基于深度学习的SAR目标识别DSP设计*
2022-08-20施慧莉李大亮
何 涛,施慧莉,李大亮
(中国航空工业集团公司雷华电子技术研究所,江苏 无锡 214063)
1 引言
传统SAR(Synthetic Aperture Radar)目标识别需要人工凭借经验进行特征提取与特征选择,具有一定的主观性和盲目性,难以保证识别的有效性,特别是现代作战环境下机载SAR目标场景复杂多变,传统目标识别算法在不同场景下的识别效率会受到干扰及目标特性的严重影响。近些年来,得益于大规模的带标签数据集PASCAL VOC、ImageNet和MS COCO的公开以及人工智能硬件平台的发展,基于卷积神经网络CNN(Convolutional Neural Network)的目标识别取得了重要突破,并成功扩展到了遥感图像领域,为SAR目标识别提供了新的解决思路。
目前主流的CNN目标识别模型可以分为2大类:two-stage识别模型和one-stage识别模型。two-stage识别模型的典型代表是基于候选区域的R-CNN系算法,如R-CNN、Fast R-CNN和Faster R-CNN[1 - 3]等;经典的two-stage识别模型一般都比较耗时,这是由于在two-stage识别过程中,需要产生大量的候选区域,这些候选区域的处理占用了大量的处理时间。YOLO(You Only Look Once)[4]创造性地提出了one-stage方法,即直接利用深度CNN网络得出目标的位置和所属的类别。但是,YOLO模型存在物体识别精度低、对于小物体识别效果不好的缺陷。后续的YOLO-v2[5]模型和YOLOv3[6]模型通过加入批归一化BN(Batch Normalization)层、提升输入层分辨率、预测位置偏移值、残差单元、多尺度识别等措施来提升小目标识别准确率和识别速度。卷积神经网络在CPU和GPU平台上已经有多种成熟的实现框架,例如Google开发的TensorFlow[7]框架,伯克利大学的C开源框架caffe[8],基于YOLO系列模型的C开源Darknet框架等。这些实现框架在GPU端的运行实现大都采用NVIDIA cudnn库进行加速,在CPU的实现采用openmp方式进行多线程加速,因此深度学习CNN的主要加速运算平台大多选用GPU或FPGA硬件平台。基于DSP与GPU和FPGA在并行运算上的天然劣势,传统的深度学习框架(TensorFlow、caffe和keras等)不支持DSP平台。
本文主要从基于深度学习的SAR目标识别在机载DSP平台实时处理需求出发,通过构建CNN在多核DSP的运行生态,完成了多核DSP(C6678)平台上的YOLOv3-TINY(YOLOv3网络的轻量级模型)网络的设计与实现,并进行了实测SAR数据验证。虽然深度学习网络在DSP的实时性上和GPU相比还有较明显的差距,但其能够满足机载SAR的实时处理需求。
2 软硬件简介
2.1 TI C6678简介
TMS320C6678[9]是TI公司基于KeyStone多核处理器架构的多核DSP,芯片集成了8个C66X DSP内核,内核频率可达1.25 GHz,芯片处理能力强,外设功能丰富,可以广泛地应用在通信、雷达、声纳、火控和电子对抗等领域。单C6678片内配置8个TMS320C66xTMDSP核,每个DSP单核内存配置512 KB核内高速缓存,8核共享4 MB SRAM高速内存;同时C6678提供了一个64位的DDR3外存接口,能以800 MB/s、1 033 MB/s、1 333 MB/s和1 600 MB/s的速率进行传输操作,数据率最高可至大约12.8 GB/s,可寻址空间为8 GB。
2.2 YOLOv3深度学习模型简介
YOLOv3模型是YOLO系列网络的第3个版本,是目前工程界首选的目标识别模型之一。相较于之前的版本,该版本增加了残差单元、特征金字塔网络和多尺度识别来进一步提升识别准确率,尤其是小目标的识别准确率。具体来说,YOLOv3主要有以下特点:(1)采用了Darknet53骨干网络;(2)包含了多个残差单元;(3)利用3个尺度的特征图来共同进行最后的预测,提升了目标识别准确率。图1给出了YOLOv3模型的网络结构图,其中CBL为YOLOv3模型中广泛采用的卷积层,是卷积层+BN层+LeakyReLU激活函数的组合;残差单元用Res_n*m表示,n表示第n个残差单元,m为该残差单元的重复利用次数,残差单元的使用保证了网络深度,提升了网络的特征表达能力。
3 基于C6678的卷积神经网络设计
常用的卷积神经网络实现框架(TensorFlow、caffe和Darknet等)主要运行平台为GPU和CPU,且不支持DSP,因此本文主要进行了多核DSP平台上的可定制卷积神经网络设计。鉴于复杂卷积神经网络的训练时间远大于预测时间,可以通过高性能GPU服务器对目标数据训练后,将训练后的网络权重输入到DSP硬件平台进行前向预测。因此,本文DSP平台上的卷积神经网络的卷积层设计不考虑反向预测,只进行卷积层的前向预测。

Figure 1 Network structure of YOLOv3 model图1 YOLOv3模型网络结构
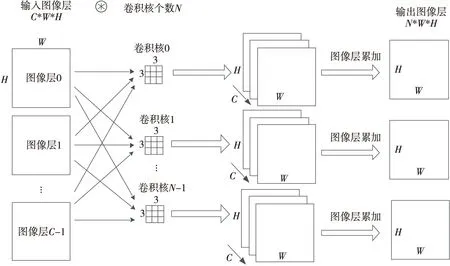
Figure 2 Schematic of convolutional layer processing图2 卷积层处理原理
3.1 卷积层设计
3.1.1 并行计算策略
卷积层处理的主要原理如图2所示,图1中的示例为多通道图像和不同的卷积核进行卷积,其中卷积层的输入图像尺寸为(C,W,H),C为图像通道数,W为输入图像宽度,H为输入图像高度,N为卷积核个数。在实际卷积处理中,单个卷积核分别和每个图像输入进行卷积后还需进行多通道加和处理,等于单个卷积核和多通道输入卷积处理后的图像输出尺寸为(W,H),N个卷积核的卷积层处理输出为(N,W,H)。
根据卷积层处理特点及C6678的多核独立计算特性,本文设计了如下2种卷积层并行计算策略:
(1)策略1:基于独立卷积核计算的并行策略。
由卷积层的计算原理可知,不同卷积核和输入图像的卷积计算是完全独立的,结合C6678的多核特性,该并行策略可以设计为:不同C6678核分配不同的卷积核来完成单个卷积层处理时的并行计算。
(2)策略2:基于图像分块的并行策略。
由卷积层的计算原理可知,每个卷积核需要遍历每个图像的不同区域位置进行卷积处理,同时多通道图像经过一个卷积核处理后,还需要进行累加生成一幅图像。从该处理过程可以看出,多通道图像不同区域参与的卷积计算是完全独立的。因此该并行策略设计为:将输入多通道图像划分为不同的数据块,每个C6678核独立完成多通道不同图像块区域的卷积运算。
以上2种并行计算策略从并行计算的实现上都是完全可行的。但是,C6678的多核及存储特性使每个核的独立缓存上很难容纳每个卷积层的输入多通道图像,只能存放于C6678的共享4 MB缓存中。策略1中每个独立卷积核在计算时都需要读取一次多通道图像数据;而策略2因为是基于图像块进行的并行任务,每个C6678核读取不同的图像数据块,读取到的图像数据块可以参与N个卷积核计算。因此,策略1和策略2相比,虽然总的计算能力一致,但输入图像数据读取时间增加了N倍。综合考虑,本文采取策略2作为卷积处理的并行计算策略。
3.1.2 卷积束核心运算
在NVIDIA的深度学习库cudnn、Darknet和caffe等实现框架中,卷积运算都是将卷积操作转换为矩阵乘操作GEMM(GEneral Matrix Multiplication),由于GPU和CPU的高速内存在处理数据时没有容量制约,所以矩阵乘操作是这些深度学习库实现快速卷积的主要方式。但是,多核DSP高速缓存资源有限制,采用矩阵乘方式,无论是核内高速缓存还是多核共享缓存C6678都无法满足计算存储需求,参与计算的数据只能存放在DDR3上,导致计算效率急剧下降。因此,需要重新设计适配多核DSP的卷积运算。
考虑到多核DSP处理器有限的快速计算内存资源,本文针对性地提出了卷积束计算概念。卷积束可以理解为收集参与单个卷积核运算的多个图像通道的数据作为单个卷积运算的输入,卷积束运算可以简化成卷积束与卷积核的乘累加。因此,在嵌入式平台上,本文抛弃常用的深度学习框架中将卷积计算转换为矩阵运算的思路,提出将单个卷积束运算作为多通道图像卷积处理的一个基本计算核心。由此整个卷积层的计算抽象为遍历多通道图像依次得到不同的卷积束,每个卷积束依次和不同卷积核进行计算,不同的卷积核计算结果分别存储于对应的输出图像层。单个卷积束运算如图3所示,基于卷积束的卷积层处理控制流程如图4所示。

Figure 3 A single convolutional beam operation 图3 单个卷积束运算

Figure 4 Flow chart of convolutional layer processing control based on convolutional beam图4 基于卷积束的卷积层处理控制流程
3.2 DSP平台上的深度学习框架
鉴于DSP平台不支持常用深度学习框架,本文对多核DSP平台上的深度学习框架进行简易开发,使其可以支持常用的卷积神经网络。多核DSP平台上的开发框架主要包含以下主要内容:
(1)主要卷积神经网络运行层支持,以组件方式进行配置运行。这些运行层包括卷积层、池化层、上采样层、连接层、残差层处理、YOLO检测层处理。
(2)深度学习网络配置分析处理:
- 结合嵌入式资源特性的网络内存动态分配;
- 结合嵌入式资源特性的处理组件配置分析。
(3)训练权重参数的加载及分析。
(4)前向预测推理。
本文目前的应用工作场景如下所示:
(1)服务器训练。
通过桌面服务器进行深度学习网络训练,训练完成后,保存训练的权重参数。
(2)DSP预测推理。
将训练后的权重导入到DSP外部存储器,在DSP平台上运行本文的处理框架进行前向预测推理。
通过以上工作,本文完成了深度学习网络在多核DSP平台上的基本生态建设,能够使多核DSP按照桌面计算机的通用设置运行深度学习网络。
3.3 调度设计
本文针对卷积神经网络在C6678平台上的运行设计了2个输入接口:图像数据输入接口和目标识别类型接口。收到图像数据后和目标检测类型数据后,根据目标识别类型选择不同的网络架构并构建网络,生成该架构下的网络处理队列,并同时进行权重数据文件分析,解析每个处理层需要的权重参数在外部存储器内的偏移地址。同时,DSP主处理核启动主处理进程,遍历网络组件处理队列,并运行每个组件的前向预测函数;每个组件层在多核DSP平台上的并行处理调度隐藏在每个组件层的前向预测函数中。网络架构及调度流程如图5所示。

Figure 5 Scheduling flow chart of convolutional neural network for SAR target recognition based on C6678图5 基于C6678的SAR目标识别卷积神经网络调度流程图
4 实验验证
4.1 运行平台及运行时间统计
依据第3节所述的卷积神经网络的设计内容,通过软件优化设计与测试时,考虑YOLOv3网络对多核DSP平台资源的需求较高,其在C6678平台上运行会受到较大限制,因此本文最终选择YOLOv3-TINY网络在C6678平台上进行实时并行处理,硬件资源为单片C6678。
YOLOv3-TINY是YOLOv3的简化版,相对YOLOv3模型,总网络层数减少到了31层,但保留了残差单元和多尺度识别,在网络轻量化和识别性能上取得了较好的折衷,其中卷积层占16层,输入为YOLOv3系列网络的标准输入尺寸416*416。在实际处理时大图通过平滑抽取至(416,416)再输入到深度学习网络进行识别处理。网络架构及运行时间如表1所示。通过多次统计,YOLOv3-TINY网络在单片C6678上的识别处理时间平均为1 s左右。表1中class参数为识别目标类型数量,X为识别前总共预测的参数数量。
4.2 实验结果分析
目前机载SAR图像的典型目标相对光学图像存在样本量少的问题,坦克、飞机等战术小目标图像源很难获取,因此在本文实验中,SAR图像样本选择获取难度较低的机场目标样本进行训练。SAR机场数据集主要包含4种分辨率(0.3 m,0.5 m,1 m和3 m)共400幅图像,其中无机场图像占比10%,训练集占比80%,验证集占比20%。
训练参数采用YOLOv3-TINY网络标准模板参数,由于训练样本数较少,为了避免过拟合情况,训练批次数在该样本集上最大不超过30 000次。训练平台为地面GPU服务工作站,训练完成后将YOLOv3-TINY网络权重导入C6678 的DDR3存储器。
由于数据集包含了多个机载平台的实时SAR图像,平台的差异性(分辨率、辐射功率、作用距离和波形差异等)导致不同源的SAR图像在质量、量化和对比度上有较大的区别,从而会影响目标识别对不同SAR图像数据源的识别能力。本文通过实验对验证集进行测试,机场目标识别准确率为84%,实验结果验证了YOLOv3-TINY网络对于少样本训练集及不同平台SAR图像的识别泛化能力,基本能够满足需求方对机载平台的识别准确率要求。
图6为8幅不同分辨率的SAR样本图像在C6678平台的机场识别效果图,这些样本来源于不同机载雷达平台,标注机场类的识别框尺寸在不同源图像上会有较大的差别,这主要是因为对于机场类的大尺寸的目标识别而言,不同平台的SAR图像其目标标注范围内会存在大量的其他形态信息,对卷积神经网络的学习记忆会有一定程度的影响;训练端对于机场类目标的位置信息标注主要是人工参与,其人工参与的机场标注范围也会对测试结果产生一定程度的影响。
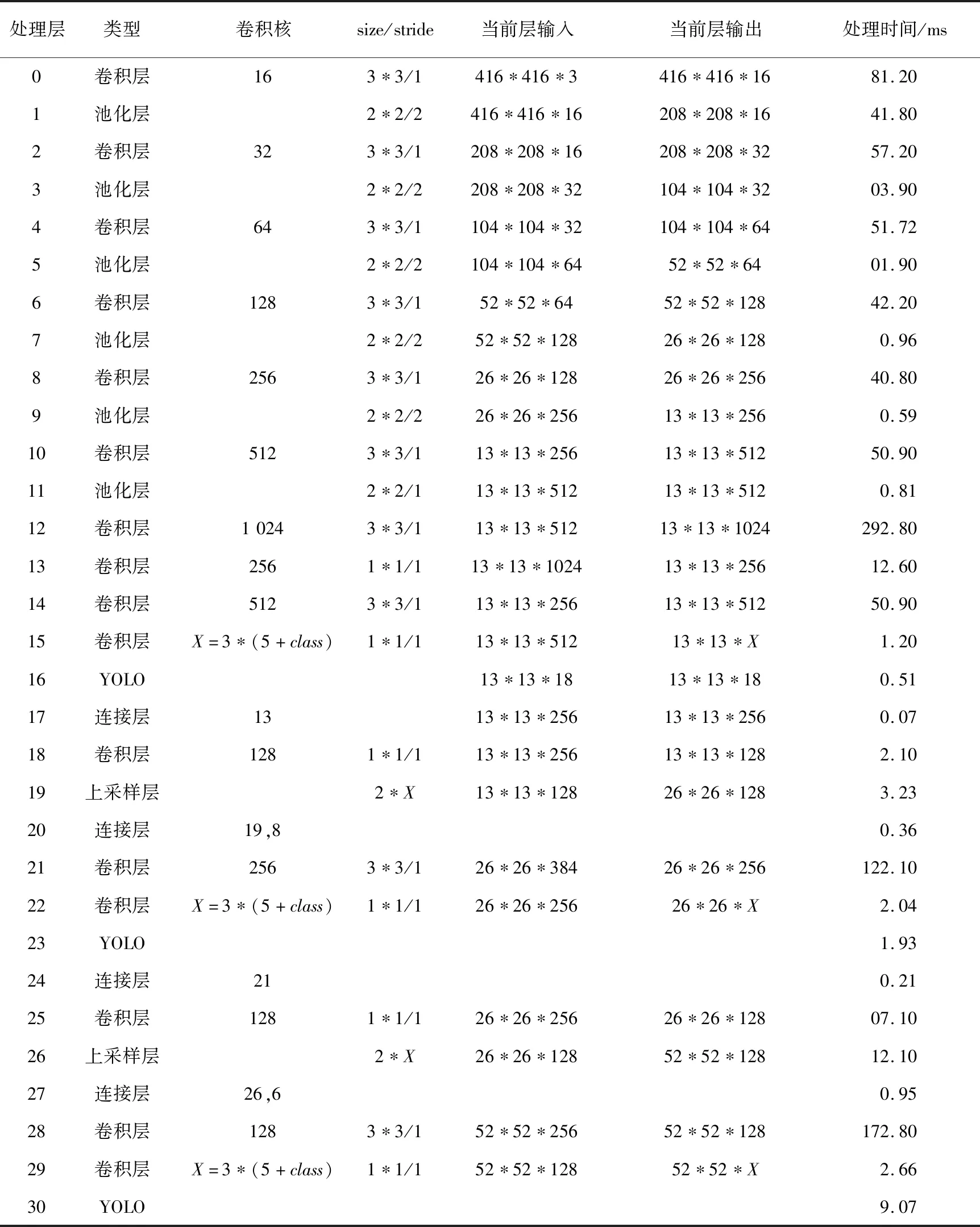
Table 1 Running time statistics of YOLOv3-TINY network architecture 表1 YOLOv3-TINY网络架构运行时间统计

Figure 6 SAR airfield target recognition results图6 SAR机场目标识别结果图
YOLOv3-TINY网络在DSP和GPU平台上的检测结果基本一致,但FPS值只有1,虽然和该模型在GPU的FPS值(大于100)相比,实时性能下降很多,但考虑到机载SAR的图像周期为秒级,帧率大都小于1,所以在类C6678平台上进行基于深度学习的机载SAR大型目标识别能够满足实时性需求。
5 结束语
本文结合C6678的多核DSP特性,通过设计卷积神经网络在多核DSP上的运行架构及主要处理层,完成了YOLOv3-TINY网络模型在C6678平台上的实测运行。本文主要出发点是在DSP平台没有成熟的深度学习开发生态的条件下,验证了多核DSP平台上运行简易深度学习网络的可行性。本文设计的深度学习简易框架在C6678多核DSP的运行性能能够满足目前机载SAR图像目标识别的实时性需求,完成了基于C6678多核DSP的卷积神经网络的设计实现。考虑到机载平台的国产化需求较强,本文方法可以应用于未来类C6678的更高性能国产多核处理器上。
