基于深度BiLSTM和图卷积网络的方面级情感分析*
2022-10-28杨春霞宋金剑姚思诚
杨春霞,宋金剑,姚思诚
(1.南京信息工程大学自动化学院,江苏 南京210044;2.江苏省大数据分析技术重点实验室,江苏 南京 210044;3.江苏省大气环境与装备技术协同创新中心,江苏 南京 210044)
1 引言
情感分析,又叫意见挖掘[1],是自然语言处理NLP(Natural Language Processing)中的一项重要任务。随着数字技术的快速发展,微博、淘宝和京东等平台上的评论呈爆发式增长,情感分析也得到了越来越多的关注。
方面级情感分析属于细粒度情感分析,旨在预测文本中特定实体或方面的情感极性,其关键在于提取文本表示。目前,同时融合语义信息和句法信息的文本表示在方面级情感分析中取得的分类效果比只融合一种信息的文本表示好[2,3],但这种文本表示仍然只包含了浅层文本信息而忽略了深层信息。因此,如何挖掘深层次文本特征,改进文本表示是值得研究的一个热点问题。
图卷积网络GCN(Graph Convolutional Network)[4]善于捕捉图中的结构信息,因此被广泛应用于NLP[5,6]。但现有研究表明:两层GCN捕捉邻域信息的性能最佳[7],即再多层的GCN也无法捕获更多的结构信息。因此,如何让GCN提取更多的结构信息是现阶段面临的一个问题。
针对以上问题,本文提出了一种基于DBiLSTM(Deep Bi-drectional Long Short-Term Memory)和紧密连接的图卷积网络DDGCN(Deep BiLSTM and Dense Connections-based Graph Convolutional Network)模型。该模型的主要贡献如下:
(1)结合深度双向长短时记忆DBiLSTM和GCN来获取不同类型的文本信息,进而生成最具代表性的文本表示。输入的词向量、位置向量和词性向量在DBiLSTM的每一层进行训练,实现文本中方面词和上下文间语义信息的挖掘;DBiLSTM最后一层的输出送入改进后的GCN,以提取依存图上的结构信息。
(2)通过引入紧密连接[8],改变了GCN只能捕捉局部结构信息的现状,进而生成一个新的能捕捉深层结构信息的紧密GCN网络。
本文在3个公开数据集上进行了对比实验和消融实验。实验结果表明,本文提出的模型性能较基线模型均有所提升,且每个组成部分对提高分类效果都有一定的帮助。
2 相关工作
方面级情感分析是一种细粒度的情感分类任务。早期模型大多是基于朴素贝叶斯、支持向量机SVM(Support Vector Machine)等机器学习方法建立的,这些模型的性能很大程度上取决于特征标注,而特征标注需要消耗大量资源。深度学习方法不需要人为构造特征,可自动实现对文本中语义特征和句法特征的捕捉,近年来逐渐成为方面级情感分析研究的主流方法。
在深度学习方法中,有些方法使用长短时记忆LSTM(Long Short-Term Memory)或GRU(Gated Recurrent Unit)来建模上下文表示,弥补了RNN(Recurrent Neural Network)模型存在的梯度爆炸和梯度消失问题。但是,单向的LSTM或GRU只能获取前面文本对当前文本的响应,而忽略了后续文本对当前文本的影响。BiLSTM(Bi-directional LSTM)和BiGRU(Bi-directional GRU)弥补了它们的不足,实现了上下文间关联信息的提取。曾蒸等[9]使用DBiLSTM进行情感分析,实验结果表明DBiLSTM能更加有效地建模上下文表示。虽然上述方法在文本表示上已经取得了较好的效果,但仍忽略了诸如依存树这样的句法结构信息。Sun等[3,10]通过图卷积网络获取依存树上各节点表示,并结合上下文间语义表示进行方面级情感分析,均获得了当时最好的分类效果,这表明同时考虑上下文间的语义信息和图结构中的结构信息对提高分类效果有明显帮助。基于此,本文尝试使用DBiLSTM学习方面词和上下文间的深层语义信息;使用GCN学习依存图中的结构信息,生成既包含语义信息又包含结构信息的文本表示。
图卷积网络是卷积神经网络的变体,它可直接对图进行操作,图中每个节点表示的更新都与其相邻节点有关。理论上讲,要想获取相距L的邻居节点信息,就需要L层GCN。但是研究发现,两层GCN捕获图中结构信息的能力最强[7],即多层GCN只能捕获丰富的邻域信息而无法获取更多深层结构信息。Xu等[11]尝试在GCN上添加额外循环层,取得了一定的效果。然而,这种方法只适用于层数小于6的GCN,因此捕捉到的信息也十分有限。Huang等[8]利用多层CNN进行图像深层信息挖掘时,发现在层与层之间引入紧密连接可以有效促进深层网络间信息的交换。受其启发,本文将紧密连接引入GCN网络中,以提高GCN对深层结构信息的提取。
综上,本文提出了一种基于DBiLSTM和紧密连接的图卷积网络模型。
3 DDGCN模型
本文提出的DDGCN模型结构如图1所示,主要由以下4部分组成:
(1)词嵌入层:将输入的数据样本转化为词向量,并与位置向量和词性向量串联,一起作为DBiLSTM层的输入。
(2)DBiLSTM层:对输入向量进行处理。该层具有多个隐藏层,前一层的输出作为下一层的输入。经过多层处理,获得包含方面词与上下文间深层语义信息的隐藏层表示,并将其作为紧密GCN层的输入。
(3)紧密GCN层:在原始GCN中加入紧密连接,使得GCN不仅能够捕获丰富的邻域信息,还能获取深层结构信息。
(4)平均池化层:先从紧密GCN层输出的隐藏表示中挑选出方面词表示,然后对其进行平均池化操作,最后将该层输出作为Softmax层的输入。
3.1 词嵌入
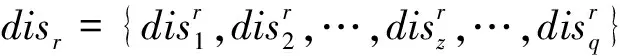
(1)
其中,a1和am分别表示方面词起始和结束的索引。本文使用Glove[12]预训练模型将wq转换为词向量表示eq,并将sr表示成q×d的词向量矩阵X={e1,e2,…,eq},其中d表示词向量的维度。另外,利用Stanford coreNLP生成句子sr对应的依存树,并构建相应的邻接矩阵A。
3.2 深度BiLSTM
虽然单向LSTM符合人们的阅读习惯,但是实际中一个词不仅与它前面的词有关联,还受后面词的影响。BiLSTM从前后2个方向捕捉上下文信息,最后合并结果得到所需的上下文表示,这更符合句子实际的语义结构。本文采用DBiLSTM模型来进一步提取方面词与其上下文间的深层语义信息。
LSTM的计算方法如式(2)~式(7)所示:
it=σ(W(i)et+U(i)ht-1+b(i))
(2)
ft=σ(W(f)et+U(f)ht-1+b(f))
(3)
ot=σ(W(o)et+U(o)ht-1+b(o))
(4)
(5)
(6)
ht=ot*tanh(Ct)
(7)
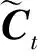
BiLSTM比LSTM多了一个反向提取信息的过程,其计算方法如式(8)~式(10)所示:
(8)
(9)
(10)
DBiLSTM由多层BiLSTM组成,其计算方法如式(11)~式(13)所示:
(11)
(12)
(13)
3.3 紧密图卷积网络
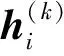
(14)

(15)

随着紧密连接的加入,GCN层与层间的联系变得更为密切,从而不仅能捕捉节点间丰富的邻域信息,还能捕捉层与层之间的深层次结构信息,如图3所示。图3是一个3层的紧密图卷积网络,图中层与层之间的黑实线代表原始图卷积网络间的连接方式,虚线表示新增的紧密连接方式。从图3中可以看出,未引入紧密连接时,节点表示只与网络层数和上一层的输出有关;紧密连接的加入增强了层与层之间的联系,使得节点表示中又融入了更深层的结构信息。另外,为了避免节点自身信息被忽略,在原始邻接矩阵A的基础上添加了单位矩阵I。因此,原始GCN计算公式应当加以修改,修改后如式(16)所示:
(16)
3.4 平均池化
经过DBiLSTM和紧密GCN的处理,方面词隐藏表示中已经包含了上下文语义信息和句法结构信息,因此本文只选取方面词表示作为分类器输入,通过式(17)所示的方法将非方面词表示屏蔽,并保持方面词的隐藏表示不变:
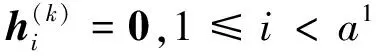
(17)
(18)
其中,f(·)表示平均池化函数;{}里是屏蔽非方面词后所得的方面词隐藏表示。
3.5 模型训练
(19)
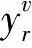
4 实验
4.1 实验数据与实验环境
本文在SemEval-2014数据集和微博评论(Twitter)数据集上进行模型性能评估,其中SemEval-2014数据集包含餐厅评论(Rest14)和笔记本评论(Laptop14),每个数据集包含3种情感极性(积极,中性,消极)。表1给出了每个数据集中训练样本和测试样本的数据分布情况。

Table 1 Rest14,Laptop14,and Twitter dataset information
表1中,pos表示情感类别为positive,neg表示情感类别为negative,neu表示情感类别为neutral。
本文实验环境如表2所示。

Table 2 Experimental environment
4.2 实验参数与评价指标
DDGCN模型中相关参数取值如表3所示。其中,词嵌入维度为300;词性和位置嵌入维度为30;考虑到篇章级情感分析中使用的DBiLSTM层数为2时,分类效果就已明显改善,以及本文使用的数据样本大多短小、精简,因此本文DBiLSTM的层数设定为2层;训练过程中使用Adamax进行参数优化,为防止过拟合,模型训练过程中还使用了input_dropout、gcn_dropout和rnn_dropout。
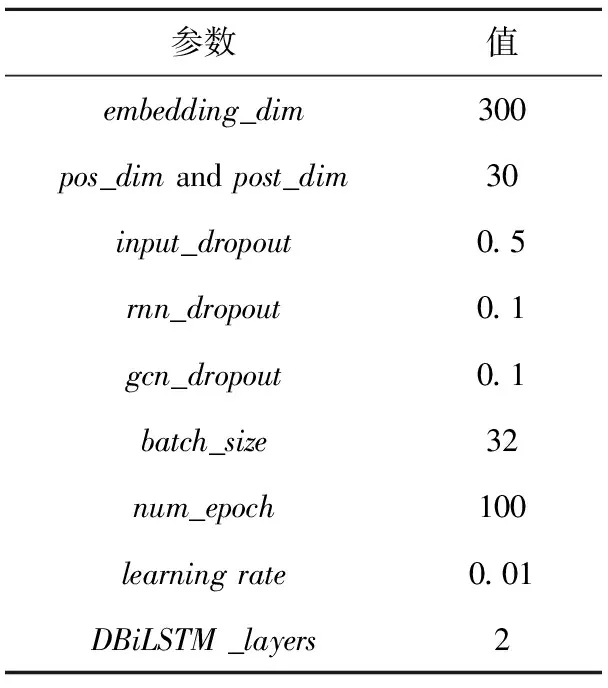
Table 3 Experimental parameters setting
为验证模型有效性,本文选用准确率Acc(Accuracy)和MacroF1(简称F1)作为评价指标,具体计算如式(20)~式(24)所示:
(20)
(21)
(22)
(23)
(24)
其中,TP代表成功预测的正样本数,FP代表错误预测的负样本数,FN代表错误预测的正样本数,TN代表成功预测的负样本数,P为精确率,R为召回率,F1是精确率与召回率的调和平均,C是情感类别数,F1v为第v个类别的F1值。
4.3 对比模型
近2年的研究工作中专门基于Glove的模型较少。为了证明本文模型的有效性,本文选取如下几个较为经典或现阶段分类效果排名靠前的模型作为对比模型:
(1)IAN[13]:一种结合BiLSTM和交互注意力机制来学习方面词与上下文单词间语义信息的情感分类模型;
(2)TNet-LF[14]:该模型从BiLSTM的输出隐藏表示中筛选出方面词表示,并将其输入CNN,以获得最终分类器的输入表示;
(3)AEN-Glove[15]:一种使用多次注意力机制建模方面词与上下文间关系的分类模型;
(4)ASGCN[10]:该模型利用BiLSTM获取上下文表示,并在此基础上使用GCN提取方面词表示,最后将两者输入注意力机制,以生成最后的隐藏表示;
(5)R-GAT(Stanford)[2]:该模型首先使用BiLSTM挖掘方面词与上下文间的语义信息,然后对原始依存树进行修剪,最后利用图注意力捕捉新依存树中的结构信息;
(6)CDT[3]:该模型通过BiLSTM与GCN的串联连接,实现了文本中方面词与上下文间信息的提取。
本文选取的6个对比模型大致可分为2类:一类是只考虑语义信息的IAN、TNet-LF和AEN-Glove;另一类是既考虑语义信息又考虑结构信息的ASGCN、R-GAT和CDT。
4.4 实验结果与分析
实验结果如表4所示。从表4中可以看出,CDT是所有对比模型中表现最好的,而本文模型在其基础上又有了提升,其中准确率在3个数据集上分别提升了0.81%,0.59%和0.97%;F1值也分别在Rest14数据集和Laptop14数据集上提升了2.24%和0.77%。可见,本文提出的DDGCN模型性能优于其他对比模型。
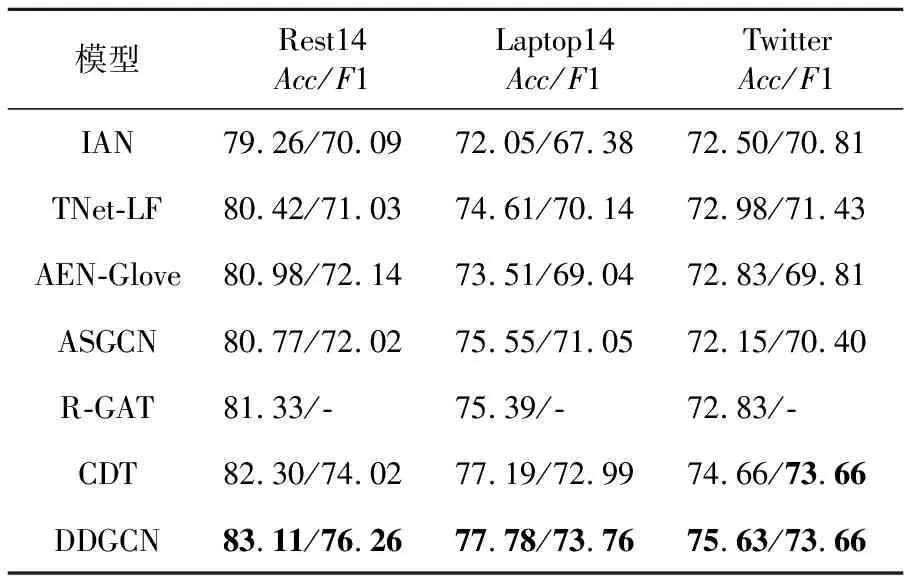
Table 4 Classification results of different models
纵观3个数据集上的整体实验结果发现,同时考虑2种信息的模型在效果上普遍优于只考虑语义信息的模型,这表明文本中的结构信息对提高分类效果有一定帮助,从而也说明本文构建的同时融入语义信息和结构信息的文本表示是合理的。另外,考虑到本文模型是在CDT模型的基础上加以改进的,因此实验结果可以初步证明引入DBiLSTM和紧密连接对挖掘文本中深层次信息并生成相应文本表示有一定帮助。
为说明DBiLSTM和紧密连接单独挖掘深层次信息的有效性,本文对DDGCN模型进行了消融实验,以Rest14为例,实验结果如表5所示。表5中DDGCN-DBiLSTM是指将DDGCN模型中的DBiLSTM替换为普通BiLSTM,其他部分保持不变;DDGCN-DC表示移除DDGCN模型中的紧密连接,改用原始GCN,其余模块保持原样。
从表5可以看出,与DDGCN模型相比,DDGCN-DBiLSTM模型在准确率和F1值上分别下降了0.17%和2.1%,这表明DBiLSTM对于挖掘文本中的深层语义信息有一定帮助;DDGCN-DC模型在准确率和F1值上分别下降了0.46%和2.32%,这说明紧密连接的引入使得GCN能够挖掘深层次结构信息,弥补了原先只能提取邻域结构信息的不足。综上所述,DBiLSTM和紧密连接的使用对于挖掘深层信息、提高分类效果都有一定帮助。
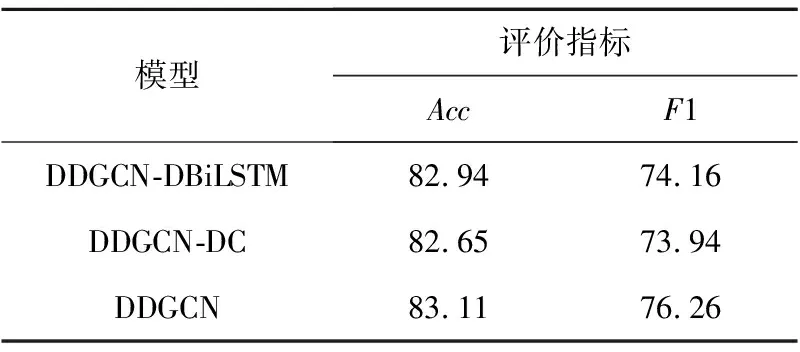
Table 5 Ablation experiment results
为了证明本文文本表示的有效性,以Rest14数据集为例,将包含深层语义信息和深层结构信息的文本表示分别替换成只包含语义信息的文本表示O-BiLSTM、只包含结构信息的文本表示O-GCN以及同时包含浅层语义信息与结构信息的文本表示CDT,实验结果如表6所示。
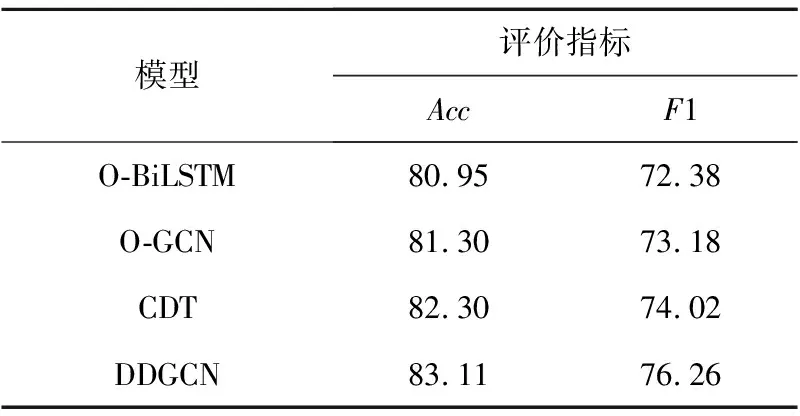
Table 6 Classification results of models using different text representations
从表6可以看出,O-BiLSTM和O-GCN的准确率和F1相比CDT分别下降了1.35%,1.64%,1%和0.84%,这表明同时融合语义信息与结构信息的文本表示对提升分类效果有明显帮助。此外,使用本文提出的文本表示方法进行分类时,准确率与F1在CDT的基础上又分别提升了0.81%和2.24%,这表明融合深层语义信息和深层结构信息的文本表示能进一步提高分类效果,也说明本文提出的文本表示方法较前3种方法更优。
实验过程中为了获得每个数据集上的最优实验结果,对紧密连接的层数L进行了一系列的实验。实验中,其他参数设置保持不变,但考虑到层数L要能被紧密连接的输入隐藏维度整除(dhidden=300),以及取值不宜过大,因此L的取值只能是2,3,4,5,6,10。
实验结果如表7和图4所示,表7显示的是层数L在各个数据集上的最优取值;图4展示的是本文分类模型的准确率在3个数据集上随层数L的变动情况,本文从中选取最好的数值作为最终实验结果。从图4可以看出,每个数据集的准确率随L变化的波动相对不大。大体上,当L取值较小时,准确率相对较低,可能是因为层数较小时无法提取更多的结构信息;但当L取值过大时,结果也会下降,可能是因为层数过多会提取出部分无用信息。

Table 7 Optimal L values on different datasets
5 结束语
为了获取更好的方面级情感分类效果,本文提出了一种DDGCN模型。该模型首先使用DBiLSTM提取方面词与上下文间深层次的语义信息;其次,在普通GCN网络中引入紧密连接,形成能捕捉深层结构信息的紧密GCN;然后,将DBiLSTM的最后一层输出作为紧密GCN的输入,以实现对依存树中邻域和深层结构信息的提取;最终,将包含2种信息的方面词表示送入Softmax层进行情感分类。在3个公开数据集上的实验结果表明,本文模型较对比模型而言在准确率和F1上均有提升。在消融实验也证明了DDGCN模型每个组成部分的有效性。
在下一步的工作中,将尝试在中文数据集和个人爬取的数据集上进行方面级情感分析,并考虑将其用于实际生活中的某个领域。
