基于时域-频域哈希编码的电网图像检索方法*
2022-10-28强梓林刘建国刘云峰
强梓林,刘建国,刘云峰,卫 栋,强 彦
(1.太原理工大学矿业工程学院,山西 太原 030600;2.国网晋城供电公司,山西 晋城 048000;3.太原理工大学信息与计算机学院,山西 太原 030600)
1 引言
电网的顺利畅通对国民经济有着重要的影响,与人们的日常生活息息相关,准确及时地发现电网系统中存在的问题并快速补救可以在一定程度上降低国民经济损失[1]。电网系统规模逐年增大,电网结构越来越复杂,如何精准高效地管理电力设备变成了一件越来越具有挑战性的事情。电力设备具有分布广泛、数量众多和种类多样等特点,亟需一种高效的方法来管理和维护这些电力设备。在一线生产过程中,大量的电力设备相关图像会被采集并保存至系统数据库中。在遇到问题时,这些一线技术人员采集的设备图像可以帮助快速地检索和精准定位设备所存在的问题并提供解决方案,工作人员的工作效率可以获得很大提升。
鉴于哈希方法在存储空间利用率和检索速度方面的优势,哈希方法在图像检索方面受到了大量研究人员的关注和研究,并提出了诸多哈希方法。局部敏感哈希LSH(Locality Sensitive Hashing)[2]是最初提出的哈希图像方法,该方法采用随机映射对样本进行编码,使得原始空间中距离较近的数据经过处理后发生“碰撞”的概率比距离远的数据发生“碰撞”的概率更大。谱哈希SH(Spectral Hashing)[3]能够产生简洁的哈希码,该方法通过松弛条件,将拉普拉斯矩阵的门限特征向量的子集作为目标编码。有监督核哈希方法KSH(Kernel-based Supervised Hashing)将哈希函数训练过程与少量监督信息相结合,提高了哈希方法的质量[4]。
此外,近年来随着深度学习的快速发展,Xia 等人[5]提出一种基于卷积神经网络的哈希方法CNNH(Convolutional Neural Network Hashing),该方法利用标签信息构造图像训练集的相似性矩阵,并分解产生相应的哈希码;并且使用优化后的损失函数来促进网络更好地调整网络参数以及图像的二值码。Zhao 等人[6]提出了一种基于语义排序的深度哈希框架,直接得到与待查询图像相似的图像序列,并对最终的评测指标进行优化。Liu 等人[7]提出了一种基于监督学习的哈希编码方法,利用卷积神经网络学习得到有标签图像对的哈希码,检索时通过计算候选图像与目标图像库哈希码的汉明距离返回相似图像。Liu 等人[8]提出了一种基于三元组的图像对哈希编码方法DTQ(Deep Triplet Quantization),利用其提出的深度三元组量化损失函数,进一步提高了基于深度学习的哈希编码模型性能。图像哈希方法在电网数据方面应用较少,工作人员在查询相似电网图像数据时费时费力,因此加强电网检索系统对图像数据的相似性度量能力对于提高电网人员工作效率具有重要作用。
2 方法
电网图像具有与自然图像相似的特点,图像中通常都有一个或多个主要的目标物体,且背景较为复杂多变,非常适合使用卷积神经网络进行处理。因此,本文拟结合卷积神经网络与频域信息,挖掘图像更深层的隐含特征,建立可以切实有效提高工作人员检索效率的哈希图像检索模型。
2.1 整体框架
本文所提出的基于深度学习的哈希编码方法主要包括4个阶段:(1)构建基于时域-频域的卷积神经网络;(2)根据模型全连接层的编码向量选择三元组数据进行训练;(3)添加哈希编码层输出图像的哈希编码;(4)保留原有分类层进一步约束网络训练。最终的输出结果可以帮助工作人员快速准确地查找到相似电力设备的信息。整体框架如图1所示。
2.2 三元组选择
(1)
其中,m为强制划分正样本对和负样本对的边界值。如果符合式(1)的无关图像数量大于1,则随机选择一幅无关图像组成元组。最终训练元组的筛选方法可以描述成式(2):
(2)
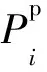
2.3 网络架构
2.3.1 FDB
频域信息在很多领域都作为重要的特征被考虑和研究,比如人脸识别、目标检测及图像分类等。本文将频域信息与密集网络进行结合,提出使用傅里叶密集连接块FDB(Fourier Dense Block)来更加有效地提取图像特征。FDB一共包括3个部分:快速傅里叶变换FFT(Fast Fourier Transform)、2个密集连接块和逆快速傅里叶变换IFFT(Inverse Fast Fourier Transform)。FDB结构如图3所示。
快速傅里叶变换可以将时域信号转化为频域信号,且可以实现比离散傅里叶变换DFT(Discrete Fourier Transform)更快的计算,从而减少计算消耗。逆快速傅里叶变换负责将密集连接块筛选过的频域信息转化为时域信息并输出。此外,本文选择了双通道的密集连接网络分别从振幅和相位2个通道提取具有高判别度的频域信息。快速傅里叶变换的结果可以表示为实部与虚部的极坐标系下的和形式,如式(3)所示:
F(u,v)=R(u,v)+iI(u,v)
(3)
其中,R(u,v)和I(u,v)分别为输入图像傅里叶变换的实部和虚部信号,u的取值范围为{0,1,2,…,M-1},v的取值范围为{0,1,2,…,N-1},M和N为傅里叶变换后的图像宽和高。实部和虚部可以用来表示信号的振幅和相位特征。
对于每个密集连接块,本文在内部设置了2个残差块。残差块具有防止梯度爆炸和模型退化的作用,可以有效提高特征的辨别性。每个残差块又设置了3个卷积层,卷积核大小分别为1×1,2×2和3×3。密集连接块的输出会被堆叠并输出到逆傅里叶变换,以重新转换为时域信号进行下一阶段的卷积。FDB的前向传播过程如式(4)所示:
y=F-1(R(·)×WR,I(·)×WI)
(4)
其中,y是FDB的输出,F-1(·)为逆傅里叶变换,WR和WI分别为FDB关于实部和虚部信号的权重矩阵。前向传播负责根据既定的损失函数对权重矩阵进行优化,以提高所提取特征的多样性和有效性,提高最终的预测正确率。
此外,FDB的反向传播过程如式(5)所示:
(5)
其中,L(·)为训练阶段的损失函数,x为FDB的输入。考虑到x被分解为了实部和虚部2部分,因此在计算反向传播梯度时需要分别考虑实部和虚部的梯度更新量。
2.3.2 转换层
FDB从频域信号中提取有效的特征信息,但是提取到的特征往往具有很高的数据维度。本文通过引入转换层对提取到的特征进行降维,还设计了1×1的卷积核和平均池化层来对提取到的特征图进行特征降维及下采样。
2.3.3 多任务学习
为了更好地约束哈希编码的正确性,本文将全连接层的神经元个数调整为现有数据集的类别数目以适应新的分类任务。考虑到现有的基于深度学习的哈希编码模型都是直接使用预训练的卷积神经网络和哈希编码层辅以相应的损失函数进行训练,本文保留了原有的分类层,使用Softmax激活函数和交叉熵损失函数约束模型训练,防止模型发生过拟合。对于神经网络而言,多个任务同时学习,模型能捕捉到多个任务之间关于目标样本的共性属性,从而降低模型在原始任务上出现过拟合的风险。
2.4 损失函数
为了更加全面地约束网络训练,本文共提出了3部分损失,分别为距圆损失、交叉熵损失和量化正则项。
2.4.1 距圆损失
考虑到使用了三元组作为模型的输入,本文使用了如式(6)所示的损失函数进行训练:
(6)
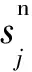
(7)
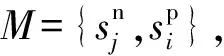
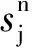
(8)
(9)

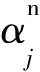
2.4.2 交叉熵损失
除了针对样本对学习引入的距圆损失,本文还引入了交叉熵损失来从另一个维度约束网络训练。本文网络对输入图像进行哈希编码的同时,还能够准确辨别出当前输入图像的类别。考虑到对于同一个样本,不同任务的深层特征仍有其共性存在,分类损失能够帮助神经网络更准确地挖掘图像中具有高表达性的特征。已知网络对于当前图像的预测结果为yp,当前图像的真实标签为ygt,则交叉熵损失函数的计算如式(10)所示:
Lce=-[ygtlogyp+(1-ygt)log(1-yp)]
(10)
2.4.3 正则项约束
对于已有的基于深度学习的哈希编码方法而言,他们倾向于使用易饱和的sigmoid或tanh函数作为哈希编码层的非线性激活函数。但是,上述易饱和的激活函数对于输入非常敏感,在训练过程中不可避免地会导致网络学习率减慢甚至阻碍网络顺利收敛。因此,本文移除哈希层的激活函数,添加正则项来约束神经网络的最终编码结果,并且实验表明该正则项对于防止网络过拟合有非常重要的作用。
考虑到如果失去了sigmoid和tanh对于网络哈希层输出值域的限制,可能会导致最终二值化后的哈希编码不符合预期的离散分布(+1/-1)。本文引入了正则项,保证网络编码后的向量的模小于1,如式(11)所示:
(11)

(12)
2.4.4 总损失函数
将上述各部分损失函数进行求和,可以得到本文需要优化的总损失函数,如式(13)所示:
Lsum=Ltri+Lce+λLre
(13)
其中,Lsum为总的损失函数,λ为正则项系数,负责权衡正则项对于哈希层输出向量的约束强度。
3 实验结果及分析
3.1 数据集
本文将提出的方法与近年来国内外的优秀方法在以下数据集上进行了比较:(1)CIFAR-10[10]。该数据集共有60 000幅大小为32×32的图像,共分为10类,每类6 000幅。本文遵循了该数据集的原始划分方案,使用前50 000幅图像用于网络训练,剩余的10 000幅图像用于测试本文方法的性能。(2)采集的电力公司日常部分图像数据。该数据集包括日常线路的电缆、电力设备、日常设备检修记录和故障设备的图像记录。该数据集具体描述如表1所示。
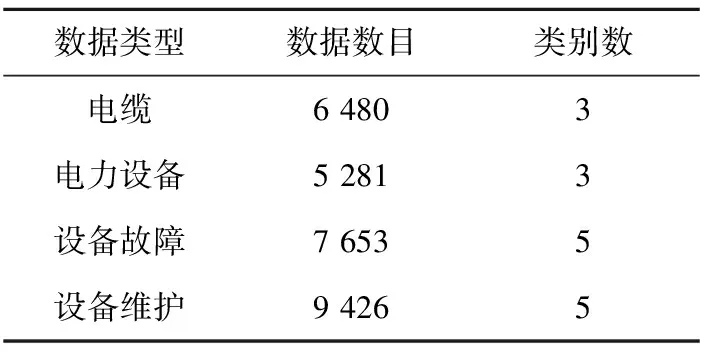
Table 1 Description of the dataset
3.2 实验环境与参数设置
所有的实验均在图形工作站上进行,工作站操作系统为Ubuntu 18.04 LTS、CPU为主频2.90 GHz的Intel(R)Xeon(R)W-2102处理器,显卡为NVIDIA TITAN XP GPU。基于TensorFlow[11]实现本文方法。采用mini-batch Adam优化器(基本学习率为0.001,beta1为0.9,beta2为0.999,epsilon为None,decay为0,batchsize为32)进行网络训练,并将网络训练的最大迭代次数设置为600。为了获得更好的方法性能,本文采用了如式(14)所示的可变学习率方案:
(14)
其中,t是网络迭代索引,初始学习率η(0)设置为0.001。为了与其他研究工作的评估标准保持一致,本文采用所有类别平均精确率mAP(mean Average Precision)、精确率-召回率曲线(32位哈希编码)和检索出的前N幅图像的精确率曲线作为本文方法的评估指标[12]。
3.3 各方法性能比较
不同位长的哈希编码下不同方法在2个数据集上的mAP结果如表2所示。
从表2可以看出,本文所提出的方法比其它方法更加优异,在32位哈希编码的情况下,分别在CIFAR10和电力图像数据集上mAP达到了81.3%和83.6%。这说明本文所提出的方法在提高哈希编码效率上有较大的作用,这可能是因为距圆损失的加入使模型训练更有目标性,且多任务学习的加入又进一步降低了模型过拟合的程度。然而,传统的哈希编码方法和优化目标较为单一的哈希编码方法(CNNH[5]和HashNet[13])在性能表现上普遍欠佳,多损失优化下的方法(DVSQ[14]和DTQ[8])的性能往往较好。此外,各方法在编码长度为32位时,性能最好。本文还绘制了32位哈希编码下不同方法在CIFAR10和电力图像数据集上的精确率-召回率曲线,如图5所示。从图5中可以看出,HashNet在不同数据集上的泛化能力较差,在CIFAR10数据集上表现尚可,在电力图像数据集上的表现仅优于传统方法ITQ-CCA。整体来讲,深度学习方法的性能普遍优于传统哈希编码方法的。
为了衡量不同方法的查准率,本文测试了不同方法在32位哈希编码下的查准率,并绘制了在该条件下的精确率曲线,如图6所示。可以看到本文所提出的方法在2个数据集上表现都较好,且在电力图像数据集上的检索性能要比在CIFAR10数据集上的检索性能好很多。
3.4 图像检索可视化
哈希编码的目标在于尽可能拉近相似度较高(同等类别)的样本对的编码距离,即使2幅图像的哈希编码尽可能相似。为此,本文从CIFAR10数据集中随机选择了32幅图像,并给出了每幅图像的所属类别和本文方法的长度为12位的哈希编码,汇总结果如图7所示。可以看出,相同类别图像的哈希编码倾向于保持一致或多位编码结果保持一致,符合本文对于哈希编码结果的预期。
此外,还给出了本文方法对指定类别的图像进行检索后排名前10的候选图像检索结果(以少数类别为例),如图8所示。可以看出,对于比较容易辨别的图像,如风力发电机,排名前10的图像全部命中,精确率100%。对于难度较大背景较复杂的小型水力发电机,精确率明显降低,只达到了80%。同样情况,变压器的检索精确率为90%。这可能是因为变压器的特点较小型发电机的要更为明显,且背景复杂的图像对于本文方法仍然具有一定的挑战性。
4 结束语
本文为解决电网系统中电力数据规模大,但检索精度低、检索速度慢等问题,提出了基于距圆损失的深度哈希编码方法用于提高电力图像检索效率,并通过引入多任务学习和正则项进一步降低网络训练过拟合程度,提高网络最终编码性能,进而提高电力图像检索效率。
从实验结果来看,本文所提出的方法有效地提高了图像检索领域哈希编码的准确性和有效性,但本文方法仍有以下不足:(1)网络的过拟合现象仍然存在。本文发现,哈希编码的性能主要取决于所提方法在测试集上的过拟合程度,不断降低过拟合程度是提高性能的最有效方法。本文所作的主要贡献之一即为引入了多任务学习及正则项进一步降低了网络的过拟合程度,进而提高了哈希编码的有效性。(2)对于哈希编码的量化损失较为单一。如何更有效地量化图像对之间的哈希编码并计算两者之间的损失可以给网络训练指出更加明确的训练方向,降低训练过程中的不确定性。
针对以上问题,未来需要进行的研究工作包括:(1)寻找更有效的防止过拟合的方法,以提高网络性能,如数据增强、生成对抗网络和正则化方法等;(2)寻找更全面的哈希编码量化损失,以更好地约束网络训练,提高编码性能。
