基于Attention-BIGRU-CRF的中文分词模型
2022-08-18徐名海许晓东
周 慧,徐名海,许晓东
(南京邮电大学通信与信息工程学院,江苏 南京 210003)
0 引 言
中文分词是在中文领域中处理自然语言[1](Natural Language Processing, NLP)过程最为基础的一步,是为进一步进行词性标注、机器翻译、信息检索的基础。但是中文的语言体系相对复杂,词与词之间的界限不够清晰,存在一词多义、未登录词、语句歧义的现象,只有结合上下文信息以及语境才能够准确地进行分词。通过中文分词模型能够较好地解决歧义问题,提高信息检索、机器翻译等工作搜索和翻译结果的准确性,从而提高人们的工作效率。
1 相关工作
自然语言作为人类最重要的交际工具,是人类进行沟通交流的最主要表达方式。随着计算机科学的深入发展,计算机已经深入各个领域,如何使人与计算机之间用自然语言进行更直观、更有效的通信成为一个重要的问题,于是诞生了自然语言处理。自然语言处理应用在各个领域,而在进行中文的语言处理中,第一步就是要对中文文本进行分词处理,中文分词主要有3种方式:基于自然语言规则的处理方式、基于概率统计模型的处理方式和基于深度学习网络模型的处理方式。
国内学者对如何进行中文分词以及如何提高分词结果的准确率进行研究。在基于自然语言规则处理中文分词的方法中,主要有正向最大匹配算法[2]、逆向最大匹配算法[3]、双向最大匹配算法[4-5]等。其中,张玉茹[6]针对中文分词算法之最大匹配算法进行研究,详细分析用该算法的长词优先原则进行分词切分,分析最大匹配算法的分类和用最简单的例子阐明算法思想。在基于统计的中文分词方法中,Xue[3]首先提出将语料标注为(B,M,E,S)的四标注集,并基于最大熵(Maximum Entropy, ME)模型实现了中文分词。王威[7]采用条件随机场(Conditional Random Field, CRF)作为分词模型,通过对中文分词预处理和中文分词算法的分析,提出了一种复合词位标记集合来使模型在引入少量参数的前提下,能够在分词的同时更好地识别出语句中的命名实体。此外有人提出将基于规则的分词方法与基于统计的分词方法进行结合,杨贵军等人[8]提出了一种基于最大匹配算法的似然导向中文分词方法,在分词阶段将训练数据的统计信息融入到基于规则的最大分词算法中,通过最大似然原理确定最优分词模型并提高分词准确率。以上提出的中文分词方法是基于规则和传统的机器学习的算法模型,这些模型都受到一定的限制,基于规则的匹配算法受到词典的不灵活特性的限制,只有出现在词典中的词才能匹配,对于未出现过的词即未登录词则受到限制;而对于传统的机器学习模型,对于模型的训练是基于人为设置的特征,针对的场景不够全面,不具有广泛而全面的适用性。
随着人工智能的深入研究,神经网络逐渐成为研究的主要方向,深度神经网络可从原始数据中自动提取深层次抽象特征的优势,避免了人工设计特征的复杂性,在语音识别[9]、情感识别[10]、计算机视觉[11]等领域取得了显著的效果。由于神经网络可以自动学习特征,避免了传统的特征工程。在NLP任务中,深度学习也展现出特有的优势[12]。Bengio等人[13]提出了一种基于神经网络变种的概率语言模型。之后,Collebert等人[14]将神经网络应用到自然语言处理中。Zheng等人[15]首先将神经网络引入到中文分词领域,并利用感知器算法加速训练的过程。Pei等人[16]在文献[15]的基础上,利用标签嵌入和基于张量的转换,提出了名为MMTNN的神经网络模型[17-18]的方法用于中文分词任务。Chen等人[19]首次在门循环神经网络(Gated Recurrent Neural Network, GRNN)网络模型基础上改进了记忆单元的长短期记忆网络(Long Short-Term Model, LSTM)模型用于中文分词,利用门单元实现了对历史信息的选择,解决了长距离信息依赖的问题。例如,刁琦[20]基于LSTM模型并采用六词位标注集进行中文分词,论文结果表明LSTM能够有效解决梯度爆炸和数据稀疏的问题。2016年,Yao等人[21]提出采用双向的LSTM(Bidirectional Long Short-Term Memory, BILSTM)模型进行中文分词,从过去和未来2个方向获取上下文的信息,提高分词效果。由于LSTM神经网络模型较为复杂,存在训练和预测时间长的问题,为了解决这些问题,采取了门限循环单元(Gated Recurrent unit, GRU)神经网络的中文分词方法。GRU模型和LSTM模型都是RNN的变体,相对于LSTM的3个门,GRU模型只有3个门控制单元,模型更加简单,从而运行时间效率更高。Jozefowicz等人[22]对比了GRU和LSTM模型,发现GRU与LSTM的分词方法也具有相似的分词效果,准确率相差不大,但是GRU的运行速度相对于LSTM更快。因此,GRU模型被越来越多地应用在自然语言处理领域中。例如,李雪莲等人[23]提出基于GRU的中文分词方法,继承了LSTM模型可自动学习、克服长距离信息依赖的优点,还提高了分词速率。车金立等人[24]在此基础上提出了一种改进的双向门限循环单元条件随机场(BIGRU-CRF)模型,通过双向门限循环单元有效利用上下文信息,而且可以通过条件随机场层联合考虑相邻标签间的相关性,考虑全局最优的标记结果。但是,这里只考虑了GRU输出层相邻标签的相关性,没有考虑输入和输出之间的相关性的重要性。此外,黄丹丹等人[25]提出将Attention机制与BILSTM-CRF模型结合,在BILSTM-CRF中文分词的模型中融合Attention机制,通过注意机制计算BILSTM模型的输入和输出之间的相关性的重要性,并根据重要程度获得文本的整体特征。但是,BILSTM-CRF的运行时间相对较长,所以在接下来的研究中可以考虑提高分词的运行速度。
LSTM在中文分词中已经取得了较大的进展,分词效率也比较高,GRU与LSTM的分词方法也具有相似的分词效果,但是GRU的运行速度相对于LSTM更快。为了在不影响中文分词的准确率的条件下,进一步提高中文分词的速度,本文将基于BIGRU-CRF模型,提出了将BIGRU-CRF模型与Attention机制结合的中文分词算法,BIGRU能够充分利用上下文的信息,CRF能够使用标签信息,Attention机制能够充分考虑不同字对输出结果的影响程度,综合利用多种信息。利用改进的Attention-BIGRU-CRF模型,在MSRA corpus和人民日报2014公开数据集上进行实验。
2 应用场景
中文分词一般应用在自然语言处理的过程中,比如场景1:用户通过在医院的问诊平台描述自己的症状,问诊平台根据用户症状输出可以就诊的科室。问诊平台将输入的中文文本,首先进行中文分词,将句子划分成一个个的词语,再通过这些词进行判断,获得就诊科室的相应信息。场景2:当用户想要通过搜索引擎[26]获取搜索结果,先要在对话框中输入请求,搜索引擎第一步将文本进行分词,提取请求中的关键字,再进行搜索。场景3:目前市面上比较广泛应用的智能音箱[27](如苹果的Siri、百度的小爱同学等)通过接收语音的方式,获取语音后,将其进行语音识别转换成自然语言文本,然后再对中文文本进行处理。根据以上的应用场景,本文通过图1来表示中文分词的功能。

图1 一般应用场景
结合以上描述和图1可知,中文分词就是将一个中文文本划分成一个个的词语,再对这些词语进行关键词的提取或者分类,从而实现搜索引擎、语音识别、机器翻译等操作。
需求分析:将中文文本(文档、句子等)划分成一个个的字,通过中文分词模型,得到让每个字获取到位置标签的概率。
3 基于Attention-BIGRU-CRF的中文分词建模
中文分词可以看成字的序列标注问题,将分词过程转化为每个字在序列中标注的过程。在中文文本中,由于一个词语中每个字在文本中都占一个确定的词位,因此可以将分词过程视为学习这个字的词位信息的机器学习的过程。本文主要采用四词位标注信息(B、M、E、S),当该字出现在单词的第一位时用词位B(Begin)表示,中间位置用词位M(Middle)表示,词的末尾用E(End)表示,独立的字用词位S(Single),最后根据CRF最后输出的概率大小来判断词位标签。
3.1 现有的分词方法分析
目前,神经网络的算法在中文分词方法中表现十分优越,有利于提高分词结果的准确率。目前常用在中文分词领域的方法如表1所示。
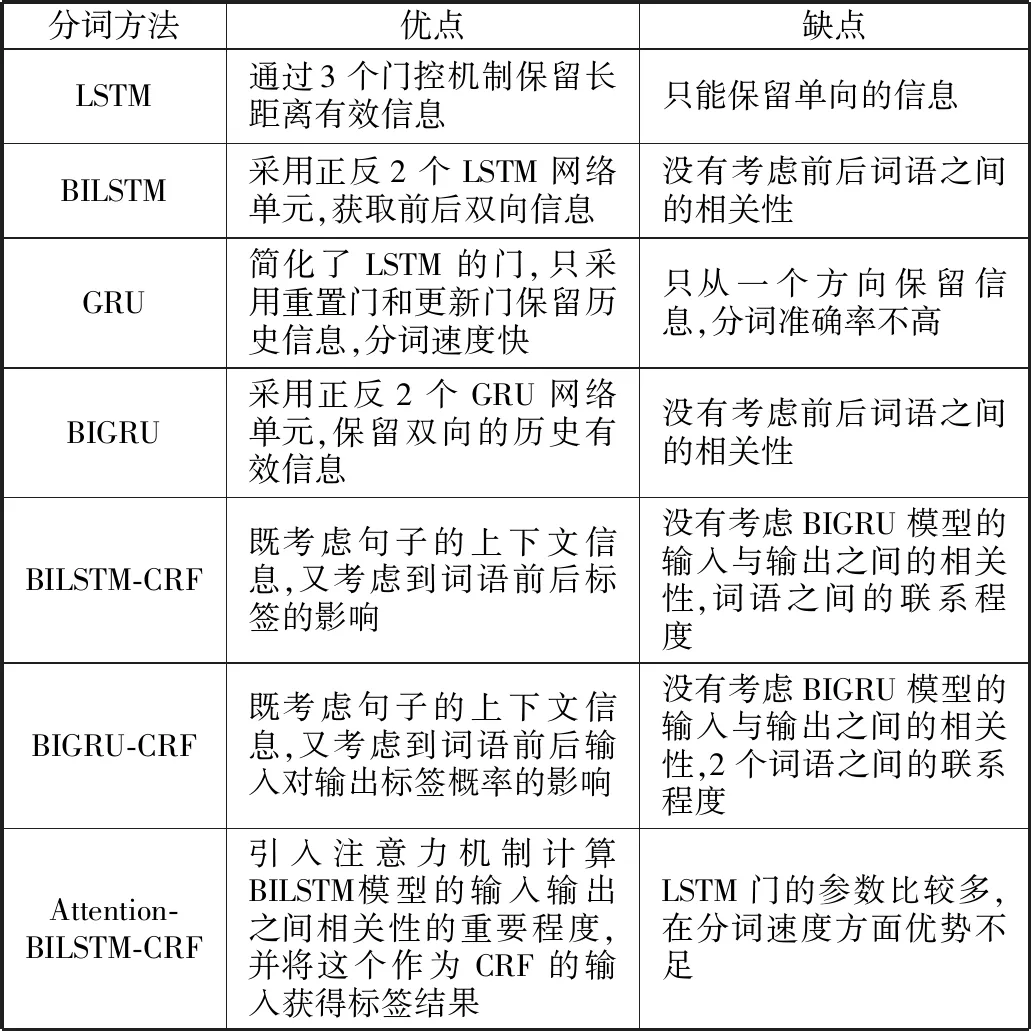
表1 传统中文分词方法优缺点
由表1可知,神经网络具有自动学习、克服长距离信息依赖的优点,还提高了分词效率。但引入attention机制后,运行速率会降低,为了从分词效率和分词速率2个方面考虑,对Attention-BILSTM-CRF模型进行改进。
3.2 基于Attention-BIGRU-CRF模型的中文分词方法
根据以上现有处理中文分词模型的分析,可以得出2个结论:1)GRU模型的参数比LSTM模型参数少,分词速度快;2)引入attention模型能够提高模型分词结果的准确率。
3.2.1 验证GRU模型的参数比LSTM参数少
LSTM模型的原理:LSTM是RNN模型的一种变体,通过门控机制来控制信息传递的路径。通过遗忘门f、输入门i、输出门o分别来控制上一个时刻的内部状态需要遗忘多少信息,控制当前时刻的候选状态保存多少信息,以及控制当前时刻内部状态有多少信息要输出给隐藏状态h。LSTM网络的单元结构如图2所示。

图2 LSTM网络单元结构
图2中x=(x1,x2,…,xn)为输入数据,h=(h1,h2,…,hn)是LSTM单元的输出,LSTM网络单元的计算公式如下:
ft=σ(Wf·[ht-1,xt]+bf)
it=σ(Wi·[ht-1,xt]+bi)
ot=σ(Wo·[ht-1,xt]+bo)
ht=ot⊙g(ct)
GRU模型的原理:GRU模型是RNN模型的一种,GRU和LSTM相似,也是用门控机制控制输入、记忆等信息而在当前时间做出预测。也可以解决RNN网络中的长期依赖问题,有效利用长距离的上下文信息。GRU网络的单元结构如图3所示。
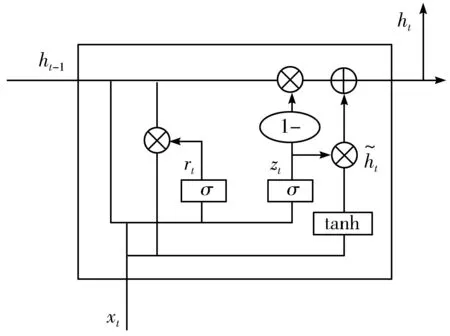
图3 GRU网络单元结构
图3中x=(x1,x2,…,xn)为输入数据,h=(h1,h2,…,hn)是GRU单元的输出,GRU网络单元的计算公式如下:
rt=σ(Wr·[ht-1,xt]+br)
zt=σ(Wz·[ht-1,xt]+bz)

根据上述的原理以及2个模型的公式可以得出GRU的参数少于LSTM的参数,训练和测试相同的文本,参数越少,计算速度越快,分词时间则越短。
3.2.2 引入Attention机制的必要性
Attention机制就是从人脑的注意力机制演化来的,深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。注意力是一种资源分配方案,将有限的计算资源用来处理更重要的信息,是解决信息超载问题的主要手段。
Attention机制是一种模拟人脑的注意力机制模型,可以看成一个组合函数,通过计算记忆力的概率分布,来突出某个关键输入对输出的影响。Attention机制如图4所示。

图4 Attention机制
本文引入Attention模型对BIGRU层的输入与输出之间的相关性进行重要程度计算,根据重要程度获取文本整体特征,以突出特定的字对于整个文本的重要程度。
3.3 融合Attention与BIGRU-CRF的中文分词模型
BIGRU-CRF模型是将BIGRU网络和CRF模型结合起来,即在BIGRU网络的隐藏层后加一层CRF线性层。该模型通过双向GRU结合上下文的特征,并且经由CRF层有效地考虑句子前后的标签信息,提高标签预测的准确率。Attention机制能够考虑BIGRU层的前后输入与当前输出之间的相关性,进一步提高分词的准确率。
本文提出融合Attention与BIGRU-CRF的模型,模型如图5所示。

图5 Attention-BIGRU-CRF模型
由图5可以得到在本文提出的Attention-BIGRU-CRF模型中,第1层是将原始文本序列进行向量化,用一个固定长度的向量表示每一个字。文本向量化就是将自然语言表示的中文文本转换成机器能读懂的数字。这里的文本向量化采用分布式表示法,获得每一个字对应的向量[x1,x2,…,xj,…,xn]。第2层是BIGRU层,通过一个前向和一个后向的GRU模型对输入的文本向量进行处理,通过保留和去除上下文的信息,从而对当前输出字有一个较为准确的预测。第3层是Attention层,Attention机制是获取当前的目标字与输入文本中的所有字的相似性概率值,即词向量层的每一个输入[x1,x2,…,xj,…,xn]与目标向量xt之间的相关性。第4层是组合层,将BIGRU层的输出与Attention层的输出进行组合,获取信息更加充分的字特征。第5层是CRF层,将组合层获取的值作为CRF的输入,预测对应字获取的标签的概率。
本文将Attention机制放置在在BIGRU层和CRF层之间,用于计算BIGRU前后输入hj与当前输入ht之间的相似性,根据相似性判断输入与输出之间的相关性,得到注意力权重系数αtj,将得到的权重系数与BIGRU对应输出hj点乘,表示BIGRU前后输入对当前输出的影响。注意力权重系数αtj计算方法如下:

用一个变量ut表示在t时刻对BIGRU的输出经过Attention机制处理,获取权重系数的加权求和的值,即注意力值。
把经过注意力机制的注意力值ut与BIGRU层的输出ht重新组合成一个向量zt,这个新的向量表示既考虑字向量在通过BIGRU时前后字符的关系又考虑每个字对于整个句子的重要性,从而能够更准确地进行分词操作。
zt=[ut;ht]
接下来,把zt作为CRF的观测序列,状态序列在本文主要是用于表示输出为标签B、M、E、S这4个状态的概率。首先,对打分函数进行定义:
其中,A表示转移分数矩阵,Ai,j表示从标签i转移到标签j的分数。Pn×k是前面几层输出的得分矩阵,n是该句话中汉字的个数,k为标签的个数,Pi,j表示第i个字被标记为第j个标签的概率。
在训练过程中,要最大化正确标签序列的似然概率,具体如下:
其中,YX是指一个输入序列的对应的所有可能标签序列。在解码时,利用动态规划算法,如Viterbi算法,通过以下公式预测其最大得分的输出序列为:
4 结果仿真
本文首先对语料库进行预处理,切分词语的部分信息,不需要词性标注信息。随后对原语料库进行读取并标注,将每个中文字符标注为4种类型。分别为S(0)、B(1)、M(2)、E(3),其中S代表单个字,B代表词的第一个字,M代表词的中间部分字,E代表词的最后一个字。同时将语料库进行划分,将90%作为训练集,10%作为测试集评估模型。
本文将比较Attention-BIGRU-CRF模型与BIGRU-CRF、BILSTM-CRF、Attention-BILSTM-CRF模型的分词效果,以及比较测试相同的数据集下本文模型与Attention-BILSTM-CRF模型两者的训练速率。
4.1 仿真平台与参数设置
本文实验模型基于Python3.7和TensorFlow1.14版本,实验数据采用MSRA corpus和人民日报2014公开数据集。MSRA corpus数据集参数设置如表2所示。
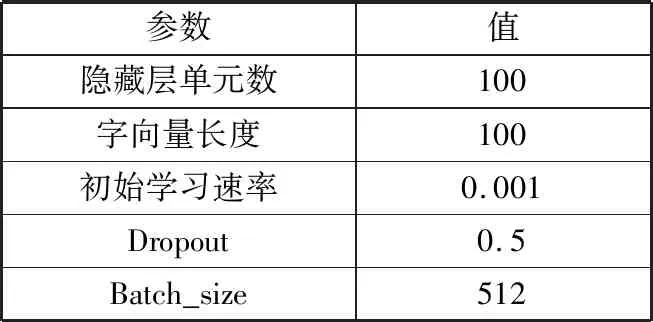
表2 参数设置
4.2 评价指标
本文采用准确率(Precision)、召回率(Recall)和F1测量值作为评估指标,指标的计算方式如下:
准确率:P=正确分词的个数/识别文本的词语数
召回率:R=正确分词的个数/文本中总词语个数
F1值=2×P×R/(P+R)
准确率和召回率是一般多用于信息检索、机器学习领域的2个度量值,用来评价结果的质量。在本文中,准确率和召回率分别从不同角度表现了模型的分词性能,两者的指标是负相关的,而F1值综合考虑了两者,所以模型的效果将优先看F1值表现。
分词速度主要是观察不同模型分词的用时,以KB/s为单位计算。
4.3 仿真结果分析
为了对本文提出的模型做出更加客观的评价,本文分别对人民日报语料和MSRA语料进行测评,具体实验结果如表3和表4所示。对人民日报语料库中进行分词速度的测试,结果如表5所示。

表3 人民日报语料测试结果

表4 MSRA语料测试结果

表5 分词速率
根据图6和图7,首先比较BIGRU-CRF和Attention-BIGRU-CRF这两者的实验结果,后者的F1值在人民日报语料和MSRA语料库上比前者分别高出2.08个百分点和2.05个百分点。由此可见,Attention能够利用BIGRU网络的输入输出相关性,提高分词的效果。
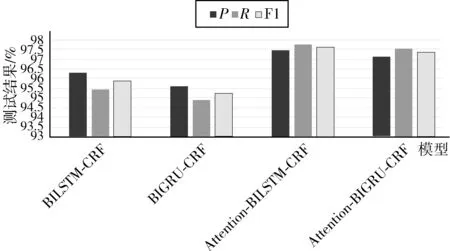
图6 人民日报语料测试结果对比
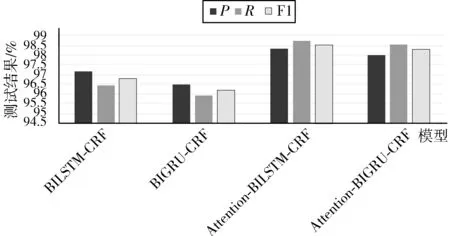
图7 MSRA语料测试结果对比
此外,通过实验计算出人民日报语料测试集前50轮的F1值的更新时间,通过表5可以得知,Attention-BIGRU-CRF训练同样的数据花费的时间要少于Attention-BILSTM-CRF,由此可以说明Attention-BIGRU-CRF模型有更高的训练效率。
5 结束语
针对中文分词的准确率,本文在BIGRU-CRF的模型上,提出了一种Attention-BIGRU-CRF分词模型,该模型不仅继承了BIGRU模型可以同时利用双向上下文的信息与相邻标签间的相关性进行分词,还考虑到BIGRU层的输入输出之间的关系,从而进一步提高分词效率。通过该模型在人民日报和MSRA语料库上进行测试,结果表明Attention-BIGRU-CRF在分词效率上优于BIGRU-CRF,在训练效率上优于Attention-BILSTM-CRF。说明本文的模型不仅在分词效果上有优越性,分词的训练速率也具有优越性。如今分词效率已经获取了较大的进步,但是仍然存在一些不足,可以考虑在词向量层进行改进,利用BERT语言预处理模型来表征词向量,能够在词向量层描述字符级、词级、句子级甚至句间关系特征,进一步提高分词结果的准确率。
