基于聚类粒化和簇间散度的属性约简算法
2022-09-25范斌郭劼
李 艳,范斌,郭劼
(1.河北大学数学与信息科学学院,河北保定 071002;2.河北省机器学习与计算智能重点实验室(河北大学),河北保定 071002;3.北京师范大学珠海校区应用数学与交叉科学研究中心,广东珠海 519087)
0 引言
粗糙集理论[1-2]在数据挖掘、决策分析、人工智能等领域受到广泛关注,该理论基于等价关系建立了信息系统的属性约简策略,即利用两个精确的集合(上下近似)对不确定概念进行刻画,在保持信息系统分类能力的前提下尽可能地去除冗余特征,提取数据中最重要的信息,从而达到知识发现和进行决策支持的目的。
传统粗糙集约简方法是基于等价关系建立的,因此仅能处理符号值数据,但实际应用问题中连续值数据是广泛存在的,而将连续值数据离散化可能会导致信息丢失,且不同的离散化策略会影响属性约简效果。许多学者对Pawlak 粗糙集模型进行了改进:一方面利用模糊性,将数据集进行模糊化处理,提出相应的模糊粗糙集模型。如Zhang 等[3]利用信息熵理论提出了一种特征选择方法,此方法基于模糊粗糙集,对原粗糙集模型进行了改进;Yang 等[4]考虑了模糊粗糙集与三支决策的组合形式,从三支决策角度构建了鲁棒模糊粗糙集模型;Xiong 等[5]利用实例间相关性来挖掘隐藏的标签相关性,提出了一种基于模糊互信息与标签分布的特征选择算法;Sang 等[6]利用模糊优势邻域粗糙集对动态区间值有序数据进行了研究,提出了增量特征选择方法;Yuan 等[7]针对无监督混合数据集难以进行属性约简的问题,基于模糊粗糙集模型提出了一种属性约简算法。另一方面,从等价关系角度进行改进。对于有序关系的数据,Greco 等[8]首先提出用优势关系代替传统粗糙集中的等价关系处理带有序关系的连续值数据集;Huang 等[9]对优势粗糙集模型进行了扩展,提出了处理复合有序数据的动态优势粗糙集方法;Ahmad等[10]优化了计算基于优势的粗糙集近似的方法;Palangetic等[11]对基于优势度的粗糙集方法进行了模糊扩展。许多研究工作采用了优势关系粗糙集模型来处理连续值数据,但实际问题数据中,连续值属性的取值是否具有序关系有时并不明显,而使用优势关系来刻画本身没有序关系的连续值数据会一定程度歪曲数据本身的含义。Hu 等[12]基于邻域关系提出了邻域粗糙集模型,成为粗糙集框架下处理连续值数据的主要模型之一,该模型通过邻域描述样本的相似关系,并可通过调节邻域半径参数对论域形成不同粒化程度的覆盖。在Hu 等研究的基础上发展出许多基于邻域粗糙集的属性约简方法,如Wang 等[13]提出邻域区分指数作为评估函数,用以代替邻域粗糙集中的信息熵,设计了特征选择算法;姚晟等[14]针对属性约简方法的单调性缺陷提出了基于邻域粗糙互信息熵的非单调属性约简算法;郑文彬等[15]设计了基于属性重要度的变精度邻域粗糙集属性约简算法;刘丹等[16]提出了不完备邻域多粒度决策理论粗糙集与三支决策模型。虽然邻域关系可以通过调整邻域半径在多粒度视角下建模,但是由于连续值数据各属性值量纲不同导致半径难以统一,并且半径参数为连续值,理论上有无数种取值,整个参数粒化过程计算量较大。针对参数粒化过程,吴将等[17]从连续参数区间视角下对多粒度属性约简进行了研究。
以上研究中,不同的二元关系下产生了不同种类的信息粒,如等价类、模糊等价类、优势类、邻域类。在粒计算框架下,钱宇华[18]指出,聚类也是信息粒化的一种重要方式,聚类簇可形成对论域的划分,而且类簇和邻域本质上都是样本相似关系的体现,只是生成机制不同。在规模较大的连续值数据集上,相比要计算每个样本的邻域,类簇的数量一般会明显小于邻域的数量(即样本的数量),可在一定程度上降低计算的耗费。目前基于聚类粒化进行属性约简的工作尚不多见,主要困难在于难以确定基于类簇差异的辨识矩阵,此外,类簇的数目对粒化程度有着重要的影响。本文基于聚类来定义约简相关的一系列概念,进而建立一种新的约简策略,不同于基于优势关系与邻域关系的属性约简方法,聚类粒化属性约简方式不要求数据属性具有序关系,且能够在有限范围内离散地选取参数对论域形成粗细不同的多粒度划分,进而对数据集进行多粒度属性约简。具体来说,首先,利用k均值(k-means)聚类算法[19-20]将数据集通过调节聚类参数k得到类簇,定义基于聚类的近似集和正域等概念;然后,用JS(Jensen-Shannon)散度理论[21-23]对不同类簇属性的数据分布进行差异性度量,利用差异性结果挑选出区分两类簇的核心属性,由此定义了辨识矩阵[24]和属性重要性度量;最后,在此基础上设计了基于聚类粒化和簇间散度的属性约简算法。
1 基本概念
本章首先给出粗糙集理论[1-2]以及JS 散度[21-23]理论的一些相关概念。
1.1 基于等价关系的属性约简
定义1决策信息系统。决策信息系统也被称作决策表,可由四元组表示:

其中:U={x1,x2,…,xn}是包含若干对象xi的非空有限集,称为论域;C=A∪D是有限非空属性集合,A与D分别是条件属性集和决策属性集;多决策属性的决策信息系统可以转化为单决策属性决策信息系统,故本文仅以单决策属性的决策信息系统作为研究对象,即D={d};V是属性集对应的值域;f是一个信息函数,它指定U中每一个对象的属性值,即对xi∈U,a∈A,fa(xi) ∈Va,Va为属性a的值域。
定义2等价关系。定义S为决策信息系统,若条件属性子集Q⊆A,满足

称RQ为决策信息系统S定义在属性集Q上的等价关系。基于以上定义,记

为xi基于属性Q的等价类;称U/Q={[xi]Q|xi∈U}为论域U基于等价关系RQ的划分。
定义3上下近似集。对于任意目标概念X⊆U,定义X关于等价关系RQ的上近似和下近似为:


上下近似集分别代表确定属于和可能属于X的对象集合。
定义4相对正域。决策信息系统中,条件属性集A关于决策属性集D的正域定义为:

若基于条件属性集A所有等价类的对象均属于同一个决策类,意味着所有样本均属于正域,此时称该决策信息系统为一致的,否则称该决策信息系统为不一致的。
定义5正域约简。给定S为一个决策信息系统,对于∀Q⊆A,若Q满足以下两个条件,则称Q为A的正域约简:
1)POSQ(D)=POSA(D)。
2)∀a∈Q,(D) ≠POSA(D)。
定义6不一致决策信息系统及其可辨识矩阵。给定不一致决策信息系统S,U={x1,x2,…,xn},D={d},其可辨识矩阵定义为n×n的矩阵,记作M,矩阵元素mij定义为:

其中:w(xi,xj)={(xi,xj)|xi∈POSA(D) ∨xj∈POSA(D)}为正域约束集。
命题1 给定决策信息系统S,M是其可辨识矩阵,属性子集Q⊆A是该决策信息系统的正域约简当且仅当Q满足:
1)对任意非空元素m∈M,有m∩Q≠∅;
2)对∀a∈Q,∃m∈M使得m∩Q-{a}=∅。
由以上概念可以了解到,对于给定的决策信息系统,正域约简所保留的属性是能够维持正域不变的属性子集,可以在保留样本区分性的前提下最大限度地约简掉冗余属性。但这种约简建立在等价关系上,只能处理符号值数据。在连续值属性上,用基于相似性得到的若干类簇对论域形成划分后,如何衡量属性对不同样本的区分度是进行属性约简的关键问题。本文引入散度概念,提出利用散度理论定义不同类簇数据分布之间的差异性。
1.2 JS散度
JS 散度由KL(Kullback-Leibler)散度理论[25]衍生而来,KL 散度又被称作相对熵或信息散度,是由Kullback 等[25]提出用来衡量两个概率分布间差异的非对称性度量,信息论中相对熵等价于两个概率分布信息熵的差。相对熵常被应用于优化算法,通常表示使用理论分布拟合真实分布时产生的信息损耗。
定义7KL 散度。设P(x)、Q(x)分别是随机变量x数据的真实概率分布和理论概率分布,KL 散度定义为:
离散值随机变量:

连续值随机变量:

有时会将KL 散度称为KL 距离,但KL 散度并不满足距离的性质,其有两个特性:
1)KL 散度的非对称性:KL(A,B) ≠KL(B,A);
2)不满足三角不等式。
为解决KL 散度的非对称问题,有学者提出了JS 散度概念,JS 散度是基于KL 散度的变体,度量了两个概率分布的相似度,解决了KL 散度非对称问题,更适用于衡量两个数据分布的差异性。一般情况下JS 散度是对称的,其取值在0~1,定义如下:
定义8JS 散度。P(x),Q(x)分别是随机变量x的真实概率分布和理论概率分布,则JS 散度定义为:
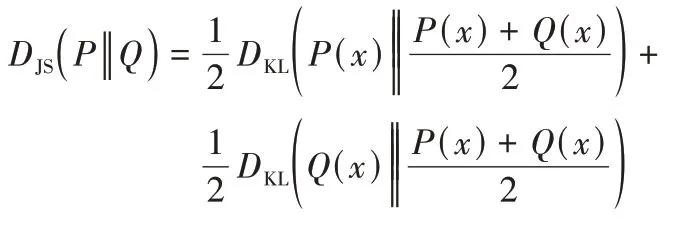
利用JS 散度衡量不同类簇间各属性上的数据分布差异,以此差异定义可辨识矩阵,矩阵中元素为导致两样本分属不同类簇的主要差异属性。特殊情形下,当两类簇数据完全没有交叠时,会导致JS 散度成为常数。实际数据中多维样本聚类后,生成类簇在所有属性上毫无交叠情况较少,当所有类簇数据都无交叠时可以考虑使用Wasserstein 散度[26]方法来度量两不同类簇数据的差异性。
2 基于聚类粒化与簇间散度属性约简算法
本章中提出一种基于聚类粒化和簇间散度的属性约简算 法(Attribute Reduction algorithm based on Cluster granulation and Divergence among clusters,ARCD)。考虑分类问题的数据集,将其类别标签看作决策属性,条件属性均为连续值,则此连续值数据集可被看作一个决策信息系统。
针对连续值数据集决策信息系统,首先利用k-means 聚类算法将其聚类。聚类本质上是将相似的样本聚成集合,若类簇内的对象均属于同一个决策类,意味着相似的样本决策相同,则称该决策信息系统为一致的,否则称该决策信息系统为不一致的。然后基于传统粗糙集理论用聚类得到的相似类替代等价类。在此基础上定义基于聚类的上下近似、相对正域以及正域约简概念。因为基于相似性且通过调整聚类参数k能对数据集形成不同粒化程度的划分结果,所以该算法不要求属性具有序关系,并且能在较小范围内选择离散的参数值k对连续值数据集进行多粒度属性约简。基于该思想定义以下相关概念。
2.1 相关概念
给定决策信息系统S,条件属性子集Q⊆A。将由Q组成的数据子集经k-means 算法聚类后生成的k个类簇记为LQ={C1,C2,…,Ck},其中Ci为k-means 聚类形成的第i个类簇。以下给出基于聚类的属性约简定义。
定义9基于聚类的近似集。给定决策信息系统S,属性子集Q⊆A,聚类后形成类簇集为LQ,给定目标概念X⊆U,定义X关于LQ的上下近似分别为:其中Cx即包含对象x的类簇。

定义10基于聚类的相对正域。在决策信息系统S中,给定目标概念X⊆U,条件属性集A聚类得到的类簇集为LA。基于聚类,条件属性集A关于决策属性集D的正域为:
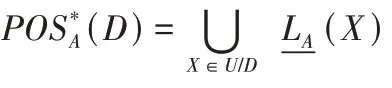
定义11基于聚类的正域约简。给定决策信息系统S,对于∀Q⊆A,若Q满足以下两个条件,则称Q为A的正域约简:

将类簇类比为传统粗糙集中的等价类,基于可辨识矩阵中元素存储的是不同决策类样本的区分属性(属性值不相等),将基于聚类的非一致决策信息系统可辨识矩阵元素定义为:导致两不同决策类样本分属不同类簇的主要差异属性集。由此上述约简也可方便地由以下定义求得。
定义12簇间属性上的JS 散度。给定决策信息系统S,论域U聚类后形成类簇集LA。令C(a)表示类簇C中所有样本在属性a上的取值,令P(Ci(a))、Q(Cj(a))表示任意类簇Ci、Cj中样本在属性a上取值的数据分布。簇间属性上的JS散度定义为:

定义13簇间属性平均JS 散度。根据式(1),给定数据集中条件属性集为A={a1,a2,…,al},A中共有l个属性,Ci、Cj簇间属性平均JS 散度定义为:

定义14簇间主要差异属性。根据式(2),设JS 散度差异性阈值为γ,不同类簇Ci、Cj的主要差异属性集定义为:

定义15基于聚类的非一致决策信息系统可辨识矩阵。根据式(3),给定非一致决策信息系统S,U={x1,x2,…,xn},D={d},论域U聚类后形成类簇集为LA。设样本xi、xj分属不同类簇Ck1、Ck2,JS 散度差异性阈值为γ,定义一个n×n的矩阵,记作M,第i行第j列矩阵元素mij定义为:

定义16基于聚类的变精度正域约简。给定决策信息系统S,论域U聚类后形成类簇集LQ,对于Q⊆A和变精度约简参数β∈[0,1],若POS(D)=POS(D)且任何Q的真子集均不满足此式。其中:
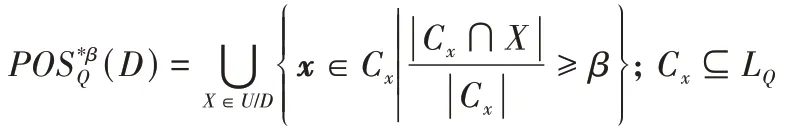
此时称Q为A的β-正域约简,变精度的引入使得模型对数据的不一致性具有一定程度的容忍性,增强了模型的容噪能力,(1 -β)即为可容忍误分率。β越接近于1,所得到的约简越接近严格正域约简。特别地,当β=1 时即为定义11 基于聚类的正域约简。
定义17基于聚类和信息增益的属性重要度。给定决策信息系统S,U={x1,x2,…,xn},D={d},决策属性集D等价划分后类别数定义为|D|,假定论域U中依决策属性第n类样本所占比例为pn(n=1,2,…,|D|),信息熵Ent(U) 定义如下:

一般而言,“信息增益”越大,意味着使用属性a来进行划分所获得到的“纯度提升”越大。
2.2 算法步骤
基于传统粗糙集理论和以上概念,可以建立基于聚类粒化和簇间散度的属性约简算法,具体步骤说明如下。
算法1 基于聚类粒化和簇间散度的属性约简算法。
输 入S=(U,C=A∪D,V,f);聚类数目k;变精度参数β。
输出 属性约简REDUCT。


步骤2)中使用k-means++聚类将数据聚类。这是由于k-means 算法在选择初始聚类中心存在不足,而k-means++算法能够选择尽可能分散的初始聚类中心点。由于采用可辨识矩阵来确定两样本分属不同类簇的差异属性,对于数据集U当聚类参数为k时算法时间复杂度为O(k2|U|2)。
3 实验与结果分析
为检验此约简算法的有效性,从UCI 数据库[27]与Kent Ridge 数据库[28]中选取了14 个连续值数据集进行实验,表1列出了数据集的详细信息,其中条件属性个数最多达7 129,样例数最多为10 000。
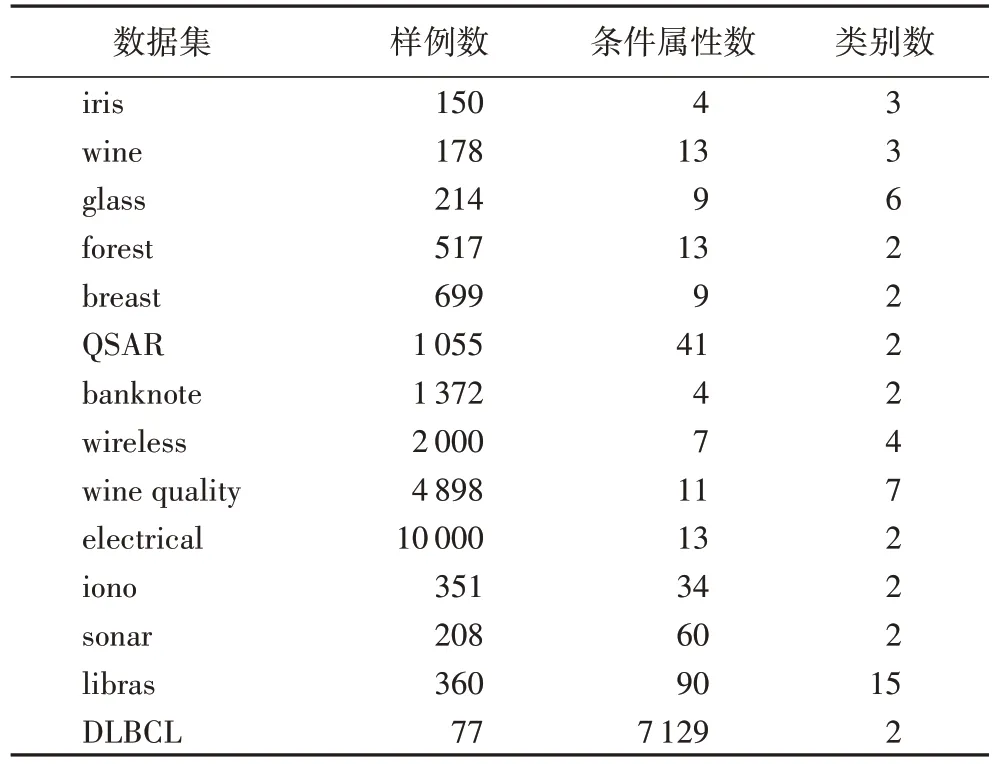
表1 实验数据集Tab.1 Experimental datasets
表1 实验数据均为连续值数据集,为消除各属性量纲对约简结果的影响,在实验之前对数据集进行了归一化处理。由第2 章中定义,得到实验数据集基于本文算法ARCD 的属性约简集,并与基于优势关系与邻域关系的属性约简算法结果进行对比。选取的4 种代表性对比算法为:1)基于优势关系的多准则决策分析粗糙集(Dominance-based Rough Sets theory for multicriteria decision analysis,DRS)算法[8];2)基于邻域粗糙集的特征选择(Neighborhood Rough Set based heterogeneous feature subset selection,NRS)算法[12];3)基于邻域粗糙互信息熵的非单调属性约简(non-monotonic attribute reduction based on Neighborhood Rough Mutual Information Entropy,NRMIE)算法[14];4)基于邻域区分指数的特征选择(Heuristic Algorithm based on Neighborhood Discrimination Index,HANDI)算法[13]。
实验过程中所有算法均通过python3.7 编程实现,实验运行的硬件环境为Intel Core i7-9750H CPU 和32 GB RAM。本实验共分为5 部分:第1 部分为上述5 种算法的约简结果比较;第2 部分对比了5 种算法所得最佳特征子集的约简率;第3 部分比较分析了5 种算法所得约简结果的分类精度;第4 部分比较了各算法计算约简结果的时间;最后将ARCD 中聚类参数k与散度阈值γ对约简结果的影响进行了分析与探讨。
3.1 约简结果比较
实验设置:NRS、NRMIE 和HANDI 三种算法都涉及邻域半径参数的选取,本文ARCD 粒化参数k为离散整数值。为权衡参数优化和计算量,体现ARCD 在较低代价下选取参数的高效性,实验中定义邻域半径δ=Δmin+h(Δmax-Δmin),其中h∈[0,1],Δmin表示数据集所有对象之间距离的最小值,Δmax表示数据集所有对象间的距离最大值;h初始值定义为0.01,其余取值以0.05 的整数倍变化。对于本文算法ARCD,聚类参数k∈[2,20]以步长为1 进行变化。通过调节粒化参数对数据集进行实验,得到了各参数对应的属性约简结果。每种算法统一以在4 种分类器上分类精度都较高时的约简集作为最佳约简结果。
表2、3 分别展示了ARCD 和其他4 种对比算法的最终约简结果,约简集中的序号表示相应数据集中属性所对应的标号。表2 中最后一列表示最佳约简结果的聚类参数k。

表2 ARCD属性约简结果Tab.2 ARCD attribute reduction results
对比表2、3 看出,ARCD 在iris 与banknote 数据集上约简结果与NRS 算法约简结果相同,在banknote、electrical 数据集上与HANDI 算法约简结果相同。当条件属性较少时ARCD在个别数据集上所选择的特征实际上是DRS 或NRS 算法约简结果的子集,例如glass 与electrical 数据集。这说明在某些低维数据集上相较于DRS 与NRS 算法,ARCD 有能力去除更多的冗余特征。另外可以发现在其他低维数据集上ARCD所选特征大多为DRS、NRS、NRMIE、HANDI 算法约简结果子集的并集。例如wine、breast、wireless、wine quality 数据集。原因可能在于ARCD 基于聚类粒化方式,通过k调节粒度粗细对数据集进行划分,具有获得更多特征组合的可能性。随着条件属性增多ARCD 约简结果的规模也在逐渐增大。特别地,在数据集DLBCL 上,由于该数据集属性维度为7 129,可能存在较多数量的约简集可以选择,因此ARCD 与其他算法的约简结果中没有出现共同属性。除DLBCL 数据集外在iono、sonar、libras 数据集上与其他4 种算法对比,虽然获得的约简集不同,但约简结果中始终存在着共同特征。所选特征子集之间的差异性表明:对于给定的分类任务,有多种特征组合具有可接受的分类能力。
3.2 约简率比较
本节中比较了ARCD 与对比算法的约简率,计算公式为:约简率=[(|A| -|REDUCT|)/|A|]× 100%。约简率越高表示去除冗余属性的能力越好,约简后需要的存储空间也越小。各个数据集在5 种算法中的最优约简率以黑体标注。从表4 所列出的结果可以看出,在14 个数据集上ARCD 的平均约简率明显高于其他4 种对比算法,达到了67.70%;其次是NRS,为60.02%。从约简集中平均属性个数上看,ARCD略高于NRS(相差0.72),基本持平,但明显少于DRS、NRMIE、HANDI 所得约简集中属性的数目。具体到每个数据,ARCD 在7 个数据集上获得了最高的约简率,其次是NRS和HANDI 分别在5 个数据集上有最高约简率。显示出所提出的ARCD 有较强的属性约简能力。
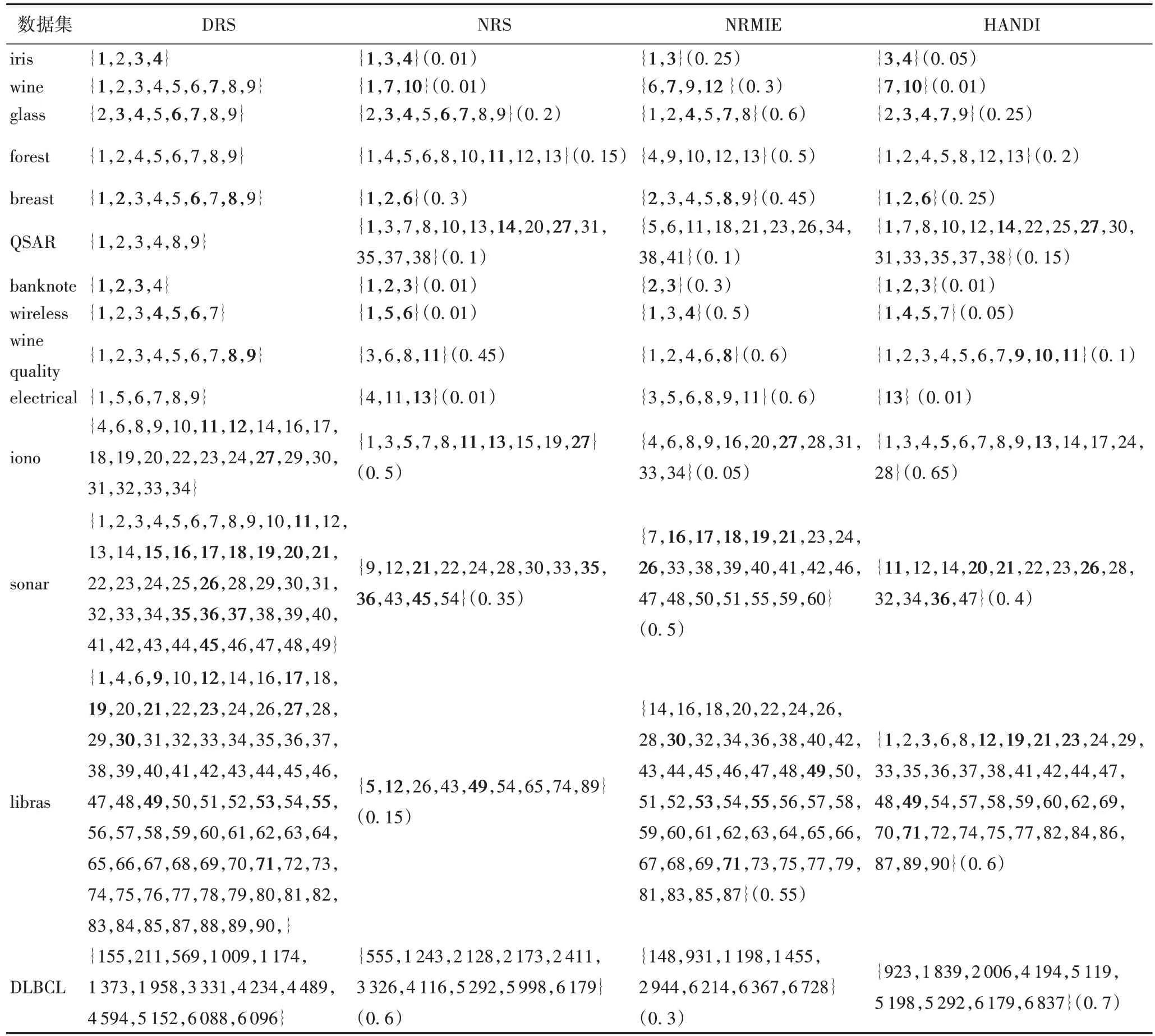
表3 各算法的属性约简结果对比Tab.3 Attribute reduction results comparision of different algorithms

表4 各算法约简结果的属性个数与约简率对比Tab.4 Comparison of attribute number and reduction rate of reduction results by different algorithms
3.3 分类精度对比
本节比较了5 种算法在各数据集上约简结果的分类精度,即对约简后的数据集进行分类,分类精度可以用来体现约简效果。实验中采用了4 种常见分类器分别为:决策树(Decision Tree)、K近邻(K-Nearest Neighbors,KNN)、支持向量 机(Support Vector Machine,SVM)、神经网络(Neural Network),其中神经网络分类器为多层感知机。以上分类器均通过交叉验证的网格搜索方式拟合参数。各数据集获得最终特征子集后用上述4 种分类器通过设置训练数据与测试数据进行10 次十折交叉验证计算得到分类精度,如表5~8所示。每个表记录了各约简算法所得最佳特征子集使用同一种分类器计算出的分类精度结果,最后一行是平均值,其中“原始属性”指没有经过属性约简的原始数据集。在每个表中,分类精度都以“均值±标准差”的形式表示;各数据集在不同约简算法上获得的最优分类精度用黑体标注;表头各算法名称后面括号中的数字表示该算法在几个数据集上得到最佳分类精度,如使用KNN 分类器时,ARCD 在9 个数据集上取得了最好的精度。
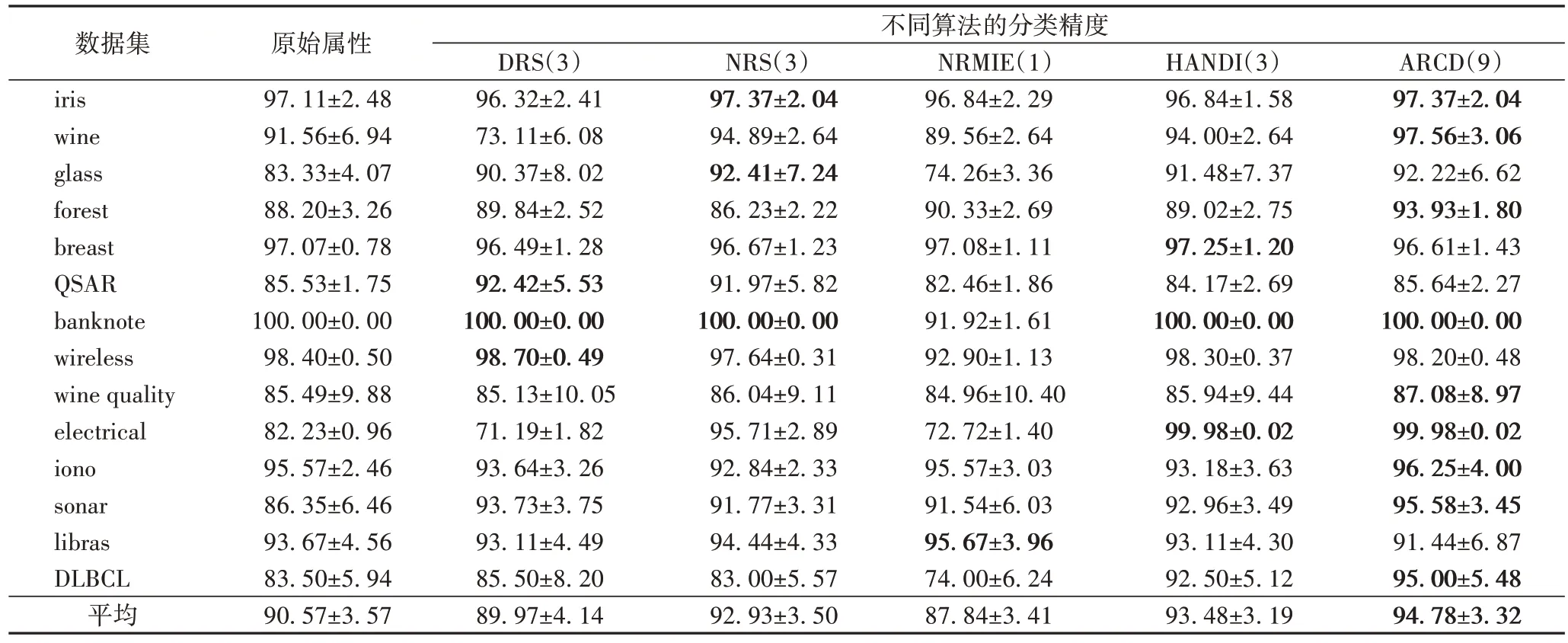
表5 基于KNN的约简分类精度比较 单位:%Tab.5 Comparison of classification accuracy of KNN based attribute reduction unit:%
从表5~8 可以看出,在4 种分类器的结果中都显示ARCD 在14 个数据集上的平均精度均优于其他对比约简算法。而且,从取得最优精度的数据集个数上看,ARCD 是最多的,除了在Decision Tree 分类器结果中有7 个数据集外,其余3 种分类算法上都是在9 个数据集上取得最优分类精度。可见,在多数连续值数据集上利用ARCD 能够保持甚至提高分类精度的前提下去除冗余属性,具有较好的约简效果。更详细地,具体到每个数据集来看,相比其他4 种对比约简算法,ARCD 在数据集banknote 和electrical 上所选特征子集在4种不同分类算法上均取得了最高分类精度;在iris、wine、glass、forest、sonar、DLBCL 这6 个数据集上所得特征子集在3种分类器上取得最高分类精度。可见当数据集样本数较多(如electrical 数据)和维数较高(如DLBCL 数据)时,ARCD 仍可以取得较好的约简效果。

表6 基于Decision Tree的约简分类精度比较 单位:%Tab.6 Comparison of classification accuracy of Decision Tree based attribute reduction unit:%

表7 基于SVM的约简分类精度比较 单位:%Tab.7 Comparison of classification accuracy of SVM based attribute reduction unit:%
在平均精度和获得最优精度次数方面,表现次优的是NRS 和HANDI。当然,不同分类器也会影响具体的分类结果。在KNN、Decision Tree、Neural Network 分类器上,ARCD平均分类精度比NRS、HANDI 略高,最高提升了约2.0 个百分点;但在SVM 分类器上明显优于其他约简算法,精度比NRS 提升了约2.6 个百分点,比HANDI 提升了约5.3 个百分点。基于优势关系的DRS 约简算法表现排在NRS 和HANDI之后,分析其原因可能在于大部分连续值的条件属性相较于决策属性并不具有优势关系,即不一定有“某个条件属性值越大/小,则决策属性越大/小”这样的单调关系,这时如果基于优势关系去进行属性约简会引入不必要的序信息。而聚类算法本质上是基于相似性将特征空间中相似的对象归类,同一决策类中的样例大多具有较高的相似度,这对于大多数分类问题是合理的假设。另一方面,通过类簇数目k可以调节对论域划分的粗细,形成多个粒度空间,可以选择在合适的粒度下进行属性约简;而且,整数k的离散化择优相比连续值的邻域半径择优更加简单易行。通过对比可以发现NRMIE 算法表现不佳,可能因为该算法对参数取值较为敏感,在低代价下选择部分离散参数没有得到较好约简结果。
以上结果说明基于聚类粒化和簇间散度的属性约简算法能够直接处理不具有序关系的连续值数据集,用较低代价离散地调节参数便能在保持甚至提高分类精度的前提下去除数据集中的冗余特征,具有比较理想的效果。
3.4 运行时间比较
本节中将ARCD 与另外4 种对比算法运行时间进行了比较。最终运行时间结果由多次计算约简用时的平均值表示。由于在14 个数据集中更关注算法在规模与维度较高的数据集上的运行效率,因此从中选取了6 个数据集进行实验对比,结果用柱状图展示。因时间差异将其分为两组展示,其中图1 为libras、wireless、QSAR 数据集上的实验结果;图2 为wine quality、DLBCL、electrical 数据集上的实验结果;图3 为各算法在所选数据集上的平均运行时间对比。

图1 不同算法在libras、wireless、QSAR数据集上的运行时间对比Fig.1 Running time comparison of different algorithms on libras,wireless,QSAR datasets

图2 不同算法在wine quality、DLBCL、electrical数据集上的运行时间对比Fig.2 Running time comparison of different algorithms on wine quality,DLBCL,electrical datasets

图3 不同算法的平均运行时间对比Fig.3 Average running time comparison of different algorithms

表8 基于Neural Network的约简分类精度比较 单位:%Tab.8 Comparison of classification accuracy of Neural Network based attribute reduction unit:%
由图1、2 可以看出,基于优势关系粗糙集的约简算法随样本规模增大其运行时间也越来越长,在wine quality 和electrical 两个数据集上尤其明显。这是由于基于优势关系粗糙集不仅要遍历样本比较各属性上的取值并排序,计算样本所属优势类,还要计算优势关系下的可辨识矩阵。ARCD的运行时间与NRS、NRMIE、HANDI 在wireless、wine quality数据集上的运行时间基本持平;ARCD 与NRS、HANDI 运行时间在electrical 数据集上相近。这是由于在决策信息系统S中,NRS、NRMIE 与HANDI 算法时间复杂度为O(|A|2|U|2),聚类参数为k时ARCD 时间复杂度为O(k2|U|2)。当数据集属性数量较小时ARCD 运行时间与NRS、NRMIE、HANDI 算法差距不大,随着数据集属性数增多,ARCD 的运行时间相较于其中某些算法会更具优势。如ARCD 在QSAR 数据上远远低于NRS 和HANDI 所需时间;在libras 上与NRS、NRMIE相近但运行速度明显快于HANDI;在DLBCL 上所需时间与NRS 和HANDI 相近,但明显低于NRMIE,由图3 各算法平均运行时间对比结果可以看出ARCD 更具优势,相较于NRS 和HANDI 分别缩减了25.4%与32.3%。可以发现即使同为基于邻域关系的属性约简算法,在同一数据集上的约简时间也不尽相同,主要是由于各算法评估函数不同,基于熵与正域等方式获得不同长度的特征子集都会影响计算约简的时间。
3.5 聚类参数k的探究与分析
根据定义可知聚类参数k对本文算法有重要的影响,调节参数k能对论域形成不同粒化程度的划分,故本节将参数k与约简集的大小和分类精度之间的关系进行了探究与分析。参数k∈[2,20],并以步长为1 进行变化,调节k值得到多种粒度划分下的约简结果,在4 种分类器上对约简后的数据集分别计算分类精度。图4~9 所示的是部分数据集随k值变化所得的约简集大小(用Size 表示)和各分类器上的分类精度变化曲线。各数据集的最佳约简结果(4 种分类器计算精度都高)用红色虚线框标注。图10 为不同数据集上各k值对应所得约简集平均大小与各分类器平均分类精度变化曲线。

图4 k对结果的影响(wine数据集)Fig.4 Influence of k on results(wine dataset)

图5 k对结果的影响(forest数据集)Fig.5 Influence of k on results(forest dataset)
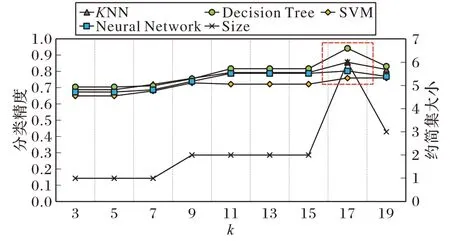
图6 k对结果的影响(QSAR数据集)Fig.6 Influence of k on results(QSAR dataset)

图7 k对结果的影响(wireless数据集)Fig.7 Influence of k on results(wireless dataset)
根据图4~10 数据集的实验结果可以看出:聚类参数k的取值从2~20 逐渐增大的过程中,约简集的大小总体上呈逐渐增大的趋势,这是由于聚类簇越多,对数据集的划分越细致,样本有更大可能被分到不同类簇中,从而导致最终结果可以吸收到更多的属性。综合图4~9 数据集的实验结果可以注意到在k∈[2,20]范围内,在不同数据集上运行ARCD都可以计算得出一个约简集小并且在多个分类器上分类精度较高的约简结果。另外,通过图10 可以看出KNN、Decision Tree 与Neural Network 分类器的分类精度结果随k值增大一开始逐渐上升随后变得稳定,而SVM 分类器所得分类精度随k值增大而升高后在小范围区间内波动。在k为10之前各分类器已经能够获得较高的分类精度,且分类精度不会随着k值增大而出现较大的增幅。这是因为在k值较小时ARCD 所计算的约简属性便具有较好的分类能力,随着聚类簇的增多,算法所计算的簇间区分属性逐渐饱和,分类精度不会出现明显提升。对于ARCD,在样本规模10 000 以内的数据集上,如果注重运行时间效率与约简率时可以将k值选定在[2,10]的范围内,可以有效降低调参的代价的同时获得可接受的分类效果;如果更关注分类精度结果则可以适当扩大范围来选择k值,通过调整参数k取得较优分类性能。

图8 k对结果的影响(electrical数据集)Fig.8 Influence of k on results(electrical dataset)
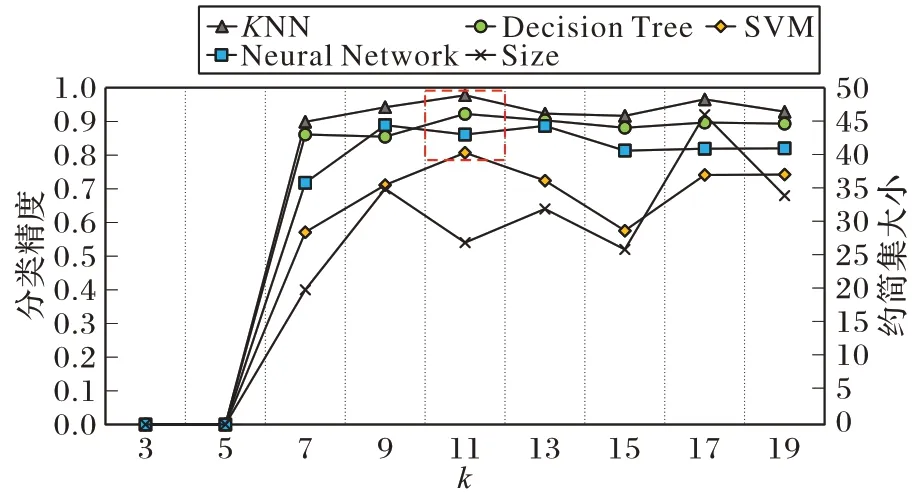
图9 k对结果的影响(libras数据集)Fig.9 Influence of k on results(libras dataset)

图10 平均分类精度、平均约简集大小随k值的变化Fig.10 Average classification accuracy and reduction set size varying with k value
3.6 阈值参数γ的探究与分析
除粒化参数k外,散度阈值参数γ的取值会决定一个属性是否具有足够的辨识能力,因此也是一个重要的参数。类似于3.5 节,本节选取了部分数据集,详细分析了不同参数值γ对约简集的大小和分类精度的影响。考虑到γ=1 所代表的含义是选择大于平均簇间散度的属性,故将γ设置在1左右范围内进行调整,观察对约简结果的影响。定义参数γ∈[0.8,1.4],以步长为0.05 进行变化,将k固定为各数据集对应的最佳值,对部分数据集绘制了随γ值变化所得的约简集大小和各分类器上的分类精度变化曲线,如图11~14。
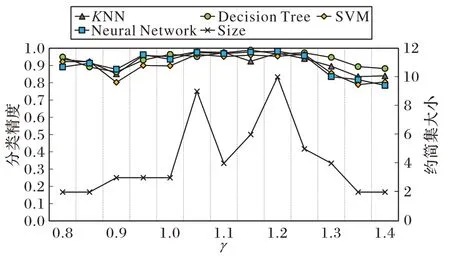
图11 γ对结果的影响(wine数据集)Fig.11 Influence of γ on wine dataset
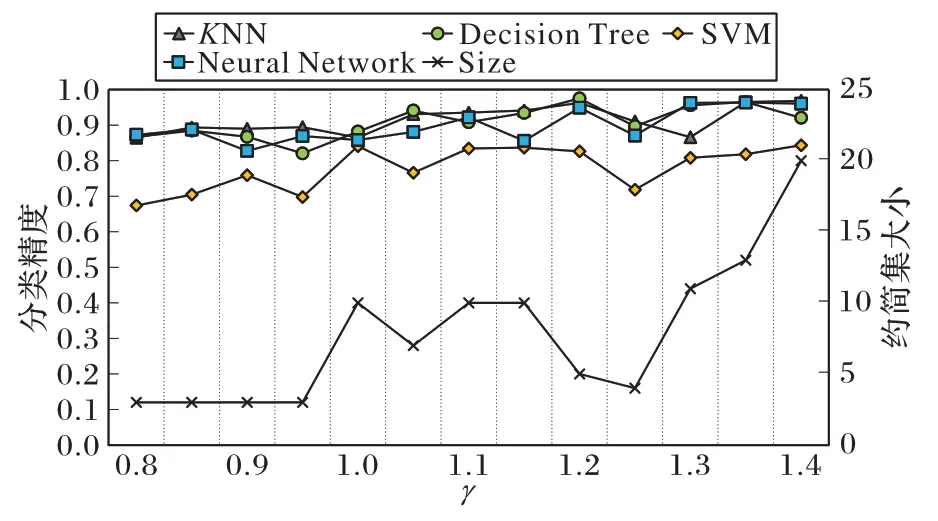
图12 γ对结果的影响(iono数据集)Fig.12 Influence of γ on iono dataset

图13 γ对结果的影响(sonar数据集)Fig.13 Influence of γ on sonar dataset
从图11~14 可以看出,随着γ取值的变化,KNN 与Decision Tree 分类器分类精度都处在高位且较为稳定,而SVM 与Neural Network 分类器对γ较为敏感,其分类精度会随γ值的变化在一定范围内波动。另外,不同于邻域粗糙集中属性重要度参数,γ值不直接决定约简集的大小,因为γ值仅决定获得两簇差异属性的比例,而这些差异属性是否普遍存在于任意两簇间才是影响最终约简结果的关键因素。可以注意到当γ值取到[1.1,1.3]区间内时会得到较为理想的约简结果,数据集约简后在4 种分类器上可达到较高精度且约简中属性个数可取到相对较低点,当然分类精度和约简率之间一般需要进行权衡。
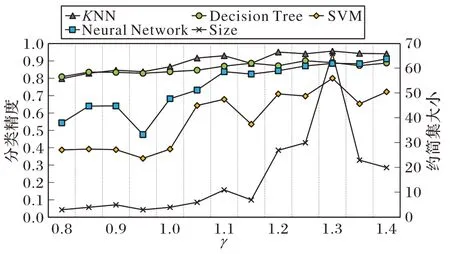
图14 γ对结果的影响(libras数据集)Fig.14 Influence of γon libras dataset
4 结语
在粗糙集框架下,基于聚类粒化方式将聚类算法生成的类簇看作基于相似关系的信息粒,用聚类类簇代替等价类定义了基于聚类的近似集、相对正域、正域约简、可辨识矩阵等概念,利用散度理论定义了不同类簇的主要差异属性等概念。由主要差异属性构造出可辨识矩阵,为处理连续值数据提出了一种基于聚类的属性约简算法,可通过调节粒化参数k在有限范围内离散地选取参数对论域形成多粒度划分,进而对数据集进行多粒度属性约简。本文算法ARCD 不要求连续值数据集属性具有序关系,同在较低代价下选取粒化参数时,相较于基于邻域关系的属性约简算法,ARCD 约简率与运行时间均具有优势,且所选特征子集在各分类器上平均分类精度都更高。在UCI 和Kent Ridge 数据库的14 个数据集上与基于优势关系和邻域关系的4 种代表性属性约简算法进行了实验对比,实验结果验证了本文算法的可行性与有效性,在多数数据集上的分类结果表明本文算法可以在维持原始分类能力的前提下,去除冗余属性,拥有较好的约简效果,将会对后续生成高质量的决策规则以及降低存储和算法运行时间耗费起到重要的作用。但注意到不同于等价类、优势类或邻域类,当属性由少增多时,类簇不能自然地由粗变细,而是通过控制k来生成不同大小的类簇。因为冗余属性的存在,可能会导致利用所有原始属性进行聚类不能完全反映对象之间的相似性,未来的工作将会考虑用更多聚类方法如(基于密度的聚类)研究不同属性子集上条件属性与决策之间的依赖度变化,从而进一步改善属性约简的效果。
