结合领域先验词汇的远程监督关系抽取模型
2022-09-07王会勇张晓明
王会勇 安 康 张晓明
(河北科技大学信息科学与工程学院 河北 石家庄 050000)
0 引 言
在领域知识图谱构建过程中,概念或实体间的关联关系发现是构建领域知识图谱的重要基础。但是,由于特定领域知识适用范围小、知识结构较复杂、专业性较强等领域因素,使得领域知识图谱构建难度较高,存在很多挑战,例如通用领域的关系抽取方法并不能完全适用于特定领域,数据标注过程人工参与程度较高。因此,针对特定领域的关系抽取研究具有重要的现实意义。
目前随着关系抽取任务的研究,常采用深度学习方法通过对文本特征的判断来进行关系分类,文本特征是关系抽取模型进行关系分类的重要特征。在关系抽取任务中,常通过改进模型来提取更多的特征信息,进而提高关系抽取效率,而且外部知识特征也逐渐被引入到关系抽取模型中辅助关系分类。例如Li等[1]提出了一种基于因果关系词汇的因果关系抽取模型,模型会将表达因果关系的词汇特征引入到卷积神经网络模型来辅助关系抽取任务,有效地利用先验词汇判别实体间的因果关系类别。因此,在特定领域中,基于外部知识的关系抽取模型可以充分利用领域知识和专家经验,为关系抽取提供丰富的先验特征,提高特定领域关系抽取的效率。而且在关系抽取研究中,常采用Mintz等[2]提出的远程监督方法,远程监督方法的自动标注数据能力可以减少大量人工标注的代价,为特定领域缺少标注数据的困难提供了解决方案。
因此,本文基于Li等[1]的方法提出了基于先验词汇的分段池化卷积神经网络模型K-PCNN,利用领域的关系先验词汇辅助关系分类任务,并在Li等提出的因果关系抽取模型的基础上拓展为多关系抽取。针对缺少标注数据的问题,采用了远程监督的方法进行关系数据自动标注。本文的主要贡献如下:
(1) 提出一种基于先验词汇的分段池化卷积神经网络模型K-PCNN。该模型在卷积神经网络中引入各类关系的先验词汇知识特征,利用先验词汇特征帮助模型判别关系类型,加强关系分类能力,以提高关系抽取性能。
(2) 提出一种基于远程监督的领域数据标注方法,利用领域三元组知识以及领域文本语料,基于远程监督的自动标注方法进行领域数据集构建,并且以金属材料领域为例,构建了金属材料领域关系抽取数据集MMRE。所提出的构建数据集的方案也可以应用到其他缺乏关系标注数据的特定领域中,用于关系抽取模型的训练和评估。
1 相关工作
1.1 关系抽取方法
关系抽取任务是构建知识图谱的重要环节,通过发现文本中实体对间的语义关系,为知识图谱提供关系特征。目前常用的关系抽取方法有监督学习方法、无监督学习方法和半监督学习方法。
监督学习方法采用了深度学习模型,将关系抽取任务作为关系分类任务,常用的模型如卷积神经网络模型[3-5]和循环神经网络模型[6-8]。无监督学习关系抽取方法是一种聚类方法,主要依据相同语义关系具有相同的上下文信息这一特征,通过上下文信息对实体关系进行聚类,例如Ma[9]采用了K-means聚类算法。半监督学习方法包含基于BootStrapping的方法和Mintz等[2]提出的远程监督方法。其中基于BootStrapping的方法是依赖人工标注好的种子实例和模板,然后迭代抽取关系模板和更多实例,例如Gupta等[10]提出了基于高置信度评估的BootStrapping方法;远程监督方法假设一个句子中若包含一类关系涉及的实体对,则该句可以作为此类关系的训练正例,这种自动标注方法大大减少了标注数据的人工成本,增加了大量的训练样本。
由于深度学习模型对于训练数据的依赖,关系抽取任务需要大量的关系标注数据。以上方法中,监督学习方法和基于BootStrapping的半监督方法均需要标注大量的数据;人工标注的方法会耗费大量人力,不能适用于专业性较强的特定领域;远程监督方法可以适用于特定领域,快速标注大量的领域数据,为领域关系抽取模型提供训练数据。
1.2 关系抽取模型
在关系抽取任务中,常通过对深度学习模型的改进来获取更多的文本特征,例如,Zeng等[11]在卷积神经网络模型的基础上,提出了一种根据实体对位置进行分段式最大池化的方法,可以获得更多的文本特征,而且Zeng等[12]通过增加实体的位置信息和其他相关词汇特征来提高关系预测准确率。Yan等[13]将句子的词性特征、依存关系特征和短语语法树特征进行融合,得到句子的特征表示,充分利用句子的语义信息,提高Text-CNN模型的抽取效率。Jia等[14]通过注意力机制发现表达关系类别的关系模式,利用发现的关系模式来实现关系抽取任务。Jat等[15]利用多种词级注意力模型的互补特性来增强较长文本的句子表示能力,从而提升关系抽取性能。
以上的研究大多在文本特征的基础上,继续挖掘文本中所包含的重要特征,进而提高模型的关系抽取效率。但随着自然语言处理的研究,外部知识赋能的模型逐渐被应用于关系抽取任务。基于外部知识的关系抽取模型可以把额外的知识特征作为辅助特征来判断文本中的关系类别。例如Li等[1]利用因果关系的同义词、近义词作为关系先验词汇,利用先验词汇特征实现关系类别判断,增加关系抽取能力。Zhang等[16]提出了一种基于知识库的知识感知模型,并将传统的关系抽取任务建模为关系检索任务进行关系抽取。Zeng等[17]提出了基于关系路径的关系抽取模型,借助中间实体和关系路径来进行关系抽取。Nathani等[18]提出基于图注意力模型的特征嵌入方法,通过获取实体对在知识库中相邻实体和关系特征来增强特征表示。Vashishth等[19]利用了知识库中实体类型和关系别名作为模型的附加信息,将附加信息作为关系抽取的软约束,从而提升关系抽取性能。在特定领域中,采用基于外部知识特征的关系抽取方法能够充分利用领域知识和专家经验,为关系抽取提供丰富的经验知识,从而提高关系抽取效率。
基于以上研究思路,本文采用了基于先验知识的关系抽取方法,充分利用能够表达关系类别的外部词汇知识辅助领域关系抽取任务,并选择具有良好学习能力的卷积神经网络模型作为特征提取模型。同时,利用远程监督方法的自动标注数据能力解决特定领域缺少标注数据的问题。
2 问题描述和概念定义
2.1 问题描述
领域关系抽取任务可以为知识图谱的构建扩充三元组的数量,是发现实体对之间关系类别的重要过程。领域关系抽取任务的进行离不开领域关系抽取模型以及领域标注数据。因此,本文要解决的核心问题是领域先验词汇的获取,以及将先验词汇特征应用于领域关系抽取模型,并为模型的训练评估标注领域数据。本文通过获取并利用已有的关系先验词汇为抽取模型提供外部特征信息,从而提高领域关系抽取效率;而且,有效利用领域文本语料及三元组为模型创建领域数据集,进行模型训练评估。
2.2 概念定义
在定义相关概念之前,首先介绍本文中所使用的符号:三元组集合表示为T={T1,T2,…,Tn},Ti=
定义1关系先验词汇知识。本文采用了能够描述关系类别的词汇作为关系先验词汇。关系先验词汇知识是判断文本所含关系类别的重要特征。先验词汇知识主要是从已有的词汇知识库、包含关系类别的文本语料、三元组中获取,例如表1所示的Founder关系的先验词汇知识来源。

表1 Founder关系的先验词汇知识获取来源
定义2领域关系抽取数据集RE。领域关系抽取数据集可表示为RE={(S1,r1),(S2,r2),…,(Sn,rn)},其中(Si,ri)为一组标注数据。Si=(si,hi,ti),其中:Si为一条标注实体对hi和ti的文本;si为未标注实体对的纯文本;hi为头实体;ti为尾实体;ri为标注的关系类别。
3 基于先验词汇的分段池化卷积神经网络模型
针对特定领域关系抽取任务,本文提出基于先验词汇的分段池化卷积神经网络模型K-PCNN。K-PCNN的模型结构如图1所示,该模型主要包含两个核心部分:基于先验词汇的卷积层(Convolution Layer with Priori Words)和分段池化层(Piecewise Max Pooling)。其中:模型的输入为文本语句;Embedding Layer为模型嵌入层。最后是实现关系抽取的分类器。
基于先验词汇的卷积层是将关系先验词汇特征作为卷积神经网络的卷积核权重,利用关系先验知识特征来识别文本中包含的关系类别。先验词汇知识特征是该模型进行关系分类的重要依据,且先验词汇特征是用预训练的词向量进行向量表示,不需要在模型训练时重新训练。本文的模型中池化层采用了Zeng等[11]提出的分段池化,可以获取更多的文本特征,减少降维过程的特征损失。
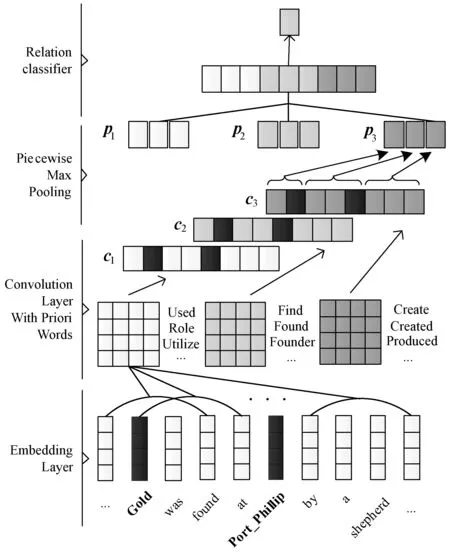
图1 基于先验词汇的分段池化卷积神经网络模型
3.1 词嵌入层
本文K-PCNN模型的输入为一条带有实体对的文本,例如图1所示的输入语句为:“Gold is found at Port_Phillip by a shepherd.”,其中:实体对是“Gold”和“Port_Phillip”;关系标签为“FOUND”。K-PCNN模型的嵌入层是为了将模型的输入文本嵌入到低维向量空间。本文采用了Word2vec模型,并利用领域数据集的文本进行预训练,从而得到词嵌入矩阵。根据词嵌入矩阵,得到输入文本的词向量矩阵。例如,给定一个文本序列{w1,w2,…,wn},其中n为文本中单词数量,根据词嵌入矩阵,将文本序列转换为词向量序列{q1,q2,…,qn},qi∈Rd,d为词向量维度,如式(1)所示。
qi=fWord2vec(wi)
(1)
式中:wi为文本序列中的单词;qi为第i个单词的词向量表示;fWord2vec表示Word2vec模型函数。
3.2 基于先验词汇的卷积层
基于先验词汇的卷积层将关系先验词汇特征作为卷积核参数,即先验词汇的词向量作为卷积核的权重参数,进行卷积运算。利用先验词汇特征来辨别文本中包含的关系类别。因此,本节主要介绍关系类别先验词汇知识的获取与应用。
先验词汇特征是关系分类的重要特征,关系先验知识的丰富性有助于关系类别的判断。WordNet[20]和FrameNet[21]两个词汇知识库包含了大量的词汇知识,可以为关系抽取提供重要的词汇知识。除此之外,在领域数据集的语料文本中已经包含了各个类别的文本信息,也是判断关系类别的重要先验知识。因此,本文利用词汇知识库和领域数据集来获取相关词汇知识,并通过专家对获取的词汇进行筛选,最终得到应用于模型的关系先验词汇。专家筛选是为了将表达关系类别的重要先验词汇筛选出来,领域专家掌握有大量领域知识及经验,能够快速判断关系类别的相关先验词汇,用于关系类别的判别。关系先验词汇的获取及筛选流程如图2所示。
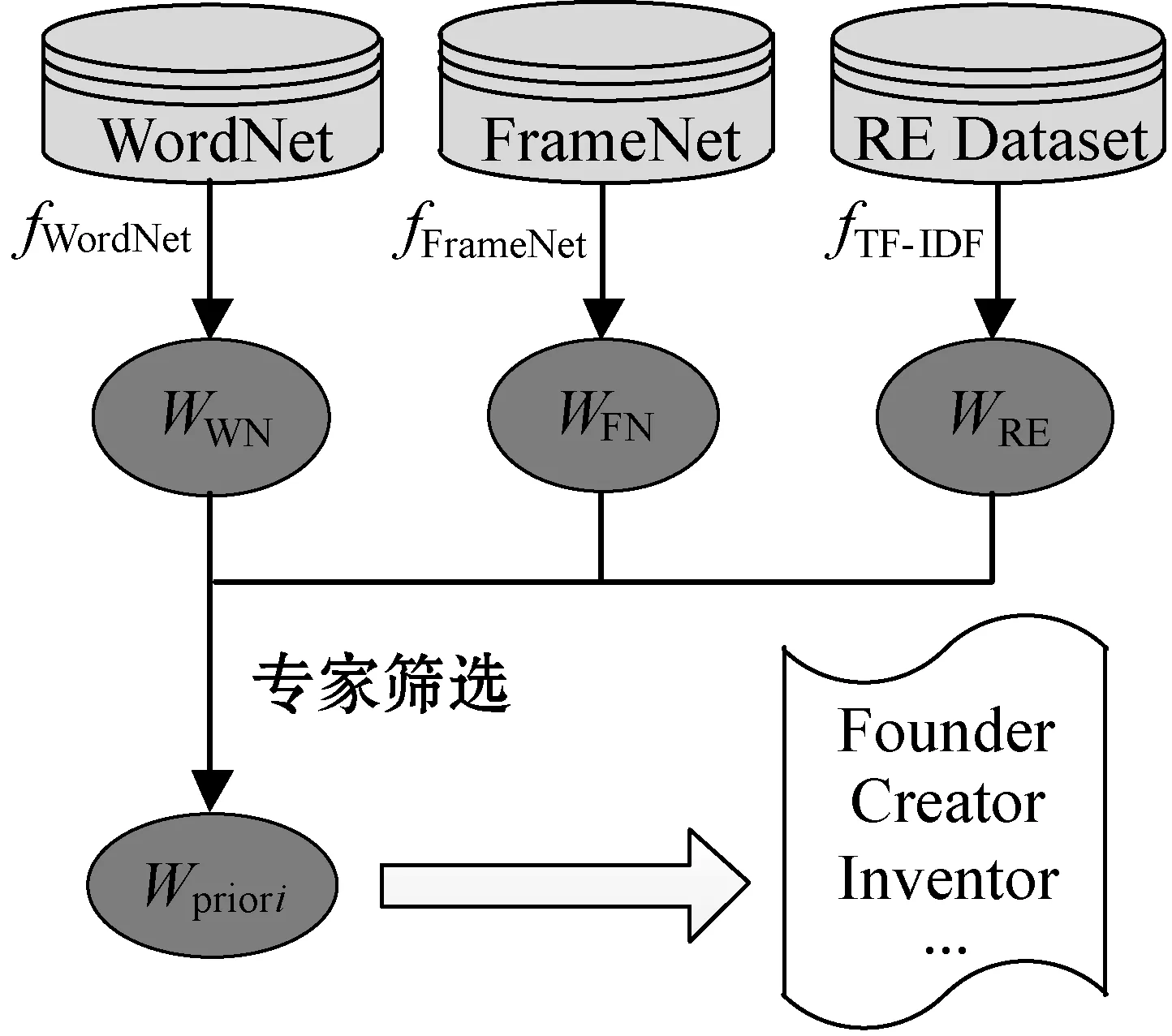
图2 关系先验词汇的获取流程
先验词汇知识的获取过程如下:
Step1从WordNet和FrameNet中获取关系先验词汇。WordNet和FrameNet作为两个词汇知识库,其中包含了较为完整的词汇知识,并分别利用同义词集和词汇框架将词汇之间链接起来。给定要进行抽取的关系类别标签r,将关系类别标签作为查询关键词,在WordNet和FrameNet中进行同义词和近义词的提取,获得词汇集合WWN和WFN,分别表示为:
WWN=fWordNet(r)
(2)
WFN=fFrameNet(r)
(3)
式中:fWordNet和fFrameNet分别为WordNet、FrameNet同义词、近义词提取函数;WWN和WFN分别是从WordNet和FrameNet提取的关系类别r的相关词汇集合。
Step2从领域数据集获取关系先验词汇。领域数据集在本文中不仅作为关系抽取训练集,也将用于抽取关系先验词汇。本文利用TF-IDF算法来提取数据集文本中的重要词汇信息。给定数据集中该类关系的文本语句集合{s1,s2,…,sm},利用TF-IDF算法得到根据词频排序的语料词汇集合WRE,表示为:
WRE=fTF-IDF({s1,s2,…,sm})
(4)
式中:fTF-IDF表示为TF-IDF算法函数;WRE为利用TF-IDF算法得到的语料词汇集合。
Step3专家筛选关系先验词汇。关系类别的相关词汇词集WWN、WFN和WRE包含了关系类别的一些相关词汇,但是词集的词汇数量繁多需要进行筛选,得到能够充分描述关系类别的先验词汇。筛选过程采用了专家人工筛选的方法,可以更为准确地保留关系类别的重要先验词汇知识,有助于模型对关系类别的分类能力,公式表示为:
Wpriori=fExpert(WWN,WFN,WRE)
(5)
式中:fExpert表示为专家筛选先验词汇过程;Wpriori为得到的关系类别的先验词汇集集合。
经过以上方法得到先验词汇集Wpriori后,在进行模型分类前需要根据词嵌入矩阵将先验词汇转换为词向量,得到先验词汇特征矩阵F,如式(6)所示。特征矩阵F将作为卷积层的卷积核权重进行模型训练和分类。
F=fWord2vec(Wpriori)
(6)
式中:fWord2vec表示为Word2vec模型函数;F为先验词汇特征矩阵。
卷积层可以包含有多个卷积核,因此不同关系类别的先验词汇特征矩阵将作为不同的卷积核权重进行卷积,多卷积核的应用能够获取不同的特征。若模型输入一条语句{w1,w2,…,wn},其中n为单词个数;经过嵌入层后得到词向量序列{q1,q2,…,qn},qi∈Rd,其中d为词向量维度;卷积核长度为k,卷积核权重矩阵为F,F∈Rk×d,则嵌入层的第i行到第j行矩阵qi:j与F卷积计算过程如下:
cj=Fqj-k+1:j
(7)
式中:cj为卷积计算得到的特征值,j∈[1,n+k-1]。卷积完成后得到特征图为c∈Rn+k-1。
3.3 分段池化层
在卷积神经网络模型中,经过卷积后得到的特征图会通过池化层来降低维度大小,防止过拟合,并且可以保留重要的特征信息。池化层常用的设置为最大池化,即取特征值中的最大值。为了获取更多的文本特征,Zeng等[11]提出了分段池化设置。分段池化是把卷积后的特征图矩阵根据实体对的位置切割为三段,再进行最大池化的方法,如图1中Piecewise Max Pooling部分。相比于普通的最大池化只获得了一个特征值,分段池化将三段分别求最大池化,可以保留更多的特征信息。
在关系抽取模型中,模型输入为一个文本序列,转换为词向量序列后进入卷积层,经过卷积得到若干个特征图{c1,c2,…,cm},ci∈Rn+k-1。若对其中一个个特征图ci进行最大池化,得到池化后的结果仅为一个特征值pi,如式(8)所示。若把特征图ci根据实体对位置进行分段处理,将ci分为三段{ci1,ci2,ci3},再分别对三段进行最大池化,便可得到三维向量pi=(pi1;pi2;pi3),如式(9)所示。
pi=max(ci)
(8)
pij=max(cij) 1≤i≤m,1≤j≤3
(9)
模型经过卷积层和池化层后,得到的特征矩阵继续在分类器中实现关系的分类。经过卷积层和池化层后的特征矩阵包含了文本的重要特征以及关系类别特征,最终这些特征矩阵进入关系分类器利用Sigmoid函数实现关系分类。
4 基于远程监督的领域数据标注方法
特定领域关系抽取模型的训练和评估离不开大量的标注数据。在特定领域中,传统的人工标注方法需要大量的人工参与。因此,本文根据关系抽取模型的训练数据需求,提出基于远程监督的数据标注方法,如图3所示。该方法主要应用了远程监督的自动标注能力,利用特定领域的三元组知识和语料文本进行数据集构建。
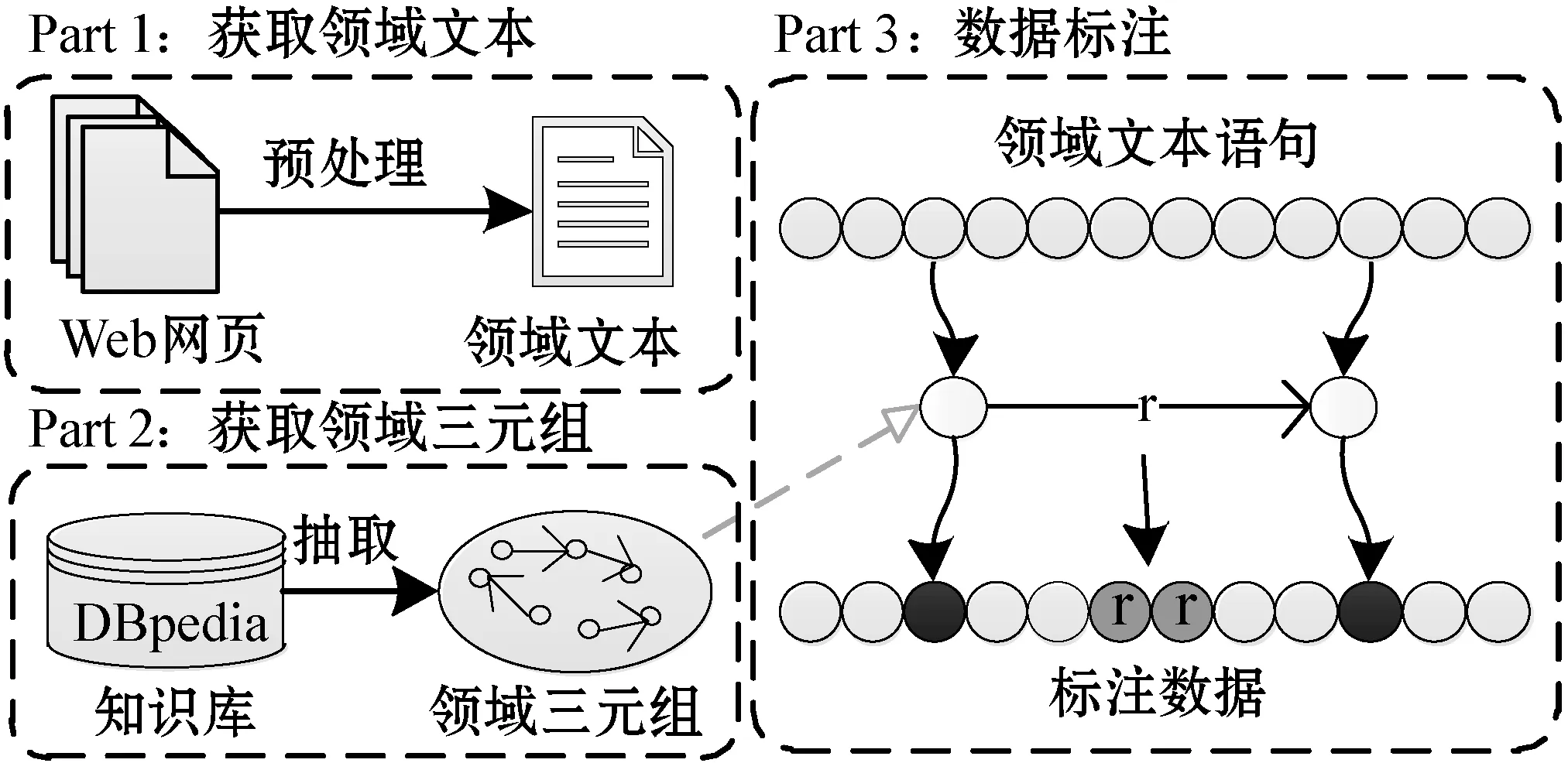
图3 领域数据标注流程
远程监督数据标注方法的具体实现是根据文本中是否存在实体对而进行关系标注的。因此,根据远程监督方法进行数据标注需要获取领域三元组及领域语料文本。本文将数据标注过程设置为三部分:获取领域语料文本,获取领域三元组知识和领域数据标注。其中:Part1为从Web网页中爬取领域文本;Part2为从DBpedia等知识库获取领域三元组知识;Part3为数据标注过程。
4.1 基于DBpedia与Wikipedia的领域语料与三元组抽取方法
Wikipedia是一个跨学科跨领域的百科全书,其中包含了大量的语料文本,而DBpedia是一个开放知识图谱,包含了大量来自Wikipedia的三元组知识,并且与Wikipedia的资源相关联。因此,本文依据DBpedia知识图谱结构,在Wikipedia和DBpedia中抽取领域文本与领域三元组知识。
本节以金属材料领域为例,介绍基于DBpedia与Wikipedia的领域语料与三元组抽取方法,并采用了Zhang等[22]提出的逐步提取策略(Stepwise Extraction Strategy,SES)。领域文本与三元组的抽取过程主要包含创建候选类别实体集合、抽取DBpedia中的领域三元组、抽取Wikipedia中的语料文本、迭代扩充四个步骤,抽取流程如图4所示。领域语料文本及三元组抽取的具体步骤如下:
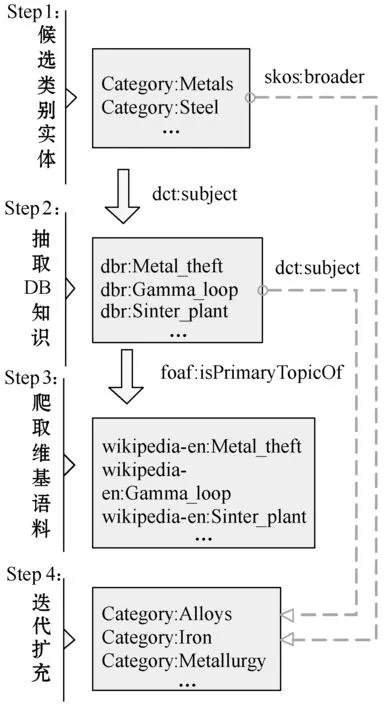
图4 领域语料及三元组抽取流程
Step1创建候选类别实体集合Edbc。DBpedia中实体可以分为两类:一类为表示类别的类别实体edbc,例如“dbc:Metals”;另一类为表示资源的资源实体edbr,例如“dbr:Iron”。候选类别实体集合Edbc是由人工初始化的一些金属材料类别实体组成。
Step2抽取DBpedia中的领域三元组。根据DBpedia中类别实体和资源实体之间的关系类别“dct:subject”,可以从DBpedia API中获取类别实体对应的资源实体,例如图4中类别实体“dbc:Metals”根据三元组
Step3抽取Wikipedia中的领域语料文本。已知DBpedia的三元组知识均源于Wikipedia,并且每一个资源实体都通过“foaf:isPrimaryTopicOf”关系链接到相应的Wikipedia网页资源,例如
Step4迭代扩充实体集合与语料文本。在DBpedia中资源实体与类别实体存在关系“dct:subject”,而类别实体之间存在包含关系“skos:broader”。因此,根据这两类关系可以对初步得到的类别实体集合进行扩充,从而得到更多的领域语料文本和三元组。
领域语料文本及三元组抽取方法的具体实现算法如算法1所示。算法的输入是候选类别实体集合Edbc,迭代次数k,算法结束后,将返回领域文本集合D与领域三元组集合T。
算法1领域语料文本及三元组抽取算法
输入:Edbc,k。
输出:D,T。
1.Edbr=∅,D=∅,T=∅,j=0
2.ForeachedbcinEdbc
3.Ifj>kdo
4.break
9.j=j+1
10.ForeachedbrinEdbr
11.doc=fisprimarytopicof(edbr)
12.D=D∪{doc}
13.{trii|i∈Z+}=fDBpedia(edbr)
14.T=T∪{trii|i∈Z+}
17.j=j+1
18.EndFor
19.EndFor
20.ReturnD,T
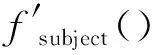
图5所示为根据算法1实现的实体扩充实例。以“dbc:Metals”为候选类别实体,可以通过“dct:subject”和“is skos:broader of”两种关系,经过两次迭代即可获得“dbc:Iron”等五种类别实体及其资源实体。
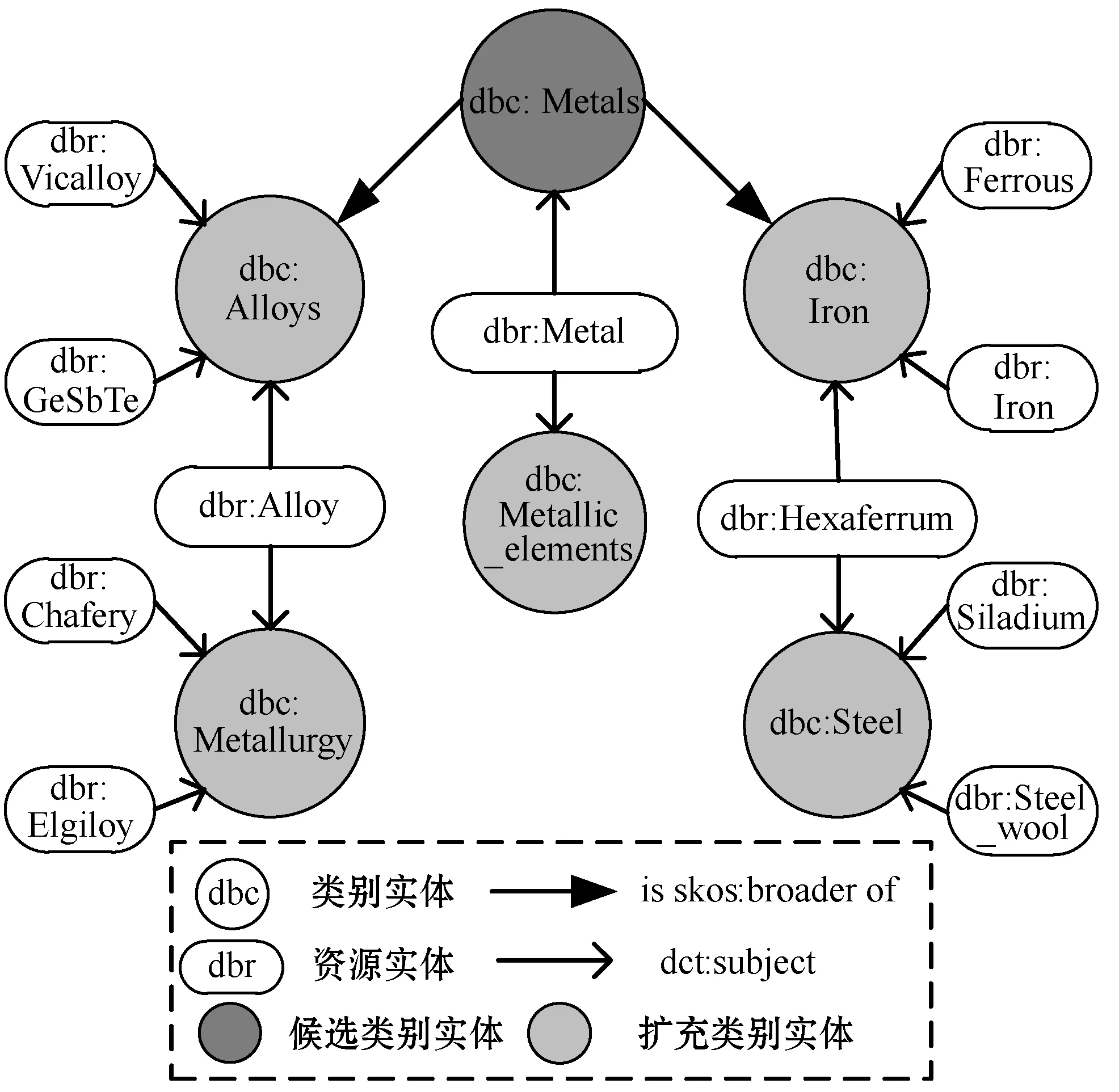
图5 DBpedia领域实体迭代扩充示例
4.2 基于OpenIE与ReVerb的领域三元组扩充方法
经过对Wikipedia和DBpedia中领域文本和三元组的抽取,可以得到领域文本集合与领域三元组集合。但是,在抽取的语料文本中仍然存在着许多DBpedia未包含的三元组知识。因此,为了获取更多的三元组知识,本文提出基于OpenIE与ReVerb的领域三元组扩充方法,利用开放信息抽取工具OpenIE[23]与ReVerb[24],继续抽取领域文本中所包含的三元组知识,扩充领域三元组集合。OpenIE与ReVerb是两个重要的开放信息抽取模型,使用之前不需要提前指定关系,即可从句子中抽取三元组。领域三元组扩充方法的步骤主要分为两步,过程如下:
(1) 三元组抽取。该步骤主要利用OpenIE和ReVerb两种工具对从Wikipedia获取的领域文本进行三元组抽取。
(2) 三元组筛选。筛选过程主要利用置信度来筛选出高置信度的三元组。置信度筛选利用了OpenIE与ReVerb的置信度评分进行筛选三元组,选取置信度高于0.8的三元组。如表2所示,两种抽取工具对同一文本的抽取结果及三元组置信度评分。最后将筛选的三元组扩充到领域三元组集合,用于数据标注过程。
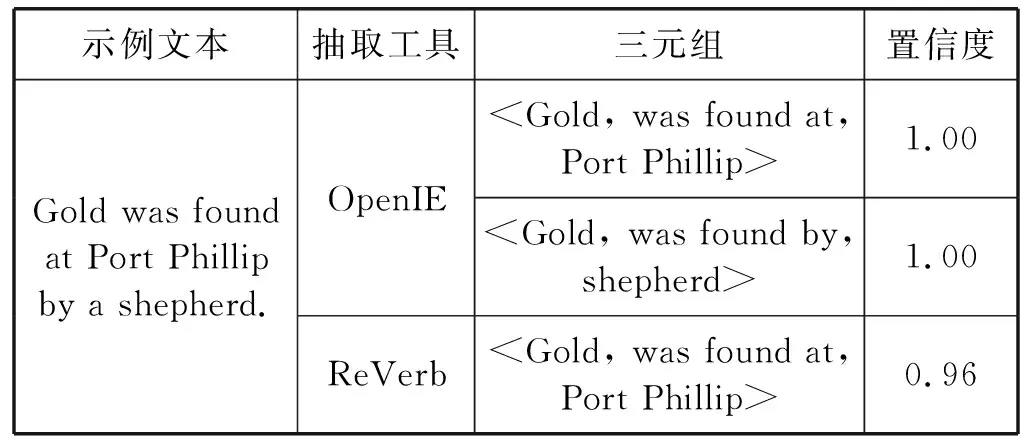
表2 OpenIE与ReVerb抽取三元组示例
4.3 基于远程监督的领域数据标注
基于上述方法,可以得到领域语料文本集合及三元组集合。利用得到的文本和三元组,就可以基于远程监督方法进行数据标注,标注示例如图6所示。在数据标注前,首先将文本语料进行数据清洗,指代消解、分句等预处理,最终得到一系列文本语句;然后将得到的文本语句及三元组根据远程监督方法进行数据标注。远程监督方法对文本的标注依据是文本序列中是否存在三元组的实体对,若文本中存在实体对,则进行关系标注,表示为:
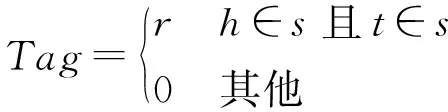
(10)
式中:s={w1,w2,…,wn},s表示待标注的文本序列,wi表示s中的单词;h、r、t分别是三元组
图6所示是以金属材料领域为例的领域数据标注示例。图6中实例1文本中包含了三元组
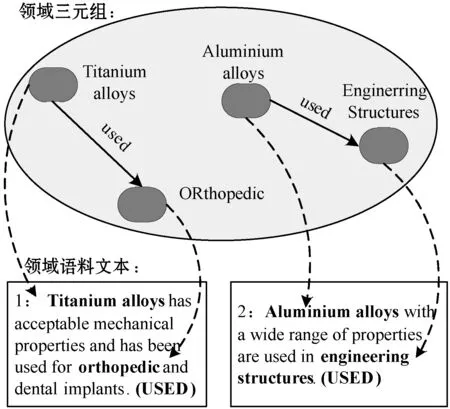
图6 金属材料领域数据标注示例
5 实 验
5.1 实验数据
由于领域缺少专有的关系抽取数据集,因此本文的实验数据利用所提出的基于远程监督的领域数据标注方法进行自动标注,构建了金属材料领域关系抽取数据集MMRE。并且,通过对三元组关系的筛选,选择了其中四类主要实体关系,共包含了7 000多条标注文本,具体关系类别如表3所示。
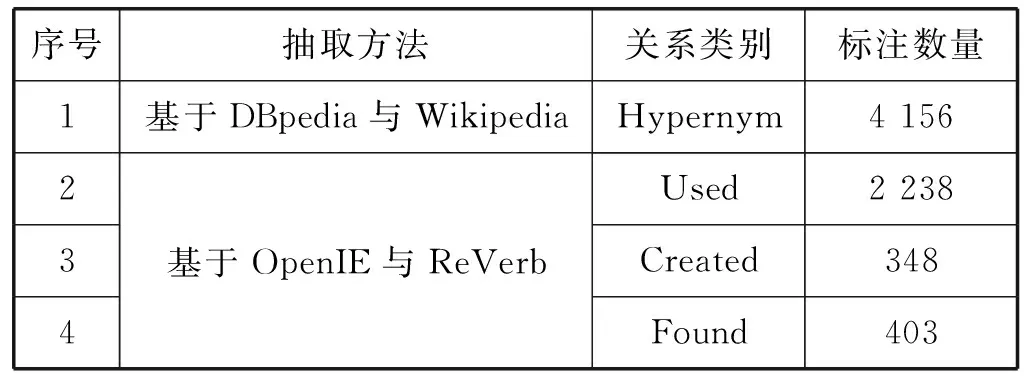
表3 MMRE数据集包含的关系类别
除了领域数据集,本文还采用了关系抽取任务中广泛应用的NYT[25]数据集进行模型的评估。NYT数据集共包含53种关系类别,本文从中选择了4类关系进行评估实验,具体的关系类别如表4所示。
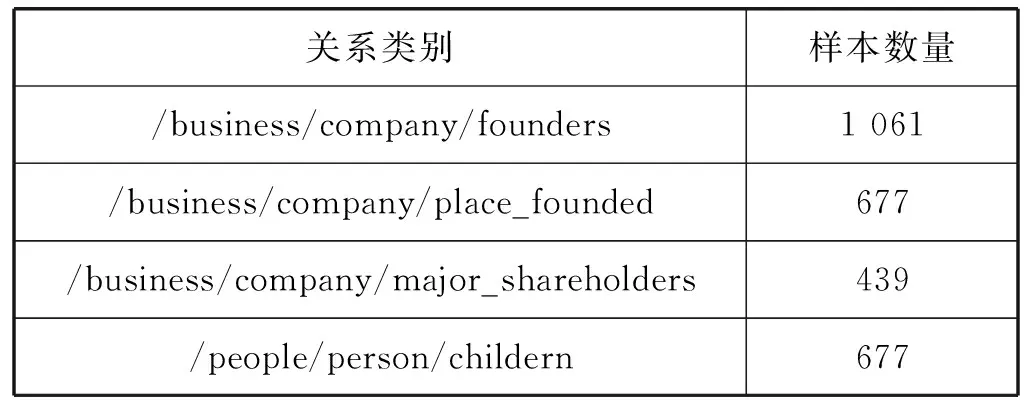
表4 NYT数据集中的4种关系类别
5.2 评价指标
本文的关系抽取实验采用了内部自动评测方法来评价关系抽取模型的性能,以F1值为评价标准对关系抽取效果进行综合评估。除此之外,为了能清楚地了解模型对每一类关系的抽取效果,采用ROC评估曲线的AUC值对各类关系的抽取效果进行详细评估。
ROC评估曲线主要表现为一种真正率与假正率之间的权衡。AUC值即ROC曲线与横轴之间的面积,AUC值的计算表示为:
(11)
式中:M为某类关系的正例样本数量;N为非此类关系的负例样本数量;PT为正例样本的预测概率;PF为负例样本的预测概率;(PT,PF)为样本对,即一个正例样本与一个负例样本的组合;I(PT,PF)为所有样本对中,正例样本的预测概率大于负例样本的预测概率的个数。
5.3 实验方法
在对关系抽取任务的研究中,本文选用了卷积神经网络作为关系抽取基础模型。因此,为了提升模型泛化能力,防止过拟合现象,本文采用了模型正则化方法和数据扩增的方法,并且实验过程中采用了K折交叉验证的训练方法。
在数据量有限、样本不均衡等情况下,模型训练会受到数据集的限制而不能达到最优。Wei等[26]提出了一种数据增强技术(Easy Data Augmentation,EDA),该技术为小数据集的训练提供了数据优化方法,可以显著提高模型性能并减少过拟合。同时,考虑到实验标注数据中实体对位置不能随意变换,不能随机删除或增加词汇,因此,采用了EDA的同义词替换和变换词序的方法来增强MMRE数据集。
在MMRE数据集的基础上,本文分别采用了EDA技术的同义词替换和变换词序方法,生成了两个新的数据集:同义词替换后的数据集MMRE_eda和原文本逆转词序后的数据集MMRE_rev。表5展示了增强后数据集样本数量情况,其中:MMRE_ori是原始MMRE数据集;MMRE_all是MMRE_eda和MMRE_rev两个数据集的集合。
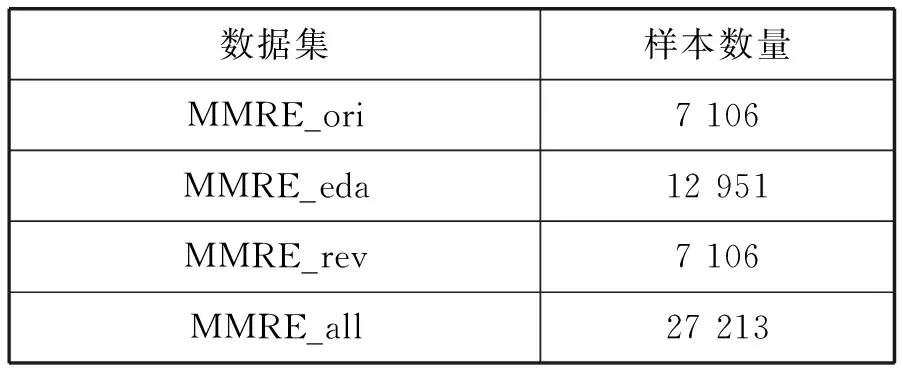
表5 数据增强后的各个数据集情况
5.4 超参数设置
实验过程中,为了提高模型的性能,本文以F1值为评价指标,从词向量维度、文本序列长度方面判断了两种参数对实验训练过程F1值的影响。词向量维度是模型将文本嵌入到向量空间时向量维度的大小,文本序列长度是指输入文本转换为词向量序列时进行扩充或切割而得到的序列长度。
本文将词向量维度范围设置为100到400,数值间隔为50,文本序列长度范围为200到500,数值间隔为50,利用网格搜索方法选取两组参数中的最优组合。实验如图7所示。
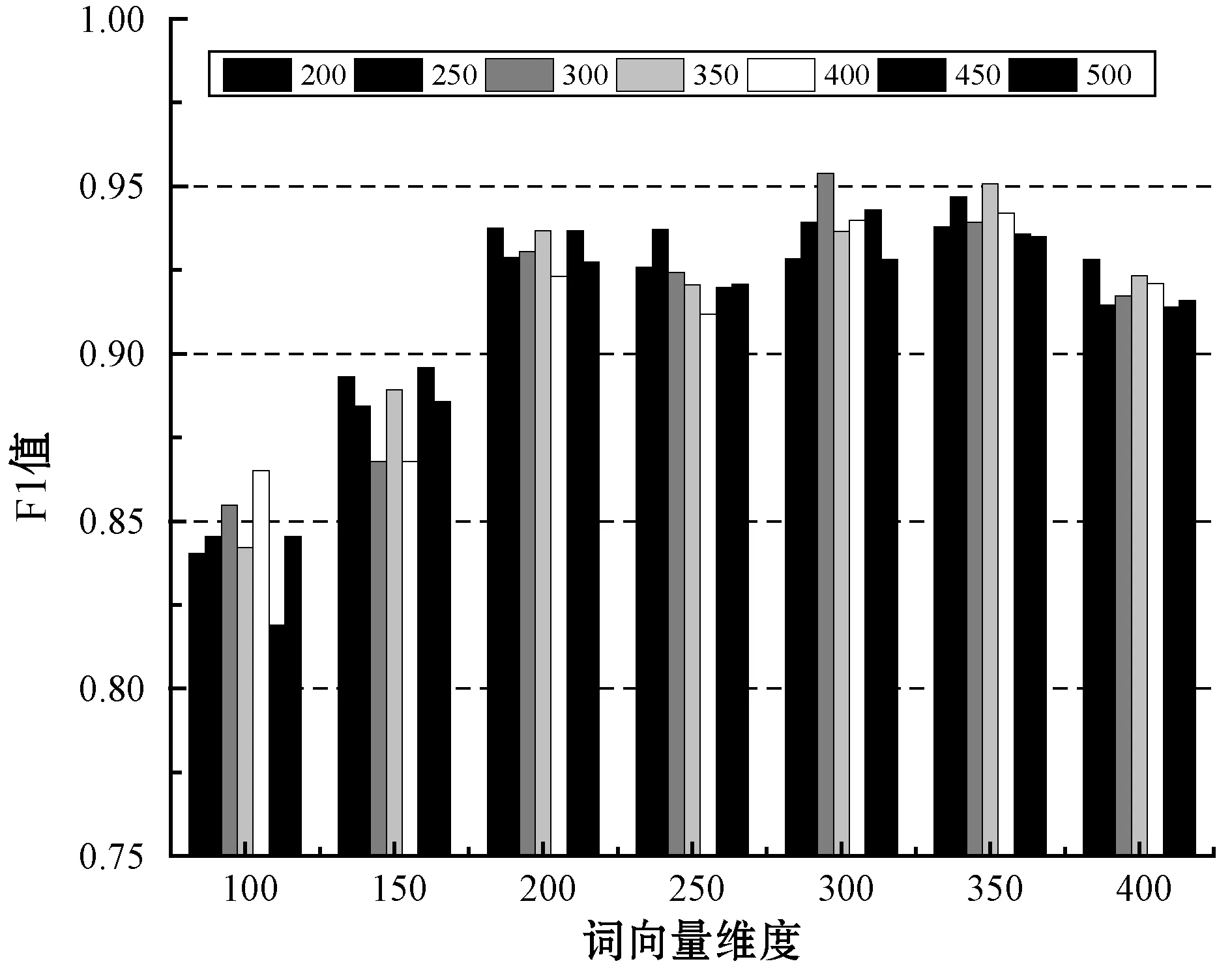
图7 不同词向量维度与不同词序列长度参数组合实验
图7中横轴为不同的词向量维度,每个词向量维度对应7个不同的词序列长度。根据图7中纵轴F1值可知,当词向量维度为300且词序列长度为300时,F1值最大,为最佳参数组合。其中,不同词向量维度和不同词序列长度分别对模型F1值的影响如图8、图9所示。
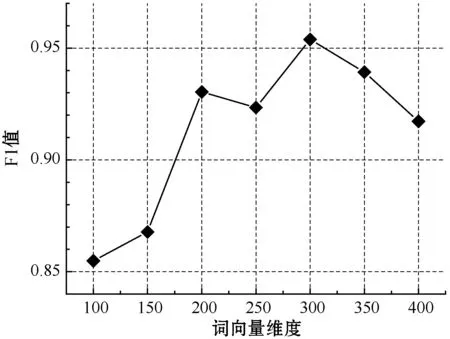
图8 不同词向量维度对模型F1值的影响

图9 不同词序列长度对模型F1值的影响
如图8所示,当词序列长度为300时,经过7种不同词向量维度的F1值对比可知,随着词向量维度增加,在300维时,F1值达到最高;并且在300维之后,随着维度递增,F1值逐渐减小。因此,最优词向量维度为300维。
如图9所示,当词向量维度为300时,随着词序列长度的不断增加,F1值不断上升,并在数值为300时,F1值达到最高点,因此实验中文本在输入层是统一采用的序列长度为300。
本文的超参数设置如表6所示。
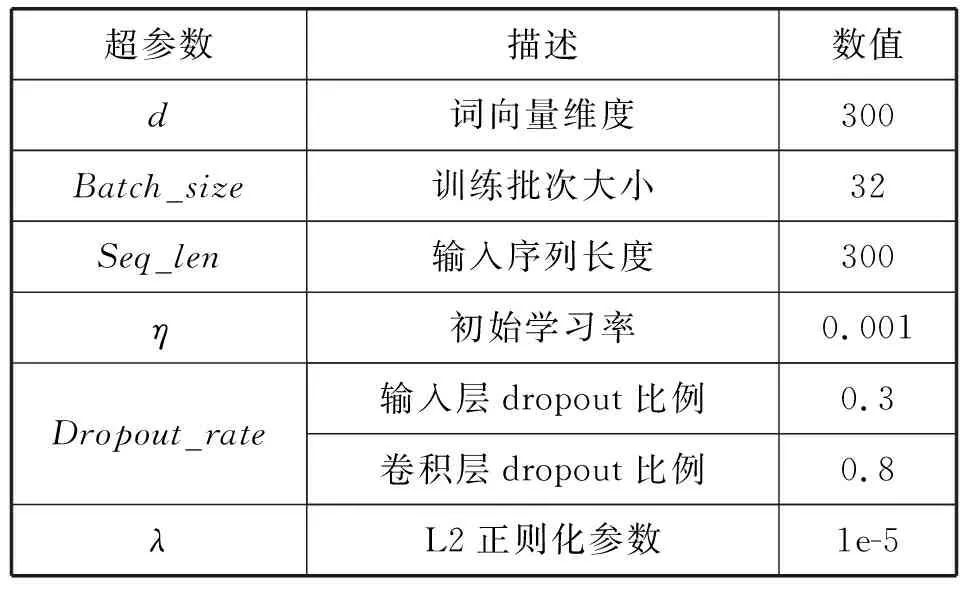
表6 实验超参数设置
5.5 关系分类实验
(1) 综合性能F1值评估。为了评价本文提出的K-PCNN模型在关系抽取任务的性能效果,本文选择Zeng等[11]提出的PCNN模型的改进模型PCNNwWLA进行对比实验。对比实验分别在领域数据集和公共数据集上进行。表7为K-PCNN模型与PCNNwWLA模型的测试集F1值对比。

表7 测试集F1值对比
表7所示实验结果显示,在领域数据集和公共数据集的对比实验中,K-PCNN的F1值均达到80以上,且均略高于PCNNwWLA模型。实验结果分析可知,领域先验词汇特征的应用有助于提高模型关系分类能力,且数据增强后的数据集也提高了模型的分类效果,使得K-PCNN模型关系抽取性能略高于PCNNwWLA模型。表8为本文模型对金属材料领域语料的关系预测实例。
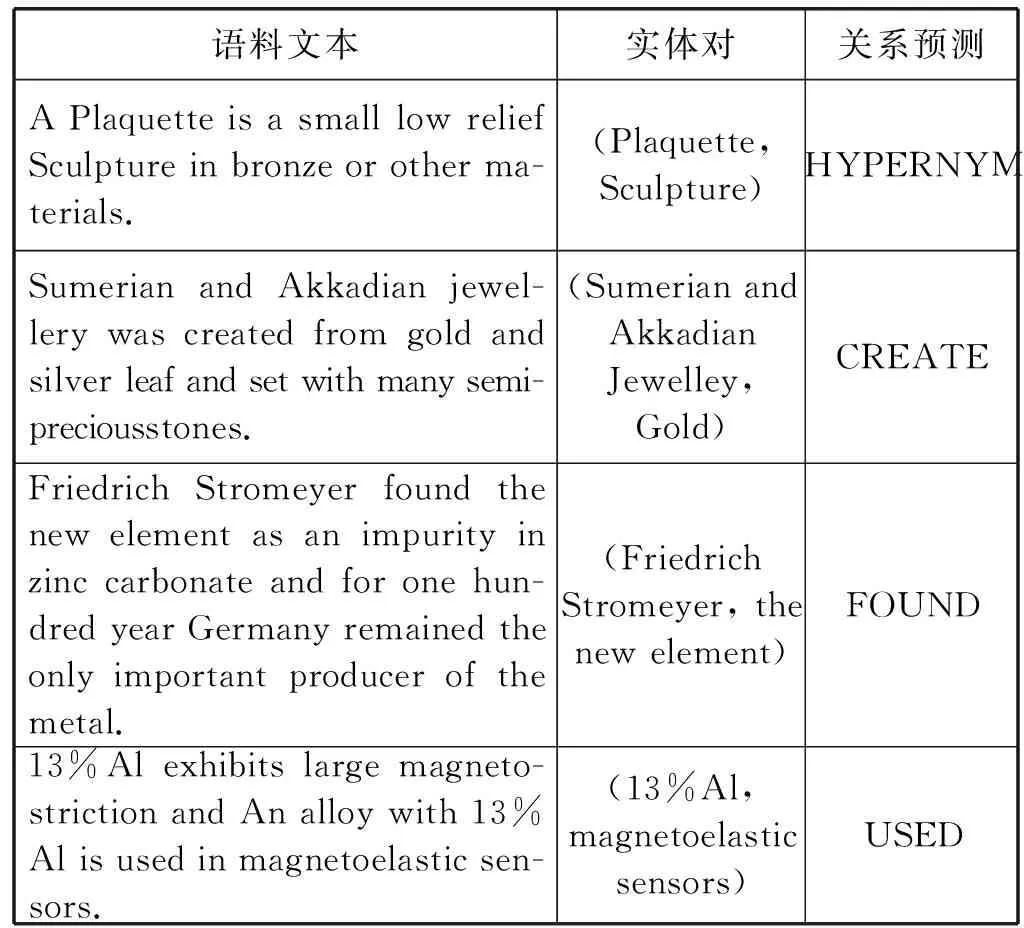
表8 K-PCNN模型关系预测实例
(2) 关系类别的AUC值评估。在经过数据增强方法得到的领域数据集上,K-PCNN模型对四类关系的预测能力以及四类关系的AUC平均值变化如图10所示。
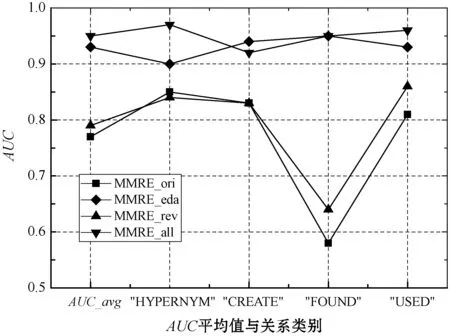
图10 关系类别AUC的对比
可以看出,在MMRE_all数据集中四类关系的AUC均高于0.9,说明模型K-PCNN对各类关系都有较强的分类能力。并且,K-PCNN模型在增强后的数据集上对每类关系的分类性能均优于原数据集,实验说明了数据增强技术有助于提高模型的性能。
6 结 语
本文在特定领域关系抽取任务中,针对领域关系抽取任务缺少适用模型及缺少领域标注数据的两个挑战,分别提出基于先验词汇的分段池化卷积神经网络模型K-PCNN和基于远程监督的领域数据标注方法。K-PCNN模型充分利用了关系先验词汇进行关系分类,将获取的关系词汇知识嵌入词向量后,输入到卷积神经网络模型作为外部知识特征辅助关系分类。并且,本文以金属材料领域为例,创建了金属材料领域关系抽取数据集,对模型的性能进行了评估。实验数据表明,该模型具有较高的关系抽取能力,说明本文提出的关系抽取模型以及数据标注方法能够在一定程度上解决特定领域关系抽取任务的问题,具有一定的现实意义。
虽然本文提出的基于先验词汇的关系抽取模型达到了较高的关系抽取性能,但是模型仅仅引入了能够表达关系类别的先验词汇知识,不能充分利用其他的外部知识或特征来辅助关系分类;而且,由于对先验词汇的依赖性,该模型只能抽取一些具有明显关系特征的关系类别,可抽取的关系类别有一定限制。因此,未来的工作将尝试把先验知识的范围进行拓展,例如实体类别等外部知识;并通过扩展更多的先验知识来增加可以抽取的关系类别。
