面向时间序列相似性的疾病风险评估模型
2022-08-29陈庆奎
沈 彧,陈庆奎
(上海理工大学 光电信息与计算机工程学院,上海200093)
E-mail:chenqingkui@usst.edu.cn
1 引 言
不良的生活规律严重危害着老年人的身体健康,同时成为产生疾病的主要因素.如何在养老照护的过程中对老年人的日常行为进行风险评估成为当下养老问题的关键环节.目前,老人日常行为的数据多采用各类传感器进行收集,传感时序数据构成的时间序列成为研究老人行为风险的依据.
时间序列是一种常见的数据类型,由一系列按照时间顺序排列的、从观测对象获取到的观测值组成.时间序列数据存在于许多应用领域,例如计算生物学、医学诊断分析、经济学等[1-4].时间序列的相似性度量用来衡量不同时间序列之间的相互关系,从中挖掘有用信息并将其结果用于分类、聚类、模式识别等方面[5-7],是时间序列领域中的研究热点,也是研究其他相关任务的基础.
时间序列相似性度量方法的性能将直接影响后期数据挖掘的效果.目前常用的时间序列相似度度量分别是欧式距离(ED)与动态时间弯曲(DTW)[8],ED应用广泛且计算简单,但只能度量长度相同的时间序列,且对形态变化过于敏感;DTW由Berndt等[9]提出并将其应用到时间序列数据挖掘领域中.这种方法不仅可以实现不等长时间序列间的度量,而且对于时间序列的偏移、振幅变化等情况具有较强的鲁棒性.虽然动态时间弯曲拥有上述优势,但仍存在局限性.动态时间弯曲计算距离的时间复杂度为O(n2),对于处理海量的高维时间序列来说,计算成本过高.此外,动态时间弯曲在匹配过程返回全局最优匹配路径,往往会忽略时间序列局部的形态特征,造成一定的不合理匹配[10].
针对上述问题,该领域的学者提出了大量基于DTW的改进方法.Sakoe等人[11]提出通过形成对称的窗口来限制匹配路径的搜索范围,窗口宽度由参数决定,一般为时间序列长度的一定比例;类似地,Itakura[12]等人提出了平行四边形的弯曲窗口,进一步缩小了允许路径弯曲的范围,从而提升了计算效率;Jeong等人[13]提出了WDTW,在计算时对参考点和测试点之间的相位差较高的点进行惩罚,以防止异常值导致的最小距离失真,但如何根据不同情况确定权重是一个难题.
现实情况下老人的行为监测序列往往是多维度的,如何对多元时间序列进行相似性挖掘具有重要的实际意义.目前针对多元时间序列的DTW算法主要分为两类.一类对多元时间序列分段拟合,对每个拟合段求取总误差作为DTW的一个元素,再应用DTW算法进行累积距离的计算;另一类则对每一维时间序列应用差分、归一化处理后分别计算各维度的距离,按一定的方式拟合计算累积距离得到最终计算结果.
本文的目标是设计一个具有适用于评判老人生活状态的多元时间序列相似性度量,从而完成对老人疾病风险的评估,为养老机构提供决策辅助.为更精准地对老人的日常行为进行风险评估,本文首先对DTW算法进行改进,提出多元分段加权时间序列度量方法(Multi Segment Weighted Dynamic Time Warping,MSW-DTW),然后依据相似性度量方法提出老人风险评估模型,最后通过实验对所提方法进行有效性分析.
2 相关技术
定义1.时间序列:时间序列(time series,简称TS)是指一系列数值xt(j)按照时间先后顺序排序而形成的序列,其中t(t=1,2,…,n)表示第t个时间点,j(j=1,2,…,m)表示第j个属性变量,xt(j)表示t时刻第j个属性的数值.当m=1时,是一元时间序列(UTS),当m>1时,为多元时间序列(MTS).
定义2.时间序列数据集:给定一个时间序列数据集D={T1,T2,…,Tn}(n=1,2,…,m),其中m为TS的个数.
定义3.动态时间弯曲:动态时间弯曲(DTW)算法是一种模式匹配算法[14],通过利用动态规划的方法寻找两条时间序列之间的最优弯曲路径,序列中的点根据坐标去匹配另一条序列中最具有相同特征的点,最优弯曲路径的累加和即为所有匹配的数据点之间的距离和.
从数据集D中选定两条时间序列X=(x1,x2,…,xm)和Y=(y1,y2,…,yn),其中m和n分别是两条时间序列的长度.根据两条时间序列构造成1个m×n的距离矩阵Dm×n:
(1)
在距离矩阵中,dij元素是通过xi和yj坐标距离的计算得到的,其计算过程为:
dij=‖xi-yj‖ω
(2)
当ω=2即为欧式距离.
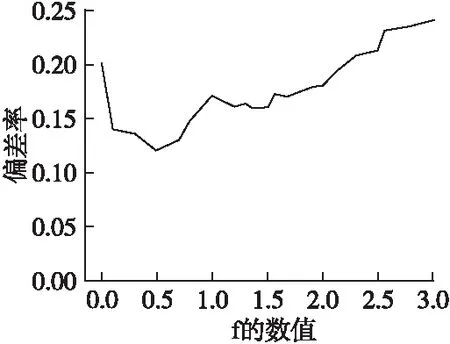
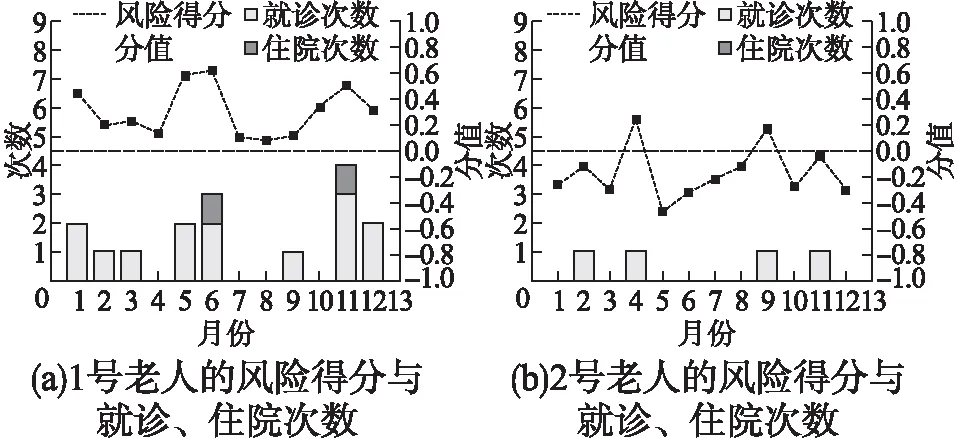
两条时间序列间的DTW距离是通过距离矩阵寻找到累积距离最小的弯曲路径:Pbest={p1,p2,…,pU},pk(k 在路径搜索过程中,DTW受到以下3个约束: 1)路径的边界性:p1=(1,1),pU=(m,n) 2)路径的单调性:给定pk=(i,j),pk+1=(i′,j′),有i′≥i,j′≥j 3)路径的连续性:给定pk=(i,j),pk+1=(i′,j′),有i′≤i+1,j′≤j+1 公式(3)展示了DTW算法的初始条件,式(4)展示了DTW算法的递推关系: (3) (4) 其中γ(xi,yi)为匹配序列上两点xi,yj的成本,常用欧式距离计算,迭代计算直至序列尾端后得到最小累积代价,为了得到最优弯曲路径,再反向寻找弯曲路径,直到i=j=1时,寻找过程结束,最终得到完整的弯曲路径. 由于老人的传感监测数据频次不一,状态监测序列长度不一,而欧氏距离只能计算等长时间序列间的距离,而动态时间弯曲除了可以计算等长时间序列间的距离,还能计算不等长时间序列间的距离,因此对于老人状态监测序列需要应用动态时间规整的思路进行计算. 定义4.离散小波变换:小波变换能够通过对信号在频域和时域上的局部变换有效提取信号的时频信息.离散小波变换(DWT)[15]是小波变换的一种,将连续的小波离散化,对基本小波的尺度和平移进行离散化,通过基函数表示原始信号.在图像处理[16]中,常采用二进小波作为小波变换函数,即使用2的整数次幂进行划分.离散小波的基本函数有两种类型:尺度函数(φ)和细节函数(ψ),分别如公式(5)和公式(6)所示: φj,k=φ(2jt-k),∑φ(t)dt=1 (5) ψj,k=ψ(2jt-k),∑ψ(t)dt=0 (6) 其中j是分解级别指数,k=1,2,…,L表示滤波器的大小,将输入的时间序列T={t1,t2,…,tN}和滤波器的系统函数卷积得到两个卷积的结果得到的两个结果分别进行系数为2的下采样得到两个分量.从低通滤波器获得的分量称为近似分量cj,k,从高通滤波器获得的分量称为细节分量dj,k. (7) (8) 其中Lj=(2j-1)(L-1),近似分量cj,k与原始时间序列数据的局部平均值成比例,因此近似分量与原时间序列数据有相同的趋势;细节系数dj,k与时间方向上的时间序列数据的局部波动值成比例,表示原始时间序列数据的方向变化. 本文使用Haar小波函数作为基函数来识别时间序列的趋势及其细节波动.Haar小波函数相对简单且计算速度快,是使用最广泛的基函数,其具体定义如公式(9)和公式(10)所示: (9) (10) 其中ψ(t)是细节函数(母小波),φ(t)是尺度函数(父小波).与其他小波变换相比,DWT具有许多优势.比如,原始小波变换无法将原始时间序列数据与比例系数部分进行比较,因为分解之前的原始时间序列的长度与分解之后的比例系数部分的长度不同.但是,由于DWT进行的是恒定变换,不会损坏原始时间序列数据中的模式.而且与原始的小波变换不同,它还可以处理不同的样本大小.因此,通过使用DWT,可以提取具有与原始时间序列相同长度的系数,从而能够计算原始时间序列数据和相同长度的转换数据之间的残差,可以为评判变换结果是否有效提供依据. DTW能在某些约束条件下找到全局最优对齐方式.但是它忽略了时间序列的局部形态信息,而时间序列的局部形态信息正是老人生活规律的有效反映,因此DTW在老人生活状态监测序列上的应用存在很大局限.因此,本文提出了分段加权动态时间规整算法(SW-DTW),通过离散小波变换将时间序列分解为尺度部分和细节部分,并对细节部分进行基于局部极值的预处理,在尽可能保存形态信息的同时降低算法的时间消耗,同时在匹配的过程中根据匹配点之间的相位差异进行加权. 3.1.1 时间序列分解 由于老人的行为监测序列复杂度较高,难以准确地进行动态匹配,因此本文在进行距离计算之前对监测序列进行分解,以便实现合理的局部对齐路径. 给定一条一元时间序列,使用Haar小波变换分解得到尺度部分和细节部分,尺度部分为时间序列卷积通过低通滤波器得到,反映了原序列的大致形态和整体趋势;而细节部分为时间序列卷积通过高通滤波器得到,表示序列在细节上的波动.根据DWT的性质,对尺度部分进一步分解能够得到更加详细的尺度部分与细节部分,并且这个过程可以一直持续下去,但是多维分解会大大增加算法的时间复杂度,因此本文仅采用一次分解,图1示出了时间序列的一次分解过程. 图1 离散小波变换分解时间序列Fig.1 Discrete wavelet transform to decompose time series 在一般的信号处理中,对于每个层级的得到的滤波结果都会进行下采样(down-sampling)处理,而使尺度部分和细节部分能够涵盖尽量多的信息,本文对滤波分解的初始结果没有进行直接采样,因此原序列的长度与尺度部分、细节部分的长度相等. 3.1.2 基于局部极值的处理 经分解后的尺度部分体现了时间序列数据的变化趋势,整体较为平滑;而细节部分体现了细节信息,整体波动较大,难以进行准确地动态匹配,因此在进行距离计算之前,需要对细节部分进行处理.为了能更准确地保留形态特征,我们依据两部分序列的交点来分割时间序列,而不是传统的固定步长式的分段方式,此做法的优点是能够将时间序列的波峰、波谷、拐点进行物理划分,从而获得更好的曲翘路径. 如图2所示,在具体实现过程中,使用原时间序列与尺度部分的交点作为时间段点,这些点也是细节序列部分数值符号发生改变的点.细节部分本身就是原序列与尺度部分的差值,这样划分让细节部分在每段区间保持同正或同负,在分段区间内形成峰或者谷,让序列局部结构更加清晰,便于后续拟合. 图2 序列分段示意图Fig.2 Sequence segment diagram 时间序列的形状通常取决于局部的极大值与极小值,因此提取序列的极值特征可以捕获时间序列的整体形状,利用时间序列的局部极值特征对整体序列进行规整,能够保留时间序列本身的形状特征,在保留大部分特征信息的情况下提升运行效率. 图3示出了拟合结果,可见使用局部极值进行拟合能够保持时间序列趋势的变化,同时序列在时间序列的一些常见失真(例如缩放和移位)情况下也能保持健壮.整个检测局部极值的处理过程是按线性顺序进行的,并且在内存消耗方面是恒定的,保证了处理的高效率. 图3 细节部分拟合效果Fig.3 Fitting effect of details 3.1.3 加权动态匹配 DTW距离通过动态规划找到了曲翘路径,能够使得两个时间序列之间的全局距离最小,但是往往在匹配的过程中会忽略局部形态结构,造成局部过度弯曲的情况.图4展示了对一组老人运动量监测序列的匹配情况,图4(a)为DTW匹配结果,图4(b)为SW-DTW匹配结果,图中方框标出的是代表相似生活规律的序列片段.由图可见,图4(a)中两条序列相似的形态片段在匹配过程中并未对应,可见DTW很难识别这种相似的行为规律. 图4 序列匹配结果Fig.4 Sequence matching result 假设p,q分别为P,Q时间序列上的点,本文在此给出自适应惩罚函数wp-q的定义: (11) 其中|p-q|表示p与q点之间的相位差,wmax是权重参数的上限值,l是时间序列的长度,f是控制值域的正参数,控制对非合理匹配的惩罚力度,x表示发生单点重复匹配的次数. 在匹配开始之前,建立两个零矩阵A=(aij)l*l,B=(bi,j)l*l在规划最佳路径时,使用矩阵不断记录对应序列在当前点发生单点重复匹配的次数,例如在最佳匹配路径DTW(s,t)上,序列P上的ps被重复匹配了as,t次,序列Q上的qt被重复匹配了bs,t次.无论匹配点的之间的相位差多大,原始DTW对于所有匹配点之间的计算都是直接使用基距离. 为了减少不合理匹配,本文定义了惩罚函数(3.1)对基距离进行加权,减少异常匹配引起的最小距离失真.时间序列的相邻点构成了局部形态,往往包含重要的结构信息,因此SW-DTW的核心思想是对于未发生大量单点重复匹配的相邻点施加较小的惩罚值,否则将施加较大的权重.因此,两个序列之间的最佳距离定义为所有可能路径上的最小加权路径,递推关系式如公式(12)所示: (12) SW-DTW包括3个步骤:离散小波分解、局部极值提取、相似性距离计算,其时间复杂度TC(SW-DTW)等于每个步骤的时间复杂度之和. 一维离散小波变换的时间消耗是线性的,因此第一部分的时间复杂度是O(n);局部极值提取的具体过程是从第一个点到最后一个点遍历原始时间序列,并检测局部极值,它花费的时间与原始时间序列的长度成线性关系,时间复杂度为O(n);相似性距离的计算分为尺度部分的计算和细节部分的计算.尺度部分计算的时间复杂度为O(n2),而细节部分经过降维,长度变为l(l≪n),尺度部分计算的时间复杂度为O(l2). TC(SW-DTW)=O(n)+O(n)+O(n2)+O(l2)=O(n2) (13) 由公式(13)可知,SW-DTW的计算复杂度在近似表示的长度上为二次量级,与DTW相近. 由于实际环境中,老人的监测数据是随机缺失的,某个时刻的某一项监测数据可能存在缺失情况,将多维时间序列转化为一维时间序列会产生对应监测参数错位的情况,加之计算每一维对应时间序列的累积误差更能说明两条时间序列的相似性,故本文采用的对一元时间序列相似度进行加权累加的方法来完成对多元时间序列相似度的计算. 就拿诊后服务来说,门诊患者服务中心的热线电话涵盖诊后咨询、解难答疑等就医相关服务,如有特殊需求的患者,还可提供医护人员专业上门服务。同时,利用门诊微信公众号,定时向患者推送门诊信息,包括患者健康宣教、门诊动态、社区医疗等,每月开展一次健康知识小讲堂活动,对群众关注的热点、常见病等进行宣教,提高群众预防保健意识,促进健康。 本文相关专家意见确定了描述老人生活状态的五个属性,分别是运动量(SP)、饮食量(DI)、睡眠量(SL)、服药量(P)和排泄次数(TO).这些因素对老人的健康有着不同程度的影响,因此在计算多元时间序列距离之前还需要确定合适的权重. 3.3.1 照护属性权重定义 变量间相关性是指在MTS中,一个变量的特征在其余变量中也可能有所体现.在对MTS进行相似性度量时,如果未考虑到变量间的相关性,可能会造成大量信息丢失,使度量结果不准确.因此,对于具有变量相关性的MTS,需要消除MTS变量间的相关性,将2个MTS序列转换至同个维度空间,保持同构性. 为消除老人状态属性间的相关影响,本文通过主成分分析法(PCA)计算得到相关系数矩阵及其特征向量和特征值,再根据主成分的方差贡献率计算得到权重,权重计算的具体过程如下: 1)对原始老人监测数据进行清洗和标准划处理 2)计算相关系数矩阵 3)计算相关系数矩阵的特征向量与特征值 特征向量A可以表示为: (14) 将计算得到的特征值按照从大到小的顺序排列,依次为λ1,λ2,…,λn. 4)选择主成分并计算其贡献率,主成分表示如公式(15)所示: Mi=a1iSP+a2iDI+…+aniTO,i=1,2,…,n (15) 每个主成分中老人状态属性的系数是相关系数矩阵特征向量的列,其中各主成分的贡献率如公式(16)所示: (16) 5)计算各个状态属性的权值.设主成分有n(n≦5)个,则运动量、饮食量、睡眠量、服药量和排泄次数的权重值如公式(17)所示: (17) 3.3.2 多元时间序列累积距离计算 对于不同的老人,其生活状态监测属性对相似性度量的影响不同,本文采用加权累加的方式进行多元时间序列的相似性度量. 将老人的多元生活状态监测时间序列表示为X={{S1(1),S2(1),…,Sn(1)},…,{S1(t),S2(t),…,Sn(t)}},其中n为老人状态属性的数量,t为时间序列的长度. (18) 其中:对于i=1,2,…,t,j=1,2,…,t′,用dk(i,j)表示r(A(1:i),B(1:j)).而最终的多元序列累加距离用r来表示,即: (19) 依据MSW-DTW算法,本文提出一种疾病风险评估模型.在历史数据中,将发生就诊行为的老人序列作为正例,将未发生就诊行为的老人序列作为负例.对待评估老人监测序列进行K近邻搜索,根据搜索结果计算出待评估老人的风险得分. 对老人进行风险评估存在两个问题:1)由于老人的身体状态会发生阶段性的变化,因此对于老人的风险评估具有时效性;2)序列长度过长导致计算量增大,运行缓慢.因此本文构造滑动窗口来对长序列进行分割,并对历史数据进行分割,将分割后的时间段内存在就诊行为的子序列放入正例集,不存在就诊行为的子序列放入负例集,如图5所示. 图5 老人疾病风险评估模型Fig.5 Elderly disease risk assessment model 设定一老人状态监测序列的长度为t,具体表示为X={{S1(1),S2(1),…,Sn(1)},…,{S1(t),S2(t),…,Sn(t)}},滑动窗口的宽度为w,原序列被划分为{X1,X2,…,Xm}.当i=m时,Xi的长度小于等于m,其余情况下Xi的长度均为w,后续实验中w取经验值30. 风险评估模型分为序列相似性挖掘和风险得分计算两部分.模型中的训练集为有标记的历史数据,其中存在疾病风险的老人样本被标记为正例,身体健康的老人样本被标记为负例.具体步骤如下: 1)对输入的待评估子序列进行K近邻搜索 2)将搜索得到的k个近邻与待评估子序列的相似度距离加入候选集,并按照距离由小到大排序为1,2,…,k 3)候选集内的子序列进行投票得到该老人的风险得分,风险得分的计算过程如公式(20)所示. (20) 其中ci为控制参数,当第i个近邻为正例时,ci为1,当第i个近邻为负例时,ci为-1;di为排序顺序为第i的序列与待评估序列之间的相似度距离. 在相似度查询中,相似度距离越近的序列,说明其代表的老人与待评估序列代表的老人拥有更相似的生活规律,更可能拥有相近的健康状况.因此利用相似性距离和合理地进行加权,同时避免了单点噪声对评价结果的影响,使得评价得到的风险得分更加准确. 实验环境为Windows 7 SP1,512GB 硬盘,8GB 安装内存,Intel Core i7-6770,主频为3.40 GHz. 本文采用YP,PT,XH这3组数据集进行实验(有疾病风险的老人序列为正例,无疾病风险的老人序列为负例).实验数据为来自不同地区养老机构的真实数据,每个数据集包含500~800的老人状态监测序列样本,时间跨度从2018年9月~2020年12月,数据维度包括运动量、饮食量、睡眠量、服药量和排泄次数.为方便后续计算,所有数据均经过清洗并标准化. 本文实验分为两部分,第1部分实验的目的是验证本文提出的多元时间序列相似性度量的有效性;第2部分实验来验证风险评价模型的合理性. 实验1采用K近邻与留一交叉验证法,具体如下:对具有n个样本的 MTS 老人数据集,分别以第i(i=1,2,…,n)个样本作为待匹配样本,然后采用某种相似性度量方法找出与待匹配样本最相似的k个样本(k分别取1、5和10)并统计准确率;实验2对不同实例的风险得分与就诊次数进行比对,从而检验风险评估方法的可行性. 定义1.平均绝对偏差(Mean absolute deviation) 两个翘曲路径之间的差之和除以原始时间序列的长度而获得的值定义为平均绝对偏差: (21) 定义2.偏差率(Error rate) 将算法的近似变形路径距离与最佳变形路径距离相差多少来测量近似DTW算法的精度,称为偏差率: (22) Dist表示采用实验方法计算得到的序列间距离,OptimalDist表示使用原始DTW规划得到的最佳匹配路径的距离.如果近似算法找到的扭曲路径的距离等于最佳扭曲路径的距离,则误差为零,如果近似曲翘路径与最佳曲翘距离的差值大于最佳曲翘距离,则误差将超过100%. 定义3.准确率(Accuracy) 数据集中正例样本和负例样本分类正确的样本的总数占整体样本数量的百分比,公式表示为: (23) 其中TP+TN为预测对的总样本数,P+N代表总样本数. 为了验证所提出的时间序列相似性度量的有效性和可行性,先运用本文提出的SW-DTW及FlatDTW[17]、ShapeDTW[18]、AC-DTW[19]分别在 3 个数据集的各个维度进行实验,统计各一元相似性度量方法运行的偏差率和运行时间;随后再运用本文提出的MSW-DTW与PLR-DTW[20]、CPCA-SWDTW[21]、MSN-WDTW[22]分别在 3 个数据集上进行相似性匹配,统计各算法进行k近邻搜索的准确率. 4.2.1 参数影响 在评估性能之前,应先考虑本文所提出相似性度量中的参数.图6展示了在确定参数a的情况下,检验算法的偏差率随参数f的变化情况. 图6 f值对错误率的影响Fig.6 Effect of f to the error rates 在f值较小时,随着f值的增加,偏差率降低,因为相位差小的匹配点之间被赋予了较大的权重,因此算法更倾向于选择距离更近的候选序列.但是,当f值较大时,偏差率与f值呈正相关.因为当f值过大时,算法对于有相位差的非垂直匹配赋予了过大的惩罚系数,使得算法逐渐靠近欧氏距离测度,而丧失了DTW的动态弯曲特性.因此,SW-DTW应根据应用使用不同的f值来调整每个点的相位差的补偿水平.为了保证算法的性能,选择f=0.5用于后续实验. 4.2.2 结果与分析 在计算多元时间序列相似度之前需要计算各个属性的一元时间序列相似度,因此首先将本文提出的一元时间序列相似性度量SW-DTW与FlatDTW,ShapeDTW,AC-DTW在各维度上进行序列相似度计算,并对比匹配路径的准确度.在计算过程中,当算法动态匹配生成的翘曲路径和人工标注的准确匹配路径的距离越小时,则平均绝对偏差将具有越小的值,算法的性能越好,反之亦然. 如表1所示,在多次实验中,SW-DTW与人工标注的Ground Truth之间的平均绝对误差小于其余3种方法,AC-DTW与ShapeDTW的实验结果较为接近,而FlatDTW的偏差较大.这是由于SW-DTW采用离散小波变换,能对复杂序列进行分解,帮助算法更加准确地依据形态特征进行匹配,同时惩罚函数使得SW-DTW能够适应复杂的时间序列形态,有效提升匹配过程的准确性. 表1 与Ground Truth之间的平均绝对偏差Table 1 Mean absolute deviation from Ground Truth 为了更精确地比较算法运行的准确率,采用偏差率来评价各个属性的相似性度量结果.同时为了进一步控制变量,令四种算法在相同的评估区域百分比下运行.评估区域百分比指的是在算法评估路径中的单元格占全分辨率的所有单元格的百分比,使用这种方法可以比较四种算法在消耗相等计算资源的情况下的运行准确率. 表2示出了各算法进行相似度计算的平均偏差率,可以看出SW-DTW的偏差率在大部分情况下均低于其余算法.在较低的评估区域百分比下,ShapeDTW和SW-DTW的运行准确率要明显高于AC-DTW和FlatDTW,而结合运行的稳定性来看,SW-DTW还要略优于ShapeDTW.SW-DTW的主要优势是对时间序列进行了分解,加强了评估区域对于序列结构的拟合程度. 表2 不同评估区域百分比下的偏差率Table 2 Deviation rate under different assessment area percentages 所有算法完成相似度计算的平均执行时间如表3所示,总体来看FlatDTW的执行效率最高.由于SW-DTW采取分段拟合将序列分为两部分,距离的计算也分为了整体部分的计算和细节部分的计算,因此SW-DTW的处理短序列的执行效率低于其余算法;但在长序列的实验中,SW-DTW的执行效率优于AC-DTW与ShapeDTW,略逊于FlatDTW,可见分段拟合对动态匹配过程的效率提升效果十分明显. 表3 相似性搜索平均搜索时间对比Table 3 Similarity search average search time comparison MSW-DTW与PLR-DTW,CPCA-SWDTW,MSN-WDTW进行K近邻搜索的分类准确率如表4所示.其中,MSW-DTW在所有情况下相似性搜索准确率均高于91%.在k=1时,CPCA-SWDTW、MSN-WDTW 与 MSW-DTW这3种方法的准确率较为接近.但在k=5,10的情况下,MSW-DTW的表现要好于另外两种方法.与另外两种方法相比,MSW-DTW虽然对细节部分进行了降维,但极大保留了局部的形态特征,并有效减少了不合理匹配的发生.因此,从总体上看,MSW-DTW 的整体准确率最高. 如表4所示,随着k值的增加,导致近似误差增加,平均准确率均有所下降;但若k值过小,整体算法的抗噪声能力不足,容易出现过拟合的情况.因此在老人的风险评估过程中,k值取居中的5. 表4 相似性搜索平均准确率对比Table 4 Comparison of average accuracy of similarity search 将YP数据集的两位老人作为输入样本进行实例分析,监测数据维度包括运动量、饮食量、睡眠量、服药量、排泄次数,时间跨度从2020年1月~2020年12月,选择2018年9月~2019年12月的历史数据作为训练集.由于风险评价的准确性难以界定,采用2020年1月~2020年12月的就诊次数作为验证. 如图7(a)所示,1号老人的全年风险得分均大于0,全年就诊次数较多.在风险得分较高的1月、5月、6月、11月,当月的就诊次数明显多于其余月份,尤其在风险得分最高的6月与11月,该老人出现了数次住院的情况;如图7(b)所示,2号老人的风险得分大多为负,仅在4月和9月出现了风险得分为正数的情况,2号老人的整体风险得分低于1号老人,而全年的就诊次数明显少于1号老人,仅在2月,4月,9月与11月各发生一次就诊.整体而言,风险得分与老人就诊的次数呈正相关,风险得分更高的老人更有可能发生就诊,证明利用多元时间序列相似度的对老人进行风险评估是合理可行的. 图7 2020年样本老人风险得分与就诊次数Fig.7 Risk score and number of visits for the sample elderly in 2020 本文提出了一种基于多元时间序列相似性度量的老人疾病风险评估模型,用于评价老人的身体状况.适用于一元序列的SW-DTW将时间序列经过离散小波变换分解为表示整体趋势的部分和表示局部细节的部分,利用局部极值对细节部分进行重构以达到维度缩减的目的,设立一种加权函数,根据时间序列点之间的距离系统地分配权重;MSW-DTW则采用对不同维度的一元相似性距离进行加权累加的方法得到结果.在此基础上,对老人序列进行近邻搜索,将近邻的距离加权计算得到老人的风险得分.实验结果表明,该模型能够准确评价老人的身体状况,具有对老人的突发疾病风险进行预测的巨大潜力.然而,如何在尽量避免损失局部信息、保持相似性匹配的准确性的同时,进一步降低维度、提高计算效率还有待进一步研究.

3 算法描述
3.1 一元时间序列相似性度量SW-DTW

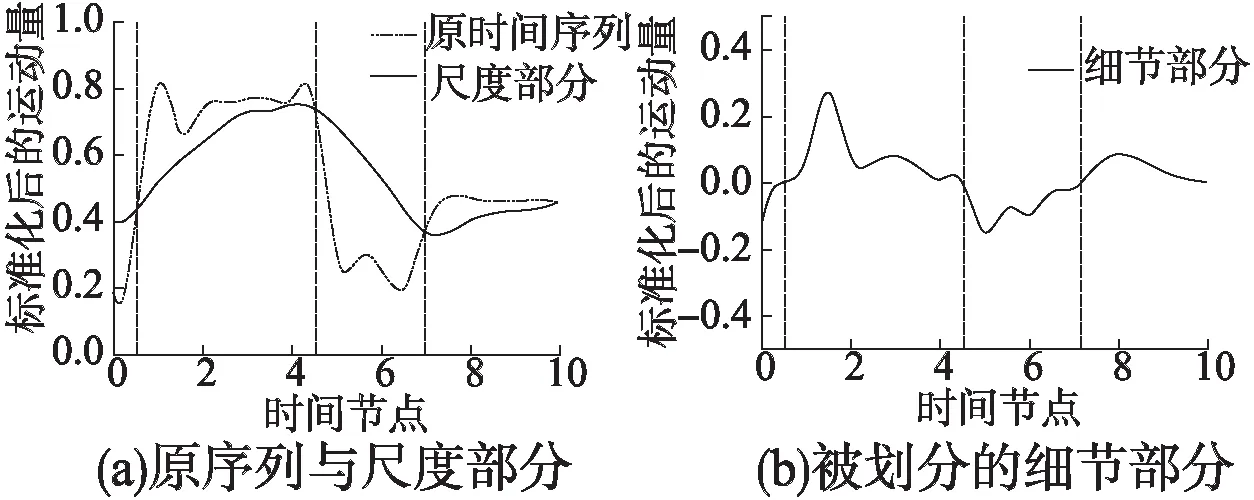
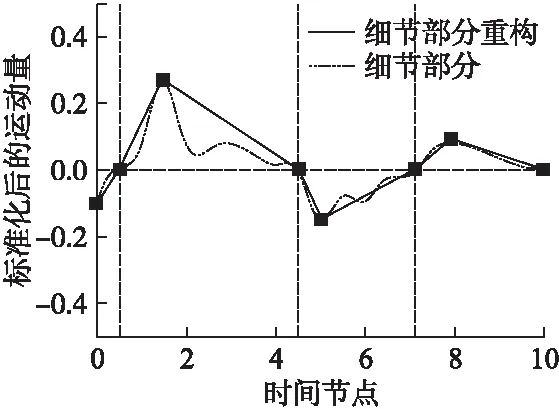
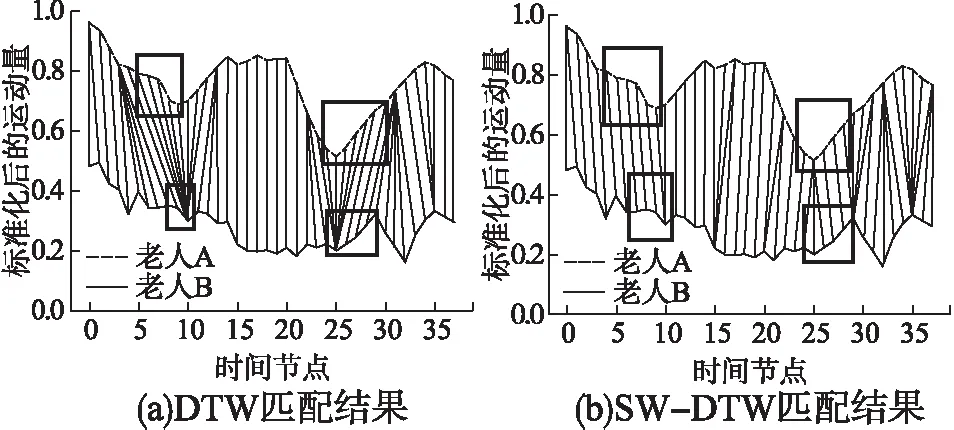
3.2 复杂度分析
3.3 多元时间序列相似性度量MSW-DTW
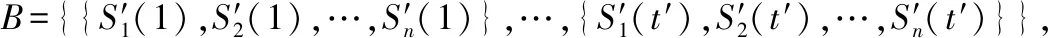
3.4 疾病风险评估

4 实验结果
4.1 评价指标
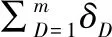
4.2 实验与分析




5 总 结
