基于 Spark 平台的网络游戏用户流失预测方法*
2022-10-28胡艳芳
胡艳芳,熊 文,高 炜
(云南师范大学信息学院,云南 昆明 650500)
1 引言
随着移动互联网和智能终端的普及,国内游戏市场已经进入存量竞争阶段,手机游戏行业的从业者面临着前所未有的竞争。一方面,由于从业者版权意识薄弱,导致公司之间相互抄袭,游戏同质化竞争严重。另一方面,无线互联网的发展已经进入稳定期,新用户的获取成本不断攀升。因此,部分敏锐的游戏公司开始调整方向,把对存量用户的服务放在首要位置。如何深入地了解用户需求,推动产品升级迭代,执行精细化的市场策略,减缓或阻止用户流失成为运营者面临的首要问题。
如何在游戏用户的日常行为数据中挖掘有价值的知识和信息,来支持游戏平台的运营决策,研究者们已经进行了大量行之有效的探索。这些探索可以分为3个方面。
(1)特征的选择与提取方面:魏玲等[1]通过直方图检验与卡方检验确定影响用户流失的特征变量。舒文丽等[2]引入二次特征提取的方法,从多个维度描述用户体验和行为,并针对多个维度分别建模,以提高流失与非流失用户体验的区分度。郑杰文[3]通过使用激活扩散算法提取用户相关性特征来提高预测性能,并结合用户之间的相关性统计和特征的相对重要性来证实用户相关性的作用。Kamya等[4]提出了一个基于特征提取的流失预测模型,该模型侧重于具有显著流失能力的最相关特征的使用。
(2)分类器的设计与选择方面:郑杰文[3]提出了基于Spark平台的Mini-Batch BP神经网络分布式算法来改善2种传统的BP神经网络算法的性能,从而减少训练时间。桂昂稀[5]基于gcForest深度森林算法搭建用户流失预测模型,并与常见的机器学习算法进行对比,得到基于gcForest深度森林算法的用户流失预测模型优于传统机器学习算法的结论。陈林辉[6]使用机器学习算法构建了一个用户流失预测模型,对与用户流失相关的数据进行训练。魏玲等[1]提出了基于改进RFM(Recency Frequency Monetary)与GMDH(Group Method of Data Handing)算法的用户流失预测。Shirazi等[7]提出利用大数据构建用户流失预测模型。Olasehinde等[8]调用大数据分析工具Spark中的随机森林分类器与普通的随机森林分类器进行对比,发现Spark结合随机森林分类器的计算性能更好。
(3)不平衡分类问题方面:桂昂稀[5]基于EasyEnsemble算法的思想,将SMOTE(Synthetic Minority Over-sampling TEchnique)算法和ENN(Edited Nearest Neighbor)算法融合到gcForest算法框架之中,提出了OSEEN-gcForest算法,得到了更优越的性能。吴悦昕等[9]在流失预测中使用了基于采样法的不平衡数据处理策略,并对现有主要的几种采样算法进行了对比实验和分析。
但是,随着游戏平台和用户规模的扩大,游戏平台产生的数据成指数级增长,海量的用户行为日志也源源不断地产生,传统的数据分析工具已经不能满足游戏平台大规模数据的存储和分析需求。本文借助Spark大数据计算引擎,基于一个超大规模的真实游戏用户日志数据集,对游戏用户的流失情况进行了预测。首先,在游戏用户行为日志中分别抽取静态特征和动态特征;然后,对这些特征进行重要性计算和选择;最后,用随机森林RF(Random Forest)[10]等经典算法对挑选出的特征进行建模,模型以一组特征作为输入,流失与否作为输出。具体来讲,本文的贡献如下:
(1)提出了一种基于集成学习的游戏用户流失预测方法,从用户信息和行为日志数据中构建静态特征和动态特征并根据相关性对特征进行选取。基于选取的特征,使用随机森林分类器构建二分类预测模型,实现对游戏用户的流失预测。
(2)系统地评估了随机森林、支持向量机SVM(Support Vector Machine)[11]、多层感知机MLP(Multi-Layer Perceptions)[12]、梯度提升决策树GBDT(Gradient Boost Decision Tree)[13]、逻辑回归LR(Logistic Regression)[14]和分类回归树CART(Classification And Regression Tree)[15]等经典算法,发现随机森林的预测精度最高,预测准确率达到了91%,如果将用户进一步细分,预测精度可以达到93%。
2 背景和动机
某在线平台开发并运营了近百款地方游戏,包括斗地主、打麻将和棋类等益智类游戏。用户通过手机和平板等移动终端参与游戏互动,游戏公司后台采集并存储用户的行为数据。截止到2021年12月底,该游戏平台的全球注册用户数超过了1 600万,日活跃用户数超过了100万,最高同时在线用户超过了10万。面对不断增长的数据量,游戏公司的IT部门通过构建大数据平台来满足数据的存储和分析需求。运营部门借助大数据技术和数据挖掘技术来精细化市场营销。如何识别流失用户的特征,构建流失预测模型,通过营销策略阻止和缓解游戏用户的流失成为运营部门面临的首要问题。图1是该平台2020年8月份到2021年3月份共8个月的用户流失数目。由图1可以看出,该游戏平台的用户流失情况严重,尤其在2021年的2月和3月流失用户数猛增。
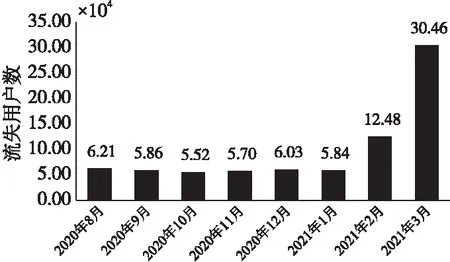
Figure 1 Number of churn users per month
针对该平台用户数量庞大,用户流失情况严重的问题,市场营销一直试图解决该问题,导致费用居高不下。本文借助Spark平台实现了大规模的数据处理、对流失用户的特征进行分析,并结合随机森林算法对游戏用户进行了流失预测,从而为游戏运营商提供决策支持。
3 研究方法
3.1 问题定义
定义1(包房) 游戏是在包房里进行的,用户需要创建包房或进入包房。
定义2(注册包ID) 运营商将游戏安装包放在不同的平台供用户下载注册,每个平台的安装包有其特有的ID。运营商可根据用户的注册包ID判断该用户来自哪个平台。
定义3(特征) 在本文中指用户的属性,比如游戏局数、登录天数和游戏时长等。
定义4(标记) 在本文中将用户标记为流失用户和未流失用户。
定义5(分类器) 对样本进行分类的算法的统称。
定义6(club) 亲友圈的代称。亲友圈的功能是借助其特有的机制帮助圈内的亲戚和朋友更好地进行游戏互动和交流。
3.2 本文方法
本文方法包括数据预处理、特征构造与选择、游戏用户流失预测和应用4个部分,如图2所示。
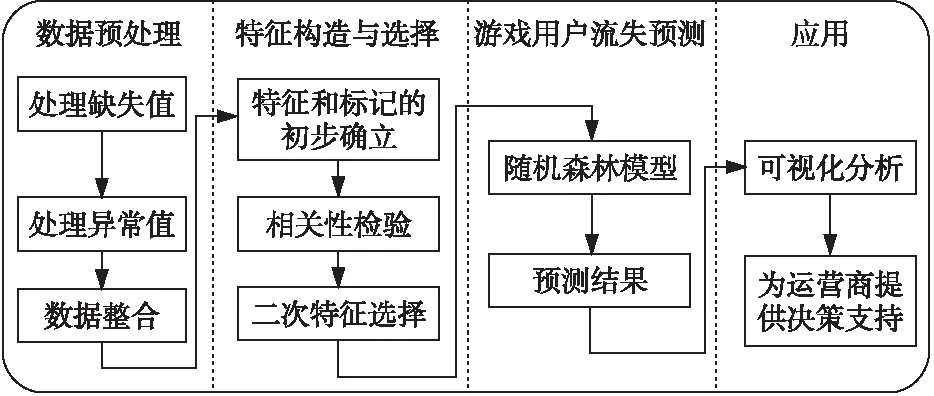
Figure 2 The proposed method
首先,对数据进行预处理,去掉缺失值和异常值,将多个表连接起来进行数据整合。其次,进行特征构造和选择,初步确立特征和标记。本文将用户一个月不玩游戏定义为流失,流失的标记为“1”,不流失的标记为“0”。初步选取了用户的静态特征和动态特征。最后,将标记和特征组合起来,得到字段如表1所示的样本数据。

Table 1 Preliminary sample data
在确定好特征和标记后,单独对每个特征和标记进行相关性检验,并根据检验结果进行二次特征选择。接下来,针对含有特征和标记的样本集构建随机森林模型,对游戏用户进行流失预测。
下一步,分4种情况对流失用户进行特征可视化分析,分别是:流失用户整体、流失用户中的新用户、流失用户中的中间用户、流失用户中的老用户。其中,将注册时长小于6个月的用户定义为新用户、注册时长在6~32个月的用户定义为中间用户,注册时长大于或等于32个月的用户定义为老用户。将这4个数据源的特征可视化结果进行对比分析,观察特征分布有何不同。
最后,将预测结果和可视化结果反馈给游戏运营商,为其提供决策支持。
3.3 相关性检验原理
本文选用了Point-biserial[16]相关性检验。Point-biserial相关性检验通常用于检验连续变量和二元分类变量的相关性,其公式如式(1)所示:
(1)
其中,A1表示二元分类变量中的“1”对应的连续变量的均值;A0表示二元分类变量中的“0”对应的连续变量的均值;Sn表示连续变量的标准偏差;p表示二元分类变量中“1”在总的变量中的比例;q表示二元变量中“0”在总的变量中的比例。
3.4 随机森林工作原理
相对于其它算法,随机森林在处理大数据集时表现更好,并且对于不平衡的数据集来说,随机森林可以平衡误差且模型泛化能力强、训练速度快。随机森林工作原理如图3所示。假设从含有特征和标记信息的数据中选出的训练集为S,该训练集包括N个样本,M个特征。随机森林的工作流程如下所示:
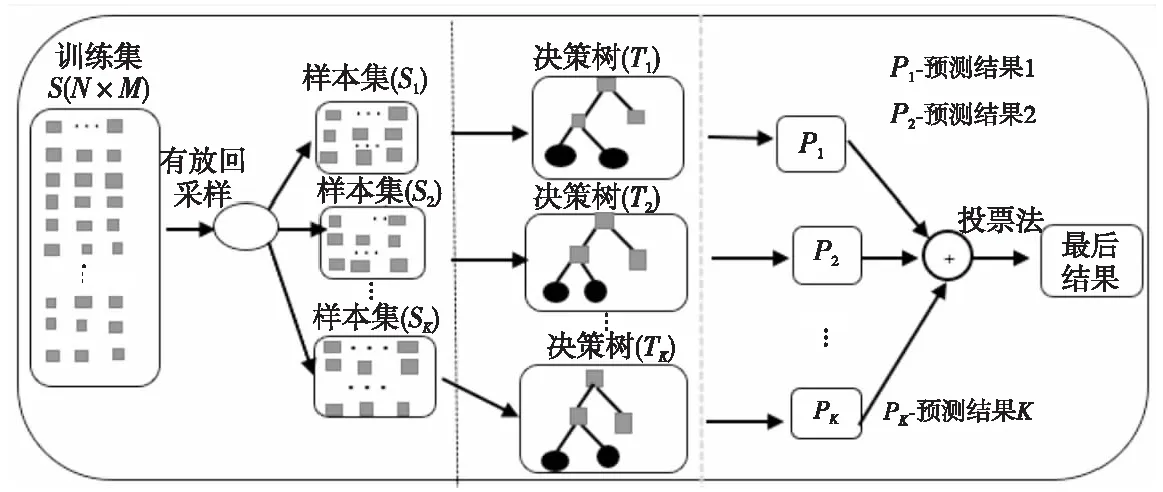
Figure 3 Schematic diagram of random forest
步骤1每次有放回地从训练集S中随机抽取1个样本,抽取N次,得到样本集S1。
重复执行步骤1,得到S2,S3,…,SK。
步骤2随机从T1决策树的属性集中抽取一个有m个属性的子集a,再从a中选择一个最优的划分属性。对决策树T2,T3,…,TK重复执行步骤2。
步骤3以投票法作为结合策略,得到最后的预测结果。
3.5 模型的评估标准
本文研究需要同时考虑查全率P和查准率R,所以选择了查准率-查全率曲线(P-R曲线)图[17]、受试者工作特征ROC(Receiver Operating Characteristic)图[18]、ROC曲线下的面积AUC(Area Under Curve)[19]及Fβ值[20]作为模型的评估标准。在介绍P-R曲线图、ROC曲线图、AUC及Fβ之前,先介绍几个概念:真正例(True Positive)、假正例(False Positive)、真反例(True Negative)和假反例(False Negative)。通常借助表2的混淆矩阵[20]来理解这几个概念。

Table 2 Confusion matrix of classification results
式(2)~式(5)分别是查准率P、查全率R、真正例率TPR和假正例率FPR的计算公式:
(2)
(3)
(4)
(5)
P-R曲线图的横轴和纵轴分别是查全率和查准率。预测模型的查全率和查准率在P-R曲线图上能被直观地展现出来。如果预测模型A的P-R曲线被预测模型B的P-R曲线完全“包住”,说明预测模型B的性能比预测模型A的性能好。
ROC图的横轴是假正例率,纵轴是真正例率。如果预测模型A的ROC曲线被预测模型B的ROC曲线完全“包住”,说明预测模型B的性能比预测模型A的性能好。
除了用P-R曲线图、ROC图和AUC值以外,本文还采用了Fβ进行度量。Fβ的计算公式如式(6)所示:
(6)
其中,β>0表示查全率对查准率的相对重要性;β=1时退化为标准的F1;β>1时查全率有更大的影响;β<1时,查准率有更大的影响。本文方法希望尽可能少地漏掉流失用户,因此查全率更重要。
4 实验环境及数据集
4.1 实验环境介绍
(1)实验环境硬件配置如表3所示。

Table 3 Hardware configuration of experimental environment
(2)实验环境软件配置如表4所示。
Spark MLlib作为Spark的核心组件之一,是Spark对常用机器学习算法的实现库。本文在Spark平台实现数据预处理及样本数据的生成,借助Spark MLlib构建预测模型。同时,为了更直观地将6个算法的对比效果展现出来,本文实验借助Python进行可视化。
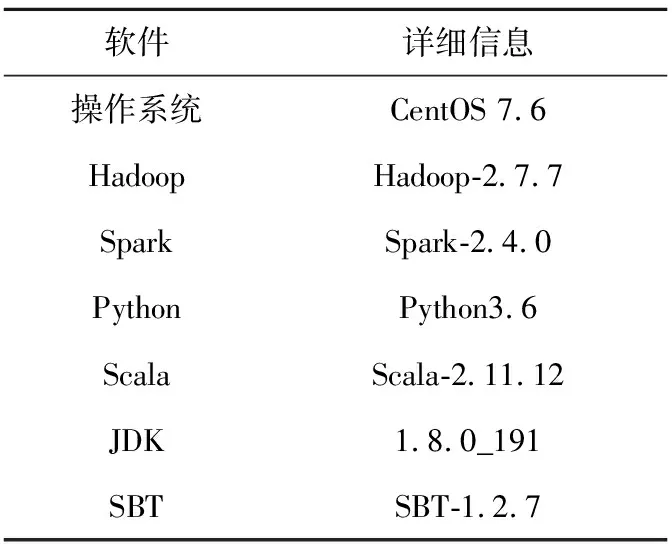
Table 4 Software configuration of experimental environment
4.2 实验数据集
本文研究是基于某游戏平台的真实游戏用户数据来进行的。实验数据包括从2020年7月至2021年4月共10个月的用户信息,数据集大小为420.3 GB,其中,用户有300万左右。为了尽可能全面地了解用户行为特点,初步选取了可能与用户流失相关的所有字段,如表5所示。

Table 5 Preliminary selected fields
5 实验及结果分析
5.1 特征的相关性检验
Point-biserial函数是用来检验连续变量和二元分类变量之间的相关性。在本文的数据集中,标记是二分类变量;登录天数、注册时长、游戏总局数、去过的包房数、游戏总时长、所在club的总局数、所在club的游戏总时长和用户年龄是连续变量,所以选择Point-biserial函数进行相关性检验。由于性别是二分类变量,packageID是无序变量,在自变量是二分类的情况下,暂时没有找到可以检验的方法,所以这2个变量不加入相关性检验。
本文调用了scipy.stats.pointbiserialr(x,y)函数计算点双线相关系数,也就是计算2个变量之间的关系。点双线相关系数的取值在[-1,1],当值是0时,表明没有相关性;取值越靠近1或-1,表明相关性越强。表6是标记与各个特征的相关性检验结果。
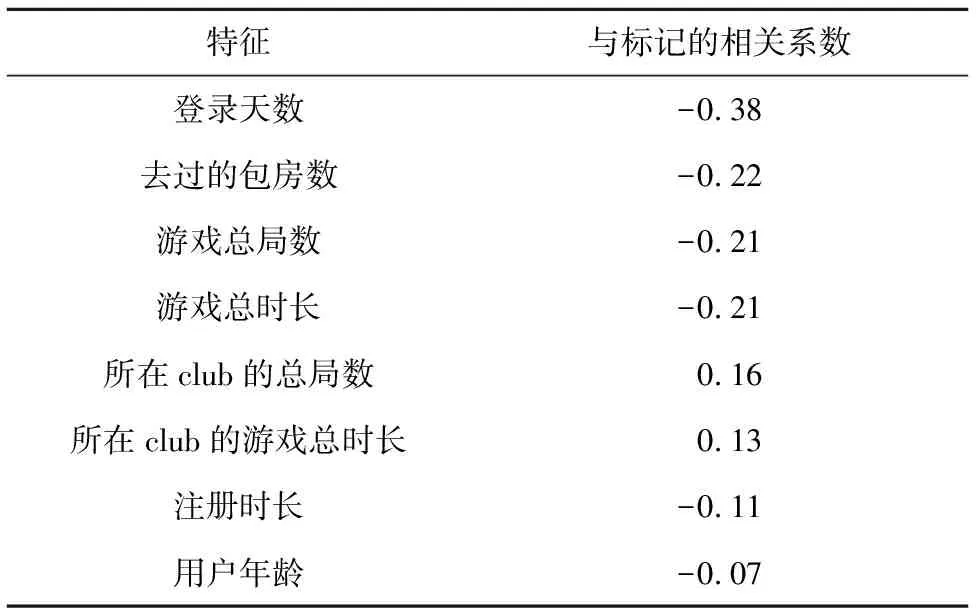
Table 6 Correlation test results
从表6可以看出,这几个特征都与标记具有一定的相关性。其中,登录天数、去过的包房数、游戏总局数和游戏总时长这几个特征与标记有超过0.2的负相关关系。但整体来看,这几个特征与结果的相关性都比较弱,考虑到多个因素共同作用对结果产生影响的情况,此处继续保留所有特征。
5.2 流失用户特征的可视化分析
对流失用户的特征进行可视化分析,得到流失用户的特征分布,能帮助游戏运营商进行运营策略的调整。可视化特征包括:年龄、性别、注册包ID流失率、登录天数、注册时长、总的游戏局数、去过的包房数、游戏总时长、所在club的游戏总时长和所在club的游戏总局数。
本文对2020年8月至2021年3月间的流失用户数据进行有放回抽样,共得到21 430名流失用户。本文将其分为4种情况进行特征分析,分别是:全部流失用户、流失用户中的新用户、流失用户中的中间用户和流失用户中的老用户。其中,每种情况下注册包ID的流失率为ML/NL,其中,ML表示该情况下的注册包ID对应的流失用户数目,NL表示该情况下的流失用户总数。下面选取了几个可视化效果比较有特点的特征进行展示。
(1)流失用户年龄分布。
图4是流失用户的年龄分布图。由图4可以看出,4种情况下的流失用户的年龄分布情况基本相同。其中,年龄段在28~33岁的流失人数最多,基于现实因素的考虑,游戏玩家的年龄主要是集中在23~43岁,28~33岁的人们多数会偏重于家庭和工作,由此造成了用户的流失。运营商可以针对这部分人群采取一定的营销措施,比如在下班后或周末时间针对这部分用户进行一定的营销活动,从而达到挽回流失用户的目的,提高游戏运营的效益。
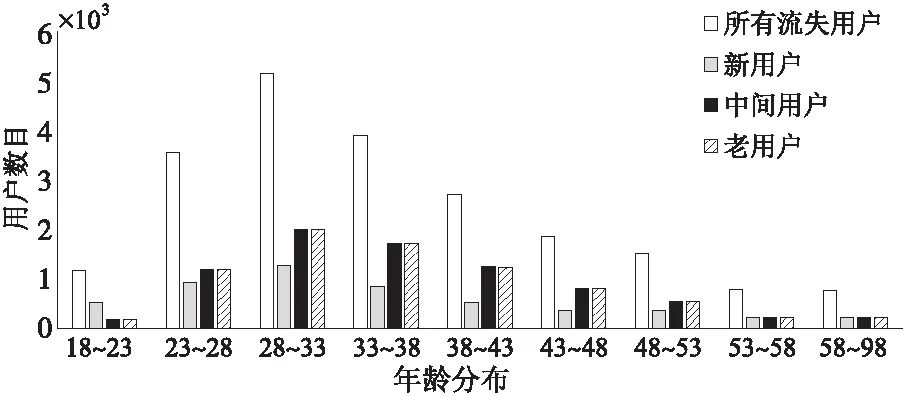
Figure 4 Age distribution of churn users
(2)注册包ID的流失率。
图5是注册包ID的流失率分布图。从图5可以看出,整体情况下,流失率在40%及以上的注册包ID有10003、10011和10037。其中,新用户中流失率比较严重的注册包ID是10003和10033;中间用户中流失率比较严重的是10011和10037;老用户中流失率比较严重的是10037。对于流失情况严重的注册包ID,说明通过这几个ID注册的用户质量较差,由此运营商可以减少在这几个注册包ID所在平台的广告投放量,降低游戏的运营投入。

Figure 5 Chrun rate of registration package ID
(3)所在club的游戏总时长。
图6是流失用户所在club的游戏总时长分布。图6中,4种情况下的流失用户所在club的游戏总时长分布情况基本相同,都分布在[0,4.17]和[66.67,79.17]。可以看出,流失用户所在的club的游戏时长要么过短要么过长,从侧面说明club的游戏时长过短或过长都会导致club中的用户流失。所以,运营商应该多关注游戏时长过短或者过长的club,并采取措施对这些club中的用户进行挽留。
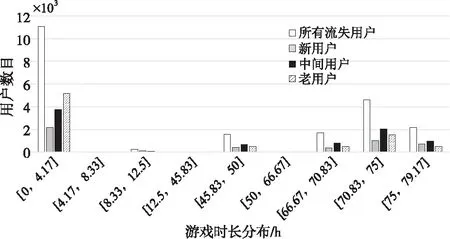
Figure 6 Distribution of total game duration of churn users’ club
通过可视化分析可以得出如下结论:
(1)流失用户的年龄、登录天数、游戏总局数、去过的包房数、游戏总时长、所在club的总时长和所在club的总局数等特征在4种情况下的分布几乎一致;注册包ID和性别的分布稍微有点不同,造成这种情况的原因可能是因为游戏公司设定了注册包ID默认的注册性别。
(2)登录天数、去过的包房数、游戏总时长和游戏总局数等几个特征与流失用户的人数成一定的反比;年龄、性别、注册包ID、注册时长、所在club的游戏总时长和所在club的游戏总局数等几个特征的分布特点各不相同。通过与前面的相关性检验比较发现,可视化结果与相关性检验结果所得的结论一致,可视化分析可以更直观地看到这些特征对用户流失的影响。
5.3 预测模型的评估
预测模型的评估部分使用的是相同的训练集和测试集。训练集和测试集是按k折交叉验证法进行划分的。图7是在相同的训练集和测试集下,支持向量机(SVM)、随机森林(RF)、逻辑回归(LR)、多层感知机(MLP)、梯度提升决策树(GBDT)和分类回归树(CART)等6种常见算法的ROC曲线及AUC值。从图7可以看出,梯度提升决策树、逻辑回归和随机森林三者的表现相差不大。其中,随机森林算法的ROC曲线面积,即AUC值,最大达到了0.875 7,表现最好。
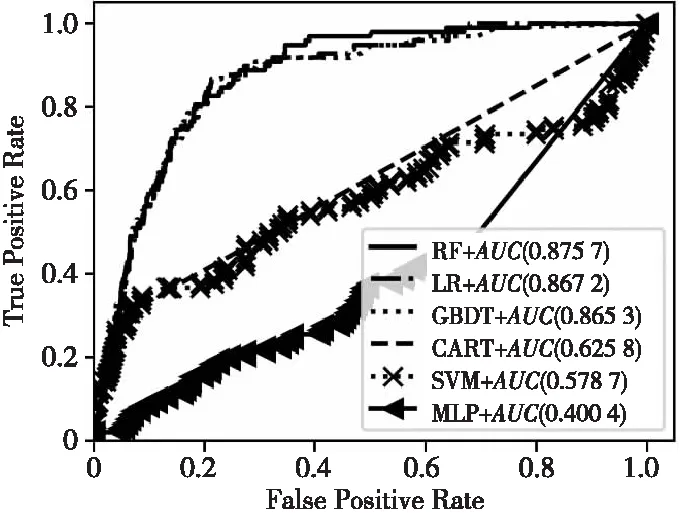
Figure 7 ROC curves and AUC values of six algorithms
图8是将全部数据放入在Spark平台构建的各个分类模型的Fβ值,可以看出,在β取值0.5,1.0和1.5时,梯度提升决策树、多层感知机、逻辑回归、随机森林和支持向量机的表现相差不大。其中,随机森林的Fβ值都是最高的,即随机森林算法在本文中表现最好。
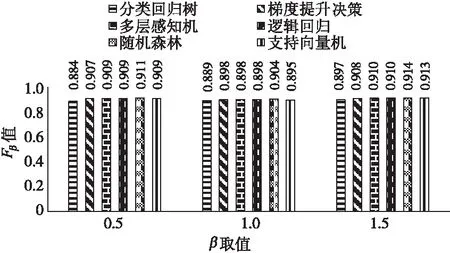
Figure 8 Fβvalues of six algorithms
图9是随机森林算法在流失用户整体、流失用户中的新用户、流失用户中的中间用户、流失用户中的老用户这4种情况下的P-R曲线图。从图9可以直观地看出预测方法在4种情况下的查全率和查准率。通过对图中P-R曲线进行对比分析,可以看出将用户分为新用户、中间用户和老用户之后,随机森林算法的查全率和查准率都得到了很大的提升。

Figure 9 P-R curves of random forest algorithm in four cases
图10是统一取β=1.5时4种情况下随机森林算法的Fβ值,可以看出,把用户分情况用随机森林算法建模以后,可以提高部分情况下的Fβ值。

Figure 10 Fβ values of random forest algorithm in four cases
同时,从图10可以看出,在没有对用户进行划分的情况下,Fβ值已经到达91%,但从表6 相关性检验结果上看,各个特征的相关性都比较弱,这里可以进一步说明用户流失受到了多个因素影响。
6 结束语
本文以一个大规模的真实网络游戏用户日志数据集为基础,借助Spark大数据处理平台和机器学习算法,对游戏用户流失情况进行建模和预测,并对流失用户的特征进行了系统分析。在数据处理过程中,使用Spark SQL对数据进行了预处理,完成了特征的选择和样本的生成;使用Spark MLlib算法库中的经典算法进行建模。实验结果显示,随机森林算法在此次预测中表现最佳,预测精确度达到了91%。
本文还可以从以下2个方面开展进一步的研究:
(1)改进用户的分类方法,以替代目前的静态划分方法。使用用户特征进行聚类,并为每种类型的用户进行建模和预测,以进一步提升预测模型的精确性。
(2)本文在选择最优预测模型时,只选择了ROC、AUC值及Fβ值作为评价指标,下一步可考虑将模型的训练成本纳入评价指标,结合预测模型的实际部署环境,全方位评价各种模型。
