基于问题分解的多跳机器阅读理解模型*
2022-08-20周展朝刘茂福胡慧君
周展朝,刘茂福,胡慧君
(1.武汉科技大学计算机科学与技术学院,湖北 武汉 430065;2.智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065)
1 引言
机器阅读理解一直是自然语言处理领域的焦点,在工业界和学术界都发挥着重要的作用。作为机器阅读理解领域的重要研究方向,多跳阅读理解任务中的多跳问题在文本内容上比单跳问题更加复杂,且要求解答者能够综合多个句子进行回答。本文发现多跳问题是由数个简单问句融合而成的,而且简单问句大都是对同一实体对象不同方面的描述。例1是多跳问题的实际例子:
例1
Q:世界上首架超音速教练机可以胜任什么任务?
P1:T-50是世界上首架超音速教练机,……
P2:T-50金鹰这种先进的喷气式教练机能够胜任高强度冲突的基本战斗任务,……
Q1:世界上首架超音速教练机是什么?
Q2:[ANS] 可以胜任什么任务?
例1中的复杂多跳问题是“世界上首架超音速教练机可以胜任什么任务?”。该问题实际上相当于2个问题:首先必须找出世界上首架超音速教练机;其次回答教练机可以胜任哪些任务。
根据上述思路,本文通过问题分解的策略来简化复杂问题,从而降低复杂问题的回答难度。比如,例1中复杂问题实际上约等于2个问题,分别是“世界上首架超音速教练机是什么?”和“[ANS] 可以胜任什么任务?”,2个问题都描述了教练机,然而第1个问题可以直接回答,而且其答案正是第2个问题的主语“[ANS]”;解答出第2个问题的答案即可回答多跳问题。
近期关于问题分解的工作多依赖于词法分析相关的语义解析器[1],这使得很难将其推广到各种自然语言问题。Min等人[2]提出了一种片段预测的模型来分解问题,该模型通过指针网络抽取多跳问题中的单跳问题片段,如例1所示。这种模型仅仅利用了语法结构信息就解决了多跳问题。本文注意到多跳问题和线索段落存在相似的文本片段。如例1中的Q和P1的相似片段就是单跳问题Q1。本文将线索段落当成辅助信息来帮助模型解析复杂问题,从而获得简单问题。因此,本文提出了新的问题分解模型,该模型将文本抽取任务转化成阅读理解任务,可以同时利用到线索段落和句子结构信息。另外,缺乏相应的问题分解数据集也是问题分解的难点之一。因此,本文将复杂问题抽取出来并进行标注,生成了一个分解数据集(https://github.com/zzhzhao/test)。
2 相关工作
斯坦福SQuAD(Stanford Question Answering Dataset)数据集[3]极大地促进了阅读理解的发展。传统的阅读理解模型主要建立在管道方法的基础上,包含语法分析和特征工程等步骤。管道方法会将上一个步骤的错误传递到下一个步骤中。为了解决这个问题,端到端模型开始蓬勃发展。Match-LSTM(Match-Long Short Term Memory)模型[4]利用词嵌入的方法将问题文本和阅读文本编码成向量,然后输入神经网络获得融合向量表示,最后利用指针网络获得答案。许多研究人员在该模型架构的基础上提出了各种优化模型。相比于Match-LSTM模型的单重注意力机制,BiDAF(Bi-Directional Attention Flow)模型[5]则采用了双重注意力机制,加强了对问题文本和阅读文本语义的提取。随着阅读理解数据集的增大,基于递归神经网络的模型在训练上花费的时间越来越多。因此,Yu等人[6]提出了QANet(Question-Answer Net)模型,该模型引入了卷积神经网络,可以进行并行训练,极大地缩短了训练时间。面对含有多篇文章的阅读理解问题,Wang等人[7]提出了一种答案校验机制,可以对每篇文章的答案进行置信度打分,以获得全文层次的真正答案。谷歌的BERT(Bidirectional Encoder Representations from Transformers)模型[8]一经提出,就迅速霸占了各种自然语言处理任务榜单的榜首。但是,该模型主要是针对西方语言的特点进行训练。因此,百度提出了ERNIE(Enhanced Representation through kNowledge IntEgration)模型[9],有针对性地对中文任务进行了微调,使之更加适应中文自然语言处理任务。
和单跳问题相比,多跳问题在内容上更加复杂,需要的线索段落也更多,因此解决多跳问题需要引入推理策略。图神经模型在多跳阅读理解任务中占有重要地位。Ding等人[10]利用图神经模型构建认知图谱,利用图谱上的节点进行多跳推理。DFGN(Dynamically Fused Graph Network)模型[11]同样利用了图神经模型构建知识图谱,然后通过迁移知识图谱的推理方法来解答多跳问题。和图神经模型不同,PathNet模型[12]利用信息抽取的方式来构建多种推理路径,从而选择最佳的路径来解答多跳问题。DecompRC(Decomposition Reading Comprehension)[2]利用分解模型来降低复杂问题的难度,从而获取简单问题,最后通过解决简单问题来解决多跳问题。受到该思路的启迪,本文也尝试利用问题分解的思路来简化复杂问题,但是本文对问题分解的手段进行了创新,将问题分解转换为一个阅读理解任务,而非DecompRC模型的片段抽取问题。DecompRC模型的问题分解只利用了多跳问题的信息,直接抽取了单跳问题的起始索引;而本文模型引入了额外的线索段落信息,可以抽取更加准确的单跳问题片段。
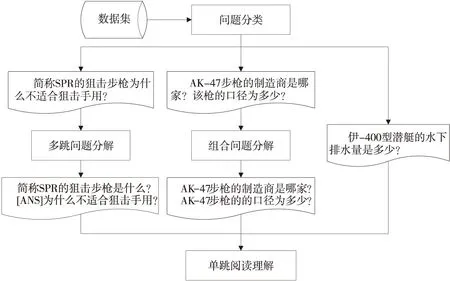
Figure 1 Framework of multi-hop reading comprehension model图1 多跳阅读理解模型整体框架
将一种自然语言处理问题转换成另外一种自然语言处理问题,这种思路在研究领域也不少见。机器阅读理解任务是一种基础的任务形式,许多其他的自然语言理解任务都可以经过一定的变换转化成问答形式,从而利用基础的阅读理解模型进行训练。DecaNLP(Natural Language Decathlon)模型[13]正是这一思路的实现者,该模型在一定程度上可以完成众多的自然语言处理任务。同时,不同的自然语言处理任务也可以相互促进,获得比单一任务更好的效果。也有一些研究人员研究单一任务的转换。关系抽取任务在形式上非常接近问答任务,因此,Levy等人[14]将需要抽取的众多关系转换成相应的问题,将实体作为答案进行抽取。类似地,实体抽取任务也可以转换成阅读理解。针对每一种实体可以生成一种相应的问题,这种方法还可以准确地抽取实体中嵌套的实体[15]。结合上述2种思路,Li等人[16]提出了一种联合学习的方法,可以通过多轮问答的形式同时抽取文本中的实体和关系。
特别地,共指消解任务也需要抽取文本中同一实体的不同表达形式,同样可以直接转换成问答形式[17]。
3 本文模型
3.1 整体架构
本文提出了一种基于问题分解的多跳阅读理解模型,如图1所示。多跳问题是由数个简单问句融合而成的,而且简单问句大都是对同一实体对象不同方面的描述。问题分解模型可以降低多跳问题的求解难度,分解之后生成的简单问题可以输入单跳模型生成答案。本文的问题分解模型引入了阅读理解模型,可以融合线索段落的信息,最终生成更加准确的单跳问题。本文的数据集主要包含3种问题,即组合问题、多跳问题和单跳问题。组合问题可以通过问号的数目直接区分。因此,本文首先利用深度学习模型训练一个二值分类器;然后,将经由二值分类模型分类得到的多跳问题和单跳问题进行问题分解。组合问题分解得到的简单问题可以直接输入单跳模型生成答案。但是,多跳问题生成的单跳问题则相互影响,如例1中,第1个问题可直接回答,而且其答案正是第2个问题的主语,解答出第2个问题的答案即可回答多跳问题。
3.2 问题分类
问题分类是基于问题分解的多跳阅读理解模型的第1步,主要对数据集中的问题类型进行划分,方便选择合适的分解模型进行分解。组合问题、单跳问题和多跳问题是中文阅读理解数据集中的主要问题类型。图1展示了3种问题类型的具体实例。其中,单跳问题是最简单也是最重要的问题类型;多跳问题和组合问题经过分解之后都可以变成单跳问题。单跳问题在句型上主要是简单句,而且需要的线索往往是单个句子,可以直接在阅读材料中获得答案,而不需要经过推理。多跳问题是由多个单跳问题经过桥接实体融合而成的,而且其中的单跳问题往往是描述同一实体的不同方面。和多跳问题不同,组合问题则是由单跳问题直接拼凑而来的,实际上仍然是2个单跳问题。多跳问题、组合问题和单跳问题拥有的特征不同,需要采取不同的方法来求解[18,19]。ERNIE模型利用大量中文文本进行预训练,还采用了词掩码机制进行优化,对中文自然语言处理任务具有较强的适应性。因此,本文使用ERNIE模型训练一个二值分类器,用以区分多跳问题和单跳问题。
对于问题文本序列Q={q1,q2,…,qn},将其输入ERNIE模型得到的语义表示向量如式(1)所示:
V=ERNIE(Q)∈Rn×h
(1)
其中,h代表编码器输出维度。然后将向量表示输入一个softmax函数进行归一化处理 ,如式(2)所示:
P=softmax(pool(V)W1)∈R2
(2)
其中,pool(·)代表池化操作,W1∈Rh×2代表参数矩阵。
3.3 组合问题分解
和多跳问题不同,组合问题实际上就是2个简单问题。2个简单问题相对比较独立,可以同时对2个问题进行回答,第1个问题的答案不影响第2个问题的解答。同时,在文本形式上组合问题也比较直观,可以通过判断问号的数目来加以区分。因此,本文直接将组合问题中的问号作为分隔符进行分割,就可以得到2个简单问题。例2直接展示了1个组合问题的数据样例:
例2
Q:AK-47步枪的制造商是哪家?该枪的口径是多少?
Q1:AK-47步枪的制造商是哪家?
Q2:AK-47步枪的口径是多少?
例2中的组合问题实际上就是询问了AK-47步枪的制造商和口径。第1个单跳问题可以直接回答,但第2个问题无法视作一个完整的单跳问题。因此,本文需要首先通过词法分析提取第1个问题的主语,然后替换第2个问题的指代词,才能形成一个完整的单跳问题。
3.4 多跳问题分解
和单跳阅读理解问题相比,多跳阅读理解问题在内容上更加复杂,需要的线索段落也更多,且往往分布在阅读材料的各个地方。单跳阅读理解模型没有对复杂的多跳问题进行解析,而是直接将其编码成语义向量和线索段落的语义向量进行交互。单跳阅读理解模型没有深入挖掘多跳问题中的隐藏实体信息,而且无法在线索段落之间进行推理。然而,问题分解模型可以简化复杂多跳问题,生成的单跳问题可以分别检索相应的线索段落。2个单跳问题经过桥接实体进行融合,可以生成1个多跳问题。多跳问题实际上经过了深度融合,无法直接通过问号进行分解,而且分解之后的单跳问题也是相互关联的,无法视作2个独立的问题。因此,本文采用深度学习模型来分解多跳问题。但是,由于分解数据集的缺乏,本文将复杂问题抽取出来并进行人工标注,生成了一个分解数据集。
为了降低多跳问题的难度,本文将问题分解任务转换成问答形式的阅读理解任务。阅读理解任务主要包括问题、答案和阅读材料,其中问题和答案都是阅读材料中的片段。为了将问题分解任务转换成问答形式,本文将线索句子改写成阅读理解任务的问题,将多跳问题中的第1个单跳问题文本当成阅读理解任务的答案。
本文采用ERNIE模型来解决问题分解任务。对于给定问题文本序列Q={q1,q2,…,qn}和阅读文本序列D={d1,d2,…,dm},ERNIE模型将问题文本序列和阅读文本序列进行拼接,提取深层语义特征向量,如式(3)所示:
U=ERNIE([Q,D])∈R(n+m)×h
(3)
其中,h代表编码器输出维度,[Q,D]代表对问题文本和阅读文本进行拼接。然后将向量表示输入一个softmax函数进行归一化处理 ,如式(4)所示:
Y=softmax(UW2)∈R(n+m)×2
(4)
其中,W2∈Rh×2代表参数矩阵。
令P(ij=indj)=Yij表示文本中第i个词语的标签是j的概率。阅读文本中的开始和结束索引标记了预测的答案文本,如式(5)所示:
(5)
3.5 单跳阅读理解
经过问题分解步骤,本文使用ERNIE模型来解答生成的单跳问题。然而,本文数据集中的阅读材料文本主要是由5篇文章构成,篇幅往往较长,而ERNIE模型对输入长度有所限制,无法直接进行处理。因此,本文采用了先检索后阅读的方法[20],即先利用BM25(Best Match 25)算法检索与问题相关的线索段落,然后利用ERNIE模型进行求解。

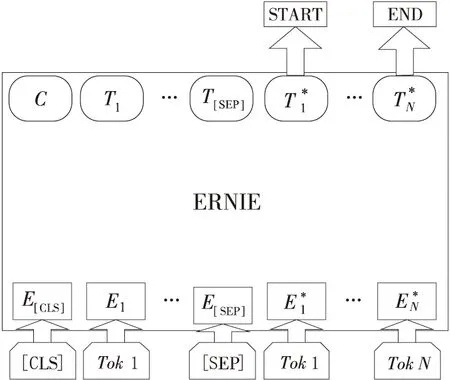
Figure 2 Overall fine-tuning procedure for ERNIE图2 ERNIE微调步骤整体框架
首先,使用式(3)获得问题文本和阅读文本的拼接向量U。然后,经过神经网络获得答案的开始索引和结束索引,如式(6)所示:
(6)
其中,Pstart(j)代表文本中第j个词是答案文本开始索引的概率,Pend(k)代表文本中第k个词是答案文本结束索引的概率。
答案文本开始索引的概率矩阵和答案文本结束索引的概率矩阵如式(7)和式(8)所示:
Pstart=softmax(UWstart)∈Rn+m
(7)
Pend=softmax(UWend)∈Rn+m
(8)
其中,Wstart,Wend∈Rh代表参数矩阵。
4 实验及结果分析
4.1 数据集
本文实验使用的英文数据集为HotpotQA[22],该数据集来源于维基百科文章,由众包人员根据给定文章构建而成,并且保留了解答问题时需要的支撑段落,主要包含大量的英文多跳问题,总计大约10万个英文问答对。和其他数据集相比,HotpotQA英文数据集具有以下特点:(1)回答复杂问题需要在多个段落之间寻找线索并进行推理;(2)问题的形式多样化而且不局限于特定知识模式;(3)每个复杂问题都包含支撑段落,可以展示预测答案的推理过程。
本文实验使用的中文数据集来自于2019年莱斯杯军事机器阅读理解比赛,总共包括大约2万个问答对,每个问答对主要包括问题、答案和线索段落。特别地,多跳问题还有一个特殊的字段——桥接实体。桥接实体指的是多跳问题分解之后生成的第1个单跳问题的答案,也是第2个单跳问题的主语,起到承上启下的作用。数据集的问题是由研究者根据军事文本编辑而成的,其平均长度大约是16个词语。军事问题的提问方式比较固定,主要是询问某种军事实体的属性。特别地,部分军事问题的参考答案并非军事文本中的片段;而且,某些复杂的军事问题需要综合多个答案才能回答。
组合问题、单跳问题和多跳问题是中文阅读理解数据集中的主要问题类型。例2的组合问题可以直接看成2个简单问题,而且这2个问题都是对同一个军事实体进行提问。例1中多跳问题的求解过程是先找到Q1的答案,然后替换Q2中的占位符,最终求得Q2的答案。中文数据集的统计信息如表1所示。

Table 1 Statistical information of Chinese dataset表1 中文数据集的统计信息
由于缺乏标注的分解样例来训练问题分解模型,本文通过人工标注的方法获得问题分解数据集。多跳问题是由多个简单问题经过桥接实体融合而成,因此,多跳问题和分解之后的单跳问题存在公共子片段。最长公共子串LCS(Longest Common Substring)算法可以抽取文本之间的相似文本片段。因此,本文采用LCS算法来提取单跳问题。但是,LCS算法生成的单跳问题不完整,需要手工进行调整。
4.2 评价指标
BLEU(BiLingual Evaluation Understudy)指标[23]和Rouge-L指标[24]是自然语言处理任务中常用的评价指标。BLEU主要用来评价生成文本和参考文本之间的相似度,具体的计算方法是统计两者之间的n元词组同时出现的频率。Rouge-L指标同样可以评估生成文本和参考文本之间的相似度,但是在计算方法上有所不同。Rouge-L主要是计算两者之间的召回率和准确率。
军事阅读理解数据集包含复杂的多跳问题,其中部分答案不是直接从军事文本中抽取而来。另外,相当一部分军事问题存在多个答案,这些参考答案本质上是对不同子问题的回答。因此,本文的评价分数计算如式(9)所示:
(9)
其中,BLEU计算或者Rouge-L计算用函数eval表示;cn代表测试集中的数据样例个数;predb代表模型的第b个预测答案文本;answerl代表第l个参考答案文本;answer_count和pred_count分别代表参考答案的个数和预测答案的个数。
4.3 实验
本文实验主要测试了3个模型,分别是基于ERNIE的分类模型、基于ERNIE的问题分解模型和基于ERNIE的单跳阅读理解模型。3个模型都采用0.000 05的学习率且都只迭代训练2轮。3个模型的其他参数设置如表2所示。表2中seq_len表示最大序列长度,ques_len表示最大问题长度,ans_len表示最大答案长度。

Table 2 Setting parameters of models表2 模型的参数设置
4.4 实验结果及分析
莱斯杯数据集包含了大量的中文多跳问题,本文在该数据集上进行了许多基于不同分解模型的实验,结果如表3所示。表3中:
(1)ERNIE:基准模型。
(2)ERNIE+SD:分解组合问题。
(3)ERNIE+SD+SPAN-CD:分解组合问题,基于片段预测的多跳问题分解,即DecompRC的问题分解模型。
(4)ERNIE+SD+RC-CD:分解组合问题,基于阅读理解的多跳问题分解,即本文提出的模型。
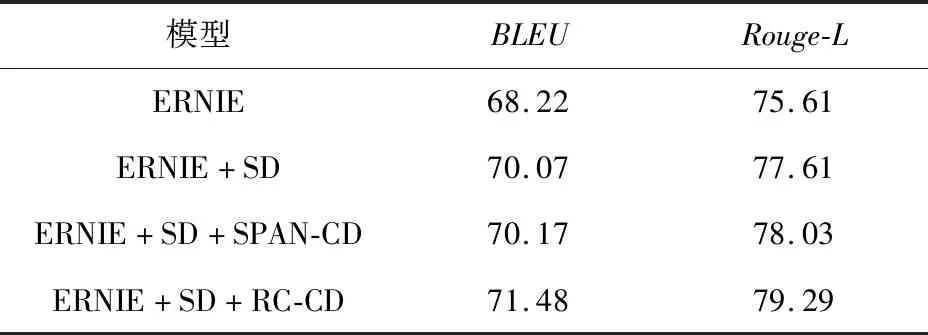
Table 3 Experimental results based on different decomposition表3 基于不同分解模型的实验结果 %
本文模型在表3的实验结果中分数最高。第3个模型比第4个模型分别在BLEU指标和Rouge-L指标上低了1.31%和1.26%。这2个模型的实验结果对比说明基于阅读理解的多跳问题分解比基于片段抽取的模型更加有效。阅读理解模型引入了线索段落的信息,可以辅助抽取单跳问题文本。第2个模型比第3个模型在Rouge-L指标上低了0.42%,表明多跳问题分解可以降低复杂问题的难度。根据基准模型和第2个模型实验结果的对比,发现分解组合问题能够提高模型的求解效果。
为了比较本文提出的基于阅读理解的问题分解模型和DecompRC模型的区别,本文在问题分解数据集上进行了实验,同时对预测的结果进行了分析。从表4可以看出,2种问题分解模型对问题分解都是有效的。本文模型在Rouge-L和BLEU指标上的得分均高于DecompRC模型的,这说明本文模型比DecompRC模型更加有效。DecompRC模型利用指针网络在多跳问题中直接抽取单跳问题片段,并没有利用证据段落的信息。相反,本文的问题分解模型充分利用了证据段落和多跳问题的相似性,可以更加准确地抽取单跳问题片段。例3展示了不同问题分解模型的样例。其中,Q1是DecompRC分解模型的结果,Q2是基于阅读理解的问题分解模型的结果。和Q1相比,Q2没有抽取“的原机型”这个片段。从证据段落P中可得出,抽取结果Q2更加准确。如果只利用多跳问题Q的信息,模型无法确定单跳问题片段的结束位置。
例3
Q:美国空军现役最大战略运输机的原机型什么时候进行的首飞?
P:为了控制零件成本,日后打算给美国空军现役最大战略运输机C-5全部换装3D打印马桶圈。
Q1:美国空军现役最大战略运输机的原机型
Q2:美国空军现役最大战略运输机
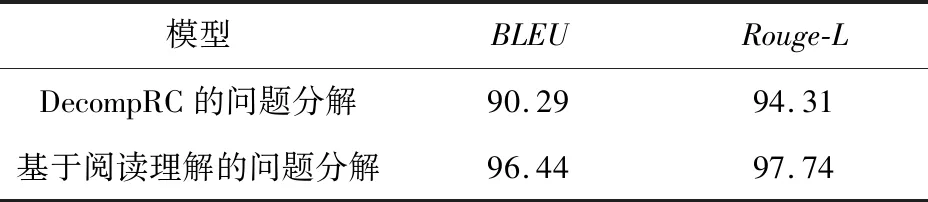
Table 4 Experimental results based on question decomposition表4 问题分解的实验结果 %
本文为了证明实验模型的有效性,还在中文数据集上对许多经典阅读理解模型进行了实验。实验结果如表5所示。本文对问题分解手段进行了创新,将问题分解转换成一个阅读理解任务,而非DecompRC模型的片段抽取问题。DecompRC模型的问题分解只利用了多跳问题的信息,直接抽取了单跳问题的起始索引。而本文模型则是引入了额外的线索段落信息,可以抽取更加准确的单跳问题片段。从表5可知,本文模型的BLEU值和Rouge-L值分别是71.48%和79.29%,在所有对比模型中,其BLEU值和Rouge-L值最大。
HotpotQA数据集包含大量的英文多跳问题,本文在该数据集上同样对众多的经典阅读理解模型进行了实验,结果如表6所示。本文模型相比DecompRC模型BLEU值和Rouge-L值分别提高了1.35%和1.38%。该实验结果表明,本文模型在英文数据集上是有效的。

Table 5 Experimental results based on Chinese dataset表5 基于中文数据集的实验结果 %
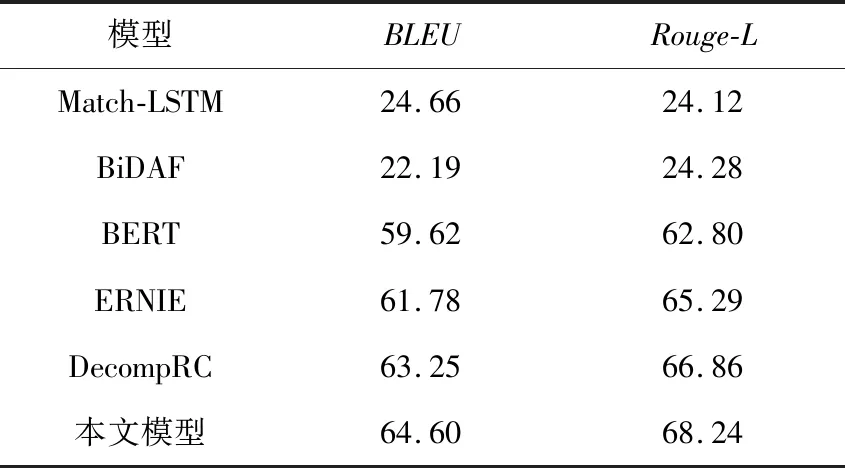
Table 6 Experimental results based on English dataset表6 基于英文数据集的实验结果 %
4.5 样例分析
本文模型对多跳阅读理解任务是有效的,但是仍然存在一些问题无法解决。下面给出了本文模型求解错误的多跳问题,如样例1~样例3所示:
样例1
Q:首架“活鱼雷”是什么时候建成的?
P1:剑鱼式鱼雷轰炸机是菲尔利航空器制造公司设计制造的一款飞行器,首架于1934年4月17日建成,1936年开始投入使用。
P2:剑鱼常常扑击船只,船只通常会被刺出一个大窟窿,因此人们称它为“活鱼雷”。
样例2
Q:哪个国家可能会购买成为巴基斯坦空军的新锐力量的战机?
Q1:哪个国家可能会购买战机?
Q2:成为巴基斯坦空军的新锐力量的战机
P1:缅甸空军有可能将增购JF-17“雷电”战斗机。
P2:JF-17“雷电”战斗机如今已不仅是巴基斯坦空军的新锐力量。
样例3
Q:除洛杉矶级外,主要远海任务承担者的设计初期目的是为了什么?
Q1:除洛杉矶级外,主要远海任务承担者
Q2:设计初期目的是为了什么?
P1:其他远海任务则主要由洛杉矶级和海狼级承担。
P2:美国的这艘海狼级核潜艇,设计初期就是为了克制俄罗斯的现有核潜艇和预防未来俄罗斯新式的核潜艇。
样例1中的多跳问题似乎仅仅是一个单跳问题,但是实际上需要挖掘更加深入的信息才能正确解答。多跳问题中的活鱼雷正是剑鱼式鱼雷轰炸机的另一种称呼。而且,阅读材料中的线索段落则是只涉及了剑鱼式鱼雷轰炸机。因此,模型需要挖掘出活鱼雷等同于剑鱼式鱼雷轰炸机这一信息。样例2中的单跳问题出现在多跳问题的尾部,类似的数据样例比较稀少,没有足够的数据对模型进行训练。样例3中的多跳问题包含有简单的逻辑运算,首先要找到所有主要远海任务的承担者,然后获得除洛杉矶级之外的舰艇。
5 结束语
本文提出了一种基于问题分解的多跳阅读理解模型。由于多跳问题具有复杂的语义,因此,本文选择问题分解模型来降低多跳问题的求解难度。对于分解生成的单跳问题,本文选择单跳模型来生成相应的答案。本文将问题分解任务转换成阅读理解形式。阅读理解形式可以吸收额外的线索段落信息,进而解析出单跳问题文本。另外,问题分解模型缺乏训练数据,本文对多跳问题中的单跳问题进行标注,生成了一个问题分解数据集。实验结果表明,本文模型对多跳机器阅读理解是有效的。但是,一些超出本文推理策略的多跳问题仍然无法解决,因此将会继续探索新的推理策略。
