利用维基百科点击流的概念依赖关系识别方法
2022-10-15胡成,陈昊,肖奎
胡 成,陈 昊,肖 奎
(湖北大学 计算机与信息工程学院,武汉 430062)
E-mail:xiaokui@hubu.edu.cn
1 引 言
伴随着互联网上学习平台的增加,网络学习逐渐成为一种学习常态.在MOOC课程体系中,不同章节或不同视频的概念间往往存在着依赖关系,这种概念依赖关系可指导学习者的学习顺序.对于两个概念(A,B),如果学习者在学习概念B之前必须先理解概念A的含义,那么我们就说概念B依赖于概念A.本文将以维基百科为例研究概念间的依赖关系挖掘问题.
维基百科作为世界上最知名互联网百科全书之一,几乎囊括了学习者需要的所有概念知识.维基百科概念是指词条的标题,一个维基百科概念就代表着一个词条.如果一个概念B依赖于概念A,那么就意味着理解B的词条内容,需要同时阅读一下A的词条内容,因为A中包含了一些理解B的词条内容所需的背景知识.当学习者浏览概念B的词条后,紧接着浏览概念A的词条,像这样的行为我们称之为“点击流”,维基百科官方公布最近30个月用户的点击流数据(1)https://dumps.wikimedia.org/other/clickstream/,而维基百科概念之间的依赖关系往往蕴含在这些点击流数据中.通过识别维基百科概念间的依赖关系,可以生成词条的学习顺序列表,解决学习者因为缺乏背景知识而无法理解词条内容的问题.
当前主流的一些维基百科概念依赖关系挖掘方法,都是利用维基百科词条间的链接关系、分类层次、文本内容等词条自身的特征进行概念依赖关系预测[11-13].相比于前文的研究,本文的贡献主要有以下两方面:
1)提出一种基于维基百科点击流数据的概念依赖关系挖掘方法,利用维基百科中的用户点击流数据建立特征,预测两个概念间是否存在依赖关系.
2)通过引入相关概念集合不仅提升了概念对的覆盖率,而且保持了较好的概念依赖关系预测准确率.
2 相关研究
最早进行维基百科概念依赖关系挖掘研究的是Talukdar和Cohen[11],作者认为如果概念B的词条中如果包含了一个链接指向概念A,那么概念B很有可能依赖于概念A.文章利用它们两个概念间的链接信息、编辑信息、内容信息设计特征,然后使用MaxEnt分类器预测概念间的依赖关系,但其平均准确率只有60%左右.
Liang等人[12,15,16]提出一种基于概念引用距离(RefD)的方法预测两个维基百科概念间的依赖关系.Zhou等人[13,17,20]建立了四组维基百科概念对的特征,包括基于链接、基于分类、基于文本内容以及基于时间关系的特征,作者随后采用六种不同的机器学习分类器进行实验,实验结果表明随机森林分类器可以在中文和英文数据集上表现出较好的效果.
上述方法都是基于维基百科概念本身的特征进行概念依赖关系预测.Sayyadiharikandeh等人[14]提出了基于维基百科点击流(Wikipedia clickstream)数据来推断概念间依赖关系的方法.这是研究人员首次利用用户交互行为预测概念对间的依赖关系.但是,此方法的主要问题在于,用户日志所覆盖的维基百科概念对的比例过于偏低,我们无法利用它来预测大多数维基百科概念对间的依赖关系.他们的研究工作与本文比较相近,所以本文将选择他们的研究作为我们的一个baseline方法.
此外,还有一些研究工作也与本文研究相关.Liang等人[15,16]在维基百科概念依赖关系预测任务中引入了Active learning方法,从而可以用更少量的训练集样本来获得同等的预测准确率.Zhou等人[17]也尝试了利用bagging+boosting的改进式集成学习方法进行维基百科概念依赖关系的预测.Alzetta等人[18]研究了如何帮助标注人员建立更准确的概念依赖关系数据集的问题.Chen等人[19]研究了如何利用概念依赖关系对教学平台上学生的知识状态信息进行补齐,从而实现对学生的知识状态的追踪(knowledge tracing).Wang等人[22]基于改进型协同过滤设计出网络学习资源的个性化推荐算法.Wang等人[21]利用课程属性与维基百科属性设计特征,识别课程概念间的依赖关系,这需要一对概念对中的两个概念必须同时出现在一门课程的课程简介中,本文方法则并无此要求,凡是维基百科中的概念,均可利用点击流数据实现概念依赖关系的识别.本文从概念层面出发,针对Sayyadiharikandeh等人[14]设计特征值存在的问题,提出利用相关概念集合方法预测概念间的依赖关系.
3 概念依赖关系识别任务的定义
为了方便起见,本文规定对于任意一组概念对(A,B),其中的两个概念都必须来自同一个领域.本文中的领域是指一个维基百科分类.一个维基百科分类通常包含了一些词条和一些子分类,而每个子分类也是由词条和下级子分类构成.换言之,在维基百科知识体系中,领域名称对应的结点是概念A与概念B的共同祖先结点.维基百科知识体系的示例如图1所示.
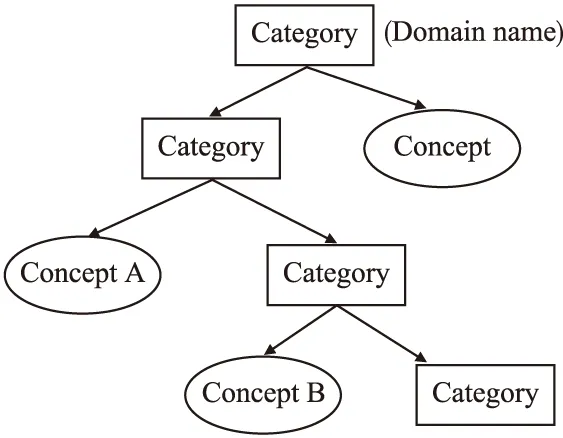
图1 维基百科知识体系示例Fig.1 Wikipedia knowledge system example
对于两个概念(A,B),它们之间的关系可能存在多种情况,比如B依赖于A、A依赖于B、A与B相关但两者没有依赖关系、A与B不相关、A与B关系不清楚[11].本文采用与以研究人员相同的方法,二分类方式来处理这个问题,即只区分B依赖于A、B不依赖于A两种情况[11-14].
4 概念依赖关系识别方法
在维基百科点击流日志数据中,不可能每一对概念都有点击流数据,即从A跳转到B(用户浏览A的词条后立即浏览B的词条,为了方便以下统称为从A跳转到B),或从B跳转到A的情况.因为大多数维基百科词条不是热点话题,不容易被注意,在过去30个月中并没有任何用户浏览过它们.如果只考虑A与B之间的跳转次数,那么点击流日志数据能够覆盖的概念对的比例会比较低.
本文将利用每个维基百科概念的“相关概念集合”,来扩大点击流数据的概念对的覆盖率.首先,我们将本节使用到的一些基本术语定义如表1.

表1 基本术语定义Table 1 Definition of basic terms
在框架语义理论中[12],一个概念可以由它的“相关概念集合”来表示,A的“相关概念集合”与B的“相关概念集合”的关系,即A与B的关系.对于一对概念(A,B),如果只考虑A与B之间直接的点击流数据("A-B"),那么这样的点击流数据能够覆盖的概念对数量往往偏少.因此,为了扩大点击流数据的概念对覆盖率,本文除了考虑两个概念间直接的跳转次数("A-B")以外,也考虑了A的相关概念与B的跳转次数("RA-B")、A与B的相关概念的跳转次数("A-RB")、A的相关概念与B的相关概念的跳转次数("RA-RB"),这样将会扩大考察的概念的范围,显著提升概念对的覆盖率.
根据上述4种不同类别的点击流数据,本文为维基百科概念对设计了4类特征,用于概念依赖关系的识别.本文使用了维基百科网站发布的最近30个月的用户点击流数据来建立概念对的特征.
4.1 "A-B"点击流数据的特征
基于"A-B"点击流数据的概念对的特征主要反应了概念A与B的直接依赖关系.本文根据"A-B"点击流数据建立了6个概念对的特征,这些特征来自Sayyadiharikandeh等人的研究工作[14].具体的内容如下:
•Weight1(A,B):用户从概念A跳转到B的词条次数,即用户浏览了概念A的词条以后立即浏览概念B的词条的次数.
•Weight1(B,A):用户从概念B的词条跳转到A的词条的次数.
•Sum1(A,B):Weight1(A,B)与Weight1(B,A)之和.
Sum1(A,B)=Weight1(A,B)+Weight1(B,A)
(1)
•Diff1(A,B):Weight1(A,B)与Weight1(B,A)之差的绝对值.
Diff1(A,B)=|Weight1(A,B)-Weight1(B,A)|
(2)
•Norm1(A):对Weight1(A,B)进行规范化处理.
(3)
其中,Sat1(i)为用户从概念i跳转到其它所有概念的次数之和.
(4)
•Norm1(B):对Weight1(B,A)进行规范化处理.
(5)
4.2 "RA-B"点击流数据的特征
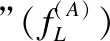
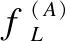
(6)
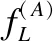
(7)
•Sum2(A,B):Weight2(A,B)与Weight2(B,A)之和.
Sum2(A,B)=Weight2(A,B)+Weight2(B,A)
(8)
•Diff2(A,B):Weight2(A,B)与Weight2(B,A)之差的绝对值.
Diff2(A,B)=|Weight2(A,B)-Weight2(B,A)|
(9)
(10)
(11)
4.3 "A-RB"点击流数据的特征
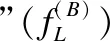
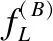
(12)
(13)
•Sum3(A,B):Weight3(A,B)与Weight3(B,A)之和.
Sum3(A,B)=Weight3(A,B)+Weight3(B,A)
(14)
•Diff3(A,B):Weight3(A,B)与Weight3(B,A)之差的绝对值.
Diff3(A,B)=|Weight3(A,B)-Weight3(B,A)|
(15)
(16)
(17)
4.4 "RA-RB"点击流数据的特征
(18)
Weight1(r1,r2)>0
(19)
•Sum4(A,B):Weight4(A,B)与Weight4(B,A)之和.
Sum4(A,B)=Weight4(A,B)+Weight4(B,A)
(20)
•Diff4(A,B):Weight4(A,B)与Weight4(B,A)之差的绝对值.
Diff4(A,B)=|Weight4(A,B)-Weight4(B,A)|
(21)
•Norm4(A):对从A的相关概念跳转到B的相关概念的次数之和进行规范化处理.
(22)
•Norm4(B):对从B的相关概念跳转到A的相关概念的次数之和进行规范化处理.
(23)
如前所述,“相关概念集合”代表了概念本身,所以总体而言,上述4个特征分别直接和间接的表示了从A跳转到B的次数,其中第一个特征Weight1(A,B)描述了A与B的直接跳转关系,其它3个特征——Weight2(A,B)、Weight3(A,B)与Weight4(A,B)描述了A与B的间接跳转关系.
另一方面,由于f1(·,·)这样描述直接关系的特征只能覆盖少数概念对.也就是说,维基百科中有相当一部分概念对,因为用户没有浏览这些词条,使得描述它们直接关系的f1(·,·)特征值并不存在,而类似f2(·,·)、f3(·,·)与f4(·,·)这样描述它们间接关系的特征值却存在.本文将利用24对特征进行维基百科概念依赖关系的预测.
5 实 验
5.1 数据集
本文使用了Liang等人建立的AL-CPL数据集[15]对提出方法的有效性进行验证.其中包含了Data-mining、Geometry、Physic与Pre-calculus共4个领域的6529对维基百科概念.
针对上述数据集,本文首先从维基百科网站获取了从2017年11月到2020年4月的点击流数据,分别计算在每个领域中,维基百科概念对覆盖的比例,也就是概念对覆盖率,具体结果如图2所示,横坐标表示领域名称,纵坐标表示覆盖率.
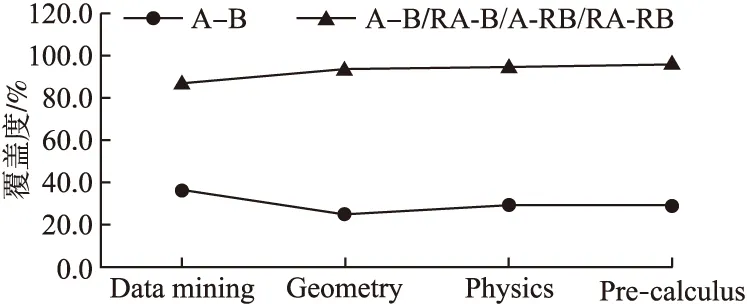
图2 AL-CPL数据的概念对覆盖度Fig.2 Concept of AL-CPL data coverage
从图2中可以看出,在引入相关概念集合以后,点击流数据的概念对覆盖率都达到90%以上,相比直接的概念对覆盖率有了大幅的提升.
5.2 方法评估
本文使用Precision(P)、Recall(R)、F1-Score(F1)和Area Under Curve(AUC)4个度量指标对提出方法的性能进行度量,实验过程采用五折交叉验证方式进行评估.本文使用7种常见的机器学习分类器进行概念依赖关系预测,这些分类器包括随机森林(RF)、朴素贝叶斯(NB)、C4.5决策树(C4.5)、多层感知器(MLP)、支持向量机(SVM)、逻辑回归(LR)和AdaBoost(Ada).所有分类器均采用sklearn库实现,各分类器使用的参数均为默认参数.本文使用过采样方法让训练样本中的类别平衡,表2显示了使用过采样方法后,训练集样本中的正例与反例数量.
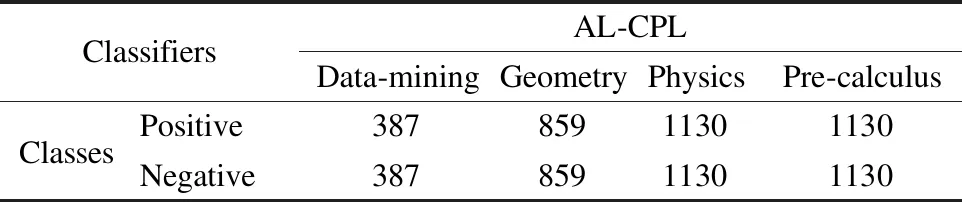
表2 训练集样本中的正例与反例的数量Table 2 Number of positive and negative examples in the training data
表3显示了提出方法在AL-CPL数据集上的评估结果.
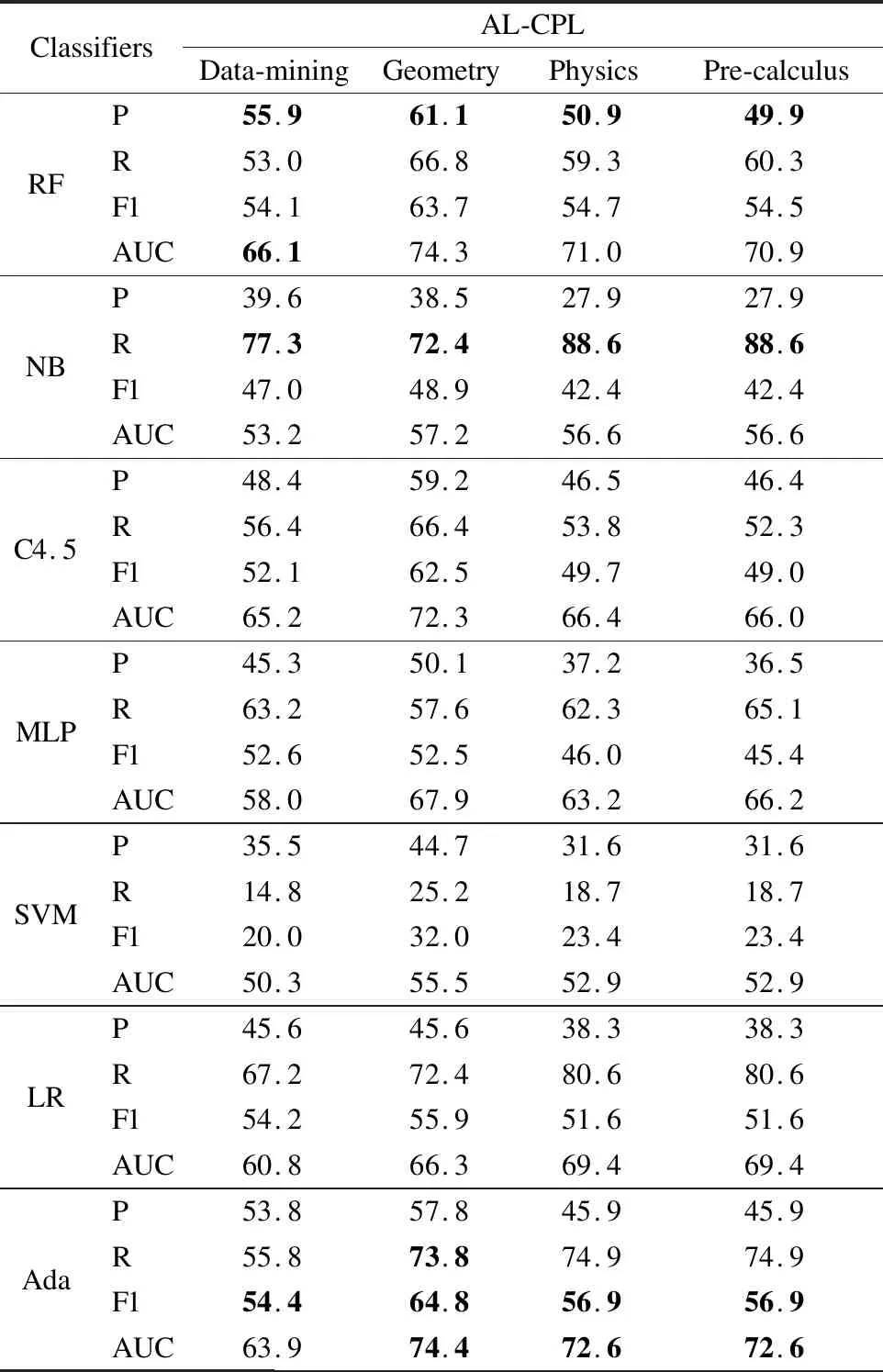
表3 方法评估结果Table 3 Method evaluation results
从表3中可以看出,AdaBoost在Geometry、Physics、Pre-calculus数据集上的F1值和AUC值均比其他分类器高,在Data-mining数据集上的F1和在Geometry数据集上的R值均比其他分类器高.同样随机森林在Data-mining、Geometry、Physics、Pre-calculus数据集上的P值和在Data-mining数据集上的AUC值表现比其他分类器好;朴素贝叶斯在Data-mining、Physics、Pre-calculus数据集上的R值表现比其他分类器好.总体而言,AdaBoost在概念依赖关系预测任务中表现最好.我们将采用AdaBoost分类器进行后续的实验.
5.3 与baseline方法的比较
本文选择了两个baseline方法进行比较.第1个是Liang等人[12]提出的计算概念引用距离(RefD)识别概念依赖关系的方法,作者在其中运用了两种方式定义维基百科概念的每个相关概念的权值,分别是Equal(所有相关概念权值均设置为1)和Tf-idf(所有相关概念权值设置为它们的Tf-idf值),实验将分别与这两种模式(RefD-Equal与RefD-Tfidf)进行比较.第2个是Sayyadiharikandeh等人[14]提出基于维基百科点击流数据来识别概念依赖关系的方法.我们将按照原文的思想计算概念依赖关系预测的结果.
图3显示了本文方法与baseline方法在概念依赖关系预测准确率(Accuracy)方面的比较结果.从表中可以看出,本文方法在3个数据集上的准确率都高于3个baseline方法.在Pre-calculus数据集上,本文方法的概念依赖关系预测准确率略低于RefD-Tfidf方法,但是仍然高于其它baseline方法.我们猜想可能是在Pre-calculus数据集中的概念对来自微积分教科书,因此不同概念对的概念之间相较其他数据集存在更多的联系,导致本文方法在判断概念依赖关系时预测,将那些有依赖关系的概念对,但是由于点击次数偏少,特征值偏低,误判为没有依赖关系.实验结果表明本文提出的方法在维基百科概念依赖关系预测任务中具有较好的性能.
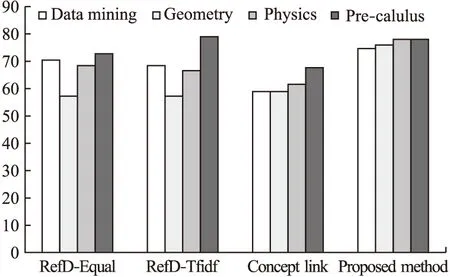
图3 与baseline方法的比较Fig.3 Comparison with baseline method
5.4 跨领域分析
一般情况下,机器学习实验的训练集和测试集数据会来自同一个领域(in-domain training).但是这也意味着我们需要为每个感兴趣的领域都准备好相应的训练集数据,很多时候这个前提条件是无法实现的.如果我们可以用来自不同领域的训练集与测试集数据进行实验(out-of-domain training),也能达到近似的分类效果,那么这将有助于改进我们的分类器,或者可以采用一些可替代的方法训练数据.
按照这个思路,我们对 AL-CPL数据集进行in-domain和out-of-domain实验.每次选择一个领域的数据集作为测试集,其它领域的数据集作为训练集.图4显示了AL-CPL数据集的实验结果.从图中可以看出,AL-CPL数据集的4个领域的in-domain分类准确率都要高于out-of-domain,而out-of-domain训练的分类准确率也均在60%以上,与in-domain分类准确率比较接近.
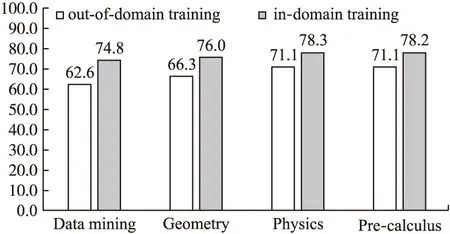
图4 AL-CPL数据集跨领域分析Fig.4 Cross-domain analysis of AL-CPL data
6 总 结
本文利用维基百科点击流数据以及每个概念的相关概念集合建立概念对特征,预测两个概念间的依赖关系.实验表明,通过引入相关概念集合,可以显著扩大点击流数据的概念对覆盖率,同时保持较高的概念依赖关系预测的准确率.
概念依赖关系挖掘是概念图抽取、学习对象排序、学习路径规划以及阅读顺序列表生成等任务的重要基础.当前的研究仅限于维基百科中概念依赖关系的挖掘,后续我们将考虑如何从文本、视频等学习对象中直接抽取概念,预测不同学习对象间的概念依赖关系,并将这种概念依赖关系用于智能辅导等智慧教育的服务中.
