基于多尺度卷积和门控机制的注意力情感分析模型
2022-09-25衡红军徐天宝
衡红军,徐天宝
(中国民航大学计算机科学与技术学院,天津 300300)
0 引言
情感分析(Sentiment Analysis)根据人们生成的文本来分析他们的情感或观点,一直以来都是自然语言处理中最活跃的研究领域之一。识别文本中表达的潜在情感对于理解文本的全部含义至关重要。随着微博、知乎、头条等社交媒体平台的快速发展,人们越来越多地在网上分享自己的观点和看法。情感分析已吸引了很多关注,因为从文本中检测到的意见或情感对于商品推荐、舆情分析、市场预测等方面都有很大帮助。
文档级情感分析的目标是判断整篇文档表达的情感,例如一段影评,或者对某一个热点时事新闻发表的评论,只要待分析的文本超过了一句话的范畴,即可视为是文档级的情感分析。对于文档级的情感分析而言有一个前提假设,那就是全篇章所表达的观点仅针对一个单独的实体,且只包含一个观点持有者的观点。
在传统的情感分析任务中,大多数模型将情感分析视为一个包含特征提取和分类器训练两部分的分类问题[1]。最初是利用基于机器学习的方法使用监督分类或回归,从极性标记的文本训练模型[1-2];然而,这些模型的性能在很大程度上依赖于大量的人工处理的特征,例如情感词典和其他具有特定含义的特征。
随着深度学习的方法的提出,情感分析模型的性能获得进一步的改进。情感分析领域应用最广泛的神经网络模型包括卷积神经网络(Convolutional Neural Network,CNN)[4]、双向长短期记忆(Bidirectional Long Short-Term Memory,BiLSTM)[5]网络等。
文档级情感分析研究主要集中在生成丰富文档表示和个性化两个方面,以提高分类模型的性能。一个人写的评论文本是主观地偏向他/她自己认知的。宽容的用户往往比挑剔的用户给出更高的评级,即使他们评论同样的产品,受欢迎的产品可能比不太受欢迎的产品获得更多的赞扬。因此,模型必须考虑用户和产品信息对文本情感分类的影响。Tang 等[6]使用CNN 作为基础编码器,并且首次将用户和产品的信息结合到情感分类神经网络模型中,使情感分析模型性能获得了极大的提升。
近年来,研究人员为了增强文档表示开始构建基于注意力的模型[7],以突出一段文本中的重要单词或者句子。使用嵌入在文本中的信息构建不同的注意力模型成为了主流,融入的信息包括本地上下文中的用户信息、产品信息和评论文本数据。Chen 等[7]提出了一个层次神经网络,通过层次结构来建模文档的语义,并且引入注意力机制,将用户产品信息融合到注意力当中提出用户产品注意力。用户产品注意力的提出,使文档级情感分析模型性能再次获得极大的提升。Kim 等[8]使用基向量来将用户产品信息融合到模型的分类器上,当分类特征的数量很大时,基向量的使用对参数量的减少十分明显。蒋宗礼等[9]同样使用层次结构来建模文档的语义,并且通过将用户信息和产品信息融合到多头注意力当中,使模型在多个子空间上得到不同用户和产品对情感评分的影响。
为了给文本分配合适的标签,模型还应捕获源文本中比词级信息更高级信息的核心语义单元,然后基于其对语义单元的理解来分配文本标签。由于传统的注意机制只是侧重于提取包含冗余和无关细节的词级信息,因此很难从语义单元中提取更多关键信息。针对这一问题,本文提出了一种基于多尺度卷积和门控机制的注意力情感分析模型。本文模型利用全局用户偏好和产品特征学习评论文本,通过提取得到不同尺度的文本表示进行情感分类。为了验证该模型的有效性,对来自IMDB 和Yelp(包括Yelp2013 和Yelp2014)3个评估数据集进行了评估。实验结果表明,该模型能够以较大的幅度优于基准模型。与基准模型中性能最先进的那个相比,本文模型在IMDB 和Yelp2014 数据集的准确率(Accuracy)上分别提高了1.2 个百分点和0.7 个百分点,并且在IMDB 和Yelp2013 数据集上获得了最小的均方根误差(Root Mean Squared Error,RMSE)。
本文的主要工作有以下两点:
1)使用多尺度卷积注意力的方式对文本进行编码。首先使用多尺度卷积提取文档单词之间的多种粒度短程局部语义信息,再通过用户产品注意力获得不同层次的更丰富的文档表示。
2)引入门控单元,构造新的门控单元GTUU(Gate Tanh Update Unit)控制情感信息流向汇集层的路径,并通过实验证明了GTUU 在文档级情感分析中更加有效。
1 本文模型
本文提出的基于多尺度卷积和门控机制的注意力情感分析模型的框架见图1。本文模型由编码层、多尺度卷积层、注意力层、门控层和分类层5 个部分构成。
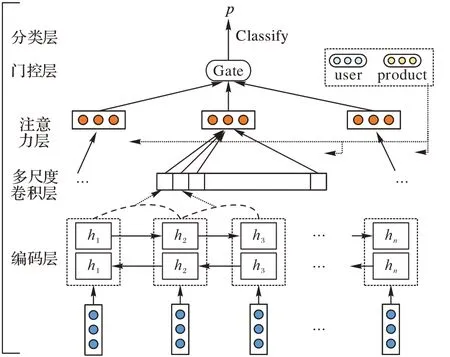
图1 本文模型框架Fig.1 Framework of the proposed model
1.1 编码层
首先定义某一个文档doc=[x1,x2,…,xj,…,xn],xj表示doc的第j个词,n代表语句的长度;然后使用预先训练的词嵌入向量来初始化,在训练阶段对它们进行微调。所有的词通过一个词嵌入矩阵将单词嵌入到相应的向量wj中。
本文使用BiLSTM 这种在长文档情感分析有很好的性能的编码器来学习基础文档表示。BiLSTM 通过总结来自单词的两个方向的信息来获得单词的特征表示,将上下文信息结合在特征表示中。由于向前和向后的长短期记忆网络(Long Short-Term Memory,LSTM)看起来相似,因此为了简洁,只给出前向LSTM 的计算过程,如式(1)~(3)所示:
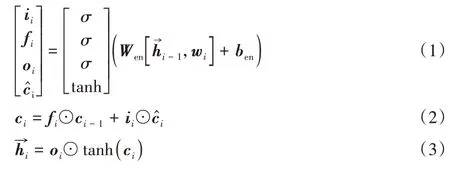
其中:ii、fi、oi是门激活函数;⊙表示点乘运算符;σ是sigmoid 函数;tanh 表示Hyperbolic tangent 函数;Wen、ben是需要训练的参数。
然后,将前后向的隐藏状态拼接在一起形成一个新的单词向量hi=文档矩阵经过编码层后表示为H=[h1,h2,…,hn]。
1.2 多尺度卷积层
受文本摘要的全局编码[10]思想的启发,本文利用卷积神经网络(CNN)来捕捉单词之间的局部交互,并生成比单词更高级别的信息表示,例如词组或短句。多尺度卷积层(Multi-Scale Convolution,MSC)采用多个拥有不同宽度卷积核的一维卷积滤波器捕获不同粒度的局部相关性,目的是获得更多不同层次的文本语义信息。

1.3 注意力层
虽然通过多尺度卷积层分别以不同尺度对文档进行过凝练,但并不是所有语义单元都对文档的情感表达含义有同等的贡献,必须要进行注意力计算,对不同的语义单元赋予不同的权重,而且对于不同用户和不同产品来说,对于情感词汇的使用也是有差异的,因此,还需要将用户信息和产品信息融入注意力的计算当中,更加准确地提取出文本中的情感信息。
注意力层分别对每个文档进行用户产品注意力计算,具体计算过程如式(5)~(7)所示:

其中:Nq代表不同尺度文档表示的数量;代表对第q个尺度文档表示的待训练权重矩阵;bd表示偏置。
1.4 门控层
在语言建模中提出的门控Tanh-ReLU 这种门控机制取得了很好的效果,其中最著名的两种门控单元是门控Tanh单元(Gate Tanh Unit,GTU)和门控线性单元(Gate Liner Unit,GLU)。GTU 由tanh(Wx+b)⊙σ(Vx+b)表示,而GLU使用(Wx+b)⊙σ(Vx+b)代替使得梯度不会被缩小,可以传播更多的信息[11]。本文构造了一个新的门控更新单元(Gate Tanh Update Unit,GTUU)控制情感信息流向汇集层的路径,实验证明门控机制在文档级情感分析中是有效的。

GTUU 门控单元具体计算过程:
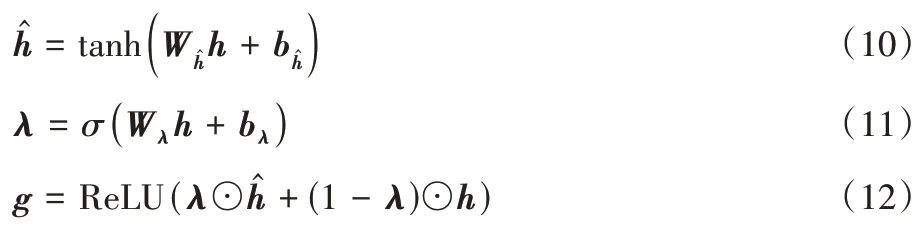
1.5 分类层
文档向量g是文档的高级表示,可作为文档情感分类的特征。使用线性层将文档表示g影到C类的目标空间中:

其中:C是情感类的数量;p是最终的情感预测;argmax(f(·))的作用是获取使f(·)取得最大值所对应的情感类别;Wc和bc分别为待训练权重和偏置。
1.6 优化策略
在模型优化的过程中,使用交叉熵损失函数最小化作为模型的优化目标,使用反向传播算法迭代更新模型参数,如式(14)所示:

2 实验与结果分析
2.1 实验数据集及评价指标
实验是在Tang 等[6]构建的3 个带有用户产品信息的情感分析公开数据集(IMDB、Yelp2013、Yelp2014)上进行模型有效性的验证,其中IMDB 是电影评论数据集,Yelp2013 和Yelp2014 是商品评论数据集。
3 个数据集的统计信息如表1 所示。按照8∶1∶1 的比例将数据集划分为训练集、验证集和测试集,使用斯坦福CoreNLP[12]进行标记化和句子拆分。本文使用准确率(Accuracy)和均方根误差(RMSE)两个标准来度量模型可信度,准确率测量整体情感分类性能,均方根误差描述预测情感和真实情感之间的离散程度。

表1 IMDB、Yelp2013和Yelp2014数据集的统计信息Tab.1 Statistical information of IMDB,Yelp2013 and Yelp2014 datasets
2.2 实验设置
在NVIDIA 2080Ti GPU 上,基于PyTorch 深度学习框架中进行了本文的实验。实验中使用预训练的GloVe[13]词嵌入向量对单词向量进行初始化。GloVe 的维度、双向LSTM的输入维度(前向后向隐藏状态各自为150 维)、一维卷积滤波器的输入输出通道数均设为300 维。多尺度卷积层采用3个平行的一维卷积操作,卷积核分别为1、2、4,卷积步长与卷积核大小相同。为防止过拟合,在每一层之后做一次Dropout,且Dropout 率为0.1。实验Batch Size 设置为64。模型超参数的优化在Adadelta[14]优化器上完成。模型在训练集上训练调参,在验证集上选择最佳性能的模型参数,最后在测试集上进行测试。
2.3 基准模型
为了验证本文提出的模型的有效性,该模型将与以下基准模型进行对比:
1)UPNN(User Product Neural Network)[6]:使用CNN 作为基本模型,并将用户和产品信息作为权重参数纳入单词嵌入和逻辑分类器中。
2)NSC(Neural Sentiment Classification)[7]:将分层LSTM作为基本模型,提出用户产品注意力方法合并用户和产品信息。
3)InterSub[15]:使用CNN 作为基本模型,利用用户和产品信息嵌入到模型中。
4)TUPCNN(Training User and Product information with CNN)[16]:使用CNN 作为基本模型,并通过评论的时间顺序来训练模型。
5)PMA(Parallel Multi-feature Attention)[17]:与NSC 类似,但并行地将用户和产品分别融合到注意力当中,并且考虑用户的偏好排序。
6)CMA(Cascading Multiway Attention)[18]:使用LSTM 作为基本模型,将用户和产品信息分别融入注意力。
7)UPDMN(User Product Deep Memory Network)[19]:通过将用户和产品信息嵌入到深度记忆网络中进行情感分类。
8)DUPMN(Dual User and Product Memory Network)[20]:使用分层LSTM 作为基本模型,并将用户和产品信息分别嵌入到两个单独的深层记忆网络。
9)HCSC(Hybrid Contextualized Sentiment Classifier)[21]:使用双向LSTM 和CNN 的组合作为基本模型,并且还考虑了用户和产品数量非常有限时的冷启动问题。
10)BLBC(Bidirectional-LSTM linear Basis Cust)[8]:使用BiLSTM 作为基本模型,并使用基向量来将用户产品信息融合到模型的分类器上。
11)HUPMA(Hierarchical User and Product Multi-head Attention)[9]:结构与NSC 类似,同样使用分层BiLSTM 作为基础模型,并且使用多头注意力机制从多个视角获取信息。
2.4 实验分析
实验在测试集上计算出Accuracy 值和RMSE 值,各个模型对比实验结果如表2 所示。为验证多尺度卷积和门控单元的有效性,本文做了消融实验,实验结果如表3 所示。
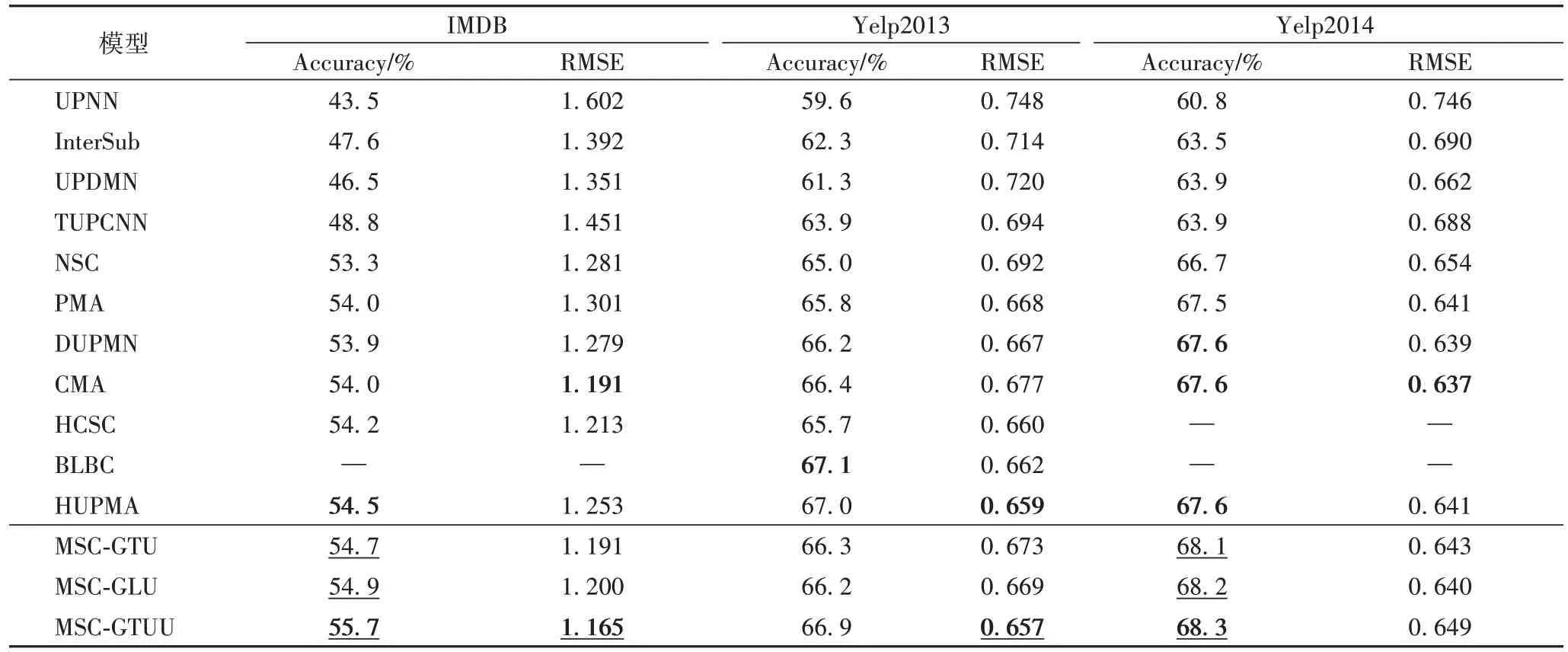
表2 不同模型的准确率和RMSE对比Tab.2 Comparison of accuracy and RMSE among different models
本文提出的模型为MSC-{GTU,GLU,GTUU},其中MSC代表多尺度卷积,NoGate 表示门控层不使用门控单元,NoMSC 表示去掉多尺度卷积层,no up 表示不融合用户产品信息到模型中。GTU 和GLU 代表Yann 等提出的两种门控单元,GTUU 代表本文提出的门控单元。本文分别在门控层使用这三种不同的门控单元做对比实验。
由表2可以看出,MSC-GTU 和MSC-GLU 在IMDB 和Yelp2014 上的准确率都超越了基准模型中性能最好的那个:MSC-GTU 分别提高了0.2 和0.5 个百分点,MSC-GLU 分别提高了0.4 和0.6 个百分点。相比MSC-NoGate,MSC-GTU 在Yelp2013 和Yelp2014 数据集上的准确率均提高了0.2 个百分点;MSC-GLU 在IMDB、Yelp2013 和Yelp2014 数据集的准确率分别提高了0.2 个百分点、0.1 个百分点、0.3 个百分点;MSC-GTUU 在IMDB、Yelp2013 和Yelp2014 数据集的准确率分别提高了1.0 个百分点、0.8 个百分点和0.4 个百分点。验证了门控单元的引入有助于提高情感分析的性能。
表2 中,对比使用门控单元的模型在3 个数据集上所展示出的性能,使用本文提出的GTUU 门控单元的模型MSCGTUU 明显优于MSC-GTU 和MSC-GLU。相比MSC-GTU,MSC-GTUU 在IMDB、Yelp2013 和Yelp2014 数据集上的准确率分别提高了1.0 个百分点、0.6 个百分点和0.2 个百分点。相比MSC-GLU,MSC-GTUU 在IMDB、Yelp2013 和Yelp2014 数据集上的准确率分别提高了0.8 个百分点、0.7 个百分点和0.1 个百分点。实验结果表明,在文档级情感分析中,本文提出的GTUU 门控单元更加有效。
GTUU 为梯度提供线性路径,同时保持非线性能力。对比基准模型,MSC-GTUU 在IMDB 和Yelp2014 上表现最佳。相比基准模型中最好性能的那个,MSC-GTUU 在IMDB 和Yelp2014 上的准确率分别提高了1.2 个百分点和0.7 个百分点,并且在IMDB 和Yelp2013 上获得了最小的RMSE。实验结果表明,本文模型可以更有效地进行文档级情感分类。
对比表3 可以看出,使用多尺度卷积编码的MSC-GTUU相比不使用多尺度卷积编码NoMSC-GTUU 在IMDB、Yelp2013 和Yelp2014 数据集的准确率分别提高了1.6 个百分点、1.1 个百分点、1.1 个百分点。由此可见,多尺度卷积对情感分类性能提升的有效性。

表3 多尺度卷积、门控单元和用户产品信息的消融实验Tab.3 Ablation experiment of multi-scale convolution,gating unit and user-product information
MSC-GTUU(no up)和MSC-GTUU 这两组对比实验结果表明,融合了用户产品信息的模型相比仅考虑评论文本信息的模型拥有更高的准确率。考虑了用户产品信息的模型MSC-GTUU 与不考虑用户产品信息的MSC-GTUU(no up)相比在IMDB 和Yelp2014 上的准确率分别提高了6.3 个百分点、3.0 个百分点、3.8 个百分点。说明了融合用户产品信息对文本情感分析的重要性。
同时为验证使用多尺度卷积联合编码的有效性,本文还在多尺度卷积层使用不同卷积滤波器做替代,并在IMDB 数据集上做对比实验,实验结果如表4所示。表4中,Conv(n)表示在多尺度卷积层使用卷积核大小和卷积步长为n的一维卷积滤波器提取相邻n个单词的语义信息作为一个情感语义单元,而Conv(a,b,c)表示同时使用3 个卷积宽度分别为a、b、c一维卷积滤波器提取不同尺度的信息对文本联合编码。
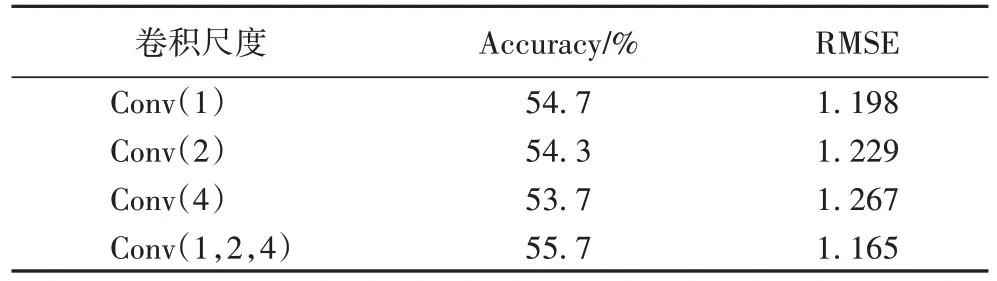
表4 不同卷积滤波器的实验结果对比Tab.4 Comparison of experimental results of different convolution filters
卷积层的卷积宽度将直接影响到注意力层对文档进行注意力计算的文本语义单元基本粒度(单词级或n元词组)。如表4 实验Conv(1)、Conv(2)和Conv(4)所示,在卷积层使用单个卷积波器情况下,随着卷积宽度的增大准确率不断下降。实验Conv(1,2,4)分别使用卷积核大小为1、2、4 的多尺度卷积联合编码方式相比对应单尺度编码中最好的词级编码实验Conv(1)准确率提升了1.0 个百分点,实验结果表明通过多尺度卷积生成不同粒度的丰富的文档表示对准确率提升的有效性。
3 结语
本文提出了一种基于多尺度卷积和门控机制的注意力情感分析网络模型。使用三个不同卷积大小的卷积层分别对文本信息进行建模,获得不同粒度的更丰富的上下文信息,再通过用户产品注意力选择与用户产品相关度较高的语义单元生成文档表示,引入门控机制到文档级情感分析中,并且提出了一个新的门控单元GTUU 取得了更好的性能。之后将考虑如何更好地使用用户产品信息去提高模型的泛化能力。
