基于AFP的有向加权注意力流网络链路预测*
2022-10-28马满福姜璐娟范颜军邓晓飞
马满福,姜璐娟,李 勇,张 强,范颜军,邓晓飞
(1.西北师范大学计算机科学与工程学院,甘肃 兰州 730070;2.西北工业大学计算机学院,陕西 西安 710129)
1 引言
个性化推荐系统在线上购物、社交平台和流媒体等众多互联网应用中得到广泛应用,主要对用户行为、商品特征等进行学习,对用户偏好进行预测,从而减轻信息超载,提供个性化服务,辅助用户决策等[1,2]。目前,大部分电商平台,如淘宝、京东等,都利用所掌握的用户行为数据,对用户偏好进行预测,然后为用户提供相关的产品推荐[3,4]。在各类推荐系统中,对用户在线点击行为数据进行挖掘的链路预测方法一直得到广泛应用。链路预测旨在通过分析已知网络节点和网络结构等信息,预测网络中的任意2个节点产生一条连边的可能性[5]。
链路预测最常用的方法是启发式方法[6],通过计算节点间的相似性来判断链接存在的可能性。低阶启发式算法,如CN(Common Neighbor)和PA(Preferential Attachment),涉及网络中目标节点的一阶和二阶邻居,高阶启发式算法,如Katz、PageRank等,考虑x(x≥2)阶邻居。高阶启发式相较一阶和二阶启发式算法性能更优,但会导致高的时间复杂度和内存消耗问题,而且启发式算法使用图结构特征,缺乏考虑包含丰富信息的网络显式特征和隐式特征[7]。此外,现有的链路预测算法大多数基于无向无权网络,不能直接应用于有向加权的注意力流网络。
推荐系统通常依赖用户行为数据,如用户浏览时间、点击次数、搜索次数和停留时间等,基于用户集体行为数据构建的注意力流网络CAFN(Collective Attention Flow Network)分析方法为推荐系统研究带来了新方向[8,9]。集体注意力流网络由在线用户点击流数据构建而成,是节点和边皆有属性的有向加权网络,基于CAFN的链路预测对推荐系统和知识图谱补全等领域具有重要的研究意义[10,11]。
本文针对传统启发式链路预测方法存在的不足,提出了基于集体注意力流网络模型的链路预测算法AFP(Attention Flow Prediction)。该算法将注意力流网络节点间不同的边方向抽象为2种边关系类型,并引入注意力机制学习网络中的节点属性和边属性[12],综合考虑了网络的图结构特征、显式特征和隐式特征,将链路预测问题转化为一个二分类问题,即判断节点间的边属于某个关系类型的可能性大小,在推荐系统等领域具有重要的应用价值。本文研究内容包含以下4个方面:
(1)基于有向加权注意力流网络和R-GCN(Relational-Graph Convolutional Network)算法提出了新的链路预测算法AFP。该算法引入注意力机制取代了传统R-GCN算法中的参数权值共享,将网络中的边方向抽象为2种关系类型,有效解决了有向加权网络边关系的准确预测问题。
(2)在R-GCN基础上,引入注意力机制学习节点特征表示。注意力流网络中的节点和边具有不同的权重,引入注意力机制取代了传统R-GCN算法中的权重共享方法,通过每个关系的不同重要性程度聚合邻居信息。
(3)将注意力流网络中的边方向抽象为{rin:vi←vj;rout:vi→vj}2种关系类型。针对不同的关系类型,分别学习并聚合不同节点和边的特征信息,有效表征了网络中边的方向信息。
(4)综合学习网络的图结构特征、显式特征和隐式特征。在学习节点特征的过程中,考虑注意力流网络的局部结构、节点嵌入、网站停留时间和点击次数等特征,捕获了关于网络的更多信息,并且有效提升了预测性能。
2 相关工作
2.1 链路预测
链路预测是推荐系统中使用的重要方法之一,通过分析已知网络节点及网络结构等信息,挖掘网络底层的潜在规律,预测网络中的任意2个节点在未来产生连边的可能性。现有的链路预测方法大多数都是基于无向无权图的。文献[13]在多路复用网络上结合层相似性度量方法和层重构方法,在多个无向图上实现了链路预测。文献[14]结合概率启发式和注意力机制,通过合适的学习方式来预测无向图中的链接,无需依赖复杂特征工程。文献[15]提出了一种捕获网络中的高阶结构的嵌入算法,并在多个无向图上验证了其有效性。文献[16]使用属性信息识别社交网络中新链接和节点的位置,预测网络中的新关系和缺失关系。这些方法在无向图上的预测性能优异,但不能有效地应用于有向加权图。
现实世界中,推荐系统研究面对的大多数网络都是有向加权图,基于无向图的方法不能有效地处理具有复杂交互关系的有向加权图。文献[17]提出了一种基于AUC(Area Under the Curve)的链路预测方法,将链路预测问题转化为优化问题,在有向图上实现了高质量预测。文献[18]提出了WLNM(Weisfeiler-Lehman Neural Model)链接预测方法,以图模式学习拓扑特征,根据顶点在提取的子图中的结构角色标记顶点,同时保留子图的内在方向性。文献[19]提出了一种有监督的链接预测方法来预测研究人员的引文数,该方法可以预测链接及其权重。这些方法都考虑了网络中边的方向,但没有综合学习网络的图结构特征、显式特征和隐式特征,有向加权的注意力流网络节点和边皆有属性,所以上述方法在该网络上是无效的。
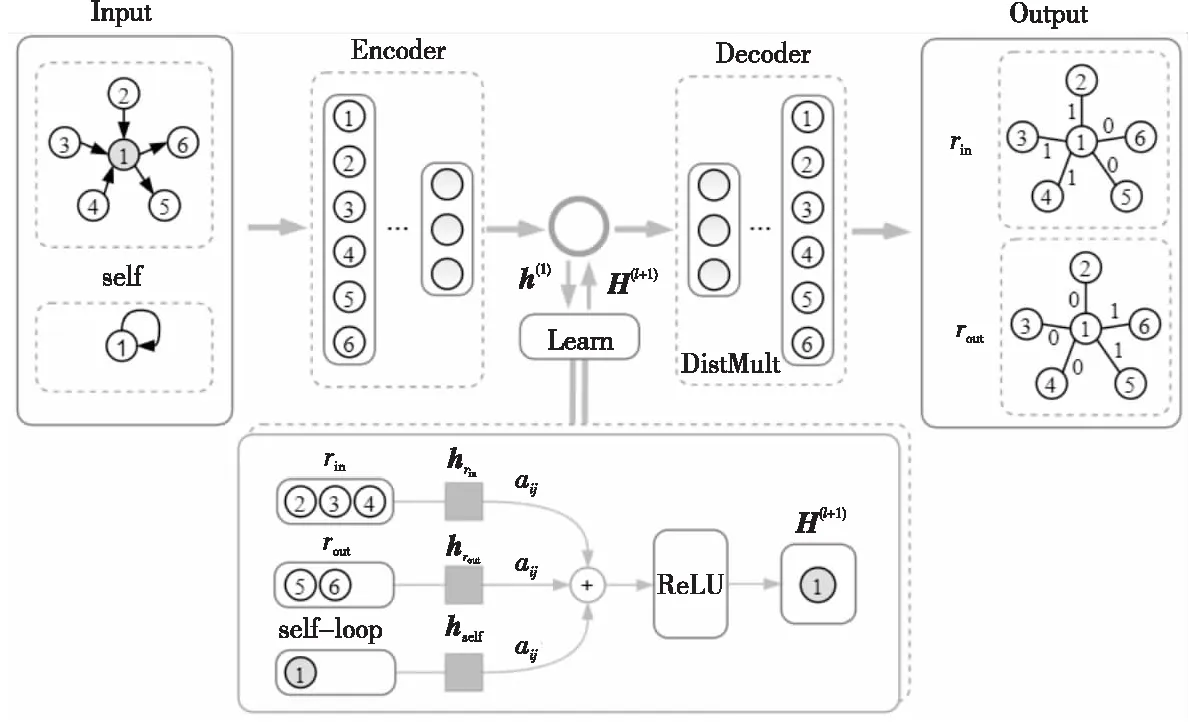
Figure 1 Framework of AFP algorithm
2.2 注意力流网络
注意力流网络由在线用户点击网站的序列数据构建而成,是一种节点和边都带有属性的有向加权网络。对注意力流网络的点击率进行预测是互联网广告系统和推荐系统中最重要且最具挑战的预测之一。文献[20]提出了基于特征交互的神经网络,通过三维关系张量对特征交互进行建模,提高了深度神经网络在点击率预测任务中的性能。文献[21]提出了自动特征交互选择两阶段算法,可以在模型训练过程中自动识别和去除冗余特征交互。文献[22]提出了一个端到端的框架RippleNet,通过沿着知识图中的链接自动、迭代地扩展用户的潜在兴趣,以刺激用户偏好在知识实体集上的传播,可用于预测最终点击率并进行推荐。随着以用户行为数据分析为主的推荐系统的发展,对基于用户行为的注意力流网络的研究吸引了越来越多的研究人员并在网络的特征捕获方面取得了优异的效果,但基于该网络的链路预测方法还很少。
综上,现有针对不同网络类型考虑不同网络信息的建模方法,还没有综合考虑网络的图结构特征、显式特征和隐式特征,不能有效应用于有向加权的注意力流网络;此外,注意力流网络已成为依赖用户行为数据分析的推荐系统的一个重要分支,却鲜有基于注意力流网络的链路预测算法研究。鉴于此,本文提出了基于有向加权注意力流网络的链路预测算法AFP,综合学习了网络的图结构特征、显式特征和隐式特征,弥补了上述相关研究中的不足,并通过多个评价指标验证了该算法的有效性。
3 链路预测算法AFP
AFP算法整体框架如图1所示,由一个编码器和一个解码器组成。首先,编码器将高维的图数据映射到低维的向量空间中。在学习节点特征向量的过程中,把网络中不同的边方向抽象为2种关系类型,目标节点根据不同的类型聚合不同的邻居信息,并引入注意力机制融合学习网络中的节点属性和边属性,经过多个隐藏层得到的向量可以表征网络中节点的局部结构。其次,编码器获得的节点向量表示和关系类型以三元组形式输入解码器,解码器采用DistMult评分函数计算三元组成立的概率,当概率值大于阈值ε时输出1,表示三元组关系成立;否则输出0,表示三元组关系不成立。最后,将评分结果映射到高维图数据中,便可得到最终的链路预测结果。
3.1 网络构建
本文使用中国物联网信息中心提供的在线用户浏览网站的行为日志数据作为实验对象,数据记录了用户开关时间、浏览网站的URL等信息。首先,清洗数据并过滤无用信息,抽取1 000名用户1个月的点击网站数据来构建注意力流网络。将在线用户浏览点击的网站抽象成网络中的节点,网站与网站之间的跳转抽象成网络中的边,网站停留时长作为节点权重,网站间的跳转频数作为边权重。当用户在网站停留时间超过30 min时,该网站作为一个新节点加入网络,同时产生一条新连边,以此构建了集体注意力流网络。该网络由20 115个节点和125 557条边组成,构建的集体注意力流网络符合复杂网络的“幂律分布”[23],网络的可视化效果如图2所示。

Figure 2 Collective attention flow network
3.2 网络特征学习
集体注意力流网络中,用户在网站的停留总时间表示网站对用户注意力的吸引。网站间的跳转次数与网站的度相关,入度反映了网站的吸引力,出度反映了网站的活跃程度,综合考虑网站的出度和入度,网站度集和邻居网站中网站vi的总度值,即集体注意力流网络的显式特征。通过结合R-GCN和注意力机制来学习网站间关系的复杂性和关系权重的多样性,即隐式特征。

具体地,网络中的节点vi将自身的特征信息hi经过抽取变换后,共享给同一关系下的邻居节点vj;接着,将2个节点的特征信息hi和hj聚集起来,实现局部结构信息融合;最后,将聚合的信息进行非线性变换,更新网络中节点在l+1层的特征状态,如式(1)所示:
(1)


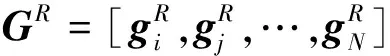
(2)
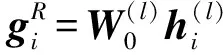

(3)
(4)
将注意力机制与R-GCN算法邻域特征更新规则相结合,式(1)转换为式(5):
(5)
以注意力流网络中任意节点vi为例,基于关系类型rin:vi←vj,该节点不仅考虑了节点自身特征hi,而且还聚合了其邻居节点vj的特征信息hj,并根据关系类型进行相应变换和归一化操作,此时节点特征状态的更新由式(5)转换为式(6):
(6)

节点vi基于第2种关系类型rout:vi→vj,节点特征状态更新如式(7)所示:
(7)

综合考虑节点vi与任意节点的2种不同关系类型,其特征状态更新描述如式(8)所示:
(8)
3.3 边关系预测及损失优化

(9)
基于上述给定的评分函数f(),在训练过程中使用负采样,对网络中的每一个正样本,随机修改三元组中的节点。利用交叉熵损失函数优化损失值,通过迭代求解损失值,并采用随机梯度下降来优化算法,迭代过程直至收敛或迭代次数超过一个阈值α时停止,故损失函数如式(10)所示:
(1-yij)log(1-σ(f(Z))))
(10)
其中,σ()是sigmoid激活函数,yij是节点标签,yij=1表示节点vi和节点vj间存在连边,yij=0表示节点vi和节点vj不存在连边。Dtrain表示训练集,Z为训练集中的样本。
3.4 具体算法AFP
链路预测算法AFP如算法1所示。
算法1AFP算法
输入:三元组Z=(vi,R,vj);层数L;输入特征{hi,∀vi∈V};激活函数。
输出:三元组成立的概率f(Z)。
1.VK←V;
2.forl=L,…,1do
3.Vl←Vl+1;
4.forvi∈Vl+1do
5.Vl←Vl∪Nl+1(i);/*Nl+1(i)表示节点vi在第l+1次聚合时的邻域*/
6.end
7.end
9.forl=L,…,1do
10.forvi∈Vldo
13.end
14.end
17.returnf(Z)
4 实验和结果分析
4.1 数据集
基于中国互联网络信息中心提供的在线用户行为数据[24],本文构建了一个由20 115个节点和125 557条边组成的集体注意力流网络,网络中节点的平均度为6.251。集体注意力流网络中度大的节点相对稀少,度小的节点较多且分布集中,符合“长尾分布”[23],可用于复杂网络链路预测任务研究。
4.2 基准算法
本文选择了6个经典算法与提出的AFP算法作对比:(1)GCN(Graph Convolutional Network)[25]算法结合深度优先搜索和广度优先搜索对图中的节点进行采样,利用word2vec的思想来学习节点表示向量;(2)GAT(Graph Attention Network)[26]在GCN的基础上引入Attention思想,计算每个节点的邻居节点对它的权重,从而获取邻近点的特征;(3)GraphSAGE(Graph SAmple and aggreGatE)[27]利用节点特征信息和结构信息得到图嵌入映射;(4)TransE(Translating Embeddings)[28]利用词向量的平移不变,对三元组实例,通过不断调整h、r和t(Head、Relation和Tail的向量)使(h+r)尽可能与t相等;(5)DistMult[29]采用基于相似性的打分函数,通过匹配实体和关系在嵌入向量空间的潜在语义衡量三元组成立的可能性;(6)ComplEx(ComplEx embeddings)[30]在DistMult的基础上引入复值嵌入,取复值点积的实部作为三元组得分。
4.3 评价指标与实验设置
本文采用链路预测任务中常用的评价指标准确度(Accuracy)、精准度(Precision)、召回率(Recall)和F1值来评价各算法。下述各公式中的TP表示正例预测正确的个数;FP表示负例预测正确的个数;TN表示负例预测错误的个数;FN表示正例预测错误的个数。各指标简要描述如下:
(1)Accuracy:所有三元组Z=(vi,R,vj)中预测正确的比例,如式(11)所示:
(11)
(2)Precision:正确预测正例样本数与预测为正例的样本数的比例,如式(12)所示:
(12)
(3)Recall:正确预测正例样本数与所有正例样本数的比例,如式(13)所示:
(13)
(4)F1值:综合考虑Precision和Recall得分,是Precision和Recall的调和均值,如式(14)所示:
(14)
除上述4个评价指标外,本文还采用推荐系统和知识图谱广泛使用的MRR和Hits@K指标对TransE、DistMult、ComplEx和AFP进行对比。分别简要描述如下:
(1)MRR(Mean Reciprocal Rank)是一个国际上通用的评价检索算法的机制,其第1个预测结果匹配分数为1,第2个匹配分数为0.5,第n个匹配分数为1/n,没有结果匹配的分数为0,最终的分数为所有得分之和,如式(15)所示:
(15)
其中,Dtest为测试集。
(2)HR(Hit Ratio)是Top-K推荐中常用的衡量召回率的指标。若正例三元组Z=(vi,R,vj)出现在Top-K中,则Hits@K=1,否则Hits@K=0,Hits@K*为所有命中Hits@K=1的测试正例,总体的Hits@K是通过对所有测试用例求平均来确定的,如式(16)所示:
(16)
注意力流数据集拥有数万级的节点集和边集,将数据集按一定比例划分为训练集Dtrain、验证集Dvalid和测试集Dtest,划分情况如表1所示。

Table 1 Data set and its division
为保证收敛速度和质量,经过反复实验,最终将训练的迭代次数设置为epoch=3000,训练批大小batch_size=3000,激活函数采用sigmoid,学习率lr=0.001,优化器采用Adam,隐藏层层数H=200,节点嵌入维度E=200。
4.4 实验结果
AFP算法预测的注意力流网络中网站的点击率排名如表2所示,其中Rank列代表网站排名序号,Source_Node列代表源节点网站,SN_f(Z)列代表源节点网站的点击概率,Target_Node列代表目标节点网站,TN_f(Z)列代表目标节点网站的点击概率。表2所示的排名结果与网站的停留时长、点击次数、度值等网络属性值成正比关系,并且与注意力流网络的真实点击情况基本一致。

Table 2 Ranking of predictive click-through rate of websites in the attention flow network
将4.2节的6个对比算法和AFP算法的10次实验结果取平均值,得到表3和表4,粗体显示的是本文算法AFP的结果,其整体表现最好。例如,在Accuracy、Precision、Recall和F1指标上,AFP与未加入注意力机制的R-GCN相比,AFP的平均Accuracy值提高了1.52%,平均Precision提高了7.88%,平均Recall提高了1.59%,平均F1提高了4.89%。此外,在MRR和Hits@K指标上,AFP与R-GCN相比,平均MRR提高了0.54%,平均Hits@1提高了0.44%,平均Hits@3提高了0.58%,平均Hits@10提高了0.14%。

Table 3 Comparison of Accuracy,Precision,Recall,and F1 of different algorithms on the attention flow network

Table 4 Comparison of MRR and Hits@K of different algorithms on the attention flow network
此外,本文还将训练集按比例从50%到90%划分以验证本文算法的有效性。不同算法在不同训练集规模下的预测性能如图3~图6所示。由图可知,AFP算法在训练集不同规模下的性能依旧显著,说明AFP算法的预测性能优势与网络训练集划分的大小无关,且在网络不完整的情况下,预测性能依旧显著。
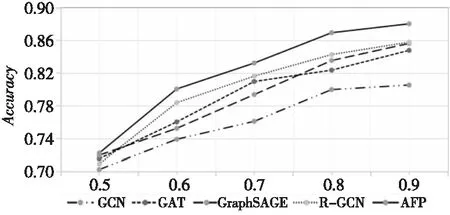
Figure 3 Comparison of Accuracy values of different algorithms under different sizes of training set

Figure 4 Comparison of Precision values of different algorithms under different sizes of training set

Figure 5 Comparison of Recall values of different algorithms under different sizes of training set

Figure 6 Comparison of F1 values of different algorithms under different sizes of training set
5 结束语
本文提出了适用于有向加权网络的链路预测算法AFP,该算法综合考虑了网络的图结构特征、显式特征和隐式特征;将有向网络中的边方向抽象为2种关系类型,实现了边方向的预测;引入了注意力机制,以捕获节点和边的不同重要性。研究结果表明:(1)针对有向加权注意力流网络链路预测,AFP算法比基准算法的预测准确率提高了至少3.52%;(2)网络中的节点和边皆有属性,综合考虑多种特征能够提高边关系预测性能;(3)注意力流网络中度大的节点相对稀少,度小的节点较多且分布集中,符合“长尾分布”。
AFP算法的优点有:(1)AFP可以有效地预测有向加权网络中的边关系;(2)构建的注意力流网络由20 115个节点和125 557条边组成,因此AFP的预测结果不受在大数据集上预测性能差假设的影响。但也存在以下不足:(1)引入注意力机制捕获网络特征提高了特征学习效果,同时也提高了时间复杂度;(2)相比于链路预测,知识图谱补全关注的是网络中最可能出现的链路的预测正确度。与知识图谱算法相比,AFP预测效果在MRR和Hits@K指标上均比较低。
有向加权集体注意力流网络链路预测是个性化推荐的重要方法之一。在未来的研究中,针对知识图谱存在的大量非对称关系,将进一步研究AFP服务于知识图谱补全等领域,以提高其预测性能,降低时间复杂度。
