面向产品指标图谱的知识表示学习方法研究
2022-08-15邱雪单世民魏宏夔王恺杨念顺
邱雪,单世民*,魏宏夔,王恺,杨念顺
(1.大连理工大学 辽宁省泛在网络与服务软件重点实验室,辽宁 大连 116620;2.北京电子工程总体研究所 复杂产品智能制造系统技术国家重点实验室,北京 100854)
0 引言
随着科技水平的快速发展,工业制造领域中的复杂产品在功能、构型和性能指标方面的数量种类及复杂程度也在快速提升。传统的复杂产品需求分析方式难以满足客户的快速响应要求,难以保持和提升复杂产品研发企业的市场竞争力。构造复杂产品的指标参数知识图谱,可以辅助企业产品研发人员对已有产品数据进行快速统计分析。同时,利用前沿的图谱表示推理算法[1],可以为新产品的指标参数需求提供有效的预测推理。
知识表示学习方法是近年来人工智能和知识图谱领域的研究热点。通过将知识图谱中的实体和关系表示为低维向量空间中的稠密向量,知识表示学习已经被应用于知识图谱补全[2]、关系链接预测[3]和一系列知识图谱下游任务之中[4]。然而,现有的表示学习方法所应用的知识图谱,只关注实体-关系之间的离散型关联,而不考虑数值型属性。对于产品指标知识图谱,大多数产品指标参数属于数值型数据。当一类产品指标的数值足够精确,同时不同产品指标变化幅度较大时,会导致相似数值被表达成大量相互独立的离散实体。这些实体不仅会耗费大量的训练参数,还会对模型预测精度产生负面影响。
针对产品指标知识图谱的数据特性和业务需求,本文在已有知识表示学习方法的基础上,重点研究针对数值型指标的表示学习技术。首先,考虑到产品指标图谱的数据特点,本文从产品指标数据中抽取产品指标图谱数据,将产品间关联关系和产品的指标参数分别用三元组的形式存储起来,作为知识表示学习算法的实验数据集。其次,本文创新性地研究数值型指标参数的分布式表示方法。设计产品数值型指标的离散化区间划分策略,通过大量的仿真实验验证了数值型指标表示方法中的关键要素,即区间数量和划分方法。再次,针对关系三元组和指标三元组的语义差异,探索全新的联合学习训练方案。本文提出了四种训练方案,包括单独学习、合并学习、依次学习和交替学习,以探索指标三元组的有效知识表示学习方法。
本文在五个前沿知识表示学习算法上进行了 试 验 ,包 括 TransE[5],DistMult[6],Com⁃plEx[7],ConvE[8]和 RotatE[9]。实验结果表明,RotatE模型的链接预测功能总体上占据优势,在关系三元组和指标三元组预测上均表现出优异的性能。对于细粒度区间划分的指标参数预测任务,ConvE方法相比其他知识表示学习模型更为适合。合并学习方案可以同时保证关系三元组和指标三元组的预测精度,而依次学习方案可以达到更高的指标预测精度。针对产品指标知识图谱的推理需求,需要权衡预测精度和区间个数的设置,以期保证高准确率的前提下,实现适当区间精度的指标参数预测,为后续的产品指标关联预测和产品方案生成奠定基础。
1 相关工作
知识图谱嵌入(KGE)将实体和关系表示为嵌入空间内的向量或矩阵,是语义网络和机器学习领域中的一个新兴主题。根据模型架构,最近的KGE方法可以大致分为三类[10],包括向量距离模型、矩阵分解模型和神经网络模型。
以TransE[5]模型为代表的向量距离模型,将关系视为头尾实体之间的平移操作,通过计算实体向量之间的距离来评估三元组为真的概率。为了解决TransE的缺陷,后续相继提出了TransH[11]、TransR[12]和 TransD[13]等变体。同时,矩阵分解方法是知识表示学习的另一个重要途径,其中代表性的方法是RESACL[14]模型。DistMult[6]模型是 RESACL 模型的简化版本,将每个关系的投影矩阵改为关系向量表示,再将向量转化为对角矩阵,用于整合头尾实体向量。ComplEx模型[7]使用复数向量表示空间来提高非对称关系的表示性能。最新模型RotatE[9]将TransE模型的平移操作改为旋转操作,通过将关系向量表示为实体向量间的旋转变换,得到了远超TransE模型的推理效果。随着深度学习的发展,神经网络模型在最近的KGE研究中取得了卓越的性能,例如ConvE[8]和ConvKB[15],引入了深度神经网络并通过向量语义匹配对三元组打分。其中,ConvE模型重塑并连接了实体和关系嵌入,并利用多层卷积网络模型进行链接预测,在保证计算效率的同时提高表征精度。
针对知识图谱中的数值型数据问题,Alber⁃to等[16]提出了一种结合潜在特征、关系特征和数值特征的知识表示学习方法,但他们针对的是常识知识图谱中的数据稀疏问题,将少量数值特征的差异分布拟合到稀疏图谱数据中。而本文工作的问题场景和研究目标与其不同。首先在产品指标知识图谱中,大部分三元组包含数值型信息,且不同指标的数值分布有明显差异。不同于以往研究针对离散型关系三元组的预测,本文重点是实现数值型指标的准确预测,为此提出了数值离散化方法和联合训练策略。
2 研究方法
本文在已有知识表示学习方法的基础上,重点研究针对数值型指标的表示学习技术。数值型指标向量表示方法通过将数值型指标进行有效的离散化处理,使得知识表示学习模型能够有效学习指标参数的向量化表示。另外,本文提出了关系-指标三元组联合学习方法,针对产品指标图谱的实际需求,探索有效的产品指标知识图谱的表示学习训练方案。
2.1 数值型指标的向量表示方法
如何对数值型指标实体进行向量表示,从而有效地应用于知识表示学习方法,是本文的研究重点之一。针对这一问题,本文提出了数值型指标的向量表示方法,其核心思路是将不同类型的数值型指标进行有效的离散化处理,使得知识表示学习方法能够有效学习数值型指标的分布式向量。指标离散化区间划分取决于两个因素,区间个数和划分方法。前者决定了最终该指标会被离散化为多少个同等类别,后者决定了对满足一定数据分布的数值参数如何进行等量划分。同时,这两个因素对知识表示学习方法性能的影响也是未知的,因此需要在实验中进一步验证。
对于区间个数因素,我们选择了五种选项,分别为5,10,20,50和100。直观上讲,过多和过少的区间划分都会对知识表示学习模型的准确度造成影响。首先,过少的区间使得最终分类类别数量小,虽然相对准确度会提高,但导致预测结果过于粗略,缺少实用价值。另一方面,过多的区间划分会增大最终分类的难度,降低模型预测的准确率。区间划分过细也会导致相似实体的指标参数无法建立关联,从而难以学到图谱中的隐含规律。
对于划分方法因素,本文选择了两种不同的方法,分别是基于数值的等量划分(Uniform)和基于频度的等量划分(Scale)。首先,Uniform方法在给定前期统计的指标数据m的最大值mmax和最小值mmin后,直接将最值区间均分为N份(其中N为预设的区间个数)。每个划分区间的长度n=(mmax−mmin)/N,每个区间的数值间距是基本相等的。使用Uniform划分方法进行划分后,划分区间的集合Z_U可以表示为:
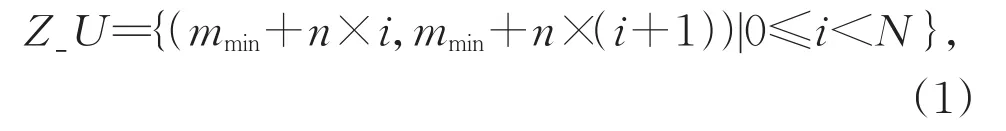
其次,Scale方法是考虑已知指标参数的分布情况,保证每个区间内的指标参数数量相同。当N=4时,Scale方法相当于统计四分位数,利用四分位数和均值将整个取值空间划分为4份。则每个划分区间的数值个数为l,即l=L/N,其中L表示整体样本数量。使用Scale划分方法进行划分后,划分区间的集合Z_S可以表示为:
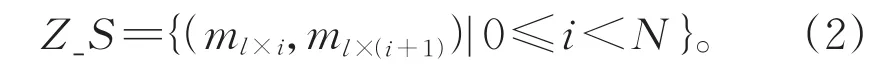
比较两种划分方法可以看出,Uniform方法适用于数值分布较均匀,且取值范围较小的情况;而Scale方法更适合数据分布不均匀,取值范围较大的指标参数。在给定区间划分之后,我们将原本的数值型指标参数转化为对应的离散型指标类别。具体的,给定一个数值型参数,程序从小到大遍历该指标的划分区间。当该参数满足某个区间的取值条件时,该参数便确定为对应的离散类型,不同的离散型指标类型在知识表示学习方法中将对应不同的分布式表示向量。
2.2 关系−指标三元组联合学习方法
设ℑ和ℜ表示实体和关系的集合,知识图谱G是 事 实 三 元 组 (eh,r,et)的 集 合 ,其 中eh,et∈ℑ,r∈ℜ。Ne和Nr分别表示实体和关系的 数 量 ,给 定 一 个 e-r查 询q=(ein,r),其 中ein∈ℑ和r∈ℜ,链接预测任务是找到emiss∈ℑ,使得 (ein,r,emiss)或 (emiss,r,ein)属于知识图谱G。知识图谱嵌入(KGE)旨在将每个实体e∈ℑ和每个关系r∈ℜ表示为d维连续向量。大多数KGE模型都采用负采样损失作为训练目标,使得每个正确三元组t的得分都小于随机生成的负样本三元组。T表示正样本三元组集合,T'表示负样本三元组集合。以最大间隔损失为例,损失函数定义为:

其中ϕ(t)是模型的得分函数,而γ>0是边界值参数。
以往的知识表示学习方法将知识图谱中的实体默认为相互独立的离散型要素,将每个离散型实体表示为一个低维连续向量。对于产品指标知识图谱,通过上述离散化方法将数值型指标参数转化为离散实体,使得数值型指标实体可以直接输入到现有知识表示学习模型中。然而,“产品-指标-参数”形式的三元组和以往图谱中“实体-关系-实体”三元组在语义层面上是有所差异的。为了便于区分,本文将前者称之为离散型关系三元组,后者称之为数值型指标三元组。
本文的核心研究目标是对产品的指标体系进行预测和推理,因此数值型指标三元组是研究的重点。但是,其他离散型关系三元组的作用不容忽视,不同于指标参数这种底层数据,产品指标图谱中的离散型关系三元组一般存储有产品的高层类别划分,能够反映产品之间的层次结构和关联关系。因此,如何实现关系三元组和指标三元组的联合学习是本研究方案中的重点。为此设计了四种类型的训练方案:单独学习、合并学习、交替学习和依次学习,以此来探究有效的产品指标图谱的知识表示训练方法。知识表示学习的基本模型图以及关系-指标三元组联合学习方法如图1所示。

图1 知识表示学习基本框架(a)及关系-指标三元组联合学习方法(b-e)(b)合并学习;(c)交替学习;(d)单独学习;(e)依次学习Fig.1 Basic framework of knowledge representation learning(a)and relational-index triple joint learning methods(b-e)(b)Merge learning;(c)Alternating learning;(d)Single learning;(e)Sequential learning
●单独学习:将关系三元组和指标三元组分割为两个图谱子图,分别输入到知识表示学习模型中训练。
●合并学习:将关系三元组和指标三元组合为一个完整图谱,输入到知识表示学习模型中训练。
●交替学习:对于同一个知识表示学习模型,交替使用关系三元组和指标三元组进行训练。
●依次学习:对于同一个知识表示学习模型,先用关系三元组训练若干轮再输入指标三元组进行训练。
对于每个训练方案,本文选择了五种不同的前沿知识表示学习模型进行训练,包括TransE,DistMult,ComplEx,ConvE 和 RotatE。上述模型的得分函数和损失函数如表1所示。
综上所述,本文通过提出多种数值型指标的向量表示方法和关系-指标三元组联合训练方案,探索有效的产品指标知识表示学习方法,从而为后续的产品指标关联预测和产品方案生成奠定基础。
3 研究实验及结果分析
为了验证提出的模型框架,本文构建了复杂产品指标图谱数据集进行实验测试。不同于以往的知识表示学习图谱数据集,复杂产品指标图谱数据集包含离散型关系三元组和数值型指标三元组两部分,基本数据统计参数如下。
● 实体数:2 971,离散型关系数:12,数值型关系数:48;
●关系三元组个数:训练集8 270,验证集640,测试集646;
●指标三元组个数:训练集12 701,验证集703,测试集704。
知识表示学习模型的主要评测任务是知识图谱链接预测任务,即给定三元组中的实体-关系两项,来预测缺失的另一个实体。通过使用训练集三元组来训练知识表示学习模型,学习每个实体向量对应的连续值参数,然后通过验证集评测性能来调整模型超参数,最后用测试集来评估模型的预测性能。知识表示学习模型的链接预测任务具有多种性能评估指标,具体包括:
(1)平均排名(MR):指目标实体在最终预测序列中的排名的均值;
(2)平均排名倒数(MRR):指目标实体排名的倒数的均值;
(3)前N项命中率(Hits@N):指目标实体排在前N项的百分比。
一般来说,越低的MR值和越高的MRR、Hits@N值表明模型的预测性能越好,准确率越高。
3.1 产品指标图谱构建
本文采用的知识图谱数据集针对复杂产品制造领域构建而成。由于该领域数据具有敏感度高、机密性高的特点,最终选择《某型号装备数据大全(第三版)》作为数据源。本节简要介绍针对复杂产品指标数据的数据采集和图谱构建过程。
由于数据源是不可编辑的PDF扫描文件,从时间成本与人工成本的角度出发,本文采用自动化提取PDF扫描文件信息的方法。通过光学字符识别(OCR)技术,从PDF扫描文件中识得复杂产品指标数据,保存到Excel表格文件中。但提取出来的数据存在明显噪音,典型错误包括:某些数学符号无法识别,数值型数据小数点遗漏,数值型数据留有空格和涉及特殊字符的产品名称识别失败等。
为保证提取的指标数据信息与原始数据一致,我们对Excel数据内容进行人工校验,修改错误信息,并进行了一系列复杂产品指标的数据清洗工作,主要包括复杂表头拆分、添加复杂产品类别信息、数值型结构指标数据格式统一、文本型结构指标数据分类等。经过上述预处理后的数据均为结构化数据,按照预先定义的复杂产品本体结构,以“产品-关系-实体”和“产品-指标-数值”的形式,将结构化数据转化为图谱三元组形式,用作后续知识表示学习模型的实验数据集。

表1 五个经过预训练的KGE模型的得分函数和损失函数Table 1 Score function and loss function of five pre-trained KGE models
3.2 产品指标图谱上的链接预测性能
本文采用了五种前沿的知识表示学习模型测试其在产品指标图谱上的链接预测性能。为了保证实验的公平性,在训练阶段统一采用合并学习方案,在测试阶段分别对两部分测试集进行单独评测,指标划分方法采用Scale方法,区间大小设置为10。链接预测任务的实验结果如表2所示。
从表2看出,五种知识表示模型在两个三元组子图上,均表示出较高的预测精度。在产品关系三元组上,RotatE和ComplEx模型优于其他三种模型。尤其在Hits@1指标上,两模型准确度均超过了50%。相比之下,TransE的预测性能最弱。相似的趋势同样反映在产品指标三元组上,RotatE模型在Hits@1指标上优于其他模型,而ConvE模型在Hits@3和Hits@10指标上达到最佳。结合两部分三元组子图的预测结果可以看出,RotatE模型总体上占据优势,在关系三元组和指标三元组的预测结果上均表现出优异的性能。同时,对比关系三元组和指标三元组的预测结果可以看出,指标三元组的预测准确率明显优于关系三元组,这意味着知识表示学习模型有能力针对产品指标参数进行一定的预测和推理。
3.3 关系−指标三元组训练方案评估
上述实验中将关系三元组和指标三元组共同训练,相当于训练方案中的“合并学习方案”。本文进一步分析了不同训练方案对三元组预测精度的影响,以期找出最优的三元组训练方案。本文对四种训练方案下的知识表示模型分别进行了训练评估,实验结果如图2所示。
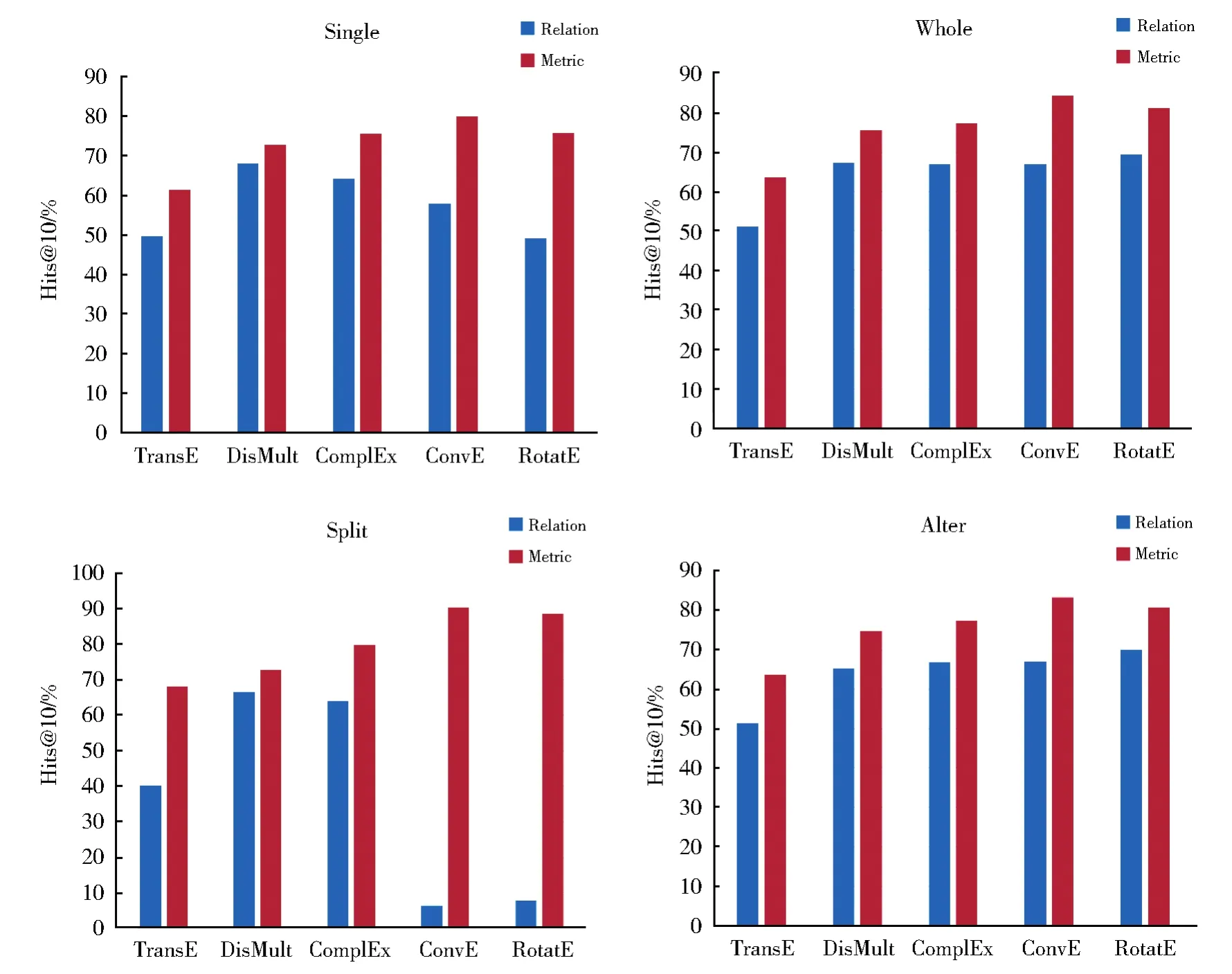
图2 不同训练学习方案下的模型性能Fig.2 Performance of models under different training and learning schemes
首先,比较单独学习和合并学习方案可以看出,合并学习方案的关系、指标三元组预测精度明显优于单独学习方案。这一差异在ConvE和RotatE模型的结果中尤为显著。原因可能在于,两类三元组混合后,丰富了产品指标图谱的数据信息,使得一些原本稀疏的实体得到了更充分的向量表示学习,因而预测准确率有所提升。此外,合并学习和交替学习方案的模型性能几乎一致。在此基础上,从实际训练成本上考虑,合并学习方案相对更优。
依次学习方案的预测性能和其他方案有明显的差异,尤其体现在ConvE和RotatE模型上。先训练的关系三元组的预测性能被大幅度削弱,同时后训练的指标三元组性能却被进一步提升,甚至超越了其他三种方案的指标三元组预测性能。分析原因可能为,预先对关系三元组的训练相当于对图谱进行了更为准确的初始化,使得产品实体在初始阶段就具备一定的聚类特征,从而更有利于指标三元组的训练。
综上所述,针对产品指标图谱的推理需求,可以采取不同的训练方案。当同时需要确保关系三元组和指标三元组的预测精度时,可以采用合并学习方案。当追求更高的指标三元组的预测精度时,则依次学习方案更为适合。
3.4 数值型指标表示方法评估
针对数值型指标三元组的预处理方法,本文进行了详细的实验探究。为了将数值型指标转化为有限个离散型实体,采用Scale和Uniform两种划分方法和多种区间个数,分别对数值型指标三元组进行预处理,然后在知识表示学习模型上比较预测性能。实验结果如图3所示。

表2 多种模型在产品关系三元组和指标三元组上的链接预测性能Table 2 Performance of link prediction to various models on product relational triples and index triples
首先,从区间个数角度来看,随着区间个数的增多,三种知识表示学习模型的预测性能都呈现出下降趋势。这是由于当区间划分过细时,模型需要区分的相似实体数量明显增多。因此,在产品指标预测的实际应用中,需要权衡区间个数的设置,以期保证高准确率的前提下,实现适合精度的指标参数预测。
其次,从划分方法的角度来比较,Uniform方法在三个模型的不同区间个数条件下基本优于Scale方法。尤其体现在区间个数为100时,Uniform方法的Hits@10指标比Scale方法高出5%。这表明基于数值的区间划分方法,更适合产品指标图谱的参数离散化处理。分析原因可能是,Scale方法对取值范围进行均分,导致不同区间内的标注样本数量不平衡。相比之下,Uniform方法保证了不同离散区间中的三元组数量基本一致。
再次,通过比较三种不同类型的知识表示学习模型可以看出,基于转移距离的TransE模型预测性能明显较弱,在不同区间个数和划分方法条件下均弱于其他两种方法。对比基于矩阵分解的ComplEx方法和基于神经网络的ConvE方法可以看出,ConvE方法在区间个数较多的情况下,预测性能仍能保持75%以上的较高水准。因此对于细粒度区间划分的指标参数预测任务,ConvE方法相比其他知识表示学习模型更为适合。
4 结论
本文通过构建知识表示模型,将产品指标图谱中的实体,关系和指标参数投影到低维向量空间,实现对实体关系的语义信息表示,挖掘指标参数之间的潜在关联,实现产品性能指标的有效预测。本文通过研究数值型指标参数的向量表示,对知识图谱中蕴含的产品-指标-属性数据进行分布式表示,并探索全新的联合学习训练方案,为后续性能推理和预测算法提供坚实的数据基础。实验表明RotatE模型的链接预测功能总体占据优势,在关系三元组和指标三元组的预测结果上均表现出优异的性能,而基于依次学习训练方案的ConvE模型更是在Hit@10指标上达到了最优的90.27%。针对产品指标图谱的推理需求,本文可以根据实际情况采取不同的训练方案。后续将在其他领域数据集上对本文算法进一步进行测评。
