基于熵权法的过滤式特征选择算法
2022-08-09李占山杨云凯张家晨
李占山, 杨云凯, 张家晨
(吉林大学 软件学院, 吉林 长春 130012)
特征选择是模式识别和数据挖掘中的一个重要预处理步骤.其本质含义是指在不明显损失数据集潜在信息的基础上从原始特征集合中选出部分特征构成特征子集,以此来降低数据集的特征维度,规避维度灾难,提高分类的时间效率,它可以缩减训练时间并产生具有可解释性的模型[1].
一般地,特征选择可以分为过滤式[2]、封装式(包裹式)[3-5]、嵌入式[6-7].过滤式特征选择算法的核心在于过滤标准,即通过某种准则对特征(子集)进行度量.为此人们提出了多种评价准则,如基于距离度量标准的RReliefF[8]、基于互信息理论的准则[9]等.
近年来人们提出了多种基于互信息理论的过滤式特征选择算法,如MIFSU[10]、mRMR[11]、NMIFS[12]、INMIFS[13]、WNMIFS[14]、CFR[15]、WCFR[16]等.
然而上述算法往往只局限于互信息这一度量标准,虽然互信息可以较好地度量变量之间的相关性,但其在实际应用中也有一定的局限性——互信息是基于信息熵理论的,该理论对于连续变量的信息熵,采取了微分熵的计算形式得出.但对于给定的数据集,常常无法知道连续变量的具体概率分布,进而无法计算其概率密度函数,也就不能在真正意义上计算得出连续变量的信息熵.这种情况下人们往往会采取将数据离散化的策略,将原始的连续变量转化为离散变量,又或者采取K-近邻等方式进行估算,这无疑在一定程度上引入了误差.
基于上述考虑,本文为了规避采取单一的互信息标准的局限性,试图在互信息的基础上引入另一种基于距离度量的算法RReliefF,以期能更好地对特征进行筛选.
RReliefF本是用于回归任务中的特征选择算法,它基于距离度量评估特征的重要性,RReliefF算法运行效率高,且对数据类型限制较少,因此可以作为互信息度量的一个有效补充.鉴于分类任务和回归任务的同一性,本文适应性地将RReliefF用于分类任务,度量特征与标签的相关性.
最大互信息系数(maximal information coefficient,MIC)是一种优秀的互信息变形,MIC利用了归一化互信息,使得MIC具有普适性、均衡性的优良特性,本文采用MIC度量特征与特征之间的冗余性、特征与标签的相关性.
RReliefF和MIC分别从距离度量和信息论的角度评估特征,将两者结合可以在某种程度上避免算法限于某一度量标准的单一性和盲目性,最大程度地挖掘特征的重要性.
通常情况下,人们往往会通过为不同事物赋权重的方式将事物结合起来,赋权的方式有主观赋权和客观赋权.主观赋权的随机性和主观性较大,普适性和自适应性较差.本文追求算法的稳定性和普适性,因此摈弃了主观赋权的思路.
熵权法是一种优秀的客观赋权方法,它基于信息熵理论,使得赋权过程更具客观性,赋权结果具有更好的可解释性.基于熵权法的上述特性,本文采用熵权法为RReliefF和MIC赋权,如此可以更充分地发挥两者各自的优势,使最终的度量标准更趋于完善.在此基础上,本文提出了基于熵权法的过滤式特征选择算法(filtering feature selection algorithm based on entropy weight method, FFSBEWM).
1 基于熵权法的过滤式特征选择算法(FFSBEWM)
基于熵权法的过滤式特征选择算法框架如图1所示.
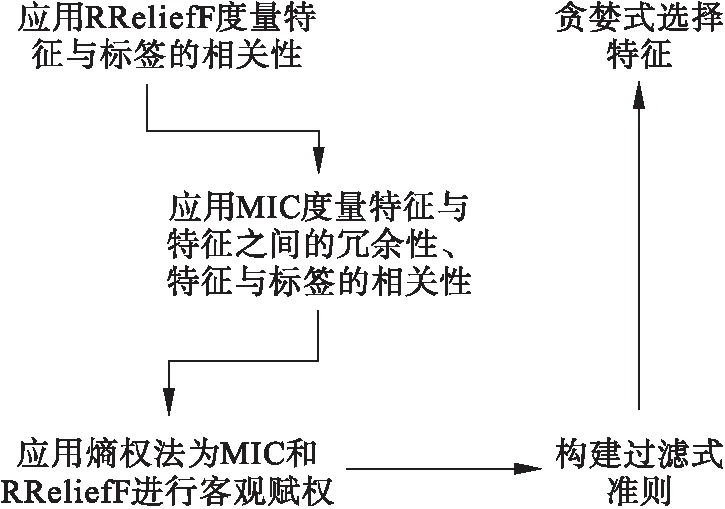
图1 基于熵权法的过滤式特征选择算法框架
1.1 RReliefF度量数据集的各个特征
RReliefF算法原是用于回归任务中的特征选择算法,该算法的伪代码如表1所示[8].

表1 RReliefF伪代码
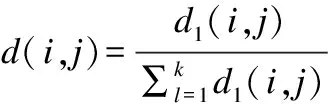
由表1可知,对于特征A的权重,该算法选取g个最近邻样本,利用该样本与近邻样本间的距离来评估A的重要性.
RReliefF可以发现属性之间的强依赖关系,且具有良好的鲁棒性.
回归任务中样本的标签是连续值,而分类任务中样本的标签是离散值,且离散值在逻辑上是一种特殊的连续值,因此RReliefF同样可以应用于分类任务.设定g=5,假定数据集的特征个数为l,对特征{A1,A2,…,Al}应用RReliefF算法进行度量,得到各个特征的权重值,以向量r表示,r=[W[A1],W[A2],…,W[Al]]T.
1.2 MIC度量各个特征与标签的相关性
MIC最初由Reshef等[17]提出,它基于互信息理论.在此本文对互信息理论予以简单介绍.
互信息用于评价两个变量的统计相关性.对离散型随机变量X和Y,其互信息定义如下:
(1)
式中:ΩX为变量X的取值空间;ΩY为变量Y的取值空间;p(x)为X=x的概率;p(y)为Y=y的概率;p(x,y)为X=x且Y=y的联合概率.
除了式(1)外,对离散变量X,Y之间的互信息也可以用信息熵来表示.其定义如下:
I(X;Y)=H(X)-H(X|Y)=
H(Y)-H(Y|X)
.
(2)
式中,H(X)即为变量X的熵,其表达式为
H(X)=-∑x∈ΩXp(x)lb(p(x))
.
(3)
变量X的信息熵描述了变量X的不确定性,变量不确定性越大,信息熵就越大,这也意味着变量X隐含的信息越大.式(2)中H(X|Y)表示在已知Y的条件下X的不确定性,其计算公式为
H(X|Y)=
-∑x∈ΩX∑y∈ΩYp(x,y)lb(p(x|y))
.
(4)
MIC的核心思想:如果两个变量之间存在某种关系,那么可以在两个变量构成的散点图上绘制一个网格,从而划分数据来封装这种关系.假设有两个随机变量X,Y,其MIC计算方式如下:
(5)
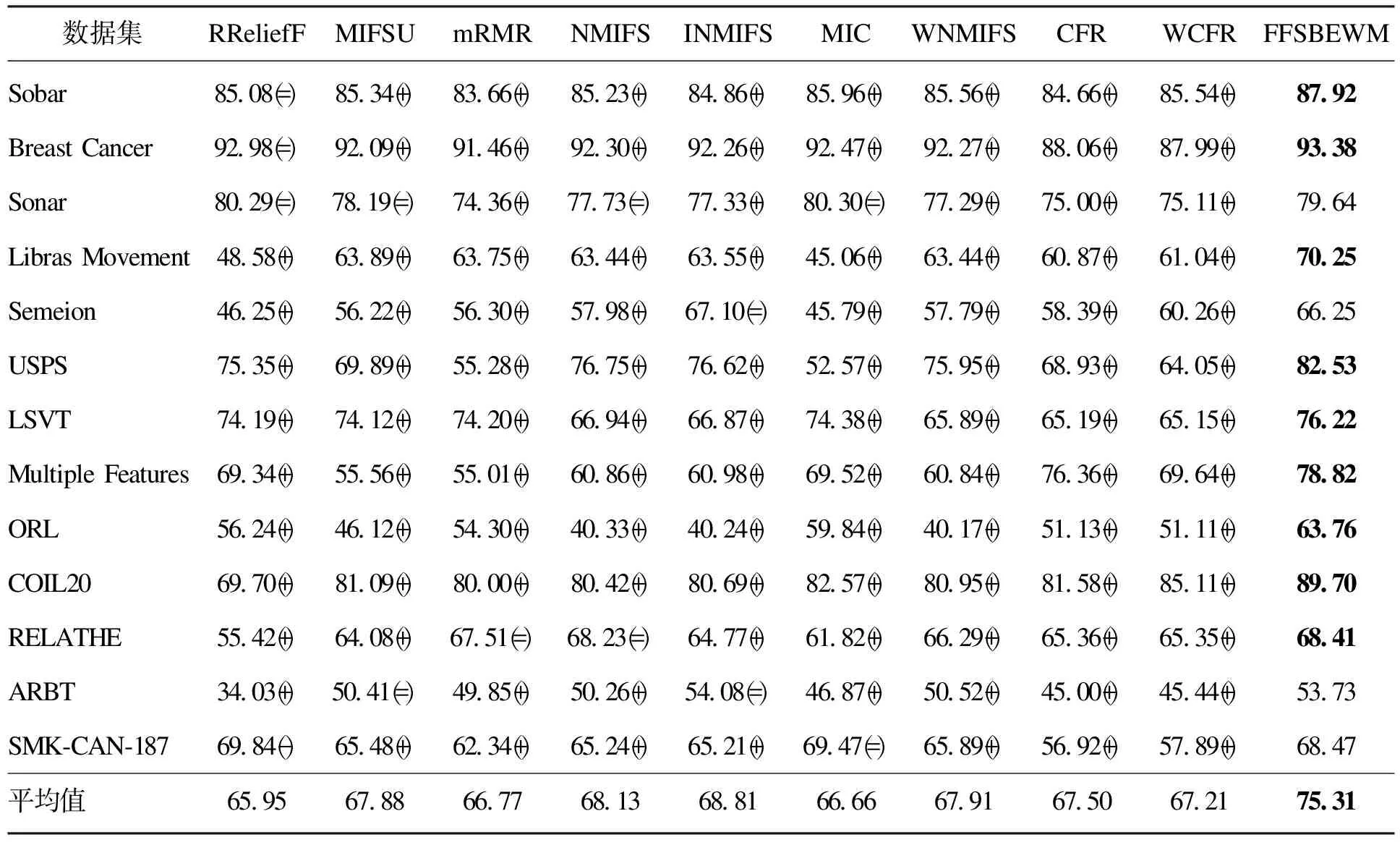
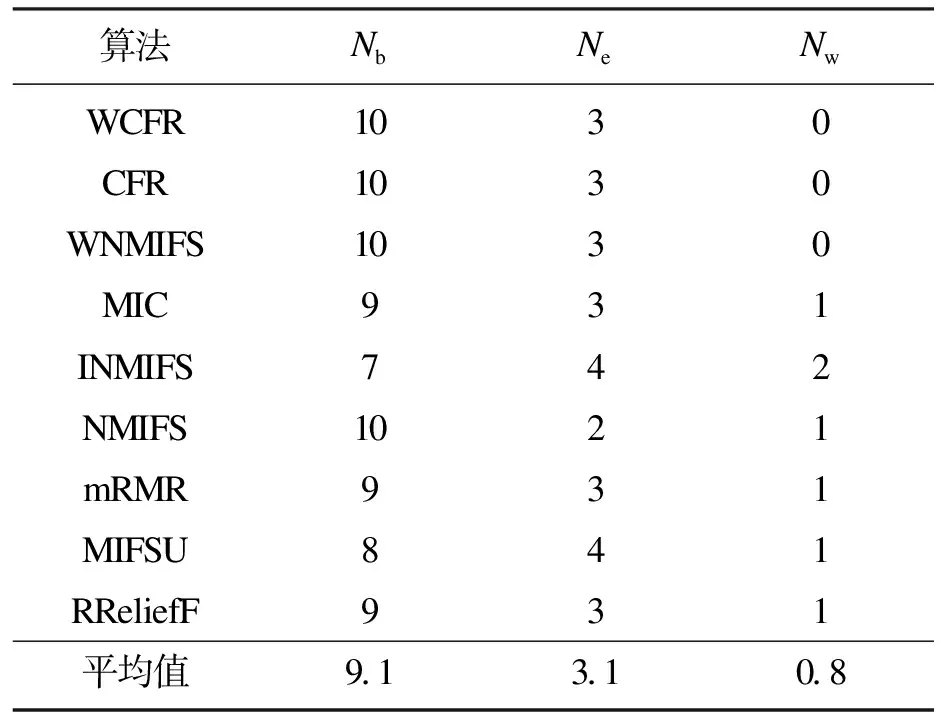
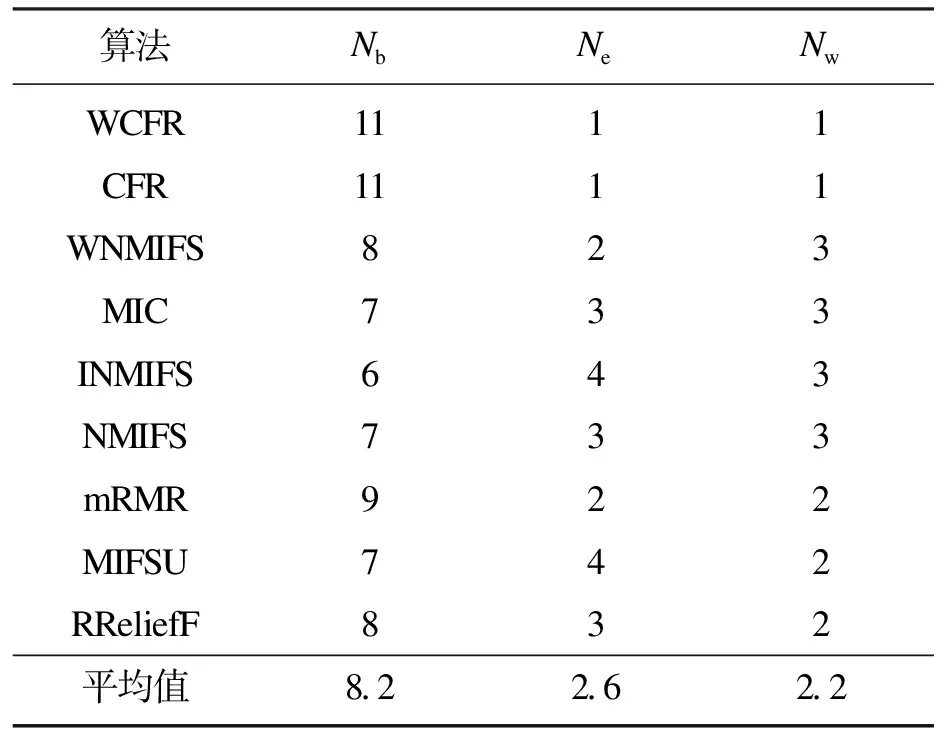
式中:M和N表示将X,Y构成的散点图划分为M列N行的网格图,M和N的取值需满足MN MIC本质上是一种归一化互信息,归一化互信息的值被限制在(0,1)之间,屏蔽了互信息绝对值的数量级差异,因此MIC具有更高的准确性和普适性.鉴于此,应用式(5)度量各个特征与标签的相关性.假定数据集的特征个数为l,对特征{A1,A2,…,Al}中的每个特征Ai,以及标签C,应用式(5)计算出该特征与标签的MIC值,最终得到向量q=[a(A1;C),a(A2;C),…,a(Al;C)]T. 熵权法是一种优秀的客观赋权方法,在数学相关领域有很多应用.其依据的原理是指标的变异程度越小,所反映的信息量也越少,其对应的权值也应该越低.应用熵权法为指标RReliefF和MIC赋权的过程如下[18].首先对r,q数据进行标准化: (6) (7) 随后根据标准化数据求r,q的信息熵: (8) (9) (10) (11) 最终的过滤式准则是相关项减去冗余项.其中相关项代表假设加入待选特征f后,新特征子集对类别的相关性的加权平均值;S代表已选择的特征子集;η,θ客观上平衡了RReliefF和MIC的重要性,更具有数理上的统计优势.其具体表达形式如下: (12) 冗余项代表待选特征f与已选特征子集的相关性的平均值.在度量待选特征f与已选特征s之间的相关性时,仅仅采用了MIC度量,并未采用RReliefF,原因在于RReliefF算法中特征与标签存在预测与被预测的关系,而待选特征f与已选特征s之间并不存在逻辑上的预测与被预测关系,它们之间是对等的,所以RReliefF不可以用来度量特征与特征之间的关系.其MIC度量表达式如下: (13) 最终得到的过滤式准则为 (14) 以式(14)为过滤式标准,采取前向搜索的策略,每次贪婪地选择使式(14)取最大值的特征,直至达到预设的特征数目为止. 为了验证所提算法(FFSBEWM)的优劣性,本文将所提算法与相关算法进行了对比.实验用到了3个分类器:K-近邻(K-nearest neighbor,KNN)分类器、支持向量机(support vector machines, SVM)分类器以及鉴别分析(discriminant analysis,DA)分类器.本文在13个数据集上进行了实验,数据集的各项信息如表2所示. 表2 数据集 这些数据集来自UCI机器学习数据库以及Scikit-feature特征选择资源库.由表2知,实验中采用的数据集涵盖了低维(特征维度小于200)、中维(特征维度介于200到1 000之间)、高维(特征维度大于1 000)数据集;涵盖了小样本(样本数小于1 000)、中样本(样本数大于1 000小于5 000)、大样本(样本数大于5 000)数据集;特征属性既包括实数型,又包括整数型.综上,本文选取的数据集具有代表性. 实验过程分为两个阶段:第一个阶段是利用各个算法对特征进行选择,得出各个算法所选择的特征子集;第二个阶段是对筛选出的特征子集的优越性进行评价,即将筛选出的数据放入分类器中进行分类,统计平均分类准确率和最高分类准确率.本文采用平均分类准确率和最高分类准确率作为评价指标,平均分类准确率的形式化描述如下: (15) 式中:λ表示对特征子集进行10折交叉验证后的分类准确率;γ为设定的最大特征数目.若原始数据集特征个数大于30,则γ=30;否则,γ=特征数目.平均分类准确率度量了算法所选择特征子集的综合分类性能. 最高分类准确率即为当v取1到γ时,所有λ的最大值.最高分类准确率度量了算法所选择的最优特征子集的分类性能.其形式化描述如下: ξ=max(λ),v∈[1,γ] . (16) 表3~表5分别表示各个算法所选择的特征子集在KNN(K=5),SVM和DA分类器上的平均分类准确率.表3、表4、表5所对应的Nb,Ne,Nw数据分别如表6~表8所示,Nb,Ne,Nw表示FFSBEWM较好、持平、较差于对比算法的数据集个数. 由表3、表4可看出,在KNN(K=5)和SVM分类器上,FFSBEWM均在9个数据集上取得最高准确率,并且这些数据集涵盖了低中高维数据集.除此之外,即便FFSBEWM在某些数据集上未取得最高准确率,其依旧排名第二或第三.由表5可知,FFSBEWM所选择的特征子集在5个数据集上取得了最高的准确率,虽然相比SVM和KNN(K=5)分类器略有逊色,但纵向对比来看依旧说明FFSBEWM相比其他算法具有一定优势.由表6~表8可知,FFSBEWM胜于其他算法的数据集个数远大于不胜于其他算法的数据集个数,在KNN(K=5),SVM,DA分类器上平均胜出的数据集个数分别为11.6,9.1,8.2,胜出率分别为89.23%,70%,63%.综合上述论证,FFSBEWM的平均分类准确率显著优于其他算法. 表3 各个算法所选择的特征子集在KNN(K=5)分类器上的平均分类准确率 表5 各个算法所选择的特征子集在DA分类器上的平均分类准确率 表6 各个算法所选择的特征子集在KNN(K=5) 表7 各个算法所选择的特征子集在SVM分类器上的Nb,Ne,Nw统计表 表8 各个算法所选择的特征子集在DA分类器上的 各个算法在三个分类器上的最大最高分类准确率如表9所示.由表9可知,FFSBEWM在6个数据集上最大最高分类准确率排名第一,这6个数据集同样涵盖低中高维;FFSBEWM在4个数据集上排名第二或第三.FFSBEWM算法的最大最高分类准确率整体上同样优于其他算法. 表9 各个算法所选择的特征子集在KNN(K=5),SVM和DA分类器上的最大最高分类准确率 为了分析分类准确率与特征子集大小的关系,选取了具有代表性的4个数据集,见图2~图4. 由图2~图4可知,整体而言,随着所选特征个数的增多,特征子集的分类准确率相应提高.这是因为当选择的特征数较小时,特征子集所包含的信息也较少,因此分类准确率较低,反之亦然.值得一提的是这种正相关关系并非绝对.除此之外,尽管同一算法在同一分类器上的曲线走势并不完全一致,但FFSBEWM的曲线整体上均位于所有曲线的最上方,即无论所选特征子集的大小,FFSBEWM所选择的特征子集的分类性能均优于其他算法.这也进一步说明了即使不同分类器会对算法产生一些影响,但这些影响在本文讨论的范围内是非实质性的. 图2 各个算法所选择的特征子集的分类准确率随特征数变化图(KNN(K=5)分类器) 图3 各个算法所选择的特征子集的分类准确率随特征数变化图(SVM分类器) 图4 各个算法所选择的特征子集的分类准确率随特征数变化图(DA分类器) 本文提出了一种基于熵权法的过滤式特征选择算法,在13个数据集上的实验结果显示本文算法选择的特征子集的平均分类准确率和最高分类准确率均优于其他算法. 但本文算法准确率还不够高,在个别数据集上略差于其他算法或者比其他算法的领先程度不够高;受数据集本身影响较大,导致在某些数据集上算法的稳定性较差;本文算法在不同的分类器上的表现也略有差异.后续将进一步对特征选择的过程框架予以改进,以期提高所选择的特征子集的分类准确率,同时完善特征选择的过滤式标准,加入对算法稳定性的度量,提高算法的稳定性.1.3 应用熵权法进行客观赋权
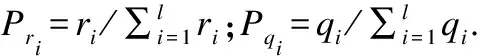
1.4 构建过滤准则
1.5 贪婪式选择特征
2 实 验
2.1 数据集与对比算法

2.2 实验实施
2.3 实验结果及讨论






3 结 语
