基于迁移学习的铝硅合金文献的文本识别
2022-08-25刘英莉李武亮么长慧尹建成
刘英莉,李武亮,牛 琛,么长慧,尹建成,沈 韬
(1.昆明理工大学 云南省计算机技术应用重点实验室,云南 昆明 650500;2.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;3.昆明理工大学 材料科学与工程学院,云南 昆明 650500)
1 前 言
材料作为社会发展的重要物质基础,纵观人类文明发展史,人类欲将改造自然的能力提升到一个新的水平都离不开材料的发现和应用。美国于2011年6月24 日提出材料基因组计划(materials genome initiative,MGI)[1],旨在运用实验能力、计算能力,数据技术更快地获取材料成分-结构-工艺-性能间的关系。如何获取大量有价值的材料数据成为现阶段的关键问题。数据可以来自计算、文献数据、假设、实验,包括来自失败的实验。在过去的几十年里,人们发现大量的科学论文中,包含了大量的材料数据,文献数据提取在许多特定领域都取得了一些进展,如化学和生物医学[2-3],然而可用于机器学习的数据规模很小。因此,在材料基因组计划中,通过机器学习进行材料性能预测不仅要关注机器学习算法本身的研究,而且必须从材料科学文献中提取有价值的材料数据。
自然语言处理(natural language processing,NLP)的目的是使计算机理解并处理用文本输入的命令,被各个领域应用于从非结构化文本中提取的有效信息,并将其进一步处理为结构化信息,从而方便领域研究应用。命名实体识别(named entity recognition,NER)作为NLP领域的基础任务之一,旨在识别文本中包含的可用信息的实体词汇或短语,例如地理位置,组织名称,通用领域中的时间、数字以及特定领域中的专有对象。在材料领域,命名实体识别任务由于其领域实体的特殊性与专业性,实体识别更加困难。2021年,Liu等[4]将命名实体识别(NER)的文本应用于材料科学文献的大规模信息提取,从材料科学文献中提取铝硅合金,铝元素等实体。杨锦锋等[5]在2016年提出中文电子病历的命名实体识别和实体关系的标注体系,为后续研究打下了基础。文献中所关注的材料实体识别任务,可以借鉴命名实体识别在生物医学等特定领域的成功应用,进一步针对材料文本特征研究适用于材料领域的命名实体识别。
在材料领域,Al-Si合金由于质量轻、导热性能好,并且强度、硬度以及耐蚀性能较好,在航空、汽车、冶金等领域[6-9]得到广泛应用。因此,对铝硅合金的研究意义重大,本论文收集整理了铝硅合金数据集,用于材料命名实体识别。
监督学习需要大量有标记的样本集,标注数据是一项耗时耗力的任务。在某些特定领域,例如,材料科学、化学、生物医学等,由于数据采集成本高,标注成本高,难以构建大规模的标注数据集,限制了其发展,而迁移学习的应用[10]能有效解决这一难题。在计算机视觉领域,广泛应用了迁移学习的思想,例如2020年,Liu等[11]利用迁移学习,实现高光谱图像的分类。近几年的研究表明,迁移学习可以扩展到多个领域,包括自然语言处理。2019年,Chen[12]将迁移学习应用于多级生物医学事件的触发识别,提出的方法提高了识别度。2020年,Heinzinger等[13]基于迁移学习成功地从与各种蛋白质预测任务相关的未标记序列数据库中提取信息。
虽然深度学习在一定程度上减少了模型对标注数据的依赖,但为了保证由初始模型判断不确定性的能力,所需的初始标注训练数据量仍然较大。随着预训练语言模型的发展,在NLP领域利用迁移学习将语言模型预训练后运用到特定领域任务中,也可以有效解决庞大的计算资源以及数据缺乏的问题。目前很多自然语言处理任务使用预训练语言模型对大量无标注的数据进行处理,提取到的语言特征对命名实体识别等下游任务模型可以起到很好的辅助作用,这在很大程度上减少了自然语言处理任务对标注语料的依赖。
2 方 法
针对材料领域的NER 任务,从头开始训练神经网络不仅需要大量训练数据,而且非常耗时。随着Transformer[14]的提出,许多基于Transformer的预训练语言模型在众多NLP 任务中取得了远超传统模型的效果。例如,BERT[15]采用基于微调的方法在Transformer编码基础上应用于下游任务,在多项NLP任务上取得了很好的效果。使用未标注数据预训练语言模型应用于铝硅合金实体识别数据集,与深度主动学习相比进一步减少NER 任务对初始标注训练数据的需求。本论文采用 BERT 的变体ALBERT[16]与CRF 模型[17],针对NER 任务进行微调,CRF模型可以用于序列标注等问题,由于其出色的标签约束能力,在各类NER 模型中成为重要的组成部分;并借助主动学习,面向少量标注数据的合金材料实体识别任务进行实验研究。
2.1 数据收集与处理
本文中合金材料实体识别任务主要针对{材料名称、材料元素、材料性能、材料实验方法、材料元素组成比}五个实体类型,具体内容如下:
(1)Material:指一种铝硅合金的材料名称。
(2)Element:指组成铝硅合金的材料元素名称。
(3)Method:指进行材料实验的方法,例如喷射沉积,快速凝固等。
(4)Property:指铝硅合金的材料性能,例如微观组织,物理、化学性能,硬度等。
(5)Com Percent:指铝硅合金中各元素的百分比含量。
本文中合金材料标注语料示例如图1所示。

图1 合金材料命名实体识别手工标注示例Fig.1 An example of manual marking for named entity recognition of alloy materials
语料内容统计如表1示。

表1 合金材料语料库数据统计表Table 1 Corpus data statistics of alloy materials
图1 采用了序列标注,序列标注(Sequence labeling)是NLP中最基础的任务。序列标注就是使用标签对句子中的每个单词进行标注。BIO 标注(Bbegin,I-inside,O-outside)是解决标注问题的最简单的方法,即将其转化为原始标注问题。将语料中的标签统一处理为“BIO”格式。其中,B 表示当前实体单词或实体短语的首个单词,I表示当前实体短语的后续组成的单词,O 表示非实体。
2.2 结合迁移学习和主动学习的命名实体识别
针对合金材料文献语料,结合主动学习与ALBERT-CRF模型(见第2.2.1节)进行实验。从合金材料文献语料库中随机选择的初始训练集的数量为500个句子,每轮迭代后随机选择的测试集数量为1000个句子,另外从合金材料语料中选取3000个句子作为扩展集。在训练过程中,每次从扩展集中选取100个句子进行筛选,扩充到初始训练集后继续对模型进行训练。在系统整体训练结束后,使用最后得到的ALBERT-CRF 模型,即可对未知的材料语料进行实体识别。实验结果取5次实验的平均值。最终实验框架结构如图2所示。

图2 结合迁移学习和主动学习的合金材料实体识别框架Fig.2 An alloy material entity recognition framework combiningtransfer learning and active learning
2.2.1 ALBERT-CRF 实 体 识 别 模 型 BERT 模型本身包含众多参数,训练成本较高。模型参数量导致了模型训练对算力要求越来越高,模型需要更长时间去训练,甚至有些情况下参数量更大的模型表现更差。于是,出现了许多基于BERT 模型的变体,其中ALBERT 的效果尤为突出。ALBERT 对嵌入参数进行因式分解,在相对较小维度的输入级嵌入之间划分嵌入矩阵,而隐藏层嵌入仍采用较高维度,使得参数量减少约80%。并且,ALBERT 进一步将所有全连接层和各隐藏层之间共享参数,使得模型仅在部分任务上性能有所降低的情况下,进一步减少了整体的参数量。
本文提出的ALBERT-CRF 模型框架如图3 所示。因为命名实体识别是序列标注任务,序列标签之间具有较强的关联,与文本分类任务不同,所以本文在将ALBERT 模型应用命名实体识别时,在ALBERT输出层使用CRF层进行联合建模。

图3 ALBERT-CRF模型训练示意图Fig.3 Schematic diagram of ALBERT-CRF model training
图3中ALBERT 的输入部分由词向量、句子向量表示与位置向量表示合并组成。对于输入序列X= (x1,x2,…,x n),设ALBERT 层输出的初始序列标签为E,矩阵大小表示序列长度和所有可能标签个数的乘积,E iy j表示初始输出中索引为i的单词被模型预测为y i标签的分数。CRF 层对于预测标签序列y=(y1,y2,…,y n)的序列真实路径分数用Preal=eS(X,y)表示,S(X,y)由标签转移分数Transition和映射分数Emission相加得到,如式(1)、(2)、(3)所示:


加入了CRF 的ALBERT-CRF 能够充分借助ALBERT 预训练模型和CRF 标签约束的优势,使得模型可以借助预训练得到的语义特征在面向少量标注数据任务时,仍能够按照CRF添加的约束规则保证标签序列的合理性。并且,ALBERT 预训练得到的词向量包含更多的上下文特征,在计算句子相似度时比Glove预训练的静态词向量更加准确。最终如图3中CRF层选择所有可能的标签序列中,将最符合标签序列关系的一组作为输出。
3 实验结果及分析
3.1 评价指标
本文命名实体识别任务的模型评价指标为精确率(Precision)、召回率(Recall)以及F1值。精确率指的是正确分类为正类的样本数与全部正类样本数之比,Precision又称为查准率。召回率指的是预测正确的正类与所有正类数据的比值,Recall又称为查全率。F1值则是精确率与召回率的加权几何平均值。精确率、召回率和F1值的计算公式分别见式(6)、(7)、(8)所示。
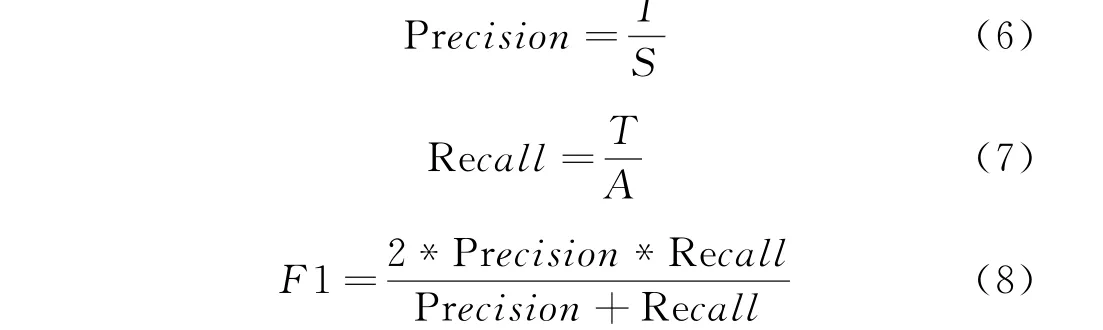
式中,T 表示这类样本中被正确预测的样本数,S表示被识别为这一类实体的样本总数,A 为样本中实际为这类样本的实例总数。
3.2 实验结果及分析
ALBERT-CRF 模型在迭代过程中F1值的变化如图4所示。图中Base_Value方法对应的直线是将包括扩展集和初始训练集的全部标注数据进行训练,得到满足应用水平的ALBERT-CRF 模型指标值,作为ALBERT-CRF实体识别实验及其对比实验方法的目标值。Active_ALBERT_CRF 方法对应的曲线为采用结合主动学习的方法训练ALBERT-CRF模型的测试结果,在测试结果中去掉了O 标签的评估。Uncertainty_Aug对应的曲线为仅基于不确定性选择样本选择的主动学习方法的测试结果。文本数据增强方法得到的模型测试结果对应图中Old_Aug曲线。同时,结合主动学习得到的最终CRF模型指标作为对比,如图中Active_CRF对应的直线所示。

图4 结合迁移学习和主动学习的合金材料命名实体识别结果Fig.4 Result of named entity recognition of alloy materials combined with transfer learning and active learning
从图4 中可以看出,结合主动学习方法的ALBERT-CRF模型(Active_ALBERT_CRF),在迭代15次时F1值就达到了CRF模型,基于不确定性样本选择的方法在迭代22 次时,模型F1 值也超过了CRF模型。证明预训练语言模型在大量无标注语料中得到的上下文特征可以更快提升模型的泛化能力。
在 迭代 约20 次 时,ALBERT-CRF 模 型F1 值 达到了ALBERT-CRF模型在扩展集完全标注(3500个句子)上训练的效果,此时训练集句子总数约为2500个句子,相对减少人工标注句子数约为1000个句子。由此可见,加入了ALBERT-CRF模型后,整体的命名实体识别框架可以利用预训练语言模型和主动学习的优势,使用更少的标注样本使模型达到更高的性能。而若仅基于不确定性样本选择的方法,ALBERT-CRF模型在迭代约30次时才达到Base_Value的指标值。
ALBERT-CRF模型在合金材料语料的3500 个句子完全训练得到的模型F1 值如表2 所示。结合主动学习基于少量训练集迭代训练的ALBERT-CRF模型最终F1值如表3所示。表2和表3所示的结果是去除了“O”标签实体后测试集中各类实体的测试结果。
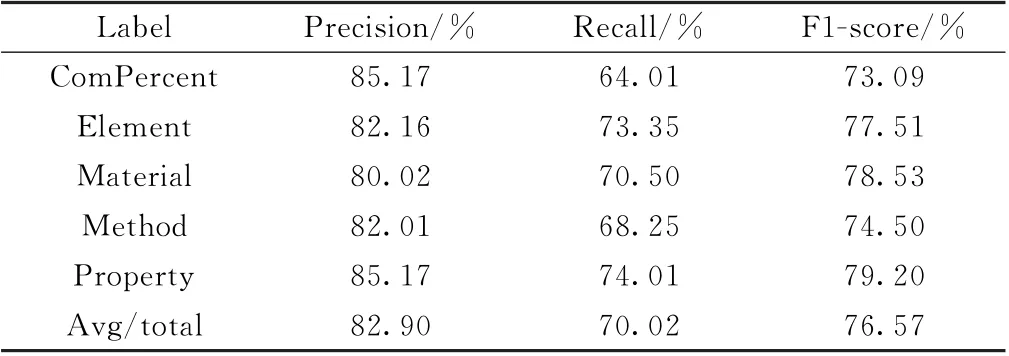
表2 合金材料语料完全训练ALBERT-CRF模型结果Table 2 Results of fully trained ALBERT-CRF model on alloy material corpus

表3 结合主动学习在少量训练集上训练的ALBERT-CRF模型结果Table 3 Results of the ALBERT-CRF model trained on a small number of training sets combined with active learning
由表2 和表3 对比可知,迭代完成后得到的Active_ALBERT_CRF 模型在合金材料实体识别中的F1值达到了ALBERT-CRF模型的平均水平,甚至略有提升,说明基于主动学习的方法进行样本选择后扩充到数据集的方法,能使得最终训练集中的样本质量更高,有助于提升模型的泛化能力。部分实体如ComPercent和Method实体识别,出现了高精确率、低召回率的情况,即模型在这两类实体识别中有一定的过拟合现象。这是由于这两类实体在少量的数据集中实体数量较少且书写格式等不统一的情况下,导致模型很难预测出未知文本中属于这两类的全部实体。而从表3 结果中可以看到,ComPercent和Method等实体的召回率虽然仍比较低,但是相比表2有所提升,说明高质量的扩充样本使得模型泛化能力有一定的提升。
为排除实验对已知语料的依赖,探究完全未知语料的使用效果,本文从百度学术中收集了完全未标注的铝硅合金材料相关英文文献,并从中随机选取了1000个句子作为扩展集。在ALBERT_CRF模型的基础上使用新的扩展集继续迭代,得到实验结果如图5所示。

图5 未知语料扩展集扩充结果Fig.5 Expansion result of unknown corpus expansion set
由图5可以看出,在使用未知语料继续进行迭代实验的过程中,F1值进一步提升。本文基于主动学习与预训练的实体抽取方法不仅适用于已有的标注语料,在未知语料场景下同样有效,继续扩充样本可以使模型性能进一步得到提升。
4 结 论
材料基因组倡导发挥材料大数据的作用,采用机器学习变革材料研发途径。数据驱动模式是材料基因工程发展的核心问题,但如何快速获取大量材料数据已成为需要解决的关键问题。为获取大量有效的材料数据,并减少命名实体识别任务对标注语料的依赖,本文采用基于迁移学习的材料文本识别方法获取材料数据。手工构建了铝硅合金材料数据集,包括5347个句子,2835个实体。
主要采用了结合ALBERT 预训练模型进行迁移学习的命名实体识别模型,结合主动学习面向少量标注数据进行合金材料实体识别,从而准确地提取材料文献中标注的实体。通过实验得到以下结论:
1.该模型对文本的精确率达到了82.90%,F1值达到了76.57%。在降低人工标注成本的同时,提高了模型的实体识别能力。
2.本文将该模型与主动学习方法相结合,在基于少量标注的初始训练集条件下,使得F1 值提高了0.61%,快速提升了模型的泛化能力,使模型实体识别性能达到较高水平。此外,探究了未知语料的场景,在迭代40次后,模型的F1值达到80%,证明了对未知材料语料的有效性。
本研究通过构建的少量铝硅合金材料数据集,利用迁移学习进行材料命名实体识别任务,减少了对标注语料的依赖以及人工标注的成本,将迁移学习与主动学习结合进一步提升了模型识别实体的有效性,并证明了对未知材料文献亦同样适用。本研究为解决材料数据源的缺乏,改善材料基因机器学习遭遇小规模数据集的困境,提供了如何解困的理论意义和应用价值。
