基于FPGA快速实现定制化RISC-V处理器*
2022-10-28蒋句平任会峰
陆 松,蒋句平,任会峰
(1.无锡学院,江苏 无锡 214105;2.国防科技大学计算机学院,湖南 长沙 410073)
1 引言
处理器作为信息处理的引擎,推动了人类社会数字化、信息化和智能化的进程。人们对处理器性能的追求永无止境。在特定领域的硬件加速,需要使用ASIC芯片、协处理器或加速卡来扩展处理器功能[1]。过去由于指令集的封闭性,这些加速部件的设计和应用软件的开发通常滞后于处理器设计[2,3]。
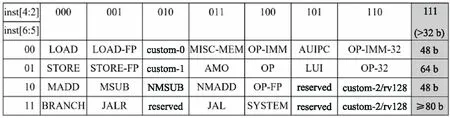
Figure 2 RISC-V base opcode map,inst[1:0]=11
随着开放指令集RISC-V的流行[4-6],其已应用于IoT智能硬件[7]、嵌入式系统[8]、信号处理[9]、人工智能[10]、安全设备[11]及高性能计算[12-14]等不同领域。大量开源和商业IP软核[15]的出现,使RISC-V处理器的快速定制化成为可能,让软硬件协同设计更加高效,大幅缩短了软硬件系统设计周期[16]。
本文基于FPGA设计了蜂鸟E203上[17,18]的计算向量内积的自定义指令,以加速矩阵运算。按照增加自定义指令、扩展ALU功能单元、连接控制信号和数据通路、FPGA原型验证和应用程序测试的流程开展了以下工作:
(1)在RV32IMAC指令集基础上增加计算向量内积的指令,确定指令类型和编码;
(2)扩展蜂鸟E203软核ALU部件,实现向量内积运算的硬件逻辑;
(3)连接控制信号和数据通路,完成向量内积指令的译码、派遣、执行、交付和写回;
(4)完成自定义指令的功能仿真,并在FPGA平台上进行原型验证;
(5)定制GCC编译器,增加对向量内积指令的支持,与硬件设计同步进行软件开发。
2 向量内积指令的定义和编码
蜂鸟E203软核是使用Verilog语言实现的,支持RV32IMAC指令集。每条指令由操作码、功能码和操作数组成,具有6种基本指令格式[4,17],如图1所示,分别是:用于寄存器-寄存器操作的R型指令、用于短立即数和访存load操作的I型指令、用于访存store操作的S型指令、用于条件跳转操作的B型指令、用于长立即数的U型指令和用于无条件跳转的J型指令。

Figure 1 Instruction format for base 32-bit RISC-V
有2种扩展RISC-V指令集的方法:
(1)模块标准化方法。使用RISC-V的标准扩展模块,包括B、E、H、J、L、N、P、Q等多种可选扩展[4]。
(2)在标准指令集基础上加入定制指令。与ASIC芯片相似,指令集可裁剪,具有更高的性能,但需要注意与标准指令的编码冲突问题。
为加速矩阵运算,本文采用了第2种方法,在RV32IMAC指令集基础上引入一条向量内积R型指令vec_inner_prod,选择标准指令编码空间(如图2所示)中的一个保留编码1101011作为向量内积的指令操作码,其指令格式如图 3所示。

Figure 3 Instruction format for vec_inner_prod
3 向量内积指令的硬件逻辑
3.1 蜂鸟E200系列CPU的基本架构
蜂鸟E200系列是两级流水线结构[17],如图4所示,指令的译码、执行、交付和写回均处于流水线的第2级,由EXU单元完成。
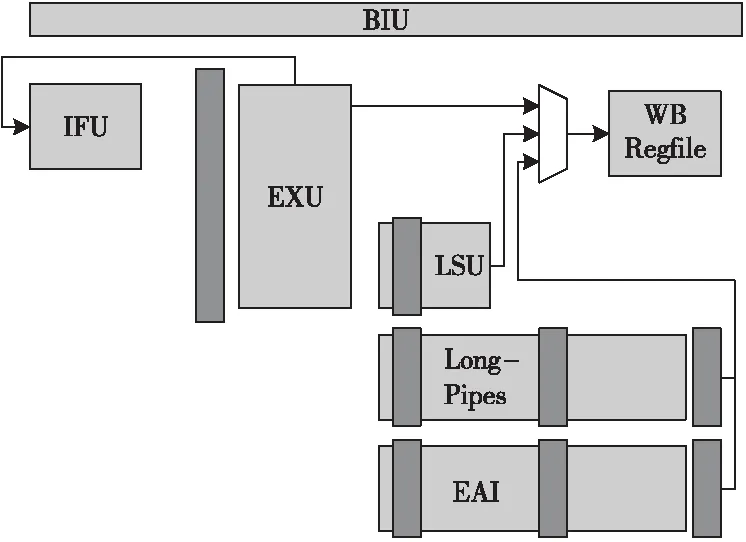
Figure 4 Two-stage pipeline of Hummingbird E203 IP
EXU的微架构如图5所示,其执行过程如下:
(1)取指单元IFU通过IR寄存器将指令发送给EXU进行译码;
(2)通过译码出的操作数寄存器索引来读取Regfile;
(3)维护指令的相关性;
(4)将指令派遣给不同的运算单元执行;
(5)交付指令;
(6)将运算结果写回Regfile。

Figure 5 Microarchitecture of EXU in Hummingbird E203 IP
增加向量内积指令需要对指令执行路径上的各个部件进行扩展,主要涉及“译码与派遣”部件、ALU、寄存器文件等。
3.2 向量内积运算部件
待增加的向量内积运算部件vec_mul用于计算向量A=[A0,A1,A2,A3]和B=[B0,B1,B2,B3]的内积,向量长度为4,存放于寄存器中,其计算结果如式(1)所示:
result=A0×B0+A1×B1+
A2×B2+A3×B3
(1)
向量内积运算部件vec_mul使用4个乘法器组成计算阵列,其逻辑结构如图6所示。

Figure 6 Logical structure of vec_mul unit
3.3 指令派遣和数据通路相关控制
指令译码部件根据向量内积指令中的操作码和功能码来产生控制信号,并发送至ALU部件的控制信号总线上,如图 7中①所示。当执行的指令为vec_inner_prod时,译码部件产生相应的operation选择信号发送到ALU的多路选择器,最后输出向量内积运算部件vec_mul的计算结果。
向量内积运算部件需要挂接在ALU内部,并将其输入端口连接至寄存器X10~X17,如图 7中②所示。
另外,为了防止与其它长指令目的寄存器之间有冲突,需要进行数据相关性检测,并记录向量内积指令,如图7中③所示。
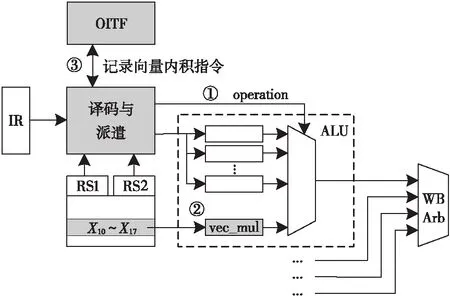
Figure 7 Control signals for vec-inner-prod
4 定制化RISC-V在FPGA平台上的验证
4.1 验证流程
定制化RISC-V的验证分为3个部分:硬件平台的验证[19]、交叉编译环境的验证[20]和应用软件的验证。硬件平台和交叉编译环境的验证用于保证硬件设计和软件开发环境的正确性,应用软件的验证用于测试软硬件的性能。验证流程如图8所示,定制化的RISC-V处理器设计通过EDA工具Vivado生成配置FPGA的比特流文件;应用测试程序通过定制化的交叉编译器生成与硬件相匹配的二进制可执行文件;两者加载到FPGA后即可在定制RISC-V处理器上运行二进制应用程序。

Figure 8 Validation procedure on FPGA
4.2 硬件平台
本文采用Perf-V Artix-7 35T开发板[21],如图8所示,使用的板载FPGA型号为XC7A35T-1FTG256C,FPGA外部时钟频率为50 MHz。
操作系统为Ubuntu 16.04 LTS,硬件开发环境为Vivado 2018.3。
根据前述分析,在E203各部件对应的Verilog代码中添加向量内积指令的相关运算和控制逻辑,其层次结构如图 9所示,原理如图10所示。
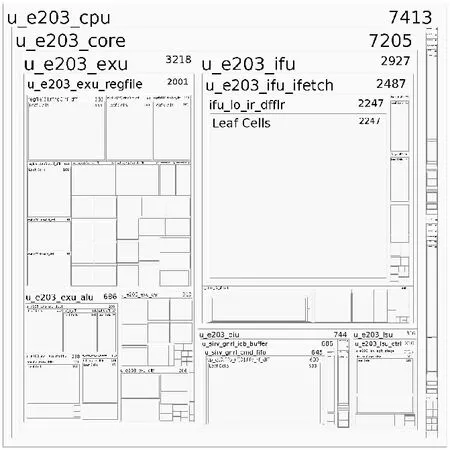
Figure 9 Hierarchy of the customized RISC-V core

Figure 10 Schematic diagram of the customized RISC-V core
在Vivado中进行综合、布局布线(如图11所示),最终生成配置FPGA的比特流文件并通过JTAG下载。未使用 FPGA DSP单元的情况下,增加向量内积指令及相关控制逻辑会多使用FPGA内9.3%的LUT硬件资源,增加向量内积指令前后硬件资源占用情况如表1所示。
Figure 11 Floorplan of FPGA prototype
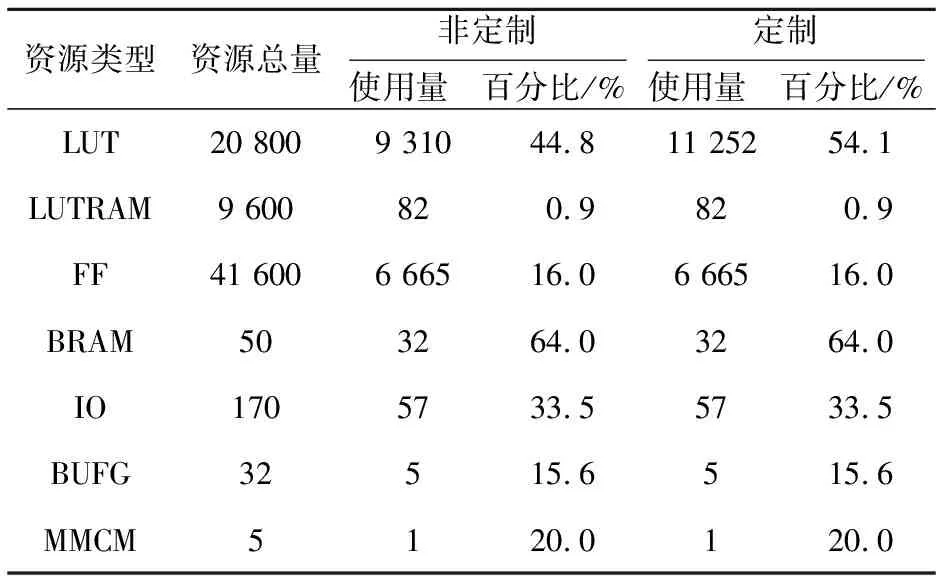
Table 1 Resource utilization comparison for customized/non-customized RISC-V
4.3 软件开发环境
应用测试程序必须使用定制化的交叉编译器才能生成与硬件相匹配的二进制可执行文件。在基于64位x86架构的Ubuntu 16.04 LTS主机上定制交叉编译器的步骤如下:(1)根据自定义指令的操作码计算指令码、指令掩码并描述指令格式;(2)将其加入到编译器源代码RISC-V的机器描述文件[22,23]中;(3)在主机上编译支持定制RISC-V指令的交叉编译器。
在开发板BSP(Board Support Package)[21,24]的支持下,可将C标准库printf等函数输出转发到串口。测试程序以内联汇编的方式调用向量内积计算汇编指令,该指令汇编助记符为vec_inner_prod,编译产生的二进制可执行文件使用OpenOCD[25]通过USER JTAG下载到flash存储器。
4.4 测试程序
测试程序为三重循环的矩阵乘法运算,外层的两重循环对应于结果矩阵中的每个元素,内层循环用于计算2个向量的内积,未使用自定义向量内积指令的C语言代码如程序1所示。
程序1未使用向量内积指令vec_inner_prod的矩阵乘法
for(i=0;i for(j=0;j for(k=0;k { c[i*C_COL+j]+=a[i*A_COL+k]*b[k*B_COL+j]; } 由于向量内积指令的向量长度为4,因此需要改造上述程序1中的代码,让内层循环中的每4个元素组成1个向量,即内层循环以4为步长进行递增,如程序2代码所示。对于长度不为4倍数的向量内积,可通过补零处理使其长度成为4的倍数。 程序2使用向量内积指令vec_inner_prod的矩阵乘法 for(i=0;i for(j=0;j for(k=0;k { asm volatile( "lw x10,%[a0]
lw x14,%[b0]
" "lw x11,%[a1]
lw x15,%[b1]
" "lw x12,%[a2]
lw x16,%[b2]
" "lw x13,%[a3]
lw x17,%[b3]
" "vec_inner_prod %[reg_output],x10,x14
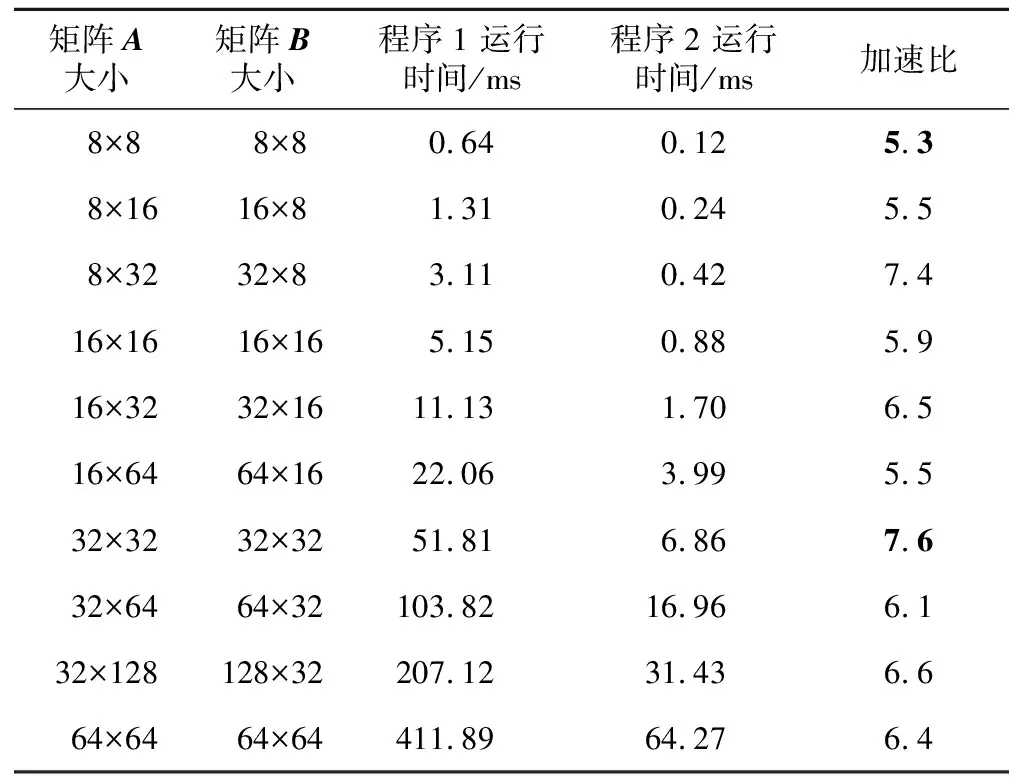
" :[reg_output]"=r"(result) :[a0]"m"(a[i*A_COL+(k+0)]), [b0]"m"(b[(k+0)*B_COL+j]), [a1]"m"(a[i*A_COL+(k+1)]), [b1]"m"(b[(k+1)*B_COL+j]), [a2]"m"(a[i*A_COL+(k+2)]), [b2]"m"(b[(k+2)*B_COL+j]), [a3]"m"(a[i*A_COL+(k+3)]), [b3]"m"(b[(k+3)*B_COL+j]) :"x10","x11","x12","x13", "x14","x15","x16","x17" ); c[i*C_COL+j]+=result; } 对程序2最内层循环代码进行了如下改造:使用内嵌汇编指令,将2个向量分别载入到寄存器,然后执行向量内积指令 vec_inner_prod,运算结果保存在变量result中,最后将其累加到结果矩阵中相应的元素上。 分别对程序1和程序2进行交叉编译生成目标平台的二进制可执行文件,两者在FPGA平台上的计算结果一致,对于不同规模的矩阵乘法,其所需时间如表2所示,最大加速比为7.6,最小加速比为5.3。 Table 2 Speedup of matrix multiplication on the customized RISC-V 本文基于FPGA在开源IP蜂鸟E203上通过增加自定义指令、扩展ALU功能单元、连接控制信号和数据通路、FPGA原型验证、定制交叉编译环境和应用程序测试的流程,设计了扩展RV32IMAC指令集的向量内积指令,实现了加速矩阵运算的定制化RISC-V处理器。对矩阵乘法测试程序上,定制化RISC-V处理器的计算性能有显著提升,性能加速比达到了5.3~7.6。同时,基于定制化的交叉编译器,软件开发与硬件设计可同步进行,大幅缩短了软硬件协同设计周期。5 实验结果
6 结束语
