基于深度残差网络的迭代量化哈希图像检索方法
2022-09-25廖列法李志明张赛赛
廖列法,李志明,张赛赛
(江西理工大学信息工程学院,江西赣州 341000)
0 引言
近年来,随着互联网的兴起,信息大量过载,图像、文字、视频等数据大量涌现。如何在庞大的图像库中方便、快速、准确地查询和检索用户所需的图像,成为图像检索领域的研究热点,图像检索技术可以应对大数据时代不断增长的图像数据要求。经过几十年的发展,基于内容的图像检索技术已经广泛应用于人脸检索[1]、商品图像检索[2]、服装检索[3]、医学图像检索[4]等生活领域。
大规模图像检索问题存在纬度高、数据量大、计算耗时等问题。为了实现高效检索,提出了一种近似最近邻(Approximate Nearest Neighbor,ANN)算法[5],根据特征向量的相似性,从图像数据集中找到与目标最近的图像。哈希算法被广泛应用于图像检索[6]等相关领域,将图像的高维特征映射为压缩的二值哈希码。由于汉明距离[7]的计算效率和存储空间的优势,可以解决大规模图像检索中存储空间和计算复杂度等问题。
由于哈希算法需要对数据进行特征提取,再将特征向量映射为哈希码,而深度学习[8]具有强大的特征学习能力,因此哈希算法逐渐开始利用深度学习进行特征提取,于是衍生出一种新的方法——深度哈希学习[9]。深度哈希学习融合了哈希算法与深度学习技术,本质是同时学习深度语义特征和哈希码,通过利用深度学习的方法,不断减小损失来训练神经网络,对输入数据提取出高维特征,然后生成为紧凑的二进制哈希码。深度哈希方法的性能优于传统哈希方法[10]。卷积神经网络哈 希(Convolutional Neural Network Hashing,CNNH)[11]首个将卷积神经网络运用到哈希算法中,但无法同时进行特征学习和哈希码学习;深度神经网络哈希(Deep Neural Network Hashing,DNNH)[12]是基于深度神经网络同时学习特征模块和哈希编码模块,但特征学习的准确性不够高;双线性卷积神经网络架构[13]使用集成网络模型来获得高维语义信息,学习了深度语义信息。为了解决特征学习不可避免地提高计算机的存储容量,提出了深度残差网络哈希图像检索架构[14],以降低计算机的存储容量,提高检索效率。
在深度哈希算法的研究中,有效的语义信息提取非常重要。DeepBit[15]是哈希技术中的一种经典方法,通过在哈希层添加损失函数训练深度哈希模型,以学习紧凑的二进制哈希码。在此基础上,还提出了具有量化误差约束的无监督方法[16],增加重构损失以确保语义相似性。基于端到端的无监督哈希算法[17]通过使用典型关联分析-迭代量化(Canonical Correlation Analysis Iterative Quantization,CCA ITQ)方法生成伪标记,将无监督算法转变为监督算法。最小化量化误差是学习哈希的另一个重要挑战,迭代量化(Iterative Quantization,ITQ)[18]通过找到最佳旋转矩阵将量化误差最小化,离散监督哈希(Discrete Supervised Hashing,SDH)[19]优化了二进制哈希码,减小了量化误差,深度监督哈希(Deep Supervised Hashing,DSH)[20]通过施加一个正则化器来控制量化误差,双线性迭代量化(Bilinear Iterative Quantization,BITQ)[21]使用紧凑的双线性投影将高维数据映射到两个较小的投影矩阵中,分布式快速监督离散哈希(Distributed Fast Supervised Discrete Hashing,DFSDH)[22]引入分布式框架共享集中式哈希学习模型,改进深度哈希网络(Improved Deep Hashing Network,IDHN)[23]引入了归一化语义标签计算的成对量化相似度。
目前,哈希算法仍然存在以下问题:1)基于传统的哈希算法研究主要基于手工标记,制约了检索的准确性;2)虽然当前的深度哈希算法能够获得更好的表示图像特征向量,但算法的训练时间急剧增加;3)目前大多数哈希方法难以适应大规模的图像检索要求。
基于上述考虑,为了提高图像检索的检索准确性和学习更优的哈希码,提出了基于深度残差网络的迭代量化哈希图像检索方法(Deep Residual Network and Iterative Quantization Hashing,DRITQH)。首先,使用深度残差网络提取图像数据特征,获得具有语义特征的高维特征向量;然后,使用主成分分析(Principal Component Analysis,PCA)对高维图像特征进行降维,运用迭代量化对生成的特征向量进行二值化处理,更新旋转矩阵,将数据映射到零中心二进制超立方体进行最小量化误差,得到最佳的投影矩阵;最后,进行哈希学习,得到最优的二进制哈希码。DRITQH 使用深度残差网络,无需传统手工标注,提升了训练速度,缩短了训练时间,优化了训练过程,解决了图像表达能力较弱、大规模图像检索效率较低、难以适应大规模图像检索的要求等问题。
因此,本文的主要内容有以下3 点:
1)使用残差网络学习图像特征,通过跳跃连接直接将输入信息连接到后面的层,保证信息的完整性,加快训练的速度,提高检索精度。
2)使用迭代量化算法通过逼近真实数据与哈希码之间最小的误差,得到更好的投影矩阵,从而学习最优的二进制哈希码,检索效率高。
3)在CIFAR-10、NUS-WIDE 和ImageNet 三个基准数据集进行了实验,实验结果表明DRITQH 方法的准确性和有效性均较高,能更好地适应大规模图像检索的要求。
1 基于深度残差网络的迭代量化哈希图像检索模型的构建
1.1 深度残差网络
从深度卷积神经网络架构开始,受到了He 等[24]提出的用于图像分类的残差网络(Residual Network,ResNet)架构的启发,该网络结构由卷积层、残差层、全连接层和迭代量化哈希层组成,用于生成哈希码。残差网络可以训练更深入的网络架构,包括用跳跃连接来替换直接堆叠的层,直接将输入信息跳跃连接到后面的层,保证了信息的完整性。图1 显示了该体系结构的基本构件,可以假设F(x) +x的等式具有跳跃连接[25]的前馈神经网络,可以跳跃多个图层,执行恒等映射。恒等映射方式连接既不添加额外的参数,也不增加计算复杂性,从而更好地实现卷积神经网络整体架构的性能。即使是在极深的网络中,整个网络仍然可以通过随机梯度下降进行端到端的反向传播训练,恒等映射方式能有效缓解了梯度消失和梯度爆炸问题,并优化了训练过程。
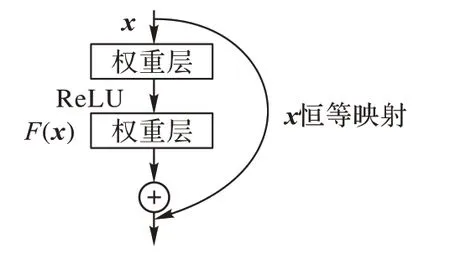
图1 残差网络基本构件Fig.1 Basic component of residual network
1.2 残差网络训练过程
深度残差网络可以有效地提高神经网络的训练速度,描述符逐层发送,保证了输出特征向量的表达能力,使用批归一化和全局池化可以得到更好的泛化网络。通过在输入和输出之间残差学习,保护信息的完整性,并简化了学习目标。如图2 所示,ResNet-50 的网络模型主要由16 个残差块组成,每个残差块包含3 个卷积层。首先是独立的卷积层,然后是池化层,最后是不同的卷积残差块,每个卷积残差块包括多个卷积层与交叉层连接。
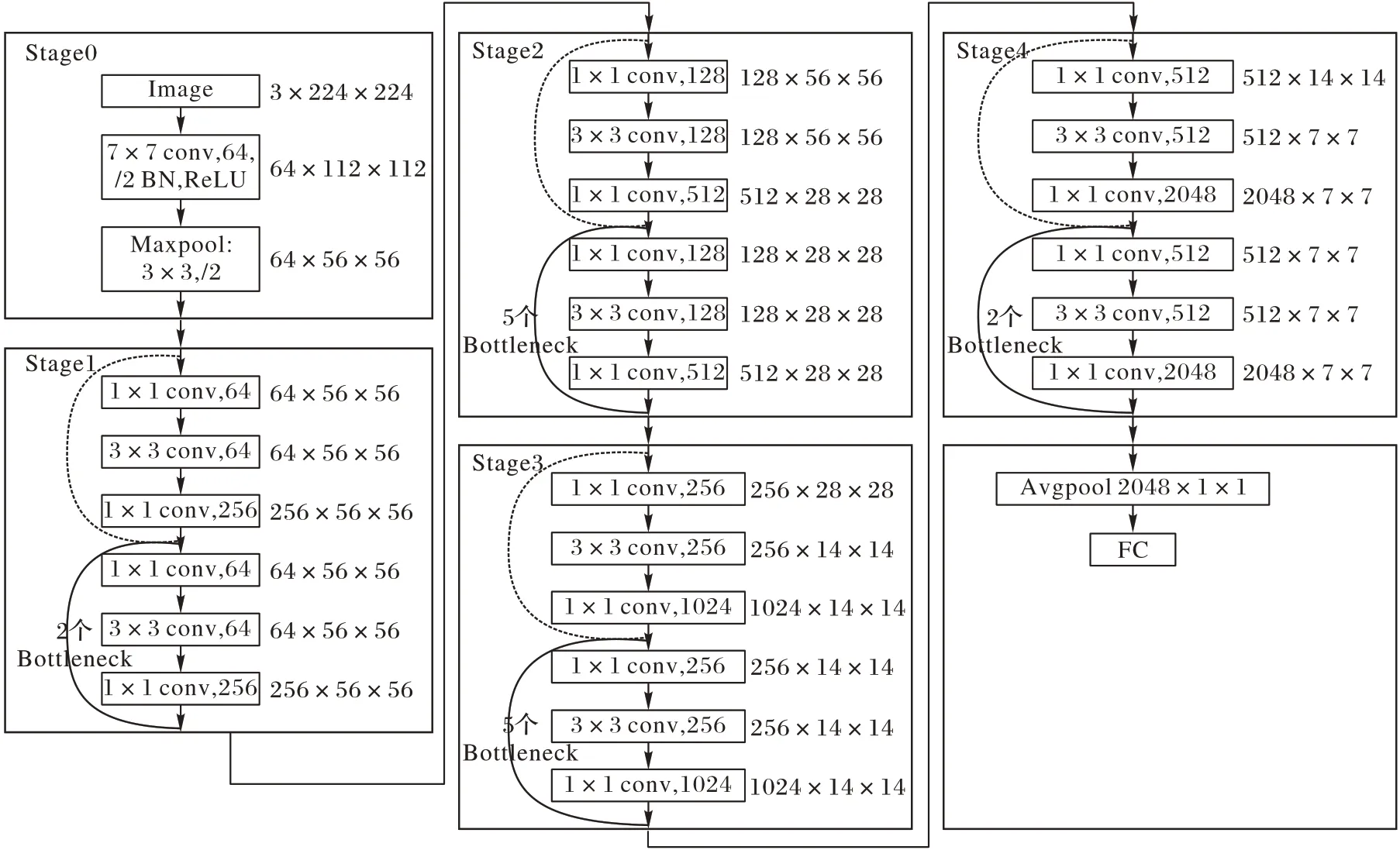
图2 ResNet-50的网络架构Fig.2 Network architectures for ResNet-50
为了简化训练的过程,本文的工作过程如下。首先,使用了迁移学习技术,在大型ImageNet 数据集上保留预先训练的ResNet-50 并执行微调阶段。然后进行微调阶段,主要集中在数据的特征提取,训练网络来表征数据并生成与检索任务相关的特征向量。训练最后一个残差块来微调网络,利用微调网络来提取深度映射。全局平均池层的输出被认为是每个输入的相关判别特征,从数据集的每个图像中提取特征向量,每张图像都用一个特征向量表示。
1.3 迭代量化算法
ITQ 通过寻找最优的正交矩阵Q,对这些样本进行量化,将汉明距离较小的样本量化为不同的二值哈希码。通过将样本与随机正交矩阵相乘,可以发现样本被旋转以找到最合适的正交矩阵,以一个小的汉明距离得到近似的哈希码。为了使量化误差损失最小,就是使真实样本数据与哈希码之间的误差最小。
首先输入特征向量,为了找到具有最大方差且成对不相关的哈希码,输入数据X∈Rn×d,其中n是特征向量的个数,d是特征向量的长度。在构建目标函数之前,首先减少特征的维度,提取主信息并减少训练时间。采用PCA 对提取的特征Kn进行降维处理,设降维特征向量矩阵X∈Rn×d在维度之后被降低为KnX,使用PCA 的数据嵌入进行投影。PCA 算法适用于数据点上,以最小化投影数据的量化误差,提出了在多维数据集上学习到更优的二进制哈希码的方法。如果W∈Rd×q为PCA 的系数矩阵,则

整个编码过程是:

如果W是最优解,那么WQ也是最优解,其中Q是q×q的正交矩阵,因此投影数据XQ也转换为正交矩阵。对投影矩阵进行ITQ 正交变换,以减小量化误差。

假设v∈Xq是投影空间中的一个向量,sign(v)是超立方体{-1,1}q的一个顶点,对该顶点进行二值化处理,q在汉明距离上接近v,量化损失是v与实际投影到二进制超立方体{-1,1}q之间的差异。
当量化损失‖sign(v) -v‖2的数值越小,意味着二值化代码矢量与以前越相似,所产生的二进制代码就更好,因此ITQ 旨在最大限度地减小以下量化损失,需要寻找正交旋转矩阵,使得投影点最接近其二进制量化。

在这个迭代过程中,首先从式(3)中寻找给定的随机初始化矩阵Q的最优Y。一旦更新Y,就会更新Q正交矩阵,使得式(4)最小化。最小化目标函数属于正交普鲁克问题,可以试图找到一个最佳的旋转来对其两组点。固定Y,对Q进行更新,旋转一个矩阵来对齐矩阵Y和XWQ。通过奇异值分解(Singular Value Decomposition,SVD)找到解决方案,得到YTXW=UΣVT,然后直接将Q更新为VUT,重复以上步骤可以找到最终的二进制代码Y。
2 DRITQH图像检索过程
基于深度残差网络的迭代量化哈希图像检索方法从深度卷积神经网络结构开始,采用ResNet-50 模型,如图3 所示,由卷积层、残差块、全连接层用于特征提取,PCA 和ITQ用于生成哈希码。这种设计选择的主要是由于深度残差网络具有跳跃连接,从某一网络层获得激活信号,可以迅速反馈给另外一层或者好几层,从而将信号传递到神经网络的更深层。深层的残差网络比普通卷积网络更容易优化,图像的表示能力随着网络的深度不断提高。在原有的ResNet-50 中引入了一种新的ITQ 的全连接哈希层来代替Softmax 分类层。全连接哈希层将从ResNet-50 提取的高维特征转换为低维二进制编码。为了实现哈希编码,引入了一个双曲正切tanh(x)激活函数,它将哈希层的输出限制为[-1,1]。本文使用ResNet-50 提取图像的特征向量,使用PCA 对特征向量进行降维,然后使用迭代量化来最小化投影样本和二值化样本之间的量化损失。

图3 DRITQH的网络结构Fig.3 Network structure for DRITQH
DRITQH 的检索过程如图4 所示,主要由3 部分组成:首先,使用深度残差网络的深层结构对图像数据进行特征提取,获得具有语义特征的高维向量;其次,使用PCA 进行降维,运用迭代量化ITQ 的哈希学习方法对生成的特征向量进行二值化处理,通过逼近真实数据与哈希码之间的最小量化误差,得到更好的投影矩阵;最后,进行哈希学习,生成有效的二进制哈希码。

图4 DRITQH图像检索过程Fig.4 DRITQH image retrieval process
算法1 基于深度残差网络的迭代量化哈希图像检索方法。
输入n张图像I={I1,I2,…,In},ResNet-50 测试样本Z,迭代t,比特b。
输出 训练样本和测试样本的相似度。
步骤1 生成n个d维特征向量X∈Rn×d。
步骤2 PCA 降维为KnX。
步骤3 使用Y=sign(XWQ)进行编码。
步骤4 执行迭代量化L(Y,Q)=‖Y-XWQ。
步骤5 使用P=YQ测试样本Z。
步骤6 按照哈希码测试样本T=sign(P)。
步骤7 生成紧凑的二进制哈希码,并计算汉明距离S=Dist(T,Z′)。
3 实验结果与分析
在本章中,首先描述3 个基准图像数据集CIFAR-10[26]、NUS-WIDE[27]和ImageNet[28]的实验设置;然后与10 种经典的图像检索方法进行了全面比较;最后对所提出的DRITQH 方法进一步分析。为了全面评估本文方法和比较方法的检索准确性,使用了平均精度均值(mean Average Precision,mAP)和准确率-召回率(Precision Recall,P-R)曲线作为实验的度量标准,使用汉明距离度量图像之间的相似性。
3.1 实验数据集
CIFAR-10[26]数据集包含来自10种类别的60 000 幅图像,每类6 000 幅图像,每个图像仅属于一个类别。在实验中将50 000 幅图像用做训练集,每类5 000 幅图像,将10 000 幅图像用于测试集。
NUS-WIDE[27]包含从Flickr 收集的269 648 幅图像,其中每幅图像均由来自81 个语义类的一个或多个标签进行注释。在实验中使用从21 个最常出现的语义标签中随机选择2 100 幅图像作为测试集,其余图像作为训练集。
ImageNet[28]共包含约120万幅图像,实验使用2012 年ISLVRC 公开的ImageNet 子集,随机选择其中100 个不同的类别,训练集为120 000 幅图像,验证集为50 000 幅图像,用于测试集为10 000 幅图像。
3.2 评价指标
为了全面评估本文方法和比较方法的检索准确性,使用mAP 和P-R 曲线的标准度量指标。准确率(Precision)是指返回结果中相关图像的数量与检索的图像总数的比率,反映检索的准确性;召回率(Recall)是指检索到数据库中相关图像数量占总的相关图像的比率,反映检索的全面性;mAP 表示每个图像检索的平均精度得分的平均值,检索得到的所有训练样本的平均准确率。首先计算每个查询的平均精度(Average Precision,AP),并将AP 定义为:


其中数据库有n张图像,与图像xi相近的图像有k个,rj是检索到的前j个图像中匹配的数量。对于P-R 曲线,显示了每个测试图像在一定召回率下的精度,绘制了所有测试图像的所有检索结果的总体P-R 曲线。
3.3 相似性度量
由于汉明距离的计算速度快,广泛用于度量两个二进制码之间的相似性。将汉明距离引入哈希学习中,通过异或操作和位计数指令,可以快速地执行计算。在执行二进制量化后保留良好的配对相似性,从而进一步减少了量化误差。通过计算相同位数的哈希码不同值的个数,相似图像的汉明距离越小,不同图像的汉明距离越大。对于数据P=(p1,p2,…,pn),其中表示为k维的列向量,汉明距离定义公式如下:

3.4 对比方法
为了测试本文方法的有效性,在两种广泛使用的基准数据集上验证了DRITQH 方法的性能,与10 种经典的哈希方法进行了比较,大致将这些方法分为两组:传统的哈希方法和基于深度学习的哈希方法。传统的哈希方法包括无监督的哈希方法:谱哈希(Spectral Hashing,SH)[29]、ITQ[18]、局部敏感哈希(Locality Sensitive Hashing,LSH)[30]和监督哈希方法:SDH[19]、核函数的监督哈希(Supervised Hashing with Kernels,KSH)[31]。基于深度学习的哈希方法包括深度平衡离散哈希(Deep Balanced Discrete Hashing,DBDH)[32]、DFH(Deep Fisher Hashing)[33]、CNNH[11]、IDHN[23]、DPN(Deep Polarized Network)[34]。
1)SH[29]:谱哈希将图分割问题联系起来,通过对相似图的拉普拉斯矩阵特征向量的子集设定阈值来计算二进制代码。
2)ITQ[18]:迭代量化方法使用交替最小化方法,找到旋转零中心数据的最佳方式,将映射的量化误差最小化。
3)LSH[30]:使用局部敏感哈希函数映射变换,随机生成嵌入数据集合。
4)SDH[19]:离散监督哈希通过找到类标签与哈希码的关系,采用非线性核函数构建哈希模型,求得每个类的哈希码,用离散法提升检索精确度。
5)KSH[31]:核函数监督哈希利用汉明距离与哈希码内积之间的对应关系来学习哈希函数。
6)DBDH[32]:深度平衡离散哈希使用监督信息直接指导离散编码和深度特征学习过程。
7)DFH[33]:采用线性判别分析最大化类之间的二进制距离,同时最小化同一类内图像的二进制距离。
8)CNNH[11]:卷积神经网络哈希是首次将深度神经网络引入到哈希中的方法,在得到图像特征向量的同时进行哈希学习。
9)IDHN[23]:改进的深度哈希方法来增强多标签图像检索的能力,使用一对多标签图像之间的细粒度相似性以进行哈希学习。
10)DPN[35]:用于学习哈希的新型深度极化网络,最小化偏振损失相当于同时最小化内部方差和最大化类间方差的汉明距离。
3.5 实验设置
在实验中,首先对基础网络进行对比实验,本文采用AlexNet、VGG、GoogleNet、ResNet-50 和ResNet-101 作为基准方法,分别得到平均准确率。实验结果如图5 所示,采用简单的网络(AlexNet、VGG 和GoogleNet)表现的检索性能较低,ResNet-50 在图像检索算法中表现较好的性能,因此本文采用了性能较好的ResNet-50 网络结构作为特征提取框架。

图5 网络模型在三个数据集上的mAP值Fig.5 mAP values of network models on three datasets
实验是通过Pytorch 框架实现的,ResNet-50 被用作本文的网络骨干。在训练过程中,将批次大小设置为256,动量设置为0.9,重量衰减设置为5E-4,学习率为0.001,总共训练了150 个周期。
3.6 实验结果分析
本文表示了DRITQH 方法和10 种不同哈希对比方法在CIFAR10、NUS-WIDE 和ImageNet 数据集上 具有不同长度(12 bit、24 bit、32 bit 和48 bit)的哈希码图像检索性能的结果。如表1 所示,可以看到,与具有不同长度的哈希码与其他方法相比,DRITQH 方法的精度具有一定的提高。CIFAR-10 数据集的结果表明,所提出的DRITQH 方法的性能显著优于其他所有方法。与传统的哈希方法相比,DRITQH 使用残差网络提取图像深层语义信息,对应不同长度的哈希码的检索性能达到了78.9%、80.1%、82.2%和82.7%。此外,深度学习的哈希方法都比传统的哈希方法的性能更好,特别是IDHN 基于深度学习的哈希方法,实现了所有基于深度学习的哈希方法中的较高检索性能。与IDHN 相比,本文的DRITQH 方法对应于不同长度的哈希代码分别实现绝对提高4.5%、5.5%、5.4%和4.6%的平均精度。
类似于其他哈希方法,本文对大规模图像检索进行了实验,对于NUS-WIDE 数据集,如果两个图像共享至少一个标签,则认为它们属于相同的类别。表1 实验结果表明,所提出的DRITQH 方法优于现有的传统哈希方法,与经典的基于深度学习的哈希方法相比,DRITQH 方法表现的性能略有提高。这些结果表明,本文的方法可以提高检索性能。
本文还对更具挑战性的大规模ImageNet 数据集进行实验,将本文方法与其他方法进行比较,结果显示在表1 中,观察到DRITQH 在除了12 bit 之外的其他所有比特位获得了最佳性能,因为较短的代码在大规模数据集中的图像语义相似性差异较小,随着代码长度的增加,所提出的DRITQH 的性能提高比其他方法更明显,检索精度达到71.1%、76.3%、77.6%和78.1%,进一步展示了本文所提出的方法的优越性,也说明该方法适用于大规模的图像检索任务。

表1 在三个数据集上不同哈希码长度的mAP值Tab.1 mAP values of hash code with different lengths on three datasets
在深度哈希方法中,本文的DRITQH 方法在大多数情况下都在3 个数据集上实现了最佳的检索精度。如图6 所示,本文的DRITQH 方法的性能通常随着哈希码长度的增加而提高,这是因为随着哈希码长度的增加,学习的图像特征更加丰富,进而提高了检索精度。
为了进一步将DRITQH 与所有方法进行比较,在3 个数据集哈希码为32 bits 绘制了P-R 曲线。如图7 所示,本文发现DRITQH 的P-R 曲线下的面积大于大多数情况下的比较方法,表明DRITQH 优于比较方法,可以返回更多的语义相似得到图像,主要原因是通过残差网络可以更好地挖掘图像深层语义信息,具有更好的表示能力。由于传统的哈希算法是通过低级语义信息生成哈希码,而深度语义特征可以获得更多的图像信息。因此,由深层语义信息生成的哈希码比低级语义信息的哈希码更好,验证了在深度学习中学习图像表示的优势比使用手工图像特征更有益于学习有效的二进制哈希码。

图7 三个数据集上在32 bit编码下的查准率、查全率和P-R曲线Fig.7 Precision,recall and P-R curves under 32 bit encoding on three datasets
通过图6(a)和6(b)可以观察到,NUS-WIDE 数据集检索性能比CIFAR-10 更好,因为图像越复杂,网络模型学习到的特征信息就越多,检索的性能就更好;但ImageNet 数据集检索性能却有所偏低,主要是由于ImageNet 数据集数据量庞大,类别多,大规模数据集中的图像语义相似性差异较小。结果表明两点:1)验证了深度学习中图像特征表示比传统手工提取的图像特征能学习更有效的二进制哈希码,CNNH 比使用深度学习网络提取特征的方法精度有所偏低,主要是由于CNNH 无法同时进行图像特征和哈希码的学习,但CNNH比传统手工提取特征的哈希方法的性能又更好。2)DRITQH方法在3 个数据集的大多数情况下实现了最佳的检索精度,检索性能通常随着长度的增加,每一种方法的检索效果都有提高。在本文的方法中,利用了ResNet-50 模型的优势,提高了训练速度和生成了高质量的特征向量,使用ITQ 算法将高维特征向量映射到低维空间并生成最优的二进制哈希码,从而提高了图像检索的准确率。
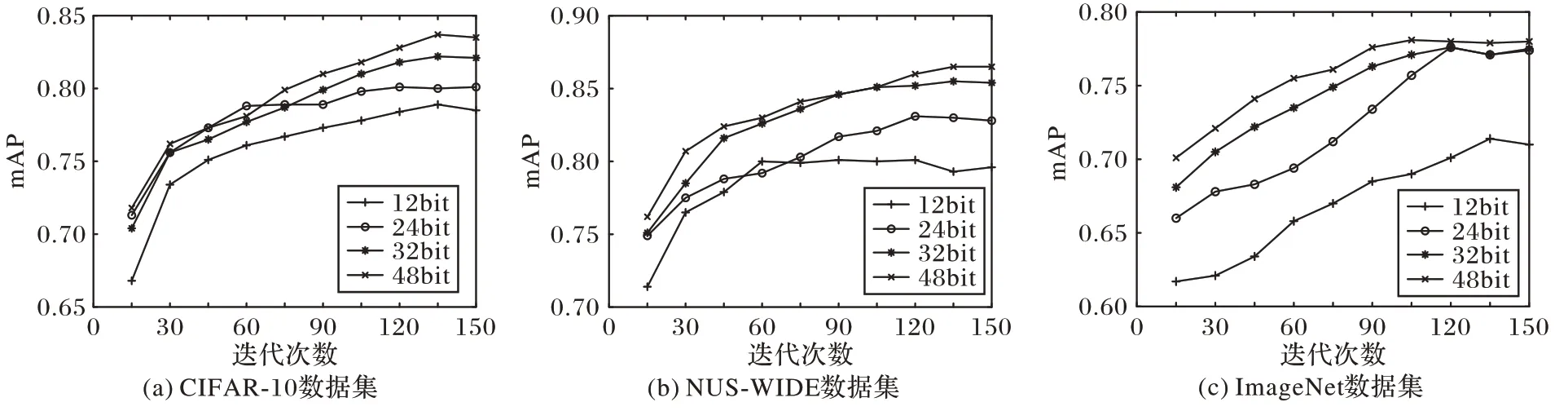
图6 DRITQH方法在三个数据集上对不同长度哈希码的检索精度Fig.6 Retrieval precision of DRITQH method for hash codes with different lengths on three datasets
3.7 编码时间分析
除了检索性能之外,本文还将所提出的DRITQH 方法在NUS-WIDE 数据集上的计算时间成本与其他方法进行了比较。基于哈希的图像检索过程通常由三部分组成:特征提取、哈希码的生成和数据库检索。
图8 显示了哈希方法的编码时间,其结果是在整个测试集上训练得到的平均编码时间。通常,当仅考虑从模型输入产生二进制代码,基于深度学习的方法比传统方法较慢至少一个级别,然而考虑到特征提取时间,基于深度学习的方法比传统的哈希方法快很多。此外,传统的哈希方法通常需要几种类型的特征来实现基于深度学习的方法的检索性能,这进一步减慢了整个编码过程。DRITQH 方法和其他方法的时间成本比较可知,当学习哈希函数时,哈希码生成的时间成本和数据库检索时间成本是一个非常快的乘法矩阵,并且使用汉明距离可以通过异或操作快速地实现,这表明哈希编码时间主要取决于特征提取阶段,包括网络的大小,其中较大的网络包含更多参数,这需要更多时间完成特征提取。与IDHN 方法相比,DRITQH 平均编码时间少1 717 μs。DRITQH 方法时间成本较低,使用残差网络学习图像特征,通过跳跃连接直接将输入信息连接到后面的层,保护信息的完整性,进一步说明DRITQH 能有效加快训练速度。

图8 在NUS-WIDE数据集上编码一个图像的时间成本Fig.8 Time cost to encode one image on NUS-WIDE dataset
4 结语
针对图像数据呈指数级增长,传统的图像检索算法已无法满足用户精准检索图像的要求。本文通过设计深度框架改进哈希算法提高二进制哈希码,提出了基于深度残差网络的迭代量化哈希图像检索方法,通过ResNet-50 提取的特征向量作为ITQ 的输入,进行哈希学习并编码。残差网络可以提高神经网络的训练速度,更好地提取图像的深层语义特征,从而提高了ITQ 的性能,在较小的数据规模下实现更高的检索准确率。在3 个基准数据集上的实验结果表明,采用残差网络提取的特征向量作为ITQ 的输入,可以学习更好的哈希码,不仅提高了训练速度,还提高了检索的准确率,且可通过较小的码长实现更高的检索准确性。本文方法与经典的方法相比,提高了检索精度和训练速度。由于DRITQH 是一种相对通用的哈希方法,它在信息检索等其他任务中具有广泛的潜在应用,在未来,将致力于图像检索领域学习更好的量化图像检索方法。
