基于改进YOLOv4的工件识别*
2022-08-25张建华李克祥
张建华,赵 维,赵 岩,王 唱,李克祥
(河北工业大学机械工程学院,天津 300401)
0 引言
随着工业智能化快速发展,利用视觉技术迅速准确地完成对工业零部件的自动识别,已经成为智能装配领域研究的热点[1-3]。
传统目标检测算法需手动提取目标特征,然后通过分类器进行训练分类。冯长建等[4]提出核心主成分分析(KPCA)与支持向量机(SVM)混合的机械零部件形状识别方法,通过傅立叶描绘子获取零部件轮廓信息,利用KPCA进行特征矢量降维,最后用SVM进行分类。实验表明,该方法对位置分散且形状完整的机械零部件有很高的识别率。王红涛等[5]提出基于边缘匹配的工件识别算法,在利用Canny算法提取图像特征之后,将改进的Hausdorff距离作为特征匹配的相似性度量方法,最后采用自适应代沟替代策略的遗传算法获得距离最优解。实验结果表明,该算法不仅可以加速特征匹配过程,而且提高其抗噪性,可有效解决平移、旋转、部分遮挡等情况下图像匹配识别问题。传统基于特征的工件检测方法存在效率低、手工设计的特征鲁棒性差等问题[6],难以满足现代工业检测需求。
近年来,随着深度学习技术快速发展,上述问题得到一定程度的解决。LIU等[7]将二维工件检测网络PolishNet-2d和三维工件识别网络PolishNet-3d串联使用,完成制造业中抛光工件的识别任务。TANG等[8]利用神经网络检测目标工件角点信息,根据检测概率和角点间几何关系总结规律建立决策树来识别工件类型。KHALID等[9]提出一种全卷积网络结构,根据图像点云信息划分出工件区域和非工件区域,进而检测出工件数量及其位姿信息。YOLOv4[10]结合了大量前人研究技术,加以组合并进行适当创新,实现了速度和精度的完美平衡,是目前性能最优越的目标检测算法之一。但是针对工件的识别问题,因其网络参数规模较大,对于实际工况网络计算速度较慢。
针对上述问题,本文提出一种轻量化目标检测算法改进YOLOv4算法,可以快速、准确地完成工件识别任务。
1 YOLOv4算法原理
与R-CNN[11]和R-FCN[12]等基于候选区域的目标检测算法不同,YOLOv4作为单阶段目标检测算法,将检测视作回归问题,不再生成区域候选框,极大提高了检测速度,可满足生产过程工件实时检测需求。YOLOv4网络结构由输入端、Backbone特征提取网络、Neck中间层和Head输出层4部分组成。
其中,Backbone特征提取网络是CSPDarknet53,由Darknet53和CSPNet[13]结合而成。借鉴CSPNet在降低计算量的同时保持准确性的经验,YOLOv4在各残差块上添加跨阶段局部网络(CSP),将基础层特征映射分为主干和支路两个部分,主干继续堆积原残差块,支路相当于一个残差边,进一步通过跨阶段层级将两部分融合。
Neck中间层包括空间金字塔池化网络(SPP)和路径聚合网络(PAN)结构两个部分。SPP分别利用4个不同尺度的最大池化对上层输出的特征图进行处理,显著增加了感受野,分离最重要的上下文特征并且几乎不会降低YOLOv4的运行速度。高层特征含有语义信息,而低层特征包含更具体的细节信息。借鉴PANet进行参数聚合经验,YOLOv4中PAN层先是利用一条自顶而下信息传输路径捕捉强语义特征,再利用一条自底向上信息传输路径传递细节信息,通过两条路径组合,可很好完成目标检测。
Head输出层用来完成目标检测结果输出。此阶段将输入图像分成网格单元,目标由目标中心点落入的网格单元负责检测,每个单元输出结果为B×(5+C)。其中,B代表一个单元能够预测的边界框数量;C表示预测目标类别数量;5代表四个边界框参数和一个边界框中目标置信度。根据单个网格的输出结果,最终网络输出为S×S×B×(5+C),其中S代表图像中每行或每列的网格数量。
2 改进YOLOv4轻量化高精度工件识别算法
2.1 特征提取网络轻量化
YOLOv4特征提取网络CSPDarknet53在分类准确性上表现优异,但是其缺点是参数量和计算量过大。因此,本文引入轻量化网络Moblienetv3[14]代替CSPDarknet53作为特征提取网络。Moblienetv3网络结构如表1所示。

表1 Moblienetv3网络结构
表中Input为每层输入特征图大小;Operate为每层处理特征图所用方法;bneck为瓶颈结构,由一个卷积核大小为1×1的卷积层和深度可分离卷积层组成;Pool为平均池化操作;NBN代表没有使用批归一化操作;exp size为模块中增加后的通道数;#out为输出通道数;SE表示是否在该bneck模块中使用SE模块;NL为激活函数类型;RE代表ReLU;HS为hard-swish;s为步长。
Moblienetv3网络结构分为3部分。第1层为起始部分,通过1个卷积核大小为3×3的卷积层提取特征;第2到16层为中间部分,由多个bneck结构组成;第17到20层为最后部分,用于输出类别。除去最后部分,剩下的16层作为Moblienetv3的主体结构。在保证各层网络输出特征图尺度不变且训练环境相同的情况下,根据主体结构不同网络层对平均精度均值(mAP)的影响大小,对mAP影响较小的网络层进行剪枝。最后将Moblienetv3的宽度因子设为0.875,进一步减少网络参数量。Moblienetv3主体结构不同网络层对mAP的影响如表2所示。

表2 Moblienetv3主体结构不同网络层对mAP的影响 (%)
由表2可看出,Moblienetv3的第16层对mAP影响最小,其次是第11层,因此本文对这2层网络进行剪枝。
简化后的Moblienetv3网络主体结构如表3所示。
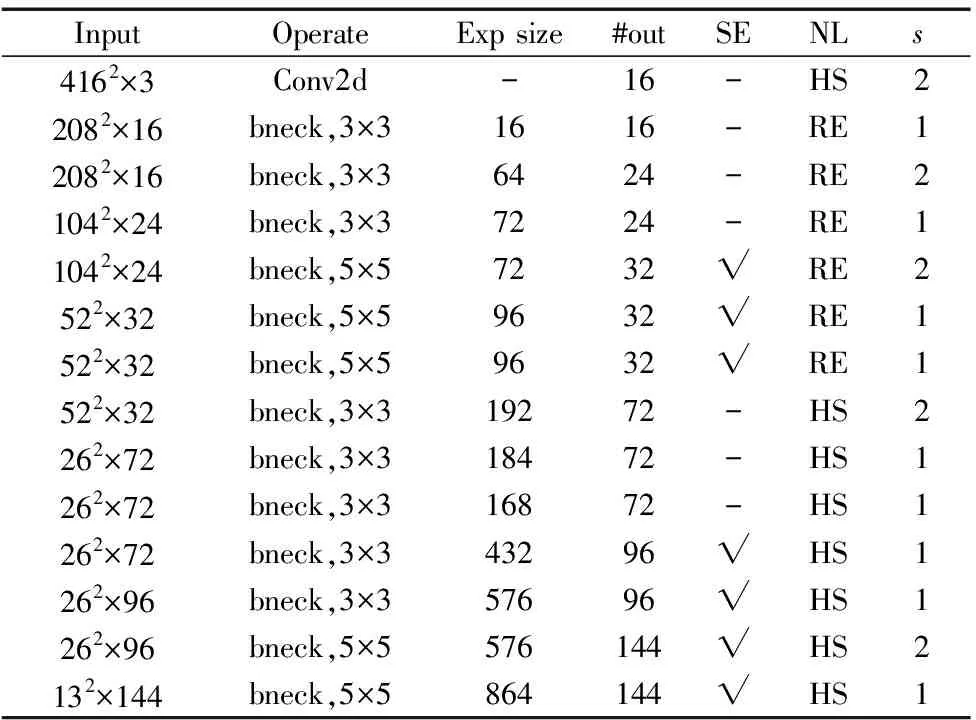
表3 简化后的Moblienetv3主体结构
将CSPDarknet53、Moblienetv3与本文简化后的Moblienetv3网络参数量进行对比,如表4所示。

表4 特征提取网络参数量对比
由表可知,简化后的Moblienetv3网络可达到减少模型更新开销、降低内存占用和计算量的目的。
2.2 改变深层网络卷积方式降低网络计算量
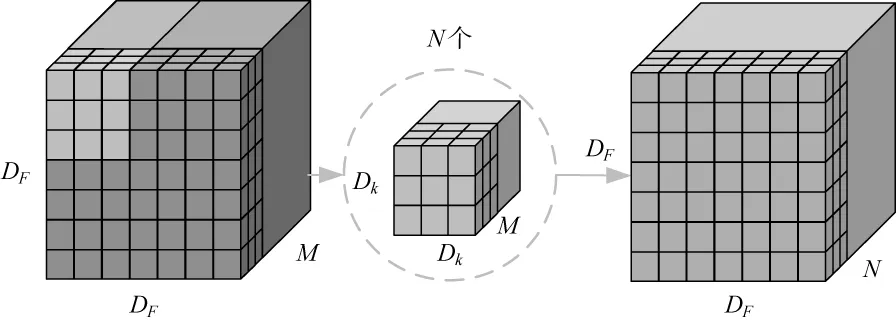
为进一步降低计算量,用深度可分离卷积层替换深层网络的标准卷积层。图1a为标准卷积过程,其输入特征图大小为DF×DF×M,输出特征图大小为DF×DF×N时,总计算量如式(1)所示:
Fs=DF×DF×Dk×Dk×M×N
(1)
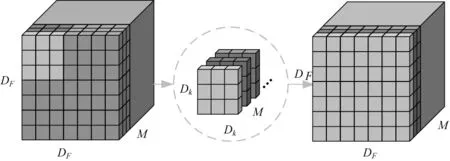
与标准卷积相比,深度可分离卷积将通道和区域分开考虑,将卷积过程分为深度卷积与点卷积。深度卷积过程如图1b所示,其计算量如式(2)所示:
Fd=DF×DF×Dk×Dk×M
(2)
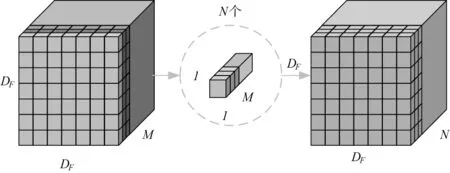
由于深度卷积是将卷积核按通道分解,并且仅在通道之间进行卷积,所以输入和输出的特征图通道数量相同且无法改变。因此需续接一个点卷积,用以改变通道数量。图1c表示点卷积过程,此过程计算量如式(3)所示:
F1=DF×DF×M×N
(3)
将深度可分离卷积与标准卷积的计算量进行比较,如式(4)所示:
(4)
(a) 标准卷积计算过程
(b) 深度卷积计算过程
(c) 点卷积计算过程
可以看出,虽然深度可分离卷积将卷积过程分为两步,但凭借轻量的卷积方式,可极大降低卷积过程计算量。
2.3 增加特征图数量提高检测精度
YOLOv4通过PAN结构输出13×13、26×26、52×52这3种不同尺度的特征图。深层特征图尺寸小、感受野大,有利于检测大尺寸物体。浅层与之相反,更有利于检测小尺寸物体。在实际检测过程中,对于小尺寸物体依然存在漏检情况。因此,为增加浅层细节信息,在YOLOv4结构基础上,增加104×104特征层,并与其他三个特征层进行特征融合,从而提高网络检测精度。
2.4 基于K-means++的Anchor Box重聚类
原始YOLOv4算法的Anchor Box是由K-means算法在COCO和VOC数据集上聚类得出。由于本文采用自制数据集,与COCO和VOC数据集差异较大,原始聚类结果不能代表本文数据,因此需重新对数据集进行聚类,以选出具有代表性的Anchor Box。由于K-means算法存在对初始点选取较敏感、随机选取的初始点对聚类结果影响较大、易陷入局部最优等问题,本文采用K-means++[15]算法对数据集进行重聚类。K-means++算法步骤如下:
步骤1:从数据集X中随机选取一个样本作为初始聚类中心。
步骤2:计算每个样本xi与当前已有聚类中心Ci的距离D(xi)。
D(xi)=1-IOU(xi,Ci)
(5)
步骤3:计算每个样本被选为下一个聚类中心的概率P。
(6)
步骤4:按照轮盘法选出下一个聚类中心。
步骤5:重复步骤2~4,直至选出K个聚类中心。
两种聚类分析算法的精度计算方法如下:计算最后得到K个Anchor Box与bounding box的重叠度(IOU),对于每个bounding box选取其对应最大的IOU值代表其精度,聚类分析算法的精度值为所有IOU值的平均值。两种聚类分析算法的精度对比如表5所示,表明K-means++算法聚类精度更高,获得的Anchor Box更能代表本文数据集。基于K-means++算法获得的Anchor Box值如表6所示。

表5 两种聚类分析算法精度

表6 Anchor Box在特征图上分布
至此,针对工件类型识别任务,完成了本文对YOLOv4网络的改进,搭建了轻量化的改进YOLOv4模型,其结构如图2所示。
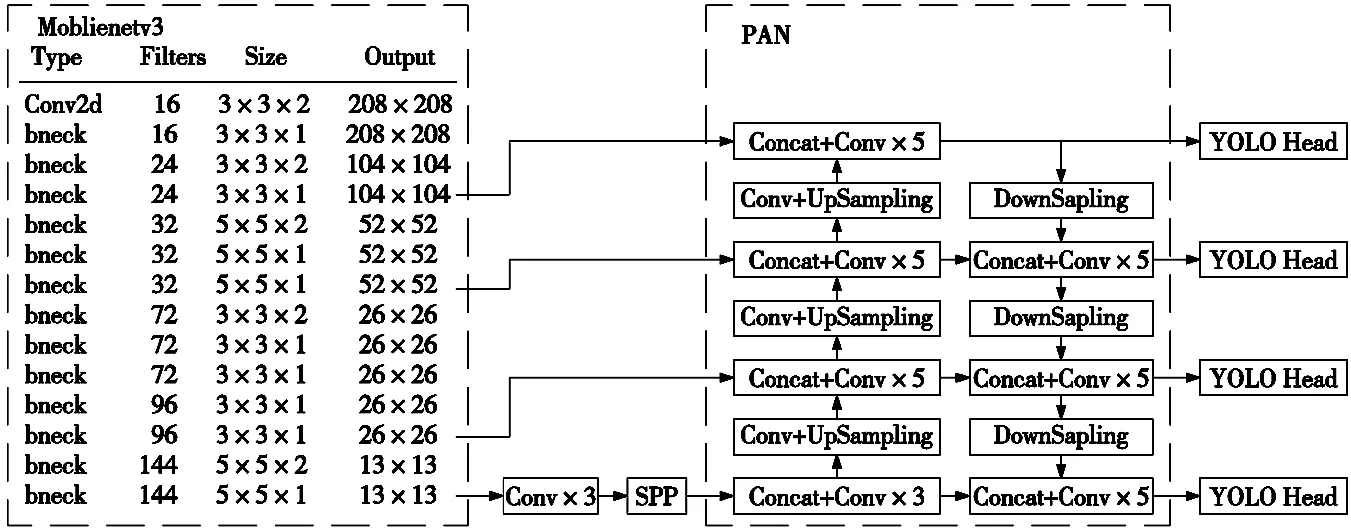
图2 所提出的改进YOLOv4网络结构
3 实验与结果分析
3.1 样本集构建
为验证所提出的改进YOLOv4目标检测算法的有效性,通过图像采集和图像标注创建具有3类工件图像样本(六角螺栓、六角螺母、轴)的数据集。
首先,搭建图3a所示图像采集平台,利用工业相机(海康威视MV-CA060-10GC,最大分辨率为3270×2048)采集图像4100张,采集的部分图像如图3b所示,用Labelimg软件对图像进行手工标注。然后,进行数据增广,对图像进行翻转、镜像、亮度和对比度变换,将图像扩充至24 000张。并将数据集分为3组,其中训练集18 000张,验证集2000张,测试集4000张。

(a) 图像采集平台 (b) 数据集部分图像
3.2 网络训练及评价指标
3.2.1 网络训练
网络模型采用分阶段训练策略:第一阶段为冻结训练,因神经网络主干特征提取部分所提取的特征具有通用性,故冻结特征提取网络,以提高训练效率,同时可以防止权值被破坏。第二阶段为解冻后训练。两个阶段的超参数如表7所示。

表7 模型训练参数
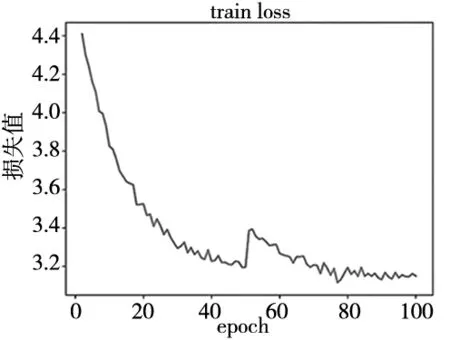
图4 训练过程损失变化曲线
表中,Momentum表示动量参数,可在梯度下降算法中加速模型收敛;Weight-decay表示权重衰减系数,可有效限制参数变化幅度,起到一定正则作用;Base learning rate表示基础学习率,决定权值的更新速度;Batch size表示每批次训练样本量大小;Epoch表示全部训练样本训练次数。总训练次数为100个Epoch,损失值变化曲线如图4所示。
3.2.2 评价指标
选择每秒传输帧数(fps)度量模型检测速度,模型参数量(Params size)作为模型规模大小参数,平均精度均值(mAP)衡量检测精度。
AP值是P-R曲线的包围面积,mAP为所有类别AP值的均值。P代表精确率,R代表召回率。P、R的计算方法如式(7)、式(8)所示:
P=TP/(TP+FP)
(7)
R=TP/(TP+FN)
(8)
式中,TP代表实际为正类且预测为正类的样本数量;FP代表实际为负类但预测为正类的样本数量;FN代表实际为正类但预测为负类的样本数量。
3.3 实验结果分析
改进YOLOv4算法工件识别结果如图5所示。

图5 工件识别结果
将改进YOLOv4算法与原始YOLOv4算法进行对比,在测试集上进行测试,对比结果如表8所示。

表8 改进YOLOv4与原始YOLOv4对比结果
结果表明,在模型参数规模方面,YOLOv4算法的模型参数量为244.29 MB,改进YOLOv4算法模型参数量为31.52 MB,降低了87.10%;在检测速度方面,YOLOv4的检测速度为30.51 fps,改进YOLOv4达到42.67 fps,提升了39.86%,可达到实时检测需求。虽然与YOLOv4相比,改进YOLOv4检测精度略有降低,但依然达到98.00%,可满足实用需求。
4 结束语
针对工业机器人生产过程中自动工件识别需求,提出一种轻量化目标检测网络改进YOLOv4算法,实现工件自动识别。与YOLOv4算法相比,所提出的算法引入简化的Moblienetv3作为主干特征提取网络,采用深度可分离卷积层代替深层网络中标准卷积层,降低网络参数量,并使用K-means++算法对数据集进行重聚类获取更有代表性的Anchor Box,同时在特征融合结构中增加104×104特征检测尺度并与另外三个尺度融合,提高工件识别精度。结果表明,改进YOLOv4算法网络参数规模减小87.1%,检测速度提高39.86%,初步满足机器人生产过程中工件自动检测需求。在未来研究中,将进一步针对零件相互堆叠遮挡导致漏检问题,借鉴MAO[16]等解决行人遮挡问题的方法,引入额外特征,如分割信息和边缘信息等,减少工件部分信息缺失对识别影响,提高检测精度。
