基于ARMv8处理器的高性能图像处理算法实现与优化研究*
2022-10-28韦存阳贾海鹏张云泉曲国远魏大洲张广婷
韦存阳,贾海鹏,张云泉,曲国远,魏大洲,张广婷
(1.中国科学院计算技术研究所计算机体系结构国家重点实验室,北京 100190;2.中国科学院大学计算机科学与技术学院,北京 100080;3.中国航空无线电电子研究所,上海 200241)
1 引言
在图像处理领域,目前虽然在ARM平台上有开源的算法库OpenCV等,但其从功能和精度上都无法替代x86平台上的Intel IPP库。本文对标Intel IPP的高性能算法库,开发了一个基于ARMv8计算平台的高性能算法库。
色彩空间转换、图像插值和图像滤波在图像处理领域都具有非常广泛的应用场景。各个行业都有其最适合的色彩空间,例如计算机图形领域一般使用RGB色彩空间,视频领域一般使用YUV或YCbCr色彩空间。各个色彩空间之间的转换本质上是将一组数据经过线性运算后转换为另一组数据。色彩空间转换可有效地使图像符合各行各业的显示标准。目前已有很多文献提出了色彩空间转换的快速算法。
图像插值函数广泛应用于医学、航空和动画制作等领域。图像插值本质上是利用插值算法,根据原始图像的各个邻近点计算出目标图像的像素值。这些插值运算可以使放大或缩小后的图像更加自然平滑。
滤波函数的主要功能包括图像降噪和边缘检测等,其在图像识别领域应用广泛。总体上,滤波函数利用各种滤波算法,根据原始图像的邻近点,经过一系列运算得到目标像素值。
针对上述函数,本文设计并实现了基于ARMv8平台的HMPP(Hyper Media Performance Primitives)算法库,库中包含CvtColor(Convert Color)、Filter和Resize 3个模块。其中,CvtColor模块提供了一系列在RGB、YUV和YCbCr色彩空间之间快速转换的算法,对于YUV和YCbCr色彩空间还支持升采样与压缩采样,此外还支持RGB与灰度图之间的转换;Resize模块提供了基于Nearest、Linear、Cubic和Lanzcos插值的图像插值算法,以及超采样(Super)与抗锯齿(Antialiasing)算法;Filter模块提供了双边滤波、高斯滤波以及均值、中值、索贝尔和沙尔等滤波算法。
本文的主要贡献如下所示:
(1)对标Intel IPP算法库,开发了一个基于ARMv8计算平台的高性能图像算法库,与开源OpenCV库对比,其性能有着显著的提升。
(2)设计了一种针对ARMv8架构的图像处理算法优化体系。该体系在提升ARMv8平台上图像处理函数性能的同时,也对其他算法在ARM处理器上的实现和优化有着一定的参考意义。
2 相关工作
当前对于图像处理函数的优化方法研究已有很多。虽然编译器也会进行向量化的优化操作,但有研究表明,相比较于编译器的自动向量化优化,利用ARM Neon技术手动优化可以得到巨大的加速空间[1]。SIMD指令通过适当的代码操作可以显著提高图像处理算法的性能[2,3]。在图像色彩空间转换领域,当前已有许多针对Intel 平台、使用SIMD指令的优化算法[4,5],对本文所提的基于ARM平台的SIMD优化有一定的借鉴意义。此外,文献[6]表明,使用移位近似浮点乘法并结合查表法可显著降低浮点运算的复杂性,提高算法性能。
图像插值算法应用十分广泛[7],各个插值算法的特性为不同需求的用户提供了选择的空间[8]。对于图像插值算法的研究成果更是十分丰富。当前已有基于ARM Neon的若干优化方法[8]。例如,对于计算复杂性较高的Lanczos插值,文献[9]指出可以使用查表法代替一些复杂运算来提高性能,也为本文的优化工作提供了一些新思路。
线性滤波函数的优化难点在于如何提高卷积计算的性能。有研究表明,在Intel平台使用SIMD技术对滤波核为3×3的卷积算法可以大大提高处理速度[10]。同时,在ARM平台也有基于ARM Neon技术对Prewitt 算子进行优化[11]。上述研究对本文中线性滤波的若干函数优化都有一定的借鉴意义。
3 算法原理
3.1 CvtColor模块
CvtColor将图像色彩从一种存储格式转化为另一种格式,是点对点的转换,同时访存连续,故具有很好的并行性。CvtColor涉及的转换模式多种多样,包含RGB、YUV和YCbCr之间的相互转换,还有Gray和RGB之间的相互转换。
在 RGB 模型中,每种颜色都显示为红色(R)、绿色(G)和蓝色(B)的组合,是三通道图像,这在图像领域应用较为广泛。Gray是灰度图,是单通道的图像。YUV模型中,Y表示明亮度(Luminance、Luma),U和V表示色度和浓度(Chrominance、Chroma)。YCbCr 是在世界数字组织视频标准研制过程中作为ITU-R BT.601 建议的一部分,其实是YUV经过缩放和偏移的翻版。其中Y与YUV 中的Y含义一致,Cb和Cr都指色彩,只是在表示方法上不同而已。此外,对于RGB和YCbCr色彩空间,还有符合ITU-R BT.709建议的HDTV(High-Definition TV)标准及CSC(Computer Systems Consideration)标准。
特别地,对于YUV和YCbCr色彩空间,可通过减少图像可接受的颜色描述所需的比特数来压缩采样。其压缩原理是基于人眼对于亮度变化的敏感度高于对色度变化的敏感度。其本质是为每个像素分配单独的亮度分量,同时将一个色度分量分配给一个像素组。如图1所示,主流的采样格式包括4∶4∶4 YUV(YCbCr)、4∶2∶2 YUV(YCbCr)、4∶1∶1 YCbCr和4∶2∶0 YUV(YCbCr)。
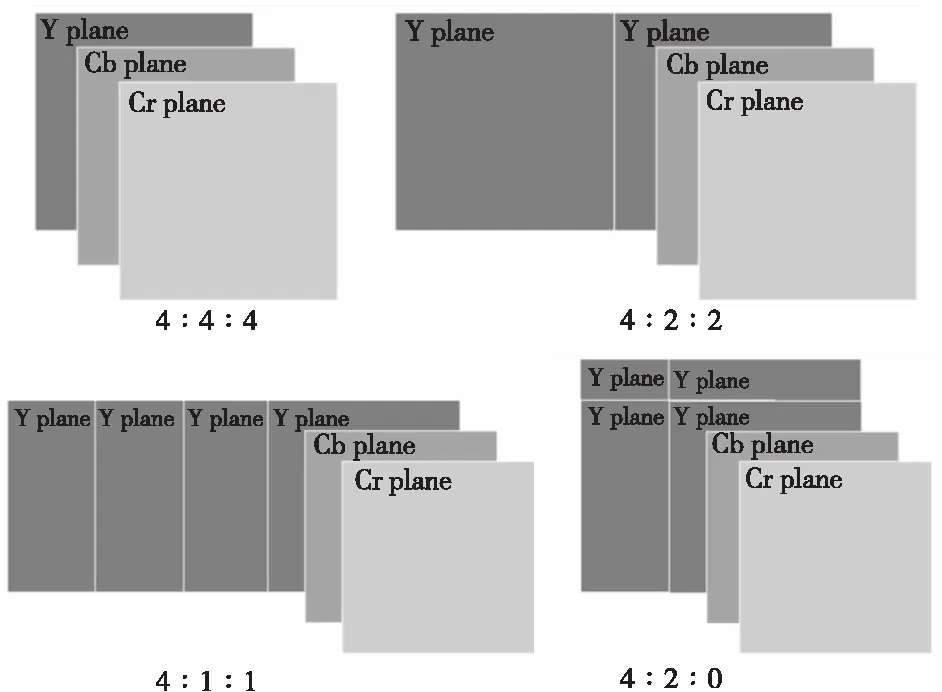
Figure 1 Downsampling for YUV and YCbCr
在存储格式上还有平面图像格式(Planar Image Formats)和像素图像格式(Pixel-Order Image Formats)。平面图像格式是将各通道数值存储在3个数组中,像素图像格式是将各个通道混合存储在1个数组中。其中像素图像格式存储的图像可以充分发挥ARM Neon指令集的优势,相比于x86平台,无需繁琐的转换就可以分离出各通道的像素。
以YUVToRGB为例,可以看出总体上CvtColor模块由于其访存连续,同时各个像素点之间相互独立,因此具有极好的并行性。
从计算公式(1)上也可以看出,运算较为简单,其性能瓶颈在于访存。
(1)
3.2 Resize模块
Resize对图像大小进行的变换,包括放大和缩小。Resize包括多种模式,最基本的是根据缩放比计算得到目标点映射在原矩阵中的坐标,然后根据该坐标从原矩阵中取数并将其直接赋值给目标点。这种方法称为Nearest,计算如式(2)所示:
(2)
其中,目标图像坐标为(m,n),源图像大小为SR×SC,目标图像大小为DR×DC,映射到原图像的坐标为(x,y)。这种方式简单且高效,不需要运算操作,仅需要依据映射公式取像素即可。但其缺点在于由于仅通过比例映射进行缩放,如图2a所示,在对图像进行缩小处理时,源图像中存在大量的点并不参与映射,造成了数据失真的情况;如图2b所示,在对图像进行放大操作时,目标图像中相邻点映射到原矩阵中的点可能是同一点,此时就会存在明显锯齿。
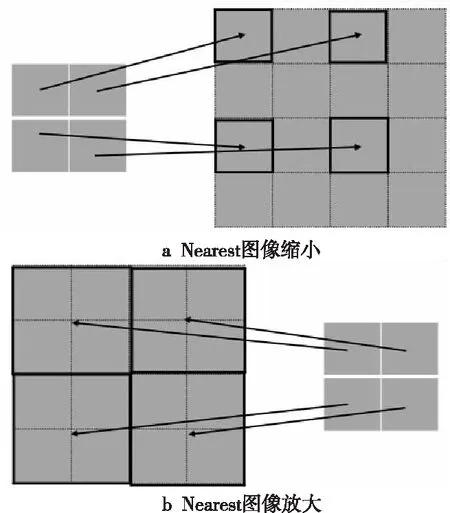
Figure 2 Nearest Interpolation
Linear、Cubic和Lanczos插值主要是为了解决Nearest存在的问题而被提出的。与Nearest类似,Linear、Cubic和Lanczos也是根据缩放比计算得到原矩阵对应的坐标。映射公式如式(3)所示:
(3)
其中,目标图像坐标为(m,n),源图像大小为SR×SC,目标图像大小为DR×DC,映射到原图像的坐标为(x,y)。系数计算的行列公式相同。以行方向为例,Linear行方向的2系数为y′-y和1-(y′-y)。
设P为参与计算的点的坐标与x′的差,B和C是用户定义的参数,则Cubic插值行方向系数计算公式如式(4)所示:
(4)
2-lobed Lanczos与3-lobed Lanczos插值行方向系数计算公式分别如式(5)和式(6)所示:
(5)
(6)
之后再分别取原矩阵映射点周围的2×2,4×4和6×6规模的小矩阵,使用相应的插值算法计算系数,并通过加权计算得到目标点的数值。
这样,在图像缩小时,就可以缓解失真现象;在放大时,就算2目标像素映射到原矩阵的同一点,但在插值计算阶段,小矩阵内各个点的加权值不同,最终计算的结果也不同,避免产生锯齿现象。
Linear、Cubic和Lanczos这3种方法引入了较多的像素参与运算,损失了性能,但是缓解了失真与锯齿的产生。图2和图3中包含了Nearest、Linear、Cubic和Lanczos所需要的原矩阵数据区域示意图。可以看出,这4种方法访问的原矩阵的数据区域依次增大,得到的目标图像相对原图像的还原度也依次提高。应用时可以根据不同需求和条件选择不同的方法。

Figure 3 Linear,Cubic,Lanczos,Super interpolation
除此之外,本文还提出了专门应对图像缩小时失真问题的超采样算法(Super),根据图像的缩放比例,将相应比例的像素点加权平均得到目标像素,对于不构成一个像素的点,使用所占面积计算其加权值(见图3)。超采样可以充分使用原始图像的各个像素点,因此可以显著缓解图像失真情况。
在上述Nearest、Linear、Cubic、Lanczos和Super算法中,其计算方式和访存方式都不同,并且依据映射公式可以看出其访存都不连续。相比于CvtColor模块,Resize模块的可并行性降低,但由于数据之间依然相互独立,即每个目标点的计算均与其他目标点的计算不相关,因此还是具有较好的并行性。对于Resize模块来说,计算并不繁琐,访存不连续的特性决定了访存仍是其高性能处理的瓶颈。
3.3 Filter模块
滤波函数主要适用于边缘检测、降噪、模糊和特征检测等图像处理操作,分为线性滤波(均值滤波和沙尔滤波)和非线性滤波(中值滤波和双边滤波)2种。
原理上,线性滤波是根据某一特定的二维卷积算子,与原始图像从左到右、从上到下进行卷积操作,如式(7)所示:
(7)
其中,dst(x,y)表示目标图像的像素,kernel(x′,y′)表示卷积算子,src(x+x′,y+y′)表示源图像的像素,kernel.width和kernel.height表示卷积窗口的宽和高。
为了确定对应于每一目标图像像素点的原始图像卷积区域,还需要定义卷积核的锚点(anchor point)。一般来说,锚点即几何中心,本文也支持一些函数自定义的锚点。
简单来说,非线性滤波也有类似于线性滤波中邻域的概念,但“卷积核”不是固定的。目标像素点是根据邻域区域通过某些非线性运算得到的。
滤波函数由于具有很高的数据重用性,即2个目标点之间存在一定的数据相关性,因此不具备很好的并行性。同时访存操作较多,并且存在一定的非连续访存,因而访存仍是Filter模块高性能处理的瓶颈。
3.4 Resize与Filter模块的边界处理
值得注意的是,如图4所示,Resize与Filter都可能超出源图像的边界,如果不提前定义这些边界情况就会发生越界操作。
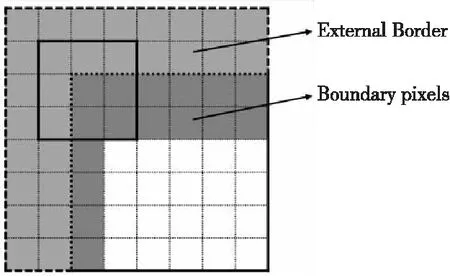
Figure 4 Possible boundary problems
因此,本文所实现的HMPP库提供了对4种边界的支持,如图5所示。4种边界包括常数边界(Constant Border)、复制边界(Replicated Border)、镜像边界(Mirror Border)及混合边界(Mix Border)。

Figure 5 Four boundary handling methods
常数边界处理方法是将用户指定的值作为越界后的取值。复制边界处理方法是当越界时取最外层数值作为越界后的取值。镜像边界处理方法是发生越界时从边框像素向内取值。此外,内存中预定义的边界(Border in Memory),即传入函数的图像外层,还有若干层数据,这样就允许用户更加灵活地定义越界后的取值。
此外还支持内存中预定义的边界及其与复制边界的混合边界,可以指定某条边使用预定义边界,其他边使用复制边界。常用于图像分块计算。
3.5 总结
从优化角度对以上3个模块中包含的算法进行分类:
(1)数据无关。每一个目标像素点的计算都是相互独立的,相邻目标像素点计算对应的源图像,访存是连续的,如CvtColor模块,其对应的优化方法主要是算法优化及计算过程的优化。
(2)数据共享。相邻目标像素点的计算可共用部分源像素点,如Filter模块。其优化的重点在于数据共享优化,减少访存次数。
(3)非规则访存。一个目标像素点计算对应的源图像,访存不连续,或相邻目标像素点计算对应的源图像,访问不连续。其优化的重点在于面向SIMD的访存优化。
4 基于ARM Neon的优化技术
ARM Neon技术是ARM cortex-A和cortex-R系列处理器的高级单指令多数据(SIMD)架构的扩展,它可以提高多媒体程序的性能。鲲鹏920平台拥有32个向量寄存器,向量寄存器中数据的位宽可以设置为 8,16,32 或 64,这意味着一个向量寄存器可以容纳多个数据。Neon指令对整个向量寄存器进行操作,一个寄存器中的多个数据可以一起处理。因此,Neon技术可以使算法并行工作,从而提高性能。
4.1 数据类型转化优化
CvtColor模块和部分Filter模块在计算中所使用到的系数为浮点数,若直接按照公式计算需要将整数转换为浮点型。但是,ARM Neon中并没有将unit 8直接转换为浮点数的操作,需要经过unit 8↔unit 16↔unit 32↔float 32 3次转换才能完成浮点运算,得到结果后还要将float 32转换为unit 8。此时数据转换指令往往比运算指令占比更大,程序大部分时间都浪费在数据转换上,十分不合算。
因此,本文用整数近似替换浮点数,进而减少数据转换带来的性能损失。若原浮点型系数为S,则使用S′=floor(S×2n)近似,n为确保计算过程中不越界的最大整数。例如,对于RGB2YUV,原始公式如式(8)所示:
(8)
使用上述方法替换后,计算公式转换为式(9):
(9)
相较于浮点运算,这样减少了大量的数据转换操作。同时,在整数运算过程中还可以通过使用长指令进一步减少数据转换操作,从而大幅提高性能。
4.2 嵌入式汇编优化
ARM Neon Intrinsics对高位操作的指令较为丰富,广泛地支持对寄存器高位的乘法、移位和数据类型转换等指令,例如vmull_high_u16,vmlal_high_u16等。但是,没有相应的对寄存器低位操作的指令。若只用ARM Neon Intrinsics指令编写程序,对低位的操作将会较为繁琐,需要增加若干步get_low操作。经查阅发现,ARM Neon汇编指令支持低位操作,因此本文考虑使用嵌入式汇编自定义一些类Intrinsics指令来实现低位操作,例如vmull_low_u16和vmlal_low_u16,以减少大量的get_low操作。如图6所示,vmull_low_u16(a,b)与vmull_u16(vget_low_u16(a),vget_low_u16(b))运行的结果是等价的,但前者可以节省2条指令。即:
vmull_low_u16(a,b)⟺
vmull_u16(vget_low_u16(a),vget_low_u16(b))

Figure 6 Opera the lower half of register
经测试,在CvtColor模块中,使用自定义的嵌入式汇编函数替换掉get_low操作,性能大约可提升15%。
4.3 访存优化
如图7所示,Resize模块的特点在于各个点之间的运算相互独立,不存在数据重用,但2个相邻的目标像素所映射的源图像坐标不连续。因此,Resize模块对于并行运算相对友好,但对于并行访存不友好。此时若要通过ARM Neon并行计算,需要取出一系列不连续的点,通过标量寄存器到向量寄存器的转换,将所需用到的像素点存放到向量寄存器中。需要注意的是,这种标量到向量寄存器之间的转换十分耗时。针对这一特点,本文设计了以移位代替频繁的标量到向量寄存器转换的方法。
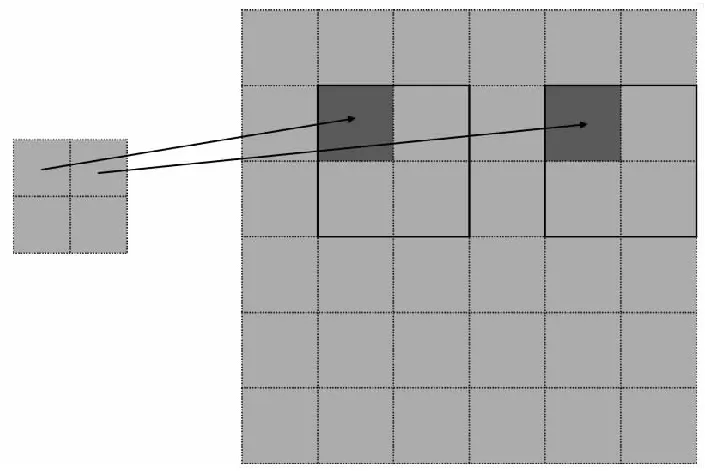
Figure 7 Discontinuous mapping of the Resize module
此外,在取值时也要充分利用C语言指针的特性,如图8所示,以Linear_8u_c1为例,计算一个像素需要周围4个点,则需要在每一行取出连续的2个点,此时可以直接以unit 16的类型取数,再重解释为2个unit 8类型的数,从而减少访存指令数。
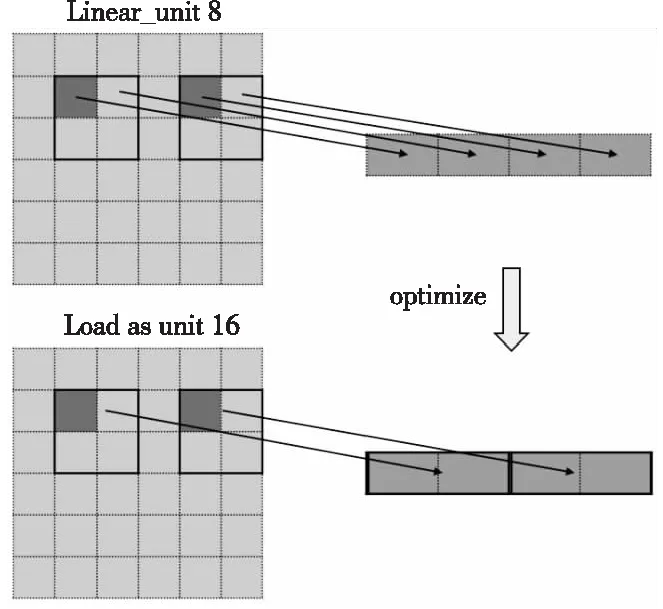
Figure 8 Optimization of loading operation
若在此基础上使用ARM Neon优化,对于鲲鹏920平台的128位寄存器,每次可计算8个结果,在原图像上映射为2行,每一行16个点。对于每一行,直接进行取数操作将会有8次标量寄存器到向量寄存器的转换。为了减少该开销,本文使用计算来代替一部分转换操作。具体步骤如下所示:
步骤1使用unit 16类型指针,取出8个不连续的点,并保存为unit 64格式;
步骤2每4个点作为一个单元,其中第i个点左移16×(i-1)位,并将这4个移位后的结果相加,此时步骤1中的8个点转化为了2个单元;
步骤3将步骤2得到的2个单元的结果保存到uint64×2的向量寄存器中;
步骤4将uint64×2重解释为uint8×16。
图9展示了上述算法的实现过程。
此时虽然增加了若干步加法与移位操作,总指令条数甚至有所增加,但标量与向量寄存器之间的转换操作减少为原来的1/4,经测试,性能提升了50%以上。这说明标量与向量寄存器之间的转换操作相比于移位与加法计算,耗时更多。
此外,考虑到ARM Neon所支持的最小操作宽度为64 bit,这种方法也可用于当数据不够64 bit的情况。
4.4 数据预处理优化
从Resize模块坐标映射和系数计算方法可以看出,行和列的系数计算是相互独立的。如图10所示,对于同一列数据,映射到源图像后也在同一列,同一行数据映射到源图像后也在同一行,系数仅与源图像与目标图像的大小有关。针对该特点,可以把系数计算放到init函数中,这样对单幅图像来说可以减少系数重复计算。若需要对多幅大小相同的图像进行插值,仅需要计算一次系数就可应用于这一组图像,大大增加了计算的重用性。

Figure 10 Mapping in the column direction
Filter模块的高斯滤波和双边滤波也可以使用类似的方法预先计算系数。例如,对于Bilateral_8u,计算公式如式(10)所示:
w(i,j,k,l)=
(10)
其中,Id(i,j)表示输出点的像素值,I(i,j)表示输入点的像素值,S(i,j)表示以(i,j)为中心的滤波窗口,w(i,j,k,l)表示空间邻近高斯函数和像素值相似度高斯函数的乘积。σd和σr这2个参数由用户输入。σd为坐标空间中滤波器的sigma值,该值较大时较大的定义域空间会影响结果。σr为颜色空间过滤器的sigma值,该值较大时较大的值域空间也会影响结果。
经观察可以发现,对于unit 8类型,I(i,j)-I(k,l)至多会有256种取值,则(i-k)2+(j-l)2在滤波核大小确定时就可确定全部情况。因此,在init函数中预先计算上述参数,在计算阶段仅需要取值就可以计算最终的结果,每次计算不再需要并行化相对较复杂的exp函数。因此,使用这种方法既减少了重复计算,又增加了并行度,性能将会有极大的提升。
4.5 数据共享优化
线性滤波的特点在于相邻行的计算可复用,在行方向上使用向量化可以减少重复访存。如图11所示,在列方向上需要通过循环展开若干次来减少重复访存,并减少重复计算。以ScharrVert为例,其滤波核为:
数据为:
则第1个数据的计算公式可简化为式(11):
result=((a3-a1)+
(a9-a7))×3+10×(a6-a4)
(11)
显然,第2行数据计算时可复用(a9-a7)和(a6-a4)这2个结果。

Figure 11 Column expands to merge the loading operation
对于这种滤波核固定,且滤波核具有一定对称性的滤波函数,这样就可以大大增加计算结果的复用性。同时考虑到循环展开过多列将会增加Cache Miss的风险,因此合理地在行方向上循环展开将大大提高数据的复用性,极大地提高性能。
此外,对于均值滤波,当滤波核较大时,可以在行方向上通过加入下一个移进来的点、减去上一个移出去的点来增加数据复用。在列方向上通过将每一行数据保存到buf中,减少Cache Miss的同时,提高计算结果复用性。
4.6 指令选择优化
(1)整数运算:移位代替乘法。
在计算压缩采样、升采样和滤波函数时,经常会遇到需要乘、除2的若干次方的情况。在鲲鹏920平台使用移位运算的实现,比使用乘法运算更快。以Laplacian滤波为例,滤波核为:
数据为:
优化前的计算公式如式(12)所示:
2(a1+a3+a7+a9)-8(a5)
(12)
使用移位运算代替乘2和乘8后的计算如式(13)所示:
((a1+a3+a7+a9)≪1)-(a5≪3)
(13)
经过测试发现,在鲲鹏920平台,Laplacian滤波使用移位运算代替整数乘2n后,性能大约提升了10%。
(2)浮点运算:乘法代替除法。
相比于乘法指令,除法指令在鲲鹏920平台性能较低。以均值滤波为例,最后的计算结果需要除以滤波核大小计算均值,这里可以使用乘以倒数来代替除法。经测试,在大规模情况下均值滤波性能提升了25%左右。
4.7 优化总结
本文依据各个模块的特点,为每一类模块都进行了单独的性能优化。表1总结了各模块所使用到的优化方法。
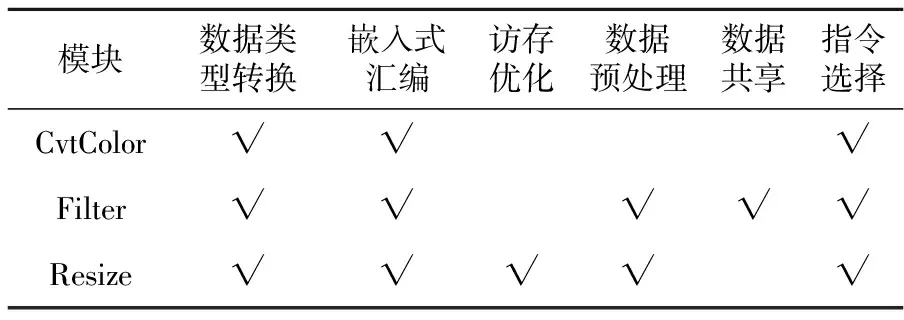
Table 1 Summary of optimization methods of each module
5 实验结果与分析
5.1 实验环境
本文的HMPP库在ARMv8架构的鲲鹏920 处理器上实现运行,处理器时钟频率为2.6 GHz。OpenCV库采用当前最新版本的4.5.3。
具体实验环境如如表2所示。
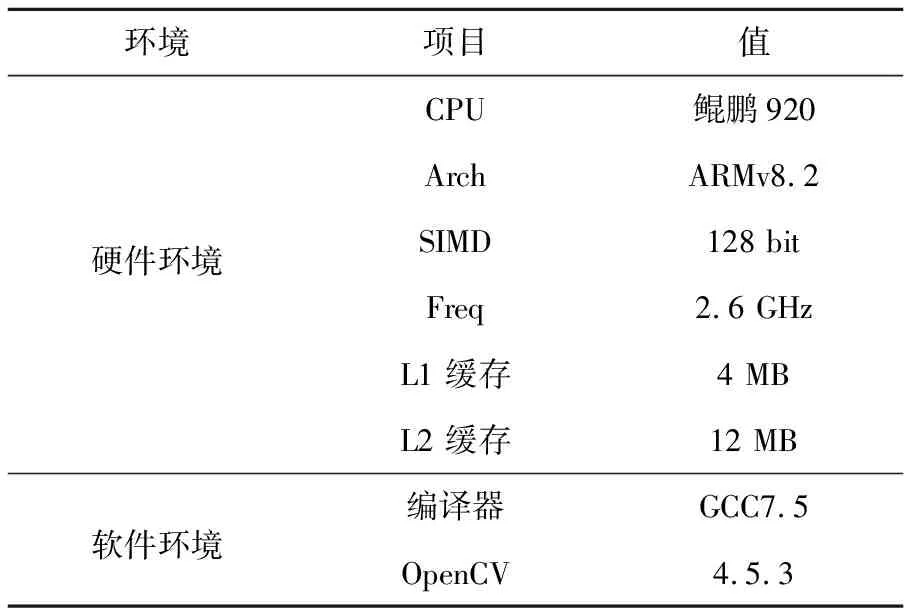
Table 2 Experimental environment
由于本文介绍的HMPP库精度参照的是Intel IPP库,与OpenCV并不一致,因此在对比中本文尽量选取与OpenCV结果相近的函数进行性能对比,以避免差异影响最终的分析结果。本文使用运行时间作为性能评价的指标,相同图像规模下时间越短,则性能越高。
5.2 性能对比分析
在CvtColor模块,选取Gray2RGB和RGB2Gray图像转换算法,与OpenCV中的CvtColor()函数进行对比。其中,数据类型都为unit 8,RGB和YUV都为3通道,Gray为单通道。
实验结果如图12所示,这表明对于GRAY2RGB,仅需要简单的存取操作并不需要运算。HMPP库充分利用了ARM Neon指令集的特性,相比OpenCV性能提升最大可达198%,性能提升最小有28%, 性能提升平均有101%。在RGB2GRAY,运算复杂性有所提升,性能提升最大有25%,性能提升最小有12%,性能提升平均有18%。
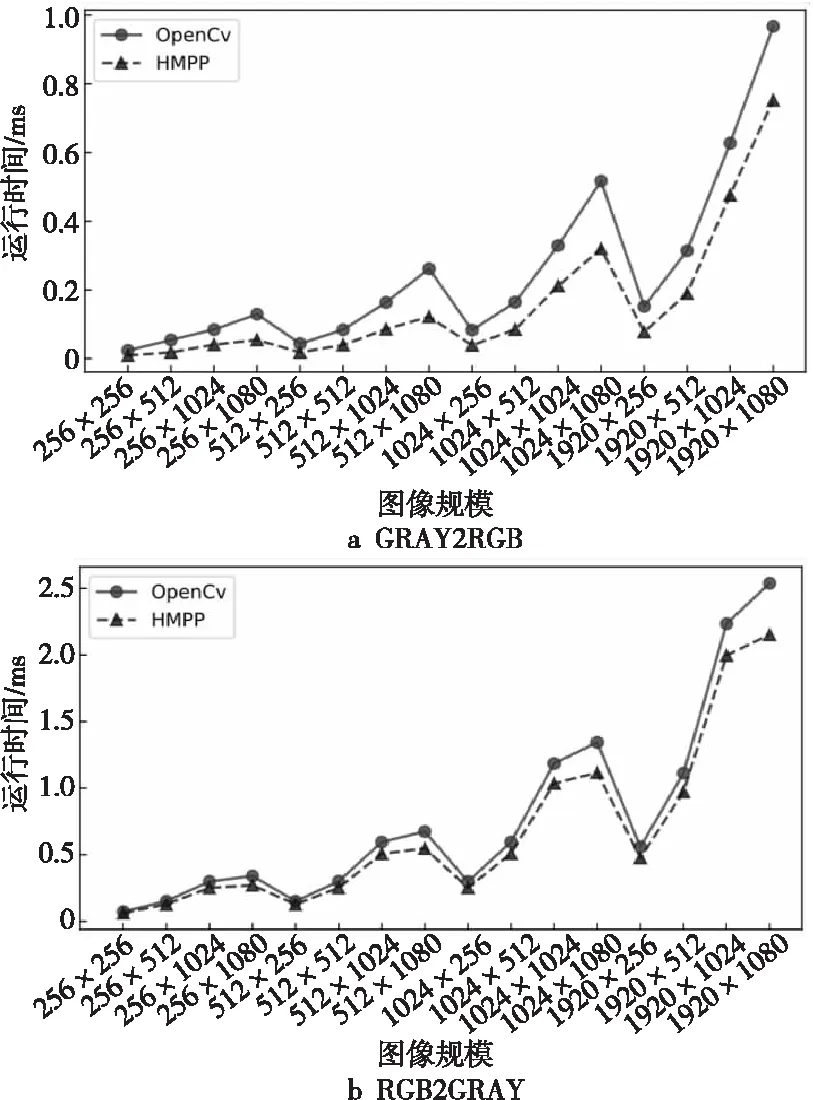
Figure 12 Color Space convert between Gray and RGB
Resize模块选取最近邻插值与OpenCV库的resize()函数进行对比。其中,数据类型为unit 8,并分别对比单通道、3通道和4通道的性能。图13的结果表明,对于单通道性能提升最大有131%,性能提升最小有22%,性能提升平均有91%;3通道性能提升最大有290%,性能提升最小有31%,性能提升平均有210%;4通道性能提升最大有94%,性能提升最小有53%,性能提升平均有71%。
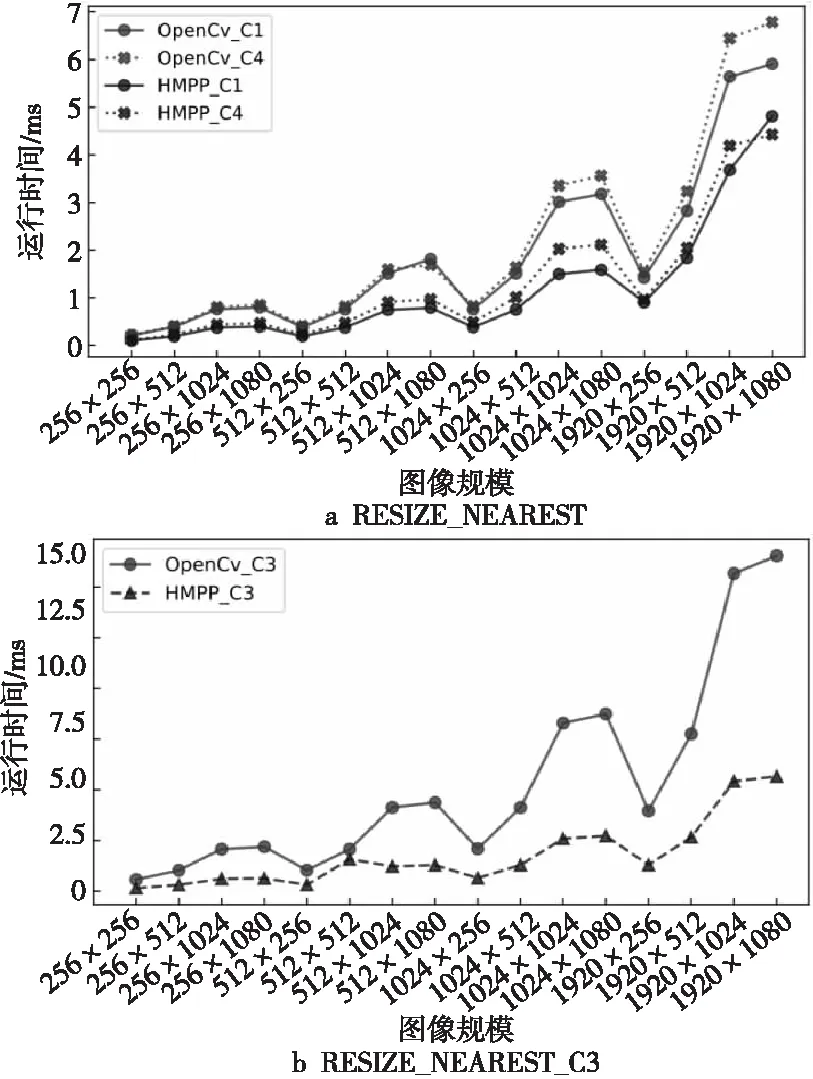
Figure 13 Performance of Resize_Nearest
Filter模块选取Laplacian滤波与OpenCV库的Laplacian()函数进行对比,其中,输入图像格式为unit8,单通道,输出图像格式为int16,单通道。如图14所示。相比OpenCV性能提升最大有233%,性能提升最小有158%,性能提升平均有194%。

Figure 14 Performance of Filter_Laplacian
整体上,本文实现的HMPP库性能均明显优于OpenCV库的。结果表明,本文设计的HMPP库以及对算法实现的一系列SIMD优化、存取优化、计算简化和嵌入式汇编优化等是有效的。
6 结束语
本文基于鲲鹏920平台,提出了一系列针对图像色彩空间转换、滤波和图像插值算法的优化方法。与现有的开源图像处理库相比,本文实现的HMPP库的优势在于与Intel IPP库具有相当的精度以及相似的接口与功能,降低了x86用户在国产处理器鲲鹏920上开发的难度。在优化方法上,本文充分利用各模块的特征,ARM Neon的特点以及鲲鹏920的特性,与OpenCV相比有着较大的性能提升。
在优化过程中发现,由于本文主要使用ARM Neon Intrinsics进行优化,在某些情况下指令延迟将会造成较大开销,因此在未来将会利用ARM neon汇编指令,尽量降低延迟开销。
