基于四叉树分解和自适应焦点测度的多聚焦图像融合
2022-08-18王纪委曲怀敬魏亚南张志升张汉元
王纪委,曲怀敬,魏亚南,谢 明,徐 佳,张志升,张汉元
(山东建筑大学信息与电气工程学院,山东 济南 250101)
0 引 言
多聚焦图像融合(multi-focus image fusion, MFIF)是图像融合领域一个重要的分支。因为相机成像系统的特点,很难获得一幅完全聚焦的图像。一种流行的解决这种问题的技术是针对同一场景将不同焦距下所获取的多张源图像融合为一幅全聚焦图像,称为MFIF。目前,MFIF技术广泛应用于显微成像、文物修复、遥感和计算机视觉等领域[1]。
传统的MFIF方法一般可分为基于空域的方法和基于变换域的方法。具体而言,基于空域的方法是直接在空间域中操作,可以进一步分为即基于像素[2]、基于块[3]和基于区域[4]的3类方法。相比之下,基于变换域的方法首先将图像变换到另一个域中,然后使用变换后的系数进行融合,最后通过相应的逆变换得到融合图像。到目前为止,已经提出了许多基于变换域的方法,如稀疏表示方法[5-7]、多尺度方法[8-10]、基于梯度域的方法[11]和混合方法[12]等。
近年来,研究者开始使用深度学习技术来解决MFIF的问题[13]。目前,基于深度学习的融合方法主要分为有监督[13-15]和无监督[16-18]2种类型的MFIF方法。更具体地说,许多深度学习模型,例如CNNs[13-16]、GANs[17]等,都已被用于MFIF领域。
现有的MFIF方法在一些方面仍需要改进。首先,基于变换域的方法在融合变换域系数和逆变换时往往会丢失一些有用信息,从而导致在融合图像中出现对比度降低和产生伪影等问题。其次,在基于空域的方法中广泛使用基于固定大小块的策略,而块大小会影响融合质量,往往还会出现块效应。另一方面,与传统的MFIF方法相比,由于缺乏大型的训练数据库,深度学习方法在融合性能和效率上目前还没有优势[1]。因此,本文研究的重点是对传统的MFIF方法进行改进。
针对上述问题,本文提出一种基于四叉树(Quad-tree, QT)分解和自适应焦点测度的MFIF方法。首先,设计一种新的基于SML和导向滤波的焦点测度,得到源图像的焦点图。然后,采取一种新的QT分解策略,将源图像分解成最优大小的树块对;由互补树块对的焦点信息确定初始决策图;对初始决策图进行优化和一致性验证后,构成最终的决策图。最后,根据最终决策图,通过加权平均规则重构出一幅全聚焦融合图像。通过利用公共多聚焦图像数据集进行实验,并与11种先进的MFIF方法进行视觉质量和客观指标比较,实验结果验证了本文方法的可行性和有效性;同时还表明,本文方法既克服了传统基于块方法对块的大小敏感的问题,又基本消除了融合图像中存在的边界伪影,从而显著地增强了融合图像的质量。
本文研究主要的工作包括以下4个方面:
1)提出一种分区域处理的基于SML与导向滤波的焦点测度。
2)根据多聚焦图像的特点,提出一种有效的QT分解策略。
3)通过将QT分解策略与焦点测度有机结合,提出一种有效的MFIF算法。
4)通过大量实验验证本文方法在定性和定量方面都优于其他11种最新的MFIF方法。
1 相关工作
1.1 导向滤波
导向滤波由He等人[19]提出。导向滤波的工作原理简述如下。对于半径为r的滑动窗口wk,引导图像I和输出图像q存在着如式(1)的局部线性关系:
qi=akIi+bk,i∈wk
(1)
其中,ak、bk为待求系数。
根据式(1),定义一个如式(2)的损失函数:
(2)
这是一个求解最优值的问题。其中,为了防止ak过大,引入一个正则化参数ε。运用最小二乘法求解极小值,并利用极小值处偏导数为0,得式(2)的解为:
(3)
(4)

最后,将线性模型(1)应用于整个图像的所有局部窗口,得到如式(5)的输出:
(5)

1.2 修正的拉普拉斯能量和
修正的拉普拉斯能量和(Sum-modified-Laplacian, SML)是一种有效的焦点测度[20]。为了防止计算图像f的拉普拉斯变换时,x和y方向的二阶导数可能出现因相反的符号而相互抵消现象,Nayar等人[21]提出了修正拉普拉斯,它取拉普拉斯变换中二阶导数的绝对值。修正拉普拉斯的离散形式近似可以表示为:
ML(i,j)=|2f(i,j)-f(i-s,j)-f(i+s,j)|+
|2f(i,j)-f(i,j-s)-f(i,j+s)|
(6)
其中,s表示像素间的可变间距,用于适应图像的纹理基元大小的可能变化。
这样,在图像位置(i,j)附近的一个小窗口内可计算出位置(i,j)处的SML,如式(7):
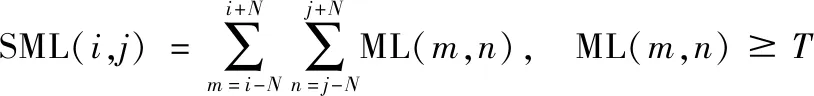
(7)
其中,T为设定的阈值,用于计算SML的窗口大小为(2N+1)×(2N+1)。
2 提出的方法
MFIF的目标是从互补的多聚焦源图像中生成一幅全聚焦融合图像。为了实现这一目标,本文提出一种基于QT分解和自适应焦点测度的MFIF方法,其融合过程如图1所示。下面对具体的内容进行详细的描述。
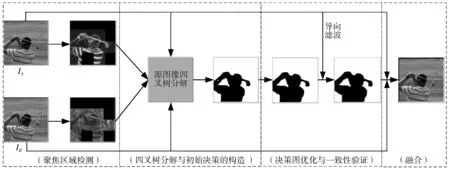
图1 本文方法流程图
2.1 聚焦区域检测
为了精确地检测出聚焦区域,本文提出一种分块处理的焦点测度,即基于SML与导向滤波的焦点测度。与传统的焦点测度相比,本文提出的焦点测度的不同之处在于,它通过充分考虑图像的不同区域之间像素聚焦情况的差异,对这些区域分开进行焦点判别处理,这样可以得到源图像中更为精确的焦点信息,从而更准确地检测出聚焦区域。
2.1.1 基于SML与导向滤波的焦点测度
焦点测度在区分聚焦区域和散焦区域方面起着至关重要的作用。目前,广泛采用的焦点测度包括:图像梯度能量(EOG)、图像拉普拉斯能量(EOL)、修正拉普拉斯能量和(SML)等。在文献[20]中,实验结果表明SML优于其他焦点测度。但在一些平坦区域,SML无法准确地区分出聚焦区域与相应的散焦区域的像素。此外,SML对噪声较为敏感。
为了克服这些问题,本文将SML和导向滤波相结合设计一种新的焦点测度。首先,将源图像进行分块处理,利用图像块对的梯度信息(本文使用的是SML),判断图像块对的类型。然后,根据不同类型的图像块对,利用SML和导向滤波器自身的特点,对提出的焦点测度进行自适应的调整。实现的步骤描述如下:
1)将源图像变换为灰度图像,并将灰度图像分成大小相同的子块。然后,采用一个遍历窗口从源图像左上角开始直至遍历整个源图像,将得到的每个子块图像作为下一阶段的输入。
(8)
(9)
(10)

3)定义一个元素都为1,大小与对应子块相同的矩阵FFMB,即:
(11)
其中,H和W分别为子块的高度和宽度。FFMB表示一个理想的全聚焦与全散焦互补子块对经过式(9)和式(10)得到的二值图。
4)定义一个子块的全聚焦焦点图的和(SFFMB)与焦点图的和(SFMB),分别由式(12)~式(14)计算得到。即
SFFMB=∑∑FFMB(x,y)
(12)
(13)
(14)
5)根据SFFMB与SFMB,由式(15)求得阈值S。
S=SFMB/SFFMB
(15)
由于SFMB表示一对图像子块整体的聚焦情况;而SFFMB表示图像子块对在一种理想情况下(即一个块为全聚焦,另一个块为全散焦)SFMB的最大值,因此两者的比值可以作为判断图像块对聚焦情况的条件。

(16)


(17)

(18)
9)将各子块图像的粗略焦点图按原位置重组,从而得到与源图像大小相同的粗略焦点图RFGi。
10)导向滤波中引导图像的高频信息可以有效地迁移到输出图像中。因此,用源图像Ii作为引导图像、以粗略焦点图RFGi为输入图像的导向滤波输出图像可以增强粗略焦点图的高频信息、细化粗略焦点图的显著结构。本文将此输出图像作为最终焦点图FGi。即:
FGi=Gf(r0,ε0)(Ii(x,y),RFGi(x,y)),i=1,2
(19)
其中,Gf(r0,ε0)为导向滤波算子,其中r0、ε0为导向滤波的2个参数,在本文中分别设置为3和0.05。
2.1.2 参数选择
这一节将确定相关参数的选择原则,依此提高焦点测度的精度。
1)参数p的选择。
图像块对一般分为2种情况:1)一个块完全聚焦,另一个块完全散焦,称为情形1;2)两者都是部分聚焦,称为情形2。从源图像得到的子块中,包含“平坦”区域的子块大都属于情形1,而包含聚焦与散焦区域边界的子块属于情形2。这2种情形的子块图像对应着聚焦区域检测的2个难点。因此,为了更准确地检测聚焦区域,本文将子块图像分为上述2种情形进行不同的处理。对于情形1的子块图像,由于包含了较多的“平坦”区域,因此基于梯度的焦点测度SML对于它们的敏感性较差。换言之,对属于情形1的子块图像,参数p设置为0,依此可更精确地检测出聚焦区域。
另一方面,对于情形2的图像块,由于含有聚焦与散焦区域的边界,一般具有较大的梯度信息,SML对于它们具有较高的敏感性。通常,SML能够准确地刻画图像的梯度信息,此时再结合导向滤波保持边缘的效果,就可以更准确地得到图像的焦点信息。综上所述,对属于情形2的子块图像,参数p的值应设置为1。
考虑式(15)的阈值S等于SFMB与SFFMB的比值,它反映一般图像的聚焦信息,可以根据S的大小来判断图像块是属于情形1,还是属于情形2。通常,SFMB总是小于等于SFFMB,当两者较为接近时,代表图像块属于情形1。综上分析,并结合实验验证,本文将参数p设置为:
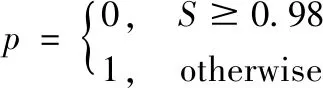
(20)
2)参数r和ε的选择。
r和ε是导向滤波的2个可调节参数。根据1.1节的内容可知,当假设输入图像p与引导图像I相同时,导向滤波为一个保边滤波器。相应地,参数(ak,bk)的计算公式变为:
(21)
bk=(1-ak)pk
(22)
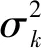

(23)
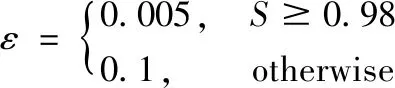
(24)
3)参数w的选择。
w为均值滤波的滤波半径。w需要结合上述导向滤波参数r和ε的设置情况而进行设置。结合实验验证,当w取以下值时,融合实验取得最优的结果。即:
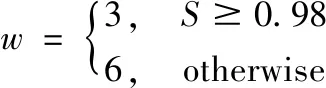
(25)
4)其他参数的选择。
在本文中,式(6)和式(7)中的参数s和T分别设置为1和3;窗口大小设置为3×3。另外,本文将图像子块大小设置为32×32。
2.2 提出的QT分解策略
本文设计一种有效策略用于图像的QT分解。前述,对于多聚焦图像块对只可能出现2种情形,其中对于情形1,全聚焦的块和全散焦的块是完全可区分的。因此,块对的分解准则可以根据块对的2种情形简单地描述为:如果块对符合情形1,则在该块对中可以找到完全聚焦的块;否则,如果块对符合情形2,则其中每个块再分别细分为4个子块。下面对本文提出的分解策略进行详细的描述。
1)根据2.1节中提出的焦点测度,计算出每个源图像的焦点图{FGi,i=1,2}。
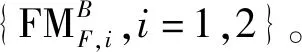
(26)

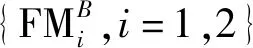

需要强调的是,在实际源图像中,树块对中任何一个块都可能存在一些噪声。因此,对于情形1中树块对的SFMB通常比相应的SFFMB略小一些。考虑这种情况,以及通过实验验证,本文选择0.99作为这种情形的判别阈值。即对于一个树块对,如果SFMB>0.99×SFFMB,则它属于情形1;否则,这个树块对属于情形2。
图2为一个多聚焦图像的QT分解示例。由图2可见,本文提出的分解策略能够很好地将源图像分解成最优大小的块,这也验证了所提出的QT分解策略的有效性。

图2 本文提出的QT分解策略示例
2.3 初始决策图的构造
利用本文提出的QT分解策略可以从源图像中有效地检测出聚焦块,最后由聚焦块组合成初始决策图。具体做法为:首先,将2幅源图像以及对应于源图像的焦点图作为输入;将源图像设置为QT结构的第1级的树块对;对于当前树块对,如果SFMB>0.99×SFFMB,则该块对属于情形1,可通过计算块对的聚焦度量值,找到聚焦度量值较大的树块标记为聚焦区域,否则该块对属于情形2,每个树块将进一步被分为4个子树块。然后,上述过程在较小的块对上重复进行,直到所有树块对满足聚焦条件或达到分解条件的最大级别。最后,对标记的聚焦块进行组合,构成初始决策图。
2.4 决策图优化与一致性验证
为了去除噪声像素,本文采用小区域去除策略。即,如果某一区域的像素数小于N,则该区域被视为小区域。在本文中,将N小于源图像总像素数的1%的区域视为小区域。
2.5 融合
根据最终决策图FDM,通过对应像素的加权平均将源图像I1、I2融合在一起,得到最终的融合图像F,即:
F(x,y)=FDM(x,y)I1(x,y)+(1-FDM(x,y))I2(x,y)
(27)
此外,为了消除融合图像中潜在的伪影,本文利用导向滤波对优化决策图进行一致性验证,得到最终决策图FDM。FDM能够较好地保真聚焦区与散焦区的边界信息,并能有效地减少边界伪影。
3 实验与分析
本文将所提出的方法与其他11种先进的MFIF方法进行了比较。其中,传统方法包括DTCWT[8]、NSCT[9]、GFF[10]、ASR[5]、MWGF[11]、ICA[22]和NSCT-SR[12];深度学习的方法包括CNN[13]、MADCNN[14]、MFF-GAN[17]和SESF[18]。实验在Lytro数据集[23]上进行,并利用5个广泛使用的客观指标进行性能评估。具体而言,它们是归一化互信息QMI[24]、非线性相关信息熵QNCIE[25]、基于梯度的度量QG[26]、基于结构相似性的度量QY[27]、基于人类感知的度量QCB[28]。对于这些指标,其值越大表示融合效果越好。
3.1 定性比较
各种融合方法在Lytro-1图像对中的融合结果如图3所示。为了进行更好的观察,在融合图像中聚焦和散焦部分边界附近的区域被放大并显示在图像的右下角。由图3可知,对于DTCWT、ASR、MADCNN和MFF-GAN方法的融合图像放大区域,在肩膀边缘处明显地呈现出不希望的伪影;MWGF方法的融合图像在放大区域处的“高尔夫球”完全模糊了;而DTCWT、ASR、MWGF、ICA、NSCT-SR和SESF方法在融合图像的“人物”的左手臂和“球杆”边缘出现不同程度的光环和伪影。总地来说,NSCT、GFF和CNN的融合结果整体观感较好,但在它们融合图像的放大区域可以看出整体的清晰度较低。而本文方法相比于其他方法,能够产生更自然清晰的视觉效果。

图3 针对图像Lytro-1不同融合方法得到的融合图像
图4和图5分别是各种融合方法针对Lytro-10图像对的融合图像与图4中源图像A和源图B之间的残差图。它们是通过从每个融合图像分别减去源图像A和B而生成的差值图像。由图4和图5可以观察到,图4和图5呈现出了相似的实验结果。其中DTCWT、NSCT、ICA、MADCNN和MFF-GAN方法的残差图中呈现出大量的噪声像素,这说明这些方法没有将源图像A和源图像B的聚焦区域信息很好地转移到融合图像中。此外,由图4和图5还可见,来自GFF、ASR、MWGF、NSCT-SR和SESF方法的残差图呈现出较多的伪影,这意味着这些方法的融合图像没有在这些区域或边界中融合足够多的聚焦信息。总地来说,CNN方法和本文提出的方法获得了不错的结果;通过仔细观察图4和图5的源图像和残差图,可以看出提出的方法在聚焦与散焦区域的交界处过渡得更加自然,因此本文方法可以提供更好的融合效果。
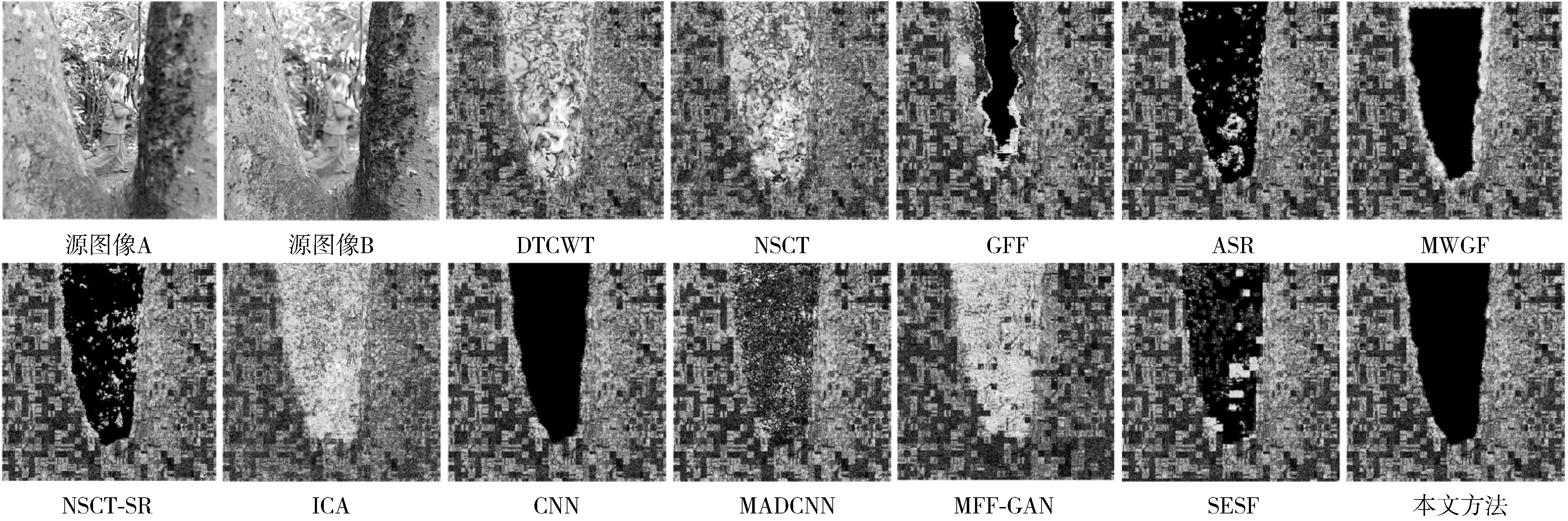
图4 由不同融合方法得到的Lytro-10融合图像与源图像A之间的残差图
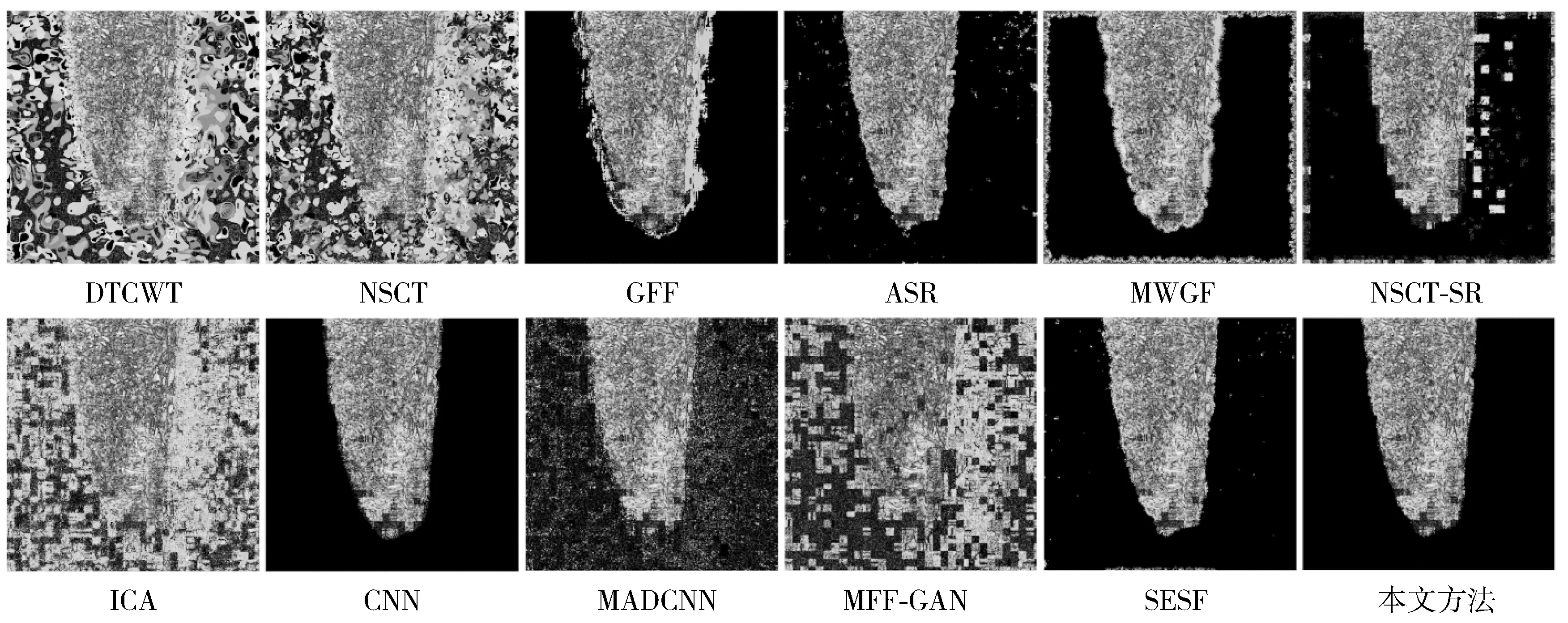
图5 由不同融合方法得到的Lytro-10融合图像与源图像B之间的残差图
此外,有关由本文方法所得到的更多图像融合结果如图6所示。由图6可知,针对广泛使用的多聚焦源图像对,本文方法在QT分解、最终决策图和融合图像等方面均取得了较好的结果,这充分地验证了其有效性和可行性。

图6 提出方法的更多图像融合结果
3.2 定量比较
表1中的结果显示了不同融合方法在Lytro数据集的20对图像中每个客观评价指标得分的平均值。对于每个指标,性能表现最好的结果以粗体显示,括号中显示了一种方法优于其他所有方法的图像对的数量。由表1数据可知,在12种融合方法中,本文所提出的方法在所有指标都显著优于其他融合方法。综合考虑上述定性和定量的比较结果,它们都充分地说明了本文方法的性能总体上优于其他方法,从而验证了其有效性和先进性。
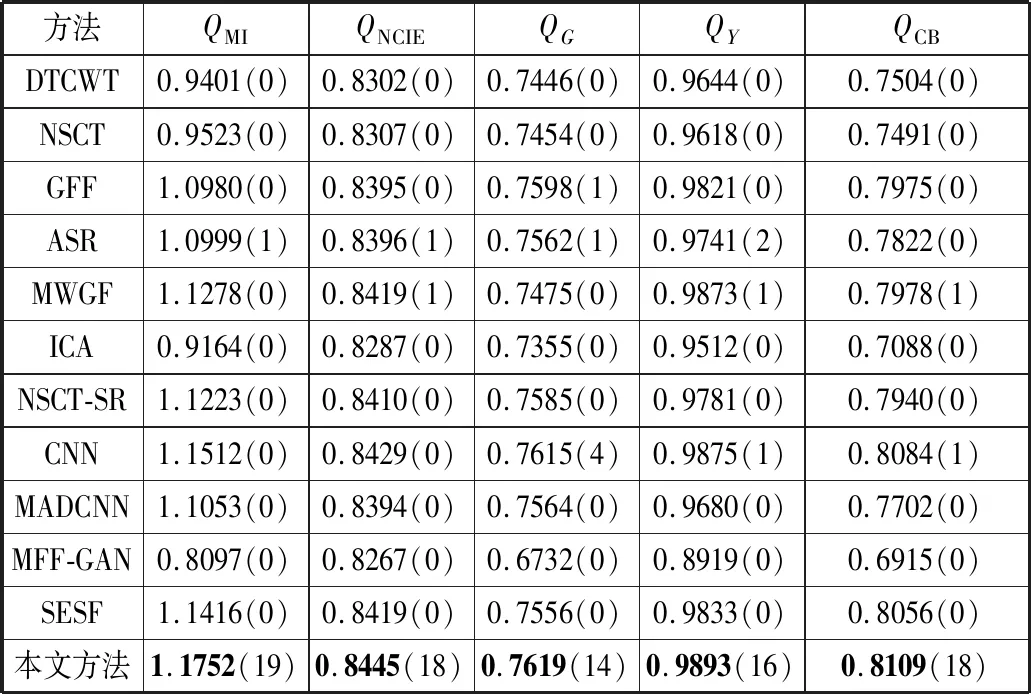
表1 不同融合方法对Lytro数据集的平均实验结果
3.3 计算效率的分析
表2列出了在融合2幅大小为520×520像素的灰度源图像时,不同方法的平均花费时间。由表2的数据可以看出,本文方法在计算效率上达到了较好的一档。虽然本文方法的计算成本略高于某些变换域方法和一些深度学习的方法,但从定性和定量综合评价上看,本文方法都优于这些方法。综上所述,本文提出的方法能够很好地实现多聚焦图像的融合。
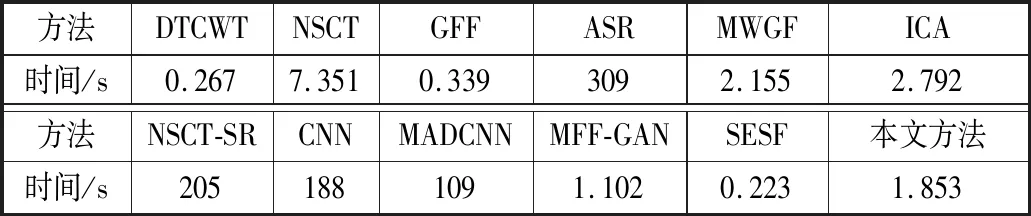
表2 不同融合方法的平均运行时间
4 结束语
本文提出了一种新的基于QT分解和自适应焦点测度的MFIF方法。首先,根据一种新的焦点测度,较精确地得到了源图像的焦点图。然后,采用一种有效的QT分解策略,检测出了源图像的聚焦区域,构成了初始决策图。最后,通过对初始决策图进行优化和一致性验证,重构出了一幅全聚焦的融合图像。本文方法既有效地克服了基于块方法对块大小敏感的问题,又基本消除了融合图像中存在的边界伪影,从而显著地增强了融合图像的质量。通过对公共多聚焦图像数据集进行实验,并与11种先进的MFIF方法进行视觉质量和客观指标比较,实验结果表明,本文所提出的融合方法取得了更好的性能。
