基于协同注意力和递归随机游走的实体链接方法
2022-09-07李圣杰史一民
李圣杰 周 新 史一民
(大连海事大学信息科学技术学院 辽宁 大连 116026)
0 引 言
语言表达的歧义性使得同一词语在不同的上下文中有多种不同的语义,如“华盛顿”可能表示一个州、一个人名、一个大学名,亦或是一个湖泊名。实体链接(Entity Linking, EL)则将一个文档中的指称(mention)链接到知识库(Knowledge Base, KB)中的相应实体。实体链接为处理语言表达的歧义性提供了一种解决方案,在互动问答[1]、信息抽取[2]和语义搜索[3]等众多领域发挥重要作用。然而,在大数据时代,数据呈现数据量大、表达多样性和数据价值密度低等特征导致这项任务越来越具有挑战性。实体链接包含三个子任务:(1) 指称探测,识别出可能需要被链接的文本片段;(2) 候选实体生成,即为文档中的每个指称在知识库中找到相应的一组候选实体;(3) 实体消歧,通过计算指称和候选实体之间的得分,依据得分排序选择最可能的候选实体为最终结果。相比于指称探测和候选实体的生成,实体消歧任务更具有挑战性,因此受到学者的热切关注。依据实体链接时仅关注单个指称还是考虑一个文档中所有指称间的语义相关性,实体链接的方法主要分为单一实体链接和集成实体链接。单一实体链接根据单个指称和候选实体的相关性来实现实体链接。早期实体链接方法多属于单一实体链接,Nguyen等[4]利用维基百科锚文本等信息计算指称和候选实体的相关性;Francis-Landau等[5]使用卷积神经网络(CNN),分别学习文本文档和规范实体页面的表示,计算指称和相应候选实体之间的相似度,然后再融合多种特征进行实体链接。单一实体链接只利用单个指称的相关信息,忽略了文档中实体之间的联系,实体链接的准确性并不是很高。针对这一不足,研究者提出了集成实体链接方法,Guo等[6]利用重启随机游走算法进行集体消歧;Cao等[7]利用图卷积神经网络(GCN)进行集体消歧;Xue等[8]提出RRWEL方法,使用随机游走实现了实体链接决策的一致性。然而,大多数集成实体链接方法,在嵌入指称和候选实体的相关性信息时,它们的表示是有限制性的,没有揭示注意力的焦点,这样的表示相当于“黑匣子”。近几年来,注意力机制被广泛应用到实体链接中。Lazic等[9]使用EM算法提取最有区别的指称上下文单词以消除歧义;Ganea等[10]使用基于神经网络的指称上下文的注意机制。然而,这些方法只注意到指称的上下文,而忽略了注意力机制的其他方面,如:候选实体描述的注意。
本文的主要贡献如下:
(1) 在指称的上下文和候选实体的描述中使用协同注意力,聚焦对实体链接最有用的单词,揭示注意力的焦点。
(2) 使用递归随机游走策略将局部兼容性和实体之间的一致性结合起来实现集成消歧。
1 问题定义
给一个包含n个指称的文档Di,每一个指称mi与知识库KB中的一个候选实体集合ε(mi)={e1,e2,…,ek}对应。文档Di中的所有指称组成指称集m(Di),文档Di中所有指称的候选实体组成候选实体集合E(Di)。表1给出实体链接的具体符号含义。形式上,可以将实体链接(Entity Linking,EL)定义为:在给定文档的指称集中,目标是找到相应的实体分配:
Γ:m(Di)→E(Di)
(1)
示例1文档“by the use ofwarmbloodhorse … by the use ofdrafthorse and Arabian … is usually bay,chestnut, brown or black in color”有“warmblood”“draft”和“chestnut”三个指称。“warmblood”对应的候选实体集合为{warmblood};“draft”对应的候选实体集合为{Draft horse、constriation};“chestnut”对应的候选实体集合为{Equine coat color,color}。通过相关实体链接的计算,这两个指称应该被链接到候选实体“Draft horse”和“Equine coat color”而不是“constriation”和“color”。

表1 实体链接的符号定义
2 相关工作
实体链接主要考虑了四种类型的特征(如表2所示):(1) 先验知识重要性,实体的先验知识重要性或者是指称和候选实体之间的先验知识重要性,在任何一种情况下,得分都是根据先前的重要性估算的。(2) 上下文相似性,计算指称上下文与候选实体描述之间的文本相似性,指称和实体的上下文提供了有利于消歧的附加信息。(3) 指称和候选实体的相关性、实体的类型和字符串的比较也有助于消歧。(4) 文档中所有实体链接决策之间的一致性,测量一对实体之间的语义相关度。

表2 实体链接的特征
根据对每个指称单独进行消歧还是一个文档中的所有指称集体进行消歧,实体链接的方法主要分为单一实体链接和集成实体链接两种。前者更高效,后者的准确率更高。早期实体链接任务主要利用单一实体链接方法,近年来,集成实体链接方法逐渐成为研究的热点[21]。
(1) 单一实体链接方法。单一实体链接分别对每一个指称进行消歧,并将实体消歧看作是一个排序问题,最后选择得分最高的候选实体。单一实体链接方法主要使用了四个特征中的候选实体和指称的先验知识重要性、上下文相似性和指称-候选实体的相关性。传统单一实体链接方法使用手工定义的特征计算指称和候选实体之间的相似性,通常是基于上下文的统计和词汇匹配,例如,指称和候选实体之间字符串的相似性、指称对应各候选实体的先验概率、知识库中指向候选实体的链接数等。手工定义的特征只包含浅层的信息。随着深度神经网络的兴起,发现深度神经网络可以学习到更多的抽象特征,弥补了传统方法的不足。最近的研究大多采用卷积神经网络(CNN)和长短记忆网络(LSTM)来获取实体更多的潜在语义特征[5,22-23]。单一实体链接方法可以形式化地表示为融合多个特征的形式:
(2)
式中:fk(ej,mi)可以是上下文无关或者上下文相关的特征,λk为相应的特征权重。
单一实体链接方法只考虑到单个指称,忽略了指称之间的关联,因此,研究者提出一种集成实体链接方法,集成实体链接方法考虑到了一个文档中所有实体之间的相关性。
(2) 集成实体链接方法。有效地消除歧义需要将局部兼容性(包括先验的重要性、上下文相似性和指称-候选实体的相关性)和所有实体的全局一致性结合起来,将文档中的实体链接决策联系在一起。集成实体链接方法假设同一文档中的指称共享相似主题,考虑到了一个文档中的所有指称之间的关系,最大限度地提高整个文档中实体的主题一致性。最常见的方法是建立一个图来模拟指称和实体之间,实体和实体之间的相似性。可以利用图的一些算法如:PageRank[24]和随机游走[8,25]等计算所有实体的全局一致性。集成实体链接方法目标函数可表示为:
(3)
式中:φ(mi,ej)为指称和候选实体的局部兼容性,如式(2)所示;ψ(Γ)为在文档中所有实体之间的一致性函数;Γ为一种解决方案表示指称-候选实体对的集合。
Deep-ED(Ganea等[10])使用指称上下文的注意机制,把深度LBP(循环置信传播)方法应用到集成实体链接方法中。而本文不仅使用指称上下文和候选实体描述的协同注意力机制,扩大了注意范围,而且把递归随机游走应用到集成实体链接方法中。Le等[25]在Ganea等[10]的基础上,增加了隐关系信息。而本文使用协同注意力机制,将递归随机游走应用于全局训练问题中。Guo等[26]提出了一种贪婪的集成命名实体消歧算法,该算法利用消歧图上随机游走传播引起的概率分布之间的互信息。该方法未利用注意力机制,而Att-RRW方法使用了协同注意力机制,聚焦对实体链接最关键的信息。通过上述几个对比方法可以看出,它们在获取指称和候选实体之间的语义信息时,没有揭示注意的焦点,没有使用或较少使用上下文的注意力,实体链接效果有待提高。Att-RRW方法在用神经网络获取指称和候选实体之间的语义信息的过程中,加入协同注意力机制,揭示注意力的焦点,修剪掉指称上下文和候选实体描述中没有用的单词。本文在指称上下文和候选实体描述采用了协同注意力机制,扩大了注意的范围,并且使用递归随机游走实现一个文档中的所有指称共同进行消歧,增强了实体链接的效果。
3 Att-RRW方法
Att-RRW由局部兼容性和集成实体链接两部分构成,其架构如图1所示。局部兼容性通过注意力机制获取最相关的指称上下文和候选实体描述,然后采用卷积神经网络(CNN)挖掘指称和候选实体的深层语义关系,计算单个指称和候选实体的局部相关性;集成实体链接首先计算候选实体之间的语义相关性,依据指称和候选实体的局部相关性、所有实体间的语义相关性,采用递归随机游走策略实现所有实体链接决策的全局一致性。
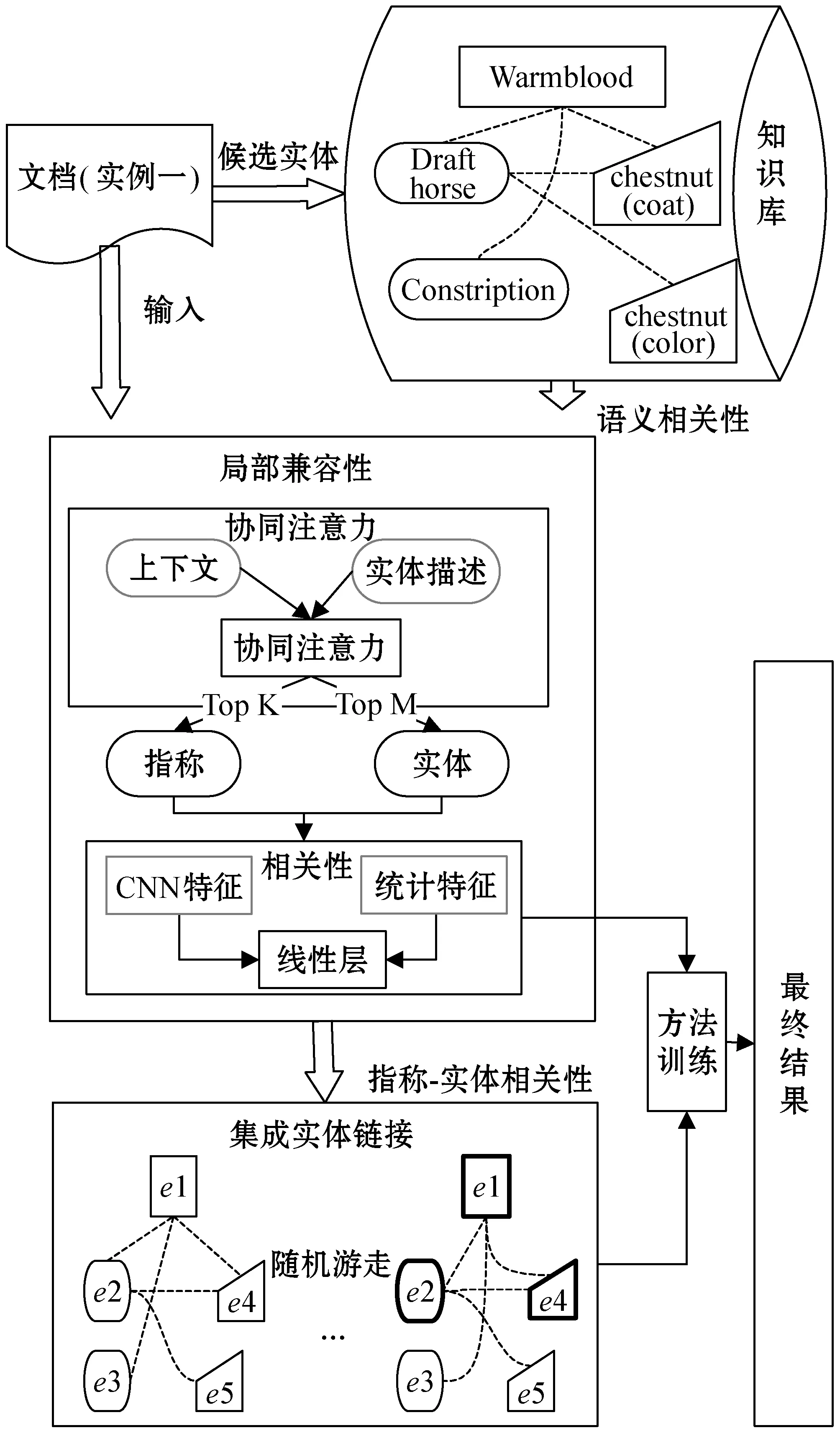
图1 Att-RRW方法架构
3.1 局部兼容性
3.1.1协同注意力
指称上下文和候选实体描述都包含着大量有关实体链接的信息,但是指称上下文和候选实体描述中每个单词对消歧的影响是不同的。针对这一现象,本文在指称上下文和候选实体描述中引用协同注意力机制,揭示了注意力的焦点。从指称上下文和候选实体描述中过滤掉没有用的单词,选择相关性最强的单词作为修剪后的指称上下文和候选实体描述。首先,使用Word2vec[27]进行词的嵌入,每个词由h维的向量表示。然后,使用式(4)得出指称上下文Ci和候选实体描述Bj的相似性得分。
(4)
式中:Wa∈Rh×h是一个参数矩阵。按行归一化亲密度矩阵Z,为指称上下文Ci的每个单词在实体描述Bj中产生一个注意力相关性得分Lc(式(5))。类似地,按列归一化亲密度矩阵Z,为实体描述Bj的每个单词在指称上下文Ci中产生一个注意力相关性得分Lb(式(6))。
Lc=softmax(Z)
(5)
Lb=softmax(ZT)
(6)
利用注意相关矩阵Lc和Lb分别计算Ci和Bj的注意概率,概率公式如式(7)-式(8)所示。
u(c)=whcHc
(7)
u(b)=whbHb
(8)
式中:Wb,Wc∈Rh×h、whc,whb∈Rh都是参数矩阵;u(c)∈RK包含指称上下文Ci中的每个上下文向量ci的注意力得分;u(b)∈RM包含候选实体描述Bj的每个候选实体描述向量bj的注意力得分。本文在指称上下文中根据u(c)选择得分最高的前R≤K个单词作为修剪后的指称上下文,如式(9)所示,同理,u(b)得分最高的前Z≤M个单词组成修剪后的候选实体描述如式(10)所示。
(9)
(10)
α=softmax(u(c)′)
(11)
β=softmax(u(b)′)
(12)
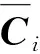
3.1.2指称和候选实体的相关性
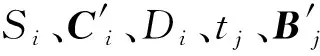
类似于Xue等[8]提出的RRWEL方法,首先计算出指称mi与候选实体ej的相关性得分φ(mi,ej),φ(mi,ej)被定义为:
φ(mi,ej)=σ(Wlocal·(Ss(mi,ej)⊕Sc(mi,ej)))
(13)
式中:σ(·)是Sigmoid函数;Wlocal是特征向量的权重;⊕表示融合;Ss(mi,ej)指的是一些统计特征,包含候选实体的先验概率、候选实体和指称字符串的编辑距离[7];Sc(mi,ej)表示联合五个元素之间的余弦相似度。Sc(mi,ej)计算式表示为:
(14)
归一化相关性得分获得一个条件概率P(ej|mi),得到指称和候选实体的局部兼容性得分,其计算式表示为:
(15)
3.2 集成实体链接
集成实体链接考虑所有指称-实体链接决策的全局一致性,需要计算候选实体之间的语义相关性以及指称-实体匹配对的全局关联性。
3.2.1候选实体之间的语义相关性
候选实体之间的相关性得分。其计算式表示为:
SR(ei→ej)=WLM+SR1
(16)
(17)
式中:WLM表示基于维基百科链接的度量;对于两个候选实体页面pi=(ti,Bi)和pj=(tj,Bj),使用超链接数来计算语义相关性得分;I和J分别是链接到KB中pi和pj的所有实体集合;W是整个KB中所有的实体数量。
同时,基于CNN语义表示获得它们之间的余弦相似度SR1,考虑到两个候选实体之间的语义相关性得分依赖于它们相应指称的相对距离,本文用其实体的位置嵌入posi补充传统实体页面pi=(ti,Bi)。在这里,按照Vaswani等[28]提出的方法定义指称mi的嵌入位置posi。SR1的计算如式(18)所示。
SR1=cos(xei⊕xti+posi,xej⊕xtj+posj)
(18)
3.2.2递归随机游走
本文构建一个实体图G=(V,E),其中:V表示所有的候选实体,E表示候选实体之间的边,包含候选实体之间的相关性信息,本文采用式(16)计算它们之间的相关性。
接下来,引入了递归随机游走层来传播EL证据,目的是有效地捕获EL决策之间的相互依赖性。随机游走是一种随机过程,为了实现递归随机游走,需要定义一个归一化后的转移矩阵A,Aij是从实体ei转移到实体ej概率,计算式表示为:
(19)
式中:Nei表示与实体ei直接相连的实体集合。
利用转移矩阵A,式(20)阐述了递归随机游走的过程。
r(k+1)=(1-λ)Ar(k)+λr(0)=
(1-λ)A(k)·r(0)+λr(0)
(20)
式中:r(k)是第k次迭代时指称mi的预测实体分布;k表示迭代次数;λ表示可调参数,实验最后选取λ的数值为0.5;r(0)=P(*|mi)表示仅利用了指称和候选实体的局部兼容性。很明显,对于k个随机游走层,可以在随机游走传播的基础上方便地传播k次证据,经过实验验证之后,k的最佳取值为5。
3.2.3模型训练
为了将EL决策之间的实体一致性与指称-候选实体的上下文局部兼容性结合起来。本文利用了基于马尔可夫链的随机游走过程的收敛性[29]。具体而言,在多轮EL证据传播之后,指称的预测实体分布将趋于收敛。如果不同EL决策之间的相互依赖已经很好地嵌入到Att-RRW模型中,那么P(*|mi)≈A(k)P(*|mi)。为了保持指称mi在第k次EL传播中的一致性,应该使得P(*|mi)≈A(k)P(*|mi)之间的差值最小。本文给出学习过程的目标函数:
(21)
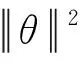
L=(1-γ)·Lc+
(22)
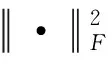
(23)
在对模型进行训练时,首先使用Lc对方法进行预训练,然后用L对模型进行微调。
4 实验与结果分析
4.1 数据集
本文采用多个流行的数据集验证Att-RRW方法的有效性。EL数据集特征如表3所示,其中:MN表示指称的数量;DN表示文档的数量;AMD表示平均每篇文档中的指称数量。
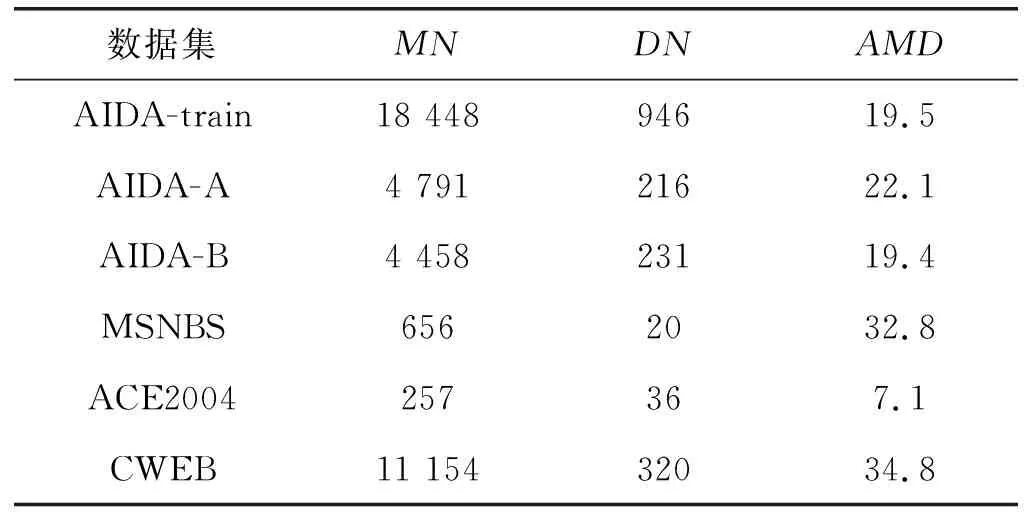
表3 数据集特征的具体数值
(1) AIDA-CoNLL:最大手动标注的数据集之一[16],包含946个文档的训练集(AIDA-train)、216个文档的验证集(AIDA-A)和231个文档的测试集(AIDA-B)。
(2) MSNBC(MSB):由Guo等[26]清理和更新,包含20个文档。
(3) ACE2004:由Guo等[26]清理和更新,包含36个文档。
(4) WNED-CWEB(CWEB):从ClueWeb和Wikipedia中自动抽取[31],因此不太可靠,数据相对较大,有320个文档。
4.2 候选实体的选择
在实验过程中,为了减少实验的时空复杂度,在每一个指称mi的候选实体集合中,按照Ganea等[10]提出的方法,仅保留7位候选实体。本文在此基础之上,对于每一个指称mi,利用式(15)选出得分最高的前4位作为候选实体。
4.3 实验设置
4.3.1参数设置
在实验中,使用数据集AIDA-train进行训练,AIDA-A进行验证,使用AIDA-B和其他的数据集进行测试。使用最新的英文维基百科转储作为本文引用的KB。
表4展示实验相关参数设置。在输入端[5],使用标准Word2vec工具包[27]在维基百科上对单词嵌入进行预训练,向量维数设置为300、上下文窗口大小为21、负样本数为10、迭代次数为10。本文首先选取一个指称在文档中的前后各20个单词作为指称上下文,然后根据式(9)选择得分最高的10个单词作为修剪后的指称上下文。大多数候选实体描述文档的文本内容是不超过200个单词的,所以本文首先选取候选实体描述的前200个单词,然后根据式(10)选取得分最高的前100的单词作为修剪后的候选实体描述。为了学习输入指称和候选实体的上下文表示,采用窗口大小为3×3的64个滤波器和ReLU激活函数的CNN,学习指称和候选实体的分布式表示。
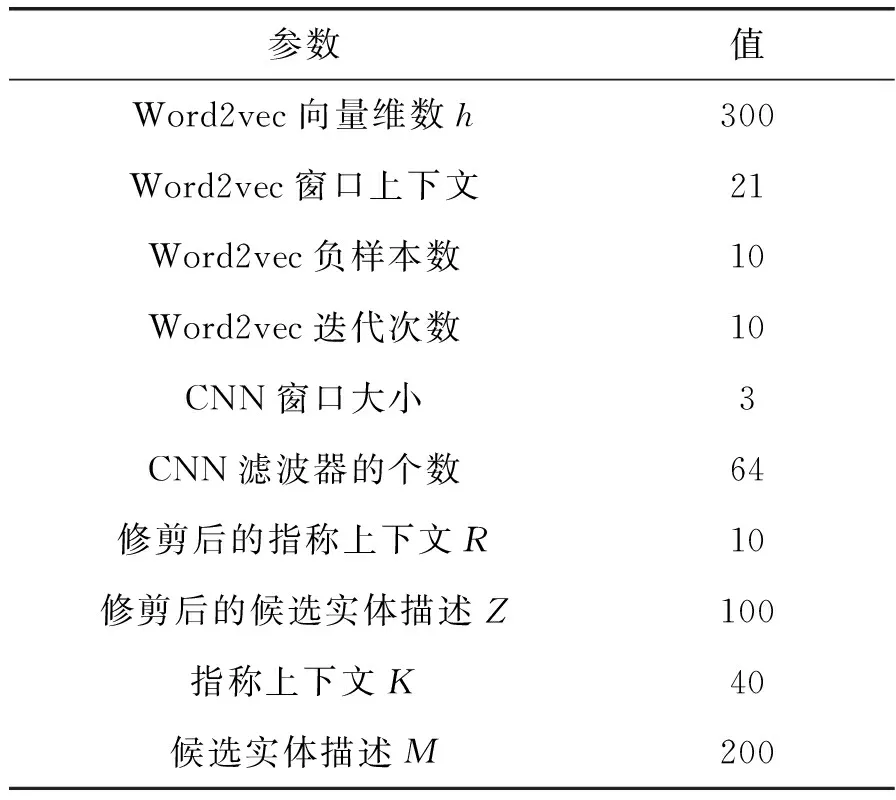
表4 实验参数设置
4.3.2实验环境设置
本文实验环境为:Windows7 64位系统,物理内存为64 GB,使用独立显卡芯片:NVIDIA GeForce RTX 2080 Ti,显存容量为11 GB。使用深度学习框架Pytorch进行实验代码编写。
4.4 评价指标
本文采用F1值对实体链接结果进行评价,评价标准如式(24)-式(26)所示[32]。
(24)
(25)
(26)
式中:P为实体链接的准确率;R为实体链接的召回率;DPactual为真实结果;DPexpected为实体链接得到的结果。
4.5 结果分析
4.5.1Att-RRW和相关工作的对比实验
由于在AIDA-CoNLL数据集上使用AIDA-train数据集进行训练,所以,首先在AIDA-B测试数据集上进行性能比较,实验结果如表5所示。对比现阶段流行的实体链接方法发现,Att-RRW的F1值高于Deep-ED[10]和RWNED[26]的方法,略低于Ment-Norm[25]的方法,他的方法中用到了实体之间潜在的关系信息,这种增量信息可以用来提升本文方法。

表5 AIDA-B数据集上不同方法的F1值
为了更加全面地验证Att-RRW方法的实验效果,除了AIDA-CoNLL数据集,本文还在另外三个数据集上进行验证,实验结果如表6所示。对比其他三种实体链接方法,Att-RRW在MSNBC、 ACE2004、CWEB三种数据集上都取了最优异的效果,平均(Avg)F1值都提高了2百分点左右。其中,MSNBC数据集中EL任务的F1超过95%,比其他方法提升了2百分点;针对ACE2004数据集,Att-RRW实现EL任务的F1为91.3%,而对比方法的F1值均低于90%;由于CWEB数据集上数据相对较大,含有较大的噪声,因此在CWEB数据集中,Att-RRW的F1值最低,超过了80%,其他方法的F1值均低于80%。表6的实验结果进一步验证了Att-RRW方法的有效性和优越性。

表6 不同数据集上EL不同方法的F1值(%)
表7为一个案例。noA-local方法表示Att-RRW方法在局部兼容性环节计算单个指称和候选实体的局部相关性时删除协同注意力机制,同时不包含递归随机游走策略计算全局相关性,仅关注局部相关性。由于noA-local获取的特征比较稀疏,所以导致指称(“chestnut”)链接错误。Att-RRW可以有效地识别正确的实体,使正确的链接实体“Equine coat color”比其他候选实体得到更高的得分。
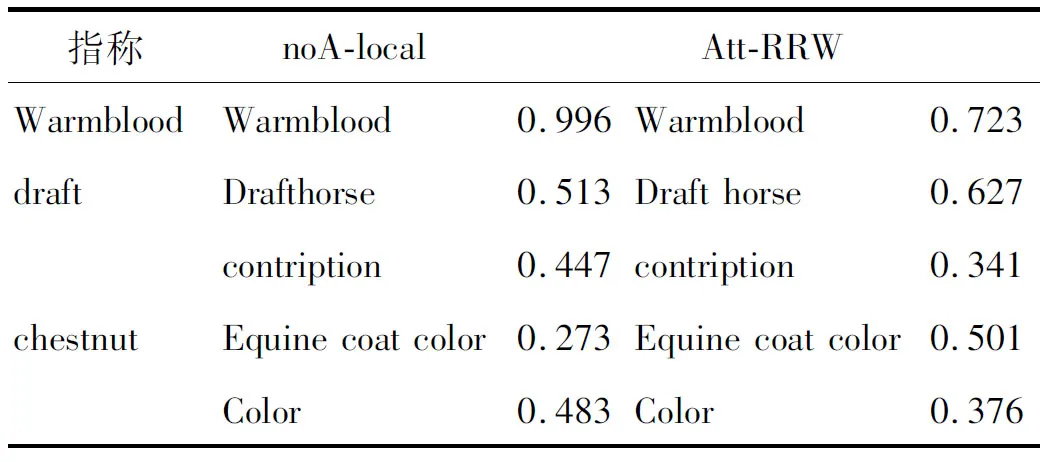
表7 预测实体分布的例子
基于协同注意力机制和递归随机游走的实体链接方法(Att-RRW)不同于其他方法,不再仅从一个侧面使用注意力,而是使用指称上下文和候选实体描述的协同注意力,获得丰富的局部信息,有效地降低指称上下文和候选实体描述的内容稀疏性。递归随机游走实现集成实体链接,利用指称之间的一致性信息提升了实体链接方法的效果。
4.5.2不同Att-RRW方法对比实验
Att-RRW由局部兼容性和集成实体链接两部分构成,局部兼容性为了提高单个指称上下文和对应候选实体的实体描述之间的局部相关性,引入协同注意力机制选择最相关的单词计算局部相关性;集成实体链接采用递归随机游走策略提高所有指称-实体链接对匹配的全局相关性,从而实现所有指称-实体链接决策的全局一致性。本文进一步在AIDA-B、MSNBC、ACE2004和CWEB四种数据集中验证协同注意力机制和递归随机游走策略对Att-RRW实现EL任务准确度的影响,实验结果如表8所示。其中,A-local方法与noA-local方法类似,表示不包含递归随机游走策略的Att-RRW方法,但是在局部兼容性环节加入协同注意力机制。
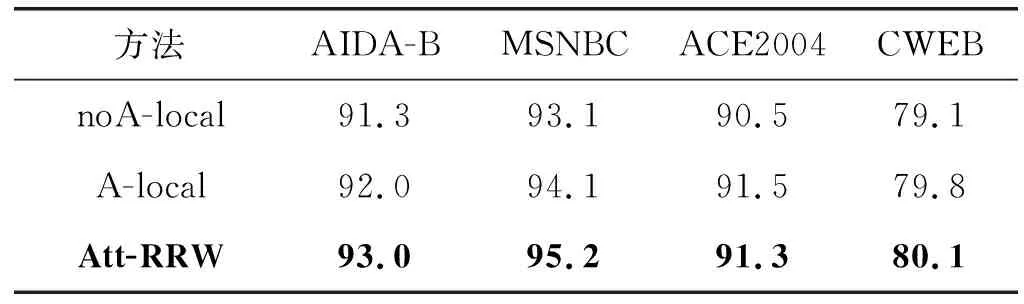
表8 多种数据集上Att-RRW不同方法F1值(%)
(1) 协同注意力机制的影响。从表8中可知,对比noA-local和A-local方法,加入了协同注意力机制的 A-local方法在多种数据集下都提升EL任务的准确度。在所有数据集上,A-local方法比noA-local方法展现了更优的实验效果,表明聚焦指称和候选实体中更为关键的信息的协同注意力机制能够提高实体链接的准确度,从而说明Att-RRW方法中协同注意力机制的有效性和必要性。
(2) 递归随机游走的影响。对比A-local和Att-RRW方法,从表8可知,在四个数据集上Att-RRW方法能够更好地完成实体链接任务,相应的F1值均比A-local方法有所提升。相对A-local局部实体链接方法,Att-RRW方法中递归随机游走策略将局部兼容性和实体之间的一致性结合起来实现集成消歧,能够显著提升实体链接任务的准确度,从而验证Att-RRW中加入递归随机游走策略的有效性和必要性。
综上所述,本文实验不仅分析了Att-RRW方法的整体性能,还分析了协同注意力和递归随机游走对于实验结果的影响。通过上面的分析可以看出,Att-RRW方法的协同注意力扩大了注意的范围,聚焦了指称和候选实体中更为关键的信息。递归随机游走实现了一个文档中的所有指称共同进行消歧。协同注意力和递归随机游走都对提升实验效果有一定的影响。在不同数据集上,与多种方法进行比较,可以看出Att-RRW总体性能是最优的。
5 结 语
为进一步提高实体链接的准确性,本文提出一种基于协同注意力机制和递归随机游走的实体链接方法(Att-RRW)。协同注意力机制聚焦了对实体链接更为关键的信息,递归随机游走传递实体链接的全局信息,增强了实体链接的效果。实验结果和深入分析有力地证明了Att-RRW方法的有效性。
Att-RRW方法通常适用于其他类似EL的任务,如词义消歧、跨语言消歧和词汇选择。集成实体链接方法的使用增加了实体链接的复杂度,未来我们将采用一些优化算法,减少方法的复杂度,同时充分利用维基百科的其他资源来优化Att-RRW中的特征选取。
