基于咖啡碱和氨基酸中碳氮稳定同位素比率的茶叶地理溯源
2022-10-31刘洪林杨天来
刘洪林,张 凯,黎 娇,李 照,杨天来,王 强
(1.重庆第二师范学院 脂质资源利用及儿童日化品研发重点实验室,重庆 400067;2.重庆第二师范学院旅游与服务管理学院,重庆 400067;3.重庆市农业技术推广总站,重庆 401121;4.重庆市规划和自然资源调查监测院,重庆 400014;5.西南大学食品科学学院,重庆 400715)
地理标志(geographical indication,GI)产品,是指在特定地区生产的,其质量、声誉或其他特性在本质上取决于该生产地的自然因素和人文因素,经审核批准以地理名称进行命名的产品。农民或制造商已引入GI保护农产品或食品,消费者认为GI产品具有优质的质量和特色,茶叶更是如此。中国名茶通常是受GI保护的产品,如西湖龙井、永川秀芽等,根据产地而命名。永川秀芽是典型的针状绿茶。虽然秀芽的定义有很多种,但正宗的永川秀芽必须产自中国重庆的永川。然而,对于消费者来说,永川秀芽与其他针状绿茶产品(如与其他非GI针状绿茶产品)具有相同的外形,很难区分。在市场上,人们常把永川秀芽与万州、秀山、江津、荣昌、宜宾等相近地区产的采用永川秀芽工艺加工而成的针型茶叶产品混淆。因此,有必要建立一种可靠的鉴别真品永川秀芽的方法,以保护利益相关者和消费者的利益。
稳定同位素技术适合用于茶叶地理溯源研究,因为不同元素的同位素组成提供了关于茶叶来源的充分信息。近年来,稳定同位素比值分析在茶叶地理溯源中得到了广泛的应用。天然有机质或组织中的同位素丰度不足以作为研究生物系统的生理特性、生物合成机制和营养来源的基础。事实上,代谢中的同位素效应导致代谢产物中H、O、C和N的同位素分布不均匀。因此,特异性化合物同位素比值分析(compounds specific isotope ratio analysis,CSIA)对于稳定同位素的生物和医学应用至关重要。CSIA不仅是鉴别茶叶来源的有效方法之一,也是了解茶树代谢的有效方法之一。咖啡碱是存在于咖啡()或茶()等一些植物的种子、叶子和根部的主要生物碱。通过多元素稳定同位素分析,咖啡碱已被用作咖啡豆地理来源的指示物。虽然通过咖啡碱分析茶的地理来源的初步研究早在20多年前就有报道,但进一步的应用和研究还没有进行,可能是因为获得足够数量的纯咖啡因进行稳定同位素分析需要很长时间。氨基酸(如组氨酸和苯丙氨酸)的C和N特征可用于区分不同植物种类对有效氮源的获取。氨基酸是植物(如茶)中占主导地位的低分子质量的含氮生物分子,这些化合物合成过程中的同位素分馏模式记录了植物生长环境的一系列信息,如植物在土壤中有效氮的形式。然而,对茶叶中咖啡碱和氨基酸中C和N特征分析还鲜有研究,本研究将探讨特征分析和地理溯源的可行性,为茶叶研究开辟新思路。
咖啡碱和氨基酸C 和N 通常由元素分析同位素比值质谱(elemental analysis isotope ratio mass spectrometry,EA-IRMS)测定。但是,该方法需要大量的高纯度咖啡碱进行测定,并且咖啡碱的提取和纯化费力且耗时。此外,在EA-IRMS测定之前的咖啡因提取/纯化过程中,咖啡碱的C和N可能会受到非定量恢复的影响。因此,提出一种利用气相色谱-燃烧-同位素比值质谱(gas chromatography combustion isotope ratio mass spectrometry,GC-C-IRMS)测定茶叶中咖啡碱和氨基酸C和N的分析方法。
本研究探讨利用咖啡碱和衍生氨基的氮和碳稳定同位素比值分析永川秀芽地理溯源的可行性。为了获得准确的C和N值,研究相关的潜在误差来源。利用GCC-IRMS测定不同产地的秀芽中咖啡碱和6 种主要游离态氨基酸的C和N特征,分析差异性及相关性,建立化学计量学模型,筛选出重要化学标记,以期为构建快速、可靠的茶叶地理溯源提供科学依据。
1 材料与方法
1.1 材料与试剂
采集来自重庆、四川等6 个不同地区的72 个秀芽茶叶样品(表1)。为了避免茶叶嫩度和季节变化的影响,所有茶叶于2019年3月采集,一芽一叶。采集含水率(约为5%)相同的茶叶样品,在40 ℃下冷冻保存。此外,再从这些地方随机采集36 个样品进行模型验证(不用于模型练习),只有一个序列号是盲样品处理。

表1 不同产地秀芽采样信息Table 1 Information about the geographical origin of Xiuya tea
氯仿(纯度99.0%)、氢氧化钠(纯度96.0%)、纯商用咖啡碱试剂(纯度98.0%) 日本和光纯药工业株式会社;无水硫酸钠 日本东京关东化学株式会社;IAEA-CH-7(纯度98.5%)、IAEA-600咖啡碱(纯度98.5%)、-谷氨酸标准品(纯度98.0%)、NBS-22燃料油、IAEA-CH-6蔗糖(纯度99.0%)、IAEA-NO硝酸钾(纯度98.0%) 北京博研科创生物技术有限公司;USGS 40-氨基酸标准品(丙氨酸、茶氨酸、谷氨酸、天冬氨酸、苏氨酸和丝氨酸)(纯度98%)、Amberlite IR120阳离子交换树脂(氢型)北京普天同创生物科技有限公司;乙腈衍生辅助试剂、-叔丁基二甲基甲硅烷基--甲基三氟乙酰胺(--butyldimethylsilyl--methyltrifluoroacetamide,MTBSTFA)衍生试剂、二氯甲烷(纯度99.8%)、异丙醇(纯度99.5%)、丙酮(纯度95.0%)、乙酸乙酯(纯度99%)、三乙胺(纯度99.5%)、醋酸酐(纯度98%)上海吉至生化科技有限公司。
1.2 仪器与设备
X-620型TP型匀浆器、ALC PK 131R离心机、GC IsoLink II+ConFlo IVIRMS、ISQ 7610单四极杆GC-MS、Delta V Advantage同位素比值质谱仪 美国赛默飞世尔科技公司。
1.3 方法
1.3.1 样品制备
分别称取0.1 g所有茶样,加入5 mL超纯水,沸水浴中浸提5 min,置于冷冻离心机中4 000 r/min离心10 min。将提取液用于咖啡碱中C和N、氨基酸中C和N的GC-C-IRMS测定。
1.3.2 咖啡碱的碳氮稳定同位素比率测定
1.3.2.1 咖啡碱标准品中C和N的测定
采用EA-IRMS法测定商业咖啡碱和IAEA-600咖啡碱的C和N。根据下式计算同位素比率:
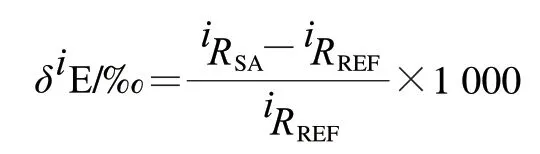
式中:为E元素较重同位素的质量数;为样品各自的同位素比率;为相关的国际公认参考物质比率。
1.3.2.2 样品前处理
精密量取茶样提取液1 mL,置于10 mL离心管中,加氯化钠饱和,摇匀。加2.5 mL乙腈,涡旋混匀1 min,超声10 min,2 500 r/min离心2 min。用吸管吸取上清液于10 mL容量瓶中,分别用2.5 mL乙腈提取残渣2 次,合并有机层,定容至刻度,加少量无水硫酸镁和少量中性氧化铝粉末,摇匀。静置后取1 μL供GC-C-IRMS进样分析。
1.3.2.3 GC-C-IRMS测定茶叶样品中咖啡碱的碳氮稳定同位素比率
GC条件:HP-1毛细管色谱柱(30 m×0.32 mm,0.25 μm);升温程序:起始温度40 ℃,保持2 min;以10 ℃/min升温至300 ℃,保持6 min;进样口温度200 ℃;不分流进样;载气为氦气;柱流速1 mL/min。
IRMS条件:元素分析仪高温燃烧炉温度设置为1 030 ℃,载气为氦气,流量为230 mL/min,氦反冲从第0秒开始,一直持续至第700秒,并在第1 990秒重新开始,直到分析结束。在第30、80、130、170、1 930、1 970秒引入6 组参考气体(CO)。在这些条件下,咖啡碱的保留时间约为1 200 s。
1.3.3 氨基酸的碳氮稳定同位素比率测定
1.3.3.1 非衍生氨基酸标准品中C和N的测定
利用EA-IRMS测定非衍生的单一氨基酸的C和N。对-谷氨酸标准品、NBS-22燃料油和IAEACH-6蔗糖进行了C计算,同时也对-谷氨酸和IAEANO硝酸钾进行了N计算。
1.3.3.2 氨基酸衍生条件
吸取一定体积的氨基酸标准品(10~100 μL,含10~100 nmol氨基酸)放入2 mL自动进样瓶中,加入40 nmol的正缬氨酸作为内标,置于氮吹仪中,室温下吹干。分别加入40~100 μL乙腈衍生辅助试剂、40~100 μL MTBSTFA衍生试剂(MTBSTFA与乙腈的体积比为1∶1),加入的体积依据不同的氨基酸体积而定,110 ℃衍生30 min,反应完成后冷却至室温,待用。
1.3.3.3 GC-C-IRMS测定茶叶样品中氨基酸的碳氮稳定同位素比率
用GC-C-IRMS测定茶叶中7 个氨基酸(丙氨酸、茶氨酸、谷氨酸、天冬氨酸、苏氨酸和丝氨酸)的同位素值。使用Trace GC Ultra与IRMS通过开放分流界面进行单体氨基酸同位素分析,并使用单四极GC-MS鉴定化合物。
N分析时GC条件:HP-INNOWAX毛细管色谱柱(60 m×0.32 mm,0.25 μm);不分流进样;进样量0.8~1.0 μL;载气为氦气;柱流速1.4 mL/min;进样口温度250 ℃。升温程序:起始温度为40 ℃,保持2 min;以40 ℃/min升温至14 ℃;2.5 ℃/min升温至180 ℃;6 ℃/min升温至220 ℃;最后以40 ℃/min速度升温至250 ℃,保持15 min。
C 分析时GC 条件:ZB-FFAP 毛细管色谱柱(30m×0.25 mm,0.25 μm);分流进样;进样量1.0 μL;柱流速1.0 mL/min;进样口温度250 ℃;GC柱温程序:起始温度40 ℃,保持1 min;以15 ℃/min升温至120 ℃;3 ℃/min升温至190 ℃;5 ℃/min升温至250 ℃,保持7 min。
IRMS条件:元素分析仪高温燃烧炉温度设置为1 030 ℃,载气为氦气,流量为230 mL/min。用Nafion膜组成的疏水阀除去水蒸气。对N进行分析时,在燃烧氧化反应器后加入液氮捕集器以从氧化和还原分析物中去除CO。
1.4 数据处理
采用SPSS v23.0软件进行单因素方差分析、线性判别分析(linear discriminant analysis,LDA)和BP人工神经网络(back propagation artificial neural network,BP-ANN)。使用SIMCA v13.0软件进行层次聚类分析(hierarchical clustering analysis,HCA)、主成分分析(principal component analysis,PCA)和偏最小二乘判别分析(partial least squares discriminant analysis,PLS-DA)。在进行PCA、HCA、LDA、PLS-DA和BPANN应用之前,所有变量都进行了自动缩放。
2 结果与分析
2.1 方法学验证
2.1.1 GC-C-IRMS测定咖啡碱C和N值方法学验证
将EA-IRMS测得的商用咖啡碱C和N值与GC-C-IRMS方法测得的C和N值进行比较,进行GC-C-IRMS的适用性考察。结果表明GC-C-IRMS与IRMS测定的咖啡碱C和N精度分别为0.15%、0.18%和0.13%、0.12%。其结果在相同精度范围内,且两种方法的相对标准偏差相似,均小于0.2%。因此,除了实验部分所描述的标准化之外,GC-C-IRMS无需任何校正因子即可使用。利用1.3.2节方法重复分析商用咖啡碱3 次,进行GC-C-IRMS的准确性考察,GC-C-IRMS测定的咖啡碱N的平均标准偏差为±0.15‰,C为±0.5‰。利用1.3.2节方法对永川秀芽样品重复提取10 次并测定其咖啡碱C和N值,考察GC-C-IRMS测定过程的不确定度。结果表明咖啡碱N的标准偏差为±0.1‰;C为±1.0‰。
2.1.2 GC-C-IRMS测定氨基酸C和N值方法学验证
将GC-C-IRMS测得的标准氨基酸混合物的C和N值与EA-IRMS测得的纯非衍生单氨基酸的同位素值进行比较,考察方法的适用性,实验均进行3 次重复。经校正后,EA-IRMS和GC-C-IRMS的氨基酸C和N测定值之差分别不高于±0.5‰和±1.6‰。利用1.3.3节方法对氨基酸对照品重复衍生10 次,每次重复衍生均进行3 次重复,以考察方法的准确性。GC-C-IRMS测定氨基酸N的平均标准偏差为±0.1‰,C为±0.5‰。利用1.3.3节方法对永川秀芽样品进行提取和衍生10 次,测定C和N值以考察方法的不确定度。结果表明氨基酸N的标准偏差为±0.2‰,C为±0.7‰。
2.2 不同地理来源茶叶中咖啡碱和主要游离态氨基酸中δ13C和δ15N的变化
从表2可以看出,不同化合物之间(咖啡碱、6 种主要游离态氨基酸)的C和N值会由于植物体内碳氮代谢过程中的同位素分馏而发生显著变化。所有茶样中咖啡碱的C平均值低于所有主要游离态氨基酸的C平均值。永川茶样和秀山茶样主要游离态氨基酸中丝氨酸C平均值>天冬氨酸>谷氨酸>丙氨酸>茶氨酸>苏氨酸,其余茶样部分氨基酸C平均值与永川和秀山茶样呈现的规律有所不同。同时研究发现,除荣昌茶样外,其余茶样谷氨酸N平均值>天冬氨酸>茶氨酸>咖啡碱>丙氨酸>苏氨酸>丝氨酸,荣昌茶样谷氨酸N平均值>天冬氨酸>茶氨酸>咖啡碱>丙氨酸>丝氨酸>苏氨酸。这种差异性可能与地域差异、耕作习俗等相关性较高。
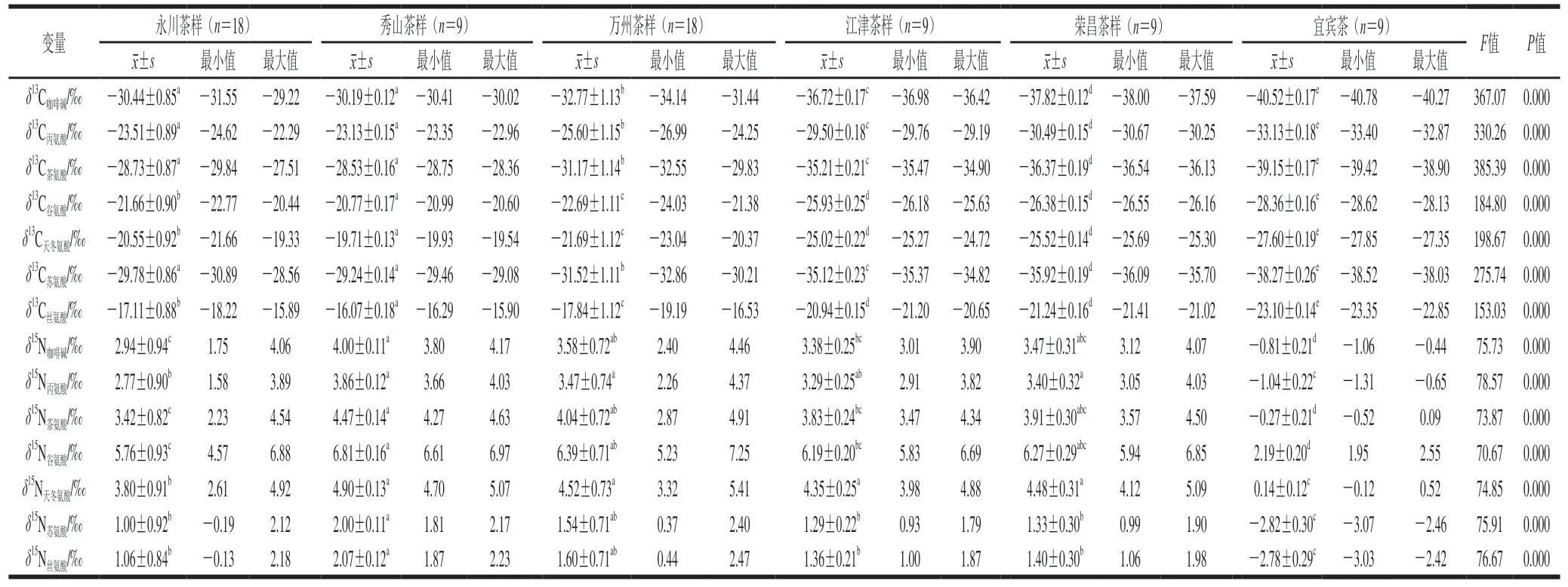
表2 不同产地茶中的咖啡碱和氨基酸的δ13C和δ15N值Table 2 δ13C and δ15N values of caffeine and amino acids in tea samples from different production regions
单因素方差分析结果显示(表2),按照不同产地对茶样品进行分组,秀山茶样中谷氨酸、天冬氨酸和丝氨酸的C显著高于其他地区的茶样;秀山茶样中咖啡碱、丙氨酸、茶氨酸和苏氨酸的C显著高于万州、江津、荣昌和宜宾4 个地区的茶样但与永川地区的茶样差异不显著,这可能与两地环境相似有关。而永川茶样咖啡碱和6 个主要游离态氨基酸的C也显著高于万州、江津、荣昌和宜宾4 个地区的茶样。万州茶样咖啡碱和6 个主要游离态氨基酸的C值显著高于江津、荣昌和宜宾3 个地区的茶样。江津和荣昌茶样中谷氨酸、天冬氨酸和丝氨酸的C值差异不显著,江津茶样中其他化合物的C值显著高于荣昌茶样。宜宾茶样咖啡碱和6 个主要游离态氨基酸的C值显著低于其他5 个地区的茶样。此外,秀山茶样中咖啡碱和6 种主要游离态氨基酸的N值显著高于永川和宜宾茶样;秀山茶样中咖啡碱、茶氨酸、谷氨酸、苏氨酸和丝氨酸的N值显著高于江津茶样;秀山茶样中苏氨酸和丝氨酸的N值显著高于荣昌茶样。万州、江津和荣昌茶样中咖啡碱和6 种主要游离态氨基酸的N值高于永川茶样,显著高于宜宾茶样;但万州、江津和荣昌茶样中的咖啡碱和6 种主要游离态氨基酸的N值差异不显著。永川茶样咖啡碱和6 种主要游离态氨基酸的N值显著高于宜宾茶样。造成这一系列的差异性与每个地区环境、耕作习俗等综合因素有关,机理有待进一步研究。
虽然这些变量均具有统计学意义,但在同一地区茶样中,各化合物的C和N最小值与最大值存在较大差异(表2),单一变量也无法准确改善茶叶产品地理溯源。为了更加准确进行地理溯源,利用化学计量学结合这些具有统计学意义的多变量对不同产地茶叶样品进行聚类趋势评价。
2.3 不同地理来源茶叶的无监督识别分析
2.3.1 不同地理来源茶叶的HCA
如图1所示,HCA主要描述了2 个变量聚类。聚类到同一聚类树的稳定同位素比值证明其相关性较高,性质相似。所有化合物的C值聚类到了同一聚类,证明茶叶中咖啡碱和6 种主要游离态氨基酸的C值之间存在较强相关性。同时可以看出,所有化合物的N值聚类到了同一聚类,证明茶叶中咖啡碱和6 种主要游离态氨基酸的N值之间也存在较强相关性,这些结果证实了2.2节中的结果,不同化合物间C值和N值均具有相似性。
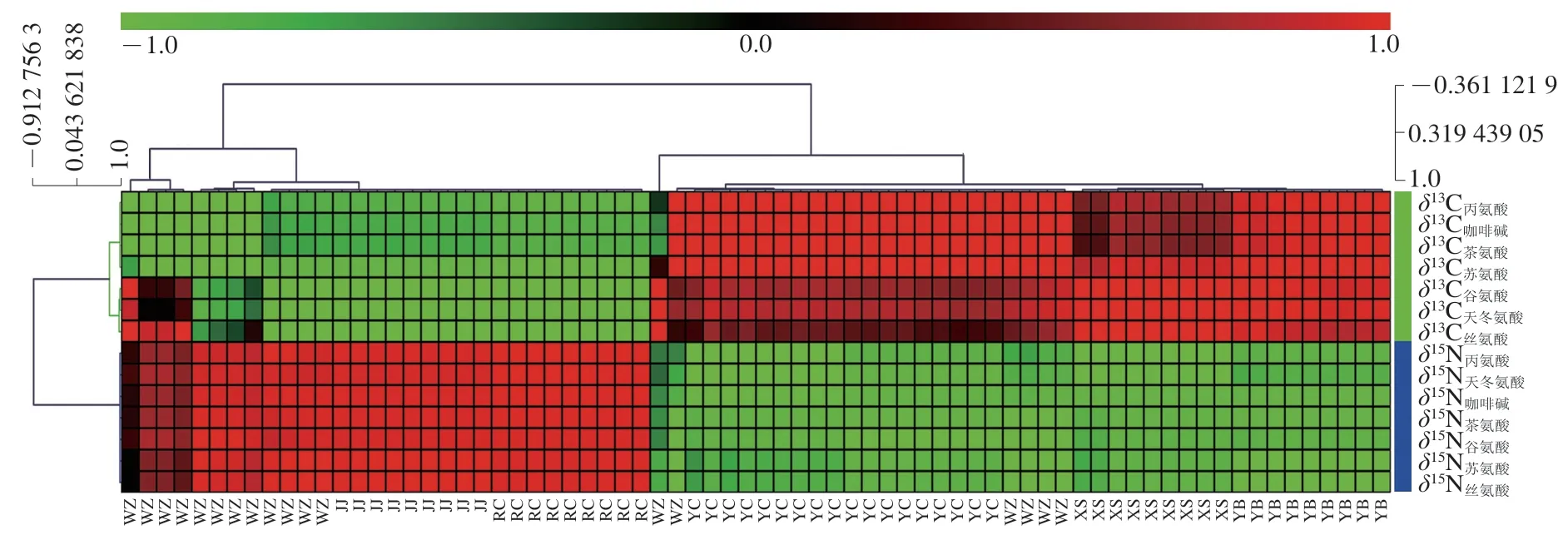
图1 不同地区茶样中基于咖啡碱和6 种主要游离态氨基酸δ13C和δ15N的HCAFig.1 HCA heatmap of δ13C and δ15N of caffeine and six major free amino acids in tea samples from different regions
此外,HCA还显示了多个样本聚类,表明不同地理来源的茶叶分组效果较差。仅有宜宾茶样和秀山茶样能分别单独聚类到同一个集群。永川茶样和万州茶样混淆,荣昌茶样、江津茶样和万州茶样混淆,无法区分开来。这可能是由于永川与万州,荣昌、江津与万州茶样生长时某些土壤性质或环境条件的相似性所致。因此,采用HCA结合咖啡碱和6 种主要游离态氨基酸的14 个C和N值对不同地理来源的茶叶无法有效分组。
2.3.2 不同地理来源茶叶的PCA
由图2可知,PC1和PC2分别代表6 个地区的茶样可变性的方差贡献率,为82.9%和16.9%,前2 个PC的累计方差贡献率较高(99.81%),表明此模型PCA分类性能较强。从图2A可以看出,永川、秀山、万州、荣昌、江津和宜宾6 个地区的茶叶样品根据产地不同有明显差异,仅永川茶样和秀山茶样有一小部分重叠。从图2B可以观察到,PC1和PC2中大部分变量的方差贡献相差不大,均有较大贡献,无突出贡献变量。此外,PC1能将江津茶样、荣昌茶样和宜宾茶样区分开来,PC2能将万州茶样区分开来。总体而言,不同产地茶样品可根据咖啡碱和6 个主要游离态氨基酸的C和N值指纹图谱的PCA初步分组。
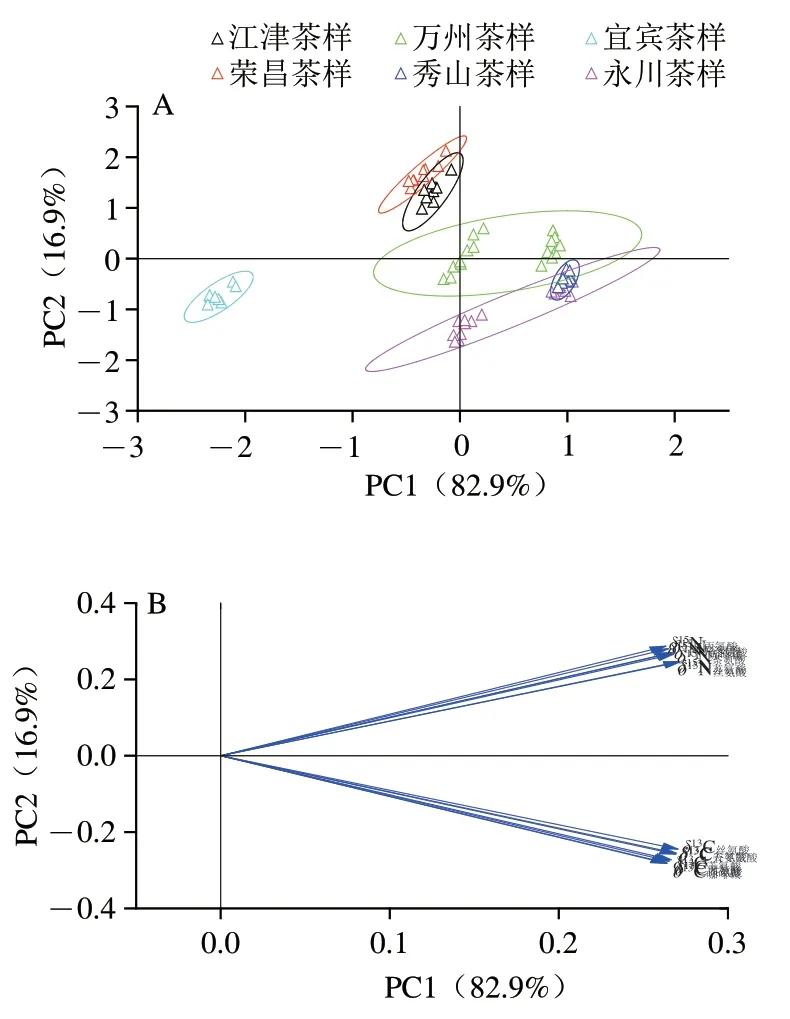
图2 不同地区茶样中基于咖啡碱和6 种主要游离态氨基酸δ13C和δ15N的PCA得分图(A)和载荷图(B)Fig.2 PCA score plot (A) and loading plot (B) of δ13C and δ15N of caffeine and six major free amino acids in tea samples from different regions
通过两种无监督模式识别方法的应用,观察到6 个地区的茶叶样品在原始数据矩阵中的自然分组,表明样本有分组趋势,且PCA分组效果更好。虽然HCA和PCA可以提供样本聚类的可视化图像,但它不能提供关于聚类质量和聚类置信度的信息。因此,使用其他监督识别的化学计量方法,进一步对不同产地茶样进行地理溯源分析。
2.4 不同地理来源茶叶的有监督识别分析
2.4.1 不同地理来源茶叶的PLS-DA
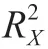
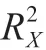
经PLS-DA模型得到变量投影重要性(variable importance in projection,VIP)值,如图3C所示。选择VIP>1的重要变量(C、C、C、C、C、C和N)作为在PLS-DA模型中改进茶叶地理溯源最重要的化学标记。

图3 不同地区茶样中基于咖啡碱和6 种主要游离态氨基酸δ13C和δ15N的PLS-DA得分图(A)、载荷图(B)和VIP值(C)Fig.3 PLS-DA score plot (A),loading plot (B) and VIP value (C) of δ13C and δ15N of caffeine and six major free amino acids in tea samples from different regions
2.4.2 不同地理来源茶叶的BP-ANN分析
设置BP-ANN模型的输入层、隐藏层和输出层分别有14、5 个和6 个神经元,隐含层层数为1。从茶样中随机抽取70%的样本作为训练集,剩余30%的样本作为外部验证测试的测试集,用于评价模型的识别能力和预测能力,结果如表3所示。在模型训练过程中,所有茶叶样品可以成功地分为6 组,代表相应不同产地的茶样;BPANN模型识别能力的准确率为100.0%。用BP-ANN模型对测试集预测发现,有30%的样本被正确预测为6 组,总体预测准确率为100.0%,说明本BP-ANN模型具有极好的适用性。与PLS-DA模型相比,BP-ANN模型的性能和效果在改进茶叶地理溯源上更好,这与BP-ANN算法有关。如图4所示,经BP-ANN分析得到变量重要性,可作为改进茶叶产地溯源的7 个最重要的化学标记,为C、C、C、C、C、N和C。

图4 不同地区茶样中基于咖啡碱和6 种主要游离态氨基酸δ13C和δ15N的BP-ANN变量重要性Fig.4 BP-ANN variable importance of δ13C and δ15N of caffeine and six major free amino acids in tea samples from different regions
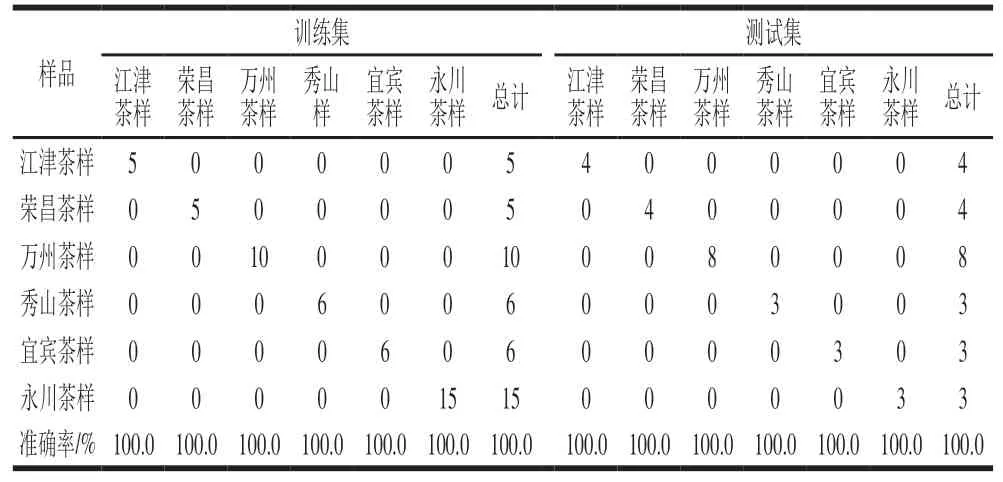
表3 BP-ANN模型的模型训练和预测结果Table 3 Results of model training and prediction of BP-ANN model
2.4.3 不同地理来源茶叶的LDA
将茶叶样本数据分为训练集和交叉验证集(均为随机抽取70%茶样数据)和测试集(剩余的30%茶样数据)用于外部验证输入LDA模型。结果表明,形成了两个具有统计学意义的Fisher判别函数:第1个Fisher判别函数中Wilks’ Lambda系数=0.003,卡方()=262.82,自由度=10,<0.001;第2个Fisher判别函数Wilks’ Lambda系数=0.167,=80.60,自由度=4,<0.001。Wilks’Lambda值的显著性表明判别函数是种群分化的基础。第1个Fisher判别函数占总方差的91.9%,第2个Fisher判别函数占总方差的8.1%。两者共占总方差的100.0%,结果覆盖面极好。
经Wilks’ Lambda步进式方法选择变量后,简化后的模型中纳入了化学标记N和C。由图5可知,茶叶的地理溯源得到了较好的改进分类。第1个Fisher判别函数对永川茶样、秀山茶样、万州茶样和荣昌茶样具有明显的证实作用;第2个Fisher判别函数对宜宾茶样具有明显的证实作用。如表4所示,识别能力以模型训练中茶样按产区正确分类的百分比表示,总体准确率为98.0%,结果很好;模型对永川茶样识别效果相对较差,有样品被错误识别到秀山样品中,正确率为92.3%。这可能是永川和秀山地区相似的耕作、采摘习俗、环境等综合因素造成。采用典型的交叉验证和外部验证方法以茶样按产区正确分类的批次百分比表示预测能力,交叉验证方法的预测总准确率为96.0%;其中永川茶样准确率仅为84.6%,这与训练集的结果相似,与秀山茶样混淆。外部验证方法的预测总准确率为95.5%,该方法预测结果较好;其中江津茶样的准确率低(66.7%),可能与样本数量不足有关。后期研究需扩大样本量以提高证实的准确性。
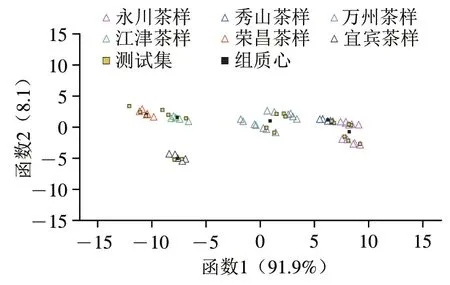
图5 基于咖啡碱和6 种主要游离态氨基酸δ13C和δ15N值的茶叶地理溯源的LDA模型得分图Fig.5 Score plot of LDA model for geographical traceability of tea samples on the basis of δ13C and δ15N of caffeine and six major amino acids
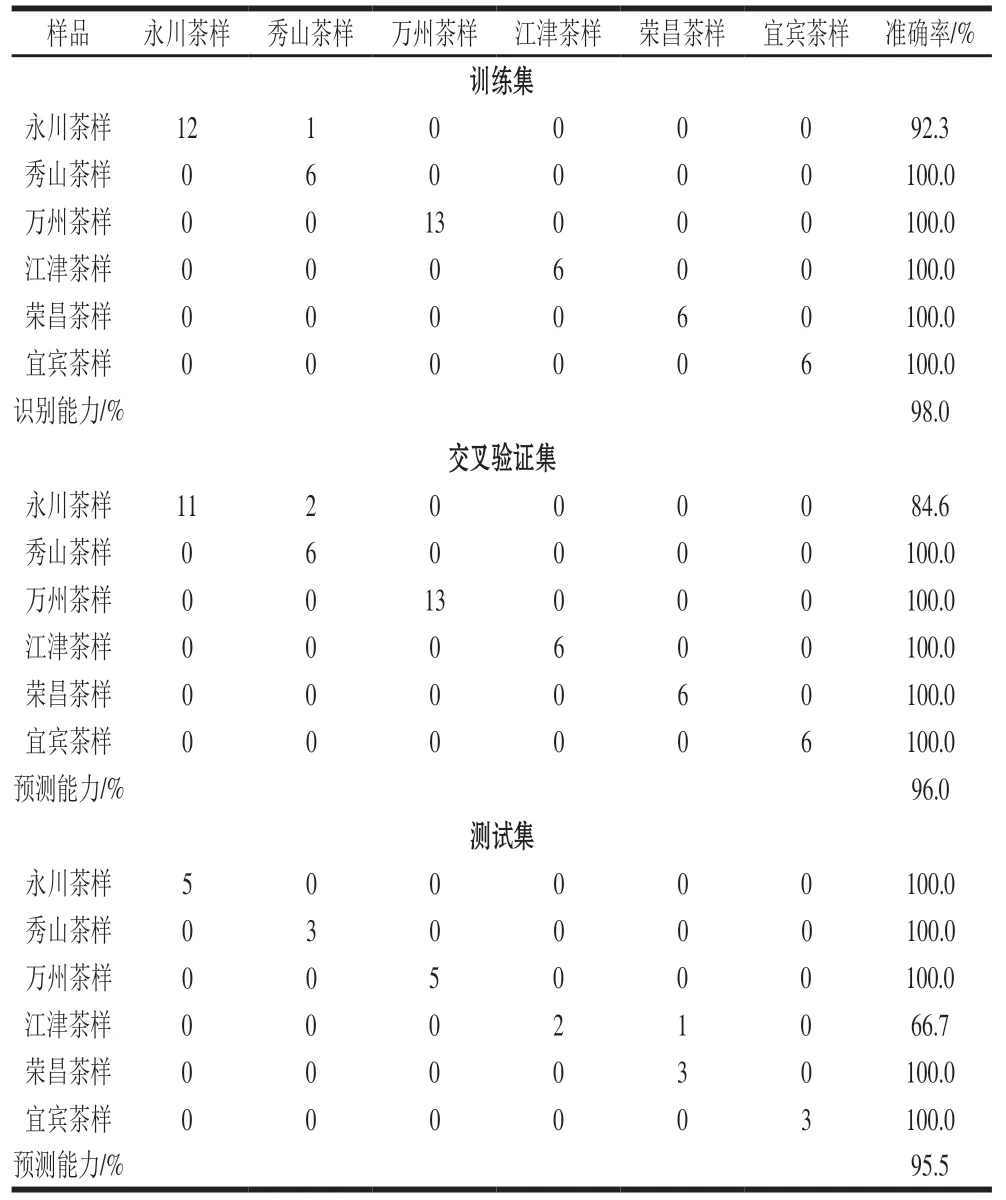
表4 LDA模型的模型训练、交叉验证和预测结果Table 4 Results of model training,cross-validation,and prediction of LDA model
对比3 个预测模型性能,BP-ANN模型的识别和预测能力优于PLS-DA模型和LDA模型。因此,使用咖啡碱和6 种主要游离态氨基酸的C和N值进行茶叶地理溯源,BP-ANN模型是其最佳认证方法。此外,3 种模型共同筛选出N和C为茶叶产地溯源中最重要的化学标记。
2.4.4 各预测模型在盲数据集的验证性能
为进一步提高化学计量学应用于计算的稳定性,比较各模型的验证性能,使用PLS-DA、BP-ANN和LDA方法对盲数据进行识别。由表5可知,PLS-DA、BP-ANN和LDA方法的总体正确率分别为88.9%、94.4%和91.7%。在3 个模型中,秀山茶样和宜宾茶样的预测准确率均为100%,永川茶样的预测准确率分别为88.9%、88.9%和77.8%,万州茶样的预测准确率分别为88.9%、88.9%和100%,江津茶样的预测正确率均为80%,荣昌茶样的预测准确率分别为75%、100%和100%。从这些结果可以看出,使用咖啡碱和6 种主要游离态氨基酸的C和N值进行茶叶地理溯源时,多数情况下BP-ANN模型可以最好地证实茶叶的地理来源,显示最佳验证性能。
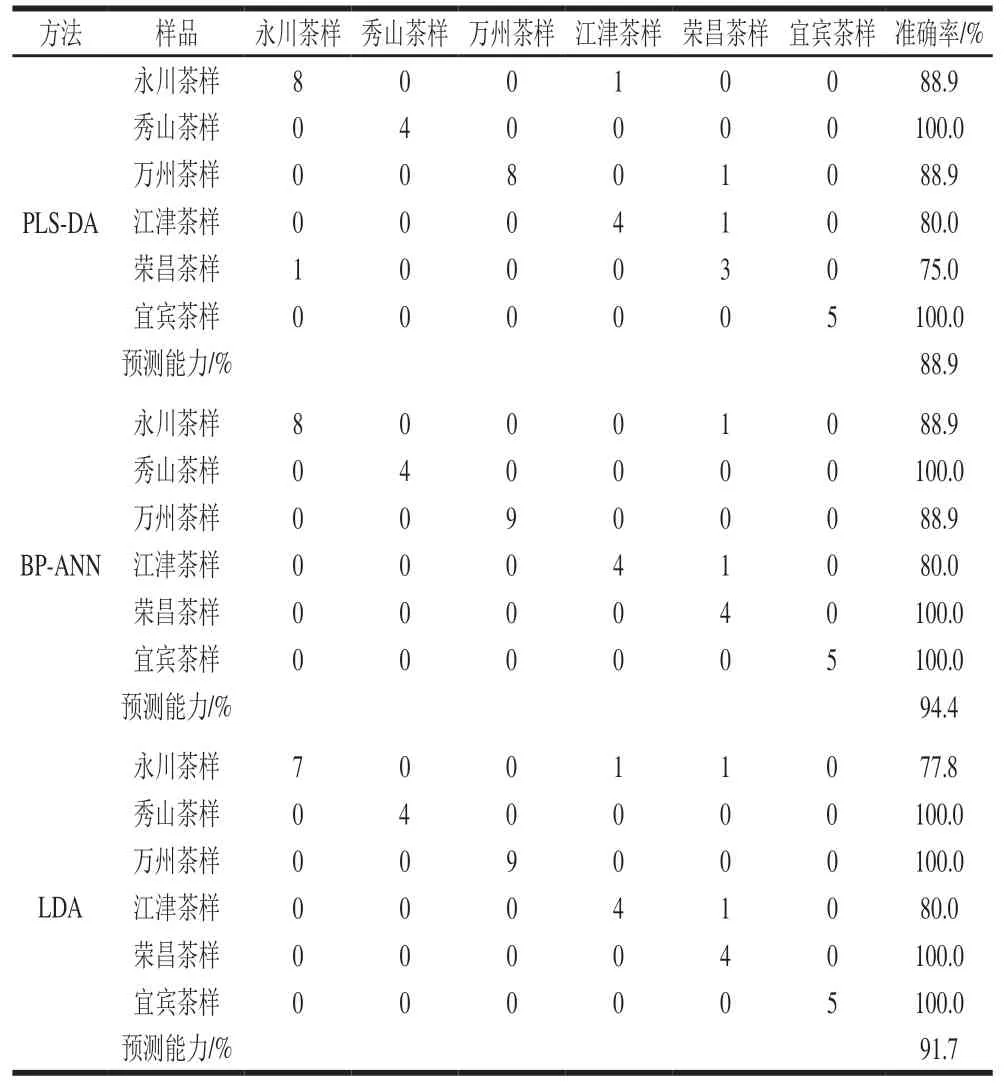
表5 各模型在盲数据集下验证性能结果Table 5 Results of performance verification of each model using blind data set
3 结论
开发一种GC-C-IRMS方法分析不同产地茶叶产品(秀芽)的咖啡碱和6 种主要游离态氨基酸C和N,并结合化学计量学模型对茶叶产地进行地理溯源。结果表明:采用咖啡碱和6 种主要游离态氨基酸的C和N指纹技术对茶叶地理溯源是可行的,GC-C-IRMS分析方法验证效果好。PLS-DA、BP-ANN和LDA模型预测准确率达到85%以上,验证准确率达到85%以上;其中BPANN模型认证性能最优。同时筛选N和C为不同产地茶叶样品认证的重要的化学标记。本研究结果为茶叶产品的认证体系的建立和完善提供一定技术和理论支撑,也为其他食品地理溯源研究提供研究思路和方法参考。今后建议在更大样本集和不同地点对这种新方法进行测试,以进一步评价咖啡碱和氨基酸化合物碳氮稳定同位素比值分析在茶叶产品认证中的适用性。
