小样本问题下培训弱教师网络的模型蒸馏模型
2022-09-25蔡淳豪李建良
蔡淳豪,李建良
(南京理工大学理学院,南京 210094)
0 引言
深度神经网络(Deep Neural Network,DNN)的训练需要在丰富且大量的数据集的前提下才能给出不错的模型,然而在实际工程中,由于内容保密、知识产权等原因,很难为大量数据标注信息,因此,在小样本问题下,如何训练得到高性能目标网络获得广泛关注,其本质上是如何在有限的数据中挖掘尽可能多的知识,以及如何将知识从外界和内部合理地传递给目标模型。
集成学习(Ensemble Learning,EL)作为一种有监督的学习算法,在处理小样本问题时,用Bootstrap 算法对数据集进行抽样间接解决这一问题[1];然而在组合阶段的堆叠泛化(Stacking)算法及logistic 回归组合策略并不能很好地挖掘多个教师模型内部的知识。
迁移学习作为一种网络训练算法,可以从优质网络迁移知识到目标网络中去,以此来改善结果并解决数据缺乏的问题[2]。迁移学习中最常见的做法是通过预训练结合微调算法得到目标模型,但是大规模细粒度蒸馏学习一文提出微调算法不能很好地解决语义相距很远的模型转换问题[3-4]。在此基础上FitNet 算法作为模型蒸馏的代表给出了一种教师培训计划以此将知识蒸馏到目标模型[5]。注意力蒸馏和Jacobian 匹配则从特征图和Jacobian 生成的注意力特征图着手来蒸馏源知识[6-7]。在此基础上,异构元学习模型蒸馏整合了从特征图蒸馏知识的算法,用外部网络增补数据集知识,元网络需提取知识与目标网络层对应关系[8]。
事实上,集成学习中有较高准确率的Boosting 算法会耗费较多的运算时间,组合阶段的Stacking 算法则依赖弱分类器的输出结果,没法真正学到分类器学习的知识,同时经组合后的模型过于庞大,很难在小型机上搭载。模型蒸馏在异构源和目标任务之间传递知识时会模糊原始数据包含的信息,尤其是当任务的输入域相似但实际任务有所不同时,此时外部信息补充的数据集缺失信息可能是无关甚至是负面的,因而不能很好地指导目标网络学习。
基于此,本文提出了一种小样本问题下培训弱教师网络的模型蒸馏。通过并行计算加快弱教师网络训练,通过压缩特征图的手段搜集浓缩知识,通过元网络以蒸馏的手段组合异构的弱教师网络。实验对象为小规模的鸟类数据集,实验结果在算法精度和算法速度上验证了本文算法的有效性和可用性;同时在相同数据集中数据减少的指标下验证了所提算法的有效性和鲁棒性。
1 针对小样本培训弱教师网络的算法
针对小样本问题,本文选择参考集成学习算法中Bootstrap 采样的思想,以此扩充数据集数量,解决数据量问题。
传统的集成学习算法主要有Boosting 及其相关的一系列改进算法,例如AdaBoost、梯度提升树等,也有可同时生成的并行式集成学习算法Bagging 算法。假定图像数据集X由数据{(xn,yn),n=1,2,…,N}构成,其中y是图像的分类标签,构成标签集Ψ={1,2,…,K}。假设用于这个数据集的分类器φ(x,X)。此时基于原始数据集X以重采样的方式构造一系列用于学习的数据子集为(k=1,2,…,κ),根据数据子集得到一系列分类器组{φ(x,)},故有:
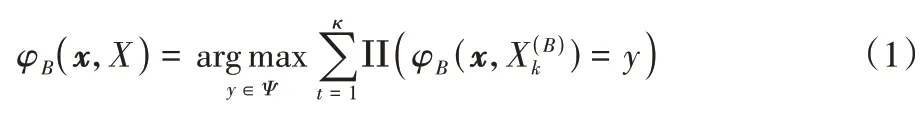

经典集成算法在处理小样本多分类问题时,由于选用Bootstrap 采样,很大程度上扩增了数据集的数据量,可以作为小样本问题的一种对策;同时在划分数据集时随机性的引入使得模型不易过拟合,也能较好地处理小样本多分类导致的输入数据高维度问题。集成算法中的Bagging 算法并行特性保证了模型训练的高效性。
在划分数据时,取值划分较多的属性会对弱学习器产生更大的影响,故弱学习器上的特征图不具有可信度。部分集成学习的弱学习器之间存在依赖关系,难以并行训练。在弱分类器选用上,选用具有低偏差高方差的线性模型或树模型;然而这些分类器在小样本多分类问题中,无法作出有效的判断。实验表明,在加利福尼亚理工学院鸟类数据库—2011(Caltech-UCSD Birds-200-2011,CUB200)上决策森林准确率只能在15.21%左右,说明这些弱学习器的分类结果不具有可信度,在后续聚合过程中,这些弱学习器提供的知识很难有效优化模型的训练。为了提高弱学习器在划分数据集上的准确率,本文选用浅层卷积网络作为弱分类器以改善集成效果。
2 多教师的模型蒸馏改进
小样本问题下,集成学习训练了大量弱分类器作为教师网络,这也意味着搜集了大量冗余的数据信息,此时需要对这些信息合并、筛选、传递,同时引入外部数据信息,弥补数据集不够丰富的缺陷。为了解决上述问题,有效控制目标网络的规模,本文改进了结合元学习的模型蒸馏。
2.1 经典模型蒸馏与元学习
传统模型蒸馏针对Softmax 层输出引入温度参数Tem获得新的软标签

来指导目标网络学习,指导算法是修改训练损失函数为:

其中:E为Softmax 层输出通道集的序号,Tem为给定温度,Ls为软标签损失,Lh为硬标签损失。
在此基础上异构元学习的蒸馏针对图像对象x在教师网络的中间特征图进行蒸馏学习,设教师网络的第m层特征图为Sm(x),目标网络第n层特征图为(x),从而特征图区别表示为:

其中rθ为保证(x)与Sm(x)规模一致的线性变换。在学习过程中元网络φ用于自动比对层对间特征图区别,结合原始数据集的网络硬标签损失Λorg(θ|x,y)得到,元学习蒸馏的最终损失函数为:
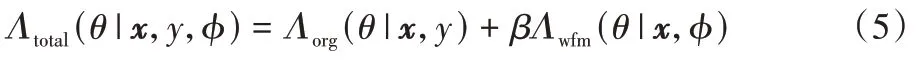
其中:β>0 是一个超参数,Λwfm(θ|x,φ)是由元网络φ测量得到的层对特征图损失。元学习蒸馏一定程度上关注了教师网络的卷积层知识,在文献[8]中给出了基于多个教师网络的实验过程,但是通过理论研究与实验表明,随着教师网络个数增加,元网络规模急剧上升,目标网络的训练任务量将会指数级上涨,故需要压缩提炼教师网络中的知识。
2.2 基于同构多教师模型的知识合并
由于第一阶段培训了大量相同结构的教师网络,设教师网络特征图输出层层数μmax,目标网络学习特征层层数νmax,在不考虑同一层特征图个数的情况下,此时元网络需要3μmaxνmax个需要在训练中同步优化的卷积模块,若教师网络为异构网络需要逐层特征图规模匹配。此时在教师网络特征图输出层数不变,只增加教师网络的情况下,元网络的规模会成倍增长,从而大幅增加训练的难度和时间损耗,设共有J个教师网络,则元网络需要3J μmaxνmax个需要在训练中同步优化的卷积模块,这在现实工程中是不合理的。因此需要对特征图进行聚合,设在具有相同体系结构A的J个预训练教师网络的集合中,每个教师网络Aj从事Dj个不同的任务,其中Dj≥1,意味着教师可以处于单个或多个任务的体系结构中。对于有Dj个任务的教师网络Aj,给定输入图像x,可以将Dj任务的输出定义为=Aj(x,θstu,j)。对于每个教师网络,将层定义为最小单位,将该网络表示为B个层的堆栈Aj=和最后几个全连接的层。从每个层输出的特征图可以定义为:
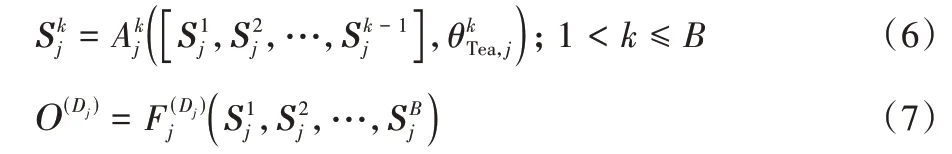
其中:S1=A(x,),以原始图像为输入,Sk为第k层所有教师网络特征图集合,故中间特征图集合S={S1,S2,…,SB}包含所有要为目标网络合并的知识。如果只选择一部分任务,则SB不能直接用作指导,因为未选择任务的知识无差别地纠缠在一起,会污染原始任务,而全部使用会大幅增加网络训练的规模和时长。
此时将特征图{S1,S2,…,SB}经合网络h合并得组合特征图H={H1,H2,…,HB}=h(S,Θ),要求中间特征图能很好地保留原始图像的信息,那么损失函数可以写成:

其中:‖Sk‖是特征图Sk的空间大小;ek是使得原始图像x与中间特征图相同尺寸的糊化操作,通过最小化特征图组合和原始图像的区别,来确定特征图组合过程中的权重。如图1 所示,特征图经过合并后保留了较为完整的信息。从过程可以看出,此算法大幅减少了蒸馏过程中需要学习的知识量,不过需要对整合后的知识进行不同于元学习的蒸馏方式。

图1 弱教师模型特征图合并过程Fig.1 Merging process of weak teacher model feature maps
2.3 基于组合特征图的元模型蒸馏改进
由2.1 节对于弱教师网络的改进,对于有Dj个任务的教师网络Aj,用损失更新网络Aj的参数,其中l是网络Aj中每个任务的交叉熵损失,而和分别保留了第i个任务的原来和预测标签,使用该损失函数对网络进行预训练可以获得参数θ。
集成算法在结果结合时使用Stacking 算法对应的训练集只与预测集合相关,缺乏对弱分类器的知识挖掘,降低了算法的准确率与泛化性,同时作为堆叠算法大幅增加了算法的存储空间;所以根据改进模型蒸馏得到的组合特征图H={H1,H2,…,HB},改用模型蒸馏将组合特征图知识蒸馏进目标网络。
设Hm(x)为图像x在组合特征图集的第m层的中间特征图,目标网络Tθ以θ为参数,设(x)为中间目标网络第n层的特征图:

其中rθ是由θ参数化的线性变换,由式(10)得到了衡量组合特征图与目标网络特征图差距的损失函数:

其中Im(x)为图像x在高性能网络的第m层的中间特征图。线性变换rθ1可以重新定义与训练,考虑到作用目标都是目标网络的特征图,为了保证结果收敛,同时为了简化运算加快知识蒸馏速度,可以取定值或与细节蒸馏一致,本文按照rθ1进行推导。
为量化层对间的蒸馏量,在每对(m,n)引入一个可学习的参数λm,n≥0。将每对(m,n)的λm,n=(Hm(x))设置为元网络gm,n的输出,该网络会自动决定学习目标任务的重要层对。给定组合特征图的给定通道w的权重和匹配对λ的权重的总传输损失为:
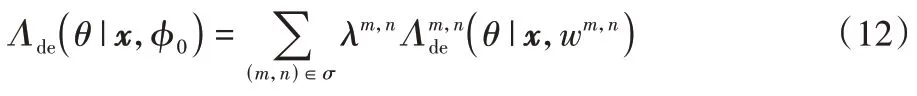
其中σ是一组候选对。同样可以定义,对于高性能外部网络的蒸馏损失:

其中:Λorg是原始损失;β、γ是超参数,当不需要外部知识时γ=0。wm,n和λm,n分别表示特征图知识蒸馏来源和量级。所以整体蒸馏过程思路简化如图2 所示,即将组合特征图集与目标网络特征图比对设置损失函数,以此训练网络,元网络的作用在于协同比对特征图尺寸,输出影响权重。

图2 基于组合特征图的元网络蒸馏模型架构Fig.2 Meta-network distillation model architecture based on combined feature maps
当使用训练目标Λtotal(·|x,y,φ,φ1)学习目标模型时,由于元网络通过正则化项Λde与Λwfm对目标模型的学习过程产生了微弱的影响,因此它们对Λorg的影响可能很小,从而内部循环迭代Tc再次使用梯度∇φ Λorg更新φ。此时优化的方案变为:1)Tc0次更新θ以使得Λde(θ|x,φ)最小;2)Tc1次更新θ以使得Λwfm(θ|x,φ1)最小;3)更新θ以最小化Λorg(θ|x,y)一次;4)计算Λorg(θ|x,y)并更新φ与φ1以将其最小化。
3 数值实验与分析
3.1 数据集、实验环境及训练细节
本文验证了对数据重采样再划分,以训练教师网络的可行性,也可用于异构网络任务的实现优化。由于Stacking 步骤运用的是蒸馏思想,最初弱分类器的训练要求不需要很高,但速度要求相对明显,所以选用可以并行运算的Bagging算法训练弱学习器。在实验过程中使用自适应时刻估计算法(Adaptive Moment Estimation,Adam)更新参数。
本文所有实验基于2660ti 显卡Intel Core i7-9750H CPU 2.60 GHz,16.0 GB 内存,6.0 GB 显存基础上,在python3.7环境下运用pytorch 开源包实现,加速库为计算机统一设备架 构 10.1(Computer Unified Device Architecture 10.1,CUDA10.1)。为了评估本文算法,在图片规模为224 × 224的小样本鸟类数据集CUB200 上进行实验,CUB200 数据集共有11 788 幅鸟类图像,包含200 类鸟类子类,其中训练数据集有5 994 幅图像,测试集有5 794 幅图像,可以作为小样本的代表测试本文算法的效果。为了横向对比小样本条件下本文算法改进的程度,选用图片规模为32 × 32 的CIFAR-10(Canadian Institute For Advanced Research-10)图像数据集,共10 个类,每个类别有6 000 幅图像数据,数据集中一共有50 000 幅训练图片和10 000 幅测试图片。在此基础上对CIFAR-10 每个类别进行按比例删减训练集图片,以此横向对比算法效果。
本文实验选用的弱分类器是结合ImageNet[9]数据集训练出来的20个18层残差网络(Residual Network,ResNet)[10],外部网络选用的是基于pytorch 的model_zoo 中的预训练网络,考虑到实验效率,选用的目标网络也是相同的ResNet18,异构网络在训练思路上是一致的。
训练时,首先将数据用Bootstrap 算法进行扩充再随机划分,并训练出弱教师网络;然后冻结教师网络的权重,输入图像数据,获取教师网络中间特征图信息,训练合网络参数;再冻结合网络参数,根据合网络输出训练元网络和目标网络。实验过程中,所有模型及弱教师网络的参数中初始学习率lr和权重损失wd分别设为0.1 和0.000 1,动量初始化为0.9,batch size 统一为32。其他超参数的设置如表1 所示,其中:J为教师网络个数,Tc0为细节损失更新次数,Tc1为外部损失更新次数,β、γ为损失函数中超参数。

表1 不同模型在CUB200数据集上的超参数设置Tab.1 Hyperparameter settings of different models on CUB200 dataset
对于有元网络的实验,将元网络构建为η层的全连接网络,η参数参考表1,元网络以教师网络第m层的全局平均池化特征作为输入,经全连接和Softmax 层后输出和λm,n。元网络的初始学习率和权重损失都设为0.000 1,元网络偏置项初始化为1,元网络采用Adam 优化器进行优化。
3.2 目标任务的评估分析
在教师网络阶段,选用的ResNet 作为教师网络相较于决策森林在准确率上提高了26.32%。蒸馏结果如表2 所示,在CUB200 数据集上,与第2 个最佳的元学习模型相比获得了6.39%的相对改进,而不引入外部知识时,相对不引入外部分网络的经典蒸馏算法,能有10.22%的准确率提升,说明保留细节知识能有效改善学习准确率和泛化性,验证了蒸馏的有效性。同时对比是否引入外部教师网络的实验,可以得出当引入外部知识时能更好地丰富原有数据集缺乏的细节知识。
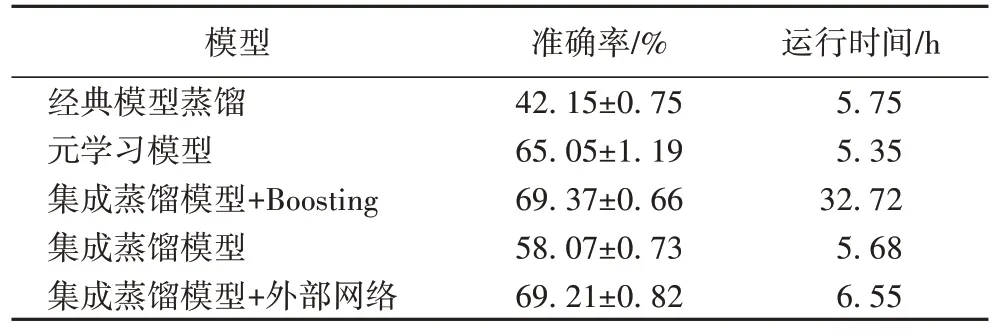
表2 不同模型在CUB200数据集上的准确率及运算时间对比Tab.2 Accuracy and computing time comparison of different models on CUB200 dataset
在算法速度上,弱学习器生成算法部分选用Boosting 获得弱学习器的算法时间长达32.72 h,而Bagging 算法平均生成时间在5.68 h 左右,对比网络生成速率提升了4.76 倍,时间约等于1/J的Boosting 算法时间,极大地缩短了目标网络的构建时间。在准确率上,Boosting算法聚合蒸馏的结果准确率为69.37%,改进仅0.16个百分点,可以算作网络训练误差。
本文模型将知识从子模型抽取再整合蒸馏到目标模型中,由于弱分类器有较好的表现,网络在前期训练过程中改进速度相对较快,如图3 所示,在前期损失函数下降速度比基线算法更快,后期改进则变缓趋于极限,验证了本文模型模块化分步进行的可行性。

图3 训练过程中集成蒸馏模型与元学习模型损失函数下降情况Fig.3 Loss function reduction situations of ensemble distillation model and meta-learning model in training process
3.3 小样本条件下模型效果分析
为了充分评估小样本条件下本文集成蒸馏模型的有效性与实用性,选用相同的图像数据集CIFAR-10,通过等比例缩减每一类训练数据的方式模拟小样本问题的情形,以此对比不同算法在不同数据量时候的效果。本文分别对比每个类别{100,200,400,700,1 000}个样本时,经典模型、注意力模型、元学习模型以及集成蒸馏模型的准确率。
实验结果如表3 所示,从数据可以发现当样本数据量越少,模型蒸馏相对经典模型具有越大幅度的改进,随着样本数据量的提升,所有模型准确率都在提升,但是模型蒸馏改进幅度逐渐减缓,这在逻辑上合理,符合当数据量足够时模型准确率趋于模型上限的假设。实验验证了当数据集的规模较小时,集成蒸馏模型有更大的改进,在规模变大时依旧保留很好的适用性。这说明模型蒸馏能有效处理小样本问题,同时面对较丰富数据量时也有比较好的表现。

表3 不同模型在CIFAR-10数据集的不同规模图像上的准确率单位:%Tab.3 Accuracies of different models on CIFAR-10 dataset’s images with different scales unit:%
3.4 模型特征图显著性分析
比较显著性图[11]即源和目标模型的最后一层之间的未加权和加权匹配,以此可视化知识蒸馏中使用的注意力图变化,这有助于了解蒸馏过程中的传输内容。显著性图如式(15)计算:

其中x是图像,c是图像的某个通道,(i,j) ∈{1,2,…,H}×{1,2,…,W}是像素位置。
图4 展示了目标网络训练中特征图对网络训练的指导作用,可以看出组合网络特征图第4 层输出图像对目标网络各层的训练都有相对显著的影响,其他各层间影响较小。
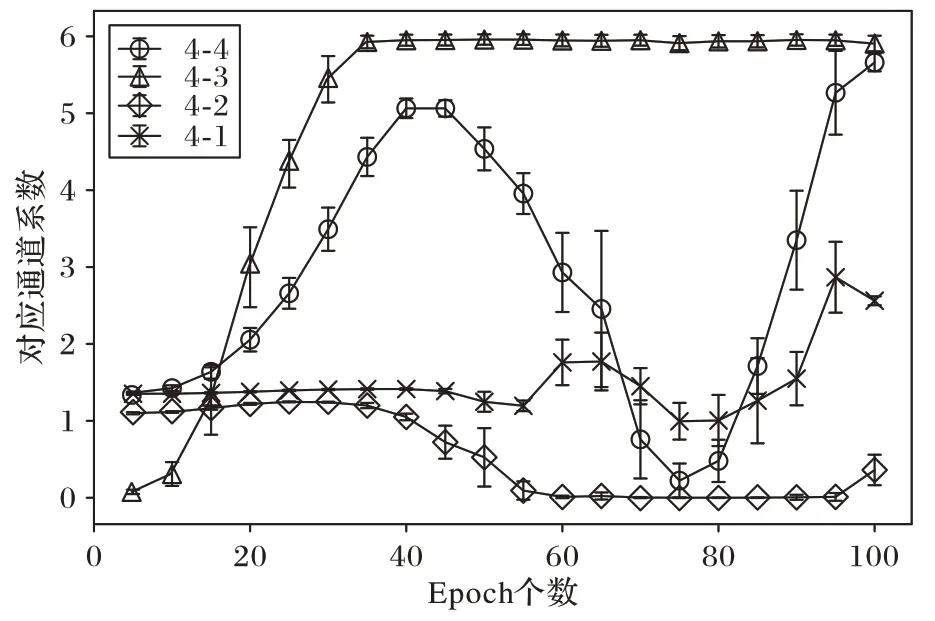
图4 弱分类器第4层对目标网络影响权重变化Fig.4 Influence weight change of the fourth layer of weak classifier on target network
对于未加权的情况,使用统一的权重,对于加权情况则使用训练方案学习的元网络的输出wm,n=(Sm(x))。为了有效对比激活像素数目,定义显著图像素点绝对值大于像素图均值的为有效像素点,有效像素点与全显著图像素个数比值为有效像素比,图5 为激活像素展示图,对比统计数据图为图6。
图5 显示了与元学习模型相比,本文集成蒸馏模型的显著图在关注重点处有更多更集中的激活像素。如图6 所示,当使用集成蒸馏模型时,包含任务特定对象的有效像素较多,而背景无效像素较少,纵向对比,总图像87.31%的图像,就显著图的有效像素比指标,集成蒸馏模型比元学习更高。这意味着权重wm,n学习到源模型特定于任务的知识,因此它可以改善蒸馏学习的效果。

图5 CUB200数据集上不同模型的激活像素Fig.5 Active pixels of different models on CUB200 dataset
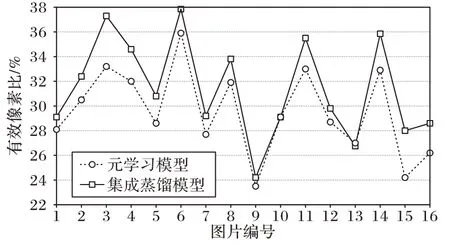
图6 一个batch内显著图有效激活像素比Fig.6 Proportion of effective active pixels in saliency map within a batch
4 结语
本文提出了一种小样本问题下培训弱教师网络的模型蒸馏模型,根据任务和架构选择性地传输知识。本文设计了一个有效的学习方案,包括提取细节、整合细节、细节传输的步骤。通过上述步骤,借助细节特征图和蒸馏元网络实现目标网络的高精度。在此基础上,借助元网络来进行数据划分、数据合并甚至最后贯穿整个目标网络训练过程是继续研究的一个方向;另外,依靠元网络来进行对目标网络的训练给出可靠的逻辑解释是未来可解释性研究的另一思路。本文算法几乎在每一步都给出了最优方向,同时每一步可分割进行,这指向了模型蒸馏的一个方向,即模块化蒸馏。
