基于知识库实体增强BERT模型的中文命名实体识别
2022-09-25胡燕刘梦赤张龑
胡 婕,胡燕,刘梦赤,张龑
(1.湖北大学计算机与信息工程学院,武汉 430062;2.华南师范大学计算机学院,广州 510631)
0 引言
命名实体识别(Named Entity Recognition,NER)在自然语言处理(Natural Language Processing,NLP)的许多下游任务如知识库构建[1]、信息检索[2]以及问答系统[3]中扮演着重要角色。NER 任务主要方法有3 种:基于规则、基于传统机器学习和基于深度学习的方法。其中基于深度学习的方法与基于规则和基于统计学的方法相比无需人工设置特征,神经网络可以自动从数据中学习特征,被广泛地应用于命名实体识别的任务中[4-6]。
NER 任务实质上是序列标注问题[7]。中文命名实体识别任务与英文有所不同,英文句子中有天然的边界,而中文句子没有,这给中文命名实体识别带来了更多挑战。中文NER 任务在进行单词序列标注之前,一般要先进行分词然后再将词级别的序列标注模型应用于所分割的句子,命名实体边界也就是词的边界;然而,分词不可避免地会出现单词的错误划分从而造成实体边界的错误识别。为了解决分词错误对命名实体识别任务的影响,Li 等[8]认为基于字符的方法没有中文分词错误,比基于词的方法更适用于中文NER 任务;然而,基于字符的NER 任务并不能充分利用词和词的序列信息。为了解决这个问题,Zhang 等[9]提出了格结构的长短期记忆网络(Lattice Long Short-Term Memory network,Lattice-LSTM)模型,将词典纳入基于字符的模型。此外,当字符与词典中的多个单词匹配时,保留所有与字符匹配的单词,而不是启发式地为字符选择一个单词,让后续的NER 模型来确定应用哪个单词。通过使用Lattice-LSTM 来表示句子中的词汇,将潜在的单词信息整合到基于字符的LSTMCRF(Long Short-Term Memory network-Conditional Random Field)中,但是Lattice-LSTM 的模型架构相当复杂。为了引入词典信息,Lattice-LSTM 在输入序列中不相邻的字符之间添加了多个额外的边,显著降低了其训练和推理速度,而且很难将网格模型的结构应用到其他神经网络结构,只适合于某些特定的任务,不具通用性。于是Ma 等[10]提出更简单的方法来实现Lattice-LSTM 的思想,将每个字符的所有匹配单词合并到基于字符的NER 模型中,在字符中表示编码词典信息,并设计编码方案以尽可能多地保留词典匹配结果。这种方法不需要复杂的模型结构,更容易实现,并且可以通过调整字符表示层快速适应任何合适的神经NER 模型。然而由于网格结构的复杂性和动态性,现有基于网格的模型很难充分利用图形处理器进行并行计算,因而推理的速度通常较慢。因此,Li 等[11]提出了平面点阵变换器,核心是将点阵结构转换成一组跨度,并引入特定的位置编码,在性能和效率上优于其他基于词典的模型;Xue 等[12]和Gui 等[13-14]利用词汇特征,外部词汇级信息增强了NER 训练。
然而,上述方法都是有监督的模型,当处理有较少标记数据的数据集时,小数据无法反映出语言间的复杂关系,同样也很容易让复杂的深度网络模型过拟合,很难获得很好的训练网络,因此预先训练的半监督语言模型就显得尤为重要。Devlin 等[15]提出的BERT(Bidirectional Encoder Representations from Transformers)模型就是一个预训练半监督模型,可以在与最终任务无关的大数据集上训练出语言的表示,然后将学到的知识表示用到任务相关的语言表示上。Sun 等[16]提出了ERNIE(Enhanced Language Representation with Informative Entities)模型,它通过知识整合来增强BERT。ERNIE 通过屏蔽完整实体来训练,而不像BERT 那样屏蔽单个字词标记。ERNIE 预训练的实体级掩码技巧可以看作是一种通过错误反向传播来集成实体信息的隐式方法。由于命名实体识别中的实体可能出现二义性,即相同的词在不同的领域有不同的语义,因此包含领域的实体词典对于该任务是有用的。考虑到这一点,Jia 等[17]提出了将词典嵌入到针对中文NER 的预先训练最小均方误差模型中,提出了一种半监督实体增强的最小均方误差预训练模型Entity Enhanced BERT Pre-training。具体来说,首先使用新词发现方法从原始文本以及相关文档中提取实体词典;然后使用Char-Entity-Self-Attention 机制替换原始的自我注意力机制将实体信息嵌入到BERT 中,也就是使用字符和实体表示组合来增强自我关注。该机制可以更好地捕捉字符和文档特定实体的上下文相似性,并将字符隐藏状态与每一层中的实体嵌入显示结合;但是提取实体词典的方式较为复杂而且获取的实体词数量和使用范围有限。如今,开放域和领域知识库构建越来越完善,可免费获得的知识库也越来越多,因此本文提出了在词典中加入知识库信息的方法来扩展词典中的实体信息,使词典中的词使用更具广泛性。具体来说,首先在中文通用百科知识图谱CN-DBpedia[18]中下载其提供的mention2entity 文档,该文档中包含了110 多万条数据,这些数据中包含了大量的实体,使用Jieba 分词对数据进行分词处理,留下带有名词标签的词,使得词典中的实体词更丰富、应用领域更广泛;而且由于各个领域的实体词典可以从其领域知识库中获得,可以减少前期词典创建的工作量。随后将词典中的实体嵌入到BERT 预训模型中进行预训练,然后在NER 微调任务中将训练得到的词向量输入到BiLSTM 中提取特征,最后通过CRF 层从训练数据中获得约束性规则,为最后预测的标签添加约束来保证预测标签的合法性,生成最优序列结果。实验结果表明本文模型在CLUENER 2020 数据集[19]上的F1 值达到了78.15%,在MSRA 数据集[20]上的F1的值达到了88.11%,相比上述Entity Enhanced BERT Pretraining 模型以及其他三个基线模型BERT+BiLSTM(Bidirectional Long Short-Term Memory)、ERNIE 和BiLSTM+CRF都有所提升,从而验证了加入知识库之后的词典结构在中文NER 语言模型预训练中整合实体信息的有效性,以及在实体识别的微调任务中加入CRF 层预测标签的有效性。
1 本文方法
本文的命名实体识别方法主要分为3 个部分:首先从中文通用百科知识库CN-DBPedia 中抽取实体来构建实体词典;然后将词典中的实体嵌入到BERT 中进行预训练,将训练得到的词向量输入到BiLSTM 提取特征;最后经过条件随机场修正后输出。
1.1 词典的构建
为了获得特定文档的实体信息,将其嵌入到BERT 预训练语言模型中,Jia 等[17]采用Bouma[21]所提出的无监督方法在原始文档中自动发现候选实体,分别计算连续字符之间的交互信息值和左、右熵度量值,然后将这3 个值相加作为可能实体的有效评分。
本文在此基础上加入开放域知识库中所提供的实体来对原有的词典进行扩充,将实体词典扩充成一个大小为6 086 KB 的实体词典。本文使用的知识库是由复旦大学知识工场实验室研发并维护的大规模通用百科知识图谱知识库CN-DBpedia,其数据来源于中文百科类网站如百度百科、互动百科、中文维基百科等的纯文本页面中提取的信息,经过过滤、融合、推断等处理后,最终形成的高质量结构化数据。本文使用CN-DBPedia 所提供mention2entity 文档中的数据,其包含110 多万条信息,包含了大量的实体,所包含的领域非常广泛,获取的途径也很方便。本文的具体做法,从OpenKG.CN 网站下载mention2entity 中的文本后对数据进行清洗,清洗的过程是用可以标注词性的Jieba 分词工具对文本进行全模式分词,将标注为名词词性的词挑选出来,去掉重复的词语,将剩余的词加入词典中作为候选实体。
1.2 嵌入词典实体信息的BERT预训练
嵌入实体信息的BERT 预训练模型结构如图1 所示,与基于中文BERT[15]的Transformer 模型中Encoder 结构类似,为了利用提取的实体,即将实体信息嵌入到模型中,将Transformer 扩展为Char-Entity-Transformer,如图2所示它是由一个多头的Char-Entity-Self-Attention 块堆栈组成。

图1 嵌入实体信息的BERT预训练模型结构Fig.1 Structure of BERT model embedding entity information

图2 Char-Entity-Self-Attention模型结构Fig.2 Structure of Char-Entity-Self-Attention model
首先将字符与提取的实体进行匹配,给定字符序列c={c1,c2,…,cT}和提取的实体字典Entity,使用最大实体匹配算法得到对应的实体标记序列e={e1,e2,…,eT}。用包含该字符词典中最长实体的索引来标记每个字符,并将没有实体匹配的字符标记为O。
在模型的输入阶段,给定一个字符序列c={c1,c2,…,cT},输入层中的第t个字符的表示是字符、文本和位置嵌入的总和,表示为:

其中:Ec、Es、Ep分别表示字符的字嵌入查找表、文本嵌入查找表和位置查找表,因为没有用到下一句预测任务的输入句子顺序,所以将文本索引s设置为常数0。
接下来将给定字符序列和前面所得到的实体标记序列一起输入到如图2 所示的多头Char-Entity-Self-Attention 模型,将汉字的隐含维数和新词实体的隐含维数分别表示为Hc和He,L是层数,A是自注意力头的个数。对于给定l-1 层字符的隐藏序列的Key 矩阵和Value 矩阵与BERT 的多头注意力有所不同,它用实体的隐藏字符和实体嵌入组合来生成Key 和Value 矩阵,表示为:

1.3 NER任务
本文NER 任务模型框架如图3 所示。

图3 NER任务模型框架Fig.3 Model framework of NER task
将文本信息转化为计算机可以识别的数据形式是任务的第一步。目前常用的词嵌入模型主要是BERT 预训练语言模型,它通过双向Transformer 编码器生成字向量,但是实体识别的任务是识别人名、地名等实体信息,BERT 模型无法利用现有的实体信息。本文使用如1.2 节所述的嵌入实体信息的BERT 预训练模型,其Char-Entity-Self-Attention 机制可以很好地捕捉字符和文档特定实体的上下文相似性,并显式地将字符隐藏状态与每一层实体嵌入结合,再将扩展后的模型对数据集信息进行编码。将嵌入词典实体预训练BERT模型的最后一层输出输入到BiLSTM 中进行训练,进一步提取文本特征。通过BiLSTM 对序列的上下文信息进行学习,为每个标签打分,BiLSTM 的输出为字符的每一个标签分值,输出结果如图4 所示。
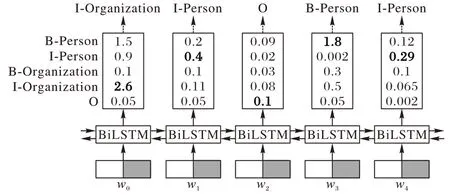
图4 BiLSTM 输出标签Fig.4 BiLSTM output label
BiLSTM 通过挑选每个标签分值最高的作为该字符的标签,并选取最大分值作为每个字符最终的输出标签。如图4所示,模型所生成的标签为I-Organization I-Person 和B-Person I-Person,但是显然I-Organization 之后不可能出现I-Person,即:标签序列“I-Organization I-Person”是错误的。这种取最大值的方法虽然可以得到正确的标签序列B-Person I-Person,但是并不能保证每次的预测都是正确的,因此模型不能仅以BiLSTM 的输出结果作为最终的预测标签,需要在预测标签与标签之间引入约束条件来保证生成标签的合法性,因此本文将BiLSTM 的输出结果输入到CRF 层。CRF 层可以为最后预测标签添加约束关系来保证预测标签的合理性。
给定输入序列X={x1,x2,…,xn},假设训练得到对应输出标签序列Y={y1,y2,…,yn},其中n代表NER 标签的数量,则标签序列的得分可表示为:

其中:Z为转移矩阵为标签从yi转移到yi+1的分值;为输入序列第i+1 个字对应标签yi+1的分值。对标签序列y的概率进行计算,可表示为:
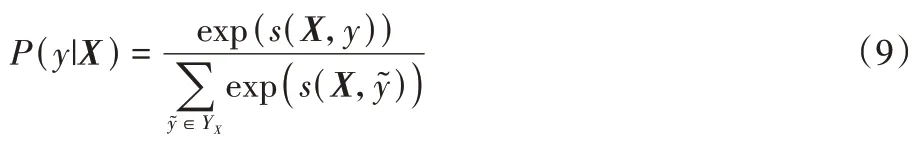
其中YX为所有可能的标签序列集合,最终输出序列的标签为概率最大的标签集合。
2 实验结果与分析
2.1 数据集与评价指标
2.1.1 数据集
为了验证本文模型的有效性,在两个公开使用的数据集CLUENER 2020 和MSRA 上做了对比实验。
CLUENER 2020 数据集[19]是一个细粒度的中文NER 数据集,包含10 种不同的实体类别,分别是组织(organization)、人 名(name)、地 址(address)、公 司(company)、政 府(government)、书籍(book)、游戏(game)、电影(movie)、职位(position)和景点(scene),并对常见类别进行了细粒度的划分,如将“组织”细分为“政府”和“公司”等;同时存在同一实体在不同语境下属于不同类别的情况,如Twins 的字面意思是双胞胎,但是在娱乐新闻的背景下,它指的是Twins 组合。本文从CLUENER 2020 数据集中随机抽取5 200、600 和748个句子分别作为训练集、评估集和测试集,并将抽取的句子划分为4 个新闻领域:GAM(游戏)、ENT(娱乐)、LOT(彩票)和FIN(金融)。
MSRA[20]是中文NER 的通用数据集。它包括三种类型的实体,分别是PER(人名)、LOC(地名)和ORG(组织名)。本文使用标记集{B,I,E,O}进行标记。
数据集的详细信息如表1 所示。

表1 数据集描述Tab.1 Description of datasets
2.1.2 评估标准
本文采用准确率(Precision,P)、召回率(Recall,R)和F1的值作为评价指标,这三种评价指标越高,代表模型性能越好。评价指标的计算公式如下:

2.2 实验环境
本文所有的实验均在Python3.6,pytorch1.7,GTX 5000平台上运行。
2.3 实验设置
本文模型使用BERT 构建,层数L=12,自注意头数A=12,字符的隐藏大小Hc=768,实体的隐藏大小He=64,其他超参数的设置如表2 所示。

表2 本文模型参数Tab.2 Parameters of the proposed model
2.4 实验结果与分析
1)本模型与基线模型实验对比。
本文对比的基线模型是Entity Enhanced BERT Pretraining[17]。它首先在与数据集相关的文档中获取词,将其作为候选实体放入实体词典中;然后将实体词典信息嵌入到BERT 的预训练中,并将预训练模型用于NER 任务中进行实体的分类输出。它在前期词典的获取过程中使用的方法并不能识别所提取词是否是真正的实体,导致词典中真正的命名实体比例降低,而加入了无关实体的词进行预训练会降低模型的性能。本文词典的提取方法是使用开放域知识库CN-DBpedia,其包含大量的实体三元组,用于提高抽取的候选实体中真正实体的比例。此外,基线模型在NER 任务中没有利用CRF 层来对生成的标签进行约束。
为了验证本文模型的有效性,在同一实验环境下,设计了两组实验与基线模型Entity Enhanced BERT Pre-training[17]在测试集上进行对比,在CLUENER 2020 数据集和MSRA 数据集上F1 值的对比如表3 所示。

表3 测试集上模型F1值的对比 单位:%Tab.3 Comparison of F1 scores of models on test sets unit:%
从表3 可知,与基线模型Entity Enhanced BERT Pretraining 相比,本文加入开放域知识库的实体增强BERT 模型OpenKG+Entity Enhanced BERT Pre-training 在上述两个数据集上F1 值都有一定的提升。从CLUENER 2020 数据集的所有类别(All)F1 的值可以看出,加入知识库之后的模型F1 值提升了0.92 个百分点,在MSRA 数据集上F1 值提升了0.58个百分点,这是因为本文选取的开放域知识库中mention2 entity 文档包含110 多万条信息,包含了各个领域的大量实体,本文从中提取了3 000 多条候选词加入对应新闻领域词典中。F1 值的提升可以验证加入开放域知识库的有效性。在此基础上,本文使用OpenKG+Entity Enhanced BERT Pretraining+CRF 模型在NER 微调中加入CRF 层来修正标签,从表中CLUENER 2020 数据集所有领域(All)的F1 可以看出,相比只加入开放域知识库的模型OpenKG+Entity Enhanced BERT Pre-training 的F1 值提升了0.71 个百分点,在MSRA 数据集上F1 值提升了0.52 个百分点。相比基线Entity Enhanced BERT Pre-training 模型,在CLUENER 2020 数据集上F1 值提升了1.63 个百分点,在MRSA 数据集F1 值提升了1.10个百分点,验证了NER 微调加入CRF 解码层的有效性。
Entity Enhanced BERT Pre-training 模型与本文的两组模型在CLUENER 2020 数据集的所有领域(All)和MSRA 数据集的测试集上准确率、召回率和F1 值的对比如表4 所示。

表4 测试集上的模型各评标指标对比 单位:%Tab.4 Comparison of evaluation indexes of models on test sets unit:%
从表4 中可以看出,在CLUENER 2020 和MSRA 这两个公开的数据集上,本文模型在准确率、召回率和F1 值上均有提升,验证了本文模型综合效果更佳。
2)与相关工作对比。
为了进一步验证本文模型的有效性,本文还对三组中文NER 方法在CLUENER 2020 数据集和MSRA 数据集上进行了比较。这三组模型分别为:BERT+BiLSTM、ERNIE[22]和BiLSTM+CRF模型。其中,ERNIE是百度公司基于BERT 模型进一步优化得到的模型,它在中文NLP 任务上获得了最佳效果,其主要是在掩码(mask)机制上做了改进,在预训练阶段不仅采取字掩码机制,而且增加了外部知识进一步采取全词掩码和实体掩码的三级掩码机制。
三组模型与本文模型在CLUENER 2020 数据集的所有领域和MSRA 数据集F1 值对比如表5 所示。

表5 相关模型F1值的对比 单位:%Tab.5 Comparison of F1 scores of related models unit:%
从表5 可以看出,相比直接对预先训练的中文BERT 生成字向量与利用BiLSTM 方法解码的模型,本文模型在CLUENER 2020 数据集上的F1 值提升了3.93 个百分点,在MSRA 数据集上的F1 值提升了5.35 个百分点,这是因为Char-Entity-Transformer 结构能够有效地利用实体词典信息,并且考虑到不同实体在不同语境下可能有不同的语义的情况,利用CRF 解码层为最后预测的标签添加约束关系来保证预测标签的合法性,从而提高了F1 的值。与ERNIE 相比,尽管ERNIE 使用更多来自网络资源的原始文本和实体信息进行预训练,但是在CLUENER 2020 数据集上F1 值仍提升了2.42 个百分点,并且在MSRA 数据集上F1 的值提升了4.63个百分点,这表明了通过字符-实体转换结构集成实体信息的显式方法比实体级掩蔽方法对中文NER 更有效。与BiLSTM+CRF 模型相比,在CLUENER 2020 数据集上F1 的值提升了6.79 个百分点,在MSRA 数据集上F1 的值提升了7.55 个百分点,这是因为嵌入词典实体的BERT 预训练模型能够将实体集成到具有字符实体转换器的结构中,从而改善实体识别的效果。从各模型F1 值可以看出,本文模型的整体识别效果得到了明显提升。
3 结语
针对实体增强预训练模型的词典获得方法较为复杂而且获取的实体词数量和使用范围有限的问题,本文充分利用了开放域知识库资源,使得词典的获得更加便利,能够包含更多相关领域的候选词,从而提升了模型的效果。在NER任务中,由于只依赖BiLSTM 对标签打分的输出会导致出现大量不合法标签,本文通过加入CRF 层的解码得到最优序列,提高了实体提取的结果。实验结果表明,利用加入知识库的预训练模型以及在NER 任务中加入CRF 解码层的模型获得了更高的F1 值,从而验证了本文模型的有效性。未来的工作重点是简化模型,以提升模型的训练速度。
