空间机器人操作:一种多任务学习视角
2022-07-21李林峰解永春
李林峰,解永春
北京控制工程研究所,北京 100190
1 引言
随着人类的太空探索从地球轨道走向深空区域,对航天器的自主性需求显著增加。空间机器人操作利用空间机器人辅助、代替宇航员完成各类操作任务,是提升航天器自主性的重要手段。当前,基于遥操作、人在环路的空间机器人操作能够执行低地球轨道的操作任务(例如空间站内部、空间站外围的维修、装配、辅助对接[1]等),并具备一定的自主性。但对于不确定性更强的高轨、深空环境,由于通信时延大、轨道动力学不确定性强等因素,难以实现高自主、强鲁棒的任务规划与执行。提高空间机器人的自主学习能力是解决上述问题的有效手段。
近年,深度神经网络与强化学习、模仿学习等方法的交叉在提高系统自主性与鲁棒性方面初见成效。目前,无论是空间机器人操作,还是一般的地面机器人操作,多数工作围绕独立执行、短时间范围的单一任务学习问题开展研究。例如:文献[2]利用深度确定性策略梯度[3]算法和人工示教的结合,学习了机械臂插销入洞任务;文献[4]利用置信域策略优化[5]算法在四足机器人平台ANYmal上分别实现了步态规划和翻倒恢复的自主学习;文献[6]利用近端策略优化[7]算法实现了Shadow五指灵巧手翻滚立方块的学习。
但是,空间机器人操作面临的工况通常是多任务的,上述单一任务学习算法很难用于解决空间机器人操作问题。特别地,空间机器人操作的典型特征包括:
1) 多任务适应性要求高。服务航天器造价昂贵,其在轨运行期间需要适应尽可能多的目标航天器,完成尽可能多类型的操作任务。例如,NASA的OSAM (on-orbit servicing, assembly and manufacturing)项目[8]计划为通用客户卫星进行在轨燃料补加,整个过程包括了7个子任务(如图1所示),即更换末端工具、捕捉与重定位目标卫星、切割包覆膜、切断绞索、拧开盖子、加注枪抵近插入、燃料加注。
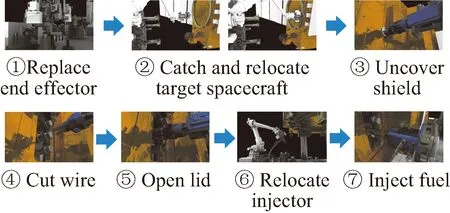
图1 NASA OSAM计划验证任务:非合作卫星燃料补加[8]Fig.1 Demonstration tasks of NASA OSAM: non-cooperative satellite refueling [8]
2)精细化要求高。①小范围:受运载能力和发射成本限制,航天器往往具有布局紧凑的复杂结构,导致操作环境复杂且操作空间受限。②多模态:需要机械臂关节测量、力触、图像等多模态感知信息。③高精度:过大的接触力将导致反向推离甚至损害航天器和捕获工具,微小的位置偏差将导致不可恢复的任务失效。
3)不确定性强。目标航天器外形和结构不确定性、非结构化程度高,空间光照条件复杂、差异性大,目标测量往往存在多源干扰;目标航天器质量惯量特性难测量,导致接触操作过程运动特性、接触力不确定,进而接触碰撞后难以准确预估其动作轨迹。
因此,针对上述空间机器人操作的典型特征,研究相应的多任务学习算法,赋予空间机器人系统多任务学习能力,是进一步提升自主性的关键。本文首先分析在轨服务的多任务发展需求;其次介绍机器人操作单任务学习的原理与局限,全面综述多任务学习方法及其在机器人操作上的应用;最后针对如何利用多任务学习方法实现高自主、强鲁棒的空间机器人操作,分析研究挑战,给出关键技术发展建议。
2 在轨服务的多任务需求
在轨服务指服务航天器与目标航天器完成交会或对接后,通过机械臂/航天员对目标航天器进行末段操作的过程。典型的在轨服务包括:燃料补加、故障修复、模块更换等。
在轨服务技术的发展已有40余年。1973年5月14日,美国Skylab空间站入轨过程发生热覆膜损坏。11天后,宇航员携带地面补制的双极太阳罩抵达Skylab,并于8月6日出舱完成了在轨维修。这一事件被认为是在轨服务诞生的标志[9]。此后,NASA又相继验证了姿态控制模块的在轨更换(SolarMax卫星,1984年)和科学载荷的维修与更新(Hubble望远镜,1993—2009年)。
近10年,发展了诸多以航天器延寿为目标的在轨服务项目,如DARPA的轨道快车项目(Orbital Express)、凤凰计划(Phoenix),NASA的RRM(Robotic Refueling Mission)、Restore-L等。2011—2018年,NASA陆续实施了3阶段RRM任务,开发了多种专用集成工具,依托于国际空间站,验证了启动锁拆卸、液态乙醇加注、移除电气连接盖、拆卸螺栓、切割导热包覆、液态氧/液态甲烷/氙的转移补加、软体机器人管路检查等。表1摘要了RRM和其他典型在轨服务项目的验证任务与关键时间节点。
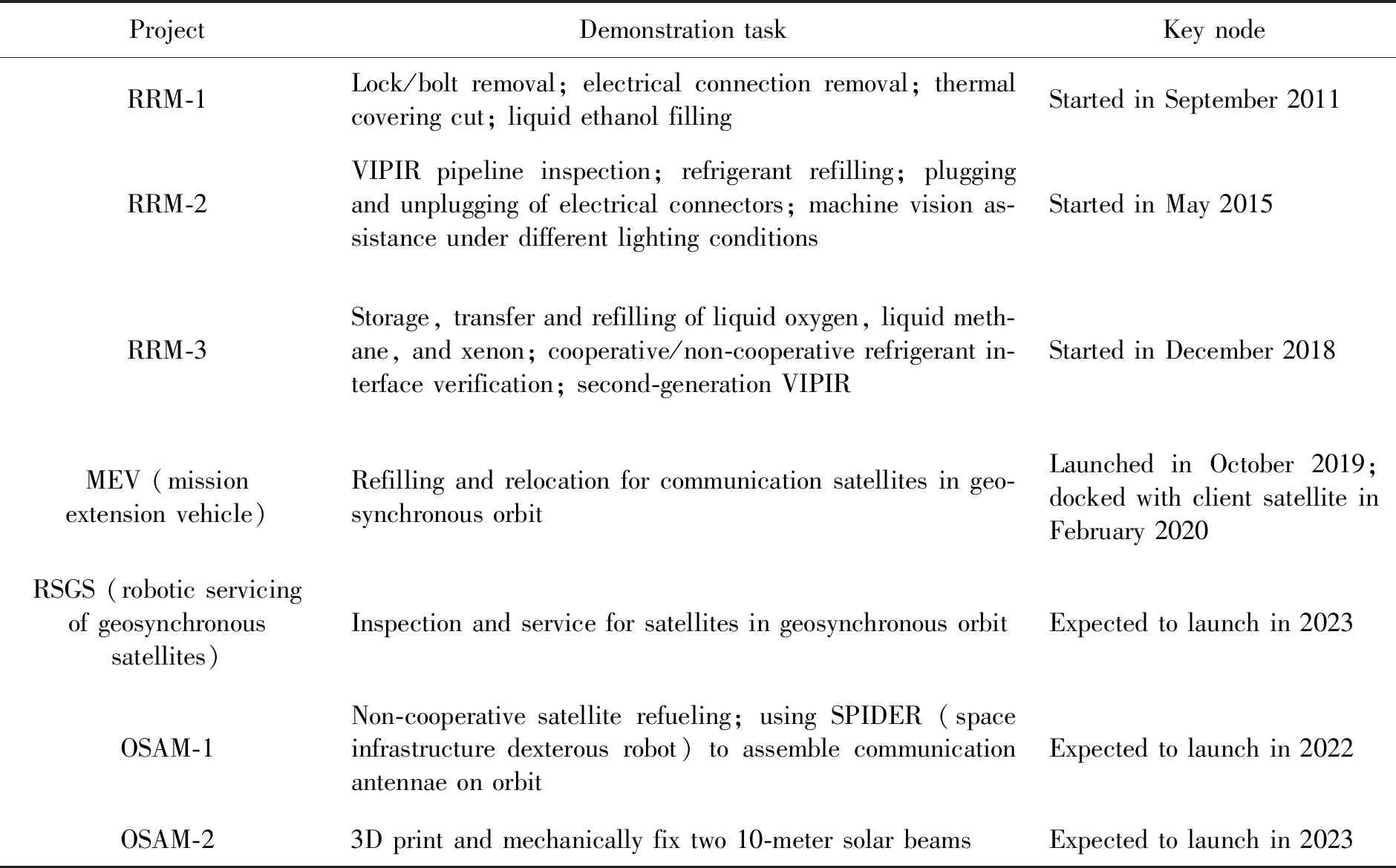
表1 近期典型的在轨服务项目
在轨服务的技术发展趋势可归纳为如下3点:
1)任务需求多样化。首先,多变化的操作对象特征(比如几何形状、轨道与姿态动力学、表面材质等)、低成本可复用的技术需求都决定了服务航天器应具备多任务执行能力。此外,增材制造技术的发展,使得在轨服务从模块化的单一服务模式,转向制造、装配、服务一体的多样化服务模式。例如,2020年4月,NASA将Restore-L和Archinaut整合为新项目OSAM,旨在建立具有长期、可持续自主运营能力的“空间工厂”与“太空补给站”。
2)舱外操作自主化。通过航天员出舱执行太空服务成本高,安全性低,且只能用于低轨场景;寻求空间机械臂替代是主要方案。低轨场景下,典型配置是大型机械臂搭配多用途末端工具(Canadarm2+Dextre);高轨场景下,服务卫星配备一个或多个小型机械臂,执行抓取、加注等操作。目前,这类操作基本通过遥操作控制,并不具备真正意义的自主性。
3)感知执行一体化。从利用航天员作为“末端工具”,转向具有高级感知与执行能力的一体化末端工具。典型例子有Dextre、VIPIR(visual inspection poseable invertebrate robot)等,均具有多模态(视觉、力、位移)的感知模块和多功能(切割、抓取、管路检测等)的执行模块。
在上述3点技术发展趋势中,任务需求多样化是最重要的一点,它也是多种太空任务(在轨装配、在轨制造、辅助离轨、空间碎片捕获等)的共性需求。
3 机器人操作学习原理
机器人操作学习将传统机器人控制中的控制器设计,替换为深度神经网络的优化,凭借深度神经网络对图像信号的强表示能力,通过深度图像特征引导机械臂进行规划与控制,对非结构化、不确定环境的适应能力更强,是近年机器人领域的研究重点。本节将简要介绍单一任务的机器人操作学习,包括原理与方法,分析单一任务学习的局限性,进而阐明研究机器人操作多任务学习的必要性。
首先,通过Markov决策过程(Markov decision process, MDP)定义任务。定义一个MDP为M:=(S,A,P,r,ρ,γ),其中S代表状态空间,A代表动作空间,P:S×A×S|[0,1]代表状态转移概率,r:S×A|R代表奖励函数,ρ:S|[0,1]代表初始状态分布,γ∈[0,1)代表折损因子。进一步,学习就是对策略πθ(a|s)∈Π:S×A|[0,1]进行参数优化的过程。策略πθ(a|s)一般通过参数化的深度神经网络表示,也被称为策略网络,它的功能是控制机器人执行相应动作。
操作任务学习的实质是策略网络的优化。策略网络的优化方式主要有两种,一是模仿学习,二是强化学习。模仿学习需要人为机器人提供行为引导,给定相同输入,利用监督学习的方式使策略网络能够复现人的输出,典型工作见文献[10-12]。强化学习则通过机器人与环境的不断交互获取交互数据τ:=(s0,a0,s1,a2,…,sT)(其中T是最大采样步数),基于交互数据进行策略优化,达到累积奖励最大化的优化目标。上述两类方法的学习过程都需要大量交互数据。得益于机械臂刚体动力学模型的相对确定性,交互数据采集可在虚拟仿真系统中完成,相比于真实物理环境采样更高效,更安全;进一步通过域随机化(domain randomization)可以将环境模拟多样化,进而实现将优化后的策略网络从虚拟仿真环境迁移到真实物理环境。
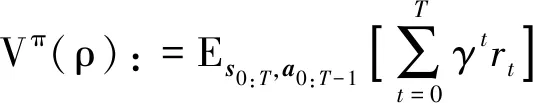
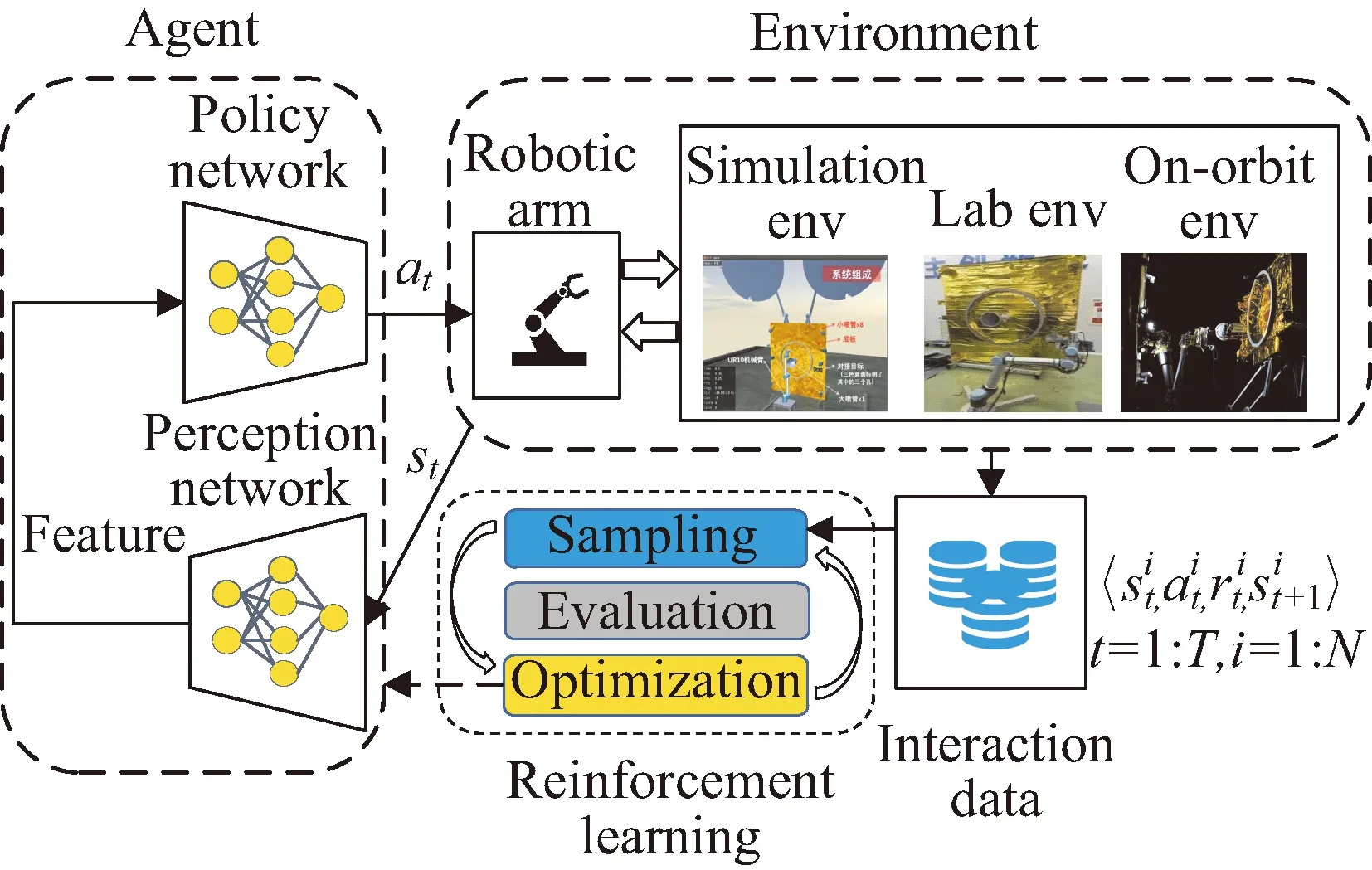
图2 基于强化学习的机器人操作原理Fig.2 Schematic of robotic manipulation using reinforcement learning
利用上述框架可以实现简单的空间机器人操作,例如图3展示了在真实地面试验环境下的在轨加注任务执行结果,实现了自主加注孔识别、自主抵近、自主插入,并且对位置不确定、光强不确定等情况具有较好的鲁棒性[13]。在上述例子中,抵近与插入就是两种不同的任务:抵近过程图像信号起主导作用,插入过程力信号起主导作用,操作模式也不相同。
采用多种任务独立学习(即一个策略网络对应一个任务)是一种可行方案,但这种方式的局限性在于:①表示不统一,无法提取多任务之间的共性特征;②切换条件难设计,需要额外设计、优化判断任务切换的模型。因此,针对以在轨加注为代表的长时间范围、序列化的空间机器人操作,通过多任务学习方法克服上述局限具有其必要性。

图3 真实地面试验环境,机械臂可以在策略网络的控制下完成加注口抵近、插入等多任务操作[13]Fig.3 In the real ground test environment, the learned policy network is able to control robotic arm conducting multiple tasks like reaching fueling port and inserting[13]
4 多任务学习算法
多任务学习能力被认为是通用人工智能的关键要素之一,多任务学习算法也是机器学习领域近年的研究热点。在国内外相关工作中,与多任务学习相近的研究议题包括:迁移学习[14]、课程学习[15]、小样本学习[16]、主动学习[17]等。文献[18]详述了上述议题的共性与差别。简而言之,课程学习、小样本学习、主动学习侧重学习模式,而迁移学习、多任务学习均侧重学习目标,理论范畴更大,与强化学习的交叉工作也更多。
首先,还是通过MDP定义多任务。在强化学习语境下一个MDP就代表了一个任务,由此,状态空间、动作空间、状态转移概率、奖励、初始状态分布等要素变动形成的MDP集合/分布就被称为多任务。相应地,多任务学习的目标就是:学习最优策略,使得MDP集合/分布上的总体奖励最大化。需要指出的是,针对空间机器人操作的多任务学习相关研究,国内外未见公开报道。因此,这里讨论一般的机器人操作多任务学习,特别地,以多任务强化学习(multi-task reinforcement learning, MTRL)为重点。
图4展示了本节内容安排:多任务强化学习的方法研究可归纳为5类,即经验复用、持续学习、结构化策略、蒸馏、梯度优化与适应,分布式学习是实施算法的必要手段。图4纵轴归纳了上述方法研究在机器人操作上的应用。
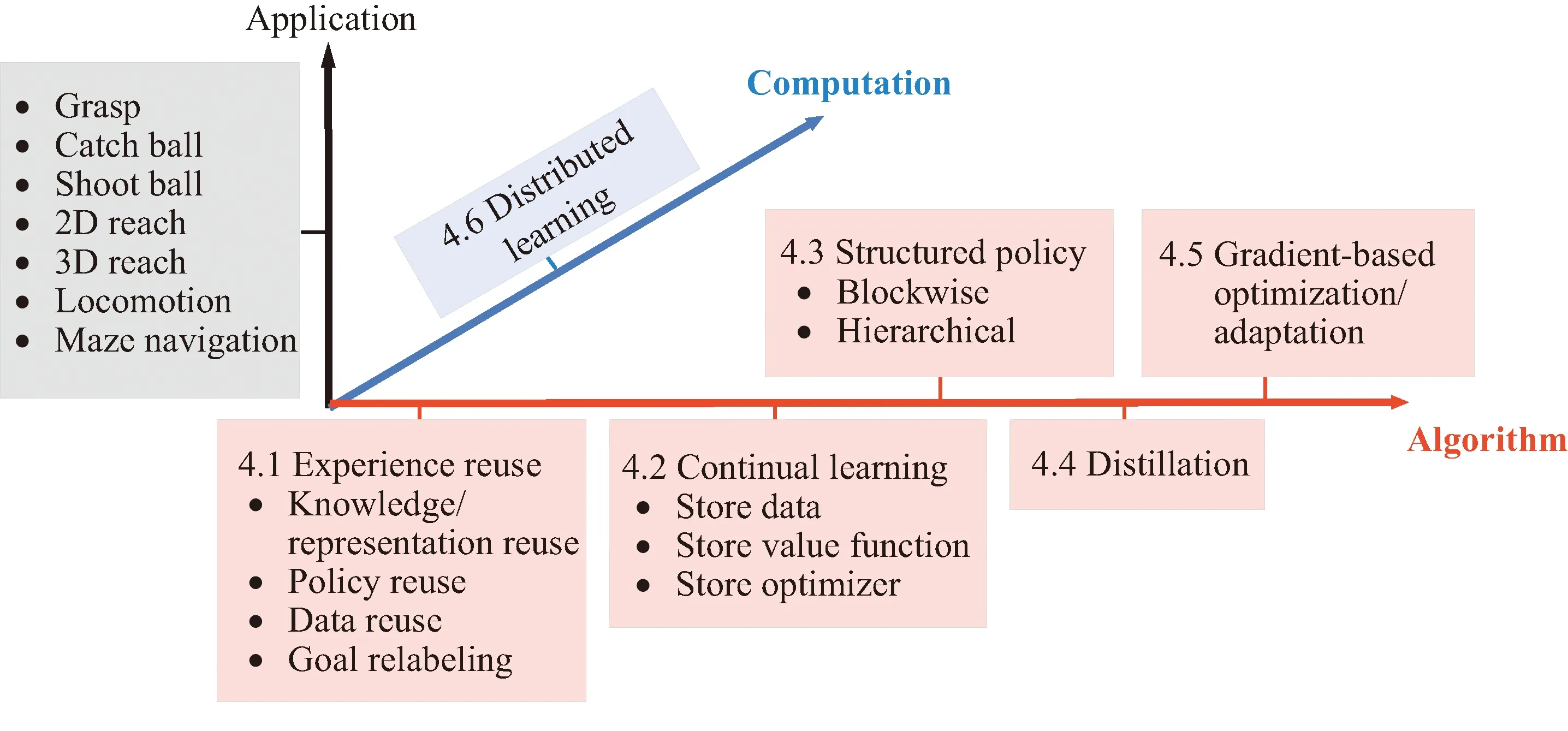
图4 多任务学习方法的研究现状及其在机器人操作上的应用Fig.4 An overview of multi-task learning research with its application in robotic manipulation
4.1 经验复用
1)知识表示复用。文献[19]指出,“通过理解世界,能够使策略最优行为的搜索复杂度大大降低”。这一工作中,理解世界的载体是一个循环神经网络(recurrent neural network,RNN)表示的M网络(model network,模型网络),其功能是模拟环境动力学、预测环境反馈;通过同步更新C网络(controller network,策略网络)和模型网络,实现在非平稳(环境时变)、反应式环境(环境反馈随策略输出变化)中的学习。文献[20]从算法信息论角度,将文献[19]的C、M网络之间的信息闭环定义为更广义的询问、回答,实现了持续主动的抽象推理、规划与决策;文献[21]将文献[19]的CM系统扩展为VCM系统,进一步引入视觉编解码器(vision network,V网络),解决视觉经验表示与存储,M网络采用带混合密度输出的RNN,预测下一时刻图像帧的概率分布。上述工作中,经验表示与存储通过高维、多层RNN实现,在网络结构设计、优化速度等方面存在一定局限。
2)策略整体复用。文献[22]提出概率的策略复用,历史策略作为当前策略学习的概率偏度,在Q-learning框架下,根据-greedy探索选择运行历史策略或当前策略,得到相应动作,优化Q函数。存储多个历史策略,形成策略库,在优化过程中策略库的元素可以增量更新。
3)交互数据复用。附加任务学习是一种典型思路。例如,文献[23]提出UNREAL (unsupervised reinforcement and auxiliary learning) 算法。整体过程分3环:①并行采样,并行运行A3C智能体[24],采用卷积-递归网络结构,交互数据存储于重播寄存器;②附加任务,采样重播寄存器的经验数据,以无监督方式训练3个附加任务——像素控制、奖励函数预测、值函数拟合;③整体优化,将上述附加任务的损失与A3C损失结合,整体优化。
4)目标重标注(goal relabeling)。文献[25]提出UVFA (universal value function approximators)算法,将深度Q函数扩展到多目标情况,此时深度Q函数与状态、动作、目标三者有关,每轮采样目标保持固定。利用Horde算法[26]提供单个、具体的目标,可以实现贪心策略泛化。在UVFA的基础上,文献[27]提出后视经验重播(hindsight experience replay,HER)算法,整体思路是为重播寄存器中的状态转移标注新目标。达到效果是轨迹在原目标的意义下奖励低,但在新目标的意义下奖励高,进而产生“成功的失败”效应。HER的优点在于:①交互数据的利用效率高;②异策略优化易于融合人工示教经验;③解决稀疏/二值奖励函数问题。文献[28]利用条件化变分自动编码器实现了图像目标的生成,RL以初始图像的编码表示、根据当前状态的生成目标为状态,基于随机交互数据进行异策略的自监督学习,实现了对未见物体的推动任务。文献[29]建立了目标调节强化学习的概率模型,并提出后视期望最大化(hindsight expectation maximization, HEM),利用变分推断技巧实现了更稳定的评价网络学习。
综上,经验复用类方法:①相比于知识表示复用、策略整体复用,交互数据复用模型无关、易于融合人的示教、算法实现简单,是目前研究领域的主攻方向;②以异策略优化为主,欠缺策略改进特性[30-31];③目标调节RL中,目标的确定、采样方式设计等缺乏理论依据。
4.2 持续学习
人类的学习过程是循序渐进的。持续学习的目标就是在学习系统上复现这种机制,克服稳定性-可塑性(stability-plasticity)困境,在持续学习新任务的过程中保留历史任务的记忆/经验。早期典型工作是文献[32]提出的CQ-learning,解决序列多任务决策问题。CQ-learning总体分为3模块:Q值估计模块、门模块和偏置模块。前两者与状态相关,偏置模块与状态无关。利用门模块进行子任务识别与切换,偏置模块提供加性偏置,自适应地修正Q值估计。表格导航验证结果表明,CQ-learning框架中的门模块对序列化的新任务引入具有适应性,但收敛速度受任务序列设定的影响较大。早期工作还包括文献[33-35]。近期,持续学习方面,文献[18]总结了持续学习与机器人的交叉研究;文献[36]归纳了利用深度神经网络的持续学习研究进展。
处理深度神经网络的灾难性遗忘(catastrophic forgetting)、选择合适的经验存储载体、检测非平稳的分布偏移是持续学习的3个主要挑战[18]。对于历史任务的经验存储是持续学习的核心。具体到持续强化学习,历史任务经验的存储体现在“(交互数据)采样-(值函数)评价-(策略)优化”基本3环节之中:
1)存储交互数据,也被称为排练(rehearsal),对于异策略优化,主要利用重播寄存器,典型工作是SEM算法[37];对于同策略优化,需要融合同策略的采样数据,典型工作是文献[38-39]。CLEAR[40]联合使用了异策略(旧任务)和同策略(新任务)数据。
2)存储值函数,典型工作是Horde算法[26]。Horde算法利用异策略的GQ(λ)更新,实现了Critterbot机器人的寻点、寻光、旋转等任务。尽管验证任务动作为离散情况,知识表示的结构较简单(二进制、线性特征),但实现了无监督的大规模并行采样。
3)存储优化要素,存储隐层网络权重、正则化参数等。例如,文献[41]提出PG-ELLA算法,随新任务的引入自适应地更新隐空间表示。
4.3 结构化策略
(1)分块策略
文献[42]采用多个专家网络模块+门模块结构,前者的前馈运行依照后者的输出概率进行切换,解决了多人的元音字母语音识别问题。第4.2小节提到的CQ-learning也是早期典型工作。上述工作中,模块间竞争与联合的权衡主要通过门模块调节实现。近期文献[43]提出的胶囊网络(capsule network)本质上与文献[42]类似,都是“分块-投票”机制的实现。
对于更复杂的多任务学习问题,权重共享型策略结构是常用方案:即神经网络的一部分负责共性功能(起联合作用),剩余部分负责特定功能(起竞争作用),进而实现总体的调节。文献[44]也将这种方式概括为依特征变换(feature-wise transformations),将任务的学习定义为一种调节(conditioning),并归纳了几种调节模式:串联调节、加性偏置、乘性尺度变换、仿射变换。文献[45]按分层的方式进行策略分块,每个低层子任务训练独立的子策略,训练通过序列化的课程学习实现。文献[46]提出一种模块化的元强化学习方法SNAIL (simple neural attentive learner),策略网络分为瞬时卷积模块和因果注意力模块,前者利用历史经验聚类情境(context,或称上下文)信息,后者推断具体信息与情境信息之间的对应,性能优于一般的LSTM策略结构。
机器人应用方面,文献[47]较早地研究了模块化策略网络的强化学习,解决多机器人-多任务问题。策略网络分为任务模块和机器人模块,前者提取任务表示,后者输出动作,但只能适用于同一环境的高相似任务。文献[48]研究了机器人操作任务的序列控制切换,利用人工示教数据训练,策略总体分3模块:①由卷积混合密度网络表示的动作策略,输入图像表示,输出目标转角供机械臂进行伺服控制;②由变分自动编码器网络表示的前向动力学模型,用以计算n步状态前推;③由卷积混合密度网络表示的目标分数估计器(goal scoring estimator, GSE),用以计算输出实际图像相对于目标图像的似然概率,选择执行控制器集合中最匹配的控制器。控制器集合含有3种操作任务:PR2机器人对齿轮零件的抬起、移动、穿孔。尽管此方法可以执行不同表示、不同带宽的控制器,但控制器集合有限、封闭,数据来源并不充分,难以实现更大范围的任务探索与泛化。
(2)分层策略
早期工作有选项框架[49]、MaxQ值函数分解[50]、分层抽象机(hierarchical abstract machine, HAM)[51-53]等,但大多需要任务指定设计,常假设简单、给定的层级结构,难以处理高维、连续的复杂环境反馈问题。近期,文献[54]研究了无模型、目标调制的分层强化学习,提出了HIRO(hierarchical reinforcement learning with Off-policy correction)算法,通过引入离线策略经验缓解了高层策略的非平稳问题,提高了采样效率;文献[55]基于HIRO,提出了分层Sim2Real,通过层级域随机化,以零样本代价实现了两个四足机器人行走、推动、合作的策略迁移。文献[56]提出HAAR(HRL with advantage function-based auxiliary rewards)算法,利用高层策略的优势函数,为低层策略提供附加奖励引导,算法保留了策略单调改进性质,在虚拟环境“蚂蚁-迷宫”任务上性能优于HIRO。
文献[57]提出DIAYN(Diversity is all you need)方法,建立隐变量的技能分布模型,不再需要设计复杂的多任务奖励,具有如下特点:①不同技能指示智能体访问的不同状态;②利用状态而非动作区分技能;③设置技能多样化的优化目标。优化目标设定为I(S;Z)+H(A|S)-H(A;Z|S),其中Z~p(z)是技能隐变量,S和A分别是状态/动作变量。利用判别模型qφ(z|s)逼近后验分布p(z|s),根据ELBO表达式可获得“伪奖励”的计算方式lgqφ(z|s)-lgp(z),p(z)设定为均匀分布使隐变量的熵最大。策略优化采用SAC算法,判别器的优化采用一般的SGD。数值仿真结果表明:Half cheetah机器人能够学到以不同速度前进、后退、跳跃等多种技能;Hopper机器人能够学到前跳、后跳、平衡等多种技能。
综上,通过结构化策略进行多任务学习:①更利于实现多任务间迁移学习[58];②可通过隐变量的任务表示,建立与变分推断(variational inference)的关系;③结构本质上是人的先验知识,可规模化存在局限。
4.4 蒸馏
文献[59]利用“教师”网络(多参数)引导“学生”网络(少参数)学习,实现了知识迁移和模型压缩。受此工作启发,在强化学习领域发展了策略蒸馏相关方法。文献[60]在多任务联合学习时,直接最小化“教师”策略和“学生”策略输出之间的差异;在任务迁移时,辅以输出前一层的隐层特征回归。文献[61]提出策略蒸馏方法,在Atari游戏上实现了模型压缩、多任务“学生”策略性能优于单任务“教师”策略、实时在线式蒸馏。
文献[62]针对共享权重的策略表示不直观,性能高度依赖网络结构问题,提出Distral(distill & transfer learning)算法,在多任务策略学习过程中,共享一个蒸馏策略,并以此作为各单任务策略优化的约束。优化目标为:
式中:i为任务指标;n为任务总数;γ折损因子。在最大化任务内累计奖励的同时,添加两项正则化:①邻近正则化,最小化已蒸馏策略π0和任务策略πi之间的KL散度,提取蒸馏策略的经验;②任务策略πi的最大熵正则化,增加探索程度,防止任务策略πi退化为贪心策略。基于SQL(soft Q-learning)优化、Boltzmann策略表示,在表格任务、视觉导航任务上,Distral算法具有较好的收敛速度和超参数鲁棒性。
文献[63]提出DnC(divide-and-conquer)框架,核心思想是:利用初始状态的数据关联,通过聚类得到隐式的情境信息,以此替代人工定义的任务。优化过程与Distral类似,交替优化“情境指定/局部”策略和“中心/全局”策略。底层优化采用置信域策略优化[5],不同情境之间的采样数据可以共享,提高了采样效率;跨情境策略之间的KL散度最小化作为优化约束,实现了向全局策略的正则化。在抓取、抛物、接物3种机械臂任务和蚂蚁、台阶2个行走任务上,实现了优于Distral的性能。特别地,在抓取任务中,基线方案最多能应对4 cm×4 cm的目标物体位置摄动;DnC优化由于具有更小的策略梯度方差,此范围可被扩展到30 cm×30 cm。
一些最近的工作包括:文献[64]研究了具有连续任务空间的课程蒸馏(curriculum distillation)问题,基于文献[65]提出的连续教师-学生框架,设计了一种可在任务分布上采样-优化的算法,但课程的形式是连续、可参数化的环境(Bipedal Walker环境),距离实际环境仍有差距。文献[66]利用变分信息最大化(variational information maximization)的方法,解决教师、学生策略状态/动作空间不匹配的问题,但验证任务的设定简单、相关性强(设定腿数不同的Centipede任务)。
综上,蒸馏类方法:1)在性能、模型压缩等方面优于权重共享型多任务学习,一定条件下能实现“学生”策略性能优于各“教师”策略;2)处理多任务学习问题时,能够有效降低策略梯度方差,但代价是采样复杂度的提高。
4.5 梯度优化与适应
优化:对于单任务的RL优化,一个核心问题就是如何降低策略梯度的方差;对于多任务RL,梯度项的估计需要进一步在任务分布上进行累加,使这一问题更加突出。一个主要方向是利用分布式的强化学习降低策略梯度方差,例如IMPALA[67]和它的改进算法PopArt[68]、LASER[69],具体见第4.6小节。PCGrad算法[70]考虑了多任务优化的梯度冲突问题,利用梯度投影的方法,在Meta-world基准平台上改进了SAC算法的性能。
适应:人类习惯从习得技能中提取经验,加速对于新技能的学习过程。为了在机器学习系统上复现这种机制,研究者们提出了元学习(meta-learning)这一概念。元学习也被称为学习如何学习(learning to learn),是一门系统地观察机器学习方法在多种学习任务上的性能差异,学习这些经验(元数据)并快速适应新任务的科学。文献[71-73]较早研究了元学习。利用循环神经网络的记忆特性,文献[74-75]最早提出并实现了元强化学习,主要思想是利用循环神经网络(如LSTM、GRU等)的隐层单元作为“经验容器”。具体地,RL2算法[75]包含以下4步。
Step 1:采样一个新的MDP,Mi~p(M)。
Step 2:重置模型所有的隐层状态。
Step 3:采样多条轨迹,优化模型参数。
Step 4:返回Step 1。
这里,策略不再是常规RL中的πθ(at|st),而是变成πθ(at|at-1,rt-1,st)。
上述基于RNN的方法,依靠一次前向传播,来实现对新任务的适应,需要网络的维数、层数足够多,一方面难设计,另一方面难优化。利用优化进行适应,可以解决这一问题。例如,文献[76]提出了基于梯度优化的元学习算法MAML(model-agnostic meta-learning),元训练阶段的经验被提取为元测试阶段的策略网络参数初始化,面对不同的未见任务执行不同的策略参数元更新,实现了多任务间的快速适应。由于MAML不依赖策略的表示,经验提取与适应都由梯度优化实现,便于规模化,它与RL的结合很快在机器人控制上得到应用。文献[77]利用MAML实现了多种机械臂操作任务的元强化学习,但任务集有限封闭并且相似程度较大。文献[78-79]研究了在线/增量式的元学习。
综上,梯度优化与适应类方法,具有随机梯度下降的一般化特点:①模型无关(model-agnostic),与问题设定、任务数量无关,具有良好的可规模化能力;②在非凸的问题设定下,收敛到全局最优难保证;③多任务下的分布偏移(distributional shift)问题,导致梯度项的估计方差大,策略优化难收敛、收敛慢。
4.6 分布式学习
分布式学习(distributed learning)是数据驱动型学习系统必要的底层功能。具体地,分布式强化学习的工作模式有二,一是采样(数据)并行,二是优化(模型)并行。表2归纳了2015—2020年有关分布式(深度)强化学习的进展,按照时间顺序排列。
4.7 小结
本节综述了经验复用、持续学习、结构化策略、蒸馏、梯度优化与适应、分布式学习等方面的相关研究,涉及算法原理、经典工作、最新进展、与机器人操作的交叉等。从算法角度,理想的多任务学习算法应具备如下条件:
条件1:给定一个目标任务,选择合适的源任务(集)[84]。
条件2:学习源任务(集)与目标任务之间的关系[84]。
条件3:源任务(集)到目标任务的高效知识迁移[84]。
条件4:使源任务(集)和目标任务的整体累积奖励函数最大。
总体而言,本节所述相关算法可至少满足上述4条件之一,但尚未达到符合全部4个条件。

表2 分布式(深度)强化学习框架
5 空间机器人操作多任务学习挑战
尽管多任务学习方法在提高机器人操作自主性、鲁棒性方面初见成效,但仍难以直接应用于复杂多变的空间环境。针对如何利用多任务学习方法实现高自主、强鲁棒的空间机器人操作,本节分析研究挑战,给出关键技术发展建议。
5.1 研究挑战
难点1:虚拟-真实策略迁移。对于一般的连续控制学习问题,常用方案是在虚拟环境学习训练,以零样本或少样本的代价将训练好的策略网络迁移到真实环境;空间操作的强化学习则需要3种环境间的迁移,即虚拟环境、地面试验环境、真实空间环境。由于空间环境的高动态、不确定等复杂因素,实际上很难利用虚拟环境逼近真实环境,制约了策略学习效率与策略运行性能的进一步提升。
难点2:多模态感知信息融合与利用。空间机器人的感知信息主要有3类:视觉感知,一般又分全局视角/局部视角图像;力触感知,即末端力/力矩测量;本体感知,即机器人关节角/角速度测量。首先,需要对上述多模态感知信息进行预处理,提取多模态特征;其次,需要对提取的多模态特征进行融合,并根据多阶段任务进行调度。具体而言,对于大范围移动的前段操作,此时没有力触感知,只需视觉与本体感知;对于小范围移动的末段操作,过小尺度的局部图像特征无法提供有效引导,须利用触觉、本体感知实现高精度操作。一些研究考虑了碰撞动力学的建模[85-86],但并未将视觉感知引入系统闭环。
难点3:长时限、序列化多任务处理。例如,为了实现对非合作目标的在轨加注任务,服务航天器需要首先进行捕获目标航天器、重定位、切割包覆膜、剪线、开盖等,才能执行加注操作。实际上,很难通过强化学习优化的单个策略网络执行上述多种操作任务。此外,对于多任务/多MDP的强化学习,需要采集的样本数量多,也需要相应地提高策略网络的参数维度,造成优化过程的梯度估计方差大、算法收敛性不佳等方面的问题。
5.2 关键技术
1) 高效的多任务样本采集与利用。现有研究工作中,异策略优化+目标重标注是提高样本利用效率的一种方式,但仍需要大量的同策略数据采样,是采样复杂度进一步降低的瓶颈因素。由此,需要研究一种具有“交互数据一次离线采集、多种任务多次重复利用”特点的多任务强化学习方法,提高数据的利用效率,增加跨环境的策略可部署性。利用分层的结构,即将单个策略网络分为上、下两层,上层策略网络为下层策略网络提供目标,下层策略网络产生与环境交互的动作信号,在时序上实现一种分层抽象;在优化时,上、下层策略的参数更新频率不同,下层策略更新快,上层策略更新慢,有利于降低单次优化的负担。
2) 可学习的任务表示与关系。“源任务与目标任务服从同一分布”是多任务强化学习的基本假设。这种分布的描述更多是定性的而非定量的,导致当前大部分研究不是“在一定的MDP分布上学习,使总体奖励最大化”,而是“先寻找一组相近的MDP,再学习使总体奖励最大化”。这种处理方式适合离散型多任务问题,不适合机器人学习这类连续控制问题;另外,将制约多任务策略网络的任务容量,进而降低空间操作应对复杂空间环境的能力。有限状态机、任务分解图等多任务表示依赖人的设计,难以参数化、规模化。由此,需要研究可学习的任务表示结构,在此基础上建立多任务表示之间的关系(例如利用隐空间的连续分布表示,代替one-hot型的离散分布表示),提高策略的任务容量。
3) 多源不确定性量化、估计与推断。具有多种来源的不确定性是复杂空间环境的关键特征。相关研究工作中未见针对此问题的讨论。现有研究工作中,域随机化作为一种增加策略执行鲁棒性的有效手段,对环境引入的摄动因素,增加交互数据的多样性。但摄动因素的确定(例如机械臂结构、质量、关节阻尼、控制时延、光照强度等),以及摄动方差的大小常通过经验来设计。摄动方差设定过大将破坏策略优化的收敛性,这一问题在多任务学习的问题设定下更加明显。此外,主观引入的摄动因素,和客观的环境不确定性之间会存在耦合影响,一旦优化算法训练失败,很难定位影响因素。由此,需要揭示空间环境不确定性的多方面来源,研究如何对多源不确定性进行量化、估计与推断,提高策略学习与执行的鲁棒性、灵活性。
6 结论
空间机器人操作面临多任务适应性要求高、精细化要求高、不确定性强问题。通过机器学习方法,特别是深度强化学习方法,可以实现简单的机械臂辅助加注操作,并具有一定的鲁棒性。但是多种任务独立学习的方案表示不统一、切换条件难设计,制约了这类方法的更深一步应用。针对长时间范围、序列化的空间机器人操作,依次递进地讨论了机器人操作学习、机器人操作多任务学习、空间机器人操作多任务学习。全面综述了多任务学习方法相关工作,包括经验复用、持续学习、结构化策略、蒸馏、梯度优化与适应、分布式学习等方面,涉及算法、计算与机器人应用3个维度。从算法角度,给出了理想的多任务学习算法应具备的4个条件。在满足多任务总体性能的同时,当前算法在任务选择、任务关系推断、跨任务知识迁移方面的性能仍存在局限。
围绕如何通过多任务学习方法实现高自主、强鲁棒的空间机器人操作,分析了共性关键技术,具体包括提高交互数据采样效率、建立可学习的任务表示、多源不确定性的量化等。上述共性关键技术的突破不仅可支撑在轨服务,还可支撑在轨装配、在轨制造、辅助离轨、空间碎片捕获等多种太空任务,为提升高轨、地外、深空等场景的空间操作智能性、助力我国空间机器人系统向全自主方向迈进打下技术基础。
