基于近红外光谱的酸枣仁不同伪品掺假检测
2022-10-27王韵彭赵志磊王献友王庭欣刘孟琛
赵 昕,刘 鑫,王韵彭,赵志磊,4, ,王献友, ,王庭欣,刘孟琛
(1.河北大学质量技术监督学院,河北保定 071002;2.计量仪器与系统国家地方联合工程研究中心,河北保定 071002;3.河北省能源计量与安全检测技术重点实验室,河北保定 071002;
4.河北大学地理标志研究院,河北保定 071002)
酸枣仁为鼠李科植物酸枣Mill.var(Bunge)Hu ex H.F.Chou 的干燥成熟种子。酸枣仁主要含有黄酮、皂苷、生物碱等物质,具有镇静催眠、抗焦虑、抗抑郁、降血糖、抗痴呆、增强免疫系统等药用功效。酸枣仁主要分布于我国东北、华北、西北以及南方等部分地区。其中河北邢台所产的邢枣仁量大质优,为全国闻名的道地药材。酸枣仁作为我国传统常用中药材,应用历史悠久,远销海内外。然而由于酸枣仁的形似易混淆品较多,不法商贩为牟取暴利掺入混伪品,使得市售酸枣仁价格与质量参差不齐,掺杂掺假现象严重。掺伪酸枣仁药材直接影响药用效果及消费者和药材厂商的经济利益,含毒或相悖药性伪品甚至危及生命健康,因此开展酸枣仁伪品的快速检测技术具有重要意义。
常用的中药材真伪检测技术有薄层色谱法、气相色谱法、液相色谱法等。以上方法虽然检测精度较高,但实验过程繁复,需要专业操作人员,仪器成本高,检测耗时长,不利于实际中的市场推广应用。近红外光谱技术基于被测物质中含氢基团的振动吸收光谱特征,具有无损、快速和环境友好的优点,便于在现代化高通量加工生产环境中实现在线监测。目前已广泛应用于粮油、果蔬、肉类和乳制品等多种农产品和食品的质量检测中。Li等基于近红外光谱结合偏最小二乘判别分析(partial least squares-discriminant analysis,PLS-DA)和偏最小二乘回归(partial least squares regression,PLSR)算法,成功地对两种外观相似的藏红花混伪品(莲花雄蕊和玉米柱头)进行了快速鉴别和定量分析。Chen等采用近红外光谱技术结合数据驱动(soft independent modeling of class analogy,SIMCA)类建模方法和基于浮雕的变量选择方法,实现了三七粉掺假(苦参粉和玉米粉)的非目标鉴别。以上研究表明近红外光谱技术可以用于中药材真伪鉴别和掺假检测。
目前,有关酸枣仁掺伪检测的研究较少。申晨曦等基于氢核磁共振与偏最小二乘法对酸枣仁及其掺伪品进行了鉴别。刘红玉和张悦综述了鉴别酸枣仁与伪品理枣仁的十种检测方法,包括性状鉴别、显微鉴别、理化鉴别、薄层色谱、紫外光谱、红外光谱、高效液相色谱(high performance liquid chromatography,HPLC)、高效毛细管电泳法、超高效液相色谱-飞行时间质谱法(high performance liquid chromatography-tandem quadrupole-time of flightmass spectrometry,UPLC-Q-TOF/MS)鉴别和 DNA指纹图谱鉴别。基于近红外光谱技术检测酸枣仁真伪的研究尚未见报道。综上所述,本文针对酸枣仁掺假质量问题,具体选取了其市场上常见的不同伪品理枣仁、枳椇子和兵豆,利用近红外光谱技术开发一种酸枣仁掺伪的快速检测方法,为后续便携式或在线检测仪器开发提供理论基础。
1 材料与方法
1.1 材料与仪器
酸枣仁及伪品理枣仁、枳椇子和兵豆 购买于河北安国中药材市场远光药业有限公司。
MPA型傅里叶变换近红外光谱仪 德国布鲁克公司。
1.2 实验方法
1.2.1 样品的制备 使用一号筛(10目)去除样品颗粒中的杂质以及不完整颗粒;分别制备掺入单种伪品的酸枣仁掺假样品,掺入的伪品质量分数为1%、10%、20%、30%、40%、50%、60%、70%、80%、90%。对掺假样品进行充分搅拌,使酸枣仁和伪品混合均匀。共制备酸枣仁掺假样品30种(3类伪品×10个掺假质量分数),以及酸枣仁和3类伪品纯样品4种。同时掺入理枣仁、枳椇子和兵豆制备含有多种掺杂物的酸枣仁样品,其质量分数配比见表1。

表1 包含多种掺假物的酸枣仁样品的配比Table 1 The proportioning of Ziziphi Spinosae Semen with multiple adulterants
1.2.2 光谱采集 实验采用MPA型傅里叶变换近红外光谱仪,使用积分球漫反射模式采集光谱数据。室温下,每次测量时取20 g样品放入样品杯中。设置光谱采集范围为 12500~4000 cm(800~2500 nm),光谱分辨率为16 cm,扫描次数为64次。每种类型样品采集20条光谱,共获得680条(20条光谱×34种掺假样品)光谱数据。
1.2.3 主成分分析 主成分分析(principal component analysis,PCA)是光谱分析中常用到的无监督数据降维算法。通过正交变换降维处理将具有线性相关性的多个光谱数据转换为一组数量较少的新变量,可以在不丢失重要光谱信息的情况下,分离具有特征差异的数据。为了对酸枣仁和三种伪品之间的差异性进行初步分析,对4种纯样品的光谱数据应用了PCA变换。
1.2.4 光谱预处理 为了消除基线漂移和噪声,提高模型预测性能,采用了归一化(normalize,NOR)、标准正态变量(standard normal variate,SNV)、移动平均平滑(moving average smoothing,MAS)、SG 平滑(Savitzky-Golay smoothing,SGS)和 SG 一阶导数(Savitzky-Golay first-order derivative,SGD1)五种预处理方法,并进行了对比分析。
1.2.5 偏最小二乘回归模型建立与评价 偏最小二乘回归方法(partial least squares regression,PLSR)是一种应用广泛的线性光谱数据定量分析建模方法,综合了主成分分析、典型相关分析和多元线性回归3种方法的优点,可以有效解决建模时变量间的多重相关性等问题。偏最小二乘回归中有两种建模方法,分别是PLS1和PLS2。PLS1方法单独校准开发每一个属性的预测模型,PLS2建立一个同时校准所有属性的模型。在本文中,PLS1和PLS2分别用于建立单掺杂样品和多掺杂样品的定量模型。
根据决定系数()、校正均方根误差(RMSEC)、交叉验证均方根误差(RMSECV)、预测均方根误差(RMSEP)和偏差(Bias)来评价所建模型的性能。数值越大且越趋于1,RMSE数值越小且趋于0,则模型效果越好。基于不同预处理后的数据,建立偏最小二乘回归模型。每种类型样品的20条光谱按照随机划分原则,14条光谱组成校正集,6条光谱组成预测集。
1.2.6 连续投影算法 连续投影算法(successive projection algorithm,SPA)是一种迭代正向选择方法,常用于多变量建模中的特征变量选择。它采用选择共线性最小变量的投影运算以从复杂的光谱数据中提取有效信息,可以大大减少建模所需变量数,提高建模效率。为了进一步优化预测模型,提高模型实用性和鲁棒性,本文采用SPA算法挑选建模最优波长变量。
1.3 数据处理
光谱采集由OPUS软件实现,光谱数据预处理及PLS建模在The Unscrambler X 9.7中进行,其余算法在Matlab R2013b中实现。图片采用Origin 2018绘制。
2 结果与分析
2.1 原始光谱分析
观察获得的原始吸收光谱曲线,发现800~1062 nm波长范围内谱线数据存在较大噪声,且整体吸光度值较低,无明显吸收峰,因此截取1063~2503 nm波长范围数据用于后续的处理与分析。酸枣仁及其掺假样品波长截取后的原始光谱如图1所示。从原始光谱曲线上无法直接对酸枣仁及伪品进行鉴别区分,需要借助化学计量学方法作进一步分析处理。

图1 原始光谱Fig.1 Original spectra
酸枣仁及伪品理枣仁、枳椇子和兵豆的平均吸收光谱及误差带如图2所示。由图可知,酸枣仁及3种伪品的原始吸收光谱曲线整体轮廓形状相似,吸光度值及其变化程度存在差异。酸枣仁及三种伪品在1063~2503 nm波长范围内均具有4个明显的吸收峰,其波段范围分别为1111~1265 nm、1370~1556 nm、1854~1984 nm 和 2022~2200 nm。在 1111~1265 nm范围内,理枣仁在1200 nm处有一个单独的波峰,可能与脂肪或油中长链脂肪酸部分的CH基团的第二泛音有关。酸枣仁、枳椇子和兵豆均在1210 nm处有一个吸收峰,且在1167 nm有一处小凸起,查阅相关文献Woodcock等在橄榄油样品的光谱分析中指出1211 nm和1168 nm 分别与CH和CH基团中C-H键伸缩振动的第二泛音有关。此外,同样地Tigabu和Odén在火炬松种子近红外光谱分析中指出1206 nm附近吸收峰与1170 nm附近的小凸起与CH,CH和CH=CH中C-H键的伸缩振动的第二泛音有关,附近波长1180 nm也反映了含有顺式双键纯脂肪酸(如油酸)中基本C-H键吸收的第二泛音。以上表明,1111~1265 nm内吸收峰与酸枣仁及伪品内的脂肪成分有关。在1370~1556 nm范围内,4种样品在1460 nm处表现出一个主要的吸收峰,文献表明该吸收峰与水有关。在1854~1984 nm范围内的1926 nm主要吸收峰与C=O键伸缩第二泛音,O-H伸缩和HOH变形的合频,以及O-H键弯曲振动第二泛音有关,主要反映蛋白质、水和淀粉的吸收特性。在2022~2200 nm范围内,主要吸收峰位于2132 nm处,与氨基酸中NH和C=O键的伸缩振动有关。以上表明,光谱数据中的主要吸收峰反映了样品中脂肪、水、蛋白质和淀粉等主要成分信息。然而目前谱线数据中存在基线漂移等噪声,难以直接从数值大小上对酸枣仁及伪品进行鉴别区分,需要对数据进行后续进一步处理。

图2 酸枣仁及三种伪品的平均光谱及误差带Fig.2 Average spectra and error bands of pure samples of Ziziphi Spinosae Semen and three kinds of counterfeits
2.2 PCA定性分析
为了初步判断酸枣仁与三种伪品基于近红外光谱数据的可分性,首先采用无监督分类方法PCA对酸枣仁及3种伪品纯样品的光谱数据进行鉴别分析。酸枣仁及3种伪品在前2个主成分中的散点图如图3所示。第一主成分(PC1)和第二主成分(PC2)的方差贡献率分别为84.6%和15.0%。酸枣仁、理枣仁、枳椇子和兵豆数据点置信椭圆间没有重叠区域,基于近红外光谱数据可以较好地实现酸枣仁与理枣仁、枳椇子和兵豆的鉴别区分。

图3 酸枣仁及三种伪品光谱数据在前2个主成分中的散点图Fig.3 PCA scatter plot of PC1 vs.PC2 of the spectral data of Ziziphi Spinosae Semen and three kinds of counterfeits
2.3 光谱预处理及PLS1全波长模型
采用5种预处理方法对波段截取后的光谱进行去噪处理,并建立相应的PLS1模型,结果如表2所示。表2方法中NON表示光谱数据未经预处理,用于不同预处理方法去噪效果的对比分析。三种掺假物不同预处理方法对应的PLS1模型的决定系数均在0.94以上,其中理枣仁掺假样品模型预测性能最佳,兵豆次之,枳椇子最差。然而从外形与纹理观察,理枣仁与酸枣仁最相似,枳椇子次之,兵豆差别最大。造成以上成因可能是由于相比于酸枣仁,枳椇子与兵豆的密度较大,混合样品制备时伪品分布较不均匀。理枣仁掺假样品中,SGD1对应模型的最大,且和相对较大,故选为最优预处理方法;枳椇子掺假样品中,SGS对应模型的数值最大,且和相对较大,故选其为最优预处理方法;兵豆掺假样品中,SNV对应模型的最大,且和相对较大,故选为最优预处理方法。三种掺假样品基于最优预处理方法的全波长PLS1模型的预测集结果如图4所示,理枣仁掺假样品对应模型的为0.9778,RMSEP为4.9891%,枳椇子掺假样品对应模型的为0.9585,RMSEP为6.8281%,兵豆掺假样品对应模型的为0.9722,RMSEP为5.8852%。图5所示为经过最佳预处理后酸枣仁与3种伪品纯样品的平均光谱曲线。
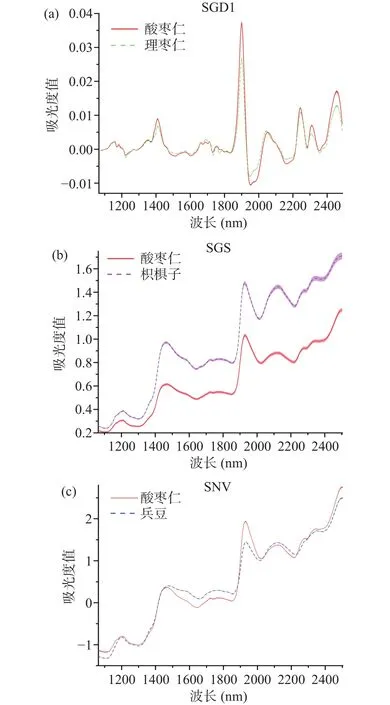
图5 最优预处理后的酸枣仁与3种伪品的平均光谱曲线Fig.5 Average spectral curves of Ziziphi Spinosae Semen and three kinds of counterfeits after the optimal pretreatments

表2 基于不同预处理方法的全光谱PLS1模型结果Table 2 PLS1 models based on full spectral data using different pretreatment methods

图4 基于最优预处理方法PLS1模型的预测集结果Fig.4 Prediction set results of the PLS1 models based on the optimal pretreatment methods
2.4 最优波长选择与PLS1多光谱模型
为了进一步优化预测模型,减少输入变量,降低模型复杂度,节省计算时间,提高模型综合性能。本文对最优预处理后的光谱数据应用SPA算法挑选最优建模波长。基于最优波长建立的多光谱PLS1模型的预测结果如表3所示。通过对比建立的多光谱模型的知,兵豆掺假样品所建模型的预测效果最好,理枣仁掺假样品次之,枳椇子掺假样品效果较差,且三种模型≥0.9491,RMSEP≤7.6232%,Bias的绝对值≤1.4168%。三个模型预测集结果如图6所示,模型均表现出了良好的预测能力。与全光谱模型相比,多光谱模型预测性能稍差,但输入波长变量个数大大降低。实际生活中,不法分子为了牟取较高利润,掺假含量一般较高。因此,所建模型具有较好的实际应用价值与意义。
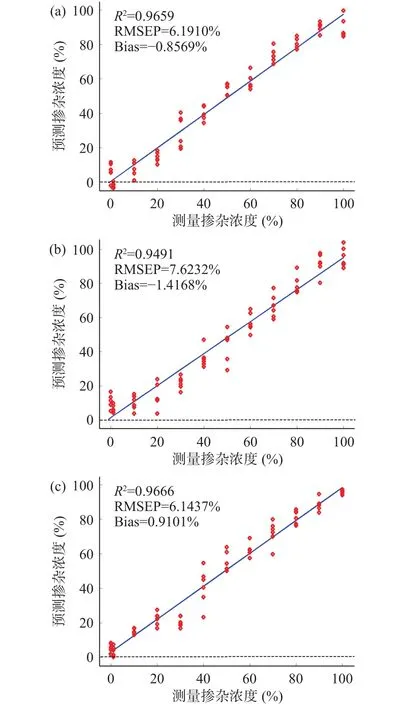
图6 基于最优波长多光谱模型的预测集结果Fig.6 Prediction set results of multispectral models based on the optimal wavelengths

表3 基于 SPA算法所选最优波长建立的多光谱模型的预测结果Table 3 The prediction result of the multispectral model based on the optimal wavelength selected by the SPA algorithm
对于理枣仁掺假样品,选取了1137、1857 nm和2054 nm 3个最优波长。对于枳椇子掺假样品,选取了 1067、1106、1145、1273、1330、1915、1961和2503 nm共8个最优波长。对于兵豆掺假样品,选取了5个最优波长,分别为1170、1198、1271、1345和1362 nm。理枣仁掺假样品最优波长的分布较分散,枳椇子和兵豆掺假样品的大部分最优波长分布在1200 nm吸收峰附近,结合2.1节分析内容,该吸收峰附近波长主要反映脂肪相关成分。研究表明,与酸枣仁相比,枳椇子和兵豆中的脂肪油成分含量较少(酸枣仁中脂肪油含量约为23.17%~29.25%,枳椇子中粗脂肪含量约为9.45%,兵豆脂肪含量约为1.1%)。理枣仁与酸枣仁具有相似的化学成分构成。由于酸枣仁与伪品中成分含量不同,导致所采集的光谱产生差异,根据此特点利用近红外光谱技术实现酸枣仁与其伪品的区分。
酸枣仁及其掺假样品多光谱模型的预测集决定系数≥0.9491,表明所建立的回归方程具有较好的拟合度。三种伪品掺假样品多光谱PLS1模型回归方程如下所示。
理枣仁掺假样品的回归方程如下:

2.5 多种掺杂物的PLS2全波长模型
表4为不同预处理方法下的PLS2全波长模型预测结果。对比不同预处理方法,SGD1预处理后模型对四种成分预测的交叉验证决定系数最大,故SGD1为最优预处理方法。对比SGD1对应的模型对不同成分的预测效果,酸枣仁掺假样品的为0.7840,RMSEP为5.7677%,理枣仁掺假样品的为0.7784,RMSEP为4.8009%,枳椇子掺假样品的为 0.2007,RMSEP为 4.3800%,兵豆掺假样品的为0.4503,RMSEP为3.7806%。酸枣仁的定量预测效果最好,理枣仁和兵豆次之,枳椇子的预测效果最差。其原因可能是多种掺假物建模样品中兵豆和枳椇子的含量相对较低,且枳椇子不同掺杂质量分数类型较少,导致建模样品代表性较差。
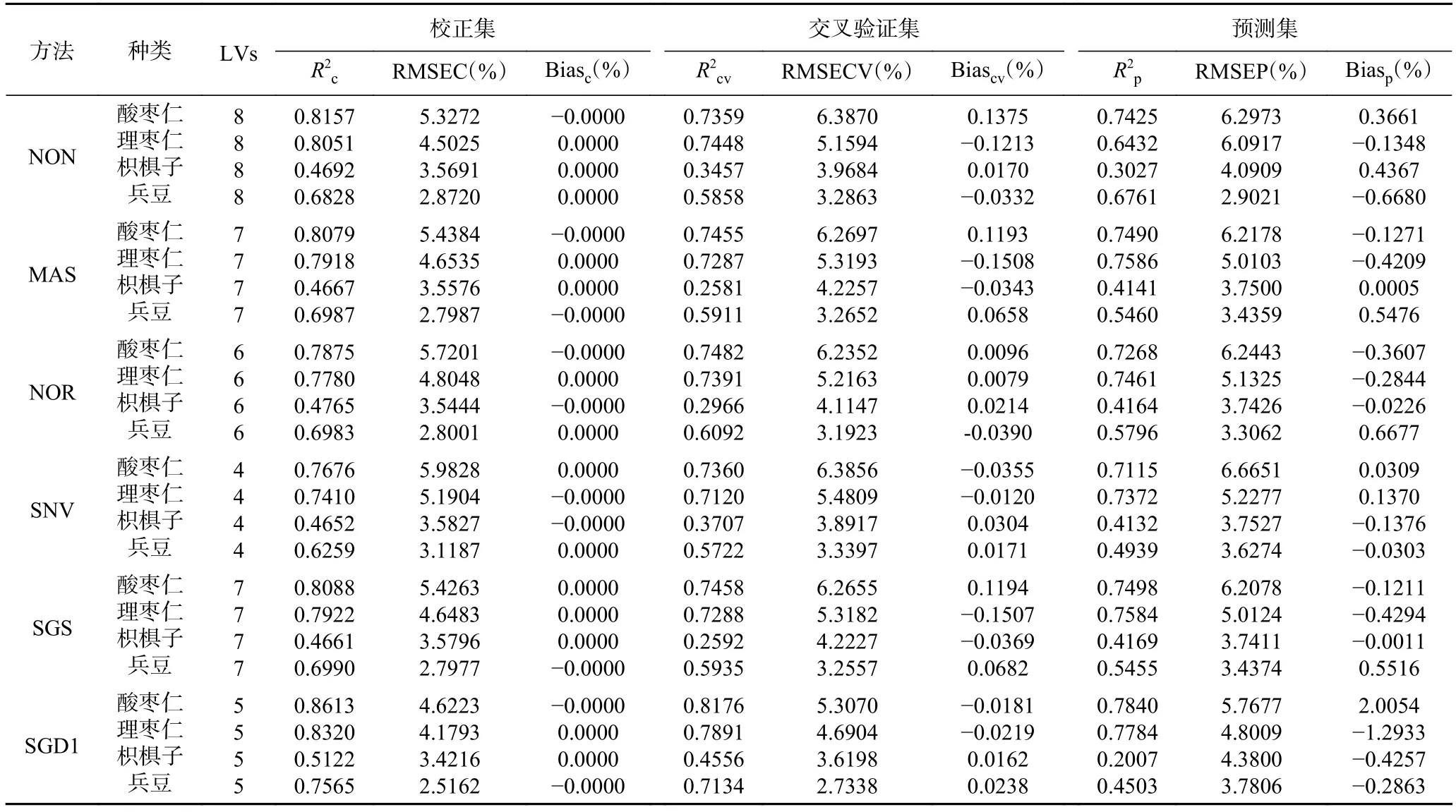
表4 不同预处理方法下多掺杂物样品的全光谱PLS2模型结果Table 4 Performance of the PLS2 models for multiple-adulterants samples using different pretreatment methods based on the full spectral range
3 结论
本文利用近红外光谱技术研究了酸枣仁中常见3种伪品理枣仁、枳椇子和兵豆掺假的定性定量检测方法。PCA定性分析表明酸枣仁、理枣仁、枳椇子和兵豆的近红外光谱表现出不同的吸收特征,数据具有良好的可分性。分别对3种伪品掺假样品建立了全波长PLS1模型进行定量分析,预测集的决定系数≥0.9480,RMSEP≤8.0225%,Bias的绝对值≤2.6690%。采用SPA算法挑选最优波长对模型进行优化。对于理枣仁掺假样品、枳椇子掺假样品和兵豆掺假样品分别优选了3个、8个和5个最优波长,分别建立了对应的多光谱PLS1模型。3类多光谱模型的预测集决定系数≥0.9491,RMSEP≤7.6232%,Bias的绝对值≤1.4168%。多光谱模型大大降低了建模输入变量个数,有利于缩短计算时间,降低仪器开发成本。PLS1模型均表现出良好的预测性能,具有实际检测应用价值与意义。对于多掺杂物样品的PLS2模型,酸枣仁的预测效果最好,≥0.7115,枳椇子预测效果最差,≥0.2007。在未来的研究中,多种掺杂物的定量检测模型有待进一步优化。综上,本文所研究方法为后续酸枣仁质量在线或便携式检测仪器开发提供理论基础,也为种子类中药材质量的光学无损快检方法研究提供参考依据。
