合并到主存储库中的权限。然而,GitHub上提交的大部分Pull Request事务都会被拒绝,这将会对开发项目和开发人员产生影响。被拒绝之后他们需要花费更多的精力来修改并重新提交Pull Request,等待提交的Pull Request被接受。如今,GitHub上有许多被拒绝的Pull Request事务,这将影响项目时间表和开发人员的工作,他们需要编辑或更改其代码,直到Pull Request被接受。
本文在分析GitHub开源开发模式的Pull Request被拒绝的因素过程中,考虑了社会关系、是否第一次进行Pull Request、删除计数、新增计数、提交计数、代码更改计数和Pull Request流程持续时间等诸多因素, 利用关联特征和关联规则中最常用的Apriori算法, 使用关联规则发现影响因素之间的关系,并将这些影响因素添加到组织或开源项目的编码指南中,成为开发人员将其代码更改合并到主存储库之前验证源代码的清单,以帮助开发人员提交的Pull Request尽量避免被拒绝。
2 影响开源项目中Pull Reguest合并结果的研究现状
Soares等[4]提出了在数据挖掘中使用关联规则方式找到影响因素。对于影响Pull Request的因素,他们采用了一种称为关联规则提取的数据挖掘技术来寻找影响因素。他们使用了GHTorrent工具,该工具从GitHub中提取信息,并设置10个属性作为数据的关键。对于在接受率高的软件项目中发现核心团队开发人员处理的Pull Request拒绝因素的解决方案,他们提出了一项关于增加核心团队成员处理的Pull Request被拒绝的研究。
Gousios等[9]和Soares等[4]都关注接受因素。前者关注评审者的视角,后者则应用定量技术提取关联规则,从而获得Pull Request认可。相反,本文主要关注被拒绝的Pull Request,以建立对拒绝原因的理解,通过应用定量方法来捕捉拒绝原因。
Terrell等[10]分析并讨论了接受Pull Request时的性别偏见。
Steinmacher[11]调查了Pull Request拒绝的原因。(1)询问了作者对他们的Pull Request被拒绝的原因的看法。(2)能够根据作者的意见建立一份拒绝理由清单。(3)交叉分析了拒绝原因列表,并对Pull Request数据集的一个子集进行手动分析。本研究采取了不同的方法。本文没有直接手动分析公关和调查公关作者,而是通过数据挖掘应用定量提取关联规则,并考虑了来自各种贡献者(内部和外部)的Pull Request。
3 挖掘影响开源项目中Pull Request被拒绝的方法主体
3.1 选择开源项目
获取多个GitHub开源项目数据集,本文选择Pull Request数量多的项目。获取多个星星数高的受欢迎的GitHub开源项目数据集,其中包括项目名称以及仓库名称、项目中具体的Pull Request 数量、项目的贡献者数量和星星数量。开源项目集如表1所示。
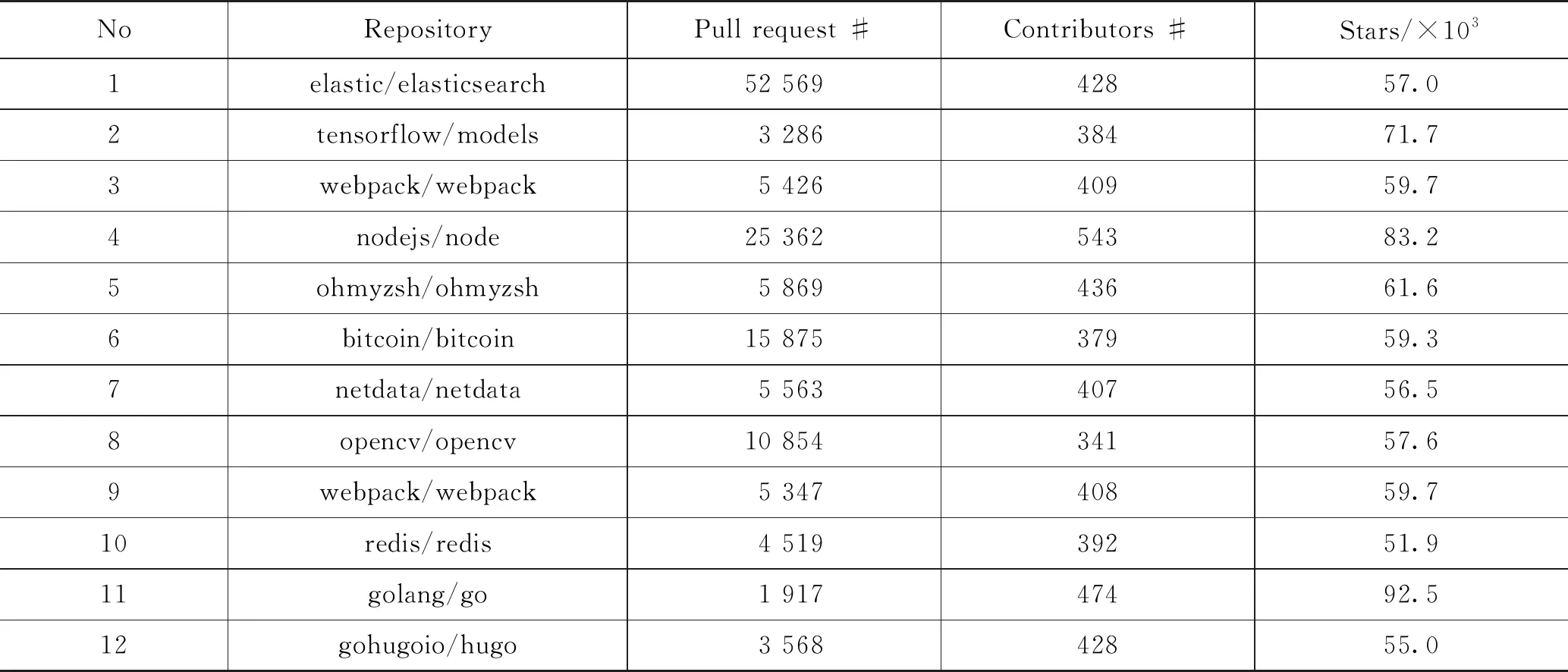
表1 Pull Request项目数据集
3.2 收集相关因素
通过两种方法可以找到相关的Pull Request评审结果因素:分析Pull Request上的标签和从相关工作中找到因素。标签是一个小的关键字,附加到Pull Request,并给出有关它的信息。Pull Request标签一般有两种类型:工作流标签和信息标签。工作流标签是识别Pull Request状态的关键,如合并、工作进行中等。信息标签是标识Pull Request一些有用信息的标签,如标识Pull Request的描述信息、标识Pull Request的平台等。信息标签也作为相关因素被应用。
许多相关的工作已经确定了GitHub上的Pull Request或代码评审因子。由于代码质量是识别Pull Request状态的关键,本研究中使用的相关工作中的多种因素不仅包括在GitHub上的Pull Request或代码审查,还包括代码质量指标,这些因素包括项目名称、Pull Request Ids、Pull Request是否合并、贡献者经验度、贡献者是不是第一次Pull Request、贡献者的社会关系、Pull Request描述相关信息、贡献者评论、Pull Request过程持续时间、Pull Request过程中评审者评论、文件修改数量、代码行增加数量、代码行删除数量、信息提交数量和Pull Request使用编程语言。这些因素的总结和描述如表2所示。
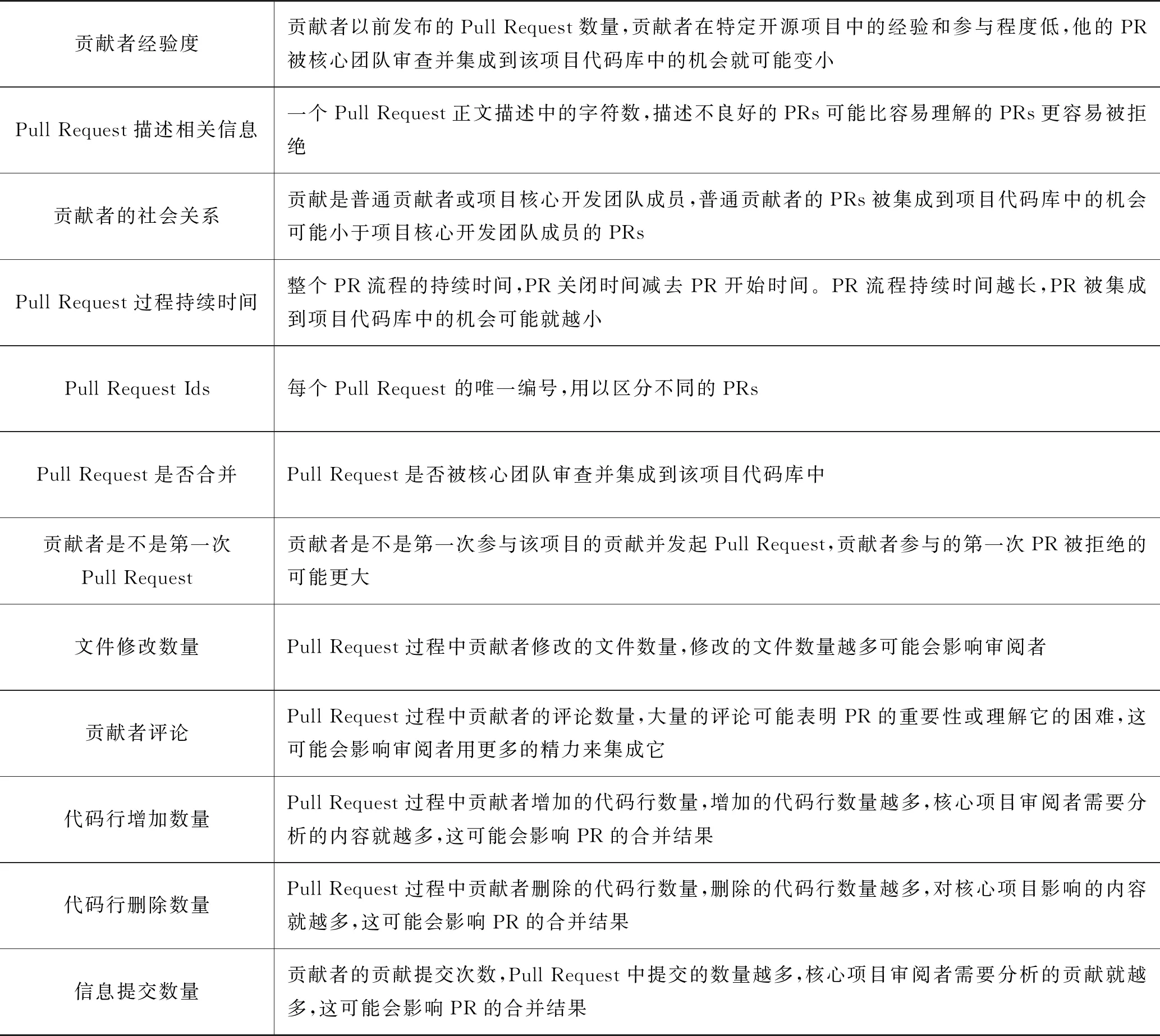
表2 相关因素总结和描述
3.3 选择算法和指标类型
Weka上提供了3种关联算法:Apriori、FilteredAssociator和FPGrowth。Apriori算法是本文所采用的算法。Apriori算法在给定的最小置信度下,不断减少最小支持度,直到完成所需规则数,其使用了基于给定支持度的剪枝手段,从而限制候选项集的指数级增长。
Apriori算法采用了逐层迭代的方法,先搜索出候选1项集及对应的支持度,剪枝去掉低于支持度的1项集,得到频繁1项集。然后对剩下的频繁1项集进行连接,得到候选2项集,筛选去掉低于支持度的候选2项集,得到频繁项集,以此类推,迭代下去,直到无法找到频繁k+1项集为止,对应的频繁k项集的集合即为算法的输出结果。
置信度、提升度、杠杆度和确定度是Apriori算法中的度量指标类型。为了发现影响因素之间的关系,需要使用指标度量类型,它是对关联规则进行排序的分数。置信度和提升度是本文研究选择的指标度量类型。
置信度Conf(Confidence)是本研究选择的第一个评估指标,计算置信度需要先计算另一个指标支持度Sup(support)。指标支持度Sup定义为满足前因条件的条件数量占数据库中总记录数的百分比。支持度Sup计算如下:Sup(X→Y)=T_(x∪y)/T,其中T_(x∪y)表示数据库D中同时满足条件X和条件Y的记录数量,T表示D中的总记录数量。置信度指标表示在前因事件发生的基础上后因事件发生的概率。置信度Conf计算如下:Conf(X→Y)=T_(x∪y)/T_x,其中T_x表示数据库D中满足条件X的记录数量。
在本文研究中考虑的另一个评估指标是提升度Lift,它表明在事件X发生的情况下,对事件Y条件发生概率的提升程度。Lift计算为规则的置信度与其结果支持度的商,提升度计算如下:Lift(X→Y)=Conf(X→Y)/Sup(X)。当Lift=1时,事件X和事件Y之间存在条件独立性,也就是说,前因事件X不干扰后因事件Y的发生。另一方面,Lift>1表示前因事件和后因事件之间存在正相关性,这意味着X事件的出现增加了Y事件的发生概率。相反,当Lift<1时,前因事件和后因事件之间存在负相关性,这表明前因事件X的发生反而降低了后因事件Y的发生概率。在本次研究中,兴趣度量(支持度、置信度和提升度)用于评估规则的相关性,这些规则指示了影响Pull Request合并失败的因素。
3.4 数据预处理
GitHub存储了开源项目的所有信息,不仅包括源代码,还包括图像、文档等,它是一个分布式的版本控制系统,需要存储开源项目的所有信息。本论文使用的数据发生时间参考到2021年10月的统计,因为分析的数据应该与本论文统计结果相关。Pull Request数据应该只发生在2021年10月之前。预处理数据有3个步骤:删除异常值,解决一些一致性和删除非编码的Pull Request。删除异常值,因为分析的因素需要统一类型的数据,所以删除了与统一数据类型不同的异常数据,例如删除非整数的数据变动数并删除整条Pull Request的数据记录。删除非编码的Pull Request,因为分析的数据需要分析和查找每个因素的值,所以判断过滤了其中没有进行代码变动的Pull Request,删除非编码的Pull Request。
4 研究结果分析
在完成相关因素的收集和处理后,将它们按照一条Pull Request的相关因素数据排列为一行的文本文件,将13多万条Pull Request信息处理输出为13行分类数据的文本作为后面实验的输入数据。部分相关因素如图1所示。

图1 Pull Request准备数据图
发现关联规则首先需要从数据集资料集合中找出频繁项集,频繁项的意思是某个项目组出现次数占比总记录数高于一个频繁设定标准,频繁项集则是所有频繁项的集合。某个项目组出现次数的频率称为支持度Sup,可以通过公式Sup(X)=T_x/T来求得项目组X的支持度,若支持度Sup大于等于所设定的最小支持度门槛值时,则称为频繁项。本文中设置最小支持度门槛值为0.25,由设置的最小支持度门槛值可以在准备数据中找出所有的频繁项集。通过找出的频繁项集来产生关联规则。一个满足最小支持度的k频繁项,可以称为高频k-频繁项,从频繁项集中产生关联规则,是利用前一步骤的高频k-频繁项来产生规则,在最小置信度的条件门槛下,若一规则所求得的置信度满足最小置信度,称此规则为关联规则。在本研究中设置最小置信度的条件门槛为0.5,由设置的最小置信度在频繁项集中提取影响Pull Request合并失败的关联规则,提取规则有四列,描述了表3中影响Pull Request失败的相关因素关联规则:规则表示规则编号,提取规则表示前后规则的发生模式;Conf表示各规则的置信度;Lift表示各规则的提升度。根据分析结果提取出的关联规则,由此得出提交的Pull Request被拒绝的影响因素以及影响的程度。
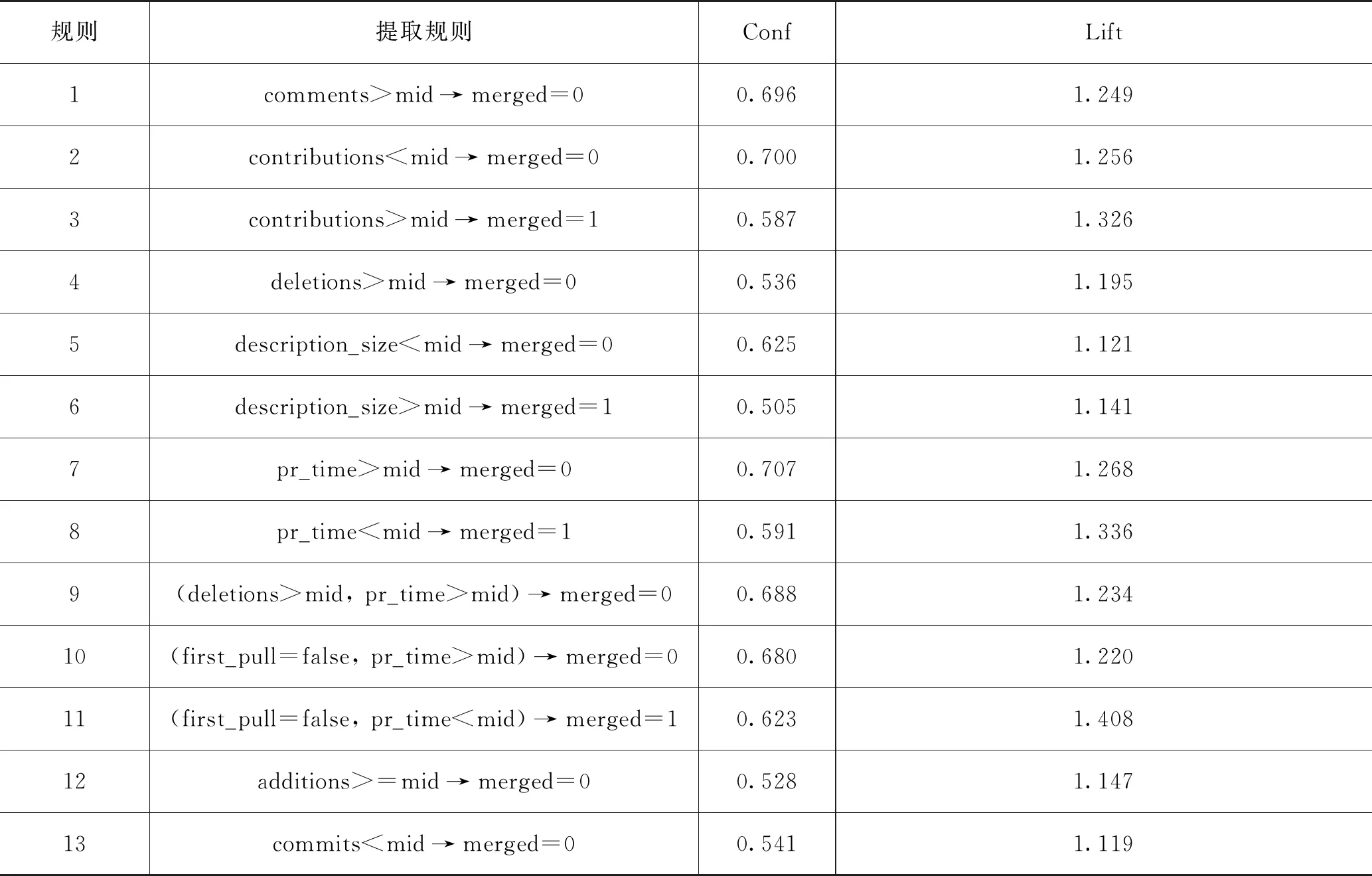
表3 关联规则
5 结语
本文针对高校图书馆在进行开源项目开发中出现的技术难点,利用数据挖掘关联规则,发现最密切影响开源项目中Pull Request被拒绝的影响因素是Pull Request评论过多、贡献者以前的Pull Request贡献度低、代码行删除数量过多、Pull Request描述相关信息过多、Pull Request过程持续时间过长、代码行增加数量过多、信息提交数量过少。文章提出帮助开发人员提交的Pull Request尽量避免被拒绝的方法,为高校图书馆在开源项目的开发和实施提供参考,努力促成图书馆领域现代技术生态系统的形成,在助力高校图书馆“十四五”期间现代化进程和跨越式转型发展[12]的同时,进一步推动高校图书馆由智能服务转向智慧服务。
